
基于LDA 模型融合Catboost 算法的文本自动分类系统设计与实现
2023-12-22 09:34刘爱琴郭少鹏张卓星
国家图书馆学刊 2023年5期
刘爱琴 郭少鹏 张卓星
1 研究背景
知识经济时代文本信息获取模式的改变对知识发现提出了新挑战[1],网络数字资源的深层知识挖掘以及信息资源与用户个性化需求的强关联成为更为智能、与用户交互性更强的Web3.0的根本要求[2]。随着学科交叉研究活动的不断深入,智能化、自动化的知识分析与文本分类成为信息资源管理当前面临的紧要问题[3]。与此同时,在机器学习技术迅速发展的当下,通过机器学习算法对文本进行分类获得了显著效果[4],尤其是通过有监督的学习算法对文本进行特征抽取。
普林斯顿大学的Blei 等于2015 年首先提出的LDA(隐含狄利克雷分布)模型,可以从大量文档中发现隐含的主题结构信息,有效解决了PLSA模型中出现的问题[5]。随后,国内外学者基于LDA 模型对文档分类开展了一系列算法研究,如Xiong 等提出了一种基于LDA 的加权混合文档摘要模型,使用FCNNM(细粒度卷积神经网络模型)提取语义特征[6];Li 等提出了一种附加类别标签的LDA 模型,即在传统LDA 中融入类别信息,最终达到全部类别的隐含主题在文档中的协同分配[7];Ma 提出了一种基于LDA-Gibbs 模型的加权算法来提高策略文本聚类的准确性[8];姚全珠等针对传统降维算法的缺陷,利用LDA 建模,结合SVM 分类算法进行文本模型表示[9];李湘东等采用LDA 模型对文本材料进行主题建模,并结合SVM 算法构建分类器,实现混合文本的自动分类[10];张志飞等提出了基于LDA 模型融合K 近邻分类算法的短文本分类方法[11];胡朝举等利用LDA 模型得到文档的主题分布后,融合SVM分类算法对特定的短文本进行分类并与传统的SVM 算法进行比较,发现可以有效地克服传统方法特征稀疏的问题,使文本在多个类别的查全率、查准率和F1 值上得到有效提高[12];刘爱琴等用LDA 模型对文本内容进行切分,根据词频对主题词进行提取、聚类,构建了共现矩阵的短文本自动分类系统[13];杨洋等选取新闻话题数据,在LDA 模型基础上加入时序和语义因素,构建了自适应最优新闻话题主题确定的算法,有效提升了新闻话题中最优主题的查准率及F 值[14]。
当前学者在基于LDA 模型探索文本分类的过程中,存在多类别文本特征的局限性和理论技术上的不完善,没有构建出适用范围更加广泛、性能更加优越、通用性更强、稳健性更好的文本自动分类系统。而本研究基于LDA 模型融合Catboost 算法构建的文本自动分类系统正是为克服这些问题所做的尝试与努力,目的是提高知识聚类与关联自动分类效率,进而满足用户更加便捷地寻找、挖掘新知识的诉求。
2 理论基础
2.1 LDA 概率主题模型
主题模型能够自动将文本语料库编码为一组具有实质意义的类别,这些类别称为主题,典型代表是LDA 主题模型。LDA 模型的基础是将一篇文档视为由若干个主题词构成的组合,从而在文本全局的泊松分布中提取出可以代表文本本质的多个主题。每个主题可以产生多个词语,同一个词语可能属于多个主题,但其归属概率不同。在LDA 模型中,每篇文本可以表示为主题的混合分布,每个主题是词的概率分布。其模型结构为“文档—主题—词”的三层贝叶斯产生式模型,结构如图1 所示。
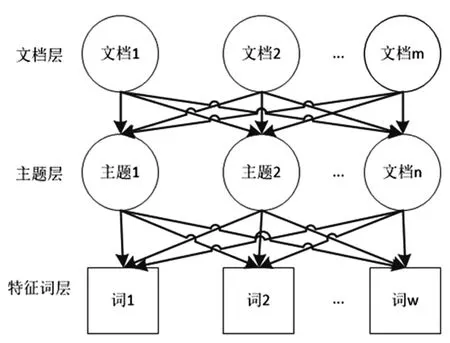
图1 “文档—主题—词”三层模型
LDA 是一个典型的词袋模型[15],不考虑词语在文本中出现的先后顺序,可以将文本表示为多个主题的混合随机分布、将主题表示为多个词语的混合概率分布。LDA 最典型的特征是它能将若干文档自动编码为一定数量的主题,操作者仅需确定主题的数量。在选择好最优主题数量后,运行LDA 模型就会得到每个主题下词语的分布概率以及文档对应的主题概率,如图2 所示。其中,α 和β 分别控制一个迪利克雷分布,方框表示重复抽样。该模型的训练采用的是Gibbs 采样。

图2 LDA 模型
LDA 模型主题提取步骤如下:
第一步:α 随机生成文档对应主题的多项式分布θ;
第二步:θ 随机生成一个主题z;
第三步:β 随机生成主题对应词语的多项式分布φ;
第四步:综合主题z 和主题对应词语分布情况φ 生成词语w,如此循环生成一个包含N 个词语的文档,最终生成k 个主题下的M 篇文档。
对语料集中的文本,重复执行以上过程。根据所使用的LDA 模型,可以得出变量所有的联合分布,见式(1):
将以上所有变量联合分布得到式(2):
据此得到整个语料集中的词项w 的分布,如式(3):
主题词是LDA 最关键的要素,建模前需要根据文本找到最优的主题词并确定其数量。语言模型即最优主题词优劣的评价指标主要为困惑度(perplexity),它和概率主题生成模型直接关系到生成文本的优劣。LDA 模型作为一种文档生成模型,其困惑度越低,表明经过训练的模型文档聚类效果越好。若表示对文档d 所属主题的困惑度,计算方法如式(4):
其中,Nd 表示第d 篇文本的词袋长度,M 表示语料集中文本数目,p(w)表示该模型生成文本的概率。
2.2 Catboost 算法和SVM 算法
Catboost 算法是由Yandex 公司提出的一种基于对称决策树的算法,具有参数少、准确性高和支持类别型变量的梯度提升决策树(Gradient Boosting Decision Tree,GBDT)算法等优势。作为Boosting 族主流算法之一,它是一种可以有效提高模型泛化能力的开源机器学习库。该算法通过数据集进行整体训练,对组合类别特征有效识别,可以生成更高效的策略以避免数据过度拟合,从而有效解决类别特征表示问题以及数据偏移问题,保证数据集的信息均能被有效利用。
首先,对于类别特征,原有的GBDT 算法框架以对应的类别特征标签均值表示,为避免由于数据集结构与分布改变而导致的预测偏移问题,Catboost 算法添加先验分布项,将分类特征值转化为数值进行处理。转化处理过程如下:
第一步:随机排列输入数据集合,生成随机序列;
第二步:将给定序列类别特征值替换为训练集标签均值;
第三步:根据式(5)将类别特征转化为数值。
设σ= (σ1,σ2,…σn) ,则有
其中,P 为先验项,a 为权重系数(a>0),添加权重可减少噪声数据,避免过拟合问题。
其次,为预测偏移问题和克服梯度偏差,Catboost 提出了Ordered Boosting 算法。以决策树为基础,由不包含xi训练集进行训练得到针对xi的子模型Mi,并且使用Mi得到数据集的梯度估计,进而得到最终的分类器。Catboost 算法仅通过极其微小的参数调整甚至使用原有参数就可以获得良好的分类效果,具有很强的稳健性,在文本分类领域有广阔前景。
SVM(Support Vector Machine,支持向量机)是在分类与回归分析中分析数据的监督式学习模型与相关的学习算法[16]。其特点是在保证稀疏性的同时兼顾稳健性,并具有模型泛化能力和小样本学习能力强等特性,适用于文本分类。
基于LDA 模型可以有效避免高维特征矩阵稀疏弱点的情况,但是SVM 算法由于数据复杂会导致选择函数时出现敏感性,而Catboost 算法不仅能有效解决SVM 算法寻求最优区分数据的超平面收敛速度慢的问题,同时可以弥补SVM 分类算法在解决多分类问题上存在的缺陷。
2.3 指标评价
在文本分类问题的研究中,评判分类器性能优劣的常用模型为混淆矩阵,也称可能性表格,是一种呈现分类算法性能的可视化工具,如表1。根据文本样例的真实类别与分类器预测类别划分为TP、FP、TN、FN 四种情形,数据表示该分类中样本的实际数目。其中,TP(True Positive)表示真实为正例且被正确预测为正例的样本数量,FN(False Negative)表示真实为正例但被错误预测为负例的样本数量,FP(False Positive)表示真实为负例但被错误预测为正例的样本数量,TN(True Negative)表示真实为负例且被正确预测为负例的样本数量。

表1 混淆矩阵
混淆矩阵各分类中的一级指标表示分类器对于测试集的基本统计结果,最终以可视化矩阵展示各分类中所包含的样本数量。但如需进一步判断二分类模型性能,仍需在一级指标的基础上进行延伸计算,进而获得模型的准确率(Accuracy),即整体模型的预测精度;预测精确度(Precision)是指已被划分的目标文本集内文本确属该分类的比率;召回率(Recall)指文本分类器对应属于目标文档集内文本正确划分的比率。同时采用F-score 指标对P(精确度)与R(召回率)进行调和平均,进一步提高对于分类器分类效果的要求,如式(6):
本研究涉及多分类任务,将生成n 个二分类混淆矩阵,因此需综合评估整体的分类性能,引入宏平均评价指标(Maro-average)与微平均评价指标(Micro-average),在局部评估单个二分类模型性能的基础上,将F1 值合并综合考察最终模型的分类效果,如式(7):
3 研究框架
本研究通过构建由LDA 模型与集成学习Catboost 算法相融合的文本分类系统,通过具体的文本分类实验来进一步对比分析传统的机器学习算法SVM 与新型集成学习算法Catboost 的分类效率。首先,通过网络爬虫获取数据集,并将其分为训练集和测试集;其次,运用LDA 概率主题模型建模,获得文档在主题上的概率分布;随后,利用训练集提取出的隐含主题文本矩阵进行分类器训练,最终构建融合文本分类系统。该系统分为文本预处理、LDA 建模、训练分类器、文本分类及分类效果评估五个模块,系统设计框架如图3 所示。
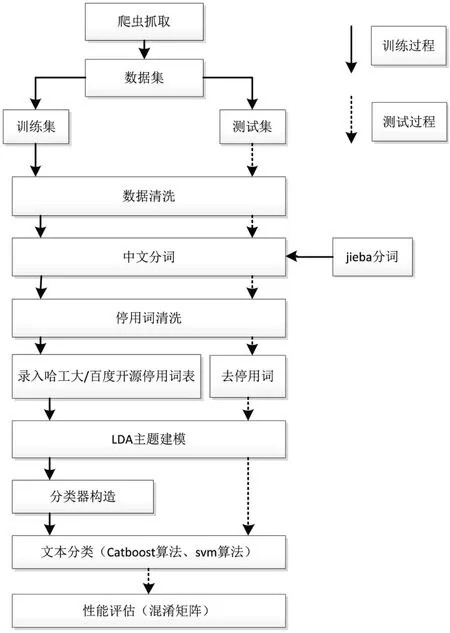
图3 文本分类系统框架
(1)系统文本预处理。由于文献资源格式存在差异,需要将多种格式的数据进行转化,使其成为能够被计算机处理的格式。在此过程中,首先要对所获取的数据进行清洗,对于数据集中所包含的重复文本或无效文本进行筛选,同时剔除对于文本无意义的数据(如标点符号、空格等)以免影响实验效果。其次,在文档处理之后进行分词处理。利用正向最大匹配及CRF 方法相互结合的方法,对文本中的词逐一进行扫描,将各个词语相互匹配,对文本集语料进行切分,形成词的集合。再次,为排除如“一个”“的”“一些”“一天”等导致分类效率低下、系统运行速率降低、对分类效果产生负面影响的无意义词语,系统载入开源停用词表《百度停用词表》、哈尔滨工业大学以及四川大学所提供的停用词表作为过滤停用词的基本词表。同时根据实验过程中的情况进行不断修正,过滤处理停用词。最后将文档分解获得的词列表按照词频进行统计,存储在本地磁盘中。
(2)LDA 建模特征抽取。首先将经预处理的文本集加载到内存,运用LDA 主题模型对训练集文本进行建模,用Gibbs 采样进行参数推理,当迭代足够次数之后,利用困惑度得到最优主题数,此时模型与语料库拟合程度达到最佳。其次,建模生成文档-主题矩阵和主题-词矩阵(训练集)。然后根据训练过的训练集数据对测试集进行模型推断,得到文档-主题矩阵和主题-词矩阵(测试集)。
(3)分类器训练。用上一步得到的训练集文档训练Catboost 算法和SVM 算法文本分类,构造文本分类器。
(4)文本分类模块与性能评估模块。首先加载训练好的分类器,导入文献特征,使用文档-主题矩阵对分类测试集分别进行Catboost 算法和SVM 算法文本分类,并将分类结果序列化到本地磁盘。最终在分类器性能评价模块运用混淆矩阵和相应的评价指标,对得出的结果进行性能评估。
4 实证分析
4.1 数据采集
为构造能够广泛应用于不同类型及来源的语料集合的文本分类器,本文所选取的实验语料集合均来自于公开信息源,包括网页以及学术文献两种不同类型。同时为保证可选取的文本资源类别足以支持实验的开展,本文依照《中国图书馆分类法》(以下称《中图法》)中所划分的文献类别选取语料类别,并且根据网页文本与学术文献资源分类类别的交集来进行实验语料的抽取。
为保证实验能够尽量模拟真实情况下的分类需求,网页文本部分来源于百度新闻,经与《中图法》分类名称进行对比筛选,抽取该语料库中IT、金融、体育三大类作为《中图法》中计算机、经济、体育类别的相似选项。同时在对网页信息进行爬取时,保留文章Url(以判断文章所属类别)、标题、关键字、内容描述等信息,作为网页文本语料集的构成内容。
在学术文献语料中,为保证信息及时性并反映研究热点,本研究选择期刊信息作为学术文献的语料集构成内容。期刊语料信息来源于维普期刊资源网,选取关键词、标题、摘要信息等作为分类样本,以计算机、经济、体育为关键词,按照相关度的疏密情况进行排序,对期刊文献资源进行信息不重复抽取,与网页文本信息共同构成文本分类所需的语料集合,见表2。学术类型文本抽取1214 篇,其中训练集文本数1000 篇,测试集文本数214 篇;网页新闻类型文本抽取1020 篇,其中训练集文本数900 篇,测试集文本数120 篇。且集合的交集均为空。

表2 维普学术期刊资源与网页百度新闻数据集
4.2 LDA 主题建模
利用基于Python 实现的网络爬虫对百度新闻网页以及维普学术期刊资源网站分别进行数据爬取,构建语料集合,为实验结果的普适性提供数据基础。在数据预清洗阶段,文本集使用jieba 开源中文分词工具进行分词,该工具能够实现较为精确的语料句子切分。进行中文分词之后,为减少高频率出现的无意义词汇对于分类结果的影响,本研究系统载入百度、哈尔滨工业大学以及四川大学提供的开源停用词表进行停用词过滤,对切分好的词表进行储存。以下实验过程均以学术语料集为例进行展示。
采用LDA 概率主题模型对语料库进行主题建模,使用困惑度确定最优主题数,在不同主题数下进行Gibbs 运算得到困惑度变化曲线如图4 所示。可确定当特征数目为6 时,模型拟合效果最好,因此后续实验的主题数K 设置为6。

图4 学术语料集困惑度值
在用Gibbs 抽样确定LDA 模型参数时,根据经验,令α= 50/K,β= 0.01,K 值取6。Gibbs 算法迭代1000 次得到在6 个不同主题上的文档概率混合分布结果,生成文档集的隐含主题-文档矩阵,部分数据如表3 所示。
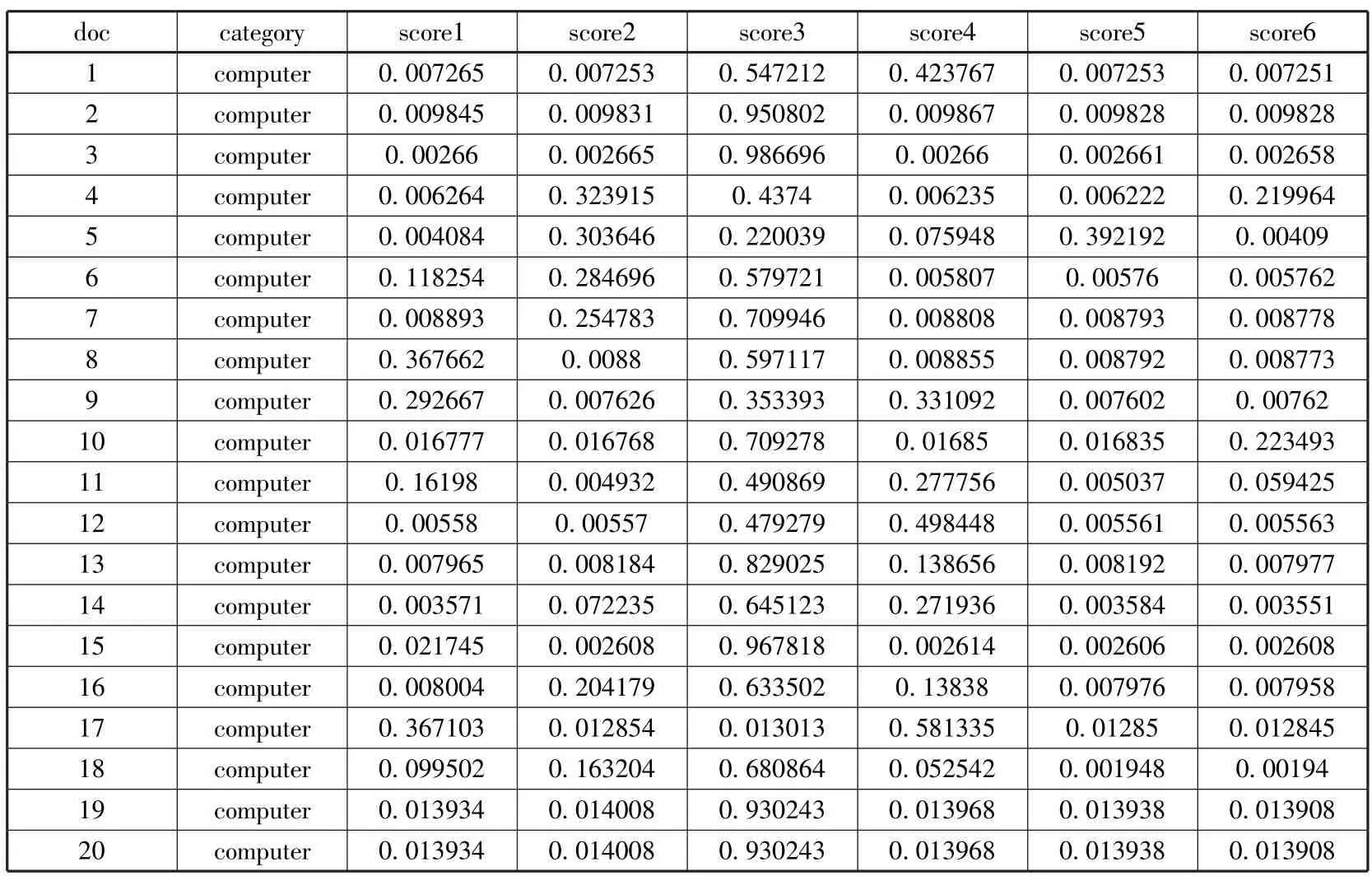
表3 文本集的隐含主题-文本矩阵数据(部分)
4.3 分类预测
为比较传统的机器学习算法SVM 与新型集成学习算法Catboost 对于文本分类性能的差异,使用训练集来训练分类器利用LDA 概率主题模型进行特征选择后所生成的主题-文本矩阵,并根据相同测试集的预测分类效果进行最终的分类器性能评估,以对比两种不同算法的文本分类效果。本实验选取Python 作为Catboost 与SVM的实验环境。
将表3 中训练集的数据分别输入Catboost 与SVM 进行建模,在Python 环境下进行训练,并通过测试集对模型进行测试,结果分别见图5、图6。
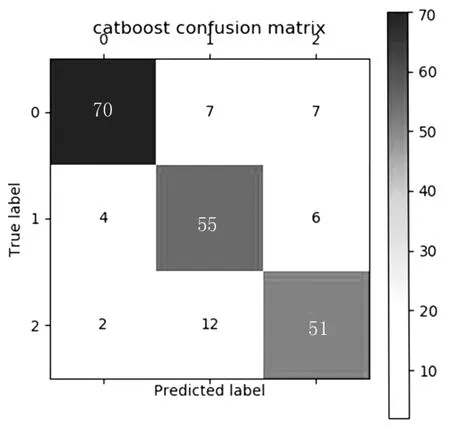
图5 Catboost 测试样本预测结果
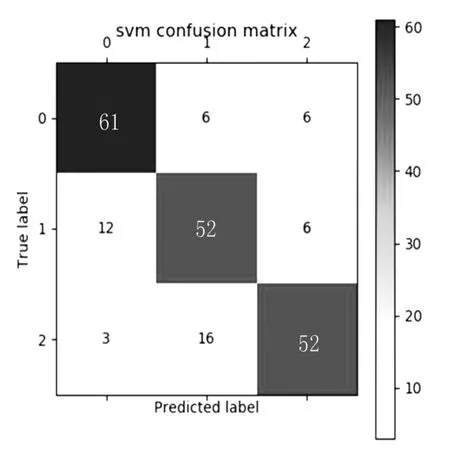
图6 SVM 测试样本预测结果
4.4 模型评价
由图5、图6 可知,对于学术语料测试集的214 个测试样本,Catboost 分类器正确预测了0 类(计算机)76 个样本中属于此类的文本数量为70;1 类(经济)74 个样本中属于此类的文本数量为55;2 类(体育)64 个样本中属于此类的文本数量为51。而SVM 分类器正确预测了0 类(计算机)76 个样本中属于此类的文本数量为61;1 类(经济)74 个样本中属于此类的文本数量为52;2类(体育)64 个样本中属于此类的文本数量为52。根据式(6)评估标准计算单独二分类模型的评估指标,如图7、图8 所示。根据式(7)评估标准综合计算两种分类模型的评估指标见表4。

表4 学术文本测试集上两种分类方法的综合比较
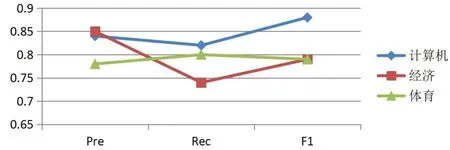
图7 Catboost 学术文本测试集三类文本评估指标
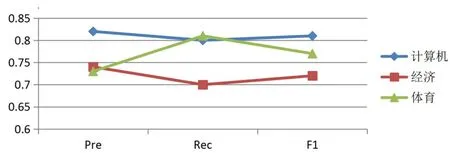
图8 SVM 学术文本测试集三类文本评估指标
按照相同的流程,在网页新闻语料集所划分出的测试集上对两种分类器分别进行测试,计算得出两者的综合评估指标如表5 所示。

表5 网页新闻测试集上两种分类方法的综合比较
当K=6 时,在LDA 模型抽取出的学术文本的隐含主题-文档矩阵(训练集)上分别训练构建LDA+Catboost 与LDA+SVM 分类器,并通过测试集对其进行分类预测。然后利用评估指标对Catboost 算法在经过LDA 特征提取后构建分类器的分类性能与SVM 算法在经过相同处理后所构建的分类器进行对比,发现在文本集中各小类上的分类结果评估前者普遍高于后者,证明Catboost算法在局部构架单独二分类模型时具备良好的稳定性与优于SVM 算法的分类性能。同时在综合评估两者分类性能阶段,Catboost 算法的综合分类准确度(Acc)、Macro-F1 以及Micro-F1 在学术文本与网页文本的测试集上分别平均达到82%与80%,均高于SVM 分类算法在两种文本测试集上达到的77%与65%,表明LDA+Catboost 分类器模型在文本分类上取得的效果更好。
5 结论
本研究以维普学术期刊资源与网页百度新闻作为基础语料集,使用LDA 模型进行文本集特征抽取,实现高维文本的降维。在此基础上分别应用新型集成学习算法Catboost 与文本分类领域经典分类算法SVM 构建分类器,对二者的分类效果进行比较,以研究Catboost 在文本分类领域的应用前景。实验表明,在LDA 作为文本表示方法的模型环境中,在不影响分类效率的前提下,Catboost 算法最终呈现的分类效果较SVM 而言,精度与准确度都得到了提升,并且以其本身所具备的稳健性和多类别特征均适用的优点,在文本分类领域是一种能够提高文本分类性能与保证分类效率的实用性算法。然而,由于现行语料库规模有限,训练模型仍存在改进空间。未来构建范围更广的语料库后,小样本的特征词存在散落于大样本分类中的风险,可能导致较小语料的分类出现偏差。因此,在后续研究中将持续推进对适用规模更大的语料库的文本分类模型的优化。
猜你喜欢
电子测试(2018年1期)2018-04-18
海外华文教育(2016年1期)2017-01-20
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
新校长(2016年8期)2016-01-10
当代教育理论与实践(2015年9期)2015-12-16
民族古籍研究(2014年0期)2014-10-27
商事法论集(2014年1期)2014-06-27
外语教学理论与实践(2014年2期)2014-06-21
电测与仪表(2014年15期)2014-04-04
