
一种基于FPGA 的CNN 硬件加速器实现
2023-12-25 09:00邱臻博
电子技术应用 2023年12期
邱臻博
(重庆邮电大学 光电工程学院,重庆 400065)
0 引言
随着深度学习技术的飞速发展,神经网络模型在图像识别、目标检测和图像分割等领域取得了巨大技术进步[1-2]。然而相比较传统算法,神经网络在获得高的性能同时也带来了高计算复杂度的问题,使得基于专用硬件设备加速神经网络成为神经网络模型应用领域关注的焦点。目前,神经网络模型硬件加速的主要方案有GPU、ASIC 和FPGA 三种方案。相比较GPU,FPGA 具有成本功耗低的特点;相比较ASIC,FPGA 具有模型实现灵活、开发速度快、综合成本低的特点,特别适用于当前神经网络在边缘设备上部署的需求,因此基于FPGA的神经网络模型加速研究成为当前神经网络领域研究的热点[3-5]。
大多数神经网络模型中卷积层的运算量占到了总计算量的90%以上,因此可以通过在FPGA 中执行卷积运算来实现神经网络加速[6-7]。文献[6]基于FPGA 实现通用矩阵乘法加速器来实现神经网络加速,获得了很好的加速性能。文献[7]则提出了一种基于脉动阵结构的矩阵乘法加速模块,并用于神经网络加速,获得了较好的性能提升。文献[8-9]从卷积运算的加速算法方面进行研究,Liang Y[8]等人基于二维Winograd 算法在FPGA上对CNN 进行了实现,与常规的卷积计算单元相比,该实现中基于二维Winograd 算法设计的卷积计算单元将乘法操作减少了56%。Tahmid Abtahi[10]等人使用快速傅里叶变换(Fast Fourier Transform,FFT)对ResNet-20模型中的卷积运算进行优化,成功减少了单个卷积计算单元的DSP 资源使用量。除卷积运算加速外,相关研究团队对神经网络加速过程中的其他方面也展开深入研究[10-14]。文献[10]提出了一种块卷积方法,这是传统卷积的一种内存高效替代方法,将中间数据缓冲区从外部DRAM 完全移动到片上存储器,但随着分块层数的增加,精度会降低。文献[11]提出一种相邻层位宽合并和权重参数重排序的策略实现数据传输的优化方法,增加数据传输并行度的同时节省了通道的使用。文献[12-14]采取乒-乓处理结构,分别在输入模块、卷积运算单元、输出模块方面提升了卷积运算的速率。
本文介绍了一种通用的CNN 硬件加速器设计方案。在方案中对输入数据加载、核卷积运算、输出数据传输等部分进行并行化设计和流水线设计,以有效提升卷积网络的综合加速效率,最终在FPGA 中完成了加速器的实现及性能评估。
1 卷积神经网络加速策略
根据Roof-line 模型[3],可以用算力π和带宽β这两个指标衡量计算平台所能达到的最大浮点计算速度。Roof-line 模型的计算力公式由式(1)给出。其中,Imax为计算力强度上限,等于算力除以带宽。
可以看到,要想提升加速器的综合性能,需要同时考虑加速器并行处理能力和接口速率。因此本设计中采用三种策略对加速器数据传输部分和卷积运算部分分别进行优化设计,以提升加速器性能。
1.1 邻通道数据位宽合并传输
由于FPGA 片上存储资源有限,卷积运算过程中的输入特征数据、权重参数数据及计算结果数据都需存储在片外存储器上。目前FPGA 的AXI_HP 高速传输接口的常用传输位宽32 bit,但目前卷积神经网络在加速时往往对模型参数和输入数据进行16 bit 量化或8 bit 量化处理以降低加速所需的硬件资源。如果每个接口单次只传输16 bit 数据,不能很好地利用AXI 总线传输带宽。由于卷积运算相邻通道数据之间并没依赖关系,可以并行执行,因此可以对相邻通道数据进行合并传输。
相邻通道数据合并方式如图1 所示。在输入数据方面,将相邻两层特征数据、权重数据分别合并为32 bit 数据,存储于DDR 上。在输出数据方面,将两个不同卷积核运算得到的结果合并为32 bit 数据,再通过AXI_HP传输通道传输到DDR 上。与使用不同传输通道来并行传输相邻通道数据相比,相邻通道数据合并传输的方式可以更好地节省传输通道从而提高传输带宽的实际利用率。

图1 相邻通道数据位宽合并
1.2 邻通道数据位宽合并传输
采用传统的BRAM 整块缓存结构,需要先将整幅特征图加载到FPGA 的BRAM 上,然后再开始计算,待计算得到整幅输出特征图后,再将数据存储到DDR 上。传统方案时间开销分布如图2(a) 所示,T1表示从DDR读取完整一层输入数据到FPGA 片上存储器的时间,T2表示卷积加速算子完成计算的时间开销,T3表示计算结果从FPGA 写回DDR 花费的时间,卷积层加速过程总时间Ttotal1=T1+T2+T3。由于加速算子在数据输入和数据输出阶段没有工作,计算性能没有得到充分发挥,因此加速器利用效率不高。
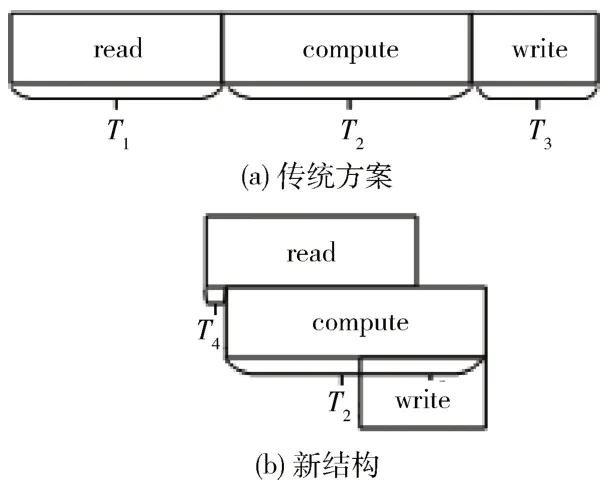
图2 两种方案时延开销对比
采用基于行数据的输入数据流加载缓存结构,在数据加载方面,只需缓存特征图的两行数据,当开始加载第三行数据,即可开始卷积运算,有效降低数据加载过程的时间开销;在数据回传方面,得到输出数据后立即回传,无需等待得到整幅输出特征图,有效降低了数据回传过程的时间开销。新结构时间开销分布如图2(b)所示。
基于行数据的输入数据流加载结构完成一次卷积层加速总时间Ttotal2=T1×2/Fh+T2,Fh为一幅特征图的总行数。相较传统BRAM 整块缓存结构,新结构能够有效地降低由数据传输带来的系统延迟,有效地提高加速器的利用效率,且使用的资源量更小。
1.3 基于流水线结构的卷积运算并行化
如并行运算是FPGA 加速神经网络的常用优化方式,主要是通过展开卷积运算过程,然后依靠FPGA 高并行性计算的优势,来达到加速的目的。常用的卷积运算并行化处理方式有三种:核内并行、输入通道并行、输出通道并行。
卷积运算过程如算法1 所示,其运算实质是六层的for 循环。核内并行是通过同时读取一幅特征图的Tk×Tk个数据,然后与对应权重进行乘累加操作,其中Tk为卷积核的长度。核内并行实现是将算法1 中循环L5、L6完全复制展开,使运算并行度提升了Tk×Tk倍。

输入通道并行是指同一时钟周期读取Ti通道特征图像素点,然后与对应的权重数据进行乘累加操作,Ti为输入通道并行度,实现过程是将算法1 中循环L2 复制展开成Ti份。合理地设置输入通道的并行度可以有效地提升卷积运算的计算速度,显然Ti的值设置越大,卷积运算速度越快,但对乘法器(Digital Signal Processing,DSP)的资源数量要求就越高。如果Ti的值设置过小,则无法充分使用FPGA 的板载DSP 资源。
输出通道并行是指在同一时钟周期读取To通道卷积核参数并与特征图像素点进行乘累加操作,To为输出通道并行度,实现过程是将算法1 中循环L1 复制展开为To份。采取输出通道并行不仅可以通过提升卷积运算的并行度来加快卷积运算的速度,还可以有效地复用特征图像素点数据,从而降低FPGA 与DDR 之间的数据交互。
为了进一步提高卷积运算的并行性能,对卷积运算的循环进行流水线处理。假设完成一次卷积的时间消耗为Tc,当前层所需要执行的卷积运算次数为Nc,两次卷积运算之间的时间间隔为Tinterval。若未采取流水线处理,Tinterval=Tc=3。如图3(a)所示,当前层卷积运算的总时间消耗Ttotal3=Tc×Nc=6。若采取流水线处理,Tinterval=1,如图3(b)所示,即当前层运算的总时间Ttotal4=Tc+Nc-1=4。卷积神经网络的每一层都包含大量的卷积运算,采取流水线的循环优化方式可以极大提高硬件的计算性能。

图3 流水线处理
2 神经网络加速器设计与实现
2.1 加速器整体框架
本设计采取外部DDR 芯片和FPGA 相结合的方式,在Zynq-7020 芯片上完成硬件加速器的设计。整个加速器由输入缓存、卷积、输出缓存和池化4 个模块组成,具体结构如图4 所示。输入缓存模块实现将输入数据从DDR 加载到卷积模块。卷积模块计算完成后则将数据先发送到卷积输出缓存模块,在卷积输出缓存模块中完成分块通道上的对应像素点累加。池化层完成池化操作后,将数据通过DMA(Direct Memory Access)回传到DDR。

图4 硬件加速器整体设计
加速器工作流程如下,首先将待测试图像数据和在PC 端上训练好的卷积权重参数及偏置存放于SD 卡中,然后从SD 卡中读取到DDR 上。在PS(Processing System)端通过DMA 将DDR 上的数据以流数据形式传递给PL((Programmable Logic)端的输入缓存模块,然后在卷积加速模块上完成卷积计算,整个架构实现了卷积核内并行、输入通道并行、输出通道并行,并且在卷积运算过程中实现了高流水线处理,使每个卷积运算之间的流水线间隔到了1。最后将计算结果传回给DDR。
2.2 输入缓存模块
在卷积神经网络模型中,每一层的运算都需要从DDR 中读取大量的特征数据和权重参数,数据传输和加载的效率是影响硬件加速器性能的重要因素之一。因此,本设计从VGG16 网络模型特点和ZedBoard 片上资源情况出发。以基于行的输入数据流加载传输形式加上 LINE_BUFEER 存储结构设计了输入缓存模块。
输入缓存模块的结构如图5 所示,由卷积窗口寄存器组和LINE_BUFFER 构成。首先,Reg0 寄存器读取DMA 中的流数据,并将其写入FIFO1 中。重复此操作,直至读取完特征图分块的一行数据后,Reg0 寄存器继续读取DMA 中的流数据,同时,从FIFO1 中读取数据,并将数据写入FIFO2 中。重复以上操作,直至FIFO1 和FIFO2 缓存下两行数据后,重复读写操作同时,将Reg0、FIFO1、FIFO2 中的数据分别传递给卷积窗口寄存器组中的Reg1、Reg4、Reg7。卷积窗口寄存器组中的数据依次向左移动,从而实现卷积滑动窗的操作,当卷积窗口寄存器组缓存好一次卷积所需的特征数据时,将数据打包以流数据形式发送给卷积模块进行卷积运算。

图5 卷积输入数据硬件缓存结构示意图
2.3 卷积层硬件加速单元
本文采取了并行运算和数据分块的优化方法来设计硬件加速器。其中,并行加速运算包括输入并行度Ti,输出并行度To,核内并行度Tk×Tk。如图6 所示,在每个时钟周期同时读取Ti个卷积窗口的特征图数据,与To卷积核的Ti通道数据进行对应乘累加,最后分别得到To幅特征图的一个输出像素点。加速器整体加速并行度=Ti×To×Tk×Tk。本设计卷积运算中乘法由DSP48E 完成,加法则由LUT 完成。

图6 卷积运算单元硬件设计
采用图6 卷积运算单元硬件设计,DSP 资源消耗为:
在卷积模块中包含特征数据输入通道、权重参数输入通道和特征数据输出通道。在卷积运算时,每个时钟周期都会接收Ti个卷积窗口的特征数据,而卷积核权重参数只会在每个特征图块的第一次卷积时接收数据,因为对于同一块特征数据,卷积核数据是不变的。在该硬件设计中,利用了流水线处理优化方法,实现了数据输入、计算、数据输出的同时进行,使得每次卷积运算之间的间隔只有一个时钟周期。
2.4 输出缓存模块
卷积神经网络中的每一层卷积层往往包含多幅输入特征图,而对于多幅特征图产生的卷积结果数据,无法直接传输到外部存储器,必须进行有效的缓存。本文输出缓存结构硬件设计如图7 所示。首先,输出缓存模块接收由卷积模块传送进来的卷积计算结果。然后判断当前特征图为第一幅特征图,若是,则不从Buffer 中读取数据,而是直接给缓存结果寄存器赋0,然后将累加的结果存入相应Buffer;若不是,则先读取出缓存于Buffer 中的中间数据,将其赋值给缓存结果寄存器。待累加至最后一幅特征图后,将卷积结果进行激活函数处理。然后判断下一层是否为池化层,若是,则将数据发送给池化模块;若不是,则将数据通过DMA 发送到DDR 上。其中,Buffer 个数由输出通道并行度决定。整个输出硬件结构实现了流水线处理,使得输入、卷积、输出三大步骤同时进行。

图7 输出缓存结构硬件设计
2.5 池化模块
在卷积神经网络中,各层之间的计算是串行结构,池化层的数据输入依赖于上一层卷积层的数据输出。为了减少因FPGA 频繁地从DDR 上读取数据带来的延迟,本设计采取将池化层后接于卷积层的输出缓存模块。当输出缓存模块完成通道累加后,将结果传进池化模块,池化模块缓存两行输出结果后,进行池化操作,将结果传回DDR 上存储。
2.6 多层神经网络加速调度策略
实际神经网络模型往往包含多个卷积层,在加速过程中,需要将不同的卷积层的计算结果存储到DDR 不同的存储区域。加速器依次对每个卷积层分别加速,前一层的计算结果为下一层的输入数据。多层网络的调度和神经网络加速器的调用通过FPGA 自带的ARM 硬核实现。具体的神经网络的加速过程如图8 所示。

图8 多层神经网络调度
3 实验结果及分析
3.1 实验环境
本设计采用Xilinx ZedBoard 硬件平台,核心芯片为Zynq-7020,内部资源包括667 MHz 双核Corter-A9 处理器和Aritix-7 系列可编程逻辑资源,DDR3 内存大小为512 MB,FPGA 内部硬件资源FF、LUT、DSP48E、RBAM_36K 分别为106400、53200、220、180。
设计工作中首先使用Vitis HLS 2020.2 完成卷积加速器关键模块设计并生成对应的IP 核,其次基于Vivado 2020.2 完成PL 端完整的卷积加速器的设计和实现,最后在ARM 端通过软硬件协同处理的方式完成加速任务。
本设计对VGG16 和Darknet-19 网络模型分别进行部署。首先对预训练的网络模型的权重参数,进行重排处理,以适应硬件加速器的读取方式。硬件加速器中具体参数如下:卷积层输入通道并行度Ti=8,输出通道并行度To=2,核内并行度为9,卷积加速器整体并行度为144。完成加速器设计后的逻辑资源开销如表1 所示,两种网络加速性能GOPS(Giga Operation Per Second)如表2 所示。

表1 硬件资源消耗

表2 加速器性能
3.2 实验结果及分析
表2 中Darknet-19 网络加速器GOPS 略低于VGG16网络的原因是Darknet-19 网络中存在1×1 卷积运算,无法充分利用已使用的DSP 资源。
表3 给出了本文设计的加速器与已有CNN 硬件加速方案的性能比较。可以看到,与文献[11]相比,其DSP使用数量较本文方案多使用了36.18%,但GOPS 仅提升了14.83%。与文献[12]相比,在相似的DSP 资源消耗和时钟频率下,本文的加速器方案的GOPS 要高18.77%。对于不同的硬件平台,由于无法直接比较不同加速器的GOPS,因此往往采用DSP 利用率来比较加速器的性能。其中DSP 利用率定义如式(3)所示,其中,λ表示一个DSP 单元在一个周内处理的操作(对于16 位定点数,λ=2),f表示时钟频率。

表3 现有CNN 方案比较
从表3 中可以看出,本文的加速器方案中的DSP 利用率可以接近80%,分别比文献[11]、文献[12]、文献[15]中的DSP 利用率高12.5%、16.5%和8.5%。经分析可得知,本方案加速器性能提升的主要因素在于,采用相邻层数据合并的优化方式,节省了传输通道从而提高传输带宽的实际利用率,使得限制加速器性能的关键因素为FPGA 的DSP 资源。采用行输入数据流加载方案,有效减少了输入数据加载的时间开销,降低了卷积加速核的空闲时间,提升了DSP 资源的利用率。
4 结论
本文提出一种通用的卷积加速硬件架构,主要针对卷积神经网络中卷积层的运算进行加速。采取输入、输出、核内三者共用的并行加速方式。通过对硬件加速单元的设计,共使用144 个MAC 单元进行并行运算,提高加速器的计算性能。在数据缓存方面,采取相邻数据位宽合并传输和基于行的数据流加载设计输入数据硬件缓存结构,有效地降低了由数据传输带来的时间开销和片上存储资源的消耗。设计采取高度流水线处理,实现了读取数据、运算、存放数据三者的流水线进行,有效提升了计算性能。
猜你喜欢
现代装饰(2022年5期)2022-10-13
小哥白尼(趣味科学)(2022年5期)2022-08-15
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
少先队活动(2021年6期)2021-07-22
数学小灵通(1-2年级)(2020年6期)2020-06-24
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中学生数理化·八年级数学人教版(2017年2期)2017-03-25
电视技术(2014年19期)2014-03-11
