
基于BERT与Loc-Attention的文本情感分析模型*
2023-12-13 12:13何传鹏周科亮王明胜李佩佩
传感器与微系统 2023年12期
关键词:文本
何传鹏,黄 勃,周科亮,尹 玲,王明胜,李佩佩
(上海工程技术大学电子电气工程学院,上海 201620)
0 引 言
在自然语言处理领域,一个重要分支是文本情感分析领域,文本情感分析也称为意见挖掘,针对带有情感色彩的文本进行预处理、分析、归纳和推理,认知大众喜、怒、哀、乐等情感,了解大众舆论对某产品或某事件的看法,引导大众对某产品或某事件迅速做出决策[1~3]。
随着深度学习的发展,基于BERT(bidirectional encoder representations from transformers)预训练模型和长短期记忆(long short-term memory,LSTM)的深度学习模型成为主流方法。汤世松等人提出基于BERT与双向LSTM(bidirectional LSTM,Bi-LSTM)的情感分析模型[4]。LDA(latent Dirichlet allocation)在提取特征方面有广泛应用[5,6],付静等人[7]提出基于BERT和LDA主题模型的新闻短文本分类模型,将词向量和位置(location,Loc)向量输入到BERT模型中,通过自注意力(self-attention,SA)机制提取全局特征,将上述向量与LDA 主题模型获得的特征进行融合拼接,解决数据稀疏问题。从上述可知,在短文本情感分类的过程中可使用Bi-LSTM 提取上下文信息[8,9],然而现有方法并没有考虑主题词与文本的相对位置关系对文本情感分类的影响。
本文提出一种基于位置权重和注意力(attention)权重加权求和的文本情感分析方法。通过使用LDA 主题模型[6],并将由设置阈值(threshold)筛选出来的主题词和原文本进行融合拼接输入到BERT模型[10~13]中,进行词向量训练,利用SA机制将文本信息与主题信息进行充分融合,加入文本的位置权重和注意力权重,使用Bi-LSTM 网络进行隐含向量的表示,最后通过SoftMax 层输出进行情感分类。
图1为BERT内部结构,本文使用拼接最后4 层隐含层的向量作为最终的词向量表示。

图1 BERT内部结构
1 模型介绍
本文提出基于BERT 与LDA 的Loc-Attention 的Bi-LSTM文本情感分析模型,具体部分如下:1)利用词袋(bag of words,BOW)模型对句子构建单词清单,使用清单的索引来对文本进行向量表示,将其输入到LDA 模型中,利用吉布斯采样的方法直至收敛从而获得文章主题分布以及词分布,设置合适阈值筛选出相应主题词;2)将提取出来的主题词和原文本进行融合拼接输入到BERT 模型中,进行词向量训练,利用SA 机制得到包含主题信息的文本词向量以及包含文本信息的主题词向量,将主题词向量作为文本的关键词向量表示;3)利用Bi-LSTM,加入文本的位置权重,结合注意力权重最终得到的文本特征表示为带有位置权重的文本特征和注意力权重的加权求和,进行情感分析模型的训练;4)通过SoftMax层进行情感分类,对实验结果进行评价。
研究框架和情感分析模型框架如图2、图3所示。

图2 研究框架

图3 情感分析模型框架

图4 注意力模块框架
1.1 提取文本主题信息
统计数据集的词频信息,并对其建立字典,对文本进行BOW表示,输入到LDA模型中,使用吉布斯采样学习到文本主题分布以及主题词分布,则第m条文本主题分布为=[z1,z2,…,zk],其中,z为概率,z之和为1;同理可得到主题对应的词分布=[w1,w2,…,wn],w为每个词的分布概率,每个主题下所有词的概率和为1。因此,特征词矩阵可表示为
式中 M为特征词矩阵,由主题概率与词概率分布依次相乘得到,设置合适阈值筛选出相应主题词,为下文进行向量表示提供文本主题来源。
1.2 利用BERT进行向量融合表示
本文将文本主题信息与文本信息进行拼接作为BERT输入,每个文本矩阵可表示为W =〈wc,wt〉,其中,wc为文本的词向量表示,wt为含有该文本主题信息的词向量表示,W为dk×(n+m)的矩阵(dk为词向量的维度,文本长度为n,主题词个数为m),选择wt作为关键词向量表示。
本文使用BERT拼接最后4层隐含层的向量作为最终的词向量表示。
1.3 构建情感分析模型
1)Bi-LSTM编码层
通过1.2 节得到文本的向量表示为context,context =得到的关键词信息为target 文本,target =
Bi-LSTM[14,15]的传播过程如下所示
式中xt为上述context 文本和target 文本向量表示为Bi-LSTM前向传播输出的隐含状态单元,为Bi-LSTM 后向传播输出的隐含状态单元,最终得到的context隐含层输
2)位置编码层
通过LDA 模型得到文本的主题信息,视为文本的target。在模型的编码层中生成了文本的语义向量,理论上更靠近target的上、下文单词应该比更远处的单词对其情感影响更大,所占的权重也应该更大,因此本文模型提出位置编码层对target 的位置信息进行表征,对target 距离较近的单词赋予更大的权重,距离较远的单词赋予较小的权重。
设target中的词权重为0,其他位置t处单词的权重计算公式为
式中N为context中的词,M为target 中的词,l为词间距离。依据上述公式可知:l越大,权重越小;反之,l越小,权重越大。context中的某个词对target中的每个关键词进行式(6)的权重计算,接着对权重值进行求和操作,得到这个词对关键词的位置权重,依次类推计算每个词对关键词的权重。最终得到基于每个target 的权重向量a1,a2,…,
an。
3)注意力层
本文通过设置位置编码层来提取文本的位置信息,并赋予权重,将位置权重与文本特征进行聚合,得到带有位置权重的文本特征;在注意力机制下,语义编码不再是文本的直接编码,而是各个元素按其重要程度加权求和得到的,注意力模块框架如图1 所示,它为每个词向量生成节点级注意,以便选择最具情感特征的部分级特征。
对于每个词向量,计算对于每个target 的注意力α1,α2,…,αn
式中F(·)为表征文本特征与targetywt之间关系的编码函数,为非线性变换。最终得到的文本特征表示为带有位置权重的文本特征和注意力权重的加权求和
1.4 训练模型
将注意力机制得到的文本的特征表示Ui通过SoftMax函数进行归一化操作,得到情感极性的概率值,从而得到该文本的情感值
式中 Wl为全连接层的权重矩阵,bl为偏置项。
使用Cross Entropy作为损失函数,通过反向传播算法对模型进行训练,更新各层网络的参数,利用最小化交叉熵对模型进行优化,交叉熵代价函数为loss
式中D为训练集数据大小为句子真实的情感值,C为情感分类的类别数,本文类别数为2,λ‖θ‖2为正则项。
2 实验结果与分析
2.1 实验数据集
通过使用谭松波博士标注的酒店评论数据集以及某外卖平台的外卖评论数据集来进行实验分析。酒店评论数据集采用总数为6000条和10000条的数据集来进行实验,分别标注为CSCHb-1、CSCHb-2,具体如表1 所示。外卖评论数据集中“积极”、“消极”情感评论各为3 000 条,共6 000条数据。
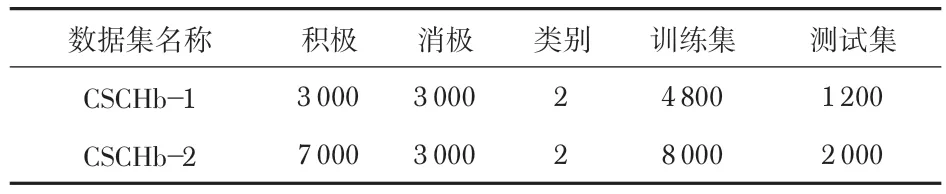
表1 酒店评论数据集概况
2.2 参数设置
本文采用的参数主要有:选用BERT基础结构BERTbase网络结构,其中,网络层数设置为12,隐含层维度为768,注意力的多头个数设置为12,句子的最大长度取值为60,每批次大小为64,迭代次数为80 次,双向LSTM 的层数设置为1,隐含层节点数为128。
2.3 实验结果分析
使用式(1)计算符合条件阈值的每条评论中的主题词信息,根据情感准确率以及阈值选择主题词,本文CSCHb-2酒店评论实验选取阈值为0.04,则筛选超过阈值的主题词通过在设定LDA主题数量为35,40,45,50 时,评论中符合要求的主题词如表2所示。

表2 主题词提取(相应主题数)
本文采用困惑度(perplexity)为指标计算最佳主题数,困惑度值计算方法如下
根据式(11)可画出Perplexity-topic number曲线如图5所示。
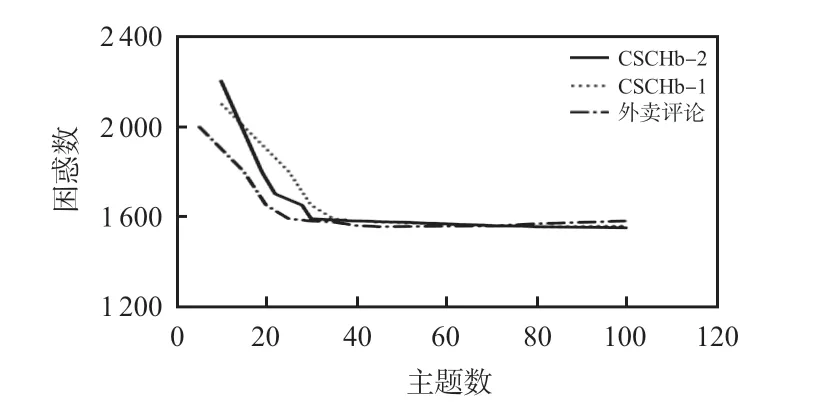
图5 Perplexity-topic number变化曲线
当主题数为45 时,困惑度值较小而主题数不至于过多。实验确定CSCHb-2数据集主题数为45。同理可确定CSCHb-1、外卖评论数据集主题数分别为40,30。
外卖评论数据集实验结果曲线如图6 所示。由图可知,train loss 随着训练周期的增加,一直在减小,train accuracy一直增加,随后在一定范围内波动;test loss先减小后增加,当训练周期为5 时达到最低,test loss 为0.321 2,test accuracy为0.877 5,当训练周期为6时,test accuracy为0.880 0,准确率达到最大。酒店评论数据集实验结果曲线如图7、图8 所示。由此可知,模型的准确率不仅与训练周期有关,而且与主题的个数、文本关键信息的选择有关。
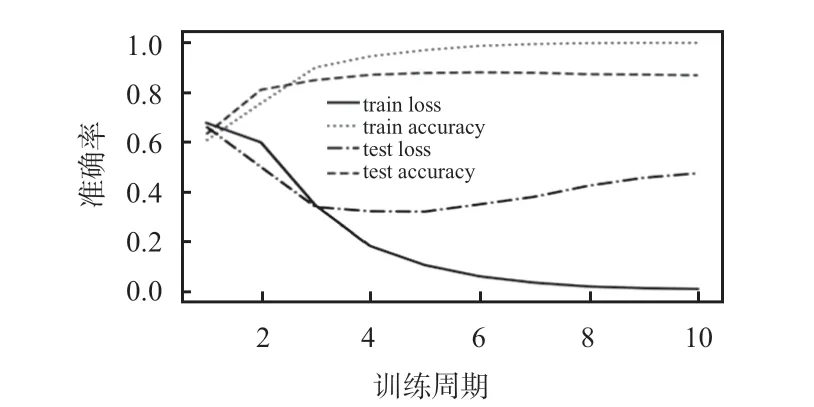
图6 外卖评论实验曲线

图7 CSCHb-1 评论实验曲线

图8 CSCHb-2 评论实验曲线
本文通过6组实验,分别在测试集上计算得到精确率(P)值、召回率(R)值和F1值,准确率达到最高时的3个数据集的对比结果如表3所示。根据表3列出的实验结果可知,BL-LABL 在CSCHb-1、CSCHb-2 以及外卖评论数据集上的运行结果要优于其他模型。
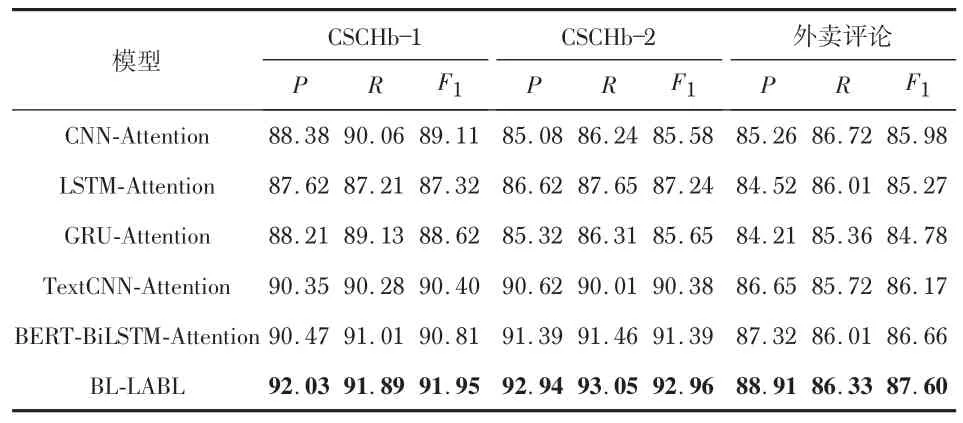
表3 CSCHb-1、CSCHb-2、外卖评论数据集实验结果 %
从实验的综合指标F1来看,BERT-BiLSTM-Attention比前4个模型的实验结果都要好,证明了BERT 预训练模型训练好的向量比其他模型训练出来的向量能得到更丰富的语义信息以及上下、文信息,Bi-LSTM 模型能更好地捕捉双向语义信息,特征提取优于LSTM模型,最终在3 个数据集上的F1值分别提高了3. 49 %、4. 15 %、1. 39 %;BLLABL模型比BERT-BiLSTM-Attention得分更高,在CSCHb-1数据集上P,R,F1值分别提高了1.56%、0.88%、1.14%,说明结合LDA主题模型进行主题信息的提取以及加入带有位置权重的文本特征的模型能有效地提高获取文本中关键信息的能力,结合注意力机制对文本进行情感分类的模型性能要优于其他模型。
3 结束语
通过在两种实验数据集的实验结果证明了本文提出的情感分类模型优于传统的注意力情感分类模型。本文的实验只是针对二分类的文本以及较短文本进行情感分析,没有考虑多分类的文本以及长文本的分类,所以接下来的研究是进行多分类的文本情感分析以及长文本情感分析,得到文本更丰富的语义信息以及更准确的情感倾向。
猜你喜欢
云南教育·小学教师(2022年4期)2022-05-17
新世纪智能(语文备考)(2020年4期)2020-07-25
新世纪智能(语文备考)(2020年4期)2020-07-25
艺术评论(2020年3期)2020-02-06
制造技术与机床(2019年10期)2019-10-26
新世纪智能(语文备考)(2018年11期)2018-12-29
电子制作(2018年18期)2018-11-14
小学教学参考(2015年20期)2016-01-15
语文知识(2015年11期)2015-02-28
语文知识(2014年1期)2014-02-28
