
基于卷积神经网络的酒文献关键词自动识别与标注算法
2024-01-01 00:00:00张桃童旭胡隆河杨强
宜宾学院学报 2024年6期




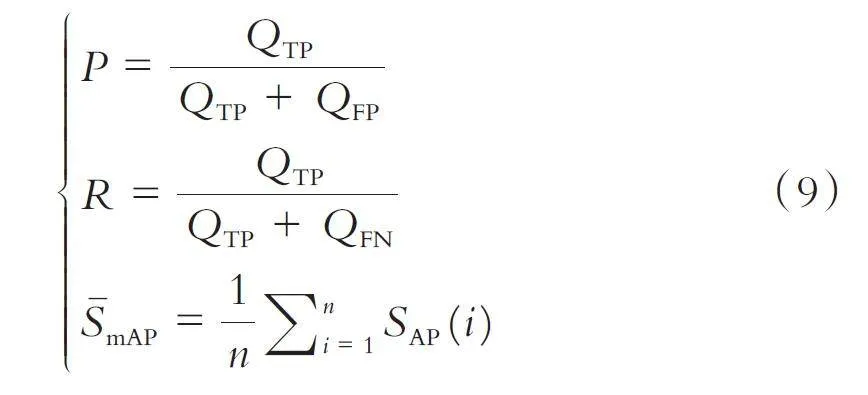


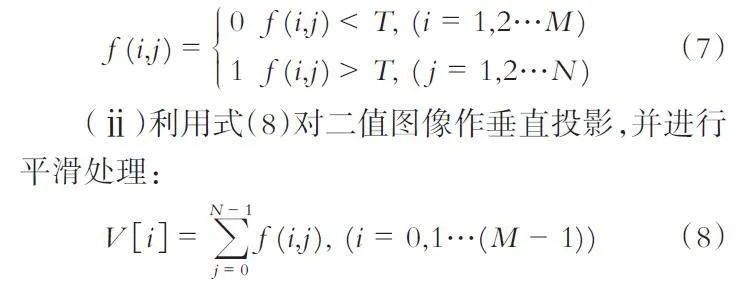
摘 要:关键词自动识别与标注算法在酒类历史文献自动分析和机器识别理解领域中有重要价值. 首先采用YOLOv7 网络模型进行酒文献的文本框识别,接着引入CBAM 注意力机制获得文本框位置、大小等特征,然后采用PaddleOCR 算法实现酒文献的关键词识别,最后应用文字修补技术进行优化处理. 应用该检测算法设计的实验分析系统能高效处理海量酒文献数据,以90% 的识别率提取文献中与酒类相关的文字信息,能有效克服酒文献中存在的文字印刷模糊不完整、字体种类多样的特殊情形,实验中取得了较好的识别标注效果.
关键词:深度学习;卷积神经网络;文字识别;酒文献
中图分类号:TP391
DOI: 10.19504/j.cnki.issn1671-5365.2024.06.05
在酒文献整理与标注分析研究中,由于文献数量庞大,人工检索和分析耗时耗力,因此采用人工智能和图像分析技术进行文献分析[1]尤其迫切和重要. 命名实体识别(Named Entity Recognition,NER)是自然语言处理中的一项关键任务,旨在从文本中识别和提取出具有特定意义的命名实体,如人名、地名、组织机构名、时间、日期等. 条件随机场模型(CRF)[2]是较为成熟的技术方案,但其通常需要手动设计特征函数来描述输入序列和标记序列之间的关系[3-4]. 随着深度学习技术和理论的发展[5-6],递归神经网络(RNN)、长短时神经记忆网络模型(LSTM)等应用其中[7-10],有效提升了特征提取的效率. 虽然相关研究已经探索了命名实体识别等技术在该领域的应用,但在酒文献处理上仍存在一些问题. 具体而言,当前的研究局限于特定领域,而酒文献涉及多方面,需要更细致和全面的分析. 本文拟利用大数据技术收集和整理酒史文献数据,结合卷积神经网络构建文献识别模型,实现自动化的酒文献识别和处理,从而更全面地理解酒文献中的内容.
1 PaddleOCR算法及YOLOv7-tiny网络模型
1.1 PaddleOCR 算法
PaddleOCR[11]基于PaddlePaddle 深度学习框架开发,提供了OCR 模型和工具,具有文字检测、文字识别和布局分析等功能. PaddleOCR 是一种基于深度学习模型,识别精度较高,具备良好的鲁棒性和泛化能力. PaddleOCR 预训练模型包括EAST、DB⁃Net、SAST、Rosetta、CRNN 等,能适用于不同的OCR 场景和需求. 由于白酒文献中的文字布局复杂、字体多样、字形多变,本文选择对繁体字识别效果较好的PaddleOCR 字符识别模型.
1.2 YOLOv7-tiny 网络模型
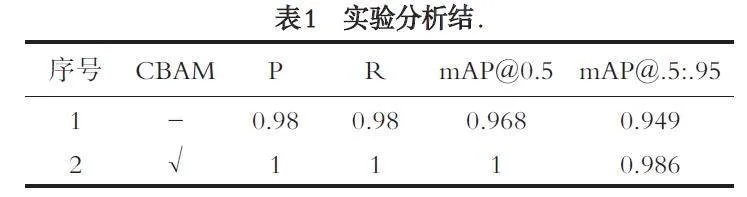
YOLOv7-tiny[12] 网络模型主要由输入端(In⁃put)、主干网络(backbone)、颈部和头部(Neckamp;Head)四个部分组成,YOLOv7-tiny结构如图1所示.
YOLOv7-tiny 模型输入端部分采用Mosaic 数据增强、自适应锚框计算、自适应图片缩放等方式对输入图像进行预处理. 主干网络部分由数个CBL 模块、MCB 层、MP 层共同组成,其中CBL 模块由1 个卷积层、1 个BN 层和Leakyrelu 激活函数组成;MCB层由5 个CBL 模块组成,它可以有效地学习和快速收敛;MP 层由3 个CBL 模块和一个最大池化层组成,两部分都对特征图进行下采样和通道数改变,最后将其结果融合,增强了特征提取能力. 颈部部分采用SPPCSP、UP 和MCB 结构,SPPCSP 模块有4 个CBL 模块,通过最大池化来增大感受野,以适应不同分辨率的图像;UP 模块通过最近邻插值的方式来进行上采样. 头部部分采用conv 和CBL 模块,通过提取特征,分别输出不同尺度大小的3 个预测结果.
2 本文算法及网络模型改进
2.1 改进的PaddleOCR 算法
由于古代酒文献布局复杂、字体古老、字形多变、印刷模糊,PaddleOCR 算法对于文本框的检测效果较差,有大量的漏检情况,进而影响了文字识别效率. 由于YOLO 在目标检测中的优秀表现,故将PaddleOCR 文本框检测部分替换为YOLO 网络模型,再将根据检测结果中得到的文本框输入到Pad⁃dleOCR 中,实现文献关键词的识别与标注.
2.2 改进的YOLOv7 网络模型
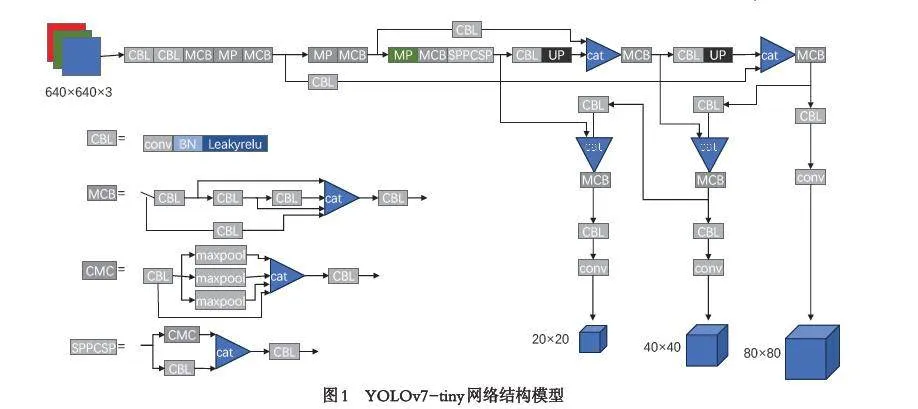
改进算法采用YOLOv7-tiny 网络模型对文本框进行检测,为了使文本框的方向、位置、大小特征获得更多关注,引入注意力机制CBAM[13](Convolu⁃tional Block Attention Module)以优化性能. CBAM模块主要由两个子模块组成:通道注意力模块(Channel Attention Module)和空间注意力模块(Spatial Attention Module),如图2 所示.
设输入特征图像为F ∈ RC × H × W(C、H、W 分别为特征图的通道数、高和宽),利用CBAM 注意力机制获得一维通道注意力特征Mc(F ) ∈ RC × 1 × 1 和二维空间注意力特征Ms (F ) ∈ R1 × H × W,计算式如下:
F' = Mc (F ) ⊗ F (1)
F '' = Mc (F' ) ⊗ F' (2)
其中:⊗表示元素乘法,F '' 表示最终结果.
在通道注意力模块中,将输入特征图F ∈ RC × H × W 分别经过基于水平和垂直方向的全局最大池化操作和全局平均池化操作之后,得到两个C × 1 × 1 的特征图,然后通过一个两层的MLP,第一层神经元个数为C/r(r 为减少率),激活函数为Relu,第二层神经元个数为C,两层权重是共享的.之后将两部分做逐元素求和,再通过激活函数(Sig⁃moid)生成通道注意力特征. 最后,将通道注意力特征与输入特征进行元素乘法,并将其结果作为空间注意力模块的输入,即:
Mc (F )= Sigmoid (MLP (AvgPool (F ))+MLP (MaxPool (F ))) (3)
其中:Mc (F ) ∈ RC × 1 × 1 表示通道特征,F 为输入特征图F ∈ RC × H × W.
空间注意力模块能学习特征图像中不同空间位置之间的相关性,并根据这些空间位置之间的相关性来分配不同的注意力权重. 将输入的特征图通过基于通道的全局最大池化操作和全局平均池化操作,基于通道的全局最大池化是对输入特征图在通道维度上进行全局最大池化,这一步的目的是获取每个空间位置上特征的最大值,以捕捉每个位置上的显著特征,计算公式为Pmax = maxc Xcij,Xcij 表示特征图X 在通道c、位置(i,j ) 处的值. 基于通道的全局平均池化是对输入特征图在通道维度上进行全局平均池化. 这一步的目的是获取每个空间位置上特征的平均值,以捕捉每个位置的整体信息. 计算公式为Pavg =1/CΣc = 1CXcij,分别得到两个1 × H × W 的特征图,将两个特征图作通道拼接,再经过一个7×7 的卷积操作,得到一个1 × H × W 的特征图,然后通过激活函数(Sigmoid)来生成空间注意力特征. 最后,将其与输入特征图进行元素乘法运算,最终得到在空间维度上关注重要特征的特征图,计算式为:
Ms (F ) =Sigmoid ( f 7 × 7 (AvgPool (F );MaxPool (F ))) (4)
其中:Ms (F ) ∈ R1 × H × W 表示空间特征,f 7 × 7 表示一个大小为7×7 的卷积运算,F 为输入特征.
2.3 文字修补技术
古代酒文献关键词识别实验存在部分文字断开的情况,严重影响文献关键词识别精度. 为了解决以上问题,本文先使用膨胀(Dilation)、再使用腐蚀(Erosion)方法对文字修补技术,以达到修复填补文字断开的区域,进而提升检测效果. 在文本识别技术中,腐蚀和膨胀是一些基本的形态学操作,通常用于处理二值化图像,其中文本区域被视为前景,背景为其他部分. 腐蚀和膨胀操作可以使用数学形式表示,其中结构元素(kernel)通常用一个矩阵或二维数组表示.
膨胀操作使用结构元素,在图像中滑动并将其放置在像素上. 如果结构元素与文本区域有任何重叠,该像素就被标记为前景. 主要作用是扩展前景对象的边界,填充空白区域,连接文本区域内的断裂部分. 膨胀操作有助于连接字符之间的空隙,填充笔画之间的空白,使文本更加连贯. 如果图像表示为二值矩阵I,结构元素表示为矩阵K,膨胀操作Dilated (I,K )的数学表达如下:
Dilated(I,K ) (x,y ) = max(i,j ) ∈ KI (x + i,y + j ) (5)
其中:max 为取最大值操作,(x,y )表示当前像素的坐标,(i,j ) 表示结构元素的坐标. 该公式表示在位置(x,y ) 处,膨胀操作将图像中与结构元素K 重叠的部分的最大值作为输出.
腐蚀操作通过在图像中滑动一个结构元素(kernel)并将其放置在像素上,只有当结构元素完全覆盖文本区域时,该像素才被保留为前景,否则被置为背景. 主要作用是缩小或消除前景对象的边界,去除小的细节,使前景区域变得更加紧凑. 对于文本而言,腐蚀操作有助于消除细小的笔画或连接线,使文本区域更加清晰. 腐蚀操作Eroded (I,K )的数学表达如下:
Eroded(I,K ) (x,y ) = min(i,j ) ∈ K I (x + i,y + j ) (6)
其中:min 为取最小值操作,(x,y )表示当前像素的坐标,(i,j ) 表示结构元素的坐标. 该公式表示在位置(x,y ) 处,腐蚀操作将图像中与结构元素K 重叠的部分的最小值作为输出.
3 算法实现
首先引入YOLOv7-tiny 模型进行文本框检测,接着采用膨胀和腐蚀方法对文字进行修补,最后采用的改进的识别算法完成酒文献的识别. 实现效果如图3 所示,整体检测识别算法具体实现步骤如下:
第一步:输入初始图像F.
第二步:对初始图像F 利用YOLO 目标检测算法进行文本框检测,并使用投影法[14]按列分割,从而得到文本框集合Φ: { Ni,i = 1,2,3… },其中Ni 表示第i 个文本框.
设M、N 分别分投影区域的水平和垂直像素点个数,f (i,j )为像素点(i,j )处的灰度值,则投影法实现步骤如下:
(ⅰ)首先对图像采用阈值法进行二值化处理,由于需识别图像颜色较为单一,T 可取128,计算如式(7)所示.
其中:V [ i ]表示纵轴垂直投影值,i 表示横轴.
(ⅲ)利用平滑后的曲线,计算出波谷之间的平均距离作为参考值,将波谷所对应的垂直线作为列分割线.
第三步:再次利用YOLO 目标检测算法将得到的文本框集合Φ 按行分割,得到单个文字框Ω:{ Mj,j = 1,2,3… },其中Mj 表示第j 个文字框.
第四步:利用文字修补技术,先膨胀后腐蚀. 膨胀后结果为F1 = max(i,j ) ∈ Kernel{F (x + i,y + j )},腐蚀后结果为F2 = min(i,j ) ∈ Kernel{F } 1 (x + i,y + j ) ,其 中Kernel为操作核,(i,j )为坐标,Kernel大小为α × α,α为操作核大小参数,根据文字大小调整.
第五步:利用PaddleOCR 文本识别算法对单个文字框集合Ω结合F2 进行识别,输出检测结果文字集合Λ和识别结果图像F'.
PaddleOCR 文本识别算法步骤如下:
步骤一:特征提取,使用卷积神经网络(CNN)对输入的序列进行特征提取. 这一步通过一系列的卷积层和池化层来从输入图像中提取特征,并生成特征图(Feature Map).
步骤二:循环层处理,将特征图输入到循环层中进行处理. 在PaddleOCR 中,循环层由一个双向LSTM(Long Short-Term Memory,长短时记忆)循环神经网络构成. LSTM 是一种特殊的RNN(Re⁃current Neural Network,循环神经网络)结构,能够捕获长距离依赖关系. 在PaddleOCR 中,LSTM 使用了双向结构,即同时使用过去和未来的信息,这有助于提高模型的性能和稳定性.
步骤三:预测特征序列的标签分布,在循环层中,预测特征序列中的每一个特征向量的标签分布. 这一步通过将LSTM 网络的输出连接到一个全连接层和一个Softmax 函数来实现,生成每个字符的概率分布.
步骤四:整合结果,最后,将LSTM 网络预测的特征序列的结果进行整合,转换为最终输出的结果. 在PaddleOCR 中,这一步通过转录层(Transcrip⁃tion Layer)完成,将LSTM 网络的输出转换为最终的识别结果.
在PaddleOCR 中,文本识别的核心公式主要包括卷积神经网络(CNN)的特征提取、循环神经网络(RNN)的处理以及全连接层和Softmax 函数的概率转换. 这些公式是实现文本识别算法的关键部分,具体如下:
(ⅰ)卷积层:卷积层是用于特征提取的核心部分,通过在输入图像上应用一系列的卷积核进行卷积运算,生成特征图. 常用的卷积操作公式可以表示为: F (x,y ) =Σi = 1kwi × xi,y,其中F (x,y )表示在位置(x,y )的特征值,wi 表示第i 个卷积核的权重,xi,y 表示输入图像在位置(x,y )的特征值.
(ⅱ)循环层:循环层是用于处理序列数据的核心部分,通过定义一个递归神经网络来捕捉序列数据的时序依赖关系. 在PaddleOCR 中,循环层使用了双向LSTM 结构,其核心公式包括LSTM 单元的递归公式和输出公式. LSTM 单元的递归公式可表示为:
[ ft,it,gt,ot ] =σ ( [Wxf xt + Whi ht - 1 + bf ] , [Wxi xt + Whi ht - 1 + bi ] ,[Wxg xt + Whg ht - 1 + bg ] , [Wxo xt + Who hp - 1 + bo ])
其中ft、it 、gt 、ot 分别表示遗忘门、输入门、候选细胞状态和输出门的输出,W 和b 分别表示权重和偏置项,σ 表示激活函数.
(ⅲ)全连接层和Softmax 函数:全连接层用于将前一层的输出转换为固定长度的向量,而Softmax 函数则用于将每个字符的概率转换为概率分布. 全连接层的公式可以表示为:a = Wx + b,其中a 表示输出向量,W 和b 分别表示权重和偏置项,x 表示输入向量. Softmax 函数的公式可以表示为:σ (x ) =ex/ex + ex + 1 + … + ex + N,其中σ (x ) 表示输入向量x 经过Softmax 函数后的概率分布.
4 实验分析
4.1 数据集介绍
数据集来源于中国酒史研究中心酒文献数据库,包括《秋白诗集》《畴人传》《诸子集成(论语正义)》《太平御览》《中国文学》,数据集中含有隶书、楷书、繁体字等多种字体,皆为竖版排列,酒文献数据丰富. 经实验整理,选择共计24 000 张作为初始图像数据集. 选取其中一部分进行文本框手工标注,以此作为文本框检测训练数据集,标注如图4 所示.
4.2 文本框单字分割
将通过投影法得到的各个列文本框,应用YO⁃LOv7 算法框选出单个汉字,实现单个文字的分割,实验结果如图5 所示. 对分割出的文字图像进行修补,修补顺序为先膨胀、后腐蚀,以提高部分受损文字的识别准确率,实验结果如图6 所示,图中从左至右依次为原图、膨胀后、腐蚀后变化效果.对分割出的酒文献汉字进行文本识别,实验结果如图7 所示.
4.3 评价指标
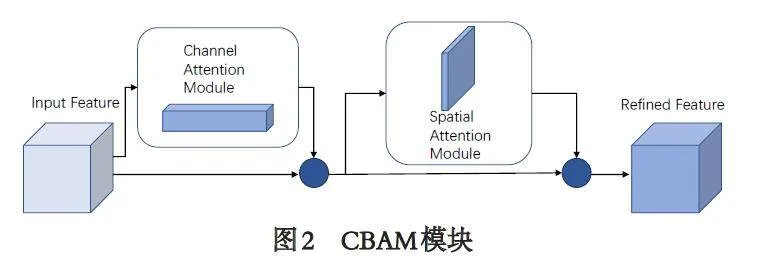
为定量判断分析本文献的改进算法对古代酒文献文本框的检测和关键字识别效果,本文采用以下评价指标来评估模型性能表现,其中指标包括精确率(Precision)、召回率(Recall)、平均精度均值(meanAverage Precision, mAP 值),计算如式9 所示.
式中:P 表示所有预测目标中正确的比例,QTP 为正样本被检测正确的数量;QFP 为负样本被检测为正样本的数量;QFN 为背景被错误检测为正样本的数量;R 表示所有已标注目标中被正确检测的比例;n 表示类别数量,SAP 表示以R 为横轴、P 为纵轴形成的P -R 曲线的面积,该曲线反映了模型在不同置信度阈值下的性能. 平均精度是对这个曲线下面积的平均值. 在一个类别上,精度越高、召回越大,平均精度就越高. 对每个目标类别计算出来的SAP 进行取平均值,可以得到mAP 值(sˉmAP),用于评估目标检测模型的性能,特别是在处理多类别物体检测任务时,mAP 值越大表示模型性能越好.
在本文的实验分析中,将IoU 设为0.5 时,计算每一类的所有图片的SAP,把所有类别求平均,即可得到mAP@0.5. mAP@.5:.95 表示在不同IoU 阈值(从0.5 到0.95,步长0.05,即0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP 值.
4.4 实验结果分析
本文采用YOLO 网络模型进行文本框检测,在此基础上增加注意力机制CBAM 进行优化,进行消融实验,结果如表1 所示.
表1 表明,引入的CBAM 方法在P、R、mAP@0.5、mAP@.5:.95 四个评价指标上均有提升,分别提升了2%、2%、3.2%、3.7%,证实本文方法的有效性,提升了模型在文献中文本框的检测性能,在海量文献识别任务中的文本框漏检情况得到了较好的解决.
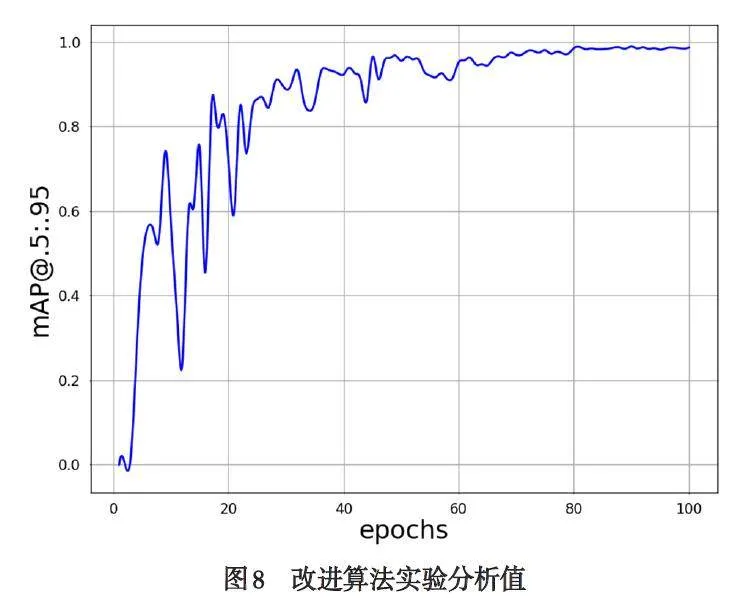
图8 的曲线反映了改进后的模型性能随训练轮次增加,mAP@.5:. 95 值的变化趋势. 在0-50 轮,mAP@.5:.95 快速提高,表明该模型收敛速度较快,性能较好. 50-70 轮,缓慢增长,70-100 轮之后基本趋于稳定,模型已经达到收敛状态.
酒文献汉字识别结果如图9 所示.
5 小结
基于卷积神经网络的酒文献关键词识别与提取算法能够更加快速地识别和分类各种类型的酒类文献,实现关键词的自动提取和标注,为酒文献赋予标签,也为酒文献的检索和查询提供更便捷的方法.本文借助深度学习与大数据技术,旨在从海量历史文献资料中发现关键信息,并找到内在联系,揭示传统文献中隐藏的知识关系和发展趋势,以优化传统酒史文献学研究和信息查找的路径.
本项目的研究开展,还将充分利用搜索引擎和网络爬虫技术在网络上寻找酒史文献资料,同时作为酒史研究数据库不断新增丰富,为将来可能的历史研究提供支持. 利用数字化技术实现文献的提取与分类研究,项目的开展将在挖掘酒史文化数据方面具有潜在意义,能为酒史文化研究发现新知识,提供新方法.
参考文献:
[1] GAO H, ERGU D, CAI Y, et al. A robust cross-ethnic digi⁃tal handwriting recognition method based on deep learning[J].Procedia Computer Science, 2022(199): 749-756. doi:10.1016/j.procs.2022.01.093.
[2] LAFFERTY J, MCCALLUM A, PEREIRA F C N. Condi⁃tional random fields: Probabilistic models for segmenting andlabeling sequence data[EB/OL]. (2001-06-28) [2023-01-27]. https://dl.acm.org/doi/10.5555/645530.655813.
[3] 黄水清,王东波,何琳. 基于先秦语料库的古汉语地名自动识别模型构建研究[J]. 图书情报工作,2015(12):135-140.
[4] 李娜. 面向方志类古籍的多类型命名实体联合自动识别模型构建[J]. 图书馆论坛, 2021, 41(12):11.
[5] LECUN Y, BENGIO Y, HINTON G. Deep learning[J]. Na⁃ture, 2015, 521(7553): 436-444.
[6] BENGIO Y, GOODFELLOW I, COURVILLE A. Deeplearning[M]. Cambridge, MA, USA: MIT Press, 2017.
[7] 谢韬. 基于古文学的命名实体识别的研究与实现[D]. 北京:北京邮电大学,2018.
[8] 杜悦,王东波,江川,等. 数字人文下的典籍深度学习实体自动识别模型构建及应用研究[J]. 图书情报工作,2021,65(3):100-108.
[9] HOCHREITER S, SCHMIDHUBER J. Long short-termmemory[J]. Neural Computation, 1997, 9(8): 1735-1780.
[10] GRAVES A, SCHMIDHUBER J. Framewise phoneme clas⁃sification with bidirectional LSTM and other neural networkarchitectures[J]. Neural Networks, 2005, 18(5-6): 602-610.
[11] LI C X, LIU W W, GUO R Y, et al. PP-OCRv3: More at⁃tempts for the improvement of ultra lightweight OCR system[EB/OL]. (2022-06-07) [2023-01-27]. ArXiv: abs/2206.03001.
[12] WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YO⁃LOv7: Trainable bag-of-freebies sets new state-of-the-artfor real-time object detectors[EB/OL]. (2022-07-06)[2023-01-27]. arXiv:2207.02696.
[13] WOO S, PARK J, LEE J Y, et al. CBAM: Convolutionalblock attention module[C]//Ferrari V, Hebert M, Sminchis⁃escu C, et al. Computer Vision – ECCV 2018. Springer,Cham, 2018. doi:10.1007/978-3-030-01234-2_1.
[14] 李治强,杨强. 基于时空分布特征的新闻字幕检测改进算法[J]. 广播与电视技术,2007,34(2):103-105.
【编校:王露】
基金项目:四川省哲学社会科学重点研究基地中国酒史研究中心开放基金项目(ZGJS2021-03);四川省科技计划重点研发项目(2021YFG0029)
猜你喜欢
科技创新与应用(2016年35期)2017-02-21 19:16:50
计算机应用(2016年12期)2017-01-13 20:26:21
江苏教育·中学教学版(2016年11期)2016-12-21 11:36:29
现代情报(2016年10期)2016-12-15 11:50:53
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
电脑知识与技术(2016年10期)2016-06-16 21:27:26
