
基于位置嵌入和多级预测的中文嵌套命名实体识别
2023-12-16 10:29:12段建勇朱奕霏
计算机工程 2023年12期
段建勇,朱奕霏,王 昊,何 丽,李 欣
(1.北方工业大学 信息学院,北京 100144;2.CNONIX 国家标准应用与推广实验室,北京 100144)
0 概述
命名实体识别(Named Entity Recognition,NER)是从一段复杂文本中找到特定文本跨度并为其分配所属类型的任务。该任务在信息抽取(Information Extraction,IE)领域中是一项重要的基础研究,给许多其他任务提供信息支撑,例如实体链接[1]、机器翻译[2]和问题回答[3]。命名实体识别任务是深度语言理解的第一阶段[4],在近十年的发展过程中涌现出许多行之有效的方法,并且随着计算机硬件性能的提高,LSTM[5]、BERT[6]等深度学习模型的提出使得该任务在整体上取得了较大进展,但许多命名实体存在多层嵌套的现象却较少得到关注。
嵌套命名实体识别作为命名实体识别任务的主要组成部分,是问答系统、知识图谱、人工智能等科学研究中最为基础、核心的技术之一,并且相关识别方法成果在实际生活中也具有广泛的应用。中文的复杂性使得在文本内往往存在较多的嵌套命名实体。深度学习在命名实体识别领域的广泛应用有效克服了浅层序列模型面临的特征稀疏等问题,但由于序列标注模型只能识别扁平结构的命名实体,因此深度学习下的序列模型仍无法有效识别嵌套命名实体。
在中文语言环境下嵌套命名实体的词汇边界十分模糊[7]。由于嵌套命名实体识别的关键是通过明确实体边界来判断实体之间的嵌套关系,因此如何在正确识别出实体类别的同时确定实体边界成为该项工作需要解决的首要问题。本文针对嵌套命名实体识别模型在中文数据集上位置信息逐层衰减的问题,建立基于位置嵌入和多级预测的中文嵌套命名实体识别模型。在编码层,使用添加了嵌套实体准确位置的嵌入层的Transformers 模型提高输入序列的特征表示能力,构建与嵌套层级相关的相互独立的隐藏状态输出,排除最优路径对预测多级嵌套实体的影响,并且在维护原始文本信息的同时为条件随机场(Conditional Random Field,CRF)提供了包含次优路径的隐藏状态矩阵。在解码层,使用排除最优路径影响的次优路径多级CRF 联合边界预测单元(Boundary Prediction Unit,BPU),实现中文实体边界的准确预测以及中文嵌套实体的识别,相对于单一的多级CRF 识别嵌套实体,添加了BPU 的解码层更加适用于中文嵌套实体的识别。
1 相关研究
1.1 嵌套命名实体识别
近年来,学者们对嵌套命名实体进行了研究并提出了一些可行方法。WANG 等[8]提出一种基于超图的方法来考虑所有可能的跨度。SOHRAB 等[9]提出一个神经穷举模型,该模型列举和分类所有可能的跨度,并设置一个阈值来丢弃过长的实体跨度,如果阈值设置得很低,则运行时间会相对减少,但较长的跨度就会被遗漏。SHEN 等[10]利用图像识别与嵌套命名实体任务的相似性,提出一种穷举分类的两阶段识别模型。然而,上述方法在实现高性能的同时会增加数据的复杂性。连艺谋等[11]提出强化实体分类模型,利用卷积神经网络提取邻接词特征,通过多头注意力获取实体边界。SHIBUYA 等[12]提出使用多级CRF 寻找次优解的方式,由外到内分层输出实体,识别嵌套实体。WANG 等[13]改进了这种分层输出,排除了最优解对输出结果的影响,由内到外分层输出嵌套实体。上述研究在英文数据集上也取得了较好的结果。
1.2 中文嵌套命名实体识别
中文嵌套命名实体识别的难点在于中文语言结构特点本身缺乏边界,要获得准确的分词结果十分困难。早期的中文命名实体识别使用的是一种基于人工制定规则的系统,例如LaSIE-II[14]、NetOwl[15]、FACILE[16]和SAR[17]都是基于规则的模型。随着隐马尔可夫模型(HMM)[18]、决策树[19]、最大熵模型[20]、支持向量机(SVM)[21]和条件随机场(CRF)[22]等越来越多的机器学习方法在NER 领域的应用,一些融合了上述方法的深度神经网络模型使中文命名实体识别效果得到显著提升。ZHANG 等[23]提出一种LSTM 模型的变种模型(Lattice-LSTM),将所有的字符向量与通过词典匹配到的词汇向量作为输入。崔丽平等[24]提出一种融合词典信息的有向图神经网络模型(L-CGNN),通过卷积神经网络提取丰富的字特征,并且构造句子的有向图,以生成邻接矩阵来融合字词信息。WU 等[25]利用汉字的结构信息,提出一种基于多元数据嵌入的Cross-Transformer 模型。
许多研究都在中文命名实体任务的基础上发现了嵌套命名实体问题。SUI 等[26]为了融合语音和文字信息,在构建文字数据集时发现了大量嵌套实体。廖涛等[27]提出一种基于交互式特征融合的嵌套命名实体识别模型,通过构建不同特征之间的通信桥梁来捕获多特征之间的依赖关系,但是该模型忽略了实体本身的位置信息。LI 等[28]提出FLAT 中文命名实体识别模型,使用的数据集为嵌套结构,但是模型本身并未对嵌套实体进行优化。为了丰富中文嵌套命名实体识别领域的研究,笔者查阅了大量相关文献,结合中文嵌套命名实体与序列模型和机器学习方法的特点,提出一种基于位置嵌入和多级边界预测的改进模型。
2 基于位置嵌入和多级预测的中文嵌套命名实体识别模型
使用改进的Transformer 模型的数据编码层来融合中文文本中存在长距离依赖的上下文信息。在嵌入层,将文本中的嵌套实体抽离出来拼接到文本尾部,形成新的含有融合嵌套实体信息的序列输入,再通过多头自注意力层以及全连接层进行编码。根据嵌套层级的数目生成多个隐藏状态,每个CRF 层独立计算发射分数,最后经过BPU 计算嵌套实体的边界偏移量得到最终结果,如图1 所示。

图1 模型总体结构Fig.1 Overall structure of the proposed model
2.1 嵌入层
2.1.1 嵌套词汇相对位置标记
为了获取融合中文嵌套实体信息的序列标注信息,将文本中的嵌套实体的首尾信息作为独立元素提取出来,用符号e表示,E={e1,e2,…,en}表示嵌套实体首尾信息的集合。
记录嵌套实体开始和结束的两个标记来表示嵌套实体在中文文本中的绝对位置信息,如式(1)所示:
其中:ei,begin、ei,end表示嵌套实体ei的开始和结束字符在输入文本中的绝对位置。
在嵌套实体中含有多个字符,开始位置和结束位置在序列中不一致,但是对于单个字符,开始和结束的位置在序列中一致。在标记后,嵌套实体之间存在交叉关系、包含关系、互斥关系3 种,这些关系可以由嵌套实体的开始和结束位置来确定。为了更好地表示这种关系,将嵌套实体的绝对位置分别嵌入文本字符序列的尾部,如式(2)、式(3)所示:
其中:Sbegin、Send表示融合了嵌套实体开始和结束位置信息的文本序列;c表示原始文本序列中字符的绝对位置,开始和结束的绝对位置相等。
2.1.2 嵌套词汇融合嵌入
为了使模型更具鲁棒性,不直接将这3 种关系作为参数融入序列,而是采用FLAT 模型的思想重新构建一个特殊向量矩阵来建模嵌套实体之间的相互关系。这个矩阵是通过对嵌套实体开始和结束位置与文本字符之间的信息差异来进行统一计算。这种表示首先能够体现出嵌套实体之间的相互关系,其次可以明确嵌套实体在本文中的位置关系,以及嵌套实体与无意义字符之间的距离关系。使用这种向量矩阵表示获得了更多的嵌套实体与原始文本之间的融合信息,增强了嵌套实体与原始文本之间的关系,如式(4)所示:
2.2 编码层
多头自注意力层在每个时间步内只能输出一个隐藏状态,在进行嵌套实体识别任务时,预测当前层级嵌套实体的标签序列时需要使用上一层级嵌套实体预测的发射分数矩阵。因此,当前层级的标签序列预测会偏向上一层的最优路径,从而影响多级嵌套实体的识别准确率。
为了消除最优路径的影响,重新设计了模型的多头自注意力层的结构。按照嵌套层数,在多头自注意力层设置与嵌套层数量一致的嵌套层级权重矩阵,用符号w表 示,W={w1,w2,∙∙∙,wl}表示嵌 套层级权重矩阵的集合,其中l表示嵌套层数。使多头自注意力矩阵分别与嵌套层级权重矩阵相乘,从而生成多个隐藏状态块,配合解码阶段多级输出时的发射矩阵计算,如式(5)所示:
其中:hi表示隐藏状态块;Z表示多头自注意力矩阵。
使用Ht={h1,h2,∙∙∙,hl}表示隐藏状态块集合。隐藏状态块的个数与嵌套层级一致,这就使得每个层级的标签序列预测都有对应层级的发射分数矩阵,同时也保证了每个层级使用的原始文本信息的一致性,增强了模型的可靠性。
2.3 解码层
解码层使用经过特殊设计的CRF 与BPU 联合模型来处理得到的嵌套实体向量,具体结构如图2所示。
2.3.1 多级CRF 层
使用多层次序列标注的方式来实现对嵌套命名实体的识别,次优路径多级CRF 是一种排除最优路径对多级别嵌套实体识别产生影响的优化的多级CRF 模型,对于不同级别的嵌套实体使用与当前级别关联度最高的发射函数,并且计算完成后将其从可选发射函数候选矩阵中剔除,这样就可以使每一级的嵌套实体序列都使用独立于最优路径之外的发射函数,使其可以更加准确地预测嵌套实体类别。使用编码层输出构建CRF 层的转移矩阵,如式(6)所示:
其中:Ai,j表示标签集合中标签yi到yj的概率转移矩阵;n为标签数量;y0、yn为文本输入的开始与结束标志。
对于不同级别的CRF 函数,在每个时间步长内都会维护一个与级别相关的块集,从块集中选择与当前级别标签序列关联度最高的块集矩阵来计算最终的发射得分,从而获得最符合当前级别标签序列的标签分类输出结果,如式(7)所示:
对于已经选择的块集,需要将其从Htl中删除[如式(8)所示]来排除该块集对每个时间步骤的影响,从而排除最佳路径对全局结果的影响,直到将所有级别的嵌套实体标签识别完毕。
对于所维护的块集而言,每次都会排除当前级别的一个最相似块,而不是按照顺序排除,这种方式避免了隐藏状态块只学习特定层级的信息,加强了多级嵌套实体信息之间的联系。
2.3.2 BPU
多级CRF 层在输出最优路径标签序列时,会将最符合当前发射分数的类别标签作为最终输出,但是嵌套实体的边界信息还是不够准确。为此,在CRF 层添加了一个边界预测单元来进一步明确嵌套实体的边界。对多级CRF 层预测出的实体,采集其在训练模型多头自注意力层隐藏状态序列时间步内的左右字符信息矩阵进行进一步训练,从而确定最终的嵌套实体输出。
首先定位CRF 层预测的实体的开始和结束边界;然后从隐藏状态字符输出矩阵{o1,o2,…,on}中提取出该实体字符信息以及外部边界字符信息,构建融合跨度表示,其中n为文本长度;最后计算边界偏移量,如式(9)、式(10)所示:
其中:oi,bpu、ok表示嵌套实体的BPU 边界融合输出矩阵和隐藏状态字符输出矩阵;bbegin、eend分别表示实体开 始、结束字 符序号;Wbpu、W1、W2为可学 习矩阵;b1、b2为可学习参数;ti表示边界偏移量。
对整体实体进行学习后,再对左右边界按照不同的方式进行计算得到最新的实体边界偏移表示,如式(11)、式(12)所示:
2.3.3 联合损失函数优化
多级CRF 层输出嵌套实体的准确类别和大致边界,BPU 通过联合多级CRF 层输出结果以及隐藏状态序列进行精确边界预测。最终通过联合多级CRF 层以及BPU 的损失函数,训练出适合当前级别的边界预测模型。
对于多级CRF 层,对每层分别计算预测标签在当前级别的条件概率,如式(13)~式(15)所示:
其中:p(yl|Hl)表示第l级输出在Hl隐藏块集合的条件下预测标签序列yl的条件概率;Z(Hl)为第l级输出的所有标签序列结果的和;Lcrf为多级CRF 层的损失函数。
对于BPU,使用平滑损失函数来优化模型,如式(16)所示:
最终设置权重并联合两个损失函数,如式(17)所示:
其中:λ表示调优参数,为多级CRF 层和BPU 的联合损失权重。
3 实验与结果分析
3.1 数据集
为了能够较好地验证所提模型的有效性,从医学与日常这两个领域选取合适的中文嵌套命名实体数据集。医学作为出现较多嵌套命名实体并且包含许多特有名词的专业领域,能够验证模型的准确度与精度;日常语料中的嵌套实体更为随机并且也缺乏既定的逻辑性,同时还包含较多的噪声,这种类型的数据可以验证模型的健壮性以及泛化性。
选用专业医疗领域数据集(CMQNN)以及大型中文日常领域数据集(CNERTA)。在CMQNN 中包含55 000 条数据,训练集包含43 896 条数据,嵌套实体比例为47.60%,验证集包含5 583 条数据,嵌套实体比例为43.74%,测试集包含5 521 条数据,嵌套实体比例为46.28%,包含身体部位(body)、标准疾病(ICD_10)、常见疾病(disease)、医学科室(department)、常见药物(drug)5种实体类型。CNERTA 包含42 987条数据,训练集包含34 102 条数据,嵌套实体比例为31.25%,验证集包含4 440 条数据,嵌套实体比例为29.50%,测试集包含4 445 条数据,嵌套实体比例为38.25%,主要包含的实体类型为地点(LOC)、人名(PER)和组织(ORG)。
3.2 基线模型
所提模型是一种基于融合了实体位置信息的多级边界回归的嵌套命名实体识别模型。为了验证所提模型的有效性,基线模型选取了一些在嵌套命名实体识别中常用的具有类似结构的序列模型作为基线模型,具体为:1)Layered-BiLSTM+CRF 模型[29],基于LSTM 模型进行文本信息编码,通过动态堆叠平面NER 层来识别嵌套实体,也是基础的基于序列标注方法的嵌套命名实体模型;2)Flat-Lattice Transformer+CRF 模型[28],面向中文命名实体识别的基于Transformer 结构的序列标注模型,可以有效增强对命名实体词汇信息的学习能力,并且在中文数据集上达到了较好的性能;3)BERT+FLAIR 模型[12],基于BERT 预训练模型编码,并使用次优路径思想进行嵌套命名实体识别。
3.3 实验设置与评价指标
所提模型在Windows 和Linux 系统平台上均可运行,所有实验均使用Python 3.8.8 环境,模型使用PyTorch 1.8.1 深度学习框架构建,使用GTX2060 显卡,显存大小为6 GB。
模型内部的可学习参数使用随机梯度下降(SGD)算法进行优化。在实验中的超参数设置如表1 所示。对于数据集嵌套层数l,在CMQNN 和CNERTA 数据集上均设置为6。采用准确率、召回率、F1 值3 个指标作为模型性能的评价标准。

表1 实验超参数设置Table 1 Experiment hyperparameter setting
3.4 结果分析
3.4.1 模型训练结果
4 种中文嵌套命名实体识别模型对比结果如表2 所示。由表2 可以看出,所提模型性能与常用的中文嵌套命名实体识别模型相比在CMQNN 与CNERTA 两个数据集上均有所提升,其中在CMQNN 数据集上准确率、召回率和F1 值相比于基线模型中的最高值分别提升0.34、1.06 和0.80 个百分点,在CNERTA 数据集上准确率、召回率和F1 值相比于基线模型中的最高值分别提升11.90、0.78 和6.23 个百分点。

表2 中文嵌套命名实体识别模型对比结果Table 2 Comparison results of nested Chinese named entity recognition models %
实验结果表明,所提模型在专业医疗领域和日常领域这两种不同类型的数据集上均获得了优于常用的中文嵌套命名实体识别模型的识别效果,也证明了所提模型在识别中文嵌套命名实体方面具有较好的泛化性能和实用效果。通过实验还可以看出:使用Transformer 编码器的模型在识别具有嵌套结构的中文数据集时效果要优于使用LSTM 编码器的模型,主要原因为Transformer 编码器特有的位置编码对嵌套实体有更优的适配性,可以深入挖掘实体内部的信息,这也证明了使用位置嵌入编码模型可以更好地识别嵌套实体;与仅使用多级CRF 的Layered-BiLSTM+CRF 模型相比,所提模型在CMQNN 与CNERTA 两个数 据集上,F1 值分别提高了2.43 和10.82 个百分点,说明使用改进的Transformer 模型以及CRF+BPU 联合模型能更加充分地学习到中文嵌套实体的潜在信息,而且对于专业词汇和日常用语领域均有所提升,也证明了所提模型对于中文语言模式具有更佳的适配性。
3.4.2 消融实验结果
为了进一步验证所提模型的重要参数设置以及各组件的有效性,设计消融实验来验证不同l、位置嵌入以及BPU 对模型性能的影响。
消融实验结果如表3 所示,由表3 可以看出:
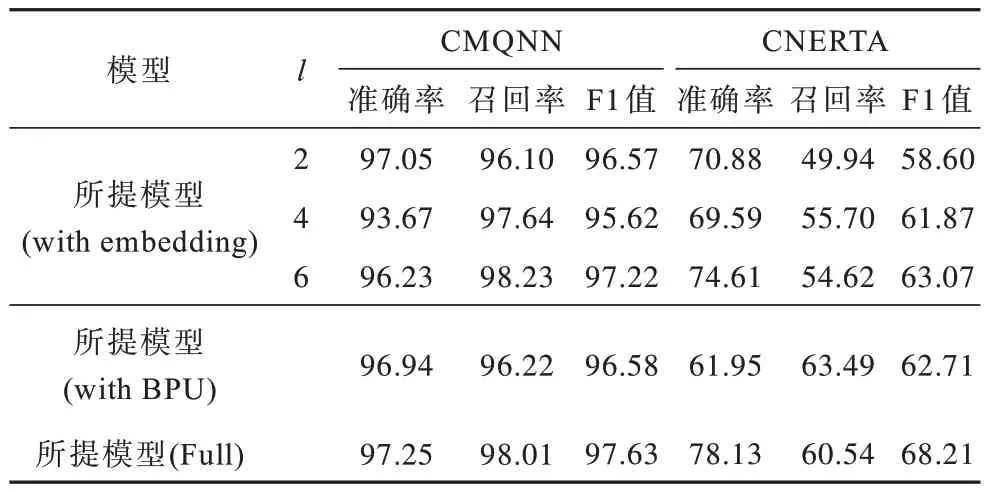
表3 不同嵌套深度模型中组件有效性结果对比Table 3 Comparison of component validity results of the models with different nested depths %
1)所提模型(with embedding)为单独使用了位置嵌入,通过调整l发现不管对于具有较深嵌套实体层数的CMQNN 数据集还是具有较浅嵌套实体层数的CNERTA 数据集,当l=6 时均可获得最好的识别效果。对于CMQNN 数据集,当l=4 时效果最差,主要原因为CMQNN 数据集中包含较多的初级医疗名词,当l=2 时模型忽略了较深嵌套实体反而更加专注于浅层嵌套实体的识别,也就是说更加类似于非嵌套实体识别模型。
2)所提模型(with BPU)在单独使用了BPU 后具有一定的性能提升,说明对于中文而言,字词之间的边界模糊问题得到了一定的改善,但并没有完全解决模型在多级信息传递时对中文字词间关系关注度不够的问题。
3)所提模型(Full)通过使用位置嵌入和BPU 有效提升了模型本身挖掘中文字词间关系的能力,使得BPU 可以进一步提高每一层模型识别结果的准确性。
消融实验的结果进一步验证了所提模型使用的位置嵌入和BPU 模块的有效性,它们能有效提升所提模型的中文嵌套命名实体识别能力。
4 结束语
本文建立一种基于位置嵌入和多级结果边界预测的嵌套命名实体识别模型,通过位置嵌入方式提高模型对于中文字词间关系的关注力,增强模型识别嵌套实体多级信息的能力,并且对于模型识别的最终结果进行进一步调整,使得中文字词边界更加清晰。使用两种数据内容和形式完全不同的数据集进行实验,在实体密集且相关性强的专业医疗领域和实体分散且相关性弱的日常领域中都具有较好的实验效果,验证了所提模型的健壮性和泛化性。后续将尝试引入知识图谱或者使用外部词典的方式,增强模型对于日常领域实体的识别能力,同时深入研究中文词汇的边界关系,提高中文词汇的识别准确率。
猜你喜欢
中学生理科应试(2024年6期)2024-01-01 00:00:00
系统工程学报(2021年4期)2021-12-21 06:21:24
儿童时代·幸福宝宝(2021年11期)2021-12-21 06:18:46
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46
证券法律评论(2018年0期)2018-08-31 02:33:08
东方女性(2018年3期)2018-04-16 15:30:02
散文诗(2017年17期)2018-01-31 02:34:08
外语学刊(2014年6期)2014-04-18 09:11:49
计算机工程(2014年6期)2014-02-28 01:25:29
河南科技(2014年23期)2014-02-27 14:19:17
