
面向微服务架构的煤矿生产监控数据采集系统设计*
2023-12-25 09:00尚伟栋苌延辉张晓霞
电子技术应用 2023年12期
王 磊,黄 晴,尚伟栋,苌延辉,张晓霞
(1.山西天地王坡煤业有限公司,山西 晋城 048016;2.煤炭科学研究总院有限公司矿山大数据研究院,北京 100000;3.天地科技股份有限公司,北京 100000)
0 引言
随着煤矿智能化建设的推进,煤炭行业不断加大“两化”融合的投入,基于传统架构的煤矿生产系统极大地提高了煤矿信息化能力[1-2],但数据采集仍处于单系统运行模式,业务与模块的耦合度仍相对较低。为了解决此类问题,国家提出采用工业互联网平台作为矿山赋能的智能化基础设施,通过基于工业互联网平台的微服务运行方式解决矿井生产系统单系统数据采集运行可靠性差、各业务子系统烟囱式孤岛运行等问题,为推动煤矿“统一标准、互联互通、业务重构、系统优化”提供解决方案[3-5],提高煤矿智能化生产监控水平,以新一代信息化手段实现煤矿“无人则安”的安全生产发展理念。
数据采集问题是推动煤炭行业智能化的关键环节,众多学者和企业对此开展了研究与实践。贺耀宜[6]等提出采用OID 编码技术实现煤矿设备的对象标志方案,实现设备统一数据编码;采用主备方式采集设备数据,主链路正常时,备链路仅保持连接而不传数据,同时对路由协议进行优化,实现路由自发现和故障自恢复,从而保证链路的稳定可靠。孟光伟[7]提出了数据采集平台提供统一的SDK,让应用通过SDK 编码获取采集数据进行可视化。李国民等[8]提出将协议封装为驱动动态链接库(Dynamic Link Library,DLL),通过采用单体进程开辟多线程加载适配协议驱动的方式实现各业务系统的数据采集。杜毅博等[9]提出自己的设备编码规则,便于后期处理过程中的数据关联分析;提出应用基于面向服务架构(SOA),调用Restful 和RPC 协议,研发定制化数据报表系统实现应用界面与业务逻辑的数据快速展示。
然而,随着智能化的推进,矿山对数据采集的数量和质量要求大幅度提高。目前,数据采集架构在煤矿信息化发展过程中逐渐暴露出一定的局限性,主要表现如下:
(1)数据采集系统数据管理编码机制,虽然对设备按照统一规则进行的数字编码,数据编码在不同的工程中编码会变化,语义不统一带来了解析困难,应用通过编码级联的方式关联设备和测点,造成数据冗余;且对于设备测点采用顺序排序的方式编码,造成不同设备对象测点编码不统一,对于数据可视化需要语义转换和测点关联不能复制等问题。
(2)数据采集基于单体架构模式,采集多个通道数据通过单进程实现,如果局部通道出问题,整个采集进程受到影响,其他采集通道不能正常采集数据;不能容器化部署,难以以微服务方式运行为其他应用提供数据服务。
(3)数据可视化工具灵活性与效率不足,主流方式是采用面向服务的软件架构(SOA),微服务化效果不好,系统整体可靠性低下;实现采用定制化表格对数据进行监视,不具备灵活性;而且,通过无状态的Restful 和RPC协议请求数据,如果需要实时刷新数据,界面需要利用定时器周期向后台请求数据,效率低下。
(4)数据采集进程采用主备方式,主备切换过程中需要周期测试主备心跳,导致数据丢失,难以做到智能化切换,数据采集系统的整体可靠性降低。
针对目前数据采集的不足,本文提出一种面向微服务架构煤矿生产系统数据采集的设计与应用,以实现煤矿生产监控数据的安全高效采集。
1 数据采集系统架构设计
微服务架构是基于单一功能组件的模块化组合方式,能够实现松耦合的应用开发。一个微服务是一个能够独立运行的小型应用,通过API 接口实现微服务间的通信,将多个不同功能、相互隔离的微服务应用按需组合,构成完整的综合应用系统[10-13]。随着大数据、云计算、分布式组件和互联网技术的发展,采用微服务架构已成为煤矿生产系统数据采集的趋势,受到煤矿系统集成商和用户的重视[14-17]。但是,由于煤矿开采系统的复杂性,如何将庞大的数据采集模块拆分成独立的微服务应用成为煤矿生产系统数据采集亟需解决的难题。
数据采集系统整体架构按照工业互联网体系要求,将矿井生产系统数据采集模块拆分为小型应用,部署在PaaS(Platform as a Service)平台上,以微服务的方式为其他应用提供服务。核心思想是每个通道采用独立的微服务的方式进行数据的接入[18-20],综采、综掘、主运输、供电、排水等系统的数据采集以微服务方式为用户提供服务。
面向微服务架构监控平台的总体架构如图1 所示。底层为数据采集层,各通道部署到独立容器中,利用PaaS 平台的docker 化能力,采用工业监控协议,以微服务的方式把煤矿设备数据采集到实时数据库中,作为监控平台的数据源,实现实时库存储的标准化。中间层为数据服务层,包含数据统一登录、权限管理、告警、服务监控、数据共享等模块,为数据可视化提供后台服务,向下与数据采集层相连,接入不同工业协议的设备数据,向上以统一接口的方式支撑矿井级生产监控系统数据可视化的开发。顶层是数据可视化层,利用数据服务共享模块提供的数据服务接口,按照统一的数据格式,使用低代码可视化组件通过拖拉拽方式,构建矿井生产控制系统专项数据可视化应用,为用户实现对矿井数据的监视。
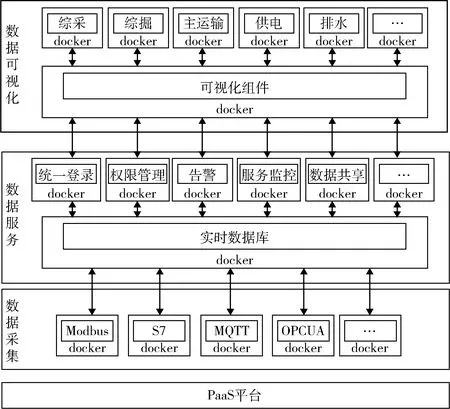
图1 煤矿生产监控数据采集系统总体架构
2 微服务架构数据采集关键技术
2.1 数据统一标准化
工业互联网平台的技术体系能够解决煤矿智能化建设过程中的统一数据标准问题[21]。煤矿统一数据标准主要采用对象分类方法,采用json 数据格式表示设备对象,设备属性采用key-value 方式访问,其中设备属性的key 是固定的,这样做的好处是统一了语义,方便不用的应用交互数据。描述主要分为两部分:(1)设备描述:主要包括子系统类型、设备类型、位置信息、设备关联关系、实时数据状态等方面的属性[22]。(2)设备测点:定义id,名称、单位类型、数据类型、数据长度,读写标志等,其中测点id 采用是固定的,这样做的好处是固定了测点id,实现项目工程实施从一个工程到另外一个工程的复制,不需要修改属性id,减少工程开发工作量。
设备对象json 描述如下:

其中,uuid 是通过雪花算法自动生成,保证矿井设备的唯一性,避免设备识别错误的问题,points 以数组的方式表示。
2.2 单通道采集微服务化处理
单体架构构建所有的通信通道,一个通道对应一种协议[23-25]。该模式可伸缩性差,如果在生产运行过程新增通道或协议,需要重启程序,影响正常的生产数据采集。此外,单体运行系统错误隔离性差,由于煤矿接入设备数量较多,需要多通道接入煤矿设备数据,如果某个通道出现问题,其他的数据采集通道也会受影响。为了解决以上难题,本文采用基于微服务的方式设计数据采集模块,即单通道采用独立的微服务方式为应用提供服务。
数据采集组单通道微服务化如图2 所示,包括配置信息前后端同步、配置信息存储、通道启动、标准模型映射和统一标准服务。

图2 数据采集模块流程图
(1) 配置信息前后端同步:现有数据采集模块主要采用客户端/服务端架构,虽然服务端可以使用 Docker容器化部署,但客户端无法容器化部署,也不能以微服务方式为用户提供服务。因此,采用前后端分离技术,基于VUE 框架开发前端,利用Axios 组件和后台通信,webpackage 打包独立部署到Nginx docker 容器中;后端基于SpringBoot 开发,提供Restful API 和前端提供数据访问服务,后端可以独立部署在docker 容器中。
(2) 配置信息存储:WEB 配置工具后台根据前端用户的配置信息,按照工程、通道、协议、点的组织关系存储到工程信息库中,工程信息库的种类包括关系型数据库(MySQL)和非关系型数据库(Minio),为了满足不同的数据库存储接口,本架构采用对应的互联网数据库访问中间件,并封装统一的存储接口。信息的存储封装SaveInfo 接口,接收参数为信息类型,底层调用Mybatis组件把关系型数据存到MySQL 中,调用Minio 访问组件把非关系型数据存到Minio 中。
(3) 通道启动:通道启动采用微服务方式,一个通道启动一个微服务,需要保证每个微服务启动通道的唯一性,同时保证采集通道服务的完整性。通道启动分为两步:一是读取配置,二是信息同步。读取配置是微服务读取通道信息表,获取唯一标识通道名称作为微服务启动的参数。信息同步过程为:微服务利用输入的通道名称启动,启动之前,首先查询ZooKeeper 服务注册中心已经启动的通道信息,接着从通道信息表过滤已经启动的通道,然后选择剩下未启动的通道进行启动,启动成功后向ZooKeeper 服务注册中心注册启动信息。如果通道运行过程中出现异常,PaaS 平台自动重新启动该微服务,启动过程按照信息同步步骤执行。
(4) 标准模型映射:由于煤矿设备种类多,其通信协议不统一,数据采集存在通信协议的兼容性和一致性差等问题,需要向下利用不同协议采集数据,向上对应用提供统一的数据标准。为了保证上层应用数据的统一性,采用基于面向对象的MQTT 协议统一进行数据采集。通过对象方式打通全矿井纵向和横向各系统层级间的数据流,达到各个子系统间“统一标准”的目的,增强数据资源共享能力。协议库用C 语言实现,JSON 模型封装采用Java 语言实现,首先通过Java JNA 接口获取协议库数据,然后采用Gson 组件把数据按照key 映射成设备对象,实现标准模型映射。
(5) 标准服务:通过统一的接口,以对象的方式为其他应用提供数据服务。这种方式有利于其他应用的开发,能够提高应用的开发效率和应用系统的集成能力。提供一个Restful API 接口,参数为设备类型和设备id,根据此,通过Redis 访问接口遍历Redis key 定位到设备数据,从Redis 取出数据返回,为应用提供数据访问服务。
2.3 数据服务状态监控
为了实现对数据服务的监控,采用监控服务的方式对数据服务进行监视。传统上数据服务单体运行的方式监控复杂度较低,监控服务采用轮询监控单体系统的运行情况就可以满足数据服务状态监控要求。本文数据采集采用微服务方式运行,每个微服务拥有独立的运行环境,导致数据服务数量显著增加,各数据服务的发布次数增加,对监控服务的要求也大大提高。采用轮询的前提条件是监控服务明确数据服务的信息,监视服务采用轮询监视方式和数据服务通信,实现数据服务监视,由于微服务启动的数量是动态变化的,无法采用轮询的方式。因此需要采用数据服务向监控服务周期自动传输的方式,实现数据服务监控功能。
服务状态监控设计如图3 所示,基于SpringBoot Actuator 组件,分别开发服务端(StateServer)和客户端(StateClient),其中服务端提供Restful API 接口供应用进行可视化,客户端嵌入到微服务应用中,封装health endpoint 获取应用的健康状态;封装heapdump endpoint获取JVM 虚拟机的使用情况,包括堆内存使用率、线程数量、垃圾回收数量和时间;封装auditevent endpoint 获取认证信息,包括用户名、登录时间等。
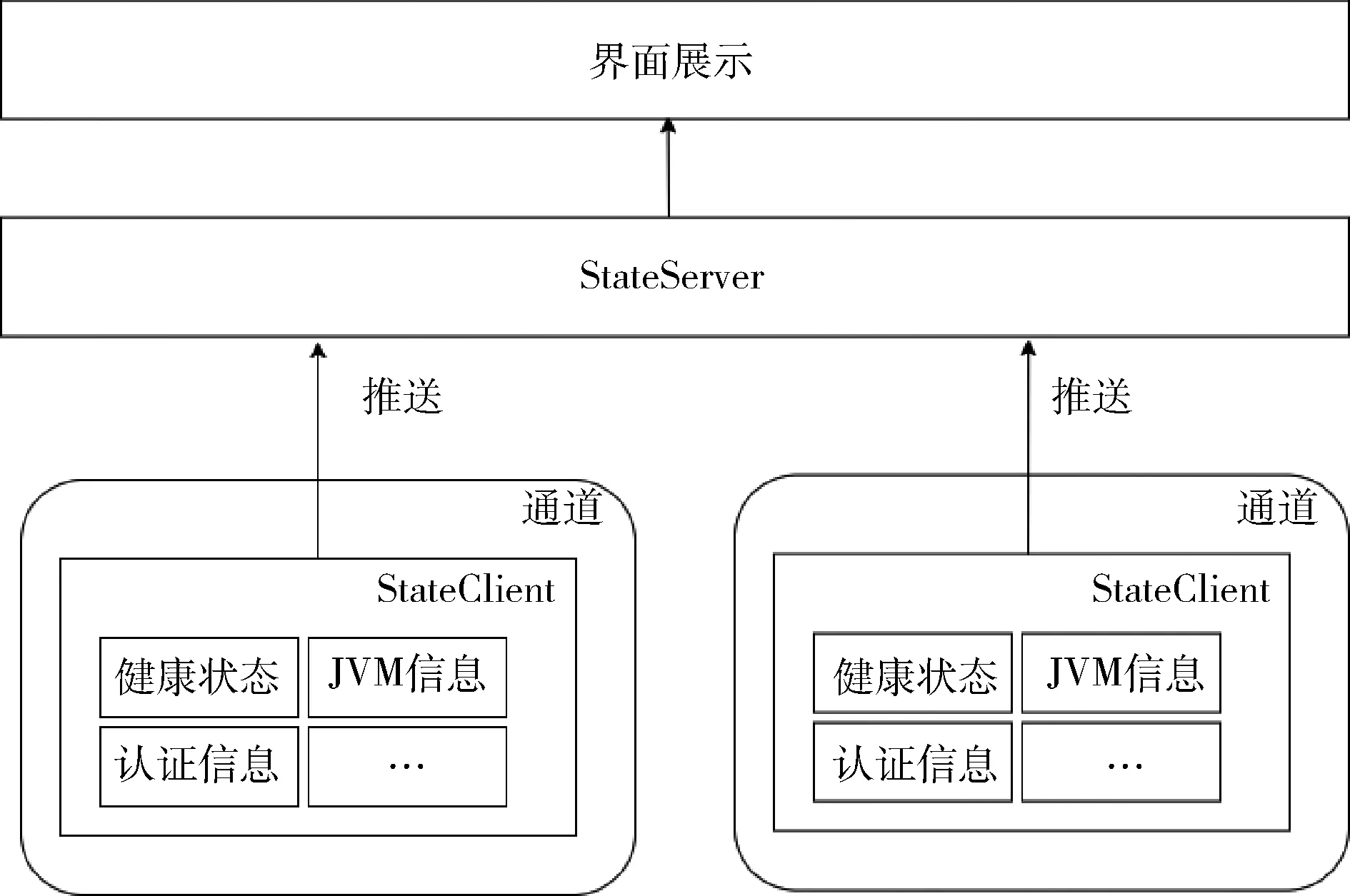
图3 服务状态监控设计
2.4 数据可视化组件
数据采集系统可视化采用WEB 报表组件,表现形式包括表格、曲线、饼图和柱状图,实现数据实时展示、通道状态监视、数据统计等功能。
目前主流厂家已实现WEB 化报表组件,但他们采用前后端一体化紧耦合架构,难以实现微服务化部署,只要一个程序出故障,会导致整个系统崩溃,错误隔离差,整体运行可靠性低。本文采用前后端分离松耦合架构,前端可分拆成一个微服务,后端可拆分成多个微服务,当某个微服务出故障,不会影响其他微服务的运行,提高了系统运行可靠性。
报表组件设计如图4 所示,包括数据源层、服务层和报表开发层。
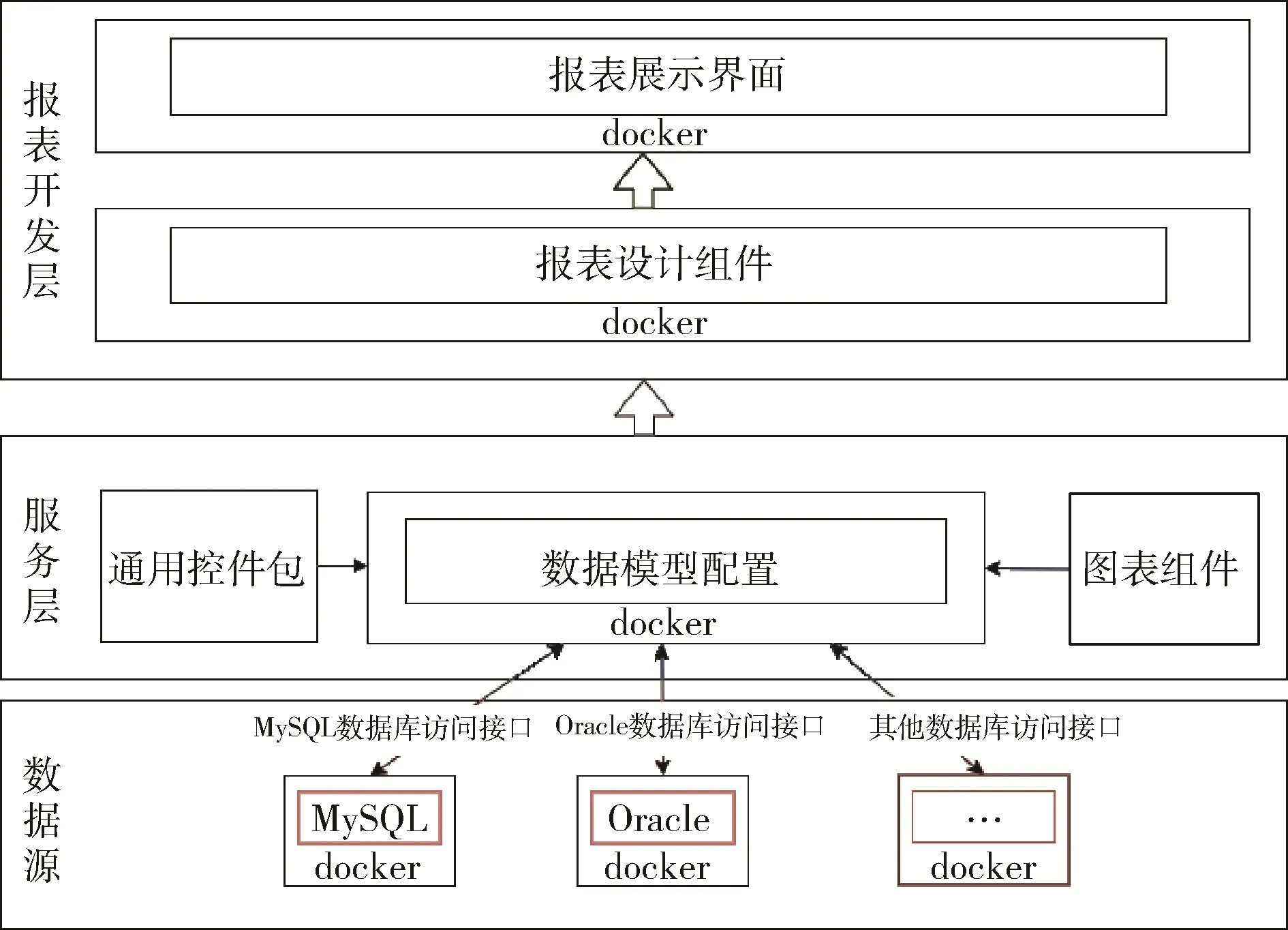
图4 报表组件设计
(1) 数据源层:为了满足数据源的多样化需求,数据源的数据库类型包括关系型数据库(如:MySQL,Oracle)和非关系数据库(如Redis)。在数据源层能够嵌入不同的数据库访问接口,以供数据源配置组件根据不同的数据库类型智能匹配对应的数据库接口。采用SpringBoot 框架,通过动态注册和切换DataSource bean来实现按照配置信息动态匹配数据源的功能,动态数据源类继承AbstractRoutingDataSource,重写determineCurrentLookupKey 函数,采用mybatis-plus 屏蔽不同数据库访问的差异。
(2) 服务层:数据模型配置根据用户利用通用控件包融合ECharts 图表组件,提供图表交互接口,设置图表的样式、形状,数据列等,为报表设计组件提供模板服务。利用VUE 父子组件数据交换框架,设计ReadInfo 接口读取Echarts 属性,设计WriteInfo 接口从实时库读取数据回写Echarts 组件进行显示。
(3) 报表开发层:报表设计器调用数据库模型提供的图表组件,按照项目的实际需求,通过托拉拽设计表格样式,调用图表插入到表格中,通过表格和图表关联数据,为报表展示界面展示提供数据模型服务。报表展示界面根据数据模型进行数据刷新和图表渲染。利用VUE 框架的鼠标mousedown 和mouseup 事件实现组件的拖拽功能,利用组件封装的接口(ReadInfo 和WriteInfo)实现读写数据功能。
(4) 数据的实时刷新:现阶段煤矿基于WEB 的数据监视主要采用HTTP 协议,前端设定定时器采用HTTP协议向后台请求数据来进行刷新。由于HTTP 每次请求都需执行三次握手流程,导致通信效率低下,为了解决此问题,本文采用WebSocket 通信协议,一旦界面和后台建立了连接,后台可以自动周期性往界面推送数据,避免了HTTP 协议每次访问都需要三次握手流程导致效率低下的缺点。利用Netty 框架,通信类继承SimpleChannelInboundHandler 类,重写channelRead0 接口获取推送周期,然后按照周期设置定时器往调用者推送数据。两种方式实时刷新对比结果如表1 所示:

表1 实时数据刷新结果对比
2.5 微服务实现技术
本文采用Docker 容器实现微服务,将数据采集规约、数据库、数据服务状态监控和可视化组件构建标准化Docker 容器,组件彼此通过提供的接口进行通信,从而实现微服务。Docker 容器的自动化部署、扩展和管理,主流的方式是通过Kubernetes 实现,本文基于Kubernetes 开发适用数据采集的管理组件。
管理组件通过调用Kubernetes 提供的API 接口来管理Docker 容器,提供Docker 容器的创建、删除、启动、迁移、扩容与缩减、调度、网关代理设置、集群管理等功能,保证Docker 容器的高可靠运行,实现为用户提供远程协同控制Docker 的目的。
数据采集微服务设计如图5 所示,命令解析器利用MySQLsql 接口读取配置库信息,根据通道、报表组件需要创建的pod 的数量,利用Sendcmd 接口向主节点API sServer 发出指令,API Sserver 响应命令,通过一系列认证授权,把通道、报表等pod 数据(包括每个pod 的docker 数据)存储到 etcd,封装StartResouce 接口创建部署资源并初始化;controller-manager 通过 List-watch 接口,监测发现新的部署资源,将该资源加入到内部工作队列,发现该资源没有关联的 pod 和副本,启用 ReplicasetCreate 接口创建副本资源;创建完成后,将副本资源更新存储到 etcd;scheduler 通过 List-watch 接口,监测发现新的 pod,经过主机过滤、主机打分规则,将 pod 绑定 (binding) 到合适的主机;将绑定结果存储到 etcd。工作节点kubelet 每隔 20 s (可以自定义)调用IntervalCall接口向 API Sserver 通过节点名称获取自身节点上所要运行的 pod 清单,通过与自己的内部缓存进行比较,新增加 pod;kubelet 调用 Docker API 创建并启动 pod;kube-proxy 为新创建的pod 注册动态DNS 到缓存中;为pod 的服务添加负载均衡规则,用于服务发现和负载均衡。controller-manager 通过 control loop(控制循环)将当前pod 状态与用户所期望的状态做对比,如果当前状态与用户期望状态不同,则controller 会将pod 修改为期望状态。

图5 数据采集微服务设计
3 应用案例
通过采用微服务架构设计煤矿生产监控系统数据采集,符合煤矿智能化建设和信息化基础设施安装部署工业互联网平台底座的要求。目前,该平台已经在山西天地王坡煤业有限公司进行试运行。将该平台部署在王坡煤矿PaaS 平台上,其中数据采集组件启动了10 个微服务,同时通过可视化组件开发了10 个子系统数据监视应用,满足了综采、综掘、主运输、排水、通风、供电、智能污水处理、智能压风、铁路智能装车和汽车智能装运系统数据的智能监控。数据采集系统展示效果如图6~图8 所示。

图6 综采工作面采集通道微服务部署界面

图7 实时数据展示界面

图8 数据监控展示界面
应用结果表明,该系统的部署操作简便,通过“一键部署”可快速部署到王坡煤矿PaaS 平台中,减少技术人员的项目部署工作量;在运行期间,微服务应用的自愈和切换、分布式运行、运行监控日志等都由PaaS 平台统一管理,减少了运维人员的工作量。平台应用后,监控系统运维人员数量由原来的4 人减至2 人,节省了王坡煤矿用户的人力成本,符合智能矿山的“少人、无人”趋势。
4 结论
本文以工业互联网平台为底座,以微服务架构理念为指导,设计了一套全新的数据采集、监控系统。该系统通过对综采、综掘、主运输、排水、通风、供电系统设备数据进行采集,当某个数据采集服务出现异常时,不会影响其他数据采集服务的正常运行,从而提高了监控系统的可靠性。此外,该系统还实现了矿井生产监控系统子系统的数据监视,满足了用户对数据可视化的要求。
虽然该平台对煤矿生产监控系统数据采集进行了微服务化初步尝试,但仍处于初级应用阶段。为了能够更好地支撑煤矿安全高效生产,需要进一步应用云计算技术,并利用分布式技术在微服务的基础上不断改进煤矿生产监控系统数据采集架构,以实现矿井级海量数据采集、监控功能,此外,微服务应用的部署和运维对运维人员的要求更高,为更方便监控微服务应用的运行状态,需要开发易用性更好的工具供运维人员使用。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
房地产导刊(2022年10期)2022-10-18
能源工程(2022年2期)2022-05-23
汽车工程(2021年12期)2021-03-08
重型机械(2020年2期)2020-07-24
装备制造技术(2019年12期)2019-12-25
电信科学(2017年6期)2017-07-01
中国商论(2016年34期)2017-01-15
电子科技大学学报(2016年2期)2016-08-31
太阳能(2015年11期)2015-04-10
