
基于语料库的英汉形合、意合比较与翻译策略研究
——以考研英语(二)2010 —2022年真题为例
2023-12-13 08:53:42杨林
福建江夏学院学报 2023年5期
杨 林
(北方民族大学外国语学院,宁夏银川,750021)
长期以来,形合与意合一直是英汉语言对比和翻译理论探讨的一个重要问题,至今学界对此还存在一定的争议。相当一部分研究采用传统的假设—验证的研究方法,依靠研究者的直觉和观察,缺乏大规模语料的支持,即便是使用经验性数据来支持假设,例证也多来自名家名著,语料的代表性和说服力存疑。随着语料库语言学的兴起,基于语料库和语料库驱动研究的英汉对比研究和翻译研究方兴未艾。这一新的研究方法有助于拓展英汉语言对比的观察范围和研究疆域,加深对英汉两种语言在宏观和微观层面差异的认识,为制定可行的英汉翻译策略提供实证参考,最终有助于提高学生的英汉翻译实践能力。
一、研究背景
早在1954 年,我国著名语言学家王力先生就提出过形合与意合的概念。形合与意合,作为语言组织的两种手段,体现了英汉语言的谋篇机制以及语篇内的逻辑语义关系。NidaTaber(1969)曾指出“就汉语和英语而言,也许在语言学中最重要的一个区别就是形合与意合的对比”。[1]114由此可见,形合和意合是英汉语之间最显著的差异。所谓形合,指的是句子的词语或分句之间用语言形式手段(如关联词)连接起来,表达语法意义和逻辑关系。[2]48,[3]47英语是重形合的语言,造句时采用大量显性连接手段来表现句子成分间的语法和逻辑关系,包括名词的单复数变化、动词时态变化、形容词和副词的不同级的变化、连词、关系代词、关系副词、连接代词、连接副词、介词及介词短语,动词的非谓语形式,词类的形态变化等[4]94,语言的意义通过形式规范化的句子得以表现出来,语篇内部注重句子的外在形式,注重结构的完整性,注重以形显义。
所谓意合,指的是词语或分句之间不用语言形式手段连接,句子中的语法意义和逻辑关系通过词语或分句的含义表达。[2]48,[3]47与英语相比,汉语是重意合的语言,很少使用这些语法形态变化和词汇衔接手段,语篇内部各小句之间的关系是隐含的,而不是显性的,唯一的规约化机制就是语序。此外,汉语注重语言的功能和意义,读者需要依靠语境和事理逻辑来理解作者要表达的意义。
二、研究内容与方法
(一)研究内容
本研究通过自建201—2022 年全国硕士研究生招生考试(英语二)真题英译汉部分原文和官方译文的小型英汉平行语料库,借助Antconc、Wordsmith Tool 和BFSU ParaConc 等语料库专业检索软件对语料库中的数据进行统计分析,描述英汉语在词汇、句法方面的特征,验证英语重形合、汉语重意合的假设,分析英汉语在词汇、句法特征、衔接等方面产生差异的原因,提出相应可行的英汉翻译策略来指导英汉翻译教学,从而提高学生的英汉翻译实践能力。
(二)研究方法
语料库翻译学将量化研究方法引入到翻译学研究之中,依据大量语料考察与数据统计优势观察到大量肉眼无法发现的翻译现象。[5]52本研究立足语言的经验性数据,尝试扩展英汉语对比的观察范围,采用描写的方式,通过自建真题英汉双语平行语料库,选择对英汉语言特征的多个语言层面进行对比分析,重点描述英汉语宏观层面的特征,具体涉及英汉语的词汇和句法特征。
1.语料收集、加工与对齐
本研究收集2010—2022 年全国硕士研究生招生考试英语(二)真题英译汉部分的原文和官方译文word 文本,然后对文本进行清洗,去除文本中多余空行,接着进行校对并保存为纯文本文件,然后在https://www.tmxmall.com/aligner/home 进行在线对齐,对于计算机无法实现的句级对齐,根据断句符(句号、问号、叹号)进行人工校对和确认,最终实现源语文本与目的语文本的句级对齐,这种对齐方式更为直观,便于观察句级和段落层面的语义—语用信息,如英汉词义的对应、句子结构特征和语篇的衔接手段(连词)等;此外,采用在线对齐和人工校对有助于避免计算机识别的误差,提高数据的准确性和可靠性,从而保证研究的科学性。由于全国研究生入学考试英语科是自2010 年起分为英语(一)和英语(二),英语(二)是为高等院校和科研院所招收专业学位硕士而设置的统考科目,其翻译部分是由一个或多个段落组成的短篇,字数一般在150 字左右,故本研究所能收集的语料有限。据统计,2010—2022 英语(二)真题语料库共计5420 字,12988 字符(不计空格),其中,源语语料共计1996 字,目的语语料共计3424字。
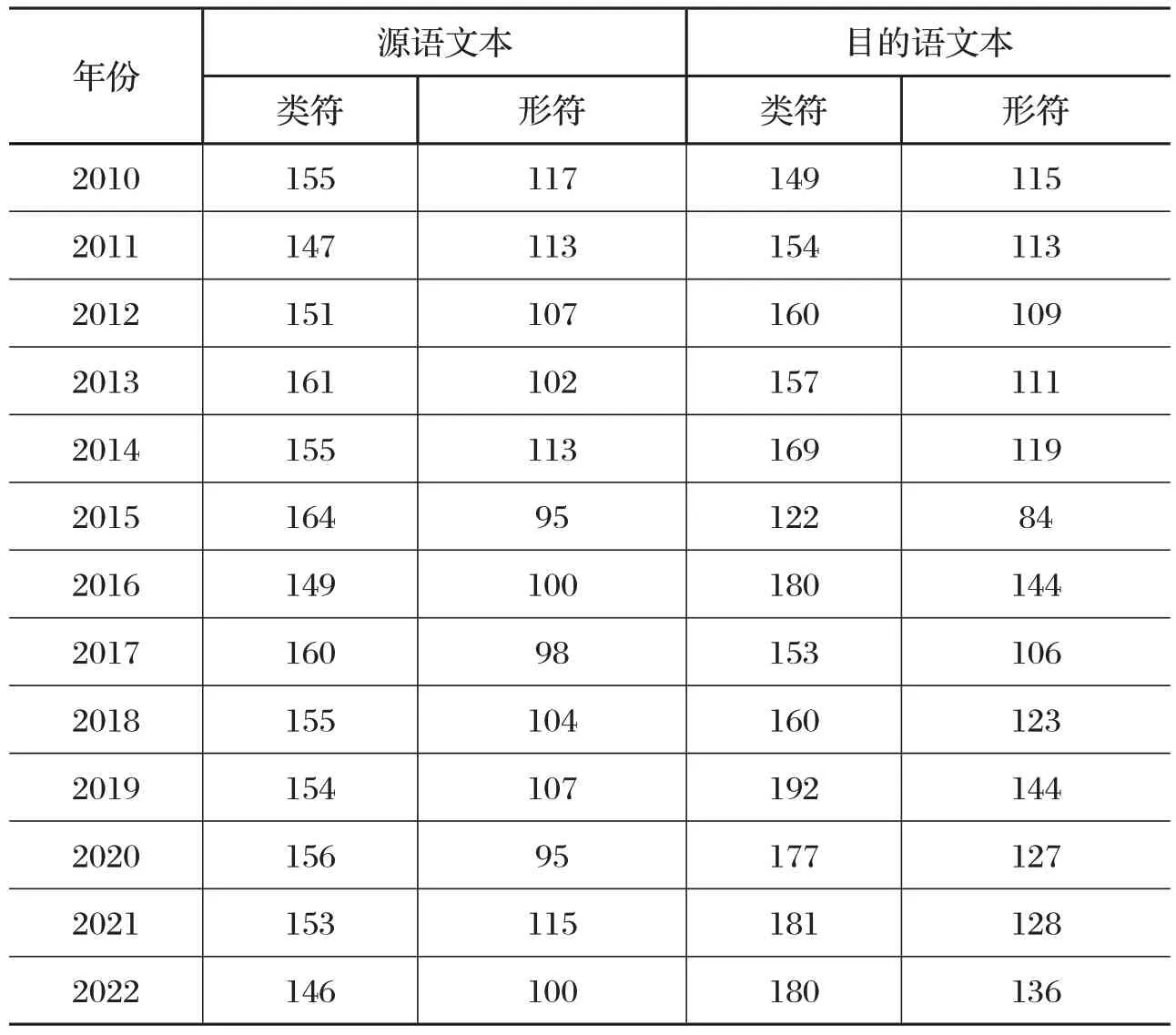
表1 语料库源语、目的语类符、形符数对照表
2.分词处理
分词与文本的整理和清洗同样重要,为了后续研究检索的方便性、准确性,同时避免语料库检索频率统计出现误差,保证研究结果的可靠性,我们还需要对文本进行分词处理。本研究借助文本分词软件Tokenizer和Segmenter对清洗过后的TXT 文本进行分词处理。
3.语料库统计分析
本研究采用 Antconc3.5.9w 对文本的词汇特征进行分析处理,包括统计语料库(源语和目的语)的标准化类符形符比以及词频分布。同时,利用Range32 软件对语料库进行词汇难度的统计分析。此外,借助Wordsmith Tools 6.0 对语料库(源语和目的语)进行句法层面统计分析,包括平均句长、句子总数以及句长标准差等。[6]25最后,利用BFSU ParaConc 软件,将导出的平行语料对常用连词、照应(人称代词、指示词)进行检索,发现英汉连词、照应的出现频率、对等词和省译、改译情况。
三、数据分析
(一)词汇层面
类符/形符比、标准类符/形符比、平均词长和关键词是语言特征在词汇层面的重要体现和参数。类符/形符比又称为词汇密度。[7]18词汇密度指文本中实词所占总词数的比例,其计算格式为:词汇密度=实词数量/总词数 *100%,实词包括名词、动词、形容词和副词,实词在文本中所传达的信息量大,因此词汇密度的大小直接反映文本的信息承载量。词汇密度越大,文本所传达的信息量就越大,难度也相应增大,反之亦然。[8]42
词汇密度可以反映词汇变化的丰富度以及文本的信息密度,它直接反映语料库中文本的词汇丰富程度,其比值越高,表明文本词汇变化程度越丰富,语料的信息密度也就越大,反之亦然。然而,随着语料文本变长,文本中虚词数量增加,类符/形符比的可信度降低。[9]35因此,使用标准化类符/形符比,即每一千词为计算单位的类符/形符比,可以较为准确地衡量语料中文本的词汇丰富程度。词长是指语料库中各种长度词的频数。平均词长指文本中词汇的平均长度,可以体现文本的正式程度,具体表现为正式程度越高的文本平均词长的数值越大,而口语化程度越高的文本平均词长越小。[7]18[9]35
由表2 可以看出,源语语料库的类符/形符比介于57.93%和76.87%之间,其中2011 年的比率最高,达到76.87%,这说明该年试题的词汇密度最高,词汇变化丰富多样,而2015 年的比率最低,这说明该年试题词汇变化少,词汇密度低,词汇不够丰富。就平均词长而言,数值差距不大,介于3.78和5.09 之间,这说明2013 年试题难度相对较低,而2012 年难度相对较大。与源语语料相比,目的语语料库的类符/形符比介于68.13%和77.18%之间,最低值和最高值均高于源语语料库文本,且每年之间的差距较源语语料略低一些。同时,从每一年源语与目的语的类符/形符比的横向对比来看,2015年、2016 年和2020 年的差距最大,都超过了10%,而其他年份源语类符/形符比与目的语类符/形符比差距相对小一些,其中2010年、2012年和2014年的数据非常接近。
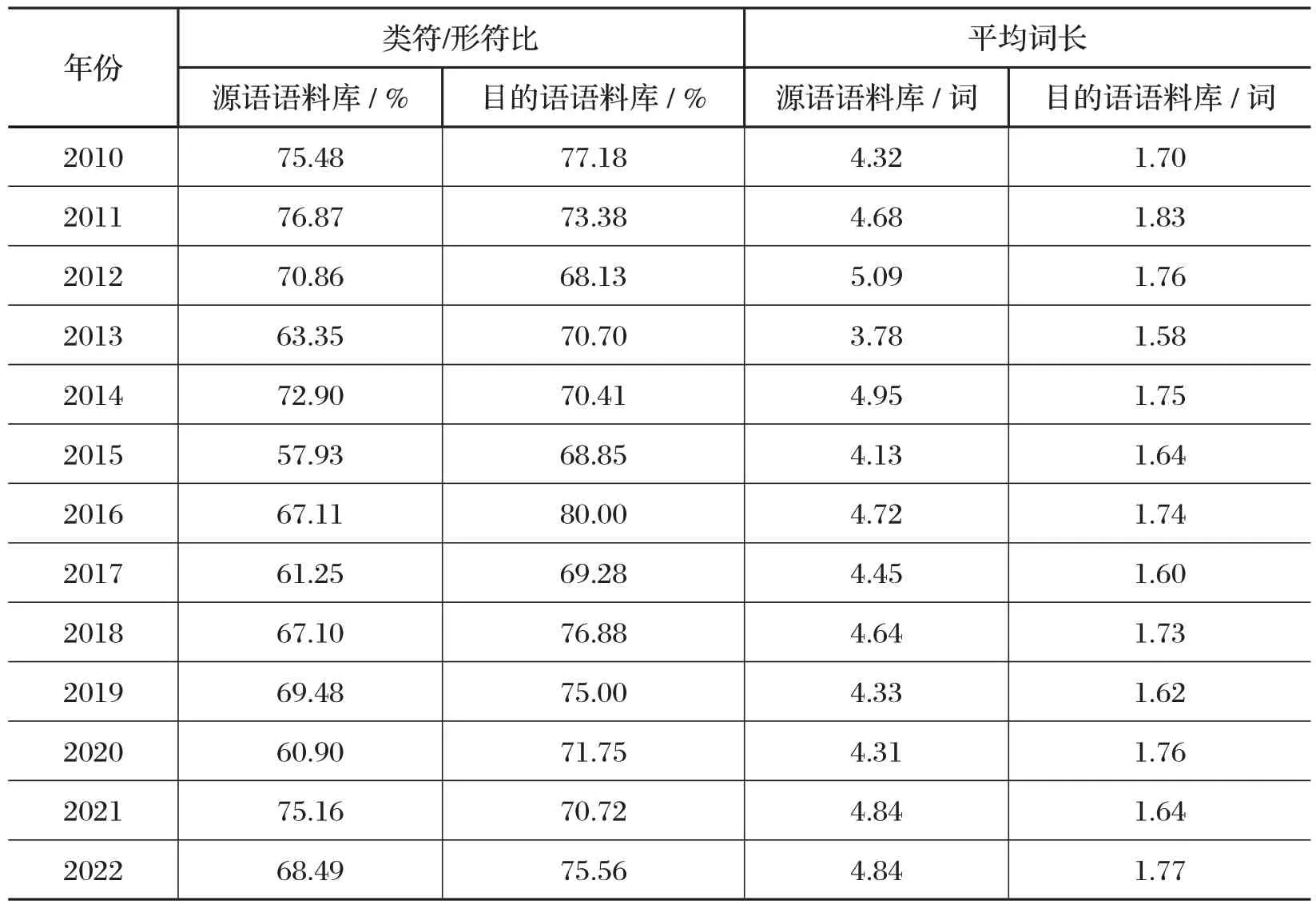
表2 语料库类符/形符比、平均词长对照表
根据检索,我们发现源语文本中使用频率最高的是由4 个字母的单词,其次是由2 个字母和3 个字母组成的单词,而目的语文本中使用频率最高的是2 个字组成的词(占绝大多数),其次是一个字组成的词和3 个字组成的词,其频率远比由2 个字组成的词要小得多,这或许与现代汉语多双音节词有关。就平均词长而言,源语语料库中每年的数值均大于目的语语料库,且分布在4 左右,而目的语语料库的数值相对较小,分布在1.5 到1.8 之间,这主要是因为英语属于拼音文字,汉语属于表意文字,在现代汉语里,双音节词占优势。
由于本次研究所建语料库规模较小,无法单独计算每年语料文本的标准类符/形符比。通过检索,发现源语语料库总的标准类符/形符比是47.10,而目的语语料库总的标准类符/形符比是54.70,这表明相对于源语文本而言,目的的词汇密度更大一些,词汇更丰富、词汇更富于变化。英语功能词使用频率高,其语篇衔接功能更强大;汉语实词使用频率高,语篇通过实词的意义衔接起来。此外,源语语料库关键词排名靠前的有“the,to,that,of,and,a,it”,其中,冠词“the”的频率最高,达到了101 次,其次是“to”“that”“of”“and”“a”“it”,出现频率分别为74、49、48、46、41、30 次,而目的语语料库关键词排名靠前的是“的、我、他、在、我们、是、人、和、了、就”,其中,助词“的”出现得频率最高,达到了130 次之多,其次是“我”“他”“在”,出现频率分别为36、26、25 次。
(二)句法层面
1.平均句长与句长标准差
语言特征在句法层面的表现反映在平均句长和句长标准差。平均句长是总形符数除以断句符(包括句号、问号和感叹号等)的个数得出的数据。[7]24总的来说,平均句长作为翻译风格的标记,在一定程度上反映了句子的复杂程度,[9]35平均句长和文本的句法结构呈正相关。平均句长越长,则说明句子的复杂程度越高,语篇的难度也就越大;相反,平均句长越短,则文本的句法复杂度就越低,语篇的难度也就越低。
标准差(Standard Deviation)是一个统计学概念,指一个数据集中各数据偏离该数据集平均数的距离的平均数,能反映该数据集的离散程度。就句长标准差而言,如果一个文本的句长标准差较大,则表示该文本的句长偏离平均句长较大,也就是说该文本中各个句子间的长度差异较大;反之则说明该文本中各个句子的长度比较一致,相差较小。[10]61句长标准差反映了语料库中句子长度与平均句长的差异,标准差越大,表明文本中句长差异越大;标准差越小,说明文本中句长差异越小。[9]36Butler(1985)根据句子包含词汇的数量,将句子分为三类:短句、中句和长句,短句包含 1~9 个词,中句包含 10~25 个词,长句包含词汇数量要超过 25 个。
由表3 可以看出,就平均句长而言,2012 年试题的数值最大,其次是2022 年,表明这两年的试题句子的复杂程度高,文本的难度较大,相比较而言,2015 年试题的数值偏小,表明该年的句子复杂程度低,文本的难度较低;与源语文本相比,目的语语料库中2022 年试题的平均句长最长,且与源语文本的数值接近,这从另外一个侧面表明该年的文本复杂度高,翻译难度也大,译者需要使用高难度的长句来再现原文的信息。有趣的是,通过对照源语文本和目的语文本的平均句长,我们发现源语文本的平均句长与目的语文本的平均句长基本保持同步,唯一的例外是2010 年的试题文本,这与英语惯于使用长句,而汉语更习惯于使用短句有关。
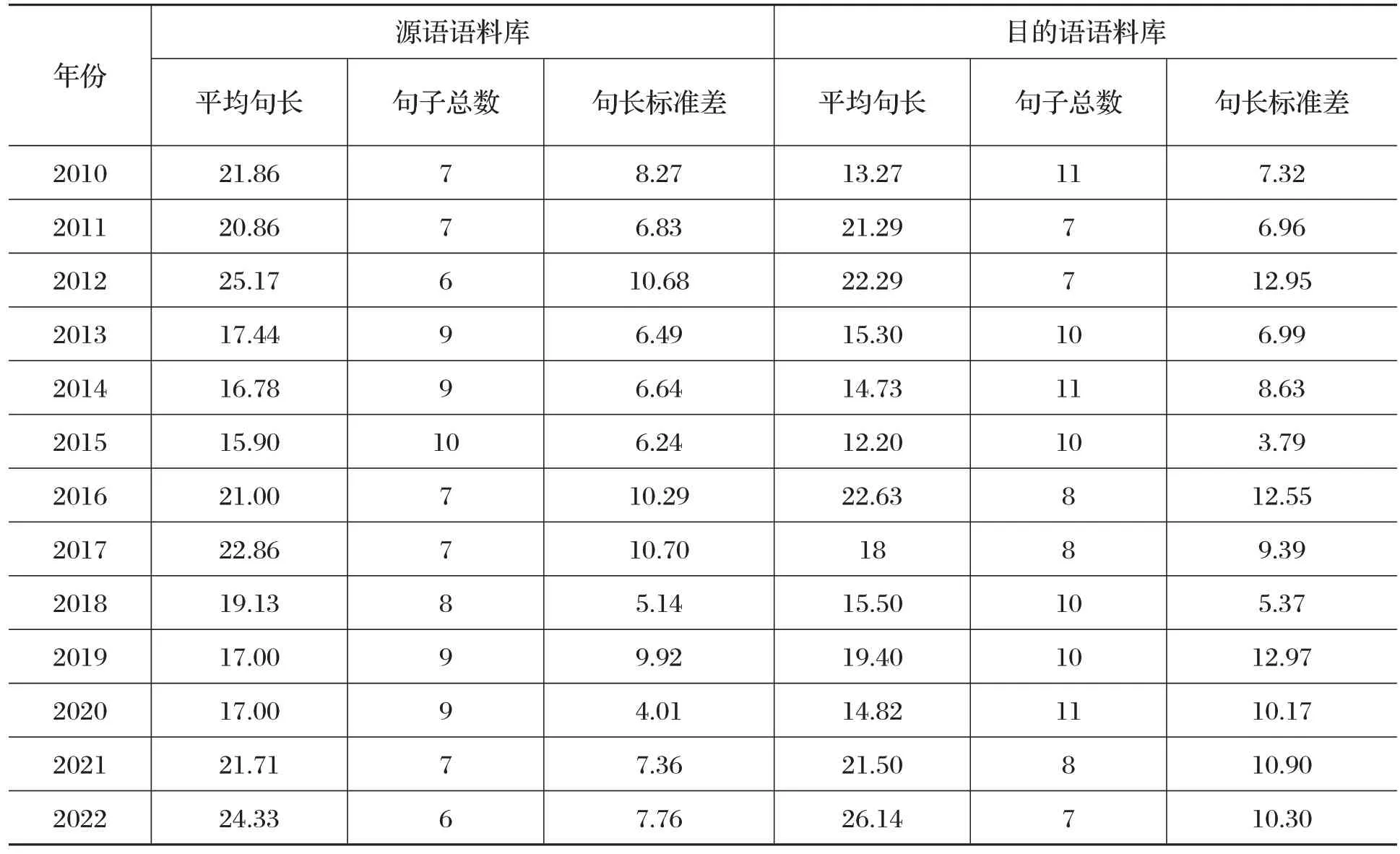
表3 语料库源语、目的语平均句长、句子总数、句长标准差对照表
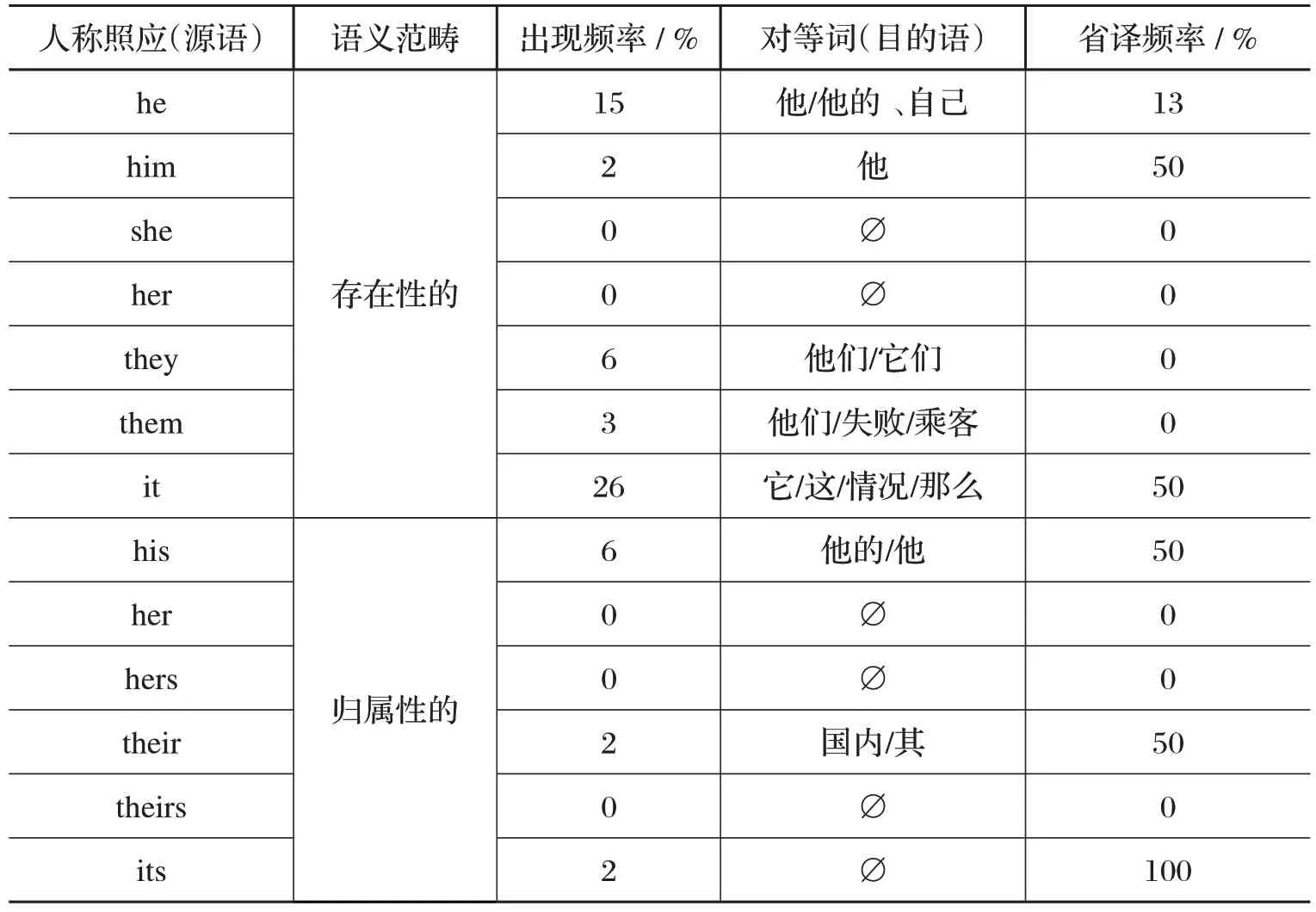
表4 语料库源语、目的语衔接手段(人称照应)对比

表5 语料库源语、目的语衔接手段(指示照应)对比
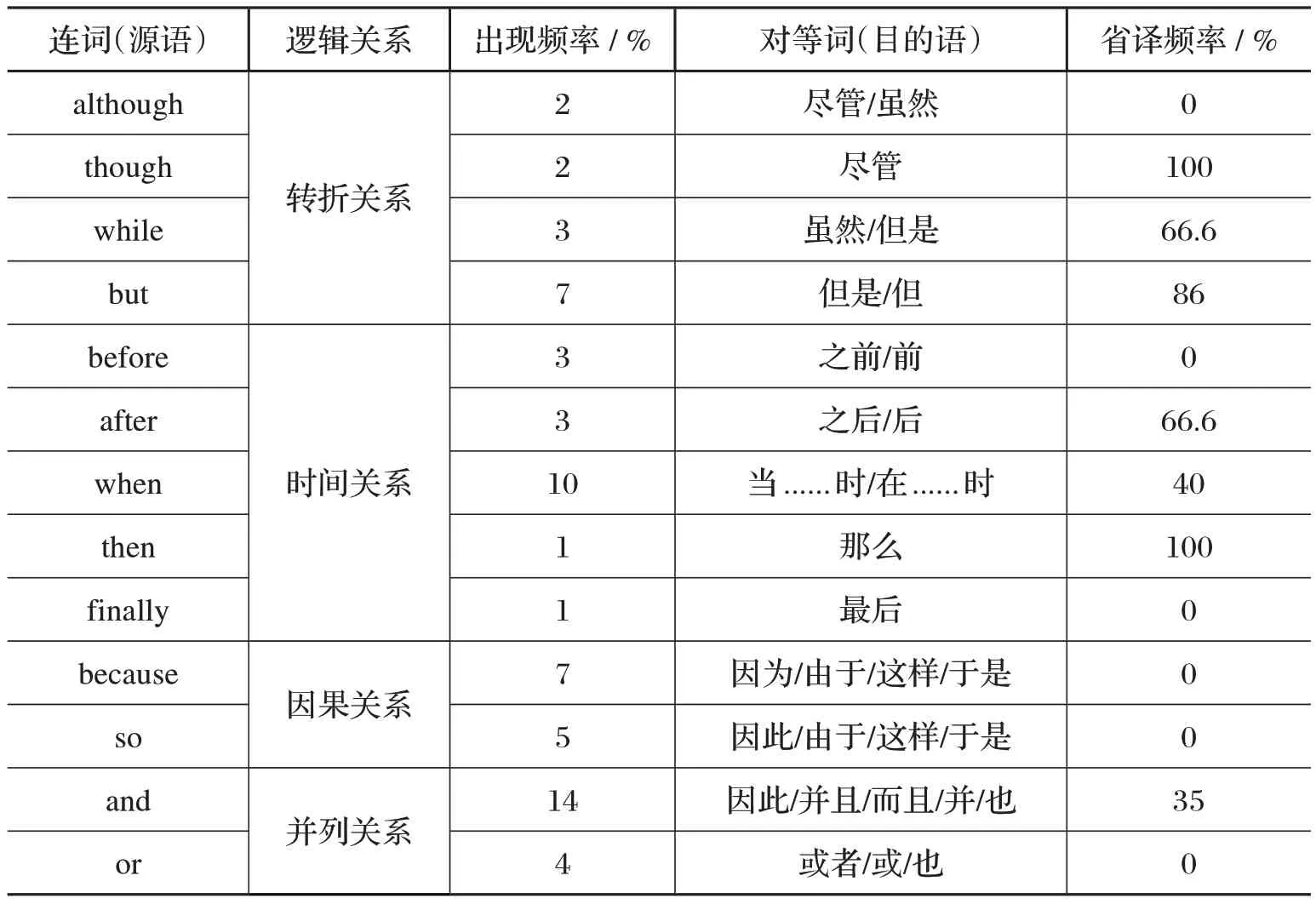
表6 语料库源语、目的语衔接手段(连词)对比
就句子总数而言,源语语料中历年的文本中句子总数控制在6 到10 句之间,相应地目的语语料库中句子总数多在7 到11 句之间,而且目的语文本的句子总数总是大于源语文本的句子总数,这与英语重形合,句子结构主次分明层次清晰,汉语重意合,句子没有主谓形式协调一致的关系,不受形态的约束,句子结构灵活多变,组句的自由度很大有关。
就句长标准差而言,通过比较我们发现在多数情况下,源语语料库文本的句长标准差与目的语语料库文本的句长标准差同步,只有2015 年和2020 年是例外,而且这两年数值走向呈相反方向,这表明2015 年源语文本中句子长度与平均句长的差异较大,而目的语文本中句子长度与平均句长的差异缩小了;与之相反,2020 年源语文本中句子长度与平均句长的差异较小,而目的语文本中句子长度与平均句长的差异增大了。
2.语篇衔接手段
功能语言学认为,语篇是一个语义连贯的整体。语篇内存在各种衔接机制,它们使语篇从结构和意义上连接起来,形成一个有机整体。语篇的衔接手段分为语法衔接和词汇衔接,前者包括照应、省略、替代和连接,后者包括复现和搭配。[11]43由于篇幅所限,本研究只考察照应和连接作为衔接手段在句法特征方面的体现。
(1)照应
照应在语篇衔接中的作用主要体现在超句结构中的照应成分与照应对象之间的相互参照关系或解释关系。照应分为外指照应和内指照应,外指照应不具有语篇衔接功能,只有内指照应具有语篇衔接作用。人称照应指用人称代词及其相应的限定词和名词性物主代词所表示的照应关系。根据韩礼德和哈桑[12]44,人称照应系统中只有第三人称代词具有内在的语篇衔接功能,属回指照应。本研究通过对自建英汉平行语料库的检索,发现英汉语在第三人称照应衔接方面的共同点和差异。
通过语料库检索,我们发现代词it 和he 出现的频率最高,体现了第三人称代词的回指照应功能,对照目的语文本,它们的翻译也很灵活,这主要取决于它们所依存的语境。此外,代词it,him,his,their,its 的省译率也很高,这主要是因为汉语在不引起指代不清的情况下,倾向于省略代词,这与汉语重意合完全一致。同时,英语代词所有格his their 的并不拘泥于原文,而是取决于语境,译法比较灵活。
指示照应是指使用指示代词或相应的限定词以及冠词等所表示的照应关系。在指示照应中,发话者是通过指明事物在时间或空间上的远近来确定指示对象。就指示词所指的时间和空间概念来说,this,these,now 和here 指近,that,those,then,there 指远,而the 是中性的。从语篇衔接的角度看,指示词一般用于回指照应。本研究通过考察自建英汉平行语料库中指示代词、指示副词以及定冠词the的回指照应功能,发现英汉语在指示照应方面存在很大的差异。
通过检索并对照目的语文本,发现定冠词the 和指示代词that 的出现频率非常高,在语篇中起到了很好的衔接作用。相较于the 和that,this 和these 出现频率明显偏低,但较其他指示指代较高。同时定冠词the 和指示代词this,that,these 的翻译比较灵活,主要取决于其所指代的在上文中出现的名词。就省译频率而言,then 的频率最高,这与语料库的规模有关,其次是 that,其省译频率高达55%,定冠词the 和代词this 的省译频率较为接近,最后是these(16%),相对于these,指示代词 those 通常根据具体语境需要译出。
(2)连接
连接是一种运用不同连接成分来体现语篇中不同成分之间具有何种逻辑语义关系的手段。连接作为一种衔接手段,体现了语篇内小句之间的逻辑语义关系。[13]27学界通常认为英语语篇中小句之间逻辑语义关系依靠显性衔接手段连接起来,具有典型的形合标记;汉语则不然,小句之间缺乏形式衔接手段,小句间靠语义形成密切关系,这种衔接关系虽说是隐性的,没有明显的标记,语篇却是连贯的。本研究通过考察自建英汉平行语料库中常用连词的语篇衔接功能,发现英汉语在连接方面存在很大的差异。
通过对语料库中常见的连词的检索,我们发现出现频率最高的是and,其次是when,because,but,so,or,while,before,after,其他连词出现频率相对较低。对照目的语文本,发现除了though,then,finally 之外,其他连词的意思较多,译法较为灵活。就省译频率而言,though 和then 的比率最高,达到了100%,其次是but,after,when,and,它们的省译频率也都在35%及以上。
四、形合与意合所反映的英汉思维差异
语言是思维的外化,也是思维的载体,语言受思维的支配,体现了人类对周围世界的认知过程。不同民族受其社会历史条件的制约和文化传统的影响,有着不同的思维方式。英语重形合,汉语重意合,这与中国人和西方人的思维方式、哲学和美学传统有着密切的联系。受儒家、道家和中国佛教的影响,汉民族的思维习惯重悟性,强调“得意忘形”、以神统形,重“言外之意”,语义模糊,追求“韵致”;与汉语不同,受亚里士多德严密的形式逻辑以及西方理性主义影响,英语民族的思维习惯重理性,强调形式论证,突出语言形态的外露和语言形式的完整性,重“以形显义”。
中国人讲究“天人合一”,认为人与自然是相互联系、相互作用的一个整体,强调人与自然的和谐共生,注重事物的内在联系和各个事物间的辩证统一,属综合性思维,这种思维方式反映在语言上则体现在注重整个句子的意义表达,重个人感受和心领神会,强调根据主观的直觉,从上下文中“悟”出各种关系来,而忽略了各个词语的词性变化和句子之间的显性衔接,组词造句依赖于小句之间隐含的逻辑关系和事件发生的先后顺序以及物体所在的空间位置,因此汉语简约而模糊,形散而神聚。语序是汉语的重要组合手段,体现了中国人的语言习惯、逻辑事理和思维方式。
西方人倡导“天人二分”的哲学理念,强调人与自然的对立,物我分明,注重个体差异性,认为整体只有在个体对立中才能存在,注重逻辑推理和形式论证,属分析型思维,这种思维反映在语言上则体现为注重语言的外在形式,词汇有明显的形态变化,句子结构严谨,小句间的逻辑语义关系存在显性衔接。
综上所述,形合与意合作为语言组织的手段,反映了中国人和西方人不同的思维方式,哲学思想和美学传统。中国人重“悟性”,讲话含蓄,事物之间的逻辑关系是隐含的,而不是外显的,语义模糊;西方人中重“理性”,讲话直接了当,事物之间的逻辑关系是外显的,而不是隐含的,语义清晰,组句谋篇靠显性的手段表明事物之间的逻辑关系。
五、英汉翻译策略
综上所述,英语重形合,词语有明显的语法形态变化,小句之间的逻辑语义关系依靠具有不同语义的连接词连接起来,从而形成一个完整的语义网络系统。汉语重意合,词语没有明显的形态变化,注重“以意统形”,少用甚至不用形式衔接手段来显示小句之间隐藏的逻辑语义关系,强调语篇的隐形连贯。
针对英语重形合汉语重意合的特点,在英汉翻译实践中,我们要熟悉英汉两种语言在宏观和微观层面上的相似性和差异性,根据英汉两种语言的不同特征进行句法转换。英译汉是一个“化整为零”的过程[4]94,译者首先需要从宏观上把握语篇的结构,将其缜密严谨的逻辑结构框架拆散,厘清语篇各组成部分之间的逻辑关系,然后根据具体语境正确理解关键词汇的意义,最后再按照汉语的表达习惯,根据原文的意义和汉语的谋篇机制进行结构重组,发挥目的语的优势,灵活运用各种翻译技巧,提高语际转换的效率和质量。
与此同时,需要格外注意的是,在英汉翻译过程中,将英语显化的衔接手段尽可能转换成隐性的,注重小句间逻辑语义的内在衔接和连贯。此外,根据汉语的表达习惯和语序,把英语中丰富的名词、介词和动词的非谓语形式转化为汉语中占优势的动词或动词短语,[4]96这样才能够译出地道的没有翻译腔的汉语。
六、结语
本研究通过语料检索,发现英语重形合、汉语重意合的假说是基本成立的。英语作为形合语言,以形制意,词语(名词、动词、形容词等)有明显的形态变化,人称代词和指示词在语篇构建中发挥着重要的衔接作用,组句谋篇借助能够体现各种逻辑语义关系的连接词将各个小句组合在一起,形成一个复杂连贯的语义网络系统。与英语相比,汉语缺乏词语的形态变化,很少甚至不使用衔接手段,语篇中的各个组成部分依靠内在的逻辑关系连接起来,语序在汉语组句谋篇中发挥着重要作用。在英译汉的过程中,需分清主从层次,厘清小句间的逻辑语义关系,根据语境灵活删减逻辑关联词,注重达意,不拘泥于语言的外在形式,以神统形,这样才能够体现出汉语的简洁凝练之美,增强译文的可读性,消除翻译腔。同时,要保证汉语形散而神不散,确定符合汉语表达习惯的句子主干和中心、时空、因果、递进、从属、前后逻辑关系等。
猜你喜欢
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
文艺生活·中旬刊(2017年10期)2017-11-19 09:21:42
文艺生活·下旬刊(2017年6期)2017-08-03 08:54:42
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
校园英语·上旬(2017年3期)2017-04-13 17:05:29
校园英语·中旬(2017年1期)2017-02-25 18:45:07
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
语言与翻译(2015年4期)2015-07-18 11:07:45
民族古籍研究(2014年0期)2014-10-27 08:24:34
