
ADsim:面向自动驾驶的高性能并行仿真平台
2023-12-25 09:00苏敬发高利斌蒋金虎
电子技术应用 2023年12期
苏敬发,周 炜,高利斌,蒋金虎
(1.复旦大学 大数据研究院,上海 200082;2.国家并行工程技术中心,北京 100080)
0 引言
自动驾驶仿真是计算机仿真技术在汽车自动驾驶领域的应用,它通过数学建模的形式将自动驾驶的应用场景进行数字化还原,建立接近真实世界的系统模型[1-2]。通过仿真环境进行分析和研究,便可在实际落地前对自动驾驶算法及系统进行测试验证。
目前大多数仿真平台仅支持单点仿真[3],单点仿真方式分散且独立,实际部署和应用面临着资源忙闲不均、作业在节点间低效串行等问题,无法满足自动驾驶复杂场景仿真日益增长的计算和处理需求,大规模节点统一管理和调度是自动驾驶仿真的必然趋势,在通用计算领域,云化是大规模节点便捷管理和高效调度的有效方式。不同于通用计算,面向自动驾驶仿真应用对异构计算资源和现有协议栈有着强依赖性,构建面向自动驾驶的云化仿真平台面临着高效虚拟化、均衡调度、便捷端-云交互的挑战。
本文针对自动驾驶仿真平台当前的难点挑战,基于轻量级虚拟化技术设计了面向自动驾驶的高性能并行仿真平台系统架构,并设计和集成了细粒度资源均衡调度和低延时远程交互方法,构建了ADsim 高性能并行仿真平台,并在一汽自动驾驶仿真业务中进行了部署应用。测试表明本系统通过ADsim 给容器应用指定分配GPU,满足了不同的策略需求,在实现更好的灵活性与均衡性的同时,其高效性和高响应性也得到提升。
1 背景概述
自动驾驶是人工智能(AI)技术与汽车行业深度融合的重要场景之一,尤其是近年来随着AI 算力和数据驱动能力的提升,自动驾驶领域的技术突飞猛进,大量科技巨头和新创公司进入到该领域。自动驾驶进入到公共出行、环卫、零售、观光、物流、农业等多个领域,涵盖客运、货运和专项工作等多种复杂场景[4],在人类活动和社会生产中越来越重要。
在实际投入使用前,自动驾驶汽车必须行驶数十亿英里才能证明其可靠性。在真正的自动驾驶车辆上测试自动驾驶算法是非常昂贵的[5],许多研究人员和开发人员无法负担真正的汽车和相应的传感器。通过软件模拟来发现和复现问题是降低成本和技术门槛的重要手段。通过仿真,开发人员可以在不驾驶真实车辆的情况下快速测试新算法,不需要真实的环境和硬件,可以极大地节省成本和时间。与真实道路测试相比,仿真测试更安全,尤其是现实世界中的危险场景,如极端天气,能够准确再现问题场景的所有因素。因此,自动驾驶仿真是自动驾驶中的关键支撑技术,是企业获得低成本核心竞争力的主要途径。近年来,随着自动驾驶技术的蓬勃发展,大量互联网企业和汽车厂商加大对自动驾驶仿真的投入和创新,各种自动驾驶仿真软件层出不穷。
国外的自动驾驶仿真软件研制处于各大巨头与创新公司百花齐放的阶段。市场上的自动驾驶仿真软件有两类:一类是以大企业为背景研发的,包括有Tesla 的FSD、Google 的Waymo Carcraft、NVIDIA Constellation、Microsoft AirSim、LG LGSVL 等;另外一类是由专注于自动驾驶仿真的专业公司研发的,如Carsim、PTV VISSIM、TESS、SUMO、VIRES VTD、RESCAN、PreScan等大量各具特色的自动驾驶仿真软件。
国内在自动驾驶仿真领域的发展与国际基本同步,但受限于技术积累和投入的原因,目前主要有百度和腾讯两家。百度与Unity 建立了合作关系,开发了基于Unity 的真实感虚拟环境仿真,为百度Apollo 提供系统仿真服务[6];腾讯为自动驾驶测试验证而专门设计研发了TAD Sim,侧重自动驾驶场景的数字孪生系统对自动驾驶算法完备性提供仿真验证。
由于自动驾驶仿真平台涉及自动驾驶核心关键技术,当前各大公司都采取内部构建仿真平台使用的方式。当前市场尽管有多个开源的自动驾驶软件,如Autoware 和Apollo,但与它们一起协同使用的仿真模拟器的选择却有限,且多数仅支持单点工作,缺少大规模的协同运作,性能也有待优化[7]。因此,本研究意在搭建面向自动驾驶的高性能并行仿真平台,以容器化等技术突破当前仿真面临的瓶颈局面。构建面向自动驾驶高性能并行仿真平台,当前存在以下几方面挑战:
(1)设备耦合紧,虚拟化难:系统运行仿真时需要大量计算资源,当前仿真应用与物理设备资源紧耦合,尤其是渲染部分,严重依赖物理显卡。虚拟化是将仿真进行云化的基础[8],传统的方案以虚拟机方式为主,但开销大,尤其是虚拟机中的GPU 虚拟化部分,会占用大量系统资源,需要一种更高效的虚拟化方式来满足云化要求[9]。
(2)通用调度无法适应新需求,灵活性差:自动驾驶测试需仿真实例与自动驾驶软件实例交互配合,面对上层应用需求的多样化,整体调度需更具灵活性[10]。且不同种实例所需的底层资源也面临差异,现有Kubernetes通用的调度策略无法感知自动驾驶仿真组件间的关系,无法适应自动驾驶仿真调度需求[11]。
(3)远程操作延时大,交互不便:将仿真服务器进行云化后,仿真运行在云端服务器,交互操作需要通过网络进行,现有的远程交互基于远程桌面,性能开销大、画面反馈延时长,导致了端-云间的交互不便,用户体验差。
为解决上述问题,本研究设计了与Kubernetes 融合的系统架构,并引入高效虚拟化、灵活均衡调度和便捷端-云交互等关键技术,实现了面向自动驾驶的高性能并行仿真平台ADsim,并在实际生产环境中进行了测试验证和部署使用。
2 系统架构
本文现有基础支撑环境基于Kubernetes 进行大规模节点部署和运维。为了与现有平台的融合统一,仿真平台基于Kubernetes 框架进行设计,利用Kubernetes CRD(Custom Resource Definition)机制增加仿真资源类型,主要由管理模块与工作模块组成,各个模块以容器方式运行,具体架构如图1 所示。

图1 系统架构图
管理模块负责整体的资源信息处理与分配工作,包含资源管理、用户管理、实例映射、与Kubernetes 交互、与工作模块通信的具体功能。管理模块会在与Kubernetes 主节点交互的基础上,综合工作节点信息、工作模块信息对不同用户按策略进行资源分配。工作模块一方面负责对计算节点上所运行实例的具体优化,对不同的两种实例Lg 节点与Apollo 节点,采用渲染加速、GPU分配策略等方案从底层进行优化。另一方面将运作信息反馈给管理模块,实时进行资源的再规划与再利用。
本系统总流程即管理模块先收集资源信息进行处理,再将实例与硬件资源进行映射,然后通过工作模块进行性能优化,开始仿真,并在工作过程结合Kubernetes、工作模块的反馈信息来交互处理。
3 系统设计与实现
本节针对高效虚拟化、均衡度调度和端-云交互三个目标进行设计与实现。
3.1 高效虚拟化
虚拟化作为仿真云化的基础,传统方案以虚拟机方式为主,但性能开销大,尤其是虚拟机中的GPU 虚拟化部分,会占用大量系统资源。在IBM 的一份针对裸机、容器与虚拟机运行性能的研究报告显示,在不同的配置情况下,Docker 的性能都等于或超过虚拟机方式。例如将广泛应用于云中的关系数据库MySQL 部署在裸机、Docker 以及KVM 下,测试结果显示Docker 具有与裸机相似的性能,在更高的并发性下差异渐近接近2%。而KVM 的开销要高得多,在所有测量的情况下都高于40%[8]。因此本系统采用更轻量级的容器化方式进行高效的虚拟化。
相比于虚拟机技术,容器的轻量级特性,使得开发、测试以及部署过程都可以节约大量时间。在同样的硬件环境下,容器能运行的镜像数远多于虚拟机的数量,因此更便于对资源的精细分配,系统利用率高。而基于Kubernetes 的开源生态迅速发展,容器在可管理性、可观察性、安全性、稳定性等多方面也均优于虚拟机,有大量组件提供保障。
自动驾驶仿真与实际的物理资源耦合密切,需大量使用物理显卡资源,尤其是渲染部分。而容器应用对显卡设备的控制度不足,仅可查看GPU 的使用信息等,而无法对其进行具体分配调度等细粒度操作。因而本系统在仿真应用与硬件资源的中间层,采取API 重定向的方式实现GPU 虚拟化。在应用与驱动之间,通过修改图像渲染接口截获处理硬件请求。API 重定向方式如图2所示。

图2 API 重定向方式
本系统首先针对仿真应用进行了容器化处理。仿真应用本身不支持容器化,本系统针对服务器Linux 环境,从底层设计Dockerfile 文件,添加仿真所需依赖项libvulkan 等,并修改添加了vulkan-loader 层,使仿真容器能实现API 重定向的转发方式。
在设计构建好仿真镜像后,依然面临容器运行报错的问题。本系统完成了对容器化多个难点问题的详细定位与解决。如GPU 启用失效,本系统通过修改验证容器依赖环境与GPU 版本配置的一致性,解决了仿真应用与容器环境的不兼容问题,使容器化使用GPU 可行,并可进一步地进行GPU 虚拟化处理。
由于图形化应用对Linux 系统的兼容性不足,本系统还针对容器的显示与渲染部分进行了设计改造,通过修改Linux 系统配置与容器显示权限问题,使得图形化的仿真应用可成功在远程端操作处理。并进一步对仿真应用的网络服务进行了优化设计。当在同台机器启动多个容器时,仿真会面临并行启动失败的问题。本系统通过对容器网络进行设计,避免了端口冲突,分别以host 以及bridge 模式完成了对多个容器的端口分配与管理,实现了在远程端的Web 界面对多个容器应用同时进行模拟仿真的配置处理。
在虚拟化的具体处理上,系统工作模块通过修改仿真应用所使用的图形渲染API Vulkan 来实现API 重定向。通过Vulkan 的Loader 机制,在Layer 层拦截函数,实现GPU 的分配处理:指定单个GPU 处理多个容器应用、多个GPU 处理单个容器应用以及多个GPU 处理多个容器应用。
3.2 均衡调度
在调度问题上,由于自动驾驶仿真不仅包括仿真环境,还需耦合自动驾驶操作系统,因而要有灵活的调度管理,且不同情况下所需底层资源的差异性也要求调度具有灵活性、均衡性。
本系统优化了仿真软件与自动驾驶操作系统软件的交互调度。在实际应用中,可能包含一个仿真场景,在此仿真场景下,又包含多个自动驾驶操作系统来控制多辆汽车。此时仿真与操作系统即一对多关系。本系统在此基础上,将对应关系扩展为多对多关系,根据不同应用需求,可以同时部署一个或多个仿真环境,再由管理模块统一管理多个仿真与操作系统实例,进行统一调度与资源分配。
系统管理模块会根据资源管理信息、用户管理信息、通信信息,将请求的实例发放到具体的工作节点并分配硬件资源,进行实例映射。管理模块根据上层需求的不同,支持不同的调度策略,包括集中往一台机器分配的低功耗策略,或是向多个节点同时发送请求的高性能并行策略。ADsim 仿真平台调度方案如图3 所示。

图3 ADsim 仿真平台调度方案
为进一步提高实例映射效率,合理利用硬件资源,在接受到具体的实例运行请求后,系统将根据实例类型进行区分优化,从而使调度更均衡。系统的实例包含模拟仿真实例Lg 节点和自动驾驶系统实例Apollo 节点两种。当接受到仿真实例Lg 节点的请求后,系统工作模块将在Vulkan 虚拟层对资源请求进行处理。工作模块支持在Vulkan 层指定分配GPU 的功能,从而达到更高效的底层映射效果。对于Apollo 节点实例,由于渲染计算不是必需的,工作模块暂不提供对Apollo 节点的加速优化。
3.3 端云交互
在使用服务器进行仿真时,需要将远程服务器渲染后的画面返回本地进行交互。
传统的解决方案采用远程显示方法,如VNC 等策略,把被控制端的屏幕做成图像,经过压缩后传送到控制端,即等待应用完成仿真渲染后再截取画面进行延时反馈。如图4 所示,VNC 在远程服务器上运行一个额外的X 服务器,然后通过 RFB 协议用将画面显示到本地。

图4 VNC 显示原理
但该方案对于自动驾驶仿真的支持度并不理想,一是服务器端本身并不包含显示画面,二是此类方案会增加额外的系统开销,且反馈延时长易卡顿,反馈效果也不够理想。
本系统选择针对帧缓冲机制来完善端-云交互过程,如图5 所示。帧缓冲(Framebuffer)是Linux 系统为显示设备提供的接口,它把显示缓冲区抽象化处理,屏蔽图像硬件底层的差异,允许应用直接对显示缓冲区进行读写操作。本系统首先将应用实例所需的显示和渲染请求分离,其渲染部分交予GPU 完成,再截取其显示流,传导到虚拟屏幕上,解决了服务器端显示缺失的问题,同时也避免了计算资源的浪费。即在Vulkan 层调用图形库时,将所需资源分流为显示需求和渲染需求两部分,并对不同分流进行操作,将显示流连接到虚拟屏幕,将渲染流拦截至渲染转发器交付给GPU 计算后,再经由帧缓冲区直接交付给虚拟屏幕,这样同时也避免远程服务器与本地传递画面的延迟问题,优化了从实例到用户的显示过程,使得端-云交互效率更高。
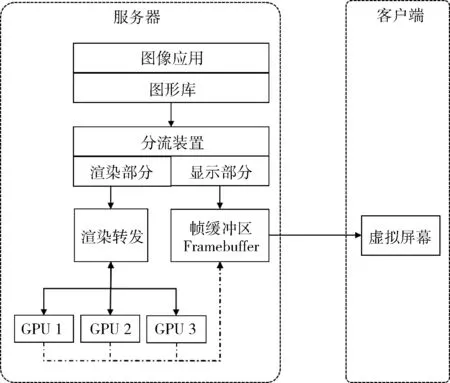
图5 ADsim 端-云交互原理
4 测试与评估
本节对实现的系统原型进行实验测试,以评估面向自动驾驶的高性能并行仿真平台ADsim 的有效性。
4.1 均衡性
本系统将LGSVL 仿真应用进行了容器化的工作并将其成功部署到云平台,进而实现了对其的优化与管理功能。系统通过远程命令在多个容器中启动LGSVL 仿真应用并运行成功。将本地端口号分配给多个LGSVL容器并成功映射到不同的IP 地址。
进一步地,对结合LGSVL 仿真应用和Apollo 的自动驾驶系统,进行测试验证。对资源负载的评价标准为:(1)利用率:指GPU 资源的使用情况;(2)均衡率:指所有GPU 利用率的方差。
本系统通过ADsim 给容器应用指定分配GPU,相较之前,满足了不同的策略需求,达成了多个容器使用多个GPU 的灵活性与均衡性。
测试1:多个容器使用单个GPU 与多个容器使用多个GPU 的效果。低功耗模式下,单个GPU 的利用率高,其余GPU 空闲,均衡率高。
测试2:单个容器使用单个GPU 与单个容器使用多个GPU 的效果。高性能并行模式下,多个GPU 同时渲染一个容器应用,每个GPU 的利用率都较低,且均衡率低。GPU 利用率对比如图6 所示。

图6 GPU 利用率对比
4.2 高效性
为了验证该平台的高效性,本文通过测试其网络延迟的情况,在系统集群中使用sample-webapp Benchmark进行网络测试,对比该容器平台和原虚拟机仿真平台在访问GPU 资源时的网络延迟。通过十组测试的几何平均值来进行比较,以此说明容器仿真平台具备高效性。网络延迟对比如图7 所示。

图7 网络延迟对比
在图7 的对比中发现,本文对容器仿真平台的重构设计消除了虚拟机相关开销带来的网络延迟,进而使得容器仿真平台获得了更好的性能。
4.3 高响应
为了验证本文对端云交互优化的有效性,本节通过对比在本文优化设计与原生设计基础上的响应时间来进行测试。在测试方法上,本节设置十组实验,对两个系统设置相同的容器测试负载,然后观察平台响应时间,即从操作提交到执行结束后可以被正常访问的总时间,并对比十组响应时间测试的几何平均值来进行说明。网响应时间结果对比如图8 所示。

图8 网响应时间结果对比
从图8 可以看出,优化设计后的端云交互系统将应用实例所需的显示和渲染请求分离,并对不同分流进行对应操作,避免了远程服务器与本地传递画面的延迟问题,优化了从实例到用户的显示过程,响应时间的几何均值相比原生设计的系统得到了进一步的提升,使得端-云交互效率更高。
5 结论
本文对自动驾驶仿真平台面临的挑战进行了分析,并设计和实现了面向自动驾驶的ADsim 高性能并行仿真平台,支持了高效虚拟化、均衡调度、便捷端-云交互特性。当前工作主要从计算资源的虚拟化和调度上进行了设计和优化,未来需要结合数据访问等方面对自动驾驶仿真平台进行进一步优化,对仿真应用的计算和数据进行区分,根据不通仿真场景的计算和数据需求来分配资源,并优化现有调度,提升仿真平台效率。
猜你喜欢
阅读(快乐英语中年级)(2022年11期)2022-05-30
读者·校园版(2019年24期)2019-12-10
电子制作(2019年10期)2019-06-17
电子制作(2018年14期)2018-08-21
电子测试(2017年11期)2017-12-15
网络安全和信息化(2015年8期)2015-12-03
小朋友·聪明学堂(2015年8期)2015-11-30
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
