
基于国产申威众核架构的二维材料分子动力学模拟算法优化*
2023-12-25 09:00段晓辉刘卫国郭佳旭万吴兵杨广文
电子技术应用 2023年12期
高 萍,段晓辉,刘卫国,郭佳旭,柳 嘉,万吴兵,甘 霖,杨广文
(1.清华大学 计算机科学与技术系,北京 100084;2.国家超级计算无锡中心,江苏 无锡 214072;3.山东大学 软件学院,山东 济南 250101;4.吉林大学 计算机科学与技术学院,吉林 长春 130012)
0 引言
分子动力学(Molecular Dynamics,MD)模拟是一种计算机模拟技术,它基于经典的牛顿力学原理,计算系统中粒子的受力、速度和坐标,从而得到粒子在运动过程中的详细信息,进而获得系统演化的微观细节和系统宏观量。作为原子尺度的模拟技术,MD 是一种探索微观世界的有力工具,广泛地应用于物理、化学、生物和材料科学等领域。
近年来,二维材料的研究呈现指数增长,成为材料科学领域中的研究热点。安德烈·海姆因分离出备受关注的石墨烯而获得2010 年的诺贝尔物理奖。他在2019年的中国科幻大会论坛上曾说,二维材料将成为未来人类文明的代表性材料。石墨是三维的,而二维的石墨烯只有一层原子。当维度降低后,材料的特性和功能会发生变化,因此,揭示其物理和化学性质是二维材料的重要研究内容之一。
然而,对于二维材料的研究,传统的实验方法无法获得单个原子和分子的动态信息,而MD 模拟通过全原子力场计算能够突破这一局限。目前,国内外的研究者们已经开发了很多MD 软件包,如AMBER[1]、GROMACS[2]、LAMMPS[3]、NAMD[4]等。其中,LAMMPS是材料科学领域最流行的开源MD 软件之一。它包含多种势函数,支持不同种类材料体系的模拟,如用于模拟二维材料层间作用力的Kolmogorov-Crespi(KC)[5]力场、Inter-Layer Potential(ILP)[6-8]力场等。
当前,我们正在迈向百亿亿次超级计算时代,越来越多超级计算机的处理器采用异构众核设计,如国产的神威·太湖之光[9]和新一代神威超级计算机[10]。在众多的应用中,MD 模拟是超级计算机上的主要数值模拟方法之一,消耗了大量的计算资源。虽然超级计算机具有强大的计算能力,但由于分子动力学软件的算法设计存在缺陷,无法充分发挥处理器的性能,导致计算效率偏低,难以满足科研工作中的模拟需求。
近年来,为了提高MD 模拟在国产超算上的计算效率,科研人员在异构众核超级计算机上进行了一系列尝试。在神威·太湖之光上,Dong 等人[11]对Lennard-Jones(L-J)力场进行优化,利用双缓冲技术实现DMA 访存和受力计算的重叠;Duan 等人提出软件Cache 方案用于L-J 力场中的离散访存问题[12],提出混合内存更新策略用于三体作用力Tersoff 力场的优化[12];Gao 等人优化了反应力场ReaxFF,先提出隔离计算和更新策略[13],又从数据局部性角度提出了行加锁Cache 策略解决写冲突问题[14]。除了LAMMPS,科研人员也对AMBER[15]、GROMACS[16]、NAMD[17]等MD 软件开展了移植和性能优化工作。然而,已有工作中,并未有针对层间力场KC 的性能优化工作。
1 新一代神威超级计算机
新一代神威超级计算机[10]继承了神威·太湖之光[9]的体系结构设计思想,专门为大规模线程和数据并行而设计。它的每个计算节点搭载的是最新的高性能申威处理器(SW39000),结构如图1 所示。
与申威处理器SW26010 类似,每个SW39000 处理器包含6 个核组(Core Group,CG),每个CG 包含1 个管理处理单元(通常称为主核)和64 个计算处理单元(通常称为从核),以及主核和从核可以共享的16 GB DDR4主存空间。
主核和从核均采用我国自主研发的申威64 指令集。主核拥有32 KB 的L1 指令缓存、32 KB 的L1 数据高速缓存和512 KB 的L2 高速缓存。从核有32 KB 的L1 指令缓存和256 KB 的本地数据存储(Local Data Memory,LDM)空间。其中,LDM 的部分空间可以配置成由硬件支持的自动Cache,这一特性提升了内存访问性能,是SW39000 处理器相对于SW26010 的改进设计。主存和LDM 之间可以通过直接内存访问(Direct Memory Access,DMA)完成连续数据块传输,也可以通过全局读取(Global Load,GLD)和全局存储(Global Store,GST)指令传输小而离散的数据。同一核组内的每两个从核之间可以通过远程内存访问(Remote Memory Access,RMA)实现数据传输。
2 层间作用力KC 力场
最初,KC 力场是由Kolmogorov 和Crespi 为石墨系统开发的。由于该力场的势函数能够捕捉到层状结构的各向异性性质,具有描述层间力学和摩擦学特性的能力,已被用于碳纳米管和层状石墨烯结构的MD 研究中[18-20]。
KC 的势函数公式由三部分构成:长范围各向同性的L-J 吸引项、短范围各向同性的类似Morse 势的排斥项和用于修正各项异性效应的横向的高斯型斥力项。表达式如下:
其中,z0,A,λ,δ和C2n是拟合的参数。rij和ρij分别是中心原子i和j之间的全距离和横向距离。横向距离是指一个石墨烯层上的原子j与相邻石墨烯层上的原子i的表面法线之间的最短距离。
由于KC 力场同时涉及长范围和短范围的相互作用,且截断半径越长,中心原子的邻居原子越多,计算密度越大,导致利用KC 力场在模拟二维材料体系时占用了绝大多数的计算时间,因此,优化KC 力场的性能将会有效提升二维材料的模拟效率。
3 算法设计与优化
在二维材料的MD 模拟过程中,层间作用力的计算时间占比通常在95%以上,因此属于计算密集型问题。而采用KC 力场描述层间作用力(模拟流程如图2 所示)时,时间占比达到97%以上,因此,KC 力场的性能直接决定了整体的模拟效率。

图2 KC 力场计算流程
本文利用热点采样工具GPTL 收集到KC 力场的热点函数占比如表1 所示,其中,斥力计算(calc_FRep)占比98%,这是因为斥力计算公式更加复杂,需要计算中心原子与短邻居原子之间的相互作用。本节从数据布局、算法优化、访存策略和并行计算四个角度对KC 力场进行性能优化。

表1 热点函数分布
3.1 数据布局
法向量用于计算原子间的横向距离。KC 力场的原版实现采用预处理方案,提前遍历短邻接表计算出每个中心原子i的法线并保存在多维数组中。由于受力计算仅需要中心原子i的法线,不依赖于其他计算过程,因此本工作采用“即算即用”策略,存储结果仅需常量数组,避免多次遍历短邻接表,从而节省了带宽和内存资源。同时,也对数组的访问顺序进行了优化。这一过程如图3 所示。

图3 法向量循环计算
另外,本文工作还对计算受力所需的原子信息进行结构体打包操作,包括原子坐标、类型和tag 标记,共32字节,这是计算每对原子受力时需要频繁读取的数据,打包操作极大提升了软件Cache 读取数据时的访存效率。
3.2 算法优化
3.2.1 消除冗余计算
因为层间作用力只涉及计算本地中心原子i的短邻居,而镜像原子不参与层间相互作用的计算,所以本工作在构建短邻居列表时只需搜索本地原子,从而消除搜索镜像原子的短邻居带来的冗余计算。
3.2.2 多核心融合
由于计算法向量需要遍历短邻居列表,因此可以将短邻居列表的构建与法向量的计算融合。计算长范围作用力时,引力项和斥力项均需遍历长邻接表,两者之间没有依赖关系,因此可以融合(如图4 所示)。经过两次融合后的算法,均需遍历本地中心原子i,为了复用中心原子信息,两者可以放在同一循环中计算。

图4 受力计算融合
3.2.3 设置缓存区
短邻居受力是嵌套在长邻接表的循环中计算的,设长邻接表长度为N,短邻接表长度为n,则累加短邻居受力时的写内存操作为N×n次。由于短邻居列表只由中心原子决定,因此本文为当前中心原子设置一个Buffer缓冲区,暂存短邻居受力结果,从而将从核写主存的次数减少到N×1 次,节约带宽资源。
3.3 并行计算
3.3.1 线程级并行
LAMMPS 中已实现基于MPI 的进程级并行,每个进程的任务是计算nlocal 个本地中心原子的受力。在此基础上,本工作充分利用从核资源实现线程级并行,将nlocal 个中心原子划分为更细粒度的从核任务,分配给64 个从核并行计算,以提升模拟效率。
3.3.2 行加锁软件Cache 累加受力
由于SW39000 不支持主从核内存的写回一致性检查,多个从核同时并行写回受力结果时会产生写冲突问题。本文采用基于原子操作FAAL 指令的行加锁Cache策略,实现多个从核并行累加中心原子及其邻居原子的受力至主存中。
3.3.3 从核通信累加能量
能量的计算需要对全局变量累加,为避免多个从核产生写冲突,本文的实现是每个从核先计算各自的能量,在整个循环结束后,利用从核通信机制,将64 个从核的结果归约到从核0,最后由从核0 写回至主存。
3.3.4 利用C++特性
新一代神威的C++特性为从核编程提供方便。主核调用从核函数时,参数的传递仅需一个this 指针。对于代码中的常量if 分支判断,采用基于模板参数的编程方法,在预编译时生成多个不同函数,从而避免每次循环迭代的判断开销。
3.4 访存策略
3.4.1 硬件Cache
新一代神威超级计算机支持硬件Cache 功能,可以方便地读取离散的数据。硬件Cache 的大小有三种不同配置:0 KB,32 KB 和128 KB。本工作充分利用自动硬件Cache 这一特性,解决常量数组和访问频率较低数组的离散读取问题。
3.4.2 软硬件协同Cache 策略
LAMMPS 采用邻接表数据结构存储原子间的关系,这将导致离散访存问题。本文提出一种软硬件Cache 协同策略解决KC 力场计算过程中的离散访存问题。
对于频繁访问的原子信息,本文采用软件Cache 策略,一次读取一个Cache 行,原子信息以结构体的形式存储,进一步提升软件Cache 通过DMA 访存的效率。
4 整体性能评估
本章利用5016 原子的六层石墨烯算例Case0(如表2 所示)对性能进行整体评估。通过LAMMPS 中的replicate 命令将此算例进行不同规模扩展(如表3 所示),分别用于加速比、可扩展性和不同平台的性能对比测试。

表2 六层石墨烯算例Case0

表3 不同规模的算例
4.1 加速比
图5 展示了各个优化版本的加速比。通过数据组织和算法优化,重构代码相对原版实现8 倍加速比。利用从核进行线程级并行后,整体性能加速20 倍,此时硬件Cache 的大小配置为0,即从核通过GLD 操作访问主存空间。当硬件Cache 的大小配置为32 KB 和128 KB 时,整体性能分别加速109 倍和120 倍。采用软硬件协同Cache 策略时,整体性能实现155 倍加速,此时硬件Cache 配置为32 KB,软件Cache 配置为128 KB(256 行,16 列)。

图5 不同优化版本的加速比
4.2 其他平台对比
本节在不同的平台(如表4 所示)对比了KC 力场模拟二维材料体系时的整体性能,如图6 所示。本工作(SW-OPT)在SW39000 单核组上具有良好的整体性能表现,比单个E5 2680-v3 核心快3.2~3.7 倍,比单个Gold 6138 核心快1.6~1.85 倍。

表4 测试平台参数

图6 不同平台性能对比
4.3 可扩展性
本节测试了弱强扩展性以及并行效率,计算方式如下:
其中,TN表示N个进程并行时的模拟性能,即每秒模拟的时间步(Timesteps/Second),base=6。
弱扩展性的表现如图7 所示。以6 进程为基准,使用Case0 和S0 两种算例,每次测试将进程数和原子数目同时等比例扩展2 倍。Case0 扩展到1 536 进程时,原子总数为1 284 096,并行效率为92.7%,模拟性能约为2 ns/day;S0 扩展到1 536 进程时,原子总数为10 272 768,并行效率为99%。由此可得,单进程负载的原子数目越多,计算密度越大,并行效率越高。
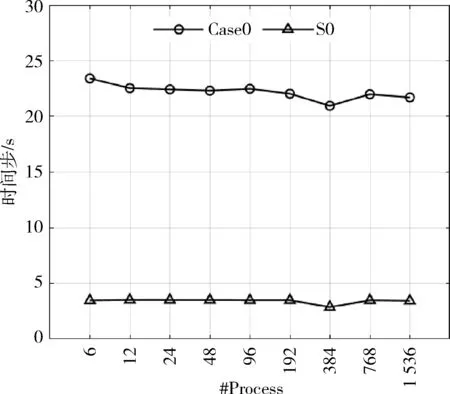
图7 弱扩展性
强扩展性的表现如图8 所示。使用S1 和S2 算例测试从6 进程扩展至1 536 进程时的并行效率分别为48.3%和78.1%。从图8 中可以看出,算例S2 的并行效率高于S1。这是因为总原子数不变时,随着进程数目增加,单进程分配的原子数目减少,计算密度降低,性能更容易受到其他因素影响,如进程间通信。

图8 强扩展性
5 结论
本文基于新一代神威超级计算机,对二维材料模拟中的层间力场KC 开展移植、算法优化和线程级从核并行等工作,针对层间力场的热点函数进行了深入分析,采用一系列的优化方案,有效提高了二维材料的模拟效率。研究表明:
(1)通过重新组织数据和算法优化,使整体性能相对原版加速8 倍;
(2)利用从核实现线程级并行,在不使用任何访存策略时,实现了20 倍的整体加速;
(3)采用软硬协同Cache 策略优化访存性能,实现了155 倍的整体加速。
与其他平台性能相比,本工作具有更为优异的性能表现,比E5 2680-v3 单核心快3.2~3.7 倍,比Gold 6138单核心快1.6~1.85 倍。通过对整体性能进行可扩展性测试发现,弱扩展性的并行效率为92.7%~99%,本工作有助于提高更大规模的二维材料体系的模拟效率,同时也为解决神威上的类似问题提供参考方案。
猜你喜欢
小学生学习指导(小军迷联盟)(2023年3期)2023-03-27
凤凰动漫(军事大王)(2022年9期)2022-11-05
中国音乐学(2022年1期)2022-05-05
今日农业(2020年18期)2020-10-27
科技传播(2019年22期)2020-01-14
中国教育网络(2018年7期)2018-08-10
物理学报(2018年10期)2018-06-14
中国计算机报(2018年42期)2018-01-31
中国卫生(2014年12期)2014-11-12
