
基于关键帧和注意力残差网络的手语识别
2023-12-16 10:30:08刘群坡盛月琴高如新卜旭辉
计算机工程 2023年12期
刘群坡,盛月琴,高如新,卜旭辉
(1.河南理工大学 电气工程与自动化学院,河南 焦作 454003;2.河南省智能装备直驱技术与控制国际联合实验室,河南 焦作 454003)
0 概述
手语是聋哑人用来与外界接触的重要工具,手语识别研究对于提高聋哑人生活质量有着重要意义。手语演示者的手部动作在整个视频画面中仅占有小部分区域,且视频数据具有时序性,因此如何有效提取空间特征和时间特征对于提高识别率具有重要作用。此外,地区文化的差异和个人习惯的不同使得具有相同含义的手语却有着不同的表达方式,考验模型的泛化能力[1]。针对以上问题,研究人员提出了许多解决方案,分为基于传统方法和基于深度学习的手语识别两大类。
在传统方法中,主要使用隐马尔可夫模型(Hidden Markov Model,HMM)、动态时间规整和条件随机场来人工提取特征。PU 等[2]构造一种基于形状上下文的轨迹描述符,进而提出一种基于HMM的轨迹建模方法来进行孤立词汇手语识别。WANG等[3]基于深度视频数据,提出一种稀疏观察方法来表示每个手势,将手语词汇之间的匹配转换为对齐稀疏观察序列之间的相似度计算,与传统HMM 方法相比,精度更高、耗时更短。然而,传统方法主要通过人工设计并提取特征,无法捕捉到手语视频中复杂的深层特征,识别精度不高。由于深度学习在图像分类[4]、目标检测[5]与识别[6]等领域表现出显著优势,基于深度学习的手语识别方法正成为研究的热点。长短期记忆网络能够很好地处理时序信息,因此被一些研究者用来处理视频数据[7]。LIU 等[8]将手语演示过程中左右手和左右肘关节的轨迹数据作为输入,提出基于长短期记忆网络的端到端手语识别方法,但是骨骼关节点数据需要用特定设备获取,基于机器视觉的识别方法在数据获取方面优势显著,普通摄像设备即可实现数据采集[9]。三维卷积神经网络[10]能够同时获取空间和时间信息,近年来被广泛应用于视频处理。王粉花等[11]提出一种融合I3D 和注意力机制的网络CBAM-I3D,识别率达到了90.76%。ZHOU 等[12]设计一种(3+2+1)D 残差网络进行手语识别,该方法采用直方图、关节点和RGB 图像3 种模态的数据进行手语识别,数据提取过程复杂。上述方法通过改进网络结构,增加通道注意力或空间注意力来提升识别率,忽略了通道和空间之间存在相互影响的问题。此外,现有方法大多随机选取一定数量的帧、均匀采样视频帧或将所有手语视频帧作为网络输入,这也是识别率不高的原因之一。
针对以上问题,本文通过设计一种关键帧提取算法以及改进的3D-ResNet 提升手语识别准确率。利用关键帧提取算法提取作为神经网络输入的关键帧,基于3D-ResNet[13]设计小卷积模块充分提取浅层特征,结合池化卷积残差连接方式增强对细节特征的提取能力,同时设计交互式四重注意力模块嵌入3D-ResNet,增强对背景以及手语者无关信息的抗干扰能力,从而提高模型泛化性能。
1 基于关键帧和注意力残差网络的手语识别方法
基于关键帧和注意力残差网络的手语识别方法整体框架如图1 所示。首先对输入的手语视频运用光流法确定候选关键帧,接着利用基于图像相似度和模糊程度的关键帧提取算法从候选关键帧中提取出最终的若干关键帧,最后将关键帧序列送入交互式四重注意力三维卷积残差网络进行识别分类。

图1 基于关键帧和注意力残差网络的手语识别方法整体框架Fig.1 Overall framework of sign language recognition method based on keyframe and attention residual network
1.1 关键帧提取
1.1.1 基于光流法的候选关键帧确定
在手语视频中,视频开始和结尾部分为演示者的抬手和放手过程,对于整个视频所代表的含义几乎没有任何意义,反而加重了模型训练的负担,候选关键帧位于视频中间部分。因此,利用Farneback 光流法[14]确定每个手语视频的关键帧时间段,主要步骤如下:
1)使用Farneback 光流计算每帧的运动速度并归一化得到vi。
2)设定初始阈值c,若在vi大于c区间内,第一个极大值对应帧Ff和最后一个极大值对应帧Fl之间的帧个数大于等于L,则这两个极大值点之间的时间段为候选关键帧的时间段T。
3)若小于L则阈值c除以2 再进行判断,直到个数大于等于L,那么此时该区间的第一个极大值对应帧和最后一个极大值对应帧之间的时间段为候选关键帧时间段T。
1.1.2 基于相似度和模糊程度的关键帧提取算法
在确定时间段T后,T内的图像序列仍然过多,相邻图像内容变化幅度小,部分视频中手部速度过快导致提取的图像帧出现模糊,因此提出基于图像相似度和模糊程度的关键帧提取算法,用于提取最终的L个关键帧,流程如图2 所示。

图2 关键帧提取流程Fig.2 Procedure of keyframe extraction
首先将T均匀分为L段,将T前1 帧作为第1 个参考帧R1,第1 段t1中的每1 帧 和R1的欧氏距离如下:
其中:xij表示t1时间内第i帧的第j个像素值;xRj表示t1的参考帧的第j个像素值;N表示像素点个数;Di表示t1的第i帧和R1的欧氏距离,距离越远意味着相似度越低。
对相似度序列进行排序,得到欧氏距离递增的新序列{Dr,1 ≤r≤n}。然后利用准则函数将n帧分割成两类:一类是前k帧,可视为与参考帧相似的帧;另一类是后n-k帧,可视为与参考帧不相似的帧。由于分割结果应使类间的均方误差最大,类内的均方误差最小,因此采用式(2)作为确定分割点的准则函数:
其中:m1和m2表示前k帧和后n-k帧的相似度的均值;σ1和σ2表示前k帧和后n-k帧的相似度的标准差。最佳分割点k*应使得此时的准则函数值大于其他分割点计算出的准则函数值,即:
在确定分割点k*后,最终关键帧位于后n-k*帧内,由于其中存在模糊帧,因此对后n-k*帧使用Laplacian 算子计算每帧的模糊程度,选择模糊程度最低的一帧作为当前时间段的关键帧,同时作为下一个时间段的参考帧。下一个时间段的关键帧选取按上述方法操作,最终提取出能够代表该视频内容的L个关键帧作为神经网络的输入。
1.2 交互式四重注意力残差网络设计
1.2.1 基于ResNet 和Inception 的小卷积模块设计
Inception[15]的主要思想是堆叠多个小卷积层,并在特征维度上将它们拼接到一起,通过增加网络宽度来提高网络的特征提取能力。ResNet[16]通过残差连接结构在一定程度上保留了主干网络层传递信息过程中损失的部分输入信息。3D-ResNet 网络的第一个卷积层的核大小为7×7×7,大卷积核提取的是粗粒度特征,而手语视频中手部动作的细粒度特征是识别手语的关键信息。本文结合Inception 和ResNet 的思想,设计一种基于残差结构的小卷积模块,用来替代第一层大卷积层,增强浅层网络对输入数据的细节特征提取能力,结构如图3 所示。
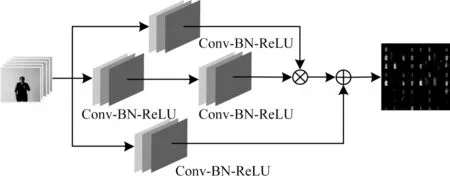
图3 小卷积模块Fig.3 Small convolution module
Inception 结构中使用不同大小的卷积核进行不同尺度特征的融合,但手语数据集中演示者的手部动作在图像中所占的区域较小,因此小卷积模块使用3×3×3 的小卷积核。该模块由3 条支路组成。在通常情况下,Inception 模块的主分支输出通道维度相同,因此小卷积模块的两条主分支输出通道维度也相同,均为32。由于卷积层过多会造成较多的信息损失,因此第1 条主分支和第2 条主分支分别设计为1 层和2 层卷积层,核为3×3×3。第1 条主分支:1 层卷积层,通道数为32。第2 条主分支:第1 个卷积层通道数为16,对图像进行下采样;第2 层卷积层通道数为32,用来缓解信息丢失的问题。2 条主分支的特征维度相同,在通道维度上对它们的输出结果进行拼接。为了充分提取输入特征,缓解特征信息在传递过程中的损失问题,引入第3 条捷径分支进行残差学习。原始3D-ResNet 的第1 层卷积层输出通道数为64,为了使改进前后输出维度相同且能够进行残差加运算,捷径分支采用通道数为64、核大小为1×1×1 的卷积层,用于调整输入数据维度。此外,在每个卷积层后都连接了BN 层和ReLU 激活函数,加快网络的收敛速度。
1.2.2 池化卷积残差连接方式设计
在ResNet 中存在如图4(a)和图4(b)所示的两种残差连接方式。当输入和输出的特征图大小相同时,使用方式1直接进行特征映射。当输入和输出的特征图大小不同时,使用方式2 进行残差连接,捷径分支的卷积核尺寸为1×1×1,步长为2×2×2,用于将特征图尺寸减小为原来的1/2,同时将通道数变为原来的2 倍。然而,虽然步长为2×2×2 的卷积层可以达到下采样的目的,但弱化了细粒度特征,细节信息有所损失,从而减少了后续网络层能够提取的有效特征。
针对上述问题,对连接方式2进行改进,将特征图尺寸大小减半与通道数目翻倍分两步进行,结构如图4(c)所示。首先在捷径分支中加入步长为2×2×2的最大池化层,达到特征图大小减半的目的;然后使用步长为1×1×1 的卷积层,用于改变通道数。这种先池化再卷积的操作在下采样的过程中减少了信息损失。本文网络部分的残差块1 使用方式1 进行残差连接,残差块2、3和4使用改进方式2进行残差连接。
1.2.3 交互式四重注意力模块设计
在手语识别过程中,确定手部动作的空间位置和时间位置有利于提高识别准确率。近年来常用的注意力有SE[17]和CBAM[18],然而SE 仅在通道维度上计算了注意力权重,CBAM 虽然兼顾了通道注意力和空间注意力,但它先对通道再对空间进行卷积,前者影响了后者空间注意力的使用效果。
Triplet Attention[19]是一种通过旋转操作建立通道维度和空间维度之间交互关系的二维注意力模块,本文基于Triplet Attention 设计出可应用于三维卷积的四重注意力(Quadruplet Attention,QA)模块,框架如图5 所示。
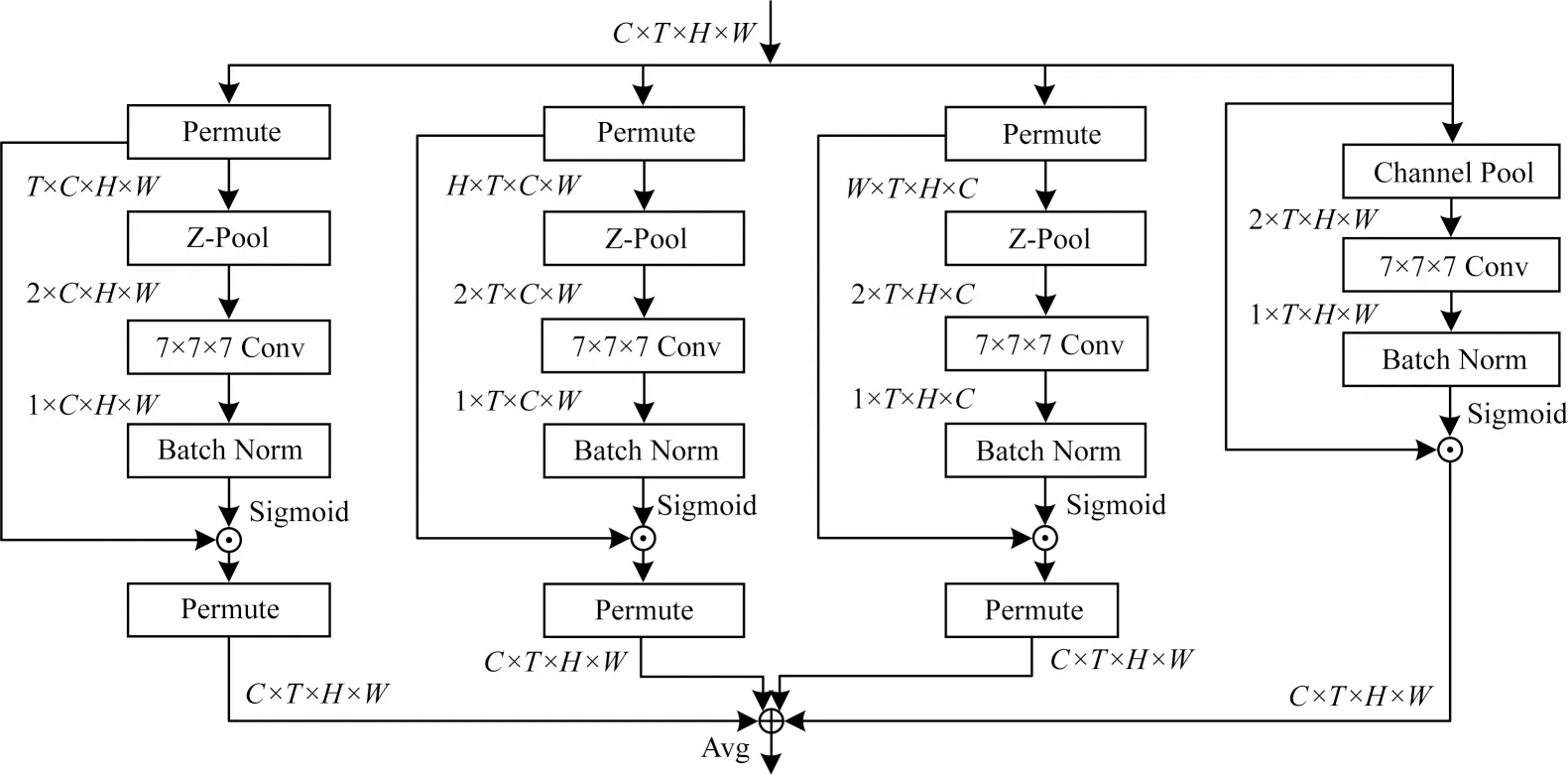
图5 四重注意力模块Fig.5 Quadruplet attention module
对于输入张量x∊RC×T×H×W,其中,C、T、H和W依次表示输入的通道、时序、高度和宽度,将其送入4 条支路。
支路1 用来获得通道维度C与空间维度(H,W)的交互式注意力权重。输入首先通过跨维度操作建立(C,H,W)维交互,接着依次经过Z-Pool 层、卷积层、BN 层和激活函数得到注意力权重,然后将其输出与维度变换后的张量相乘,最后经过反向跨维度作用,获得和原始输入形状相同的输出。此处Z-Pool 是指将最大池化结果和平均池化结果进行拼接,其数学公式如下:
支路2 用于获取通道维度C和空间维度(T,W)的交互式注意力权重。它的操作和第一条分支类似,不同的是它的跨维度操作建立的是(C,T,W)维交互,反向跨维度作用是与(C,T,W)维相对应的反向操作。
支路3 用于捕捉通道维度C和空间维度(T,H)之间的交互关系。跨维度操作建立的是(C,T,H)维交互,反向跨维度是与(C,T,H)维相对应的反向操作。
支路4 仅用于计算空间维度(T,H,W)的注意力权重。它不需要进行跨维度操作,而是直接将输入送进Z-Pool 层、卷积层以及激活函数,然后将其输出与输入相乘,从而获得最后一条分支的输出。
最后将4 条支路的注意力权重进行平均即可得到QA 模块的输出:
2 实验结果与分析
2.1 实验数据集
使用两个数据集,分别是CSL[20]和DEVISIGN[21]数据集。
1)CSL 数据集包含了500 类词汇,每类词汇由50 个操作者演示5 次。从中选取100 类词汇,将视频数据按照7∶2∶1 的比例划分为训练集、验证集和测试集,即训练集、验证集和测试集分别有17 500、5 000、2 500 个视频。
2)DEVISIGN 数据集包含了500 类常用词汇,每类词汇由8 个操作者演示,其中4 个操作者每人重复演示2 次。从中选取100 类词汇,并进行平移变化、翻转变化和数据裁剪对数据进行扩充,最终得到12 000 个视频,其中,训练集有8 000 个视频,验证集有2 000 个视频,剩下2 000 个用于测试。
2.2 实验设置
实验环 境:PyTorch1.6.0+CUDA10.0,NVIDIA GeForce RTX 2080 Ti GPU。关键帧提取的初始阈值c设为0.2,关键帧个数L设为16。模型训练使用Adam 优化器和指数衰减调整学习率,初始学习率为0.000 1,学习率调整倍数为0.9,训练批次为4,在CSL 和DEVISIGN 数据集上分别迭代50 和100 次。
2.3 评价指标
在二分类任务中,通常使用准确率(Aaccuracy)、精确率(Pprecision)和召回率(Rrecall)来评价模型的性能,它们的计算公式分别如下:
其 中:TTP、TTN、FFP、FFN表示正 样本被 正确识 别的数量、负样本被正确识别的数量、误报的负样本数量和漏报的正样本数量。对于本文的多分类问题,采用宏平均的评价方法,即先对每一个手语词汇计算准确率、精确率和召回率,再对所有手语词汇计算算术平均值作为模型整体的准确率、精确率和召回率。
2.4 结果分析
为了分析每种改进方法对模型性能的影响,在CSL 手语数据集上进行如表1 所示的改进实验,其中√表示具有该模块。实验A 采用均匀采样的方法提取出16 帧送入3D-ResNet 网络进行手语识别,由于存在静止帧,含有手语动作的帧较少,因此模型识别效果较差。实验B 对手语视频进行关键帧提取操作,获得了更能代表视频内容的数据,识别准确率明显提升。实验C 在实验B 的基础上,改进了3DResNet 网络,利用小卷积模块增强模型对输入细粒度特征的提取能力,使得模型性能有所提升。在实验D 中,残差块捷径分支的先池化再卷积的操作减少了信息损失,为后续网络层的特征提取打下了良好基础。在此基础上,实验E 在残差块中嵌入了四重注意力模块,捕捉到了通道注意力和空间注意力并且考虑了它们之间的交互关系,使得模型准确率高达92.0%。此外,每个改进实验都在一定程度上提升了识别的精确率和召回率。

表1 不同改进实验的结果对比Table 1 Comparison of results from different improvement experiments %
为了评估所提方法网络部分的性能,以关键帧提取为前提,将本文改进的3D-ResNet和原始3D-ResNet在CSL 和DEVISIGN 数据集上进行对比分析,结果如图6 和图7 所示。由图6 和图7 可以看出,3D-ResNet在CSL 数据集上的验证曲线与训练曲线有着较大的差距,出现了欠拟合现象,然而改进的3D-ResNet的拟合效果更好,并且收敛于更高的准确率和更低的损失。在DEVISIGN 数据集上进行实验,改进的3D-ResNet迭代约10 次后准确率有所上升,约35 次后开始收敛,训练速度明显快于3D-ResNet。在训练后期,在这两个数据集上,改进的3D-ResNet 相比3D-ResNet曲线震荡幅度更小,模型更加稳定。
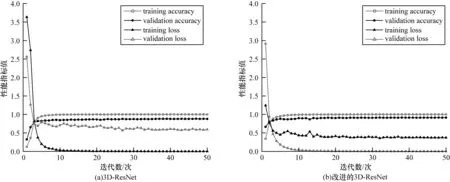
图6 CSL 数据集上的实验结果Fig.6 Experimental results on the CSL dataset

图7 DEVISIGN 数据集上的实验结果Fig.7 Experimental results on the DEVISIGN dataset
为了进一步说明所提方法的有效性,将其与Adaptive HMM[22]、C3D[23]、B3D ResNet[24]、3D-CNN[25]等手语识别方法分别在CSL 和DEVISIGN 数据集上进行对比实验,结果如表2 和表3 所示。由表2 和表3 可以看出,基于深度学习的方法相比于传统方法准确率更高,使用多模态数据相较于使用单一模态数据具有更好的性能,而所提方法仅用RGB 视频数据模态就取得了优异的效果,并且准确率在CSL数据集上高于同样使用视频数据的基于B3D ResNet和CBAM-I3D 的手语识别方法,在DEVISIGN 数据集上高于同样使用视频数据的基于B3D ResNet 的手语识别方法。综上,所提方法在CSL 和DEVISIGN 数据集上分别取得了92.0%和92.2%的识别准确率率,均优于其他手语识别方法。
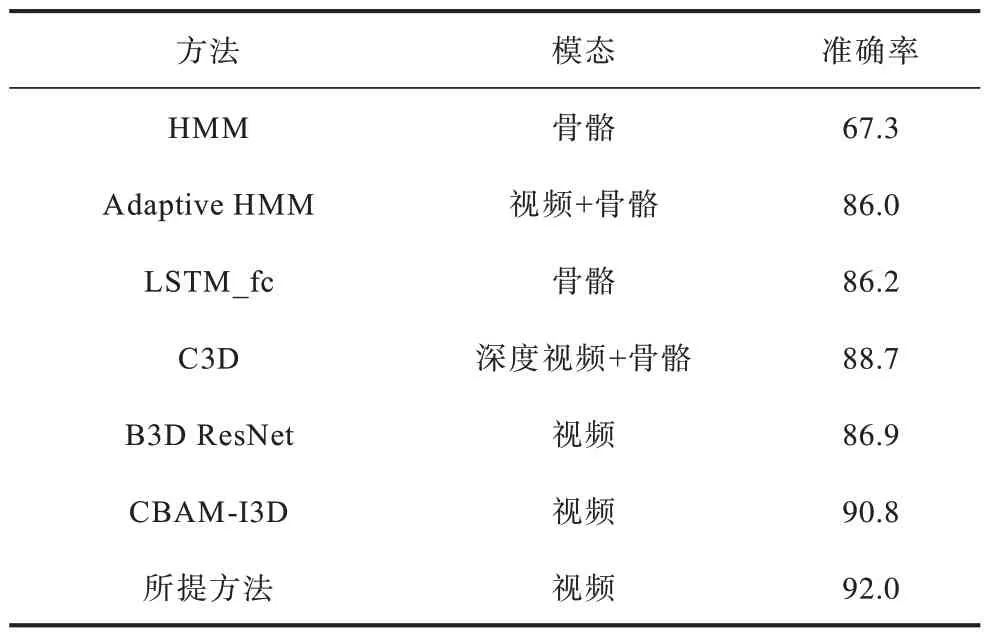
表2 不同方法在CSL 数据集上的实验结果Table 2 Experimental results of different methods on the CSL dataset %
3 结束语
本文提出一种基于关键帧和交互式注意力残差网络的手语识别方法。通过基于图像相似度和模糊程度的关键帧提取算法提取能够代表视频内容的关键帧,减少了冗余数据。将3D-ResNet 的大卷积层替换为小卷积残差模块,更加有效地提取细节特征。采用池化卷积残差连接方式,解决了下采样时信息损失严重的问题,进一步提高模型精度。设计四重注意力模块减小背景以及操作者等无关信息对模型分类的干扰,提升网络的表征能力。实验结果表明,所提方法相比于其他手语识别方法具有更高的准确率,能够有效地进行手语识别。后续将对手语识别网络结构做进一步优化,使用含有复杂背景的手语数据集进行实验,并搭建真实环境下的手语识别系统。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
活力(2019年15期)2019-09-25 07:23:06
数学物理学报(2017年5期)2017-11-23 07:51:31
大连理工大学学报(2017年4期)2017-08-07 07:03:20
重庆交通大学学报(自然科学版)(2016年1期)2016-05-25 00:37:00
西北工业大学学报(2015年3期)2015-12-14 13:08:46
青少年科技博览(中学版)(2015年8期)2015-10-28 21:26:56
文艺生活·中旬刊(2014年12期)2015-01-06 03:03:56
作文大王·笑话大王(2014年11期)2014-11-13 09:01:43
