
基于微分博弈的追逃问题最优策略设计
2021-09-28 07:20:18郑晓帅林业茗夏元清
自动化学报 2021年8期
刘 坤 郑晓帅 林业茗 韩 乐 夏元清
在追逃问题中,智能体需要完成追击或防御任务,如多无人机对抗[1]、飞行器轨迹规划[2]、无人机打击[3]等.近年来,追逃问题受到了广泛的关注,Zhou等利用维诺图分割区域的方法研究了有限区域内多个追捕者对单个逃跑者的抓捕[4],De Simone 等利用模型预测控制方法研究了存在障碍物的追逃问题[5].博弈论易于建立不同博弈者之间的策略交互模型,且博弈者的策略选择过程即是系统内部的合作或竞争过程.因此,利用博弈论的方法研究追逃问题逐渐成为热点[6-8].
在经典的追逃问题中,系统包含两组对立的博弈者,一组博弈者作为追捕者,另一组博弈者作为逃跑者.Isaacs 利用微分博弈方法研究了单个追捕者、单个逃跑者的追逃问题,通过定性微分博弈方法获得了追逃双方的胜利区域,并求解出了追逃双方的最优策略[6].进一步,Fang 等研究了单个逃跑者和多个追捕者的追逃博弈问题[7],Lin 等研究了有限观测信息下的追逃微分博弈问题[8].
在导弹打击、无人机对抗等实际场景中,通常要考虑存在目标的追逃问题.此时,攻击者相对于目标扮演追捕者的角色,相对于防御者扮演逃跑者的角色.因此,攻击者在抓捕目标的同时需要避免被防御者拦截,防御者在保护目标的同时力图捕获攻击者.当目标为静态时,该问题转化为两人博弈问题.Pachter 等研究了相同速度下攻击者和防御者的追逃问题[9].Venkatesan 等给出了不同速度下攻击者和防御者的最优策略,并分析了防御者捕获半径非零的情形[10].当目标为动态时,Li 等基于线性二次型微分博弈,获得了目标固定、目标以任意轨迹运动及目标采取逃跑策略时攻击者与防御者的最优策略[11].Garcia 等采用零和博弈的框架处理主动目标防御问题,以攻击者和目标的终端距离作为性能函数,给出了各智能体的闭环最优状态反馈策略并得到了博弈的值函数[12].Liang 等采用定性微分博弈方法,以胜利时间作为性能函数,获得了基于界栅的双方最优策略和最优轨迹[13].以上结果仅仅考虑了单个攻击者、单个防御者的情形.
针对多个攻击者或防御者,Casbeer 等讨论了两个防御者、一个攻击者的情形,给出了双方的最优策略和安全区域[14].Chen 等考虑了数量相同的攻击者和防御者在有障碍物的二维区域内进行博弈,将目标分配算法与经典的Hamilton-Jacobi-Isaacs方法相结合,获得了每个攻击者和防御者相应的最优状态反馈策略[15].Coon 等考虑了任意数量攻击者和防御者的场景,通过等时线的交点确定防御者是否可以成功拦截攻击者,最后给出了攻击者在偏离预定轨迹时仍能被捕获的充分条件[16].Chipade 等结合估计函数方法优化目标函数,利用Lyapunov 方法获得了攻击者、防御者的最优策略[17].Yan等通过构建界栅划分多个追捕者、单个逃跑者的胜利区域,并结合任务分配和整数规划算法,最大化追捕者捕获逃跑者的数量[18].Garcia 等将微分博弈理论与任务分配算法相结合来研究多个追捕者、多个逃跑者的边界防御问题,求解出了追逃双方的最优策略[19].Sin 等考虑了多个防御者合作拦截多个攻击者的目标防御问题,给出了目标沿固定轨迹运动时攻防双方的最优策略,但未考虑攻击者、防御者各自内部的通信问题[20].以上研究通常涉及任务分配,在智能体规模较大时,求解较为困难.
为了便于求解大规模问题,Li 等考虑了追逃双方之间的通信,将基于图论的控制律引入追逃问题,但仅获得了追逃双方的局部最优策略[21].在有些实际场景中,要求博弈的某一方内部的所有智能体在保持聚合状态的同时完成一定的任务,即保持较近的距离,从而保证彼此的通信连接.Mejia 等讨论了一组追捕者追捕一组逃跑者的情形,基于通信拓扑图考虑了有限时间捕获和渐近会合情况,给出了追逃双方在各自聚合状态下的纳什均衡策略和最大最小策略,但仅考虑了追逃两方之间的博弈[22].
基于以上的分析讨论,本文主要研究基于线性二次型微分博弈的多个攻击者、多个防御者和单个目标的追逃问题.首先,针对攻击者、防御者保持聚合状态的情形,分别给出了目标按固定轨迹运动和目标采取逃跑运动时攻防双方的最优策略.然后,针对攻击者、防御者保持分散状态的情形,采用二分图最大匹配算法为防御者匹配攻击者,将多个攻击者、多个防御者的追逃问题转化为多组两人零和微分博弈,求解出了攻防双方的最优策略.最后,数值仿真验证了所提策略的有效性.
符号说明. R 表示实数域; Rn表示n维实数列向量组成的集合; Rn×m表示n×m维实数矩阵组成的集合;In表示n×n维的单位矩阵; 0m×n表示m×n维的零矩阵;AT表示矩阵A的转置;A-1表示矩阵A的逆;M表示邻接矩阵;A≻0(A≽0) 表示矩阵A是实对称正定(半正定) 矩阵;A≺0(A≼0) 表示矩阵A是实对称负定(半负定)矩阵;⋆表示对称矩阵中的对称块; b lkdiag{A1,···,An} 表示分块对角矩阵,其主对角线上为方块矩阵A1,···,An;‖x‖表示向量x的欧几里得范数,;A⊗B表示矩阵A和矩阵B的Kronecker 积.
1 问题描述
本文中,追逃博弈问题考虑存在目标、攻击者和防御者三方,攻击者试图攻击目标,而防御者试图拦截攻击者以阻止其攻击目标.当攻击者捕获目标或者防御者成功拦截攻击者时,博弈结束.攻击方的任务是在保持聚合状态的同时攻击目标,而防御方的任务在保持聚合状态的同时保护目标,拦截攻击方.
1.1 系统通信拓扑的图描述
定义 1.有向图Gd=(Vd,Ed) 表示防御方的通信拓扑,其中,Vd={1,2,···,m} 表示m个防御者的集合,Ed ⊆Vd×Vd表示防御方内部边的集合.对于边 (i,p),其权重为αip≥0.防御者i在图Gd中的邻居集合用Nd(i) 来表示.定义Dd为关联矩阵,Wd为权重矩阵,那么图Gd的Laplacian 矩阵为Ld=定义2.有向图Ga=(Va,Ea) 表示攻击方的通信拓扑,其中,Va={1,2,···,l} 表示l个攻击者的集合.Ea ⊆Va×Va表示攻击者内部边的集合.赋予边 (j,q) 权重值βjq≥0.攻击者j在图Ga中的邻居集合用Na(j) 来表示.定义Da为关联矩阵,Wa为权重矩阵,那么图Ga的Laplacian 矩阵为La=
定义3.二分图G=(V,E) 为有向图,表示攻击方和防御方之间的通信拓扑,其中,V=Vd ∪Va={1,2,···,m,m+1,···,m+l} 表示m个防御者和l个攻击者的集合,E⊆V×V表示双方之间边的集合.图G=(V,E) 只包含攻防双方之间的通信而不包含各自内部的通信.边 (p,q) 表示防御者p可以获取攻击者q的信息,赋予其权重γpq≥0;反之,边(q,p) 表示攻击者q可以获取防御者p的信息.智能体r在图G中的全部邻居用集合N(r) 来表示.定义D为关联矩阵,W为权重矩阵,那么图G的Laplacian 矩阵为L=DWDT.
假设 1.对于追逃博弈问题,假设攻击方、防御方都能获取目标的状态信息,且能够获取邻居的状态信息.图Gd=(Vd,Ed) 和Ga=(Va,Ea) 都是连通图.
1.2 目标沿固定轨迹运动时的攻防博弈建模
下面对攻防双方在保持各自聚合状态,目标沿固定轨迹运动时的追逃博弈问题进行建模.
防御方具有m个防御者,其状态方程如下:

目标沿固定轨迹运动的状态方程如下:

防御方需要在保持聚合状态的同时保护目标,并拦截攻击方.因此,防御者i需要优化的加权距离可以表示为:
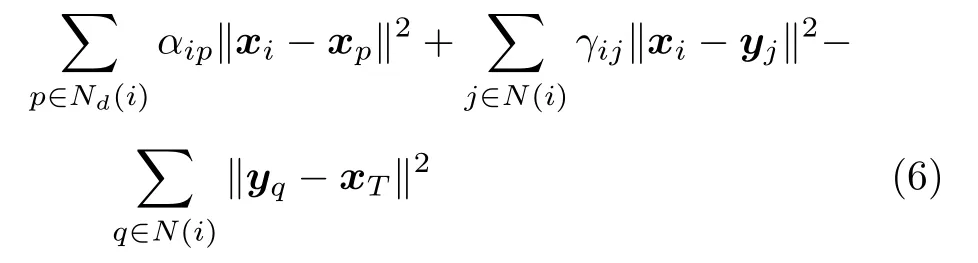
其中,第一项是防御者i与其邻居Nd(i) 的距离加权和,为防御者聚合项,第二项是防御者i与其可以观测到的攻击者N(i) 的距离加权和,第三项为防御者i可以观测到的攻击者N(i) 和目标T的距离之和.
加权距离式(6)可以转化为如下形式:
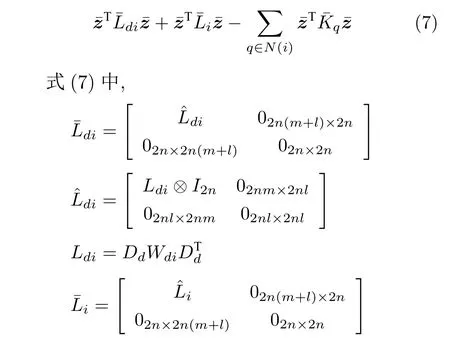
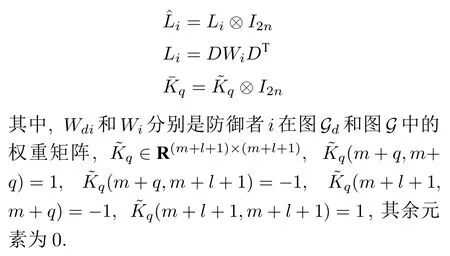
类似地,攻击方的任务是在保持聚合状态的同时捕获目标.因此,攻击者j需要优化的加权距离可以表示为:
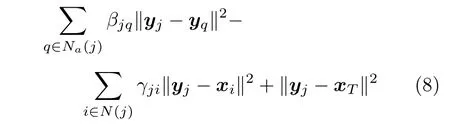
其中,第一项是攻击者j与其邻居Na(j) 的距离加权和,为攻击者聚合项,第二项是攻击者j与其可以观测到的防御者N(j) 的距离加权和,第三项为攻击者j与目标T的距离.
加权距离式(8)可以转化为如下形式:

在博弈过程中,每个智能体需要最小化自己的成本函数,用v-i表示防御者i可观测到的所有攻击者策略的加权和,即:


2 主要结果
本节首先给出目标按固定轨迹运动时的攻防双方的最优策略,并进一步设计目标采取逃跑运动时的攻防双方的最优策略.然后,针对攻防双方保持分散状态的情形,采用二分图最大匹配算法为防御者匹配攻击者,将多个攻击者、多个防御者的追逃问题转化为多组两人零和微分博弈进行求解.
2.1 目标沿固定轨迹运动时的攻防双方的最优策略
根据式(5)、式(10)和式(11)博弈模型,下面定理给出攻击者、防御者双方在保持各自聚合状态下的最优状态反馈策略.
定理 1.考虑系统(5),防御者i和攻击者j的成本函数分别为式(10)和式(11),那么,防御者i的最优策略




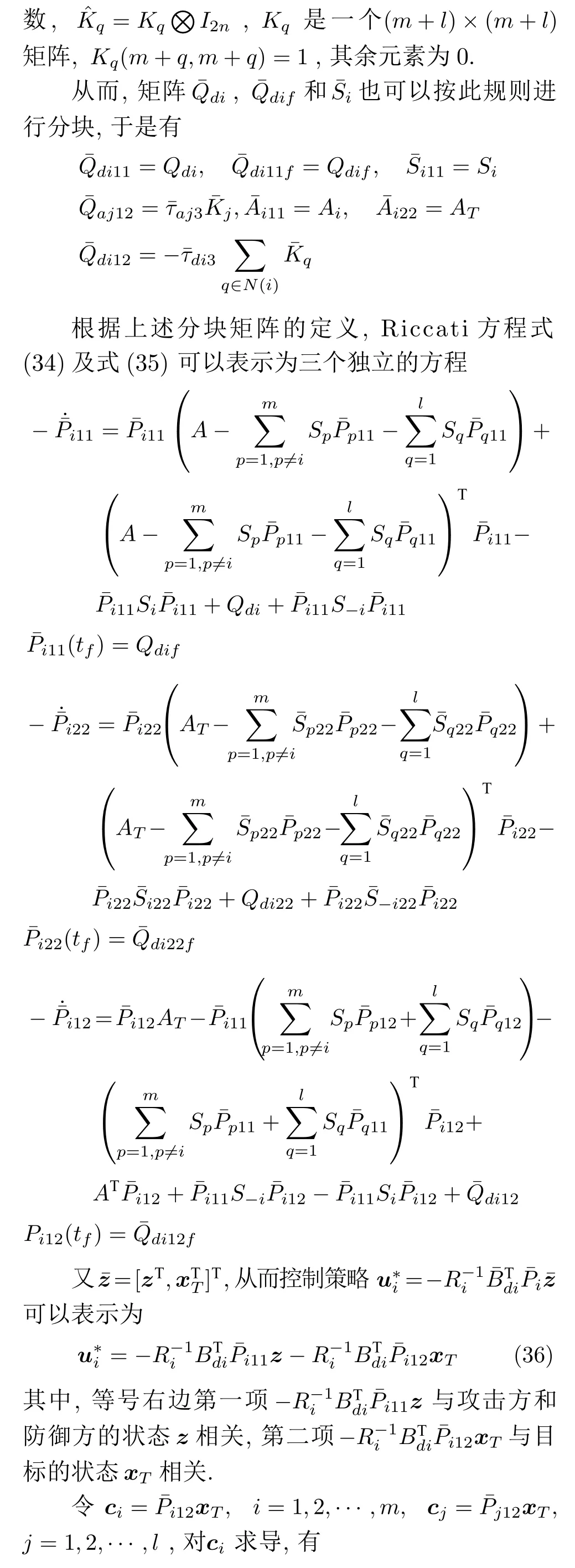


2.2 目标采取逃跑运动时的博弈
下面考虑目标可以控制自身状态来躲避攻击者的攻击,即目标也参与博弈,选择自己的策略,其状态方程如下:


2.3 攻击者、防御者分散状态下的追逃策略
当攻击方没有保持聚合状态,而是选择分散状态进行攻击时,相应地,防御方也采取分散状态对攻击者进行拦截.此时,每个防御者需要提前选择自己的拦截对象.本节研究攻击者、防御者分散状态下各自的最优策略,设计的策略适用于攻击者数量小于等于防御者数量(l≤m)的情形,为简单起见,只考虑目标静止时的博弈.
在本节中,用二分图G来描述攻击者与防御者之间的通信拓扑,假设个体间通信是双向的,那么,防御者可以采用二分图的最大匹配算法[24]为自己选定拦截对象,防御者只能拦截自己可以观测到的攻击者.
当防御者选定自己的拦截对象后,多攻击者、多防御者追逃问题转化为多组两人零和博弈的情形.对于防御者i,假设匹配的攻击者为j,定义zs=,则有:
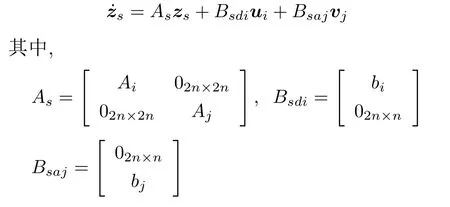
不失一般性,假设目标点在原点,即xT=[0,···,0]T∈R2n,那么,防御者需要优化的加权距离可以表示为:


3 仿真
在本节中,首先选取防御者和攻击者数量为m=3,l=3,分别给出聚合状态下防御者胜利和攻击者胜利两种情况下双方及目标的运动轨迹,并分析成本函数中权重系数的影响.进一步,分别考虑防御者和攻击者数量为m=5,l=3 和m=3,l=5的情形.同时,给出目标采取逃跑运动时的博弈结果.最后,考虑防御者、攻击者分散状态下的追逃策略.每个智能体均采用双积分动力学模型.此外为了便于计算,成本函数中的R-i,Ri,R-j,Rj均取对应维数的单位矩阵.
3.1 防御者、攻击者聚合状态下的追逃问题策略仿真
3.1.1 目标沿固定轨迹运动
考虑防御者数量m=3,攻击者数量l=3.图1~3 分别给出了防御者、攻击者内部和两方之
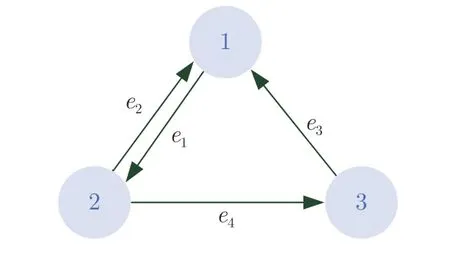
图1 防御者通信拓扑Fig.1 The communication topology of defendes
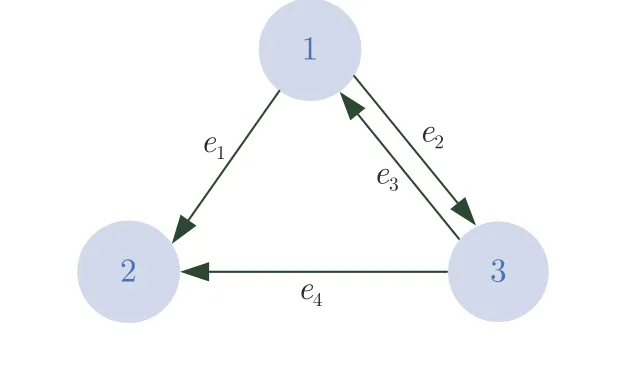
图2 攻击者通信拓扑Fig.2 The communication topology of attackers
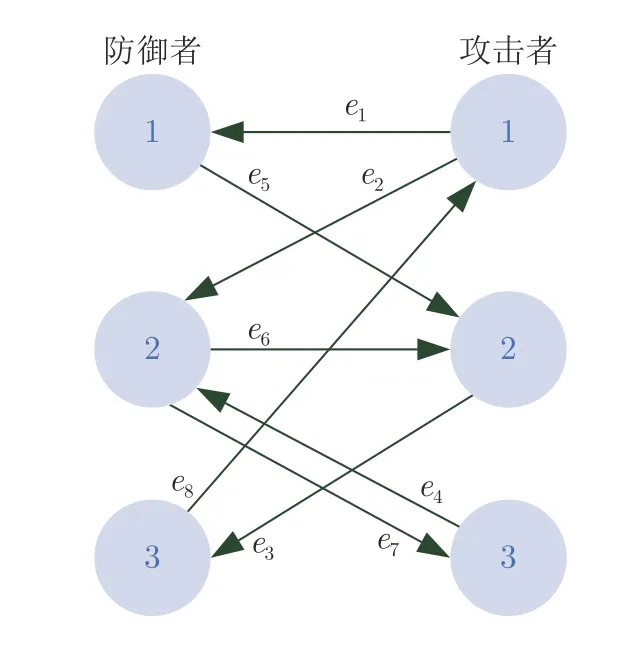
图3 防御者与攻击者之间的通信拓扑Fig.3 The communication topology between defendes and attackers
间的通信拓扑关系,相应的邻接矩阵分别为:

假设目标沿固定轨迹做正弦运动,目标状态为
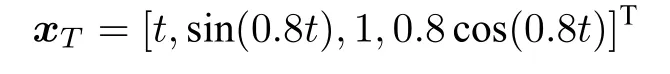
当目标被捕获或所有攻击者被拦截,提前终止博弈.设置防御者拦截半径和攻击者捕获半径都为0.2 m,采样时间为0.05 s,终端时间tf为10 s,权重系数为:
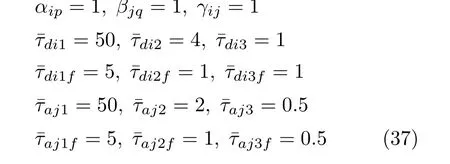
其中,i∈Vd={1,2,3},j∈Va={1,2,3}.
设置防御者的初始状态为:
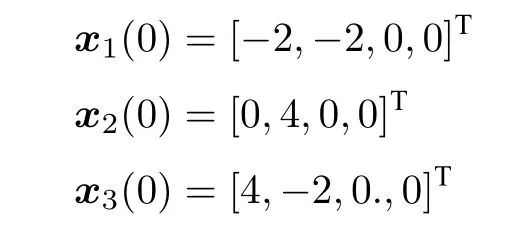
攻击者的初始状态为:
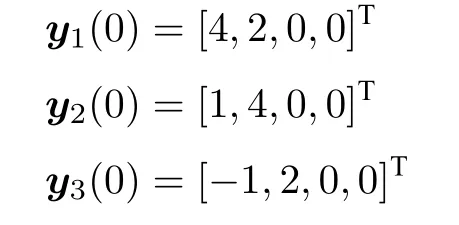
根据定理1 中的最优策略式(14)和式(15),以及注1 中的求解过程,可以得到如图4 所示防御者、攻击者和目标的运动轨迹.博弈结果为攻击者3 在未被防御者拦截的前提下成功捕获目标,攻击者取得胜利.
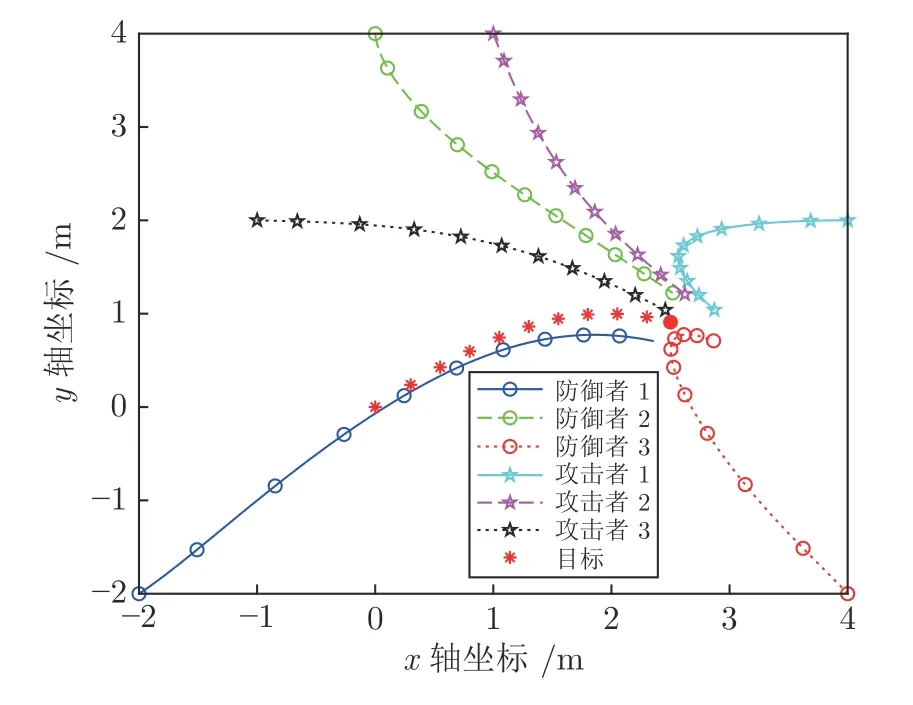
图4 攻击者胜利时目标、攻击者、防御者的运动轨迹Fig.4 Trajectories of the target,attackers and defenders when attackers win
在保持式(37)中权重系数不变的情况下,改变防御者和攻击者的初始状态,设置防御者初始状态为:
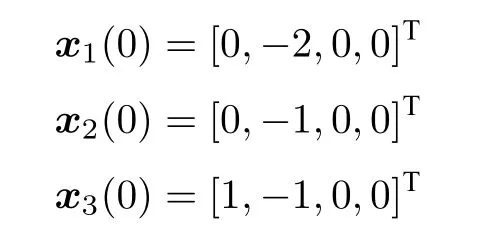
攻击者初始状态为:
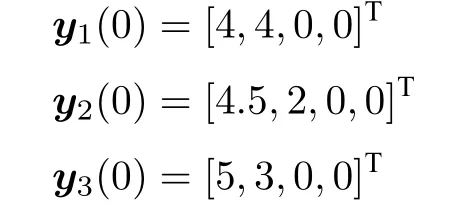
根据定理1 中的式(14)和式(15)得到防御者胜利的博弈结果,三方的运动轨迹如图5 (a)所示.
进一步,研究式(37)中防御者和攻击者的权重系数变化对仿真结果的影响,分别调整权重系数(参数分别表示攻击者和防御者的聚合程度,效果相似,此处省略分析),得到防御者、攻击者和目标的运动轨迹图5 (b)~5 (f),以及攻防双方的成本函数图6 (b)~6 (f).通过图5 (a)和5 (b)、图6 (a)和6 (b)可以看出,减小权重系数,即防御者聚合程度降低,相应地防御者拦截攻击者的重视程度相对提高,使得防御者拦截时间缩短,攻击者成本函数增大.通过图5 (a)和5 (c)、图6 (a)和6 (c)可以看出,减小权重系数,即防御者对拦截攻击者的重视程度降低,使得防御者拦截时间明显增加,攻击者与目标间距离增大,相应地攻击者成本函数增大.通过图5 (a)和5 (d)、图6 (a)和6 (d)可以看出,增大权重系数,即防御者对阻止攻击者攻击目标的重视程度提高,使得防御者在拦截攻击者的同时让攻击者远离目标,拦截时间增加,攻击者成本函数增大.
通过图5 (a)和5 (e)、图6 (a)和6 (e)可以看出,增大权重系数,即攻击者对躲避防御者的重视程度提高,攻击者与防御者之间的距离增大,使得防御者拦截时间明显增加,防御者的成本函数快速增大.由于攻击者与目标之间的距离增大,防御者成本函数相应地减小.最后,通过图5 (a)和5 (f)、图6 (a)和6 (f)可以看出,增大权重系数,即攻击者对攻击目标的重视程度提高,使得攻击者成功地在防御者拦截前捕获目标.由于攻击者在接近目标的同时减小了与防御者之间的距离,防御者成本函数相应地减小.
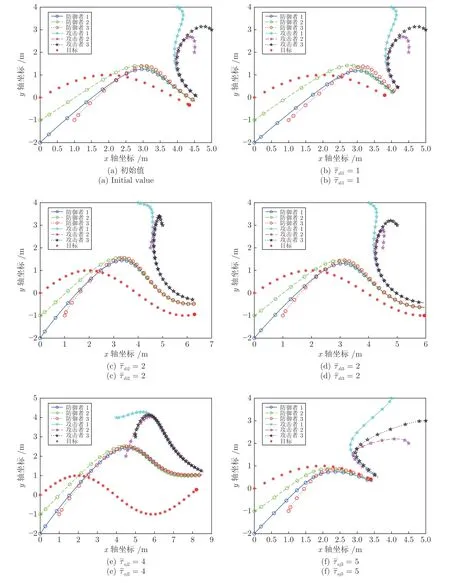
图5 防御者胜利时权重系数调整目标、攻击者、防御者的运动轨迹Fig.5 Trajectories of the target,attackers and defenders with different weight coefficients when defendes win
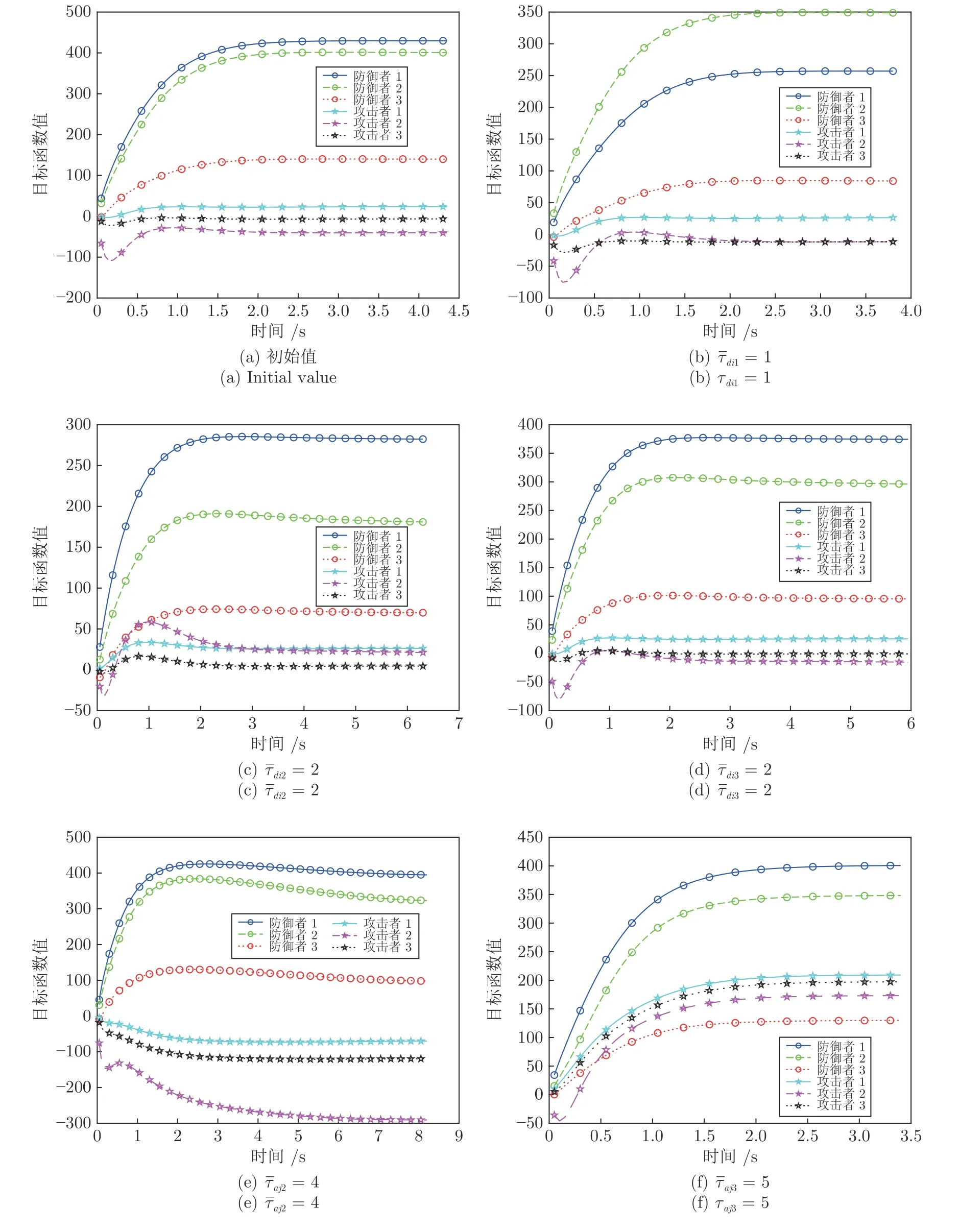
图6 防御者胜利时权重系数调整目标、攻击者、防御者的成本函数Fig.6 Cost functions of the target,attackers and defenders with different weight coefficients when defendes win
上述考虑的是防御者和攻击者数量相等,进一步讨论数量不等时的情形.在不改变双方权重系数式(37)的前提下,考虑m=3,l=5 的情形,此时通信拓扑图的邻接矩阵分别为:

设置防御者的初始状态为:
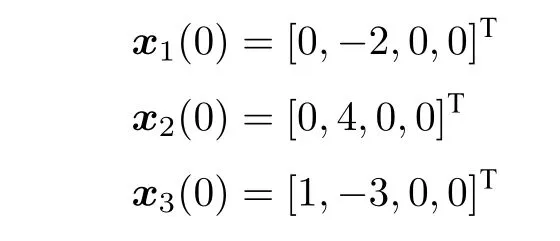
攻击者的初始状态为:
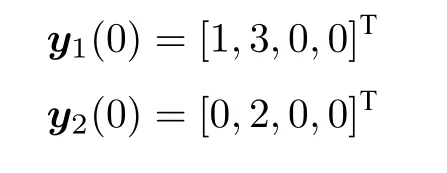
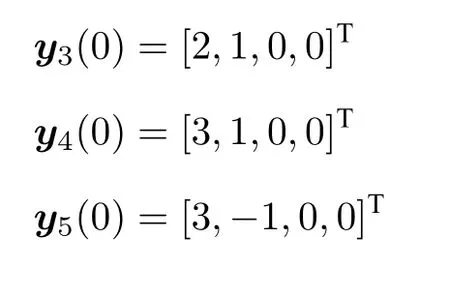
如图7 所示,由于攻击者数量的增加,防御者无暇顾及拦截所有的攻击者,最终攻击者3 顺利捕获目标.类似地,考虑m=5,l=3 即防御者数量多于攻击者的情况.如图8 所示,防御者在保持聚合的基础上,在距离目标较远的位置拦截所有攻击者.

图7 m=3,l=5 时目标、攻击者、防御者的运动轨迹Fig.7 Trajectories of the target,attackers and defenders with m=3,l=5
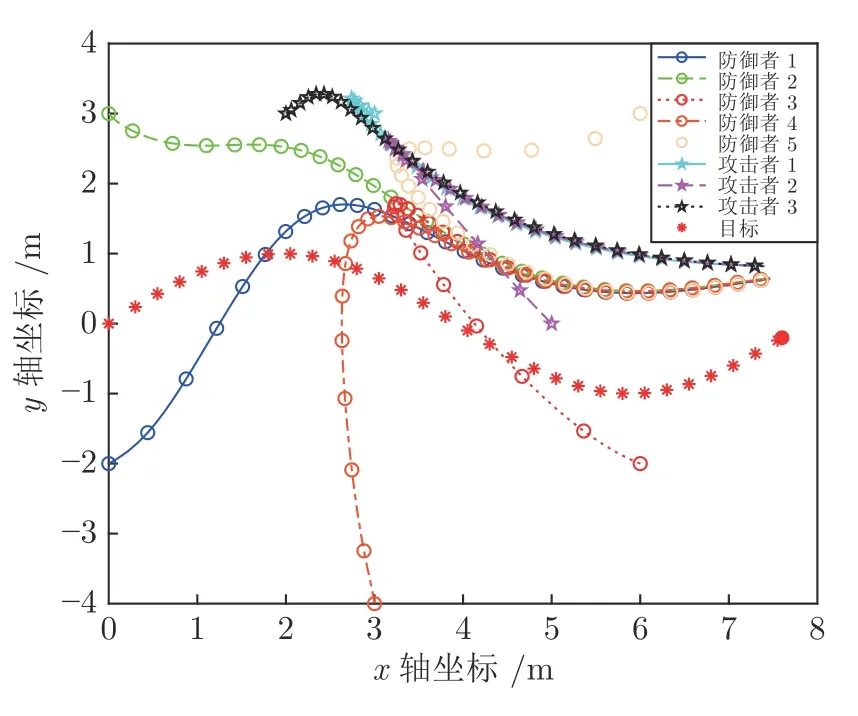
图8 m=5,l=3 时目标、攻击者、防御者的运动轨迹Fig.8 Trajectories of the target,attackers and defenders with m=5,l=3
3.1.2 目标采取逃跑运动
考虑m=3,l=3 的防御者和攻击者数量,当目标采取逃跑策略时,选取式(37) 中的权重系数,防御者的初始状态为:
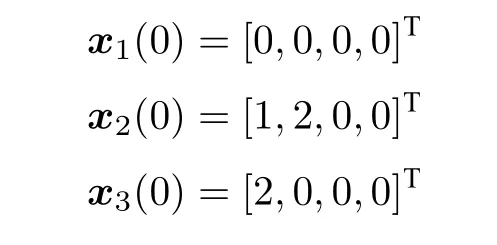
攻击者的初始状态为:
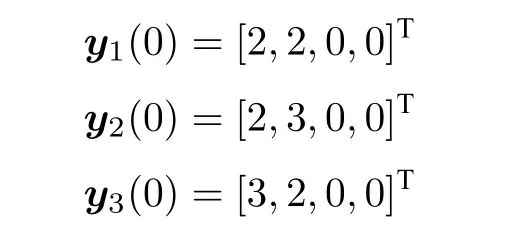
逃跑者的初始状态为:

目标采取逃跑行动的博弈结果如图9 所示,在初始时刻攻击者处于目标和防御者之间的位置.在运动过程中,目标朝着三个攻击者聚合的反方向逃跑,使得防御者顺利地实现对攻击者的拦截.

图9 目标采取逃跑行动时目标、攻击者、防御者的运动轨迹Fig.9 Trajectories of the target,attackers and defenders when the target adopts an escape strategy
3.2 防御者、攻击者分散状态下的追逃问题策略仿真
当攻击者采取分散状态进行攻击时,参数设置如下:博弈时域选择tf=3 s,权重系数为:

其中,s={1,2,3}.系统初始状态为:
目标状态为
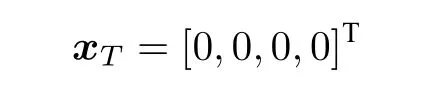
首先,采用二分图的最大匹配算法为每个防御者匹配拦截对象此时,最优分配方案为防御者1 拦截攻击者1,防御者2 拦截攻击者3,防御者3 拦截攻击者2.通过终端值Ps(tf) 进行反向迭代,可以得到对应Riccati 方程的解.最后,可以得到最优策略下智能体的运动轨迹如图10 所示.此时,防御者1在坐标点 (-0.3,-0.1) 成功拦截了攻击者1,防御者2 在坐标点 (0.5,-0.3) 成功拦截了攻击者3,防御者3 在坐标点 (-0.2,0.4) 成功拦截了攻击者2,三个防御者分别成功拦截了自己匹配到的攻击者,攻击方胜利.
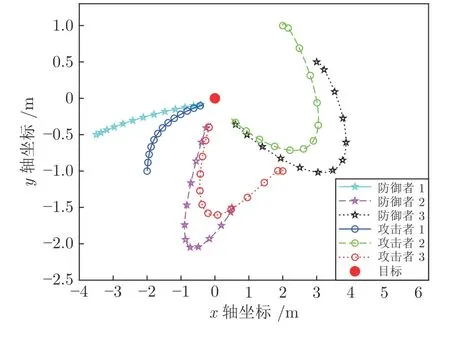
图10 防御者、攻击者分散状态下攻击者、防御者的运动轨迹Fig.10 Trajectories of attackers and defenders when defenders and attackers stay distributed
4 结论
本文采用线性二次型微分博弈的方法研究了追逃博弈问题.首先,当攻防双方保持各自聚合状态,分别设计了目标按固定轨迹运动和目标采取逃跑行动时攻防双方的最优策略.其次,当攻防双方保持分散状态,采用二分图最大匹配算法为防御者匹配攻击者,将多个攻击者、多个防御者的追逃问题题转化为多组两人零和微分博弈,求解出了攻防双方的最优策略.最后,数值仿真验证了所提方法的有效性.在追逃问题中,随着攻防双方个体增多,拓扑结构更加复杂,大规模数据将会增加网络的通信负担和系统的计算负担.而云控制系统[26]利用云计算高效的运算能力,具有实时性强、可靠性高等优点.因此,未来可以考虑将上述算法扩展到云控制系统.本文在分析攻防双方分散状态下的追逃博弈问题时,只考虑了防御者数量大于或等于攻击者的场景.未来可以研究当攻击者数量大于防御者时,具有一定优势的防御者需要连续拦截多个攻击者的情形.
猜你喜欢
指挥与控制学报(2022年4期)2022-02-17 02:56:02
当代陕西(2020年17期)2020-10-28 08:18:18
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
人大建设(2018年5期)2018-08-16 07:09:00
爱你(2018年16期)2018-06-21 03:28:44
现代装饰(2018年5期)2018-05-26 09:09:39
电信科学(2017年6期)2017-07-01 15:44:57
中国三峡(2017年2期)2017-06-09 08:15:29
指挥与控制学报(2015年4期)2015-11-01 10:09:34
