
融合注意力与多层次特征提取的行人再识别方法*
2023-12-13 12:12张天奇张琳钰
传感器与微系统 2023年12期
张 荣,王 进,张天奇,张琳钰,万 杰
(南通大学信息科学技术学院,江苏 南通 226000)
0 引 言
行人再识别的任务是在非重叠的摄像机中识别匹配出感兴趣的行人。行人再识别在智能安防中的应用至关重要,然而由于姿态、遮挡、背景、光照、相机分辨率等外在因素的影响,行人再识别至今仍然是一个非常具有挑战性的问题。先前大多数研究集中在利用卷积神经网络提取行人的全局特征[1~3],然而这些基于全局特征的方法很难解决由于遮挡、光照不均匀等造成的错误匹配问题。
很多研究人员引入了局部特征。例如一些研究引入了人体姿态信息学习局部特征[4,5],以及提出切分行人图像,在不同图像之间的各个部位匹配中学习局部特征[6,7]。然而,这些学习局部特征的方法,忽略了由于图像背景复杂度高以及拍摄距离远近不同,而导致局部特征提取存在偏差的问题,因此融合后的特征并不能很好地表示行人特征。
注意力机制是指捕捉图像的特定区域,通过关注图像特定的区域来提高识别精度。然而,注意力机制更注重特定的小区域,往往会忽略大的全局信息,因此,往往也会遇到由于弱化了全局特征导致的识别精度不高的问题。
本文提出了一种新的行人再识别方法,该方法将局部特征与全局特征相融合,通过在提取特征的过程中嵌入空间注意力机制与通道注意力机制,使得提取的局部特征与全局特征能更好地表示行人特征。并且在训练过程中对部
分数据集进行随机擦除与随机加噪处理,从而达到提高行人再识别精度和鲁棒性的效果。
1 行人再识别方法
1.1 网络结构
本文模型结构如图1所示。将注意力机制嵌入到Res-Net50网络的第4层后,并嵌入了通道及空间2种注意力机制。采用2个网络分支结构,分别代表全局特征分支和局部特征分支,这种结构不仅解决了单分支网络结构导致特征提取不全面的问题,而且解决了多分支网络结构较复杂,网络训练难度较高的问题。

图1 网络结构
1.2 特征提取与融合模块
本文方法使用ResNet50网络进行一个特征映射C×H×W,通过特征映射后,最后一个卷积层输出的结果是N×C×H×W,其中,N为输入N张图像,C为通道数,H×W为空间尺寸大小。接下来通过2个分支分别进行局部特征提取与全局特征提取。
1)对于局部特征分支,先采用水平池化,将ResNet50得到的特征映射进行水平池化后得到C×H×1 的特征映射,从而得到局部特征。对得到的局部特征进行局部距离测量,得到2 幅图像的相似度。对于局部特征对齐,如图2(a)所示,采用局部特征对齐最小距离算法来匹配局部信息。在计算局部距离之前先做处理,假设有2 幅图像a和b,局部特征分别表示为
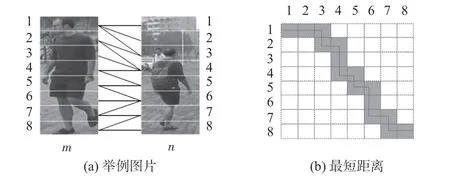
图2 计算局部距离
将该距离标准化到(0,1)之间,则为
式中i为图像a的第i部分,j为图像b的第j部分。计算2幅图像的最短距离,这里用图2(a)举例说明,将图2(a)中图片m与图片n的所有局部特征映射到一个矩阵中,即如图2(b)所示,竖着的数字表示图片m的所有局部特征,横着的数字表示图片n的所有局部特征,那么它们之间的最短距离如图2(b)中的阴影部分所示。这样计算的距离是2幅图像的省时又简便的最短距离。从图2中的2 幅图像容易看出,对于不同的2幅图像a和b,从(1,1)走到(i,j)时的最短距离计算方法为
式中Sl(i,j)为2幅图像a和b从(1,1)走到(i,j)时的最短距离。则图像a和图像b总的局部距离表示为
2)对于全局分支,使用全局平均池化将特征映射转化为全局特征向量,用全局距离计算得到2幅图像的相似度,对得到的局部距离结果与全局距离结果使用传统的三元组损失函数计算损失,经过训练得到最终训练结果。对于全局距离,假设有2幅图像a和b,Fga和Fgb分别为图像a和图像b的全局特征,那么图像a和图像b的全局距离可定义为
2幅图像总的距离为
这里简单地将两部分所占的比例设置为1∶1。知道2幅图像局部距离与全局距离的总距离后,通过2 幅图像的总距离来计算2幅图像的相似度就变得很容易。
1.3 注意力机制模块
如图1 所示,为了不改变ResNet50 的网络结构,注意力机制模块嵌入到最后一层卷积中,从而在训练时可以使用ResNet50的预训练参数。
空间注意力机制是为了寻找网络中最重要的部位进行处理。如图3(a)所示,对输入的特征x,分别进行最大池化(maxpooling)和平均池化(avgpooling)操作,得到不同的特征和,将得到的特征拼接起来形成一个有效的特征描述符,最后对该特征描述符沿着通道方向进行池化操作,得到空间特征Fs(x)。具体计算过程如下
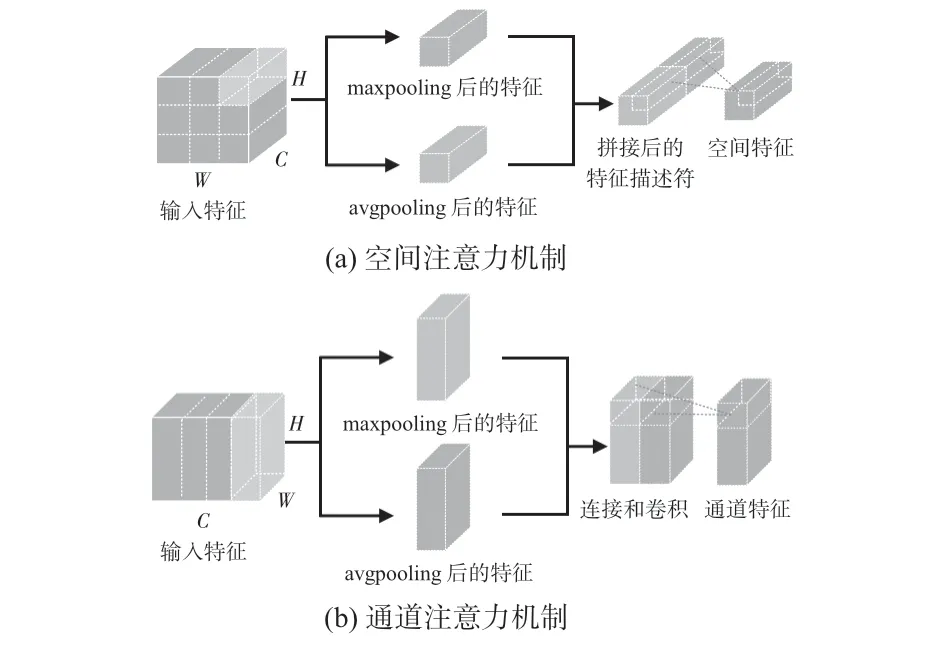
图3 空间与通道注意力机制
式中M为Sigmoid函数,V为卷积核大小为7 ×7 的卷积层,T为拼接函数。
对于通道注意力机制,是通过利用不同通道的重要程度从而有针对性地增强或抑制不同的通道,以此来达到提取的特征可以更好表示行人特征的目的。如图3(b)所示,首先对输入的特征x分别进行最大池化和平均池化操作,得到不同的特征和。与空间注意力机制不同,将得到的特征分别经过卷积层和ReLU激活函数层进行卷积和拼接,从而得到通道特征Fc(x)。具体计算过程如下
式中M为Sigmoid 函数,f1和f2分别为不同卷积核大小的卷积层,R为ReLU激活函数。
1.4 数据增强模块
在本文方法中,对输入的行人图像先进行部分数据的随机擦除以及随机加噪声处理,如图4所示。模型训练时,设定概率p对输入的图像进行随机擦除和随机加噪处理。当概率p设置为0.5时,表示输入的样本有50%被处理后进行训练。在Market1501数据集上进行了超参数p的取值实验,p取值为0.2,0.3,0.4,0.5,0.6,0.7,实验结果发现当超参数p取值为0. 5 时训练的模型的均值平均精度(mean average precision,mAP)和Rank-1 值最高,因此在以下实验中取该超参数p为0.5。

图4 数据增强图像示例
1.5 损失函数
采用了SoftMax 和TriHard 损失函数[8]。对于全局分支,用LID表示SoftMax 损失,Lglobal表示全局分支的TriHard损失。对于局部分支,用局部距离来计算TriHard 损失,用Llocal表示局部分支的TriHard损失,则总损失函数为
2 实 验
2.1 数据集介绍
实验使用了3个数据集进行验证及消融研究。其中,Market1501数据集包含1501个不同的行人,共32668张图像;CUHK03数据集包含1 467 个不同的行人,共13 164 张图像;DukeMTMC-ReID数据集包含1 812个不同的行人,共36 411张图像。
2.2 实验设置
实验基于Pytorch 深度学习框架,使用ResNet50 作为骨干网络,并使用SoftMax 损失及TriHard 损失训练。模型在ImageNet[9]上进行预训练且1 ×1卷积层使用Pytorch默认的初始化方式进行初始化。模型使用Adam 梯度优化器,训练批次大小设置为32,网络训练周期数设置为300,前150个周期学习率设置为0.0002,从第151个周期开始,学习率下降为0.00002,衰减权重设置为0.00001。网络模型的输入图像都被调整为256 ×128,数据增强部分进行了调整,除了常见的数据增强方式随机反转和剪裁以外,加入了随机擦除以及随机加噪声处理来增强模型的鲁棒性。
2.3 实验分析
2.3.1 消融实验
实验的具体设置如表1 所示,ResNet50 表示仅使用SoftMax损失和TriHard损失的基线模型,GL表示局部特征与全局特征相结合的特征提取模块,att表示注意力机制模块,ers表示数据增强部分的随机擦除及随机加噪声模块,RK表示为提高性能引入RK 重排序技术[10]后的精度。表1分别给出了添加各个模块的mAP和Rank-1精度,从表中可以看出:1)添加局部与全局特征模块的网络mAP 和Rank-1精度明显高于不添加该模块的精度;2)在添加局部与全局特征融合模块的基础上再添加注意力机制模块的网络mAP和Rank-1精度明显高于不添加注意力机制模块的精度;3)添加随机擦除与随机加噪声模块后网络的mAP和Rank-1精度又高于不添加该模块的精度。

表1 消融实验结果%
2.3.2 与相关方法比较
如表2 所示,在Market1501 数据集上,本文方法实现了82.1%的mAP和93.0%的Rank-1精度,相比于同时使用软注意力和硬注意力的HA-CNN[11]方法,本文方法提高了6.8%的mAP和1.8%的Rank-1精度;并且在使用重排序RK技巧的情况下,得到了92.1%的mAP 和94.3%的Rank-1精度,相比于仅使用局部特征动态匹配的AlignedReID ++(RK)[12]方法,本文方法提高了2.7%的mAP和1.5%的Rank-1精度。对于CUHK03 数据集,对比时使用的是Zhong Z 等人[10]提出来的带有检测边界框的训练和测试协议,本文方法实现了64.5 %的mAP 和68.1 %的Rank-1精度,相比于HA-CNN[11]方法提高了26. 2 %的mAP和26.4%的Rank-1 精度;在使用重排序RK 的情况下,得到了79.2%的mAP 和77.3%的Rank-1 精度;相比于AlignedReID ++(RK)[12]方法,本文方法提高了9.0%的mAP和9.7%的Rank-1精度。在DukeMTMC-ReID数据集上,本文方法实现了71.8%的mAP和83.9%的Rank-1精度,相比于HA-CNN[11]方法,本文方法提高了8. 0 %的mAP和3.4%的Rank-1精度;并且在使用重排序RK技巧的情况下,获得了86.0%的mAP 和88.0%的Rank-1 精度,相比于AlignedReID ++(RK)[12]方法,本文方法提高了4.8%的mAP和2.8%的Rank-1精度。

表2 在3 个数据集上实验对比%
3 结 论
本文提出了一种融合注意力与多层次特征提取的行人再识别方法。该方法只需要2个分支进行局部与全局特征提取,减小了多分支网络结构的复杂度,在结合局部特征与全局特征的同时,融入了空间注意力机制与通道注意力机制,增强了特征表示能力。在行人再识别的3 个主要数据集上实验,表明了该方法的有效性,并通过与现有的行人再识别方法对比显示了本文方法的优越性。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
小雪花·成长指南(2022年1期)2022-04-09
意林(2021年5期)2021-04-18
扬子江(2019年1期)2019-03-08
金桥(2018年4期)2018-09-26
传媒评论(2017年3期)2017-06-13
小天使·一年级语数英综合(2017年6期)2017-06-07
第二课堂(课外活动版)(2016年2期)2016-10-21
中国卫生(2014年5期)2014-11-10
