
基于用户评论情感分析的O2O平台推荐策略研究
2023-12-25 09:19:28刘齐平
湖北第二师范学院学报 2023年11期
刘齐平,杨 平
(1.湖北经济学院 信息管理学院,武汉 430205;2.湖北大学历史文化学院,武汉 430062)
随着互联网的发展,用户的“信息过载”问题日益严峻,因此帮助用户快速发现其可能感兴趣信息的个性化推荐系统已经成为互联网应用的“标配”。然而,在汹涌而来的大数据之中,能够很好反映用户需求、偏好和关切的用户评论和消息数据却未能得到主流的个性化推荐系统的充分利用。以互联网餐饮服务为例,目前已有的搜索和推荐系统主要基于价格、销量、评分、地理位置等明确的结构化数据,而忽略了用户在页面上贡献的大量充满了强烈偏好信息的非结构化评论数据,未能将其转化为精准有效的用户偏好和商户特征信息;另一方面,想要找到符合自己口味餐厅的用户经常要花上大量的时间来阅读、比较不同餐厅的其他用户评价,在这个复杂费力的过程中往往陷入“选择困难症”,导致潜在消费意愿的流失。
在大数据时代,用户生成内容越来越多,尤其是O2O平台上的用户体验评论数据非常多,作为平台如何利用好这些数据给用户做精准推荐,给商户提供餐饮改进建议,做好对用户体验、商户价值的服务工作有较大的实践意义。如果能将用户评论数据转化为比用户购买数据更精准的用户偏好、比用户评分更全面的多维度评分,就能为用户进行更加个性化的推荐,也能为平台和商户提供更加及时的产品反馈。一方面,平台可以通过用户评论动态地分析用户的偏好,为用户量身推荐最符合其需求的商户,节省用户搜寻成本,提高订单转化率;另一方面,平台可以通过对商户的评论动态地获取商户的属性评分,为商户匹配适合的目标用户群,并为产品和服务的开发和改进提供参考借鉴。
一、文献综述
对用户评论的已有情报学研究可以分为以下几类:
第一种通过对评论进行一般的统计分析研究用户需求、用户体验及其改进策略等,例如公共图书馆[1][2]、酒店[3][4]、知识直播产品[5]、虚拟学术社区[6]、共享经济平台[7]等。
第二种通过对用户评论进行情感分析构建基于用户偏好的推荐模型,例如电影[8][9]、图书[10]、手游[11]、饮食[12]、旅游景点[13]。此外,微博等[14]、视频弹幕[15]等类似于用户评论的文本也有基于情感分析的研究。
第三种通过对产品评论进行情感分析得到产品属性评分并构建基于物品属性的推荐模型,如SUV车型的汽车外观设计推荐[16]、电商产品特征词典[17]等。
第四种Turney最早提出了一种基于评论情感极性的无监督学习推荐方法[18],开了同类研究的先河。同时对用户评论和产品评论进行情感分析,通过对用户偏好和物品属性进行匹配构建联合推荐模型,如电影推荐[19]、新闻推荐[20]、电视节目推荐[21]等。王安宁和张强等[22]认为网络评论与物联网产品数据的联合分析将为商务智能带来新的生机。
本文的思路接近于上述最后一种类型,可以看成一种通过对基于标签的用户画像和产品画像进行匹配的推荐策略。用户画像(user profile)是一种根据用户的目标、行为和观点的差异,将其区分为不同类型分组(user grouping),进而构造人物原型(personas)的过程,可以简单概括为“用户信息标签化”。类似地,产品画像(product profile)也可以简单概括为“产品信息标签化”。在现有文献中,基于用户画像的个性化推荐方法出现不多,基于产品画像的就更少。在早期的推荐系统研究中,有部分学者采用了用户分组或用户建模(user modeling)方法[23]-[25]。在近期研究中,仅有Li、Deng 等[26]和Gao 等[27]通过构建用户画像或用户标签进行推荐服务。
综观已有文献,我们发现目前主流的推荐策略还是基于结构化的数据的协同过滤推荐算法,多采用通用的训练集数据检验算法的有效性,而未能充分利用网络用户主动生成的大量非结构化的真实评论文本数据;即使利用了用户评论数据,现有研究也大多没有同时针对用户偏好和物品属性进行情感分析,更没有由此构建出用户画像和产品画像并进行匹配推荐。
二、研究思路
本文通过对用户评论数据的文本挖掘,计算在不同属性维度上的用户关注权重和商户情感词评分,然后加权求和得到商户综合评分,从而给出个性化的推荐结果。以大众点评网餐饮门户为例,本文提出了一种结合了个性化分析(用户通过自己的评论显示出的个人偏好)和大众智慧(不同用户对商户的众多评论)的较为合理的推荐策略,将有效提升网络平台的服务质量和用户体验。一方面,通过对特定用户和商户的评论文本的挖掘获取用户偏好(关注权重)和商户特征(各属性的情感分析结果),综合计算得出推荐指数,并依据推荐指数排序进行推荐。另一方面,通过问卷调查收集受访者对不同商户属性的关注度及阅读评论后对商户的选择,以证实用户偏好、商户属性与用户选择之间的相关性,从而验证本文推荐策略的有效性。本文研究思路如图1所示。
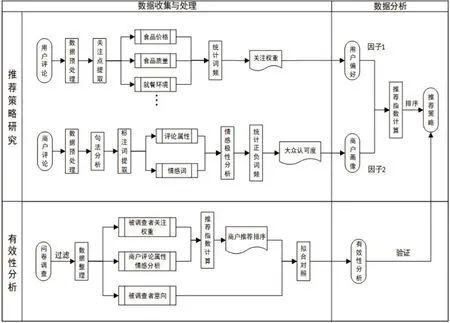
图1 研究思路流程图
三、基于情感分析的推荐模型构建
(一)评论属性库构建
评论文本涉及商品或服务的众多属性,任何商品或服务都是内容、形式和价值的结合产物。笔者运用文本挖掘工具ROST CM6的网站抓取功能对大众点评网美食领域的用户和商户的相关评论进行采集,并处理采集到的文本数据,分析总结5类评论属性的具体内涵,如表1所示。

表1 评论对象库类别表
(二)情感词提取
情感词是挖掘评述中商户属性大众认可度的依据,本文先使用自然语言处理技术和相关工具软件对文本数据做预处理,再对语料做句法关系拆解得到词料,分别给词料标注词性,最后匹配识别句子中的评论属性和其情感词,具体步骤如下:
1.数据处理与分析。首先利用文本挖掘工具ROST CM6 对采集到的文本数据进行预处理,比如筛选语句、分词、去停用词、清洗等步骤,得到预处理语料。根据语料挖掘出情感词与评价属性的句法依赖关系,主要有两种,分别是主谓句式和定中句式,如表2所示。

表2 句法依赖关系表
导入ROST CM6文本分析功能,再对待挖掘数据进行预处理,得到表2中所示的分词后词料。
2.提取标注词。本文利用中文句法分析器Stanford Parser 作为文本挖掘工具,对预处理语料做“抽丝剥茧”,识别出句子中的评价特征词。Stanford Parser 的句法分析器先将分词后的语料赋予词性标注,如表3所示。

表3 词性标注表
在表3中,主谓句式和定中句式结构的中心词都是名词,一般为评价属性,而主谓式中的谓语和定中结构中的定语一般为情感词,词性多为形容词和动词。句法分析器Stanford Parser将句子处理成树状结构,如图2所示,在句法树中,为信息抽取程序设定如下规则:

图2 句法树示意图
(1)遍历句法树中的所有叶子节点,寻找到被标注为常用名词或固有名词的节点,判断这些节点的内容是否属于评论属性。
(2)当找到评论属性相关的叶子节点时,寻找该节点的父节点下的所有兄弟节点。
(3)如果兄弟节点中有动词短语节点或表语形容词节点,提取其中的表语形容词短语或者动词短语节点下的表语形容词或动词。
在图2中,句法分析器遍历句法树中的所有叶子节点,寻找到两个标注常用名词的节点,并与评论属性库对照,判断它们(“菜品”“环境”)属于评论属性。随后找到它们的父节点下的兄弟节点,即动词短语,并提取各兄弟节点的子节点形容词,分别是“好看”和“漂亮”,与“菜品”和“环境”相对应,最后生成评论属性与情感特征的词对表。
(三)情感词极性分析
情感分析的目的是分析用户的情感倾向,情感倾向可分成正向、负向和中性。推荐策略中,中性情感倾向往往基本没有指导意义,故本文不将中性情感词做为研究参考的数据。笔者对处理后文本语料进行情感极性匹配,得到各个评论属性的正、负向情感词频数,作为推荐指数中商户画像的数字依据,具体步骤如下:
1.构建情感词典。知网提供了4个方面的情感词典,包括评价(正向、负向)、情感(正向、负向)、主张、程度级别。本文使用知网HowNet情感(正向、负向)词典。[28]
2.挖掘情感倾向程度。利用Jupyter Notebook应用程序和Python编程语言,基于情感词典对提取各个评论属性对应的正负向情感词做词频统计,部分代码如下所示:

(四)推荐指数计算
笔者研究的推荐策略主要涉及两方面信息。一方面,每个用户所表达的评论,体现出此用户选择商户时关注的主要属性。利用每个属性占所有统计词频的百分比作为推荐指数计算的权重因式Wi。另一方面,某一个商户的大量用户评论客观上体现出大众对此商户提供的商品或服务的印象,即大众对该商户各个属性的认可度。采集并统计评论属性对应的正负向情感词的数量,进而将大众智慧量化表示出商户画像。
公式(1)中,R是推荐指数的量化结果,i代表餐饮商户的某个评论属性,m是评论属性的个数,Wi指评论属性的用户关注权重(用户偏好程度),pi代表第i个评论属性包含的正向评论的数量,而ni表示第i个评论属性包含的负向评论数量。pi与ni的值差表示情感词的综合极性程度,pi与ni的和代表有效情感词总数。由公式(1)可知,当用户偏好(关注热点)与商户画像分量化计算得到的因式值均较高,即产生积极共鸣时,推荐指数较高。
四、实证研究
(一)数据采集与处理
1.样本选取。大众点评网作为国内规模较大的第三方消费评价网站,不仅用户数量多、商户覆盖率高,而且用户活跃度高、商户评论数量较多。因此,本文选择大众点评网的评论数据作为研究对象。
(1)先选取大众点评网美食领域中评价数量排名靠前且具有代表性的三家餐饮商户。DX海鲜点心酒家(简称DX酒家)的评价数量排名第一,且菜品种类丰富,兼具主食、菜品、甜点、饮品和小吃;QJ排名第二,为蛋糕西点美食商户,美食种类较为单一,代表性欠佳;XS砂锅排名第三,美食种类较为齐全;QY咖啡排名第四,仅为饮品商户,不作为研究样本,继而选取其后的XC洋风料理(简称XC料理)。
(2)再使用简单随机抽样的方法选取三位用户。从随机数表中的一位数、二位数、三位数和四位数中分别随机取出100个数字,再从400个数字中随机选出3个数字。根据选出的随机数,依次在三家商户的评论列表中查找到对应序号的评论用户,作为用户样本对象。
2.用户的评论数据采集与处理。
(1)首先通过八爪鱼数据采集器爬取三个用户对餐饮商户的评论文本。选取的三位用户中:用户“梅花鹿”发表了美食评论47篇,用户“爱酱”发表72篇,用户“寻味”发表80篇。
(2)使用文本挖掘工具ROST CM6和“Jieba”中文分词库[29]对评论文本分词。
(3)再使用文本挖掘工具ROST CM6的功能并导入大连理工大学的中文停用词表[15]对分词后的数据清洗和词频分析,导出前300位词频。
(4)最后根据评论属性库,与词频数据一一匹配,统计各用户评论中属性词的词频和占比,如表4所示,作为用户关注偏好的数字依据。

表4 用户评论的词频统计表
3.用户的评论数据分析。由表4的统计数据可知,三位用户的关注点具有一定的共性,都把“食品质量”作为较为关注的属性,而属性“交通地段”都给予了较少关注。而存在明显差异的地方有:用户“爱酱”对于属性“服务体验”给予了高度的关注,用户“寻味”给予了属性“就餐环境”较高的关注。总之,用户对于餐饮商户选择时,既有共同关注点,也有用户个性层面的兴趣偏好。
4.商户的评论数据采集与处理。
(1)在分析完个人用户的关注点后,分别对选取的三位商户的500 条近期评论文本数据进行采集和预处理。
(2)把分句、分词、清洗后的语料列表数据和情感词典导入Jupyter Notebook 程序,并将两者进行逐一匹配,记录每个评论属性匹配到的正、负向情感词,最后汇总词频数,统计结果如图3所示。

图3 情感分析示意图
5.商户的评论数据分析。从图3所反映出的信息可知,商户“DX酒家”的属性“服务体验”负向情感词频数远多于正向情感词,翻看文本数据发现,主要原因是商户“排队时间长,上菜慢,催上菜回应不及时”等。商户“XC料理”的属性“食品价格”的负向情感词频数稍多于正向词频数。分析数据发现,主要原因是“同类型菜品,价格比其他商家稍贵”。除这两点外,其余均为正向词多于负向词,其中的差异则为正向词频数占总情感词频数的比例大小,代表商户画像里大众认可程度的高低。
继续观察图3发现,商户“DX酒家”的“食品价格”属性在三家商户中的大众认可度最高。调查发现,三家商户中,商户“DX酒家”的人均消费最低,与实际情况相符。而其5个属性中,“交通地段”的正向词占比最大,可能与“位于武汉八号线地铁附近”和在“汉街步行街里,离杜莎夫人蜡像馆等景点距离近”等因素有关。商户“XS砂锅”的属性“服务体验”在其所有属性的正向情感词占比中最高,翻阅评论可知主要原因有“服务员反应迅速,中途会帮忙加热汤”等,而属性“交通地段”在三家商户里情感正向词占比最低,翻阅评论发现“附近停车位真的是很难找”等原因。商户“XC料理”的属性“就餐环境”在三家商户中的大众认可度最高,翻阅相关评论发现与“居酒屋装修,日式风格,很舒服”等因素有关。
(二)推荐指数计算
将“梅花鹿”等3位用户的关注偏好量化值和“DX酒家”等3家商户评论中的大众认可度量化值带入上文中的公式(1)),计算求得每个商户对应每个用户的推荐指标,如表5所示。
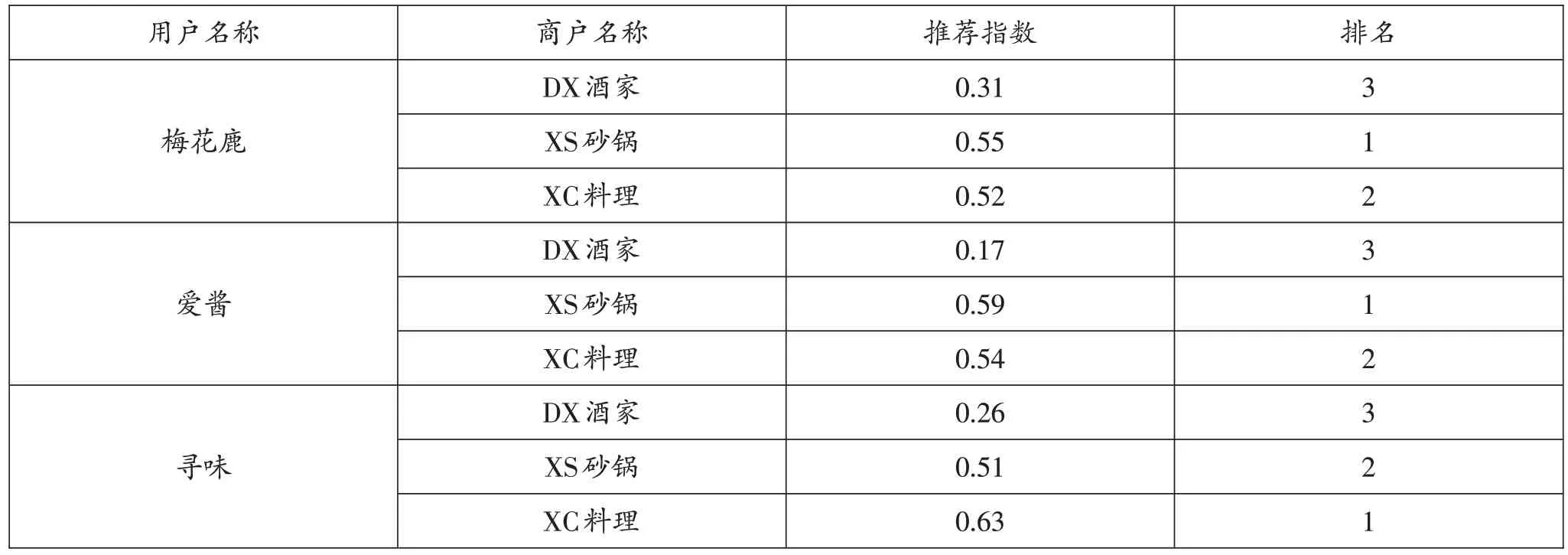
表5 用户-商户推荐指数计算表
由表5可知,商户“DX酒家”对三位用户的推荐指数均为垫底。回顾三位用户的关注共性:食品质量,而“DX酒家”的评论中此属性的计算结果排第三。故在推荐指数计算中,三位用户都较高程度关注的属性,却得到最小的计算收益。
此外需要指出的是,全部计算结果中,商户“XC料理”对应用户“寻味”的推荐指数最高。观察数据发现,虽然其评论里的食品价格情感值为-0.065,但用户“寻味”对该属性的关注权重仅有0.045,即计算过程中,乘式运算获得了最小损失。此用户在属性“食品质量”“就餐环境”“服务体验”上的关注权重较为均匀,均在0.3附近,同时商户“XC料理”在这三个属性上的情感分析值也均在0.5-0.8之间,故这三个共同较高的权重都获得了较大的计算收益。
(三)推荐策略分析
本文研究的推荐策略有两个主要影响因素,一是公式(1)中的关注权重Wi,它由用户评论中的属性名词的词频比重决定;二是公式(1)中的第二个因子,它是商户评论中属性词对应的正、负情感词频数按照一定规则计算出的结果。此因式会产生两种情感共鸣类型,如果因式值为正数,则为积极情感共鸣,否则为消极情感共鸣。
关注权重和情感词计算两者共同影响推荐指数,关注权重来自用户画像,情感词分析来源于商户画像,其中任何一方的高低并不能直接说明推荐指数的结果。可见,推荐策略是两因素综合考虑的有机结合。
(四)推荐策略有效性分析
1.问卷调查。为了评测推荐策略的有效性,笔者设计了一份调查问卷,并通过网络途径发布,收集受访者的关注点与网络平台中商户评论画像之间的关系数据。调查的内容有两方面:一方面,了解受访者选择餐饮商户时对商户各个属性的关注程度,即发掘受访者的偏好;另一方面,问卷摘录数家大众点评网美食领域的三家商户的数个文本评论,供受访者阅读,阅读评论后根据自身感受勾选心仪商户。回收问卷101份,筛选出有效问卷,过滤掉无效问卷。在检查收集到的问卷时,发现有数个问卷的完成所用的时间仅有几秒,而此次问卷涉及文段阅读,有理由怀疑这部分受访者没有完整阅读评论文本信息,故作无效问卷处理。在问卷数据的统计过程中,笔者发现有受访者对于所有属性的关注程度的填选均为“不关注”,既不符合实际情况,也不满足研究需要,故认定为无效问卷。经筛选和过滤,过滤掉12份无效问卷,保留89份问卷。
具体过程如下:首先,统计每个受访者对五个商户属性的关注分值,并计算出每个受访者对应的每个关注点的权重,即某个关注分值除以总分值。其次根据问卷上商户的文本评论数据挖掘出商户画像,即商户属性的情感分析结果。最后带入推荐指数计算公式中,分别计算出商户-受访者对应的推荐指数,摘录部分计算结果如表6所示。表6中节选的部分数据显示商户B的推荐价值最大,结合商户B的画像特点和受访者的关注情况可发现:受访者对“食品价格”和“食品质量”的关注普遍较高,同时对交通地段的关注较低;商户A和商户C在价格和质量两个属性上有所欠缺,情感值计算为负值;而商户B这两项属性的计算取值均为正数,“交通地段”的情感值为负。参考本文推荐算法实验结果,问卷调查与其不谋而合。前后两次分析的共同点是用户较为关注的,商户属性同时被大众认可的程度较明确,此时推荐策略呈现热反应。

表6 问卷数据整理表(摘录)
参考此结果可缩减推荐策略的处理流程,提高推荐效率。推荐模型在计算出用户偏好和商户画像的量化结果时,可优先比对用户关注程度高的属性,若此属性在评论信息里的情感倾向明确,即可推荐。
2.推荐策略有效性验证。记录受访者的商户选择,与推荐指数排名对照分析出推荐策略的有效性。结果显示,在89位有效受访者中实际选择了推荐指数排名第1的商户的有53位,占总数的59.6%,实际选择了推荐指数排名第2和第3的用户分别占总数的24.7%和15.7%。也就是说,有59.6%的受访者的意向和首位推荐吻合,85.0%的受访者选择和推荐较高程度地达成一致。因此,推荐策略具有较强的有效性。虽然有问卷调查结果验证了本文推荐算法的有效性,但由于受访者在回答问卷时需要认真阅读一定量的评论文本,一些认知规律会影响受访者的阅读行为,所以受访者对商户的最终选择可能会受到这一过程的扭曲:
(1)阅读过程中的信息加工,受刺激物的“惊奇值”[30]影响。在问卷上的文本评论中,出现了“颜值惊艳”“小姐姐服务员”等网络热点词汇,这些词汇对不同年龄段人群的刺激程度不同,影响受访者的理性判断。比如,某位受访者对服务体验的关注程度不高,而“小姐姐服务员”的“惊奇值”产生较高影响,则会导致此用户对本不关注的属性产生强烈兴趣,从而选择与推荐策略结果背道而驰的商户。
(2)阅读过程中的信息加工,受阅读者的眼动凝视时间[31]的影响。问卷的商户评论存在先后阅读顺序,当一个受访者阅读完靠前商户评论,已经产生心仪感时,会缩短靠后商户评论的凝视时间,造成受访者对靠后信息获取残缺。比如某位受访者非常注重食品质量属性,阅读完靠前商户的评论,已经产生了选择的想法,此时靠后商户的评论中虽然有高质量食品的相关信息,但可能因为该受访者无意识缩短了后文的眼动凝视时间,关键信息被忽略。
(3)阅读过程中的信息加工,受词频[32]的影响。高词频和低词频在默读中产生一种维持稳定的频率效应。即读者在低频度的词用时比高频度的词更长,从而影响阅读者的眼球运动。问卷阅读文段中,反复出现“价格”“环境”“服务”这类标准化的词汇,受访者更容易跳过这类高频且常规的词,注视词频较低且新颖的词,导致受访者产生对文本理解的主观偏差。
综上所述,受访者以及网络用户在阅读评论文本时,不一定完整、准确、客观地获取了文本中的信息,因此问卷调查所得到结果的局限性是需要注意的。
五、结语
本文充分利用了传统推荐策略未能利用的具有丰富偏好信息的海量用户评论数据,通过挖掘用户关注与偏好和商户画像之间的拟合关系,构建了基于多维度用户偏好和商户特征模型的个性化推荐策略。本文通过网络爬虫技术采集了大众点评网上特定用户和商户的评论数据,运用文本挖掘方法分析用户偏好和商户特征,得出用户关注权重和商户属性情感分析结果,再将二者进行加权求和得到针对用户个人的个性化推荐指数,最后依据推荐指数的排序进行推荐。本文提出的推荐策略是一种结合了个性化分析(用户通过自己的评论显示个人偏好)和大众智慧(不同用户对商户的众多评论)的较为合理的推荐策略,能有效提升推荐质量和用户体验。本文用问卷调查数据分析了用户偏好、商户特征与用户实际选择之间的关联,验证了推荐策略的有效性,结果显示有85.0%的受访者选择和推荐指数前三位商户达成一致。
本文的理论价值在于:主流的协同过滤推荐算法只是在“用户-物品”选择矩阵的数据中根据用户或物品的相似性做出唯象的预测,而本文提出的推荐策略没有回避用户决策过程的核心问题——用户偏好和物品属性,并通过对用户评论的文本分析将用户偏好和物品属性数据挖掘出来,借助线性的效用函数模拟了用户的决策行为,得到了较好的推荐结果。本文的推荐策略侧重于决策过程的因果关系,与只考虑数据的相关关系的主流推荐算法可以形成方法论上的互补,这还有待于未来进一步的研究。
本文的实践意义在于:(1)充分利用了具有丰富偏好信息的海量用户评论数据,将其转化为比用户购买和评分等更加精细和全面的用户偏好、商户特征数据,为盘活现有海量数据、提升数据价值提供了新的思路;(2)通过构建和匹配用户画像和商户画像,为用户量身推荐最符合其需求的商户,节省搜寻成本,提高订单转化率;(3)平台可以通过分析用户发表的评论和商户收到的评论,动态地获取用户偏好和商户属性评分,从而为商户匹配适合的目标用户群,并为产品和服务的开发和改进提供参考借鉴。
本文的方法基于对用户评论的文本分析,因此需要用户发表一定数量的评论,才能对用户的偏好做出分析,也就是说对“冷启动”不够友好;但我们可以通过在新用户注册时引导用户对各属性维度进行偏好排序来为用户偏好提供一个初始值。由于本文的文本分析仅限情感词正负极性分析计算,而未能考虑情感色彩强度差异(比如“好吃”“美味”“绝世佳肴”同属于正向情感词,但情感色彩依次增强),因此在未来的研究中,可在词频的基础上,增加强度赋值,提高推荐的准确度。此外,未来还可更多关注用户的地域化习惯和口味习惯等群体特征和评论的非文字内容(如标点符号、表情符号、特殊符号)等数据的挖掘,拓展用户画像和商户画像的描绘方法。
猜你喜欢
小康(2022年28期)2022-10-21 02:35:38
小康(2022年19期)2022-07-09 10:41:00
小康(2022年16期)2022-06-13 05:05:44
小哥白尼(神奇星球)(2022年3期)2022-06-06 07:39:34
时代邮刊(2021年8期)2021-07-21 07:52:36
新世纪智能(高一语文)(2020年9期)2021-01-04 00:42:42
非公有制企业党建(2020年10期)2020-10-27 06:30:14
金融周刊(2018年13期)2018-12-26 09:09:38
四川党的建设(2018年21期)2018-12-05 09:09:14
延河(下半月)(2014年1期)2014-02-28 21:05:10
