
基于注意力机制的YOLOv5优化模型
2023-12-30 05:26潘烨新黄启鹏
计算机技术与发展 2023年12期
潘烨新,黄启鹏,韦 超,杨 哲
(1.苏州大学 计算机科学与技术学院,江苏 苏州 215006;2.省计算机信息处理技术重点实验室,江苏 苏州 215006)
0 引 言
目标检测是机器视觉领域重要的研究内容之一[1],目前主流的检测模型分为单阶段模型、双阶段模型以及基于Transformer解编码结构的模型[2]。双阶段算法先提取候选区域再进行分类和回归,如RCNN[3],Faster R-CNN[4]系列。这些方法在检测精度上表现出色,但由于计算量较大,检测速度较慢。单阶段检测算法无需提取候选区域, 2直接对每个特征图进行回归预测。经典的单阶段检测算法有YOLO[5],SSD[6],FCOS[7]等系列算法,YOLO因检测速度快被广泛应用于工业和日常生活中。但由于YOLOv5使用的骨干网络CSPDarknet-53[8]提取的特征图尺寸较小、分辨率较低、像素感受野较大,导致小目标的定位性能较差,因此整体性能仍存在一定的优化空间。同时整个网络中主要负责提取图像特征的是C3模块,分布在网络的骨干和颈部中。在骨干部分,C3模块可以为特征图提取到大量的位置与细节信息,但语义信息提取的较少。当特征图前向传播到颈部部分后,在特征金字塔网络(FPN[9])与像素聚合网络(PAN)框架的结合作用下,C3模块主要负责纹理特征的提取,此时会获得较为丰富的语义信息,但丢失了大量的位置与细节信息。导致网络模型对于小物体及有遮挡目标产生漏检误检情况,性能下降。该文提出一种基于注意力机制的YOLOv5优化模型。通过引入DRA(Dimension Related Attention,维度关联注意力)模块来解决C3模块信息丢失问题,增强主干网络提取图像特征的能力;针对感受野大而导致的定位困难问题,引入新的定位计算损失函数,在提高边界框的定位精确度的同时优化模型的推理速度,间接提升模型的性能。在通用数据集上的实验结果表明,该方法提升了主干网络的特征提取能力,降低了回归参数的损失,从而提升了模型的整体性能。
1 相关工作
1.1 目标检测模型
双阶段模型的代表RCNN开创性地使用深度学习模型进行目标检测。但存在两个问题:一是经过缩放处理后会使一些图片特征信息丢失,从而降低检测的准确性,不利于小目标的检测;二是在训练和预测中,RCNN的速度都非常慢。Faster R-CNN提出了区域生成网络(Region Proposal Networks,RPN)用于提升检测框的生成速度,最终精度较高,但实时性与检测小目标的效果差。YOLO是单阶段模型的起始作,不再生成候选区而是直接进行分类和回归。v1通过将图像划分成多个网格来生成候选框。相比于二阶段模型,检测速度有了很大提高,但精度相对较低,尤其在小目标检测方面。v2[10]改变了主干网络,相比v1模型在精度、速度和分类数量上都有了很大的改进,但由于每个网格只能预测一个物体,当同一个网格内包含多个物体时只能检测到一个,因此对小物体的识别效果仍然非常差。v3[11]中提出了基于锚框的思想,使得最后的特征图上基于每个单元格都有三个不同的尺寸大小的锚框,进而对锚框进行分类与回归。v4[8]针对预处理以及激活函数问题,分别引入了Mosaic数据增强手段以及Mish激活函数[12],使得网络的收敛速度与精度进一步提升,但仍然存在框定位不准以及召回率低的问题。YOLOv5在对模型主干以及颈部的基础改进之外,更换了新的损失函数计算方法,同时优化了一直存在的正负样本分配问题。但对于整体而言,预测框的回归精度与速度仍然较差。研究者们针对不同应用场景和问题,提出了基于YOLOv5的一系列应用优化算法。张浩等人[13]提出的算法旨在提高无人机视角下密集小目标的检测精度,并保证实时性。李永军等人[14]将红外成像与v5模型相结合,解决动态识别与密集目标的问题。窦其龙[15]通过优化深度学习网络、重新设置锚点框大小和嵌入GDAL模块,提高检测速度和降低漏检率。刘闪亮[16]则提出了注意力特征融合结构,进一步提高模型对小目标的检测性能。田枫[17]提出了Cascade-YOLOv5,用于油田场景规范化着装检测,来提高检测性能。这些算法都是基于YOLOv5的改进和优化,以适应不同领域和应用需求。
1.2 注意力机制
在机器视觉领域,常使用的是软注意力,对其按维度可划分为通道注意力、空间注意力和自注意力。通道注意力旨在联系不同特征图,通过网络训练获取每个通道的重要度从而赋予不同权重最终强化重要特征,代表模型如SE-Net(Squeeze and Excitation)[18]。空间注意力通过空间转换和掩码加权等方式增强兴趣区域[19]的同时弱化背景区域。如轻量级注意力模块CBAM[20]。自注意力旨在最大化利用特征自身的固有信息进行交互。在Google提出的Transformer架构中被实际应用,何凯明等人将其应用到CV领域,并提出了Non-Local模块[21],通过自注意力机制有效地捕获长距离的特征依赖,实现全局上下文信息的建模。注意力机制模块众多,模型性能差异大,对比评估一些新型且有效的注意力机制模块,并进行一些创新改进,对提升复杂多尺度目标的检测性能是非常有意义的。
2 改进后的YOLOv5优化模型
2.1 DRA注意力机制
DRA模块在经典的SE模块上做出优化,如公式1所示,它可以对网络中任意的中间特征张量进行转化变换后输出同样尺寸的张量。DRA模块结构如图1所示。

图1 DRA注意力机制
X=[x1,x2,…,xc]∈RH×W×C→
Y=[y1,y2,…,yc]∈RH×W×C
(1)
在原先同时关注空间和通道信息的基础上,通过改变全局池化的操作,保留通道间信息的同时考虑重要的空间信息。
通道注意力常采用全局池化编码全局空间信息,简而言之是全局信息被压缩成了一个标量,而压缩完之后的标量难以保留重要的空间信息。为解决此问题,DRA将全局池化操作改进为两个1维向量的编码操作。
为了获取输入图像的高度与宽度上的注意力,并完成对精确位置信息的编码,对于输入特征图,使用池化核(1,W)和(H,1)分别对高度和宽度的特征进行平均池化,从而获得两个方向的特征图,如式2和式3所示。
(2)
(3)
对比全局池化的压缩方式,这样能够允许注意力模块捕捉单方向上的长距离关系,同时保留另一个方向上的空间信息,帮助网络模型更准确地定位目标。
接着将获得全局感受野的高度和宽度两个方向的特征图按通道维度拼接在一起,主要目的是方便之后进行批量归一化(Batch Normalization,BN)操作。将它们送入卷积核为1×1的共享卷积模块Conv2D,将其维度降低为C/r,r为可设定的缩减因子,接着对其进行BN处理,将得到的特征图记为F1,最后送入Swish激活函数进行非线性变换,将这种变换记为δ,即可得到尺寸为C/r×1×(W+H)的包含横向和纵向空间信息的特征图f,如公式4所示。
f=δ(F1([Zh,Zw]))
(4)
随后将f按照原来的高度和宽度进行卷积核大小为1×1的卷积,分别得到通道数与原来一样的两个独立的特征fh和fw,最后经过Sigmoid激活函数后,分别得到特征图在高度上的注意力权重gh和在宽度方向的注意力权重gw,如式5和式6所示。
gh=σ(Fh(fh))
(5)
gw=σ(Fw(fw))
(6)
最后在原始特征图上通过乘法加权计算,得到最终在宽度和高度方向上带有注意力权重的特征图,如式7所示。
(7)
2.2 注意力机制融合
针对原模型对于特征表达能力的不足,不易识别难检目标,以及由于只考虑通道信息而缺失方向相关信息带来的定位不准等问题,通过将DRA模块插入到网络模块中解决。同时由于原模型的主干,颈部,检测头三层结构会带来结果的干扰性以及不确定性,该文分析了在三层结构不同位置插入DRA模块的效果。如图2所示,分别在主干,颈部,预测头中插入DRA模块。对于主干部分,细分了DRA的插入位置。根据后续实验表1的数据,最终确定选择(b)方式插入到主干,将新的整体结构命名为CDRA模块,取代原模型主干中的C3模块。CDRA模块相比YOLO v5原先的C3模块最大的改进在于,每个权重都包含了通道间信息、横向空间信息和纵向空间信息,能够帮助主干网络更准确地定位目标信息,增强识别能力。

表1 不同位置的注意力机制融合结果对比 %
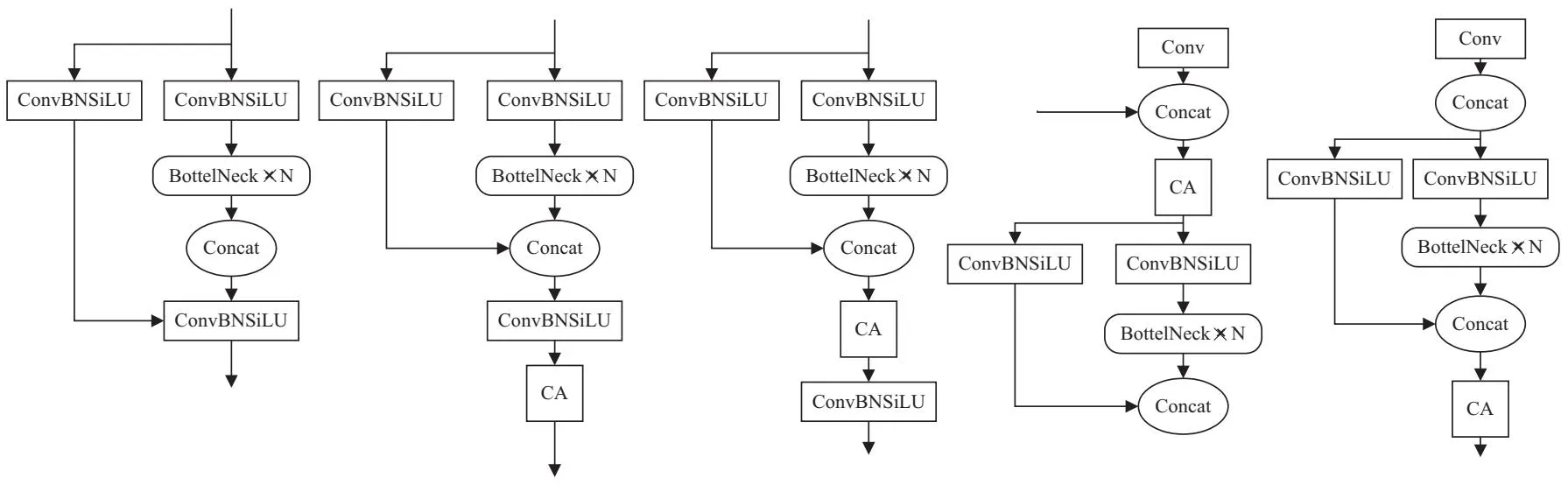
(a)原C3结构 (b)插入主干C3最后一层 (c)插入主干C3的残差模块 (d)插入Neck部分 (e)插入Head部分
将运用维度关联注意力机制融合的CDRA替换原C3模块,经过改进后的YOLOv5s结构如图3所示。图3中,YOLOv5s主要由主干网络、颈部、预测头部网络三部分组成,主干部分的替换工作对改进后的YOLOv5s性能提升起到决定性作用。
2.3 损失函数
目标检测模型的损失函数通常由三个部分构成,分别为预测框的定位损失Lbox,置信度损失Lobj,分类损失Lcls,整体的网络损失的计算如式8所示。
L=Lbox+Lobj+Lcls
(8)
其中置信度损失和分类损失均采用交叉熵损失(Binary Cross Entropy Loss),公式如式9所示。
(9)
预测框的定位损失用来衡量当前模型所给出的预测框与真实框之间位置上的误差,具体会计算两者的中心坐标、高、宽等误差。早期模型一般采用L1,L2,smooth L1来计算该损失,但其忽略了4个回归参数之间的相关性。当前常用的是交并比损失(Intersection over Union,IoU),IoU的计算公式如式10所示。
(10)
其中,B=(x,y,w,h)表示预测框的位置,Bgt=(xgt,ygt,wgt,hgt)表示真实框的位置。
IoU损失的计算公式如式11所示。
lossIoU=1-IoU
(11)
由公式可知两个矩形框重合度越高,IoU越接近1,则损失越接近0。但采用IoU损失生效的情况仅在两框之间有重叠的部分,对于非重叠的两个框,IoU损失不会提供任何可供传递的梯度。
YOLOv5原始模型中采用CIoU作为边界框的定位损失函数。CIoU是在DIoU(Distance IoU)[22]的基础上考虑了两框的长宽比而演化而来,但是仍然没有考虑到真实框与预测框之间不匹配的方向。这种不足导致CIoU收敛速度较慢且效率较低。
为了解决CIoU存在的问题,该文引入SIoU[23]用以改进,保留了原损失函数的全部性质,同时考虑方向框的角度回归问题,重新定义了惩罚指标。
SIoU由四部分组成:角度损失Λ、距离损失Δ、形状损失Ω以及交并比损失(IoU)。
角度损失函数组件Λ,如式12所示。
(12)
其中,x是直角三角形中的对边比斜边,如图4所示,α是两框中心连线与预测框中心水平线的夹角。则x可由式13表示。
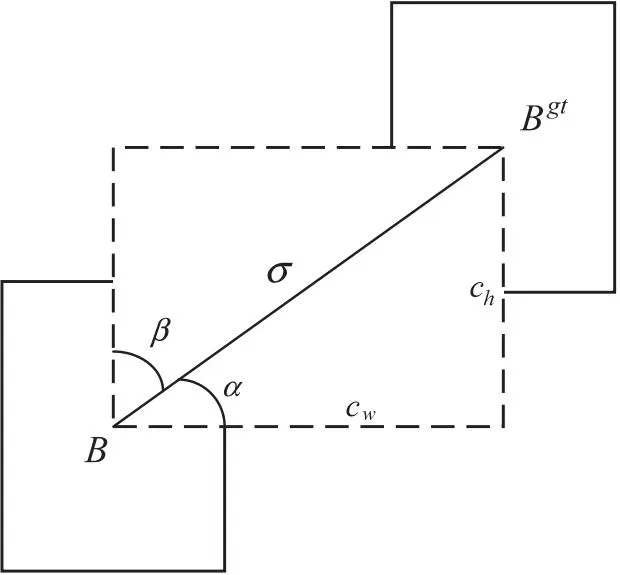
图4 损失函数组件示意图
(13)
其中,ch为真实框和预测框中心点的高度差,σ为真实框和预测框中心点的距离,可由式14表示。
(14)
将式13带入式12化简可得最终的角度损失计算公式,如式15。
Λ=sin(2α)
(15)
定义角度损失后,考虑到当出现同时存在一个角度很小但是很近,与一个角度很大但是很远的框的情况时,近的框总是会被优先选择,所以直接使用角度损失不合理,还需要考虑距离与角度的互相关系。为了保证距离与角度的平衡,将角度损失同时考虑,重新定义了距离损失函数,记为Δ,如式16所示。
微库仑综合分析仪(江苏江分,JF-WK-2000);轻油氯标准物质(10mg·kg-1,江苏江分);冰醋酸(优级纯,科密欧);二次蒸馏水或去离子水。工作时参数设置。见表1。
(16)
其中,ρx,ρy,γ定义如式17所示。
(17)
ρt是使用原始的距离损失的平方次幂来赋权重,说明距离的影响要大于角度的影响。
形状损失主要负责从长宽角度评价预测框的回归参数与真实框是否相似,记为Ω,如式18所示。
(18)
其中,ωw,ωh如式19所示。
(19)
θ用来控制整体对形状损失的关注程度。
综合考虑上述3项以及默认的IoU损失,就可以得到最后的预测框的定位损失函数,如式20所示。
(20)
3 实验与分析
3.1 实验环境
实验环境配置:Window10操作系统,32核Intel CPU,32 GB内存,两块TELSA A100,40 GB存储空间。深度学习框架为PyTorch1.10,图形处理器驱动为CUDA11.4和Cudnn8。训练过程中所使用的优化器为Adam[24],初始学习率为0.01,动量因子为0.937,权重衰减为0.000 25,批尺寸为32,总迭代次数设置为300。
3.2 数据集及预处理
使用Pascal VOC07+12训练集以及VOC07测试数据集来评估模型性能,包含20个类别的常见交通工具、家具和动物等图像,可用于目标检测任务。共包含8 281张训练图像、8 333张验证图像和4 952张测试图像。同时,在ImageNet数据集上对模型的主干网络进行了预训练,在训练过程中,使用Mosaic数据增强技术对前75%的训练周期进行了处理。
3.3 评估指标
使用检测速度、检测精度和损失函数收敛曲线等客观指标来评价模型的性能。其中,FPS是检测速度的评价指标。AP(Average Precision)是指在0~1范围内P(Precision,正确率)指标对R(Recall,召回率)指标的积分,即P-R曲线下面积,AP值越大,模型精度越高。mAP是平均精度均值,指的是每个目标类别AP的均值。
(21)
(22)

(23)
(24)
式中,TP表示正确识别的目标数量,FP表示识别错误的目标数量,FN表示未被识别出目标数量。如果IoU大于一定阈值,则检测框被标记为TP,否则为FP,如果检测到真实目标没有匹配到对应的预测框则标记为FN。
3.4 结果分析
3.4.1 改进模型的性能综合分析
如2.3节所述,该文尝试将DRA模块融合到网络模块的不同位置,并对相应检测结果展开对比。分别在原模型的主干,颈部,检测头中融入DRA模块。特殊的对于backbone部分,更细化地对比了简单的拼接在尾部或是融入原本的C3模块中的结果数据。实验结果如表1所示,将DRA模块融入主干网络中C3模块的最后一层检测效果最佳。YOLOv5网络中提取特征的关键网络在主干部分,其中隐含着易被网络忽视掉的小目标特征信息,而在加入DRA模块后,对这部分的特征信息进行了注意力重构,突出了重要信息,而在网络更深的Neck以及Head部分,小目标的特征信息被淹没,语义信息较为粗糙,注意力模块难以区分出空间以及通道特征,自然无法很好地对特征进一步加强重构。
同时,将文中对YOLOv5的注意力及结合方式与其他注意力机制做对比,对比结果如表2所示,SE[18]是经典的注意力机制起源,CA[25]是坐标注意力机制,CBAM[20]是经典的空间通道注意力机制,ANG是一种轻量型的融合注意力机制方法模型。可以看出模型并不适合简单地嵌套所有的注意力机制,当融合SE后,模型的漏检率不降反增,说明网络对于深层信息还是没有掌握能力,再看ANG模型,轻量化的同时也带来了精度的大量牺牲,而传统的CA,CBAM也都基本维持在原精度附近,说明对于网络没有实质性的提升。

表2 不同注意力机制融合对比结果 %
为了分析不同的改进策略对于模型最后的检测性能的影响,设计了4组消融实验,结果如表3所示,其中,“×”代表在网络中未使用的改进策略,“√”代表使用了改进。改进1在网络中替换了损失函数,解决了目标框与预测框的角度问题,使模型收敛速度与定位精准度提升;改进2在网络主干部分的C3模块中融合了DRA注意力机制,使得权重中同时包含了通道信息,横向以及纵向空间信息,mAP提升了4.0百分点,FPS下降了12.8;改进3将两者同时融入网络中,如前文所述,模型在更好地提取特征的同时加快了收敛速度,mAP最终提升了4.7百分点,检测速度则在改进2的基础上加速了5.2,仅与原模型相差7.6。
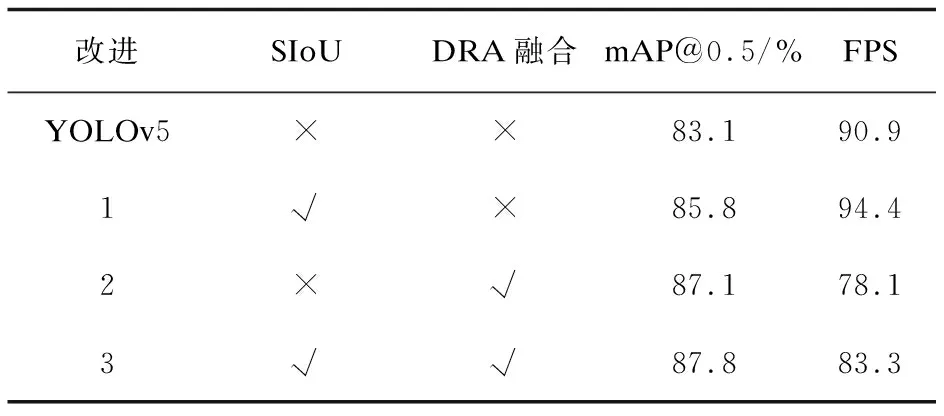
表3 消融实验结果
同时将消融实验的mAP@0.5曲线绘制在同一个坐标系中,如图5所示,改进后的模型在迭代次数达到45时逐渐趋于稳定。进一步分析SIoU改进的数据值曲线,与原始模型的曲线对比,以更高的收敛速度趋于稳定,表明了SIoU损失函数的替换使得回归目标框能够以更快的速度,更低的损失,精准地定位到待检测目标。
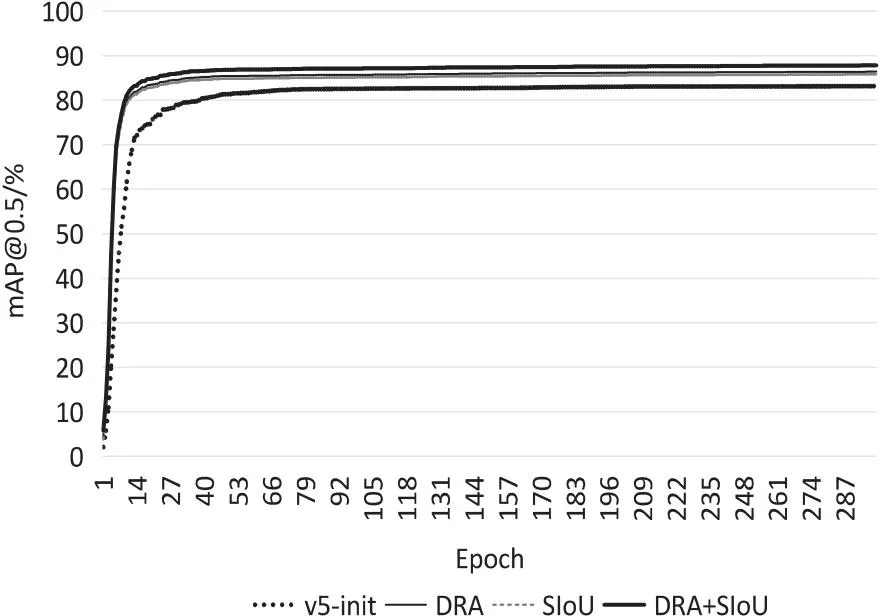
图5 不同改进策略的mAP@0.5对比
3.4.2 模型对比实验
同时将文中模型与其他模型对所有类别检测精度进行对比分析。Faster R-CNN[4]是二阶段检测模型的典型代表,SSD[6]是经典单阶段模型,v3[11]在精度和速度上有较好的均衡性能。v7[26]是当前表现较为出色的检测模型,而YOLOv5是文中改进对象。表4为所比较模型在所有类别上的检测平均精度对比,在所有20类上的检测结果均优于原v5s模型,平均精度均值为87.8%,同时与当前较为优秀的YOLOv7模型相比,20类中有16类的结果高于v7,同时最终的平均精度均值提升1.4百分点。

表4 VOC上各类别平均精度结果
为进一步证实文中算法的有效性和优越性,将文中算法模型与主流模型进行对比。由表5中实验结果可得,文中算法模型在保持一定检测速度的情况下,拥有更高的检测精度。与传统的双阶段算法Faster R-CNN[4]相比具有较大的检测速度优势,平均精度均值提升了14.6百分点。与YOLO系列算法相比,改进模型比v3[11],v4[8],v5,v7[26]原始模型的检测精度分别提高了10.6,15.1,4.7和1.7百分点。对于衡量难检目标以及小目标检测问题的阈值为0.5到0.95的平均精度均值(mAP@0.5:0.95),对比v5提升了4.5百分点,对比v7提升了2.8百分点。而在检测速度方面,文中模型虽比原始模型有所降低,但仍达到83.3 frame/s,完全可以满足工业场景下的实时检测要求(30 frame/s)。
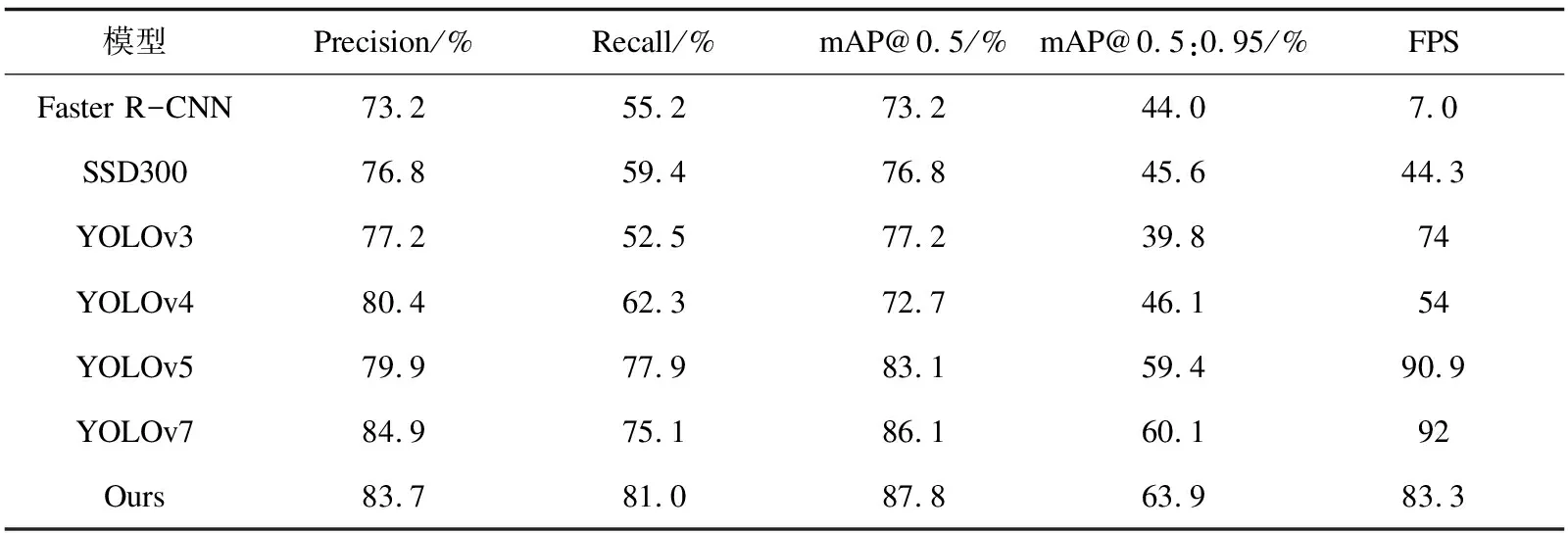
表5 不同模型的VOC数据集测试结果
4 结束语
YOLO系列目标检测算法是运用较为广泛的单阶段目标检测算法之一。针对YOLOv5对难检目标,包括小目标和遮挡目标等检测精度不高的问题,提出了注意力机制融合的方法,将DRA模块与v5网络的主干部分进行结合,以增强模型对于一些易漏信息的捕捉能力。同时使用了SIoU函数替换原损失函数中负责计算回归参数的CIoU损失,提高了收敛速度和回归精度,改善了遮挡等复杂情况下的漏检以及小目标物体识别差的问题。实验结果表明,改进模型的平均精度超越了原YOLOv5网络。虽然模型参数量稍有增加,但改进模型的检测速度仍符合工业需求的检测速度。在后期研究中,还可以尝试对于主干网络中的卷积部分进行替换,或是替换特征加强的Neck部分,进一步提升模型对于难检目标的检测精度。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
广东教育·高中(2022年1期)2022-03-16
数学小灵通·3-4年级(2021年5期)2021-07-16
今日农业(2019年15期)2019-01-03
中华心脏与心律电子杂志(2017年2期)2017-10-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
新课程研究(2016年21期)2016-02-28
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
中国交通信息化(2015年2期)2015-06-05
