
一种开源许可证的检测与依据兼容性的推荐方法
2023-12-13 01:39游传捷
小型微型计算机系统 2023年12期
游传捷,朴 勇
(大连理工大学 软件学院,辽宁 大连 116620) (大连理工大学 软件工程研究所,辽宁 大连 116620)
1 引 言
随着开源社区的发展,基于开源组件的软件开发方式变得越来越流行[1,2],这种方式节约了软件开发周期中所需的软件开发成本、提高了软件的可扩展性、提升了安全性.开源软件在为人们提供便利的同时,相应的对使用者的行为做出了规定,也就是开源许可证.开源组件[3]通常包含一种或多种类型的开源许可证,其描述了基于该开源组件进行软件开发时需要遵循的条款与规定.开源组件重用与修改时的许可证分析是合法地进行软件修改与重用的先决条件,开源许可证其授权一般是针对软件的开放源代码,允许用户在承认软件原作的著作权基础上对软件源代码的使用、修改、商用等权益,以确保开源软件能够合法地被软件开发者自由使用和共享[4].在使用开源软件时,为避免产生法律问题[5-7],需要考虑几方面的问题,如开源要求、修改申明、专利允许、许可证兼容、商标使用、网络分发等[8].当前存在很多有关开源软件的纠纷,这都是因为忽视了开源许可证的重要性,将开源软件进行了不正规的使用,违反了开源许可证中的条款,从而为自身带来了法律上的问题[9].如微软Windows 7就因为其下载软件使用了“GPLv2”的ImageMaster工具代码[10],最终引发了开源法律问题.
开源软件以及开源许可证目前正处于极速发展阶段,OSI(Open Source Initiative)开放源码促进协会认可的许可证类型已达百种以上,未在认可中的许可证更是大有所在,这些许可证都可能在开源中所使用.同时申明许可证有时会根据实际情况做出一些更改,这为开源项目中的许可证检测带来麻烦.许可证的类型众多、申明多变使得人工的检测方法耗时耗力,通过程序进行许可证检测早已成为必要的需求.
目前存在的许可证检测器主要有两种方式完成检测,一种是使用规则匹配的检测方式.Daniel M.German[11]等人构造了4种信息库用于检测许可证,关键字、等价短语集、句子标记表达式、许可证规则.通过将待分析数据替换为标准短语集的形式进行正则匹配来检测许可证的类型,从而创建了Ninka工具,由于其考虑到了大部分的许可证申明变化,相较于其他检测器来说检测效果更好.Pombredanne等通过创建大量的规则文件,其中包含大多数许可证的主要短语以及短语的变体,再根据许可证文件与规则文件的匹配结果给出许可证类型,从而实现了检测许可证工具Scancode-Toolkit(GitHub中的发布的一个开源许可证检测工具).Ohcount和OSLC(Open source license checker)工具都为许可证类型创建了正则表达式进行匹配.第2种检测方式是由惠普公司的Fossology[12]工具创建的,其首先使用单词标记过滤器将文本标记为格式化版本,再使用bSAM符号对齐矩阵对每个文件的标记化版本进行分析相似度,其主要缺点是速度较慢以及准确度有待提升.
以上的多数检测许可证工具都需要构建复杂的匹配信息库,同时使用匹配的方式来检测许可证,这种匹配方式虽然是精确的,但在需要进行许可证信息更新或是添加新许可证信息时,需要大量的人力进行匹配库的添加或是匹配规则的修改[13].而大多数许可证申明有规范性好、重复度高等特点,本文采用相似度检测不仅能节省构造与维护匹配所需规则的时间成本,更能在检测结果中有相似度上的体现.对于许可证的兼容分析方面,主流的检测工具只能检测项目中的开源许可证类型,并不能基于许可证的类型给出许可证的兼容性和法律风险的分析结果,而现有的关于兼容性以及冲突分析方法主要是检测许可证使用是否违规或是从某些角度描述许可证的兼容,缺乏真正能从许可证文本之间提取的兼容性特点,这使得当前许可证兼容性分析大多停留在人工分析的层面,需要有相关专业知识的人员对项目中全部许可证类型进行分析,自动化推荐许可证为其提供了便利[14-16].
综上所述,为了改进大量匹配所带来的高成本,本文主要使用了相似度比较作为检测许可证的方法,通过机器学习的方式检测而非消耗大量人力去构造完整的匹配规则.同时本文也吸收了前人的经验,使用简单的匹配作为结果的校准,在最终的检测效果上对比以上所提到的检测器有所提高.另外,本文提出了一种自动化兼容性分析的方法,对于项目中多种许可证给出分析结果,最终开发出系统LSCK(License similarity check).本文第1节对开源软件以及其相关研究现状进行了概述,第2节分析了许可证中需要关注的问题,并给出了本文对于解决这些问题提出的系统架构,第3~第5节提出了相应的解决方法,最后给出了实验结果以及结论.
2 开源许可证
开源许可证是对代码的一种许可证授权,一般是为了以法律的形式对受版权法保护的开源软件的使用、复制、修改和分发行为进行规范[17].开源许可证一般存在于项目代码文件开头的注释中,这代表此代码文件中使用了某些开源组件或是作者希望开源而为代码添加许可证,若整体项目开源则需要携带一个总许可证来让他人遵守开源规则.通过了解Ninka实现机制 、《开源许可证兼容性指南》等文章,总结出了许可证识别和兼容性判断问题的3类方向:
1)找到许可证申明:查找项目中所有可能的许可证申明位置.许可证申明通常存在于代码文件的头部注释中,传统的许可证检测系统采用全检测的形式,无论文件是否为代码文件都统一进行识别.开源社区的代码类型中,流行编程语言如python、java、c、c++、go等占比非常高,而这些编程语言的规范化特性让提取其头部注释变得很轻松.许可证申明还可能存在于项目根目录的“LICENSE”文件或是“READEME”文件中,这种申明为项目整体的许可证申明.
2)识别申明类型:识别出许可证类型;对于项目整体的许可证申明,“LICENSE”文件为许可证文本的复制,很难在其基础上有所改动,本文使用Jaccard方法直接进行文本相似度的比较,时间复杂度低的同时效果也很好.对于头部注释的许可证申明,通过浏览多数开源项目以及观察其他开源检测工具中的规则检测,基本可以将申明分为两类:按照许可证文本指示编写申明以及简要的编写申明许可证.
规范的许可证一般都会带有许可证申明编写的范例[8],如图1所示.

图1 许可证申明范例Fig.1 Example of open source license statement
简要的许可证申明通常只会说明许可证类型,或是加上许可证的URL链接或是项目中许可证地址,例如“This program is under xxx License ,see
3)兼容性分析:确定项目中所包含的许可证有无兼容性问题.目前的兼容性权威文件少之又少,2020年底业界首部《开源许可证兼容性指南》正式发布,其根据8个许可证的常见特性对许可证进行了分析,但其中也仅仅总结了12个许可证类型之间的兼容性关系.一方面是由于许可证条款的复杂性,多数时候需要消耗大量的人力进行条款的比较和分析,另一方面,许可证规模的庞大以及许多许可证编写不规范,使得兼容性分析更加困难.本文参考Georgia M.Kapitsaki[18]以及王志强[19]等所提出的兼容性模型,利用有向图算法实现了许可证兼容性的检测.
根据以上探究方向制定图2的许可证检测和分析架构.
3 BERT模型生成文本向量
由于BERT模型的语义理解能力出众,近年在NLP(自然语言处理)任务上表现十分出色,对于专有领域进行部分微调便有良好表现.其模型具有很高的扩展性,将专有领域的数据进行训练后就可以执行面向该类专有领域的多种任务,且由于BERT模型已对很多基本的语料进行了预训练,大多数任务即使不进行微调也能有好的结果.BERT模型首先将需要处理的句子(单个或是两个句子)进行分词并添加标志位与分隔符如图3所示,模型的输入层是根据标准化后句子生成的的3个向量层叠加,Token Embeddings层根据构造的词典将句中每个词编码为不同的词向量,Segment Embeddings使用不同的向量编码区分输入的两个句子,Position Embeddings对输入的词位置进行编码,通过将3个向量求和可以将句子中的每个词的信息进行表征并交给模型分析.由于需要识别的许可证申明中,短许可证申明往往也含有URL链接,而BERT模型对URL链接也做了分词,URL链接产生的不合语义的文本对于短文本的影响比较大,因此本文采用去除URL链接来构造训练集的方式训练模型,本文实验结果对此有清晰的说明.
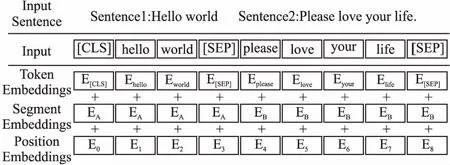
图3 BERT模型输入层Fig.3 BERT model input layer
BERT模型的训练层由12层Transformer Encoder层拼接而成,每一层的输出为下一层的输入,实际上每一层的输入与输出都是将数据构造了成了一个首部标识位加上数据中的分词加上分隔位的标准形式,并将每一位表示为了768维度的向量(标准长度)形式来进行多次特征提取.由此可见,模型的每一层输出向量都包含了句子的语义信息,这些向量经过处理都可以作为原始句子的句向量生成,本文也在实验部分简单做了部分实验,由于许可证申明与规范的申明之间差异不会非常大,所以本文采用了生成句向量与原始句子相关性好的生成结果.
能对句子进行句向量生成后,本文使用单个BERT模型对数据库存储的申明事先进行编码,在对比许可证申明向量x时,只需与数据库中的向量y做出余弦相似度比较,即:
(1)
不同类型的申明的区别明显,相似度判定效果显著,但对于同类型的许可证判定效果并不显著.例如“BSD-2-Clause”与“BSD-3-Clause”申明之间的差距只有一句话而其他部分完全相同,这导致相似度判定并不能将两者很好的分隔开.对于这种情况本文将含有多版本的许可证类型分成了多个类型集,将相似度检测的结果归属到类型集中而并非直接归属到单一的许可证中,例如常见的“GPL”、“BSD”、“MIT”等等,因此基于相似度的检测也是基于许可证类型集进行检测的.
在拓展部份本文也对基于BERT-flow[20]简化后的向量处理BERT-whiting做出了尝试,但实验数据的结果并不理想.由于BERT-whiting将语料库中数据向量标准化,即:
(2)
其中u为均值向量、W为协方差矩阵.但在本文中所对比的文本不一定是某一类型的许可证申明,可能并不属于任一类型,本文需要在对比结果中加入所有负样本集的向量参数,由于多种多样的负样本加入标准化中,负样本的大量添加反而对所需比较的正样本造成较大影响,提高了精确度但降低了很多召回率,导致实验结果不可用,标准化参数求解公式如式(3)、式(4)、式(5)所示:
(3)
WT∑W=I
(4)
(5)
在本文的相似度比较中采用这种方式效果欠佳.但在文本分类中对于分类量覆盖广、待分类文本类型确任在已知类别中的情况,使用BERT-whiting处理生成向量后的实验效果会有明显提高.
4 AC自动机关键字提取
对于机器学习生成向量的相似度检测来说,当遇到申明编写混乱或是文本过于相似时,不能保证检测结果完全正确.本文根据的传统检测器的匹配思想,采用了关键字匹配的方式来确认相似度匹配结果,文本扫描器根据许可证不同类型对应的关键字,对待扫描文本再次进行扫描,匹配到对应的关键字之后,可以根据扫描出的类型与文本向量识别的类型以及URL检测的类型得到一个综合的评判,结果更为准确.实际在扫描的过程中,本文用模式集合P{p1,p2,…,pm}对一段文本运用AC自动机进行匹配检测,假设文本长度为n,可以在O(n)时间复杂度内找到文本中的所有匹配模式.
对于模式匹配P{“he”,“his”,“her”,“she”}本文创建树形结构,如图4.树中虚线表示下一次匹配中如果没有子节点能匹配上时,当前节点应该移动的位置.带有下划线的节点存储当前成功匹配的模式信息.假如待匹配文本为“sher”,在匹配到“she”后,当前节点的位置在右下角的“e”节点,而“r”并没有出现在当前节点的子结点中,因此按虚线移动当前节点到左边的“e”节点,左边的“e”节点存储了“he”的模式信息所以“he”也匹配上了,同时当前节点的子节点有“r”节点并移动,“her”也匹配文本.系统仅遍历了一次待匹配文本就能将所出现的模式全部匹配上.本文将节点中的字符替换为字符串,创建了类似于{“Lesser General Public License v2.1”,“Affero General Public License version 1.0”,“Apache License Version 2.0”,… }的关键字匹配模式,通过匹配申明中的关键字可以进一步确定申明的类型.
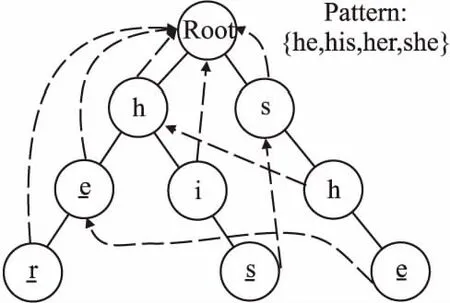
图4 AC自动机样例Fig.4 Example of AC automata
在上一部分相似度检测中,本文可以比较好的检测出许可证所属的类别集,而检测出的类型可能会由于许可证不同版本改变较小而失去意义,而关键字检测往往会精确的给出具体的类型以及版本.因此,使用AC自动机进行关键字检测能帮助系统对相似度检测的结果进行精确化处理.本文没有只进行关键字匹配而不进行相似度检测,这是因为当待检测文本中出现了关键字,但待检测文本并非为许可证申明而仅仅是提及该许可证时,就会出现结果的错误.所以相似度检测和模式匹配的检测是相辅相成的.
5 有向图推荐算法
Georgia M.Kapitsaki[18]等人分析常用的许可证类型之间的兼容性并设计了较为全面的许可证兼容性有向图.在查阅GNU官网对于GPL许可证的描述中发现,由于他们扩充了“GPLv2” 许可证和 “GPLv3”许可证的兼容性,在许可证文本以及许可证申明文本中加入了“either version x of the License,or (at your option) any later version.” 使得许可证版本存在扩充前版本以及扩充后版本,如许多论文中出现的“GPL-2.0”和“GPL-2.0+”.在OSI(Open Source Initiative)开放源码促进协会以及GNU官方中已经只存在更改后的许可证文件,即扩充兼容性的版本,并已采用原命名“GPL-2.0”,原有的未扩充兼容性版本只存在于早期的开源项目中,现在基本已被取代.本文使用官方命名重新构建了兼容图,并进行了部分优化,如图5所示为改进的许可证兼容性有向图.
在有向图中箭头指向表示许可证单向兼容,如“AFL-3.0”到“OSL-3.0”有单向箭头,其表示若项目中出现了这两种许可证,可以按照箭头指向的“OSL-3.0”许可证进行分发,虚线则表示两端许可证的兼容性不能继续向下传递,即“Apache-2.0”与“MPL-2.0”兼容但与“LGPL-2.1”不兼容.最终可推荐的许可证不必限制于原有许可证类型中,但需要寻找到最优推荐(最宽松的许可证),例如项目中所含许可证有[“Apache-2.0”,“MPL-1.1”],经过推荐算法得出项目最终可以按“MPL-2.0”进行分发.以下算法1描述了分析项目许可证组兼容性的过程,利用res_list(比较集合)存储已访问过的许可证的推荐结果,利用lic_temp(中间集合)存储单个许可证与已访问过的许可证的推荐结果.
算法1.许可证组的兼容性分析
输入:license_list{L1,L2,…,Ln}/*项目许可证类型集合*/
输出:res_list{Lr1,Lr2,…,Lrn}/*许可证集合推荐许可证,若不兼容则为空*/
过程:
1.Begin/*对类型集合进行预处理,初始化中间集合*/
2.for lic in license_list:/*读取类型集合中的许可证*/
if len(res_list)==0:/*若比较集合没有初始化*/
res_list.append(lic) /*初始化比较集合*/
else:/*若比较集合已初始化*/
3. for lic_res in res_list:/*遍历比较集合中的许可证*/
if lic_res==lic:/*若比较集合中许可证与当前类型集合许可证相同*/
lic_temp.append(lic) /*中间集合直接添加许可证*/
continue
else:/*若比较集合中许可证与当前类型集合许可证不相同*/
4. lic_temp = list_add(lic_temp,compatibility(lic,lic_res)) /*中间许可证添加两个许可证的推荐结果,此推荐结果为层次遍历找到的最优结果*/
if len(lic_temp)==0:/*当没有推荐许可证时,也就是许可证不兼容*/
return None
else:
res_list=lic_temp.copy()/*将比较集合更新*/
lic_temp.clear()
5.End/*最终的比较集合则为推荐结果*/
其中compatibility函数为两个许可证求推荐许可证,使用有向图的广度优先遍历算法实现了该函数的功能,所推荐的许可证为同一深度的许可证,即宽松程度相当的许可证,这样就能保证寻找到的许可证是最优推荐(最宽松的许可证).在有向图中虚线表示的不可扩展兼容性,本文使用一个虚拟复制节点来表示所指向的许可证,复制节点只存储虚线关系,原节点存储实线关系.例如:若有许可证l1到l2为虚线,l2到l3为实线,可以构建l2的复制节点l2_virtual,让l1指向l2_ virtual、l2指向l3,这样就可以实现l1只能到达l2而无法到达l3,即虚线的不可扩展兼容性关系.使用以上的方法,能准确地检测出给定的项目许可证类型集合是否兼容、给出集合兼容后的推荐许可证.
6 实验结果
在BERT模型对文本相似度训练中,本文提出了对文本中语义混乱的URL链接对模型训练有较大的影响.对此,本文采用在数据预处理时将URL链接去除的工作形式对BERT预训练模型进行微调,数据集采用的是scancode-toolkit(GitHub中的发布的一个开源许可证检测工具)中的许可证模式规则总结、以及部分非许可证申明的头部注释,对于相同类型的许可证设置标签“1”,对于不同类型的许可证设置标签“0”.表1为两种方式进行数据训练后的准确率对比,由于申明格式不会有很大的变化、申明内容没有复杂的隐喻关系,BERT模型识别申明是否为同一类型的效果非常好,且去除掉URL等无关信息后效果有明显提升.

表1 数据集URL链接对BERT训练的影响Table 1 Influence of data set URL link on BERT training
对于BERT模型如何生成句向量的研究,本文通过BERT模型对STS benchmark(简称STSb)数据集进行有监督训练,将模型中的不同向量作为句向量求余弦相似度,再与数据集标签对应的相似度求Spearman系数,如表2所示.可以观察到BERT模型第四层或第五层输出的CLS向量(模型为每个数据生成的头部标识向量)与实际相似度是具有很大的相关性的,本文使用模型的第4层的CLS对应向量作为句子相似度的输出.
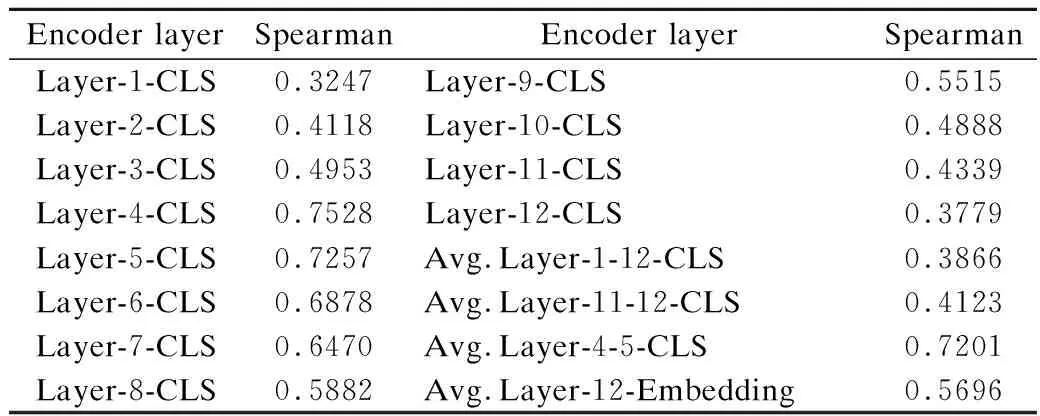
表2 BERT模型不同向量作为句向量的Spearman系数Table 2 Spearman coefficients of different vectors as sentence vectors in BERT model
对工具LSCK本身效果的实验中,基于Ninka[11]工具所做的对比试验,本文也采用了Debian 5.0.2中随机选择的250个应用程序,并在每个程序中随机取出一个代码文件所构筑的数据集进行检测,验证并修正了Ninka论文实验中对数据集的手工标注结果,将本文的程序(LSCK)对于项目组的检测结果与手工标注结果进行检验.与Ninka实验部分相同,本文也将对比结果分为3类:
C类:系统识别结果与手工标注的结果相同.当存在许可证时,系统识别需确保许可证与手工识别许可证版本号以及类型一致,当手工识别出不存在许可证时,系统识别也不能有许可证输出.此时识别结果判定为C(Correct)类.
I类:系统识别结果与手工标注的结果不相同.系统识别输出至少有一个不正确或与手工识别结果不符时,识别结果判定为I(Incorrect)类.
U类:系统识别出未知许可证.该文件的手工识别结果为有许可证,系统识别时能够识别到许可证但无法检测出类型.识别结果判定为U(Unkown)类.
以上每个类互斥,即某识别结果必然属于且仅属于其中一个类别,通过式(6)、式(7)、式(8)可以求出工具的准确率(Precision)、召回率(Recall)和F值(F-Measure):
(6)
(7)
(8)
表3显示了各项工具的分类结果,图6显示了各项工具指标的比较结果,ohcount和OSLC以及本系统都不支持报告未知许可证,所以召回率都是100%.Ninka工具拥有最高的准确率,而本系统由于许可证库的限制,所能识别的类别还未扩容到小众许可证类别,因此出现了手工识别为小众许可证而系统识别不出许可证的情况,不正确的识别数目相比于Ninka有所增加.本系统在综合指标F-measure上领先于其他的系统,这得益于本系统中相似度检测和关键字检测的多层检测机制.同时本系统在数据扩容以及维护方面是最为方便的,这代表系统提升的空间大.综合下来,在所有的研究工具中本系统是有极大优势的.
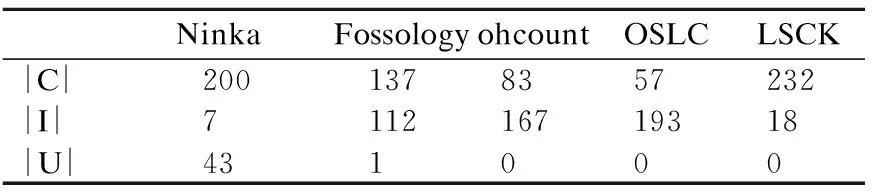
表3 各项工具的分类结果Table 3 Classification results of each tool
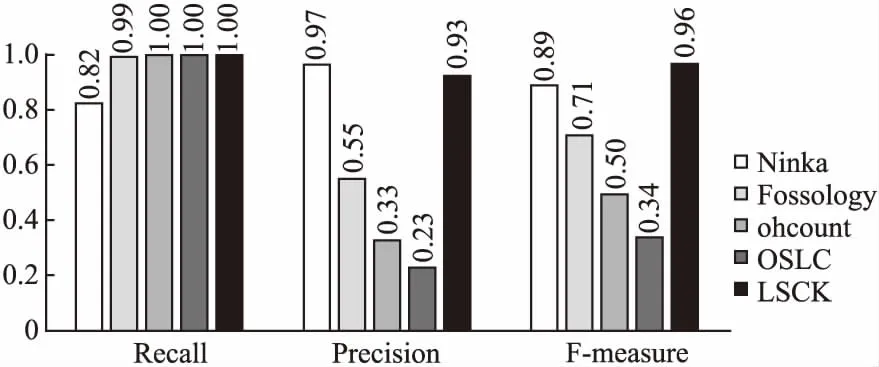
图6 各类工具实验结果指标对比图Fig.6 Index comparison chart obtained from the experimental results of each tool
在对工具LSCK进行测试的过程中,本文选取了一些开源项目利用工具进行分析,并与手工分析结果对比,工具运行得到的结果与实际分析结果一致,表4所示为工具分析了在GitHub上的jieba开源项目(某中文分词工具)的分析结果.
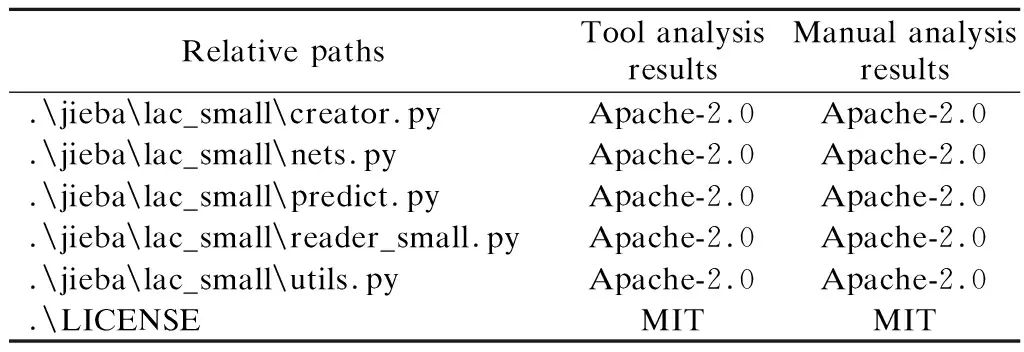
表4 开源项目实际分析Table 4 Open source project practical analysis
从结果中可以看出,该项目按照“MIT”许可证进行发布,而项目中的某些开源组件使用的是“Apache-2.0”许可证.基于《开源许可证兼容性指南》以及各兼容性模型[18,19]中的研究,“MIT”许可证比“Apache-2.0”许可证更加宽松,实际上当项目中既有基于“MIT”许可证的开源组件又有基于“Apache-2.0”许可证的开源组件时,组合后形成的作品按照“Apache-2.0”进行发布是合规的.这里的开源项目出现了类似的问题,项目所使用的发布许可证必须是项目中所有开源组件携带许可证所向下兼容的,而“Apache-2.0”许可证并不是向下兼容“MIT”许可证的,所以按照“MIT”许可证发布并不合规.在本文进行工具测试的过程中发现了很多这类的问题,可见目前对于开源许可证的普及程度是很低的.
另外在许可证推荐部分,本文在实际项目中检测了数种许可证组合形式,系统对于许可证的推荐结果与手工分析一致.当系统对于开源社区中的项目进行检测时,90%以上的项目都使用了单一许可证,出现这种状况主要有两方面的原因:1)大多数项目为小型项目,项目使用了单个或同一项目组的开源组件就可以完成;2)大多数项目为作者原创,仅仅是为了能够被开源使用而添加了许可证.
7 结 论
对于规范的许可证申明使用相似度检测对比使用匹配检测比较重要的优势就是,相似度检测可维护性好,即使不重新训练模型参数,也能通过较为准确的识别语义判别相似度,而传统的匹配检测模式虽然会耗费大量精力编写匹配规则,但也更加精准.所以本文主要使用了相似度检测,同时利用其他方面的检测,如识别URL、识别关键字,能有效地增加许可证相似度匹配的精准度,相较于传统的检测工具,本文提出的工具LSCK更加精准,也更加方便维护和更新.
依据兼容性推荐许可证时,本文根据构造好的兼容性有向图能推荐出最适合项目的许可证.这种方法的使用前提是构造好兼容有向图,但兼容有向图的构造过程无疑是极为复杂的,当前关于这方面的研究也很少,如何顺利判断出两个任意许可证之间的兼容关系、兼容性判断的依据是什么是否能使用机器来判断、如何为有向图添加新的许可证…这些一系列的问题也都有待解决.
可以看出目前各个开源社区都发展的非常好,但关于开源软件许可证的研究依旧很少,开源软件普遍被大家使用的同时,使用者却可能并不了解许可证.大家需要更加关注开源许可证,并让这一部分的知识得到广泛的普及.
猜你喜欢
趣味(数学)(2022年3期)2022-06-02
新高考·高一数学(2022年3期)2022-04-28
中国核电(2021年3期)2021-08-13
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
创新作文(1-2年级)(2019年3期)2019-09-03
环境保护与循环经济(2017年4期)2017-03-03
办公自动化(2016年18期)2016-08-20
办公自动化(2016年18期)2016-08-20
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
