
基于DMD-Xgboost电商概念股的交易量化预测算法
2023-12-20 03:18童珺仪
哈尔滨商业大学学报(自然科学版) 2023年6期
童 珺 仪
(北京邮电大学 理学院,北京 100876)
随着大数据时代的发展,人们更倾向于用数据去解释一些规律事件,比如用户画像分析预测,股市预测,产品销售量预测等等,从而达到数字化分析预警,有助于使用者群体实现更加合理化的决策.鉴于此,学者们在定量预测运算的基础上,衍生出一系列的预测模型.如处理时间序列模型的季节平滑、Hole现象趋势模型、ARIMA模型等;利用机器学习的决策树模型、支持向量机(SVM)模型、长短时记忆网络(LSTM)等;基于统计学框架的方差分析(ANOVA)、假设检验、回归分析等.模型输出结果将作为预测的直接依据,因此模型的准确度十分重要.然而对于大多数现实意义数据,其内在规律十分隐蔽,并非任意的预测模型都能给出较高的精确度,受因素影响多、敏感性高的数据预测就成为一大难点.本文就复杂的股市数据进行预测分析,并以此为高维非线性敏感树的处理提供新思路.
2021年,伴随着基金市场的巨大波动,人们对于投资市场态度愈加两极分化,相较于传统“望闻问切”的投资方式,人们更倾向于量化投资,寻求以最低的风险获得最大的收益.而股市本身具有波动性和强随机性,所以在收益预测方面,经济学家们一直在尝试.目前也已有大量研究从不同角度出发,在传统经济学领域和计算机科学领域的基础上展开探讨.
在传统经济学领域上,1970年Eugene Fama[1]提出“有效市场假说”(Efficient Markets Hypothesis),该假说认为,任何投资者均为理性经济人,其决策经过一定的思考,在有效市场的前提下,每只股票的市场价格都反映了已经发生或者尚未发生但是预期会发生的事情.这一假说也成为资本市场不断提高有效性的起点.2000年徐嫩霞等[2]利用经济序参量和经济预测建立了“智能股票预测系统”.2003年Dennis Olson 等[3]将会计比率因素作为输入变量,利用普通最小二乘和Logistics回归技术得到了较好的收益预测效果.2009年Wei L等[4]提出GARCH方法改进了传统计量经济学模型,使之产生更加准确的样本外预测.2011年,李竹薇[5]通过对中国证券投资者的交易策略、交易行为和预测能力进行分析,填补了国内在该研究领域的空白.
在计算机领域,2008年王莎[6]通过改进后的BP神经网络对股市进行预测,并取得较好的仿真性能.2010年王文波等[7]通过EMD和神经网络的结合提高了预测精度.2016年吴玉霞等[8]发现移动平均自回归模型对于短期静态股价预测有较好的效果.2016年张贵生等[9]分析了传统线性模型解决非线性模型的不足,通过近邻互信息的方式融合了与目标股指数据关系密切的周边证券市场的相关变化信息.2018年韩山杰等[10]将Tensorflow应用于股票预测中,将深度学习和股票预测结合.与此同时,学者们也逐渐意识到人为主观因素对股票市场的作用.2013年祝宇[11]利用文本挖掘技术提取网络信息中体现的投资者情绪特征,并以此研究网络信息与股票市场的关联机制.2016年石兆伟[12]利用股吧中投资者的情绪信号作为辅助,从而预测股票未来趋势.2019年吴璇等[13]分析了上市公司财务报告对投资者的投资决策产生的影响.
综合以上文献,目前的研究过程中缺乏根据市场特点对数据指标内在关联的挖掘以及高维非线性数据特点,只是笼统地将数据集与主客观因素衔接且研究多针对单一股,应用范围受限,本文创新性地采用学科交融的方式,从非线性时间序列数据特点考虑,设计了一套利用针对一簇概念股的非线性复杂动力系统模型DMD特征分解,再融合机器学习Xgboost的股价预测算法.动力学模态分解(DMD,Dynamic Mode Decomposition)是实现Koopman分析的一类常用算法.特别是针对大量高维数据,其优良的降维分析能力使得DMD算法被广泛应用于非线性测量数据的分析预测.尽管算法被提出在“动力系统”领域,但学者们逐渐将其运用在各类问题中并取得重大突破.2015年张青山[14]提出在DMD算法进行旋涡动力学分析,2016年寇家庆等[15]人提出了跨声速抖振的DMD模态分析,2017年叶坤等[16]人利用DMD方法负圆柱绕流进行稳定性分析.2016年Jia-Chen Hua等[17]人利用Koopman模式分析解释了股票市场的四个未知的周期变化. 2020年史建楠等[18]人将DMD模型与长短期记忆神经网络(LSTM)融合,针对特定唯一股票实现更高的价格预测精度.Xgboost(Extreme Gradient Boost)算法是一种集成学习算法,2019年[19]史佳琪等人实证证明了多模型融合的集成学习具有更高地预测效果.2020年陈振宇[20]等人对沪深300股指期货1分钟高频数据进行研究发现处理经济数据时,Xgboost预测能力优于传统的神经网络.
实证中,本文选择了2019年9月1日~2021年9月1日期间电子商务平台概念股日交易数据.近些年来,电子商务的普及吸引了大量学者的注意力,2013年黄海龙[21]研究了电商平台的形成背景分析并总结了互联网的金融模式,2014年徐洁[22]等人分析了互联网金融和新型融资之间的重要联系,2014年王达[23]从网格经济学视角对中美互联网金融进行比对并提出深入研究电子商务的意义,2015年张江洋[24]等人探索了电子商务金融模式的特殊交易市场,2017年邵弘强[25]分析了电子商务对特定领域的对策研究,2019年刘航[26]等人基于数字经济的健康发展详细阐述了电商互联网与数字经济的重要理论分析并提出一系列政策建议.电子商务的重视程度愈来愈高,由此本文为研究结果的普适性和合理性,引入电商概念股,以一类数据的形式进行实证研究,并提出合理化建议.
本文创新点为:1)对一类数据进行归纳总结,通过学科交融模型的优势,消除了量化交易中人为因素的干预,使得机器学习模型得到最好效果;2)通过模型验证,可以有效地挖掘股票市场信息,这对量化投资的技术预测提供了新思路,也为非线性高维数据的预测模型提供改进方案;3)将电商与大数据时代相连接,利用技术手段对庞大数据集进行专业化处理,凸显价值规律,对行业发展和社会信息化建设提供有力支撑.
1 相关概念及方法
本文将基于DMD模型和Xgboost的融合对近三年电商领域股市进行分析预测并提出一种新型时间序列量化交易模型.
1.1 特征分解模型—DMD
DMD算法是基于Koopman算子的特征分解算法,其主要功能是针对非线性时间序列数据,创新地将基于时间的功率谱分析和基于空间的主成分分析合二为一,最终产出系统当前时刻的重构数据以及未来时态的预测数据.设x1,x2,…,xM是原始数据中M个时间序列截面数据,每个时间序列截面数据包含N个样本,记N×M矩阵X=[x1,x2,x3,…,xM]为数据集X.在Koopman算子的影响下,存在矩阵A使得系统下一时刻数据和上一时刻的数据产生关联,也就是xt+1=A·xt,受到Krylov的思想启发,将原始数据写成如下形式:
(1)
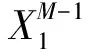
1.2 机器学习模型—Xgboost
2016年陈天奇[29]提出了Xgboost算法,从而开启智能化学习时代,相比于传统的梯度提升树,Xgboost具有如下优点:1)支持自定义代价函数,可被展开至二阶使得更多的信息得到保留;2)L2正则化的引入可以降低模型的复杂性,避免过拟合;3)借鉴随机森林中列抽样的优势,在减少计算量方面更胜一筹;4)在缺失值处理上有自己独特的划分,减少了数据预处理工作量;5)支持多线程并行;6)高速缓存压缩算法和每轮迭代交叉验证的加入提升了模型的效率.
利用上一节的DMD模型进行特征分解并重构原数据,直至重构数据的|D2-D|近似为时认为e-6重构数据具有代表性,由此得到具有价值的影响指标,并将处理后数据列入Xgboost模型进行运算.
具体设计原理如下:
Step 1:构建目标函数
(2)
(3)
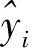
由于模型采用加法训练,即t时刻的预测=t-1时刻的预测+t时刻的函数值,公式为
(4)
Step 2:利用泰勒展示求近似值
Ω(ft)
(5)
Step 3:重新定义树
用叶子得分定义树,每个样本落在一个叶子结点上,qx表示样本x在某一个叶子结点上,则该节点得分为
ft(x)=Wq(x)
(6)
Step 4:更新目标函数
用每一个叶子节点得分重新组合目标,记Ij={i|q(xi)=j}得到
(7)
(8)
计算最优函数值
(9)
2 模型设计
2.1 数据的收集
1)电商平台下的概念股.概念股表示的是一类具有很强的投资者共识和广告效应的股票集合,本文设计了电商平台下的概念股系统,包括电商、电子支付、物流三类关键词并进一步细分从而界定所涉及的概念行业.自2019年以来,电商平台随着“线上消费”升级转型,也迎来了自己的挑战与机遇,其中“直播电商”进入爆发期.
2)数据来源.因此本文选取国泰安CSMAR 2019年9月1日~2021年9月1日期间电商平台概念股日交易数据,剔除缺失数据及ST企业.保证了数据的真实性、有效性和完整性.
2.2 DMD特征提取
DMD算法能应用于股票系统,主要是由于股票系统存在的复杂性和高维离散非线性性质,Koopman方法能够将非线性系统升为到一个线性维度空间下,在保证不会损失信息的前提下,对该复杂系统进行全局线性化.DMD算法作为目前应用最广泛的Koopman算子的近似算法,能够捕捉股市价格变化的模态特征和潜在行为模式.
2.3 Xgboost模型预测
由于DMD算法需要更具实际情况人为选择基函数,模型的结果很容易受到主观因素的限制,故单一使用DMD算法缺乏客观依据.故本文选择在DMD算法提取特征后,利用更为精确的Xgboost模型,避免了人为因素的干扰,使得结果更加具有说服性.
2.4 评价指标体系建立
对预测效果进行度量的时候本文选取均方根误差(Root Mean Square Error,RMSE)、平均绝对误差(Mean Absolute Error,MAE)作为衡量标准,RMSE为均方误差的平方根,MAE描述观测值与真实值误差绝对值的平均数,当RMSE数值较小时,模型的精确度较高,但是RMSE受异常值影响明显,所以辅以MAE值,保证预测更准确.
其公式如下:
(10)
(11)
3 实验及结果分析
本文对电商概念股所收集的指标数据进行分析预测,首先针对每个指标提取DMD特征,在模态分解完成后可以获取概念股系统中的动态模态,以特征值uk表示.uk分解对应股票市场模态下包含信息的多少,由此在DMD分解当中得到的第一个特征值u1起到决定性作用,称为决定特征,其包括了绝大多数的模态信息.
本文利用Matlab将特征值画在单位圆区域上,当特征值落在单位圆外部时,表示该指标有日益显著趋势,反之,如果特征值落在单位圆内部时,表示该指标的影响力越来越低.此外,有部分特征值存在没有虚部的情况,此时这类指标的变化是较为显著的,也是股票市场的变化主要因素.本文为了进一步研究DMD-Xgboost方法的应用效果,配合计算需求,将电商概念股数据集分为训练集、测试集和验证集.实验结果处理如下:
在处理器中DMD分解得到特征阶段,得到如下变化规律,决定模态总体围绕0进行波动,当数值超过0或者低于0时意味着该指标具有不稳定性.
图1为特征值傅里叶变换值在复平面中的数值分布图,图1中横坐标为特征值实数部分,纵坐标表示特征值虚数部分,横坐标为正数时表示该指标呈现上升趋势,当横坐标为负数时呈现下降趋势;纵坐标绝对值越大表示波动情况越明显,纵坐标绝对值越小表示指标越稳定.接着本文利用直方图展示波动规律,特征值虚部在0~1之间的约20个;虚部在1~2之间的约23个;虚部在2~3之间的约20个;虚部在3~4之间的约3个.这表示多数指标呈现为弱波动态或趋于稳定态,而发生明显波动的少于全体的5%,符合股票交易市场普遍情况和筛选指标的影响力作用条件.由此我们可以找到波动频繁的指标进行重点分析并重构历史数据,从而找到内在规律.
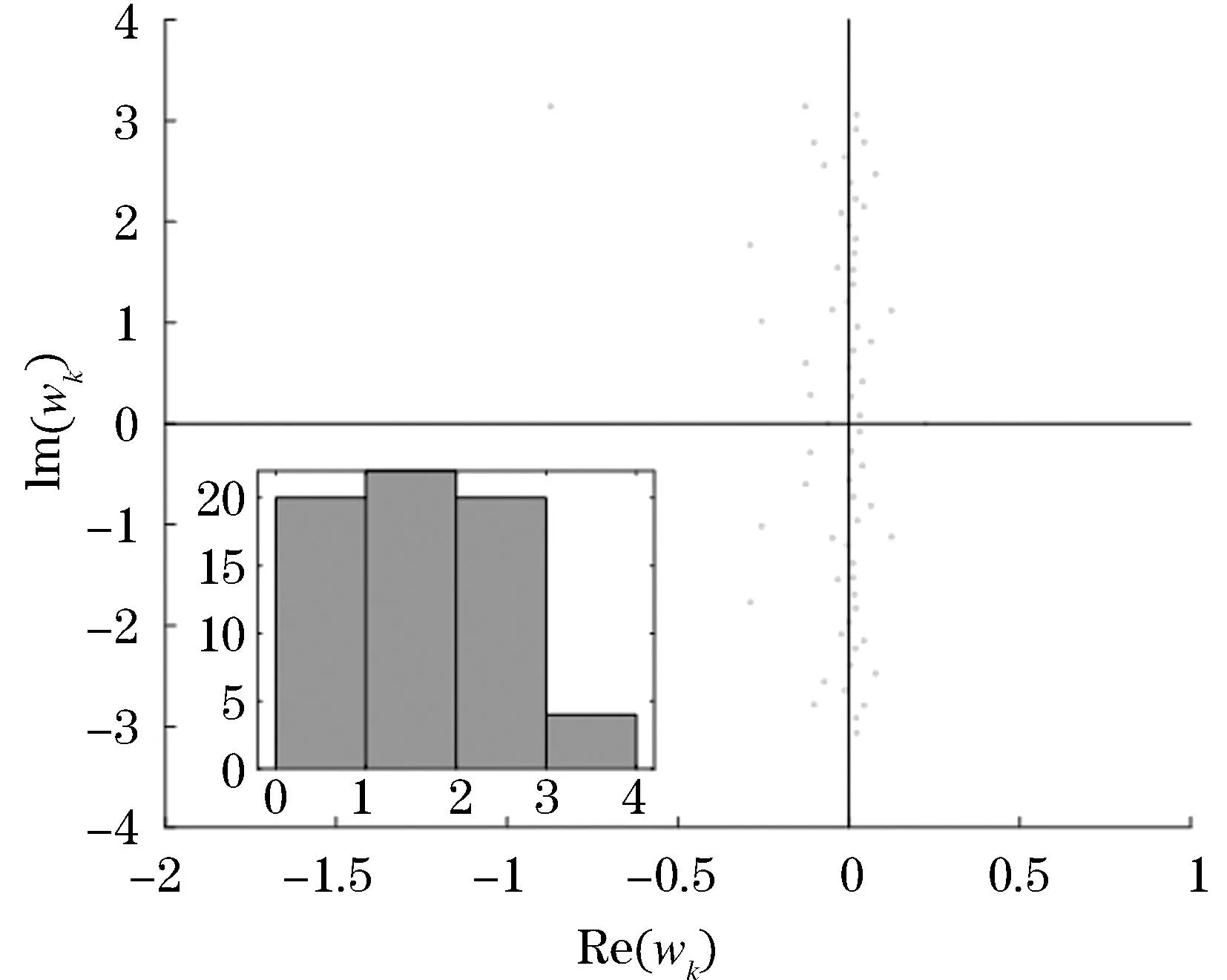
图1 特征值数值分布图(增长率-频率)Figure 1 Distribution of eigenvalue values (growth rate-frequency)
下面以归一化的000150为例,展示本文算法的预测过程.
Step 1:利用DMD模型进行特征分解并重构原数据,直至重构数据的|D2-D|近似为e-6时认为重构数据具有代表性,由此得到影响指标.
由图2可以看出,图中特征值的复平面分布圆上基本呈现为上下对称,符合特征值共轭对称的性质.其中分布圆内的点显示收敛状态,表示随着时间的演变,其影响力在不断减小,而分布在圆外的点起影响力在不断增加.特殊地,在Lm(wt3)=Lm(wt6)=Lm(wt593)=Lm(wt645)=Lm(wt707)=0,这些点分布在复平面圆的横向对称轴上,分别对应了两个收敛态,一个平稳态和两个增加态.
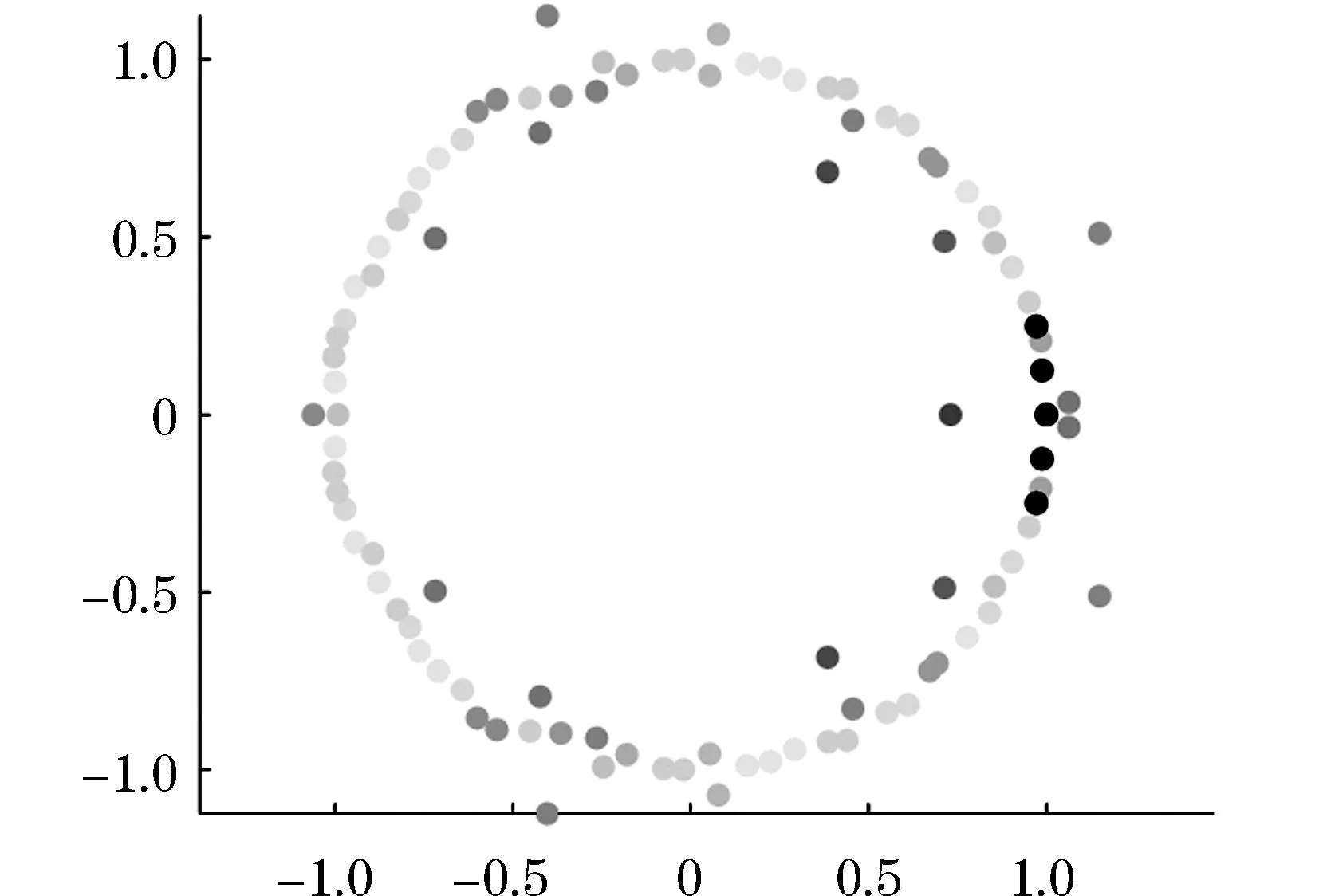
图2 矩阵A的特征根分布复平面圆Figure 2 Complex plane circle of eigenroot distribution of matrix A
图3展示各个模态的形态以及在利用DMD方法得到的非线性数据混合信号分离展示.
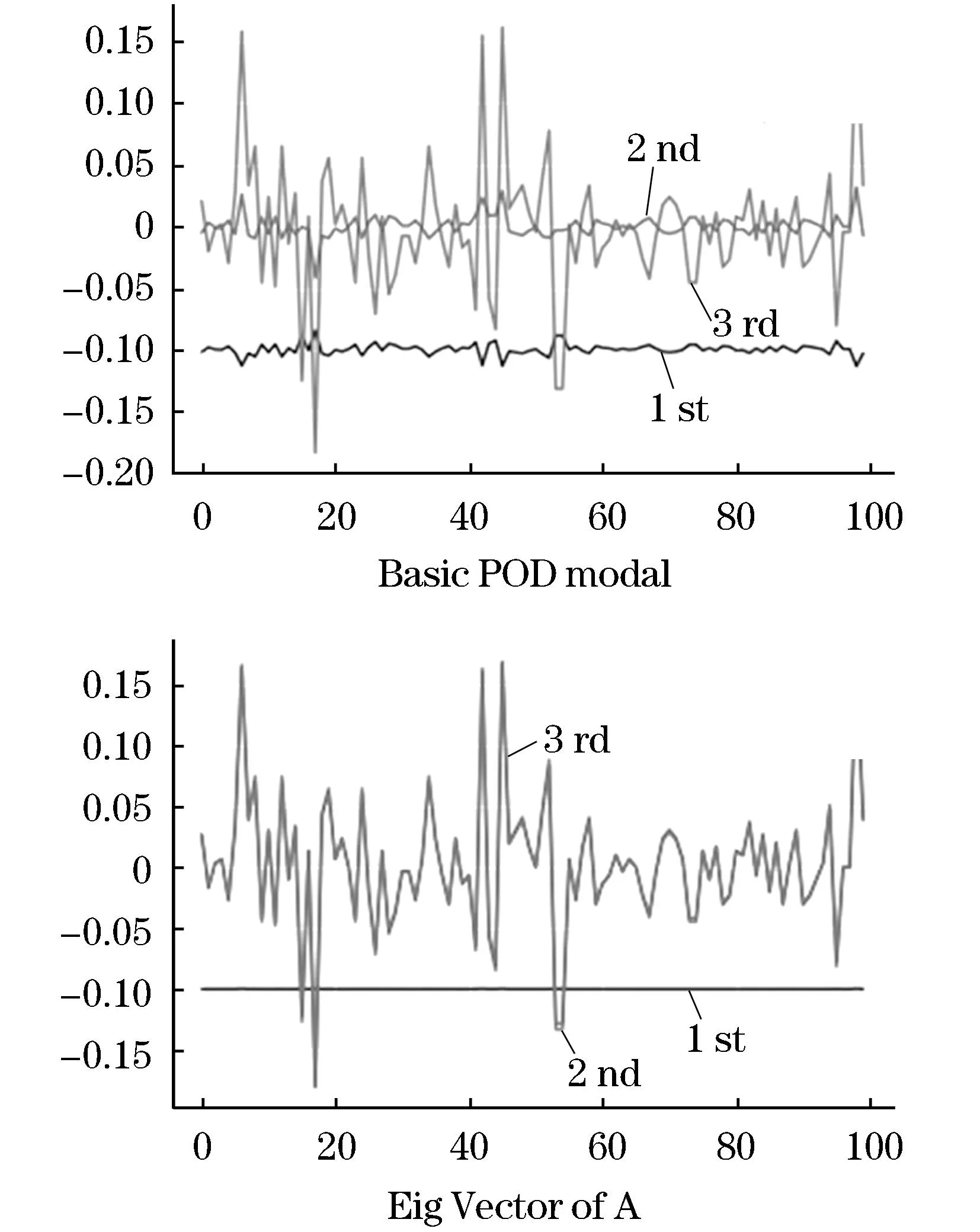
图3 模态分布图Figure 3 Modal distribution diagram
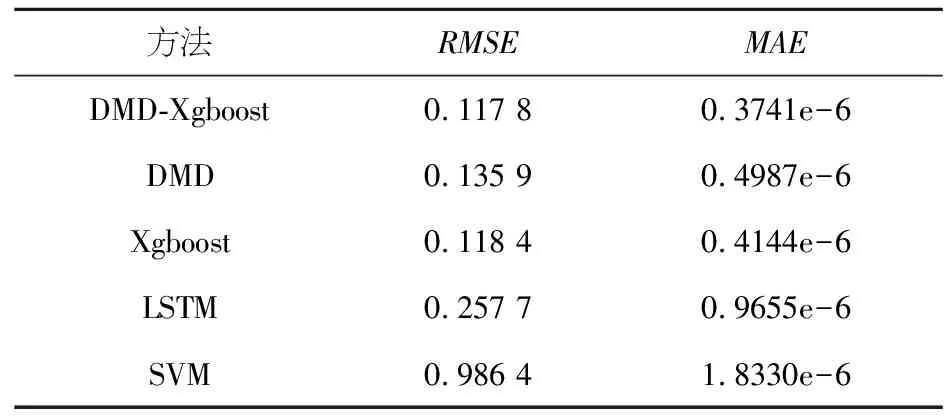
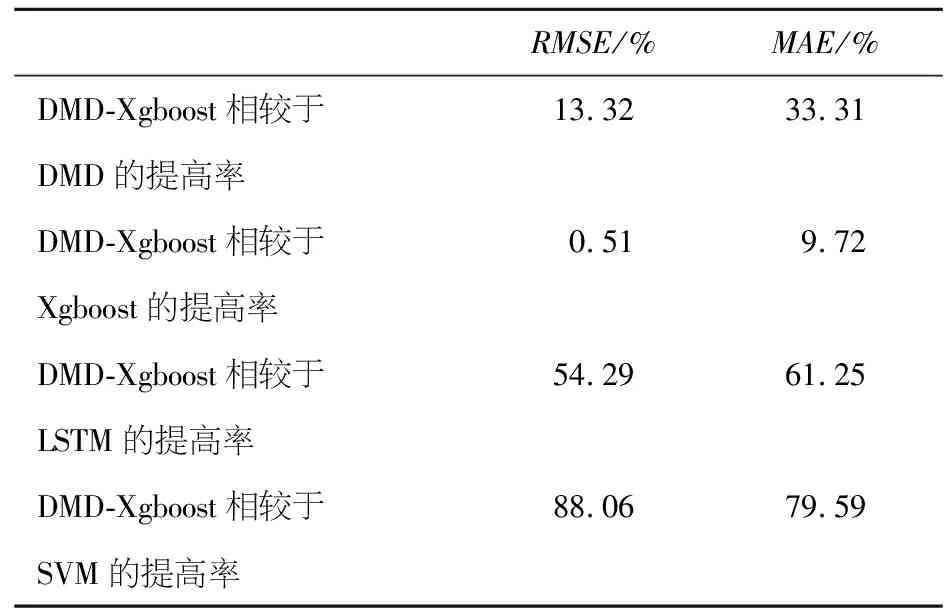
通过对比发现,原始数据模态还原程度较好,在一定程度上三种模态进行概括,为下面Xgboost方法的使用提供了降维铺垫.由于随机高频噪声的加入,在细节中看出与原始数据存在微小差异,由此计算偏差热力图,数据符合|D2-D| Step 2:利用Xgboost对概念股数据进行预测 首先将数据集按照60%、20%、20%的比例拆分为训练集、测试集、验证集.通过训练,将模型回测检验得到RMSE值为0.053 187 061 806 792 86. 通过计算RMSE对实验结果的合理性进行评估,其值越小表示模型越精确,拟合效果越好,本文试验得到结果为RMSE=0.117 176 517 115 127 64,具有可信度.见图4. 图4 模型回测及预测图Figure 4 Model backtest and prediction graph Step 3:实验对比与分析 本文在电商概念股中,比对本文融合模型实验结果、单一DMD结果、单一Xgboost结果、常规常用方法的预测准确率如表1、2所示. 表1 DMD-Xgboost方法与其他机器学习方法预测效果比较Table 1 Comparison of prediction effectiveness between DMD-Xgboost method and other machine learning methods 表2 DMD-Xgboost方法对比其他机器学习方法提高率Table 2 Improvement rate of DMD-Xgboost method compared with other machine learning methods 由此可见,本文方法的预测结果较其他机器学习方法均有一定程度提升. 数据预测模型主要是根据提供的数据进行预测得到不同的结果,再通过不同的结果进行决策,如何合理运用机器学习相关知识加以创新去解决金融数据的分析预测以及提供金融投资领域的决策建议,是最近几年学者们广为热议和积极研讨的问题.本文选择将电商平台数据整理为概念股,运用DMD和Xgboost的方法对电商概念股数据进行分析和预测,并且系统地比较了这些算法的分别预测效果和融合模型的预测效果,最后将结果和单一DMD、单一Xgboost以及相关传统机器学习算法进行对比,凸显了融合模型具有更好的预测能力,由此得出以下结论: 1) 从数据上分析,改变了以往从宏观上处理数据忽视数据内部规律的弊端,从金融数据本身规律入手,引入概念股并对这一类股票数据进行模态分析,用DMD算法消除量化交易中人为因素的主观性,通过将Ritz特征值判断模型的趋势,从而找出最具影响力的指标,作为Xgboost模型的输入指标,避免了机器学习对非线性市场信息的不敏感性. 2)从模型上对比,五种方法的对比预测结果通过建立的评价指标体系体现,可以明显看出,融合模型的预测效果优于其他方法,强有力地证明了DMD-Xgboost方法在金融数据分析及金融投资领域的有效性. 3)由于股票市场的复杂非线性,很多信息的累计都没有达到阈值的时候,很难使得机器学习模型对其做出反馈,这就导致资产价格预测产生有偏估计和截断误差,所以在数据选择上本文选择一类数据簇去构造特征工程,避免了单一股的隐形趋势被忽略.与此同时,相较于传统的模型加权融合,本文选择对每个模型各取所长,实现预测结果的突破. 4)随着大数据时代的融合革新,电子商务潮的推进也逐渐技术化和专业化,相较于传统模式,大数据技术可以帮助人们收集更加全面完整且有效的信息,做出更加合理的决策.面对如今电子商务大数据化愈加强烈的趋势,有效数据的提取往往受到数据量的限制,如何在更少数据中更加敏锐且及时地提取更有效的信息以及如何寻找最佳投资周期值得下一步重点研究.研究电商平台股市趋势也有助于扩大人的自主选择权、拓展“产业网络”以及满足了不同人群的价值需求,为推进“互联网+”的国家行动计划,促进电商和其他行业的融合创造良好的社会环境.通过本文的模型分析,可以对现阶段的网络电商提出合理化建议.首先是做好数字化资源的收集和整理,便于更广泛人群了解并深入;其次是降低电商“距离感”,增加产品丰富度;最后是要引入深度学习技术,精准定位,满足用户个性化和动态化的需求.
4 结 语
猜你喜欢
今日农业(2022年16期)2022-11-09
数学物理学报(2021年5期)2021-11-19
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
大众投资指南(2020年10期)2020-07-24
现代企业文化(2018年13期)2018-06-09
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
东北电力大学学报(2015年1期)2015-11-13
上海电机学院学报(2015年4期)2015-02-28
机电信息(2015年28期)2015-02-27
四川轻化工大学学报(自然科学版)(2014年3期)2014-04-16
