
基于序列遗忘行为的动态键值记忆网络
2023-12-13 07:57洪青青魏李婷
扬州大学学报(自然科学版) 2023年5期
孙 浩, 洪青青, 魏李婷, 李 斌
(扬州大学信息工程学院(人工智能学院), 江苏 扬州 225127)
1978年, 知识追踪的概念首次被提出, 其主要任务是根据学生的练习表现动态预测知识状态, 从而预测学生在后续练习中的表现.近年来, 知识追踪成为实现个性化学习的关键研究问题之一.Piech等[1]将循环神经网络(recurrent neural networks, RNN)中的隐藏变量视作学生的掌握情况并应用于知识追踪任务, 提出一种基于深度学习方法的知识追踪(deep knowledge tracing, DKT), 但因其仅使用一个隐藏变量故难以准确说明任一知识点的掌握情况.于是, Zhang等[2]受记忆增强神经网络[3](memory augmented neural network, MANN)启发提出一种动态键值记忆网络(dynamic key-value memory networks, DKVMN), 获得较好的预测性能.Xie[4], Sun[5], 宗晓萍[6]等通过修改DKVMN的内部结构提升了模型预测的准确性,但在遗忘和学习方面仍有待改进.对于遗忘和学习行为, 王璨等[7]利用RNN计算学生的先验基础,选择通用时间卷积网络预测下一题的正确率, 有效融合了学生遗忘行为; Nagatani等[8]考虑艾宾浩斯曲线理论[9-10]在DKT中增加重复时间间隔、序列时间差和过去答题次数等因素进行建模, 提出纳入遗忘特征的深度知识追踪; 李晓光等[11]基于DKT+Forget模型, 考虑学生对知识点的掌握程度, 将其答题结果作为知识追踪过程中掌握程度的间接反馈, 建立了一个融合学习和遗忘行为的知识追踪模型.本文在DKVMN基础上引入重复时间间隔和过去答题次数等特征进行建模,通过门控机制[12]在预测部分整合遗忘因素和学习因素,提出一种基于序列中遗忘行为的动态键值记忆网络(dynamic key-value memory networks-forget, DKVMN-F).
1 建立模型
1.1 问题定义
给定答题者的答题序列X=({q1,y1},{q2,y2},…,{qt-1,yt-1}), 其中qt为问题编号,yt∈{0,1}表示答题者答题是否正确,正确为1,错误为0.知识追踪的主要任务是根据给定的答题序列X,预测时间t内该答题者正确回答新问题的概率p(yt=1|qt,X).
1.2 序列特征提取
根据序列X提取所需特征: 1) 重复时间间隔(repeated time gap, RTG), 即学生对于同一知识点中习题的答题互动与前一次互动之间的延迟时间; 2) 过去答题次数(past test counts, PTC), 即学生针对同一知识点中习题的已答题次数.设置首次出现的问题的RTG为无穷大值, PTC为0.为了避免数据过于稀疏,对提取的特征进行lb(·)运算.提取过程如图1所示.

图1 序列特征提取
1.3 模型框架构建
基于DKVMN的整体架构, 在其预测部分增设重复时间间隔和过去答题次数特征, 再利用门控机制进行特征融合, 改进后的DKVMN-F网络结构如图2所示.由图2可见, DKVMN-F框架由嵌入层、键处理层、读取层、写入层和预测层组成.
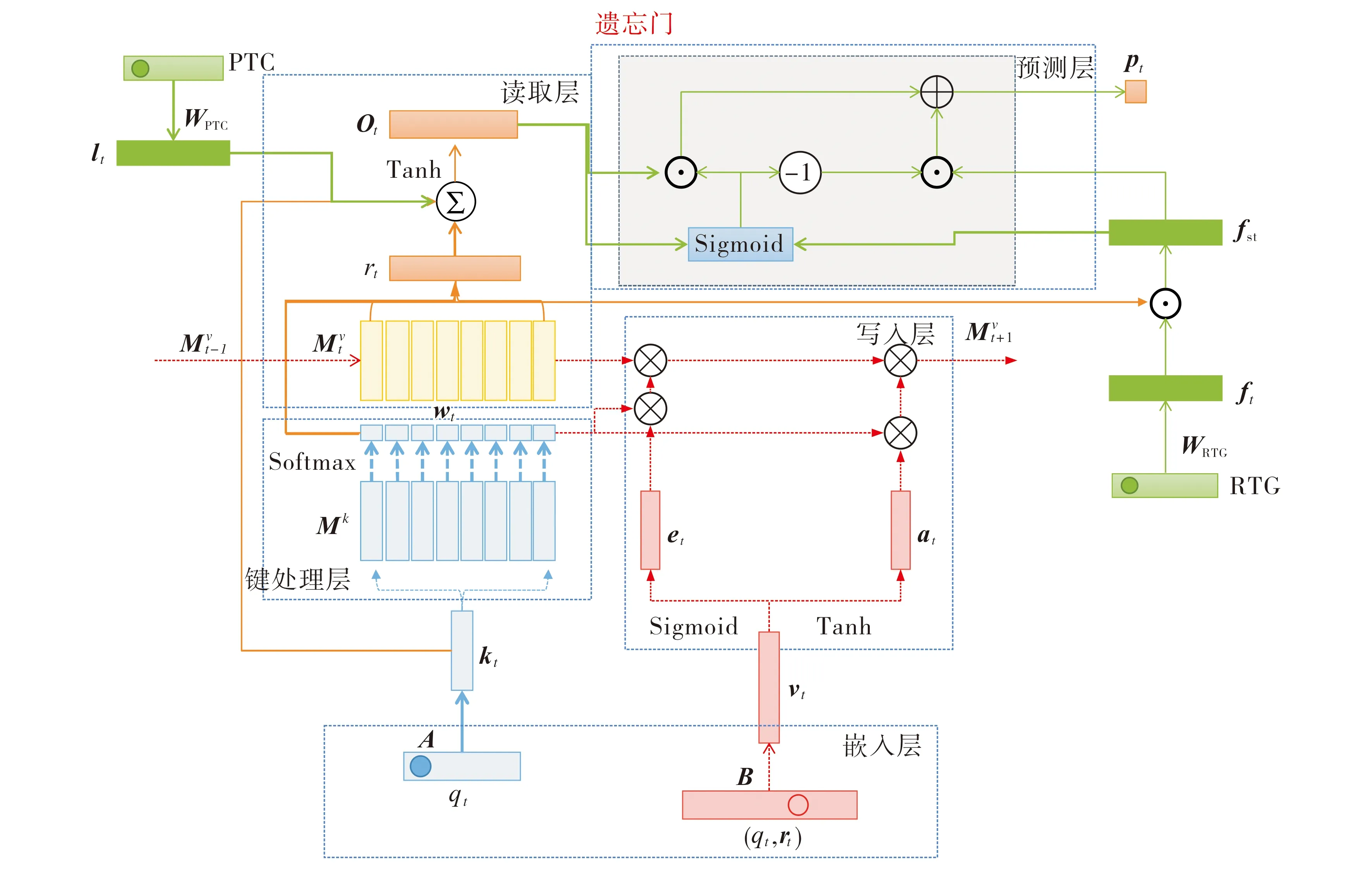
图2 DKVMN-F的网络结构示意图
DKVMN-F模型的实现流程如下:
1) 掌握程度初始化.DKVMN中以键矩阵存储潜在知识点, 值矩阵存储知识点的掌握情况.设定键矩阵(大小为N×dk)和值矩阵(大小为N×dv)的维度, 其中N为潜在的知识点个数,dk,dv为嵌入的维度, 对键矩阵和值矩阵进行随机初始化.
2) 答题序列嵌入.在嵌入层对习题编号qt、元组(qt,yt)进行嵌入.计算元组(qt,yt)的联合表示qyt=2qt+yt, 再将qt、qyt分别乘以嵌入向量A,B进行嵌入, 得到习题编号嵌入kt和联合嵌入vt,kt的维度为dk,vt的维度为dv.将重复时间间隔和过去答题次数特征的独热编码(One-Hot编码)分别乘以嵌入向量WRTG、WPTG, 得到学习因素向量lt和遗忘因素向量ft.
3) 知识点相关性计算.在键处理层通过习题编号嵌入kt与键矩阵Mk=(Mk(1),Mk(2), …,Mk(N))中的每个单元Mk(i)内积, 再进行Softmax激活, 得到kt与键矩阵中每个单元之间的相关权值
(1)
即其与每个潜在知识点之间的相关性.
4) 知识点掌握程度计算.在读取层根据相关性计算所得权值wt计算出习题编号qt所需的知识点掌握情况, 即wt与值矩阵Mv=(Mv(1),Mv(2),…,Mv(N))中每个单元内积的加权和, 所需知识点掌握情况
(2)
采用残差连接方法将习题编号嵌入kt与知识点掌握情况rt相结合, 并引入学习因素向量lt, 得到已掌握信息汇总向量
(3)
其中W1,b1分别为已掌握知识的权重矩阵和偏置向量, 从而提升预测的性能.
(4)
其中We,be分别为遗忘信息的权重矩阵和偏置向量; 然后计算值矩阵中每个知识点遗忘后的值
(5)
其中w′t(i)为利用相关性计算得到的与每个知识点之间的相关性权重; 其次计算从题目中学习的新增信息向量at,
(6)
其中Wa,ba分别为新增学习信息的权重矩阵和偏置向量; 最后更新记忆矩阵为
(7)
6) 答题情况预测.利用遗忘门机制整合知识点掌握程度, 得到学习信息总向量ot和遗忘总向量
fst=wt⊙ft,
(8)
其中ft为遗忘因素向量.首先, 计算门向量gt∈RN用于控制记忆的读写,
gt=Sigmoid(Wo·ot+Wf·fst),
(9)
其中Wo∈RN×N和Wf∈RN×N分别为总学习信息和总遗忘信息的权重矩阵; 其次, 得到整合遗忘和学习的组合信息向量glt∈RN,
glt=gt⊙ot+(1-gt)⊙fst;
(10)
最后, 将组合信息向量glt发送到Sigmoid层, 计算正确回答当前习题的概率
(11)
其中Wg∈RN,bg为组合信息的权重矩阵和偏置向量.
7) 模型优化.使用预测习题答题状况与真实答题状况之间的交叉熵损失函数
L=-∑t(rtlogpt+(1-rt)log(1-pt))
(12)
优化模型.
2 仿真实验
2.1 数据集
本文采用如下4个数据集对模型进行性能评估:
1) ASSISTment 2009.收集ASSISTments在线辅导平台中2009—2010年的学生练习数据, 过滤去除仅一次练习记录的学生练习数据、未标注技能的数据以及重复的数据;
2) ASSISTment 2015.收集ASSISTments在线辅导平台中2015—2016年的学生练习数据;
3) Statics 2011.收集的2011年秋季卡内基梅隆大学某统计学课程相关数据;
4) JunyiAcademy.Kaggle网站中君一书院平台中2018年8月至2019年7月的数据, 约7.2万名学生的1 600万余次练习记录, 并删除仅一次练习记录的学生.
具体的数据集统计信息如表1所示.
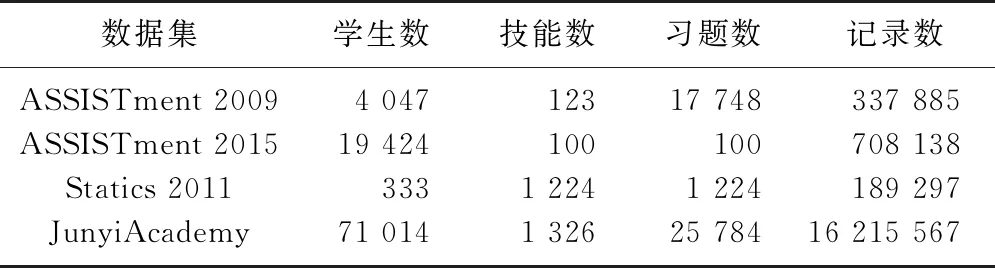
表1 数据集统计信息
2.2 数据预处理
对上述所有数据集通过删除重复数据和部分不完整记录, 处理成如图3所示的数据格式. 图3中第一行表示某学生学习序列的答题总数, 第二行表示完整序列的习题编号, 第三行表示对应的学生答题情况.取最大序列长度为200, 截取多余部分作为新的学生序列, 序列不足200进行补0操作.将数据集按4∶1划分为训练集和测试集.
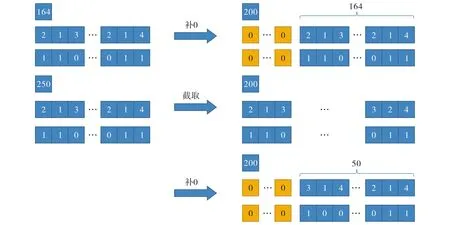
图3 数据预处理示意图
2.3 评价标准
选择曲线下面积(area under curve, AUC)和准确率(accuracy, ACC)作为评价指标, 其中AUC表示接收者操作特征曲线(receiver operating characteristic curve, ROC)曲线下的面积, ACC的计算式为:
ACC=(NTP+NTN)/(NTP+NTN+NFP+NFN),
(13)
式中NTP为正确分类为正样本的样本数,NTN为正确分类为负样本的样本数,NFP为错误分类为正样本的样本数,NFN为错误分类为负样本的样本数.AUC的取值范围为[0.5,1], 其值越接近1, 模型的效果越好.
2.4 参数设置
设置kt的维度dk=50,vt的维度dv=200.根据数据集调整Mk和Mv的潜在知识点个数N, 令Mk的维度为dk,Mv的维度为dv, 将重复时间间隔及重复答题次数的嵌入向量维度均设置为N.
2.5 对比实验
为了验证本文模型的有效性, 将DKVMN-F模型与DKT[1]、DKVMN[2]和DKGRU[4]模型进行比较, 结果如表2所示.由表2可知: DKVMN-F在ASSISTment 2009、ASSISTment 2015和JunyiAcademy数据集上的预测性能均最佳, 而在Statics 2011数据集上预测性能略低于DKGRU; 在Statics 2011数据集上, DKVMN-F模型虽未获得最佳效果, 但与DKVMN相比, AUC提升了3.22%, ACC提升了0.7%.结果表明, 通过门控机制整合遗忘因素和学习因素是有效的.

表2 各模型在4种数据集的预测性能对比结果
猜你喜欢
中学生数理化·七年级数学人教版(2022年9期)2022-10-24
数学小灵通(1-2年级)(2022年6期)2022-06-17
数学小灵通(1-2年级)(2022年5期)2022-06-01
新高考·高一数学(2022年3期)2022-04-28
数学小灵通(1-2年级)(2022年3期)2022-03-17
中学生数理化·中考版(2021年12期)2021-12-31
中学生数理化·七年级数学人教版(2021年6期)2021-11-22
数学小灵通(1-2年级)(2021年3期)2021-04-13
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
福建基础教育研究(2019年9期)2019-05-28
