
对抗多模式网络层析成像的拓扑混淆机制
2023-12-16 10:30:24林洪秀邢长友
计算机工程 2023年12期
林洪秀,邢长友,詹 熙
(中国人民解放军陆军工程大学 指挥控制工程学院,南京 210007)
0 概述
大量研究表明,大部分网络攻击开始之前通常存在网络侦察阶段[1]。在网络侦察阶段,攻击者主要获取目标网络的网络拓扑、IP 地址块、服务依赖关系和存在漏洞的服务器等信息,其中,网络拓扑是一种非常重要的攻击信息,攻击者可以根据目标网络的拓扑结构对网络中的关键链路和关键节点发起链路洪泛攻击(Link-Flooding Attack,LFA)[2]等精准攻击,破坏目标网络的连通性。
作为一种主动欺骗防御技术,网络拓扑混淆技术能够有效对抗攻击者实施的网络拓扑推断[3]。网络拓扑混淆技术[4-5]并不刻意阻止攻击者的攻击行为,而是识别网络中的探测流,通过策略性地混淆探测流,将真实网络拓扑伪装成混淆网络拓扑,使攻击者无法发起有效攻击。
目前,网络拓扑混淆技术在对抗基于traceroute的网络拓扑推断研究中取得了较好的成果,但面向网络层析成像的拓扑混淆技术的相关研究较少,且存在一定的局限性。在网络层析成像拓扑推断中,攻击者通过使用多种探测模式测量路径性能相关性,从而根据测量结果推断网络拓扑结构[6]。网络拓扑混淆技术则通过对探测流进行混淆操作[7],扰动攻击者的测量结果,使其推断出错误的网络拓扑,其具体的混淆操作方法与攻击者进行拓扑推断时使用的性能参数类型相关,如攻击方以时延为拓扑推断的性能参数时,防守方通常通过延迟操作来混淆探测流,而当攻击方以丢包率为拓扑推断的性能参数时,则防守方通常通过丢弃数据包操作来混淆探测流。不同性能参数对应着攻击方不同的探测模式,若混淆操作与探测模式不匹配,则会出现无法有效混淆探测流的后果,因此,准确识别探测模式对于增强面向网络层析成像的拓扑混淆技术具有重要意义。然而,现有面向网络层析成像的拓扑混淆技术只能识别攻击者的探测行为,无法进一步识别攻击者使用的探测模式。
针对上述问题,本文提出一种既能在线识别探测行为与探测模式,又能策略性混淆探测流的方法,实现这一目标主要存在以下3 个挑战:1)在线检测攻击者的探测流对实时性的要求比较高,在追求检测准确性的同时也能保证检测时效性具有一定的挑战性;2)不同探测模式下的探测流区别较小,准确识别探测包的探测模式具有一定的挑战性;3)如何混淆探测流使攻击者侦察到混淆网络具有一定的挑战性。
为解决以上问题,本文提出一种对抗多模式网络层析成像的拓扑混淆机制M2NTO。针对第1 个挑战,设计一种基于增量学习的在线决策树分类算法,在探测流的早期阶段进行识别和分类,根据分类结果对探测流的后续数据包进行相应的混淆操作。针对第2 个挑战,根据网络层析成像探测流在传输模式上存在的区别,将探测流检测分为2 个步骤:首先使用流量分类算法识别网络中的探测流,然后再以块的形式对识别到的探测流进行二次分类,从而得到探测流的探测模式。针对第3 个挑战,根据网络负载情况与探测方法判断攻击者使用的性能参数,结合性能参数的特点和探测模式的原理为每种性能参数设计相应的混淆方案。
本文基于SDN[8]技术实现M2NTO 的原型系统,M2NTO 通过在网络边缘部署SDN 交换机实时捕获端节点发出的网络流数据并转发到SDN 控制器,随后SDN 控制器再进行特征提取、流量分类及下发流表等操作,最后,SDN 交换机根据下发的流表规则进行相关混淆操作,从而准确识别探测流类别并有效混淆网络层析成像探测包,达到防御基于网络层析成像的拓扑探测的目的。
1 相关工作
网络层析成像技术根据端到端测量结果推断网络拓扑结构,常用的拓扑推断算法主要有MLT(Maximum Likelihood Tree)[9]、HTE(Hierarchical Tree Estimation)[10]和RNJ(Rooted Neighbor-Joining)[11]等算法,这些方法的拓扑推断过程主要分为测量端到端性能、计算节点相关性、重构网络拓扑3 个步骤[12]。首 先,使 用“三明治”分组列 车[13]和“背 靠背”[9]等测量方法从源节点发送一组探测包到目的节点。然后,在目的节点计算共享路径性能(排队时延、链路利用率、时延协方差等),根据相关性能的值计算目的节点对之间的相关性,共享路径越长,相关性值越大,节点对相关性越大。最后,根据节点相关性重构网络拓扑结构。
网络层析成像技术准确推断目标网络拓扑结构的前提是测量数据真实可靠,根据这个特点,HOU等[4]提出了一种先检测后混淆的网络层析成像拓扑混淆框架ProTo。ProTo 中的检测模块以一种轻量级的KNN 分类器识别网络层析成像探测包,通过离线自训练和在线增量更新,可以达到较高的检测率和较低的误报率;混淆模块通过延迟识别到的探测包,使攻击者测量的网络端到端性能不准确,从而计算到错误的节点相关性,推断出错误的网络拓扑。LIU等[5]针对ProTo 的混淆性能存在不确定性这个问题,设计了一个多目标优化模型AntiTomo,根据欺骗性、安全性、低成本等目标,在候选混淆拓扑组成的候选森林中使用贪心算法选择最优候选树作为混淆网络拓扑。
虽然ProTo 和AntiTomo 在对抗网络层析成像拓扑推断上起到了一定的作用,但两者都存在一定的局限性:AntiTomo 不对网络层析成像探测包进行识别,仅通过增加网络链路的端到端时延来混淆网络拓扑,这种混淆操作会影响正常数据包的传输,降低网络性能甚至影响网络功能;ProTo 只能检测到攻击者基于网络层析成像的探测行为,无法进一步识别其使用的测量方法类型,且只能在网络层析成像的性能参数为排队时延的情况下进行混淆操作。
2 基于网络层析成像的拓扑探测及对抗模型
2.1 基于网络层析成像的拓扑探测模型
图1 是攻击者利用源节点s1和目的节点{d1,d2,d3,d4,d5}形成的1×5 探测网络。在网络拓扑端到端探测过程中,攻击者在源节点s1发出一组探测分组,这些探测分组将沿着相应的路由到达目的节点。在基于层析成像的网络拓扑探测模型中,为了推断目标网络的拓扑结构,攻击者需要测量任意2 个目的节点间的相关性,因此,需要组合测量到所有目的节点对之间的性能,最后推断出整个目标网络的拓扑结构。为了准确计算节点间的相关性,在实际测量中攻击者往往多次测量计算均值,通常需要向每个节点对发送几百甚至上千个探测包。因此,在攻击者探测期间,网络中可以观测到具有相同模式的大量流量。

图1 基于网络层析成像的拓扑推断方法Fig.1 Topology inference method based on network tomography
网络层析成像常用的测量方法如图2 所示,“三明治”分组列车测量方法的探测包组由3 个数据包
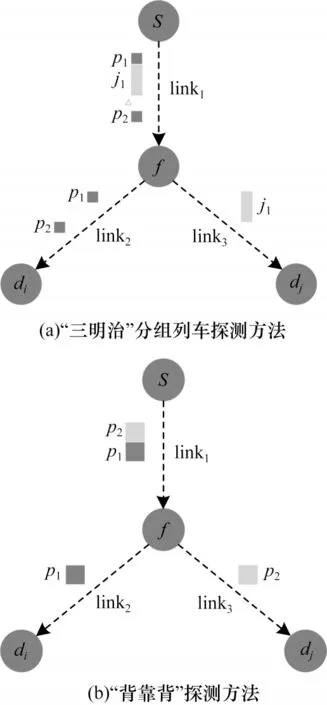
图2 基于网络层析成像的拓扑探测方法Fig.2 Topology probe method based on network tomography
2 种测量方法的探测模式不同,节点相关性计算的思想也不同。在“三明治”分组列车探测方法中,大数据包j1大小通常超过1 000 Byte,在链路中的传输时延较大,导致小数据包p2在节点f处的排队时延较长,使得节点i和节点j的共享路径越长,数据包p1和大数据包j1经过的节点越多,在目的节点di观测到2 个小数据包的时延差值就越大,节点di和节点dj相关性越大。“背靠背”探测方法的本质是模拟多播网络,由于2 个数据包之间的时间间隔极小,可以认为2 个数据包在共享链路上所经过的网络状况相同,在目的节点计算端到端单向时延或丢包率,根据时延协方差或丢包率计算2 个节点的共享路径长度,时延协方差或丢包率越大,共享路径越长。
2.2 对抗网络层析成像的拓扑混淆模型
针对上述探测过程,本文设计的网络拓扑混淆模型如图3 所示,主要分为网络流量监听与处理、探测流量识别与分类和探测流量混淆操作3 个阶段。在网络流量监听与处理阶段,完成监听网络实时数据流、提取数据流特征以及特征选择等处理操作。在探测流量识别与分类阶段,将处理好的数据送入分类器进行分类,得到网络流类型的分类结果,之后根据新到达的数据动态更新该分类器。在探测流量混淆操作阶段,首先结合流量分类的结果和网络负载情况判断攻击者使用的网络性能参数,然后根据混淆网络拓扑生成算法构建混淆网络拓扑并计算混淆操作中用到的性能参数,最后根据得到的性能参数对K-cast 探测流进行相应的混淆操作。

图3 对抗网络层析成像的拓扑混淆模型Fig.3 Topology obfuscation model against network tomography
需要说明的是,由于流量分类阶段初始分类器的构建需要带标签的数据集进行训练,因此在流量检测系统上线前还需要经过一个离线处理阶段。在离线处理阶段,首先收集网络流数据提取网络流的特征,并人工对样本进行标记生成初始训练集和初始探测流数据集,以备后续使用初始训练集和探测流数据集训练分类器得到初始分类器。
3 网络层析成像探测流量在线识别与混淆机制
3.1 网络流量监听与处理
在入口节点监听端节点发出的数据包,解析数据包的五元组信息(<源IP,目的IP,源端口,目的端口,协议类型>),根据五元组信息判断当前数据包所属的网络流,并对网络流进行信息统计与特征提取。MOORE 等[14]提出了248 个可以 用于机 器学习流量分类的流量特征,但这些特征大多都无法在线提取,因此,许多关于在线流量分类的研究通常把前n个数据包的统计信息作为流特征[15]。HUANG 等[16]通过实验证明了仅使用网络流的前几个数据包进行分类能同时兼顾效率与精度。由于网络层析成像技术使用的网络探测方法具有固定的传输模式,且其早期子流的特征能够基本反映整条流的网络特征,因此本文以网络流前5 个数据包的统计特征和到达时间及五元组信息作为网络流的特征,如表1 所示。
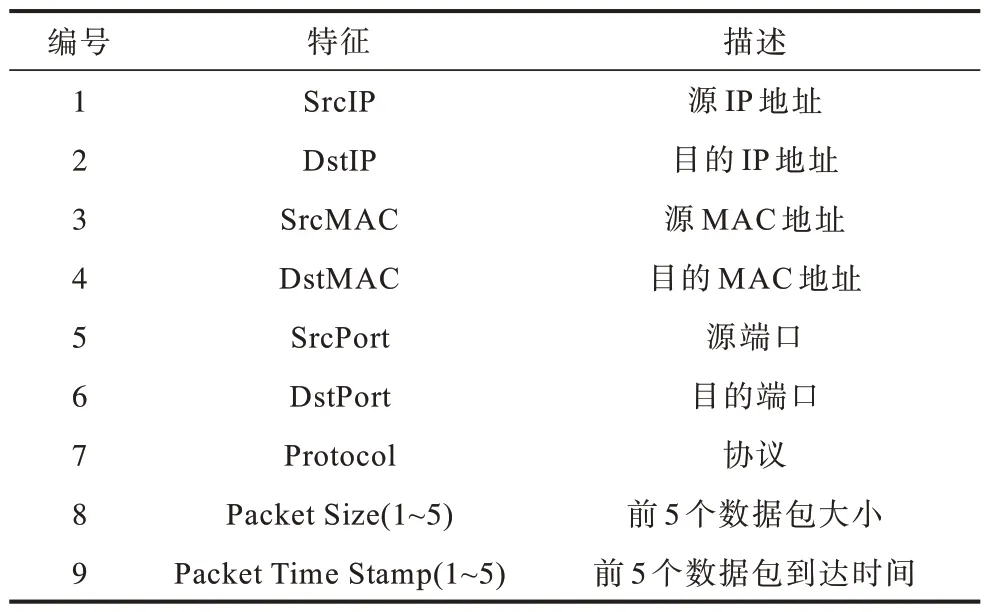
表1 网络流特征信息Table 1 Network traffic characteristics information
1)IP 地址距离
IP 地址可以标识端节点的网络位置,IP 地址距离是源/目的IP 地址相与的结果,可以度量2 个IP 地址的距离。给定源IP 地址[10.0.0.1]和目的IP 地址[10.0.0.2],逐位相与结果为1,表明2 个地址非常接近,可能位于同一子网中。
2)数据包大小的方差
网络层析成像在探测时不同探测流的数据包大小可能不同,但在同一条探测流中的数据包大小通常是一致的。为了使这种特性更好地应用到分类中,对数据包的大小进行方差计算,数据包大小波动越小,方差越小。
3)时间间隔
网络层析成像探测数据包以恒定的时间间隔传输,以消除随机测量噪声。在数据收集阶段记录了每条流的前5 个数据包的到达时间,再增加5 个数据包之间的时间间隔特征。
4)时间间隔方差
不同探测流的探测包时间间隔大小可能不相同,但在同一条探测流内的探测包时间间隔是一样的。因此,采用时间间隔方差来衡量数据包时间间隔的波动。
5)反向流
网络层析成像从同一个源节点发出探测包,在目的节点观测探测包的性能,不要求有从目的节点到源节点的反向流。然而,很多正常的网络流是有反向流的,如实时视频语音通话、网站表单验证等,因此,是否存在反向流也是检测探测流的一个特征。
网络层析成像探测流因其特殊的测量方式,IP地址距离、数据包大小方差、时间间隔等特征存在明显的规律,与正常网络流区别较大,但是探测流之间的区别较小,如“三明治”探测方法中的2 个小数据包与“背靠背”探测方法中的数据包IP 地址距离、数据包大小、时间间隔等特征区别较小,无法根据单个探测流的特征识别探测模式,而探测流的主要区别在于探测流之间的整体传输模式,需要提取多个探测流之间的相关关系来区分传输模式。因此,本文将网络层析成像探测流分类过程分为2 步:首先,以单条流的特征来识别网络流中的探测流;然后,从识别到探测流开始,以连续到达的k条探测流视为一块,以块的形式提取探测流相关关系特征,识别探测流块的传输模式。考虑到探测流与正常数据流的区别,在第1 步中使用如表2 所示的特征。

表2 探测行为识别采用的特征信息Table 2 Feature information used for probe behavior recognition
第2 步要对识别出的探测流类型进行分类。考虑到探测流之间的区别主要在于传输模式的差异,而单个探测流不易识别其传输模式,此处须通过提取由k条探测流构成的探测流块的特征进行分类,因此第2 步使用如表3 所示的特征。
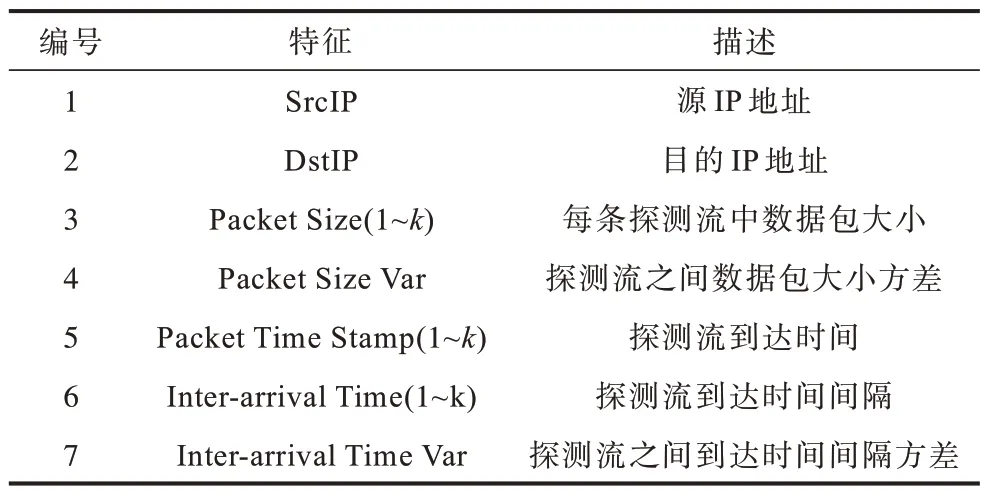
表3 探测流分类采用的特征信息Table 3 Feature information used for probe traffic classification
3.2 探测流量识别与分类
考虑到决策树[17]在处理离散特征上的优势,而上述提取的特征多为离散值,因此,本文使用决策树作为基础分类器。考虑到网络流的特征会随着网络状态的波动而不断发生改变,普通算法无法处理应对这种不断发生变化的情况。增量学习的方法是渐进地进行知识学习、修正和加强已有的知识的过程[18],其能适应不断变化的网络流,在学到与当前网络状态匹配的特征时,还能保存大部分以前已经学到的知识[19]。因此,本文结合决策树算法与增量学习,设计了一种在线流量检测方法,使其能够适应不断变化的网络状况,达到较高的流量检测精度。该检测机制主要分成3 步:
1)初始决策树生成。基于离线处理阶段提取的初始训练集和探测流数据集创建2 棵初始决策树T1和T2,其中T1用于探测流识别,T2用于探测流分类。
2)探测行为识别。使用T1识别新到达的网络流是否为探测流,若识别结果为正常数据流则直接传输,否则,使用T2对该探测流进行二次分类。识别完成后将该网络流数据加入训练集,然后根据训练集中网络流样本特征的到达时间更新样本权重,最后,根据更新后的训练集对决策树T1进行更新。
3)探测流分类。将T1最新识别出的探测流与其前k-1 个被识别出的探测流合并成探测流块,使用T2以提取该探测流块的特征进行二次分类,识别出新到达的探测流的模式,识别完成后将该探测流数据加入探测流数据集,然后根据探测流数据集中样本的到达时间更新样本权重,最后,根据更新后的探测流数据集对决策树T2进行更新。
下面从初始决策树生成、探测行为识别和探测流分类这3 个方面详细介绍本文提出的探测流量在线检测机制。
3.2.1 初始决策树生成
在流量检测系统上线前,需要构建初始决策树T1和T2。决策树模型呈树形结构,如何确定内部分支节点是创建决策树的关键。在流量识别中,选择特征属性的顺序决定了决策树的内部分支结构,直接影响到分类的性能。
信息熵增益率是选择最佳特征的常用方法之一,表示特征使数据集分类的不确定性减少的程度,信息增益大的特征分类能力更强。对于一个包含K类样本的数据集D,其信息熵的计算公式如下:
其中:Ck表示数据集中属于类k的样本;Pk为样本的类属性为k的概率;Wk表示Ck中样本权重的总和;WD为所有样本权重的总和。在数据集样本权重都为1时,Pk=|Ck|/|D|,|Ck|表示Ck中的样本个数,|D|表示数据集D的总样本个数。攻击者在网络层析成像探测时为了达到隐蔽性的目的,探测包造成的网络负载通常为链路带宽的1%~2%,而总体网络负载比例一般在30%~70%之间,这会导致数据集中正常网络流的样本数量大于探测流的样本数量。为了解决数据集类别不平衡的问题,本文给小类样本赋予更高的权重,权重大小由数据集中大类样本数量与小类样本数量的比例决定,大类与小类之间的权重关系如下:
其 中:wk1和wk2分别为 类k1和 类k2的样本权重;|Ck1|为类Ck1样本个数;|Ck2|为类Ck2样本个数。本文将大类即正常数据流这一类的权重设定1,则探测流数据的权重为|Cnormal|/|Cprob|,其中:|Cnormal|为正常网络流样本个数;|Cprob|为探测流样本个数。
设数据集D的特征集为A={A1,A2,…,An},每个特征Ai能取ni个不同的值{ai,1,ai,2,…,ai,ni}。根据特征Ai的取值可以将数据集D分为ni个子集D1,D2,…,Dni,|Dj|为子集Dj中的样 本个数|D|,Wij代表分支ai,j的权重,其值为子集Dj中样本权重总和。记子集Dj中样本类属性为p的样本的集合为Djp,Wijp表示Djp中样本权重的总和。特征Ai的条件信息熵为:
其中:Pi是特征Ai取值为ai的概率。信息增益的定义为:
信息增益的值与训练数据集相关,当训练数据集的信息熵大时,信息增益值会偏大。因此,使用信息增益率进行改进:
在初始决策树T1的生成过程中,首先利用离线阶段收集的初始数据集D1和特征集A(如表2 所示),计算初始数据集D1的信息熵和每个特征的信息增益率,然后根据信息增益率的值选出最佳分裂特征,以最佳分裂特征为根节点,并根据最佳分裂特征划分子集,用剩余的特征递归构建子树,最后得到完整的决策树T1。初始决策树T2的创建步骤与创建T1一样,区别在于初始数据集和特征集。初始数据集D2是从数据集D1中分类出来的探测流集合,特征集B如表3 所示。
在初始决策树训练完成后,用分层交叉验证法对决策树进行后剪枝,提升决策树分类的泛化能力。
3.2.2 探测行为识别
流量检测系统在线后,入口交换机监听到实时网络流,根据决策树T1识别网络流中攻击者发出的探测流。由于网络流的特征会随时间发生变化,而当前流与最近到达的流相关性高,与最开始到达的流相关性低,因此本文引入衰落模型的概念,根据流到达的先后顺序对数据进行加权。本文应用一个具有指数函数的衰落模型来设置样本e的权重:
其中:λ为衰落因子,0<λ<1。为减少实时更新数据集实例权重的时间花销,根据网络流到达的顺序对数据集中的样本进行编号,第一个到达的网络流样本序号设置为1,最新到达的实例序号为t,Δt是当前样本的序号与数据集中样本序号的差值。wk是样本的类别权重,表示类别为k的样本的权重大小。每新到达一个流时,都更新数据集中样本的权重。样本权重更新会引起特征权重的变化,即决策树中每个节点分支的权重发生改变,而权重过小的分支意味着很少或者很旧的样本属于这一特征的分类决策下,对整体分类贡献不大,因此,对这类分支予与删除操作,而权重较大且不纯的分支则进行继续生长。
探测流模式识别的在线更新算法如算法1 所示。算法输入数据集D和决策树T,以及相关参数即衰落因子λ、节点权重下界参数α、节点权重上界参数β,输出更新后的数据集D'和决策树T'。该算法首先计算数据集中的每个样本与当前样本的序号差值(第2 行),接着根据式(6)更新样本权重(第3 行),然后再计算节点权重的平均值(第5 行),从根节点开始遍历决策树中所有节点(第6 行),根据新的样本权重更新节点分支的权重值(第8 行),若该分支为叶子节点分支且权重值大于上界阈值(参数β与节点权重平均值的乘积),就为该分支创建子树(第9~10 行),并剪枝权重小于下界阈值(参数α与节点权重平均值的乘积)的分支(第11~12 行)。
算法1OnlineUpdate
3.2.3 探测流分类
在识别出探测流后,要进一步区分探测流的模式。探测流分类算法如算法2 所示。新的网络流e到达后,首先根据决策树T1区分出探测流和正常流(第1 行),并将分类结果加入到原始数据集(第2~3 行),然后根据在线更新算法对决策树T1和原始数据集D1进行更新(第4 行)。如果新到达的流是识别为正常数据流(第5 行),直接输出分类结果(第6 行);否则用列表tmpProbData 存储探测流数据(第8 行),直到收集满k个探测流(第10 行),提取这k个探测流的特征(第11 行),根据决策树T2进行分类(第12 行),将分类结果和探测流数据加入到探测流数据集中(第13~14 行),并进行更新(第15 行),以及将列表清空,等待下一个探测流进入(第16 行),最后输出探测流模式的类别(第18 行)。
算法2Attack flow classification
3.3 探测流量混淆操作
在识别出探测包,并对探测包的模式进行准确分类后,需要对探测包进行相应的混淆操作,具体的混淆操作方法与探测包的探测模式和使用的性能参数类型相关。为了使攻击者推断出混淆后的网络拓扑,需要将攻击者测量的端到端性能修改成混淆网络拓扑的性能,本文基于文献[5]提出的方法构建混淆网络拓扑和计算混淆网络拓扑的相关性能。
性能参数类型与探测模式有关,网络层析成像拓扑推断常用的网络性能参数有排队时延、时延协方差和成功传输率,排队时延可以通过“三明治”分组列车探测方法得到,时延协方差和成功传输率通过“背靠背”探测方法得到。相关研究表明[10,12],不同性能参数在网络环境中的适应情况不同,当网络负载较小时,网络中的时延和丢包较少,测量分组在共享链路中的时延变化较小,因此,时延协方差和成功传输率性能参数不适用于网络负载较小的网络环境,而当性能参数为排队时延时,端到端时延完全由“三明治”测量中的大数据包产生的,测量结果较为准确,推断的网络拓扑准确性最高;当网络负载适中时,网络中的背景流量较多,影响排队时延的概率增大,而测量分组在共享链路中的时延变化较大,节点间共享链路的时延方差较大,时延协方差性能参数推断的网络拓扑准确性最高;当网络负载较大时,网络中丢包较多,丢包率较大,导致测量的样本数量大大减少,使得时延协方差和排队时延性能参数测量准确率下降,而采用成功传输率性能参数可以较好地反映节点间共享链路的情况。
因此,本文结合网络负载情况推断攻击者使用的端到端性能参数类型。如果探测包的探测模式是“三明治”分组列车,那么攻击者采用性能参数为排队时延;如果探测包的探测模式是“背靠背”探测,需要网络负载信息进行辅助判断,如果网络负载较轻,那么攻击者采用性能参数是时延协方差,否则攻击者采用性能参数是成功传输率。
本文为每种性能参数都设计了相应的混淆操作方案。以图4 为例,假设在真实网络中,攻击者从源节点S发出一组探测包,分别到达目的节点i和目的节 点j,P(i,j)为节点i和节点j的父节 点。链 路(S→P(i,j))为节点i和节点j的共享路径,XP,(i,j)为共享路径的性能,Xi,(i,j)为链路(P(i,j) →i)的性能,Xj,(i,j)为链路(P(i,j) →j)的性能,Yi,(i,j)和Yj,(i,j)分别为攻击者在目的节点i和目的节点j测量到的端到端性能。根据文献[5]可以计算得到混淆网络中节点i和节点j的相关性能为XP',(i,j),为了将真实网络拓扑伪装成混淆网络拓扑,还需计算混淆网络的端到端性能Yi',(i,j)和Yj',(i,j),将真实网络的端到端性能Yi,(i,j)和Yj,(i,j)修改成混淆网络的端到端性能Yi',(i,j)和Yj',(i,j),每种性能参数的混淆操作方案和计算过程如图4 所示。
1)排队时延
排队时延由“三明治”测量包中的大数据包在经过节点和链路时产生,导致跟在其后的第2 个小数据包与第1 个小数据包到达目的节点的时间隔间变大。因此,排队时延性能参数的混淆操作只需延迟“三明治”分组列车中的第2 个小数据包,延迟时间Dt为混淆网络端到端时延Yi',(i,j)与真实网络的端到端时延Yi,(i,j)的差:
需要说明的是,在实际的网络操作中,增加探测包的时延和丢弃概率比减少探测包的时延和丢弃概率简单得多,因此在与时延相关的性能参数混淆操作中,本文一律采取延迟探测包,在成功传输率性能参数的混淆操作中采取丢弃探测包。
2)时延协方差
节点i和节点j的时延协方差由“背靠背”探测方法测量的端到端时延计算得到,根据网络层析成像中链路独立性假设,节点对的端到端时延协方差为共享路径时延的方差:
根据式(9)所示的协方差计算公式可以得到混淆网络拓扑的端到端时延协方差计算公式,如式(10)所示:
在实际的网络探测中,攻击者会向每个节点对发送多个探测包组,以消除测量误差。而根据文献[6]计算混淆网络的相关时延时,一个节点对通过计算只能得到唯一确定的相关时延XP′,(i,j),因此,将式(10)简化为:
在已知XP',(i,j)和Xi,(i,j)的情况下求解Yi'(i,j)和Yj',(i,j),有无数多个解。时延协方差性能参数的每次混淆操作取其中一组满足Yi',(i,j)≥Yi,(i,j),Yj',(i,j)≥Yj,(i,j)的解,根据解Yi',(i,j)和Yj',(i,j)同时延迟“背靠背”测量中的2 个探测包。到达目的节点i的探测包延迟时间Cov_delay(i)为:
3)成功传输率
成功传输率表示探测包在目的节点被成功接收的概率,节点i和节点j的共享给路径越长,成功传输率越小。假设XP',(i,j)为混淆网络中节点i和节点j在共享路径(S→P(i,j))的成功传输率,Xi,(i,j)为链路(P(i,j) →j)的成功传输率,Xj,(i,j)为链路(P(i,j) →j)的成功传输率,那么混淆网络的端到端成功传输率为:
成功传输率性能参数的混淆操作为以一定的概率丢弃探测包,到达目的节点i的探测包被丢弃的概率为:
综上所述,在探测流量的混淆操作中,当攻击者以排队时延作为拓扑推断的性能参数时,需要在目的节点i处的出口节点上延迟“三明治”分组列车中的第二个小探测包,延迟操作的具体实现是将探测包存入特殊的队列中,延迟时间由式(7)计算得到;当攻击者以时延协方差作为拓扑推断的性能参数时,需要在目的节点i和节点j处的2 个出口节点上分别的对“背靠背”探测中的两个探测包进行延迟,延迟时间由式(12)计算得到;当攻击者以成功传输率作为拓扑推断的性能参数时,需要在目的节点i和节点j处的2 个出口节点上以一定的概率丢弃探测包,丢包概率由式(14)计算得到。
4 实现与评估
4.1 原型系统实现
本文利用SDN 控制器可以对网络转发设备进行编程的特点,在SDN 环境中实现了M2NTO 的原型系统,其原型架构如图5 所示。考虑到SDN 交换机的部署成本,M2NTO 只在入口节点和出口节点部署SDN 交换机。在入口SDN 交换机处监听端节点发出的网络流,在接入端口收到数据包后根据流表项中的动作进行操作,若没有匹配的流表项则以Packet_in 的消息形式转发至SDN 控制器。SDN 控制器对捕获到的网络流进行识别和分类,根据网络层析探测包的类型制定相应的拓扑混淆策略,并通过下发流表项将混淆策略部署到出口SDN 交换机,出口SDN 交换机根据流表信息对探测包进行丢弃、延迟等混淆操作。
M2NTO 原型系统实现如图6 所示。在控制层,使用RYU 控制器[20]进行数据包特征处理和探测包检测,根据检测结果制定相应的流表策略并下发到SDN 交换机。在数据层,使用Mininet 仿真软件[21]实现网络拓扑构建和数据包处理相关的任务,包括数据包捕获和转发等操作。

图6 系统实现Fig.6 System implementation
RYU 控制器主要由3 个模块组成:流量监听器,流量检测器,流表管理器。流量监听器负责捕获OpenFlow 交换机接收的数据包,并对数据包进行预处理,例如提取数据包的基本特征(如IP 地址、网络服务、连接时间等)。流量检测器负责对数据包进行分类,检测模型设计为在线增量监督学习框架,分为离线训练和在线更新两部分,根据实时流量动态更新数据集和分类模型。流表管理器负责根据流量检测结果设计流表项,将流表项下发给出口SDN 交换机。
4.2 性能评估分析
为评估防御系统的性能,本文基于Mininet 构建Internet Topology Zoo[22]中 的3 种真实 网络拓 扑,分别代表小型网络、中型网络和大型网络,其网络拓扑信息如表4 所示。本文遵循树结构进行网络层析成像端到端测量,将拓扑中度数较低的节点(degree ≤2)视为端节点,并随机选择一个端节点作为源节点,其他端节点作为接收节点。随后,计算源节点到每个目的节点的最短路径,将所有最短路径组成网络层析成像探测网络。由于目前没有网络层析成像测量的公开数据集,因此本文用Python 的scapy 模块[23]生成网络层析成像探测包,从源节点发送到各个目的节点。同时,通过运行不同的网络应用程序来收集各种类型的网络流,包括网页浏览、文件传输、在线聊天和视频流等,并将这些数据包作为实验网络的背景网络流量进行重放,通过这种方式模拟真实的使用场景。
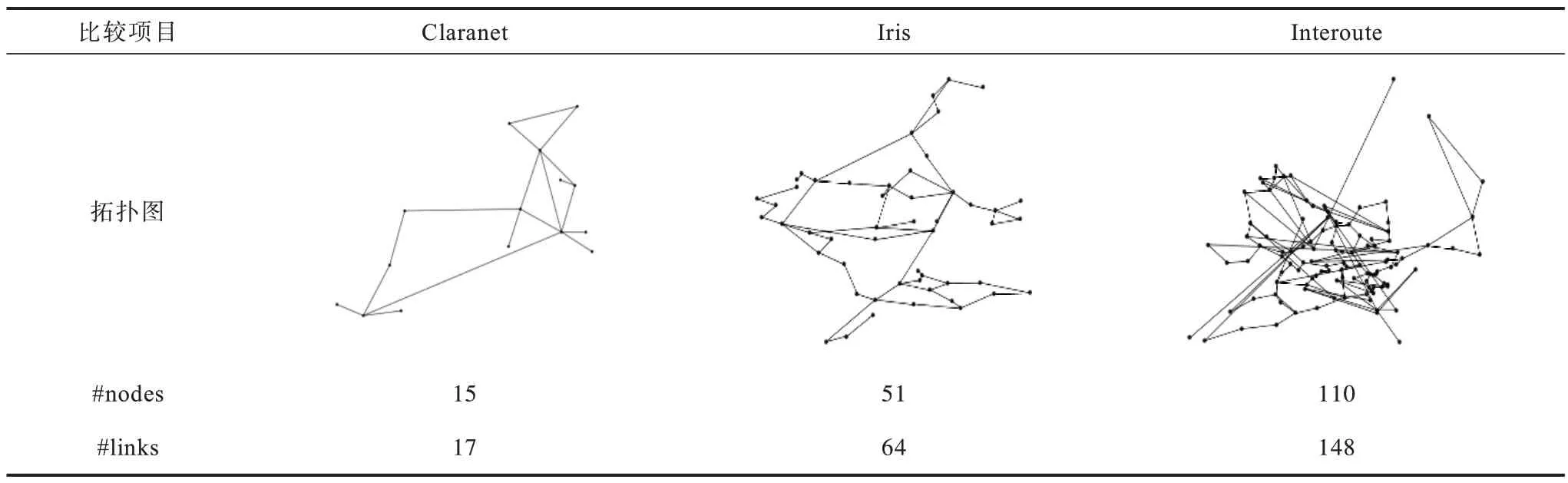
表4 网络拓扑信息Table 4 Network topology information
作为经典的网络层析成像拓扑推断方法,RNJ算法[14]推断准确率高、计算复杂度低,本文假设攻击者使用RNJ 算法推断目标网络拓扑。实验相关参数初始设置为λ=0.999 9、α=0.8、β=1.2、k=3,初始数据集的大小为1 000。本文在相同的实验设置下重复执行了100 次评估实验,并将其平均值作为最后的评估结果。
为了评估M2NTO 的流量检测性能,在实验中将M2NTO 与另外几种经典分类算法进行了对比:
1)M2NTO:使用基于在线增量更新的动态决策树算法对探测流量进行实时检测与分类。
2)ProTo:使用增量更新的半监督KNN 算法检测探测流量检测,不对探测流量的类型进行分类,统一对探测流执行延迟的拓扑混淆操作。
3)No update:使用没有在线增量更新的决策树算法检测流量。
4)Random Forest:使用随机森林算法检测探测流量,并对探测流量的测量模式进行分类。
5)SVM:使用SVM 算法检测探测流量,并对探测流量的测量模式进行分类。
6)s-M2NTO:不进行两步分类,直接使用增量更新的动态决策算法对网络流进行多分类。
4.2.1 流量检测性能评估
为评估M2NTO 在线流量检测的性能,本文使用了以下3 个性能指标:
1)探测流检测率:正确区分探测流和正常网络流的概率,即分类正确的网络流数量在所有网络流数量中的所占比例。假设网络流集D={(x1,y1),(x2,y2),…,(xn,yn)},其 中,x为网络 流,y={'normal','prob'}为网络流类别,yi='normal'表示网络流xi的真实类别是正常网络流。若yi'为第一棵决策树对网络流xi的分类结果,则探测流的检测率为:
2)误报率:正常网络流被识别为探测流的概率,即被错误识别的正常网络流数量占所有正常网络流数量之比。错误识别的正常网络流会视为探测流而被延迟或者丢弃,对网络性能造成一定的影响。因此,在网络层析成像流量检测中应尽可能降低误报率。误报率的定义为:
3)探测流分类准确率:探测流的类型分类正确的概率,即探测流的类型分类正确的数量占所有探测流数量的比例。假设探测流数据集Dprob={(x1',z1),(x2',z2),…,(xm',zm)},其中,zi是探测流xi'的真实类别,第2 棵决策树分类的结果为zi',则探测流量分类率为:
如图7 所示,本文评估了在初始设置下不同流量检测机制在不同规模的网络中的检测性能。由于ProTo 算法只能识别探测行为,探测流分类使用文本提出的动态决策树机制进行分类。从图中可看出,直接进行多分类的方法探测流识别准确率和分类正确率较低,误报率较其他方法高,而增量更新决策树算法的检测率、误报率和探测流分类准确率都要优于其他几种流量检测机制,在3 种不同规模的探测网络中本文提出的增量更新决策树流量检测算法识别探测流的准确率都达到了98%,误报率维持在2%左右,探测流分类准确率达到95%以上。实验结果表明本文提出的网络层析成像流量检测机制能够准确识别网络层析成像探测模式,抵御攻击者实施的基于网络层析成像技术的网络拓扑推断。

图7 流量检测性能Fig.7 Traffic detection performance
初始训练数据集的规模对流量检测系统的性能有很大的影响,不同初始训练集规模下的检测性能如表5 所示。
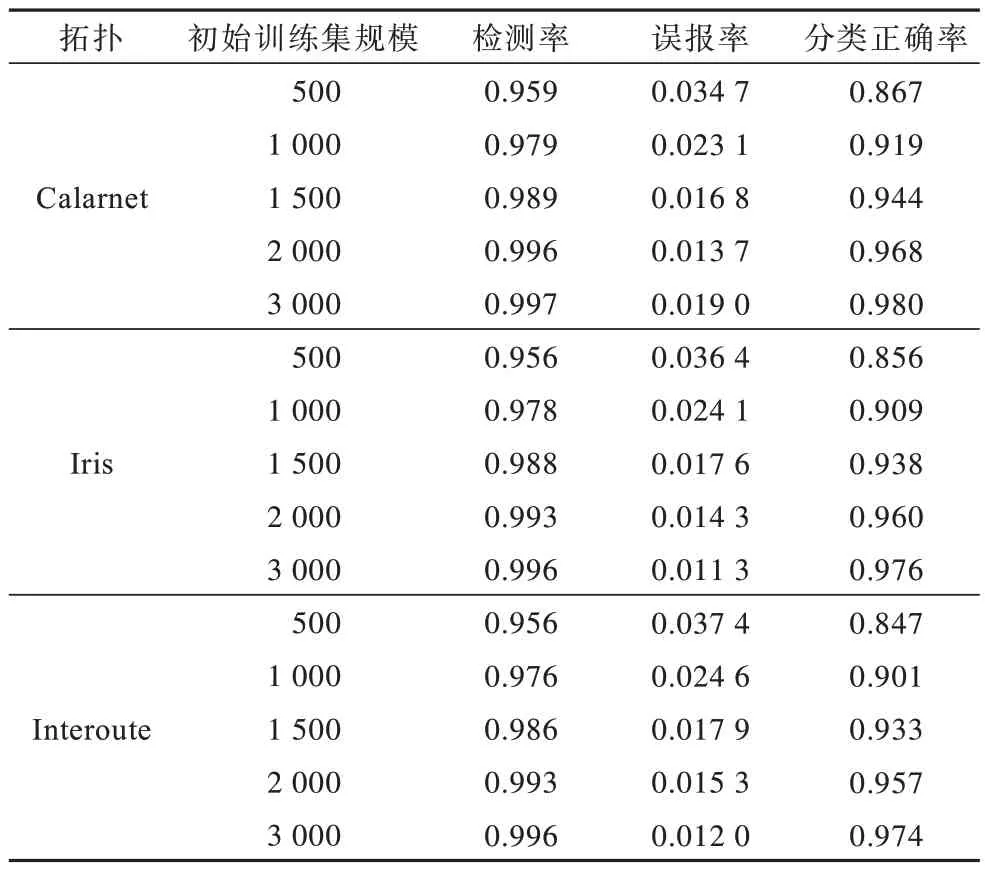
表5 不同初始训练集规模下的检测性能Table 5 Detection performance under different initial training set sizes
由表5 可以看出,当初始训练集规模从500 增加到3 000 时,不同规模的网络中的探测流检测率和探测流类型分类正确率都大幅提高,同时误报率也有所下降。
决策树根据节点密度的下限和上限值动态更新,枝剪节点密度低于下限的节点,分裂节点密度大于上限的节点。决策树的复杂度和分类准确率与参数α和β有关,图8 显示了α和β取不同值时,随着时间推移网络流数量增加探测流检测率、误报率和探测流分类准确率的变化。实验结果表明,流量检测机制在线后,随着网络中流的数量增加,探测流的检测率和分类准确率也随之增大,误报率随之下降,并且检测率和分类准确率呈现随着α的增大和β的减小而增加的趋势。然而,并不是β值越大越好,过度的生长会导致决策树过于复杂,增加动态更新和分类过程的时间花销。实时流量检测系统要对准确率和实时性进行平衡,在保证高准确率的同时也能够对实时到达的流进行快速分类,减少对网络性能的影响。

图8 参数α 和β 对检测性能的影响Fig.8 Influence of parameters α and β on detection performance
此外,探测流是以块为单位提取特征,探测流分类的准确率还与块的大小即k值相关。图9 展示了探测流分类准确率与k值的关系,在k=3 时探测流分类准确率最高。这是因为“三明治”探测是以3 个小包夹着一个大包的数据包组的方式进行探测,4 个探测流为一块提取的特征更具代表性。
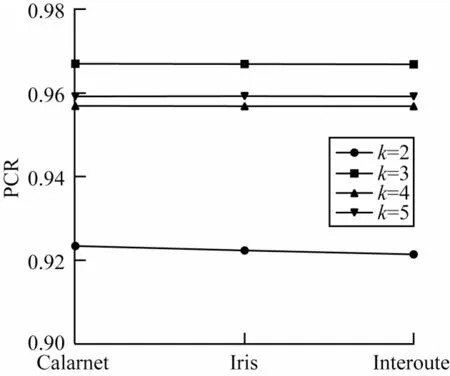
图9 探测流分类准确率与k 值的关系Fig.9 Relation between classification accuracy of probe flow and the value of k
4.2.2 混淆效果评估
网络拓扑混淆的目标是混淆攻击者的测量结果使其推断出虚假的网络拓扑,攻击者推断的虚假拓扑与真实网络拓扑之间的差距越大表示混淆效果越好,网络拓扑混淆机制对抗网络层析成像探测行为的有效性越高。树编辑距离是衡量两棵树之间差异性的常用指标[24],表示通过替换、插入、删除等编辑操作将一棵树转换为另一颗树的成本。为了使评估更加直观,本文使用相似度分数进行评估,其公式如下:
Ssimi的取值范围为[0,1],TED(T')表示真实网络拓扑T转化为攻击者推断的虚假网络拓扑T'之间的编辑成本,TED(T)表示从头构建T所需的编辑成本,TED(T')表示从头构建T'的编辑成本。真实网络拓扑与攻击者推断的虚假拓扑相似度越大,Ssimi的值越大,当两个网络拓扑完全相同时,Ssimi=1。
由于攻击者在用网络层析成像技术进行拓扑探测时,会根据网络负载情况调整探测模式并选择不同的网络性能指标作为端到端性能参数,因此,本文比较了当网络负载不同时,ProTo 拓扑混淆机制、AntiTomo 拓扑混淆机制和本文所提出的拓扑混淆机制在3 个不同规模的网络拓扑中的混淆效果。
实验结果如图10 所示,在网络没有任何防护措施时,攻击者推断的网络拓扑与真实网络拓扑的相似度较大。ProTo 和AntiTomo 只有在网络负载较低时才能降低攻击推断的网络拓扑与真实网络拓扑的相似性,混淆效果随着网络负载增加而变差,而M2NTO 在网络负载较小、网络负载适中和网络负载较大的情况下都能显著降低攻击者推断的网络拓扑与真实网络拓扑的相似性。这是因为AntiTomo 和ProTo 都只通过增加探测包的排队时延来混淆探测包的测量结果,而排队时延由“三明治”分组列车方法测量得到,但“三明治”分组列车测量方法只有在网络负载较小的时候测量结果较为准确,随着网络负载增大,出现链路拥塞的概率加大,探测包的排队时延会受到链路拥塞的影响,测量的准确降低,导致混淆效果变差,并且网络负载发生变化,攻击者可能会采用其他测量方法和其他性能指标,AntiTomo 不识别网络层析成像探测包,ProTo 没有对探测包的测量方法进行分类,两者都感知不到攻击者探测策略的变换。而M2NTO 不仅识别探测包的测量方法类型,还会根据网络负载变化调整混淆操作,可以有效对抗基于网络层析成像的拓扑推断。

图10 拓扑混淆性能对比Fig.10 Topology obfuscation performance comparison
4.2.3 实时性评估
在线分类对实时性有很高的要求,实时性的要求包含两个方面:快速的线上检测和快速的模型更新。为评估本文提出的网络层析成像流量检测机制的实时 性,本文在8 核2.30 GHz Intel®CoreTMi7-10875H CPU 和16 GB RAM 的电脑上,测试了在不同数据集规模中动态决策树模型更新和网络层析成像探测流检测与分类所消耗的平均时长,如图11 所示。模型更新和探测流实时检测分类的平均时长随着数据集规模增大而增加,在数据集规模为5 000时,识别探测流的平均时长约为2.4 ms,模型更新时间为1.5 ms,这说明探测流量检测机制可以在极短的时间内识别探测流,从而适应高速网络流环境。

图11 探测流检测与模型更新效率Fig.11 Efficiency of probe flow detection and model update
5 结束语
作为一种典型的网络侦察方法,攻击者使用网络层析成像技术可以准确推断目标网络拓扑结构,精准攻击网络中的关键链路和关键节点。为了对抗基于网络层析成像的拓扑推断,本文提出了对抗多模式网络层析成像的拓扑混淆机制M2NTO。M2NTO 的主要思想是使用增量更新的动态决策树算法识别攻击者的多样化探测行为,在此基础上根据测量方法类型和网络负载情况判断攻击者进行网络层析成像拓扑推断使用的网络性能参数,再对探测包进行相应的混淆操作,从而使攻击者得到错误的测量结果,推断出虚假的网络拓扑。最后,利用SDN 技术实现了M2NTO 的原型系统,并在几种不同规模的网络中进行了仿真实验。实验结果显示,M2NTO 能够以较高的准确率和实时性识别网络层析成像探测包和探测模式,在不同网络负载情况下也能达到较好的混淆效果。在下一步的工作中,作者将进一步优化探测流量检测算法,并结合多源混淆拓扑生成算法继续扩展M2NTO,提升混淆效果。
猜你喜欢
网络安全与数据管理(2022年2期)2022-05-23 13:25:46
自动化学报(2021年8期)2021-09-28 07:20:18
北京大学学报(自然科学版)(2021年3期)2021-07-16 07:13:40
矿产勘查(2020年5期)2020-12-25 02:38:52
电子制作(2018年23期)2018-12-26 01:01:16
爱你(2018年16期)2018-06-21 03:28:44
汽车维修技师(2017年10期)2017-03-17 02:25:01
电测与仪表(2016年5期)2016-04-22 01:13:46
指挥与控制学报(2015年4期)2015-11-01 10:09:34
雷达学报(2014年4期)2014-04-23 07:43:22
