
基于“嵩山”超级计算机的UCX 库分析与优化
2023-12-16 10:30:24李俊宏
计算机工程 2023年12期
刘 康,万 伟,刘 波,李俊宏,李 柱
(郑州大学 计算机与人工智能学院,郑州 450001)
0 概述
“嵩山”超级计算机部署于国家超级计算郑州中心,是我国国产自研的新一代超高性能计算平台,它采用32 核CPU+国产加速器的异构计算架构、InfiniBand(直译为“无限带宽”技术,缩写为IB)[1-2]超高速网络以及高性能分布式并行存储系统,理论峰值算力可达100 PFlops,整机实测性能达到65 PFlops。InfiniBand 是一个用于高性能计算平台的计算机网络通信标准,具有极高的吞吐量和极低的延迟,用于计算机与计算机之间的数据互连,也用作服务器与存储的互连以及存储系统之间的互连。InfiniBand搭载的Mellanox ConnectX-6 网卡提供了最高200 Gb/s带宽的数据传输性能。
“嵩山”计算平台所搭载的主要通信框架为UCX(Unified Communication X)[3-4]。UCX 作为底层InfiniBand 网络和上层并行编程模型的通信中间件,定义了一组统一的标准化通信编程接口,以满足主流的并行编程模型,如MPI(Message Passing Interface)[5]、UPC(Unified Parallel C)[6]、PGAS(Partitioned Global Address Space)[7]等的需求,同时又可以在各种高性能平台上实现,以便在互联网络上更好地满足高性能、可移植、可伸缩等并行应用的开发需求[8-10]。
但是,由于RDMA(Remote Direct Memory Access)系统具有复杂性,因此存在很多未知的问题[11-12],UCX 作为“嵩山”RDMA 系统中的通信框架,在“嵩山”特色互联网络架构上还有一定的优化空间。在存在复杂通信环境的集合通信中,通信有时会成为瓶颈而拖累了整体计算速度。UCX 的通信性能直接影响了上层并行编程模型的数据传输与计算性能。因此,在“嵩山”超级计算平台上对UCX 进行研究与优化具有重要的工程意义。
本文基于“嵩山”超级计算平台,以MPI 为例,使用osu_benchmark 测试工具[13]在不同的传输下进行多种集合通信测试,获得各种情形下的延迟与带宽数据,以发现节点设备存在的瓶颈。同时,对UCX的代码进行优化,以解决节点内通信占用网卡资源的问题。在此基础上,实现UCX 在“嵩山”超级计算平台上的最优传输选择,以提升平台的集合通信能力以及整体的计算性能。
1 “嵩山”超级计算机互联网络
1.1 InfiniBand 互联网络
InfiniBand 是一种高速互联网络,用于连接大型集群和超级计算机,它是目前应用最广泛的高速互连网络之一,2016 年在Top500 互连网络中就已经达到37.5%的份额[14]。InfiniBand 网络为通信提供了双边(发送-接收)和单边(RDMA)语义。InfiniBand上的通信使用队列对(QP)模型,其中,发送和接收队列分别用于发送和接收消息,工作请求被提交到这些队列中,硬件可以在队列中读取工作请求以执行通信。此外,将队列与每个QP 相关联,用于通知通信完成。在通过InfiniBand 进行通信时,需要注意注册硬件访问的所有内存区域。为了减少内存注册的开销,短消息(Short)可以内联到工作请求中,而较大的消息可以利用零拷贝(ZCopy)协议。这种策略意味着工作请求只获取内存缓冲区的描述信息,然后直接从缓冲区读取数据,而不需要CPU 的参与。
当前InfiniBand 结构实现了各种传输机制[15-16],最常见的是RC(面向连接的可靠连接)和UD(无连接的不可靠数据报),后者只实现了双边通信语义。此外,UD 一次只能传输一个MTU 的数据(通常是4 KB),而RC 通常能提供比UD 更高的带宽和更低的延迟,代价是RC 对资源有很高的要求:要完全连接N个进程;要求每个进程有O(N2)个连接和O(N)个队列对。而UD 是无连接的,因此,每个进程只需要一个UD 队列对。为了减少RC 的内存消耗,InfiniBand 规范引入了共享接受队列以及扩展的RC传输。Mellanox 后续又推出了动态连接(DC)传输服务[17],该服务动态地创建和销毁连接,将内存消耗限制在接近UD 的级别,同时提供与RC 类似的内存语义。然而,DC 的可扩展性设计是以性能为代价的,主要是因为存在连接事务的开销[18]。
InfiniBand 的用户 空间接口是Verbs API[19],它是一个带有OFED 堆栈的用户级别的库,位于内核级Verbs API 之上。内核API 与特定供应商的InfiniBand 驱动程序和驱动程序库协作,以实现InfiniBand 硬件访问。InfiniBand 软件栈示意图如图1 所示。

图1 InfiniBand 软件栈和UCXFig.1 InfiniBand software stack and UCX
1.2 Socket Direct 技术
随着数据量的指数级增长,使用者对服务器和计算资源提出了更高的性能要求,以便对海量数据进行实时分析。“嵩山”超级计算平台采用非均匀内存访问(NUMA)架构[20],每个处理器拥有4 个CPU Die,在每个Die 内集成了8 个物理核心,共计32 个物理核心。
在一般情况下,数据主要依靠GMI 总线来进行跨Die 传输,如图2(a)所示,此时Die3/Die4 中的数据如果要传输至网卡,则网络流量需要使用GMI 总线经过Die0/Die1 然后再流入网卡。而“嵩山”平台的网络架构支持Socket Direct 技术,该技术可以使节点中的每个Die(NUMA node)都可以通过其专用的PCIe 接口直接连接到网络,使得网络流量无须遍历内部总线(GMI)和其他Die,如图2(b)所示。Socket Direct 不仅降低了CPU 的利用率、增加了网络吞吐量,还显著降低了开销与延迟,从而提高了服务器的性能。

图2 跨Die 传输的对比Fig.2 Comparison of cross-Die transmission
1.3 UCX 设计
随着DPU 的普及以及各类DSA 芯片的广泛使用[21],如何在这之上抽象出统一的内存访问语义和统一的通信方式成为一个值得研究的问题,因此,UCX 应运而生。UCX 可以在通信方面实现低级别的软件开销,并且提供接近原生级别的性能。UCX旨在提供一个统一的抽象通信接口,能够适配任何通信设备,并支持各种应用的需求,从而满足当前高性能、可移植且稳定可靠的并行应用开发需求,同时还能通过持续的迭代更新来适应未来的高速互联网络。
从图1 可以看出UCX 软件堆栈是如何放置在InfiniBand 之上的,UCX 由下层UCT 和上层UCP 这2 层组成。下文将介绍UCX 框架,讨论UCP 和UCT这2 个层之间的主要区别以及UCX 内部最重要的语义。
1.3.1 UCX 框架
UCX 利用高速网络进行节点间通信,并利用共享内存机制进行有效的节点内通信。UCX 总体采用分层结构公开一组抽象通信原语,这些原语充分利用了可用的硬件资源和负载,其中包括RDMA[22-23](InfiniBand 和RoCE)、TCP、共享内存和网络原子操作。图3 显示了UCX 的软件栈结构。
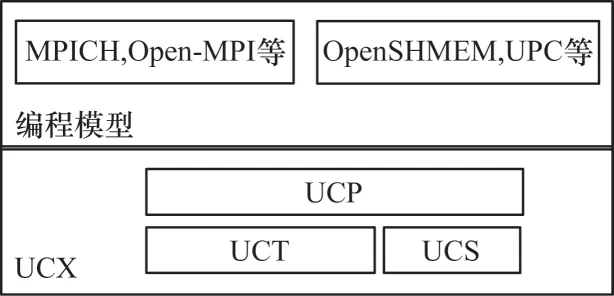
图3 UCX 软件栈结构Fig.3 UCX software stack structure
UCX 通过提供高级API 促进快速开发,屏蔽低层细节,同时保持高性能和可伸缩性,其框架主要由3 个组件组成,即UCS(UC-Services)、UCT(UCTransports)和UCP(UC-Protocols)。每一 个组件都导出一个公共API,可以作为一个独立的库使用。底层的UCT 适配各种通信设备,上层的UCP 则是在UCT 不同设备的基础上封装更抽象的通信接口,以方便使用。
UCT 是传输层,它抽象了各种硬件架构之间的差异,并提供了一个支持通信协议实现的低级API,从单机的共享内存到常用的TCP Socket 以及“嵩山”超算底层的InfiniBand 协议,都有很好的支持。该层的主要目标是提供对硬件网络功能的直接有效访问,为此,UCT 依赖供应商提供的低级驱动程序,如InfiniBand Verbs、Cray 的uGNI 等。此外,该层还提供用于通信上下文管理(基于线程和应用程序级别)以及分配和管理的构造。在通信API 方面,UCT 定义了立即(short)、缓冲复制、发送(BCopy)和零拷贝(ZCopy)等通信操作的接口。
UCP 是协议层,通过使用UCT 层公开的较低级别功能来实现上层高级编程模型(如MPI、UPC、PGAS)所使用的较高级别协议。UCP 提供的功能是能够为通信选择不同的传输、消息分段、多轨通信以及初始化和完成库。目前,API 具有的接口类别包括初始化、远程内存访问(RMA)通信、原子内存操作(AMO)、活动消息(Active Message)、标签匹配(Tag-Matching)和集合(Collectives)。
1.3.2 UCX 语义
UCX 提供的最主要语义包括通信上下文、通信原语、通信实体和连接建立。这4 种语义详细叙述如下:
1)通信上下文。UCP 和UCT 的最主要区别在于通信上下文。UCT 被设计成一个位于单个通信设备和传输层之上的通信层,而UCP 可以让用户操作不同的设备和传输层。因此,UCT 在设备(如InfiniBand、共享内存SM)上定义了一个内存域,用来分配和注册进行通信的内存以及特定设备(如InfiniBand 上的UD 和RC)上的特定传输接口。内存域和接口都有一组它们自己的属性,这些属性来自于硬件功能。内存域属性包括内存分配限制和内存访问的凭据,接口属性包括传输机制的通信和连接能力以及协议切换的阈值。UCP 将这些多个UCT内存域和接口封装在单个通信上下文中,并根据硬件属性和性能指标选择适合通信操作的接口。
3)通信实体。Worker 是UCX、UCP 和UCT 的核心通信实体。Worker 的主要特征是有自己的进度引擎(progress engine),进度引擎会在所有打开的接口上强制执行当前的进度。在Worker 要启用与另一个进程的通信时,每个进程都会创建一个端点(endpoint),并将其连接到远程进程的endpoint。UCT endpoint 与特定接口(如UD、RC)绑定,即每个使用的接口对应一个UCT endpoint,而UCP endpoint拥有多个UCT endpoint。因此,在UCP 中,endpoint始终连接着2 个Worker。在内部,UCP 负责从可用于执行通信操作的接口/UCT endpoint 中选择最佳的接口/UCT endpoint。
4)连接建立。当UCP 的Worker 创建endpoint时,UCP 层为每种类型的操作选择一个或多个接口,并且在每个接口上创建并对应一个UCT endpoint,所有的这些UCT endpoint 都与父UCP endpoint 相关联。如果一个接口对应无连接的传输,那么它可以立即连接到远程接口,这也就是UCP 中发生的情况,即UCT endpoint 通过无连接传输立即建立连接。但是,如果接口对应P2P 的传输,UCP 将创建一个stub endpoint。Wireup UCT endpoint 始终是无连接的,通过立即发送Wireup 请求然后通过P2P 传输以实现所有UCT endpoint 的连接。当父UCP endpoint 的所有UCT endpoint 都已连接时,stub endpoint 即被销 毁。
2 UCX 在“嵩山”中的优化
2.1 参数调优
UCX 可以适配多种设备、系统、架构等,因而具有繁杂的参数设置,调整各项参数可以使UCX 更加适配“嵩山”平台。
“嵩山”平台的高速网络使用Socket Direct技术划分CPU 为4 个NUMA nodes 并分别连接至4 块网卡设备,实现各个Die 与网卡的直连。在UCX 中设置UCX_MAX_RNDV_LANES 为4,为Rendezvous 协 议开启4 端口的多轨传输,使用多块网卡同时进行传输,从而提升数据的传输效率。
“嵩山”平台CPU 使用的NUMA 架构,在PCIe总线传输中更适合采用宽松排序(relaxed order)的事务排序方法,即允许PCIe 交换开关,将软件确认过的事务重排在其他事务之前发送,这样既提升了PCIe 总线效率,又能保证程序如期执行。本文使用UCX_IB_PCI_RELAXED_ORDERING=on 在UCX 中开启宽松排序,使得所有使用UCX 通信库的程序采用宽松排序,从而获得更高的性能。
2.2 网卡占用优化
在使用UCX 进行节点内部通信时,进程间通信不仅会使用共享内存传输,还会调用网卡设备共同完成数据传输,这是由于ITIGIN[4]为UCX 添加了实现,即进行进程间通信时rc 会辅助共享通信,从而共同完成通信。但是在“嵩山”平台上,实测IB 网卡对多进程的通信支持相较于共享内存并不友好,多进程会平分网卡带宽,导致整体性能下降。而在进行大规模节点运算时,网卡是节点间通信的主力设备,应该尽可能地保证网卡用于跨节点传输。因此,需要对UCX 的传输逻辑进行修改,使其在进行节点间通信时不使用网卡。
以MPI 为例,在其进行通信时,UCX 会调用远程内存访问(RMA)[24]和活动消息(AM)等操作来实现快速的节点间通信。在涉及进程间通信时,UCX同样也会选择网卡来调用这些操作进行传输。
在“嵩山”超级计算平台中,MPI 节点内通信使用的设备有memory 和mlx5。memory 会调用am、am_bw 和 rma_bw 操 作;mlx5 网卡会调用am_bw 和rma_bw 操作。因此,mlx5 网卡在节点内通信时所调用的操作完全可以被memory 所取代。程序调用am_bw 和rma_bw 操作之 前,UCT 会执行ucp_wireup_add_bw_lanes 函数,选出合适的传输,以此建立支持相应功能的endpoint。对此函数进行分析可以发现,函数调用ucp_wireup_select_transport,根据bitmap 选出支持am_bw 或rma_bw 的传输,随后函数将传输放入ep 的配置文件中,等待endpoint 的创建,这些操作都发生在连接的准备阶段。
在实验确定的最佳色谱条件下,选取1#果酒样品,分别加入10,50,100 mg/L标准混合溶液,平行进行6次实验,实验结果见表3。回收率为81.6%~102.8%,相对平均偏差不大于4.4%,说明方法精密度高,准确度好。
本文在ucp_wireup_add_bw_lanes 函数中添加判断。在函数循环搜寻可用传输并将其添加到设备的dev_bitmap 后,读取出Worker 的上下文信息,判断此时的设备是否为共享内存传输:如果是共享内存传输,则break 跳出循环,不再搜索额外的传输;如果不是共享内存传输,则正常循环,搜寻可用传输。修改后的程序流程如图4 所示,可以这样做的原因是搜索过程中的设备次序memory 排在mlx5 网卡之前,当选择出共享内存传输时,函数退出,便不会检索到mlx5 网卡,从而在进行节点内的进程间通信时只使用共享内存通信而不是网卡传输。

图4 优化后的程序流程Fig.4 Optimized program procedure
使用osu_benchmark 以4 MB 包长测得单节点内2~32 进程的alltoall 集合通信延迟数据,如图5 所示,其中,before 是优化前同时使用网卡rc 传输和共享内存传输的通信数据,after 是仅使用共享内存传输的通信数据。从图5 可以看出,在节点内通信时,随着PPN(Processes Per Node)的增加,2 种传输方式的延迟差距愈加明显,优化后的通信延迟相较于优化前最多降低了70%。
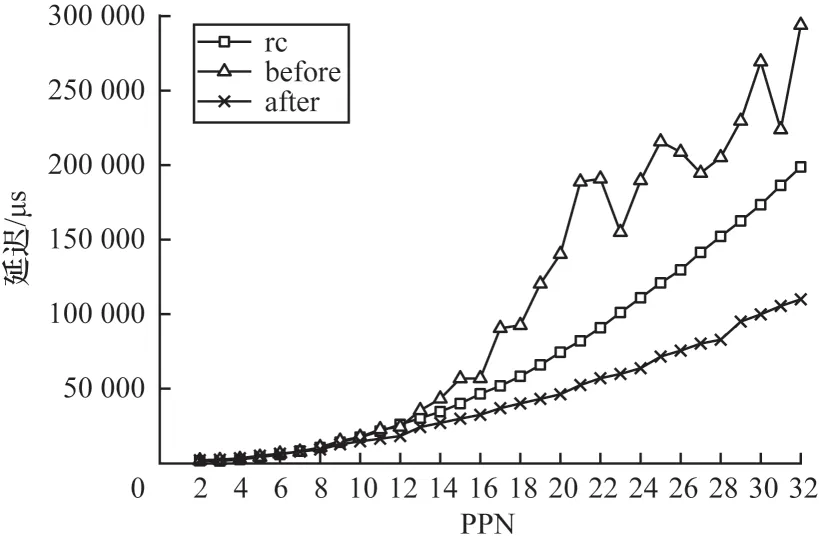
图5 节点内alltoall 测试结果Fig.5 Intra-node alltoall test results
测试不同PPN 下的点对点通信带宽数据,如图6所示。从中可以明显看出,在PPN 大于8 时,仅使用共享内存传输的通信性能优于使用IB 网卡的通信性能,此外,如果节点内的进程间通信使用了网卡传输,在绝大多数情况下,网卡通信还会对本来的进程间通信造成负面影响,降低整体的通信带宽性能。

图6 节点内点对点带宽测试结果Fig.6 Intra-node p2p bandwidth test results
2.3 共享内存通信选择优化
“嵩山”平台的MPI 库中存在不同的节点内通信机制,图7 主要展示了其中的2 种。传统的双副本拷贝的共享内存实现,其传输数据涉及一个共享的缓冲区空间,由本地进程来交换消息,如图7(a)所示。但是,这种方式仅适用于小消息,对于较大的消息,双副本拷贝会给CPU 带来额外的负担,导致缓存污染和带宽的浪费。图7(b)展示了支持内核辅助的共享内存传输实现[25],传输实现依靠内核的援助,内核模块可以为节点内通信提供单拷贝机制,在传输较大消息时会大幅提升传输效率。

图7 2 种共享内存通信机制Fig.7 Two shared memory communication mechanisms
对于第2 种通信方式,“嵩山”平台的MPI 库支持CMA 和KNEM[26]这2 种内核模块。CMA 引入了2 个系统调用,分别是process_vm_readv 和process_vm_writev,它们根据进程的PID 和远程虚拟地址直接读写另一个进程的内存[27]。对于使用KNEM 内核的通信,发送进程在KNEM 驱动中声明一个发送缓冲区(不管是否连续),并将相应的标识符cookie传递给接收进程,接收进程接收到cookie 并请求KNEM 驱动从cookie 缓冲区复制到它的本地缓冲区(连续或非连续)[26]。
本文使用osu_benchmark 分别指定CMA 和KNEM 传输,测得2 种共享内存通信的带宽与延迟如表1 所示。在“嵩山”超算平台下对输出的UCX 日志进行分析发现,节点在进行共享内存传输时,无论何种情况都只会选择CMA 进行通信,并不会选择带宽更高、延迟更低的KNEM。
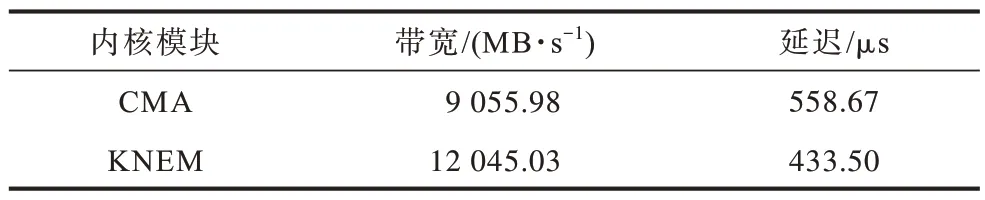
表1 CMA 与KNEM 的性能参数Table 1 Performance parameters of the CMA and KNEM
进程间在进行共享内存通信时,通过rma_bw 操作来进行高速的远程内存访问。在建立连接前,UCT 会根据UCX 提供的一套公式来计算传输评分,选出rma_bw 中评分最高的传输,添加到连接通道(lanes)中。
本文对rma_bw 操作传输选择的评分机制进行分析。在UCT 中,计算评分时以256 KB 的消息大小为基准,调用rma_bw 操作的传输的评分为时间开销的倒数,如式(1)所示:
设mcost为内存域注册开销,注册开销近似为一个线性函数,如式(2)所示:
其中:omd为固定开销;ggrowth为增长系数;ssize为数据大小(256 KB)。设bl和br分别为本地和远程的带宽大小,因此,总开销为256 KB 消息的传输时延、内存注册开销mcost与传输接口间延迟llr的累加,如下:
对于节点中的每个进程,其带宽b在UCX 中的计算方式如式(4)所示:
其中:bdedicated为专用带宽;bshared为共享带宽。
对平台的UCX 源代码进行分析,可以发现:在UCX 1.9.0 的带宽设置下,CMA 拥有11 145.00 MB的dedicated 带 宽,而KNEM 是13 862 MB 的shared带宽。根据srma的计算公式,在PPN 不为1 时,UCX在计算KNEM 和CMA 的rma_bw 评分时带宽会存在巨大差异,从而导致永远不会选择KNEM 传输。这是因为早期KNEM 对多进程支持不如CMA,单进程时KNEM 会有更高的带宽,但是存在多进程通信时,KNEM 性能将不如CMA,因而将KNEM 带宽值设置为shared。但是,“嵩山”超级计算平台所具有的优化KNEM 对多进程的支持极好,同时支持高性能单拷贝消息传输。因此,本文将KNEM 的带宽从shared 改为dedicated,使KNEM 获得了更合理的评分,从而在进行集合通信时共享内存方面的传输会更多地选择带宽更高、延迟更低的KNEM。
在大部分通信中,KNEM 和CMA 两者差异较小,但是在涉及节点内进程间gather 通信时,KNEM内核相对CMA 内核有较为明显的性能提升,并且随着PPN 的增加提升效果愈加明显,如图8 所示。

图8 节点内gather 测试结果Fig.8 Intra-node gather test results
3 数据测试与验证
3.1 实验环境
在“嵩山”超级计算机的固化节点上进行实验,单个节点配置为32 核2.0 GHz CPU,网卡采用Mellanox ConnectX-6,以HDR 模式(200 Gb/s)工作。操作系统为CentOS 7.6,内核版本为3.10.0-957.el7.x86_64。
在本次测试中,使用的MPI 版本为Open MPI v4.0.4rc3,它在平台的共享内存通信时支持KNEM和CMA 内核。使用的HPCX 版本为2.7.4,UCX 版本为UCX 1.9。对于点到点和集合通信测试,使用osu_benchmark v5.5 来测试并记录通信性能数据。在性能测试对比数据中,before 的通信底层是目前在用的由ITIGIN 优化后的UCX 正式版本,after 采用本文优化后的UCX 库。
3.2 节点内集合通信测试
首先测试优化后的UCX 库在单节点内的通信表现。图9~图11 展示了单节点内不同PPN 下的4 MB 包长的MPI 集合通信测试数据,横坐标为使用核心数(总进程数),纵坐标为平均通信延迟,每个核心绑定一个进程进行通信。从中可以看出,使用优化后UCX 的MPI 集合通信能力有了明显提升,alltoall 的通信性能提升尤为明显,延迟最多降至优化前的30%(图9),gather 的通信延迟最多约降至优化前的55%(图10),allreduce 的通信延迟最多约降至优化前的69%(图11)。

图9 优化前后节点内alltoall 测试结果Fig.9 Intra-node alltoall test results before and after optimization

图10 优化前后节点内gather 测试结果Fig.10 Intra-node gather test results before and after optimization

图11 优化前后节点内allreduce 测试结果Fig.11 Intra-node allreduce test results before and after optimization
3.3 节点间集合通信测试
对于节点间的集合通信,本文对2 个规模(32 节点和100 节点)进行测试。对于32 节点的规模,选取分属lka 2 个交换机的32 个节点,每个交换机16 个节点,测试消息包长为1 MB。经过测试发现,在节点间集合通信时,其他集合通信测试效果与优化前一致,allgather通信产生了较为明显的差异,如图12 所示。
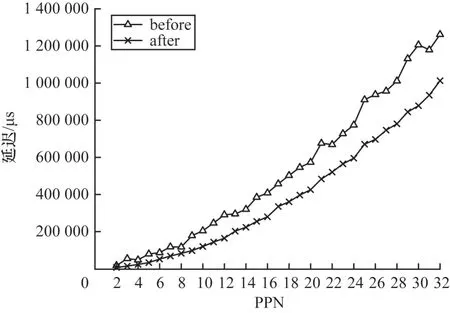
图12 32 节点allgather 测试结果Fig.12 32 nodes allgather test results
本文在8 箱的节点中随机选择100 个节点,进行100 个节点间的集合通信测试,获得节点间的2~18 PPN 下1 MB 包长的集合通信延迟数据。从图13 可以看出,优化后的UCX 在allgather 集合通信中取得了极为明显的优化效果,延迟最多可降至原来的20%,并且随着进程的增多差距逐渐变大。其他的集合通信测试优化前后数据基本保持一致。

图13 100 节点allgather 测试结果Fig.13 100 nodes allgather test results
4 结束语
“嵩山”超级计算平台支持多种并行编程模型,对高速互联网络进行优化有助于提升平台的整体通信性能,为平台的并行编程模型提供良好的底层通信支持。本文对“嵩山”超级计算平台上的节点进行测试,获得了节点间与节点内的通信性能数据,并且发现IB 网卡在节点内多PPN 通信中存在的局限性。然后,对平台的主要通信框架UCX 进行分析与优化,解决了节点内进程间通信占用网卡的问题,同时改善了UCX 对共享内存传输的选择机制。优化后的UCX 对大PPN 下的节点间allgather 集合通信以及节点内的进程间集合通信性能提升效果明显。
由于RDMA 具有复杂性,很多因素都可能影响RDMA 系统的整体通信性能。下一步将找出其他制约节点间通信速度的因素,对算法进行改进,使得节点间的其他集合通信能力得到加强。此外,UCX 根据PPN 来预测带宽,依此带宽来选择传输,这种带宽计算方法还不够准确,未来将对此进行改进,从而改善UCX 的传输选择评分机制。
猜你喜欢
科技与创新(2023年17期)2023-09-17 12:26:12
山西电子技术(2019年4期)2019-09-07 08:00:34
网络安全和信息化(2019年1期)2019-02-15 02:45:42
作文评点报·低幼版(2019年48期)2019-01-03 02:01:08
艺术品鉴(2017年8期)2017-09-08 02:20:42
科技风(2017年20期)2017-07-10 18:56:06
测绘科学与工程(2017年5期)2017-05-07 06:30:40
电脑爱好者(2015年15期)2015-09-10 07:22:44
电子世界(2014年21期)2014-04-29 06:41:36
组合机床与自动化加工技术(2013年1期)2013-12-23 04:47:02
