
融合无监督质量估计指标的译文质量估计方法
2023-12-13 01:39朱俊国余正涛
小型微型计算机系统 2023年12期
胡 雨,朱俊国,余正涛
(昆明理工大学 信息工程与自动化学院,昆明 650500) (昆明理工大学 云南省人工智能重点实验室,昆明 650500)
1 引 言
随着神经机器翻译(NMT)技术的发展,机器翻译系统已经被应用在很多现实场景中,但是在一些特定场景中机器翻译系统仍然无法避免地产生错误的翻译,尤其是对于没有足够训练数据的低资源语言对[1].如果因为系统翻译错误而导致最终用户有所损失,可能会损害用户对翻译系统的信任,因此,有一个反馈机制来告知用户给定机器翻译输出的可信度是非常重要的,用户可以在知道机器翻译结果质量好坏的情况下,选择决定是否采用它们[2].
质量估计(Quality Estimation,QE)能够为用户提供这样的反馈机制,它旨在没有人工参考译文的情况下,能够对机器翻译系统的输出译文质量进行实时的预测估计,目前,有不同类型的质量估计任务,包括词级、短语级、句子级和文档级[3].
QuEst[4]和QuEst++[5]等早期的译文质量估计系统严重依赖于语言处理和特征工程,通过从统计机器翻译系统中提取或从源语言和翻译句子中获得大量人工设计的特征,如语言模型概率、长度特征等特征,输入到传统的机器学习算法中估计翻译的质量,这些方法提供了良好的结果,但是适应性较差.随着统计机器翻译(SMT)向神经机器翻译的发展,逐渐被基于深度神经网络的质量估计方法所取代,后者通常很少或者不再依赖于语言处理.例如,在2017年WMT的质量估计评测任务中表现最好的系统——POSTECH[6],它就是一个纯神经系统,并且完全不依赖于特征工程.
目前,质量估计中表现最好的通用方法是基于知识迁移的质量估计框架,这一类方法的模型系统通常分为两个阶段:第1阶段,预测器(Predictor)是在大量的平行预料上进行预训练的“词预测”模型,用来学习源语句和目标语句中有用的向量表征.第2阶段,估计器(Estimator)在少量的QE标记数据上进行训练,学习如何使用在预测器中提取的句对特征上拟合QE标记[7].POSTECH系统的预测器模型是基于一个双向和双语循环神经网络(BiRNN),从影响每个目标单词预测的神经网络组件中生成质量估计特征向量(quality estimation feature vectors,QEFVs),再将QEFVs输入估计器中来产生质量估计.在此基础上,阿里在WMT18的QE评测任务中提出了“双语专家”模型[8],特征抽取模型与估计模型使用了Transformer[9]与双向LSTM的框架,相比于双向RNN的词预测,完全基于注意力的Transformer框架能够更好地对原文和译文中的信息或特征进行抽取,除了利用抽取到的QEFVs外,还利用“双语专家”模型词预测为当前词和强制输出为目标端词之间的差异,人为的设计了四维的错误匹配特征.尽管取得了很好的结果,但这些方法是基于复杂的神经网络,需要密集的资源训练,并且依赖大量的平行数据和计算资源.随着以ELMo[10]和BERT[11]为代表的预训练的语言模型的提出,2019年Lample[12]和Commeau[13]等人尝试将预训练的语言模型BERT和XLM应用到翻译质量估计中,取代了用大量平行语料进行词预测预训练的过程,实验结果表明,这种方法存在一定的潜力.2020年Ranasinghe[14]等人将XLM-Roberta(XLM-R)[15]应用到质量估计任务中,并取得了良好的结果,通过使用微调的跨语言嵌入,避免了使用大量并行语料库进行训练的需要,并减少了复杂神经网络结构的负担.
虽然预测器阶段所需要的大量平行数据和训练的问题得到了缓解,但是估计器阶段需要使用到的人工标记的QE数据仍然是一大难题.QE数据除了真实的原语句和机器翻译的目标句之外,还需要由人工估计或者人工后期编辑产生高质量的注释.然而在实践中获得这样的注释数据是非常昂贵且耗时的,WMT质量估计的共享任务中每年所提供的QE标记数据集通常只有两三万条左右,相比于成百上千万的平行语料而言,是非常稀少的.为了解决这个问题,越来越多的学者开始研究不需要标记数据的无监督质量估计方法.Fomicheva[16]等人提出了一种除了NMT翻译系统之外,不需要训练或者获得任何额外的资源的无监督质量估计方法,利用来自NMT模型的输出概率分布和注意力权重的熵,还通过不确定性量化的方法让输出概率分布能够更有效的代表翻译输出质量.Tuan[17]等人使用合成的标注QE数据来训练无监督的QE模型,通过用机器翻译模型或者掩码语言模型构建合成目标句,并使用TER工具将合成目标句和参考译文进行比较,生成高质量的伪标签注释,但是合成数据会产生偏置噪声,包含很多更严重且稀少的错误.为了缓解合成数据中噪声的影响,Zheng[18]等人提出了一种自监督的质量估计方法,通过恢复被屏蔽的目标词来进行质量估计,进一步提高了机器预测与人工打分之间的相关性.虽然无监督的质量估计方法解决了标注数据稀少的问题,但是整体的结果相比于有标记数据学习的方法,还是存在的很大差距.
前面所介绍的基于知识迁移的两阶段QE框架Predictor-Estimator,证实了通过预测器在平行语料上的训练学习,可以有助于估计器阶段的效果,但两阶段由于训练目标的差异:预测器在平行语料上做词预测的任务,估计器在标记数据上预测翻译的质量.这会导致大规模的平行语料没有被充分学习利用,因为预测器的训练过程与最终的质量估计任务目标存在差异,从而学习不到QE任务实际需要的知识.
考虑到无监督质量估计方法主要是使用机器翻译系统的内部信息作为指标,也就是直接针对最终的目标QE任务对源语言和目标语句进行学习预测,因此有可能将其作为特征直接加入到估计器的阶段,弥补预测器阶段因为目标差异学习不充分的问题.对此,本文尝试将两种质量估计的方法结合到一起,以达到互相弥补问题,提升性能的效果.在这方面,本文尝试使用上述想法作为实验的起点,实验结果表明,引入特定的无监督QE指标的方法优于不引入该指标的方法.
2 相关工作
2.1 无监督QE的估计指标
正如上文中提到的,Fomicheva[16]等人设计了一种直接从NMT系统中提取有用信息作为质量估计指标,在无监督QE方法中取得了最好的效果,甚至可以和有监督的QE模型相媲美.作为翻译的副产品,除了机器翻译系统本身之外,该方法不需要训练或者额外的资源,因此本文中将其中的估计指标提取出来作为特征用于后面的任务.
图1展示了一个使用注意力机制的序列到序列的神经机器翻译模型,同时也是无监督质量估计的估计指标抽取的模型.给定输入序列x=x1,x2,…,xM,假设解码器生成输出序列y=y1,y2,…,yN,输出序列长度为N,生成y的概率可以被分解为:

图1 神经机器翻译模型Fig.1 Neural machine translation model
(1)
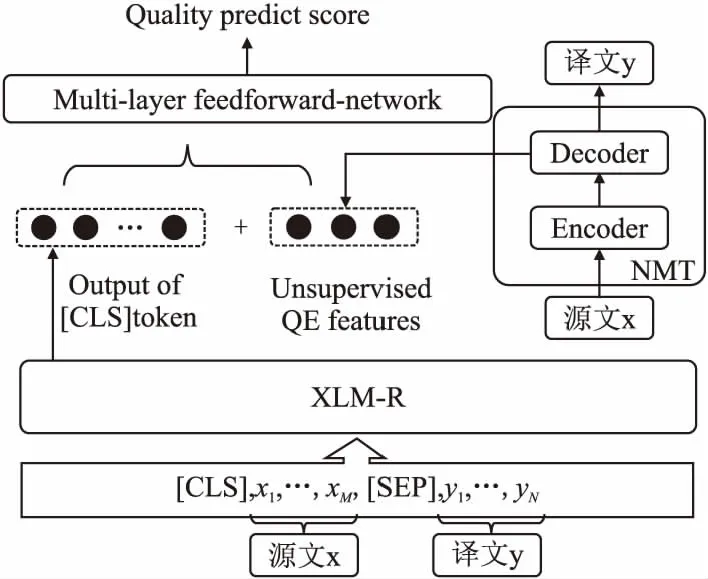
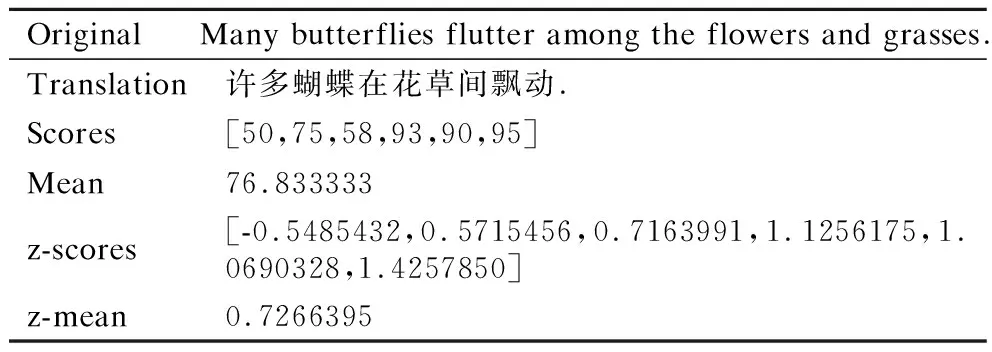
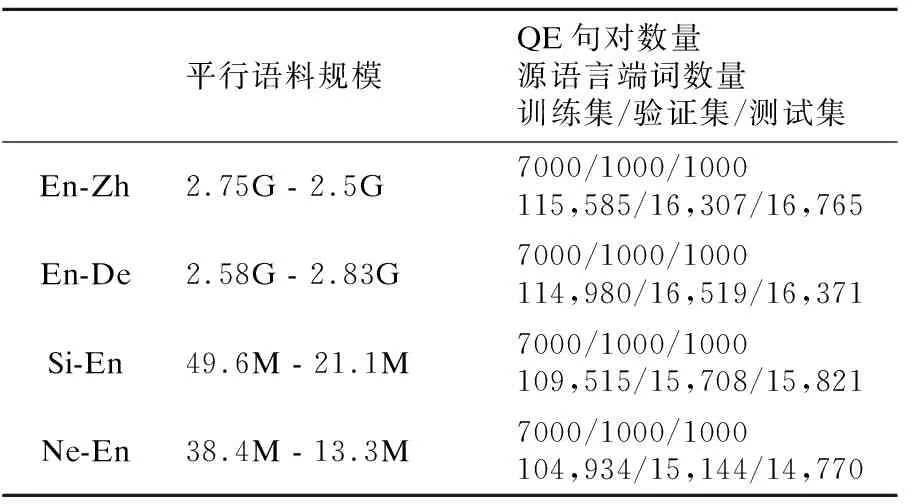
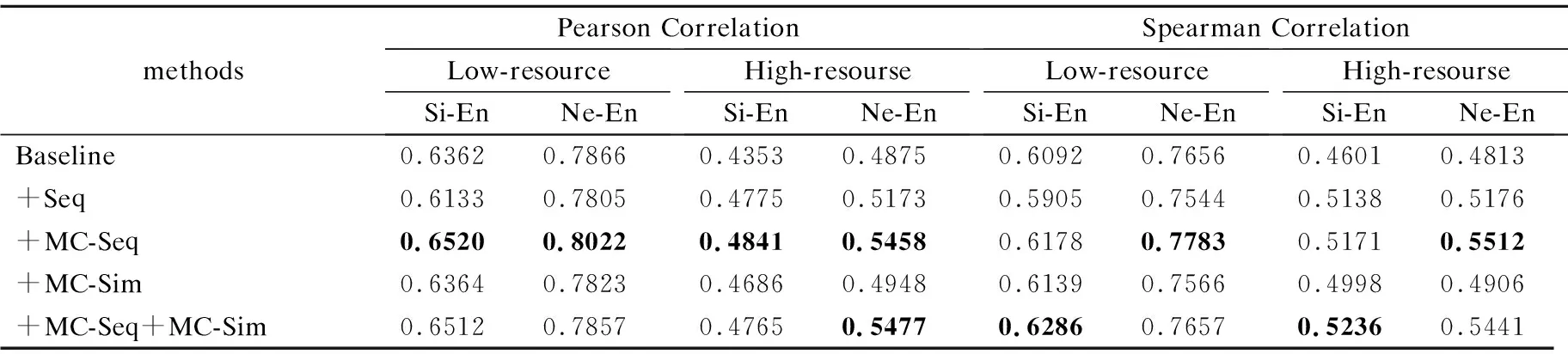
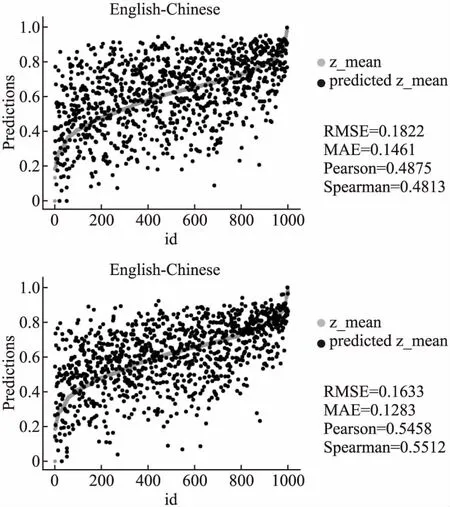
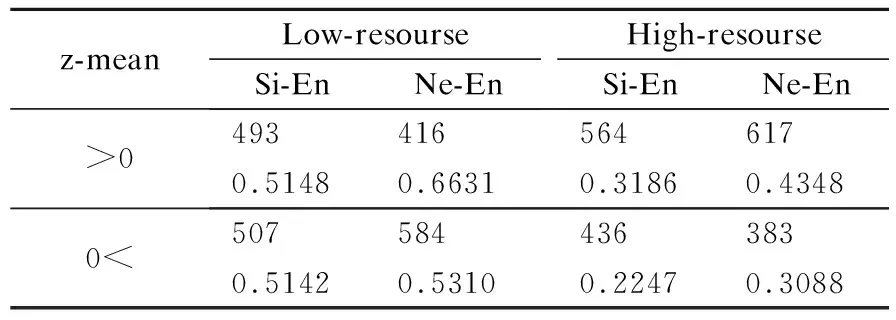
其中θ代表模型参数,系统词汇的概率分布p(yn|y 本文采用Fomicheva等人[16]的论文中的3个无监督质量估计指标来进行特征融入: ·首先是对词级的概率分布取对数,再按照序列长度取平均值得到序列级翻译概率: (2) (3) ·当通过MC dropout进行不确定性量化时,对同一个源语句会产生不同的翻译输出,假设机器翻译不同输出之间的差异也可能代表了不确定性以及源语句的复杂性,计算了一组翻译输出H之间的平均相似性分数: (4) TransQuest是WMT2020的质量估计任务中表现最好的开源QE框架,通过将多语言预训练模型XLM-R应用到质量估计任务中,提出了一个简单的QE框架,可以很容易地训练不同语言对或者不同领域语言的输入,实现不同资源语言对之间的迁移学习[14].其中XLM-R模型是在一个大规模的多语言数据集上进行训练:从CommonCrawl数据集中提取104种语言的过滤文本,在共2.5TB的数据上仅使用RoBERTa的掩码语言模型(masked language model,MLM)目标进行训练.该框架在跨语言问答、分类推理等任务上都取得了出色的结果,同时在QE任务上也获得了更好的效果. 其中的一种框架如图2的左半部分所示,将原文及其译文的连接作为输入序列,然后通过XLM-R模型获取质量估计的输出表征.这样的方式使得模型的训练计算强度要小很多,因为框架不依赖于复杂的输出层,但是因为依赖于预训练的XLM-R模型,模型也存在一些不足.首先,用于训练XLM-R的是多语言的单语语料,会导致模型在双语语义相关方面的学习能力有所欠缺,而且在下游的QE任务中,用于训练的QE标记数据集数量少,会让最终输出的QE表征内容学习不完整.对此,可以尝试将前面的无监督质量估计指标作为特征直接加入到有监督QE的估计器的阶段,弥补预测器阶段XLM-R模型学习不充分的问题. 图2 模型整体框架Fig.2 Model overall framwork 受TransQuest工作的启发,本文所提出的结合有监督QE和无监督QE指标的模型框架如图2所示.首先采用2.1节中所述的无监督质量估计方法,在NMT模型的翻译过程中直接从源文x和译文y中提取出评价指标UnQE:Seq、MC-Seq、MC-Sim,上述3种评价指标的维度数都为1,即每个句子都对应一个分数;再将这3种评价指标当作特征分别融入或组合融入到有监督QE中进行特征融合. 其次如图2左边所示,模型输入为源文x及其翻译y的串联拼接:S={[CLS],x1,…,xM,[SEP],y1,…,yN}序列的第1个标记为[CLS],源文x和译文y中间由标记分隔,通过基于Transformer的预训练模型XLM-R,将序列S转换输出为融合上下文信息的词嵌入向量.序列的第1个标记始终为[CLS],它包含表示整个序列的特殊词嵌入,是代表正在输入的整个序列的一个很好的标记,之后是序列中每个token的词嵌入.将序列S通过XLM-R模型转换后的整个输出切片获得单独的[CLS]token的表征: [CLS]embdding=XLM-R(S)*[:,0,:] (5) 选取[CLS]标记的词嵌入向量作为整个序列的质量估计特征向量,然后在此时将无监督估计指标UnQE融合进去,再将整体的特征向量输入回归器预测序列的质量分数,即输入到具有隐藏层和tanh激活函数的多层前馈神经网络中,使用均方误差损失作为目标函数,然后多维度的张量就会被投射到维度为1的张量中,进而作为译文质量估计分数: QEScore=tanh(W*[CLS]embdding⊕UnQE]+b) (6) 其中,⊕表示两种张量进行连接的操作,W、b参数都是模型训练中学习到的,分别表示权重和偏置的张量,为了能够方便估计翻译的质量,激活函数将特征向量映射到[-1,1]的范围内. QE标记数据:直接估计(Direct Assessment,DA)[20]:与基于机器翻译和参考译文之间的编辑距离的人工翻译错误率(Human-Targeted Translation Error Rate,HTER)[21]不同,每个句子的DA分数由专业的翻译人员进行注释.根据至少3名专业翻译人员对机器翻译质量进行直接的感知判断,每一句机器译文都被在0~100的范围内进行一个打分,然后将DA分数转换为z-scores标准化.尽管HTER是通用的翻译质量估计指标,但研究人员对这一指标的可靠性提出了质疑[22],而DA方法已经被证明可以提高人工估计的再现性,在估计质量估计系统的性能时更加可靠,为自动估计指标提供了更可靠的标准.本文使用发布于WMT2020质量估计任务1中的数据集,表1为中文-英文数据集里面的一个DA数据例子. 表1 人工直接打分的数据例子Table 1 Example of direct assessment data 模型设置:对于无监督质量估计特征指标提取部分,NMT模型的翻译质量受到训练数据集数量的强烈影响,同时也会影响提取的指标.为了区分差异,本文对两类语言对进行了实验:高资源语言对,包括英语-德语(English-German,En-De)和英语-汉语(English-Chinese,En-Zh),低资源语言对,包括僧伽罗语-英语(Sinhala-English,Si-En)和尼泊尔语-英语(Nepali-English,Ne-En).其中的高资源和低资源的区别为用来训练NMT模型的平行语料数据集的多少,使用开源的fairseq工具为4组语言对训练了基于Transformer的NMT模型.针对高资源语言对的NMT模型,采用标准的Transformer架构;而低资源语言对的MT系统采用基于Vaswani等人[9]在论文中定义的 Big Transformer架构进行训练,模型按照FLORES半监督设置[23]进行训练:训练一个反向MT系统,使用该系统将单语目标句子翻译为源语言;然后将有噪音(反向翻译)的源句子和原始目标句子合并,并将它们作为额外的并行数据添加到正向的MT系统中.其中包括使用源语言和目标句子进行两次迭代回译,表2为实验中所使用数据的具体数量信息,其中回译所使用的单语数据即为表中低资源语言对的目标端数据. 表2 实验数据集信息Table 2 Information of experimental data sets 在无监督模型中,对于基于MC dropout的指标,本文使T=10个推理过程来获得后验概率分布,对于每一组语言对中的DA标记数据,都包含7k条的QE标记数据用于训练,1K条用于验证以及1K条用于测试,数据都来源于WMT2020中QE任务的公开数据集.此外,为了能够结合无监督质量估计特征,有监督的质量估计部分使用相同的QE标记数据集进行训练,batchsize设为8,使用Adam优化器,学习率设置为2e-5,同时也设置dropout防止过拟合(rate=0.1).上述关于无监督质量估计的模型和数据在Fomicheva等人的论文中提供1. 特征融合:为了融合有监督的特征向量[CLS]embdding和无监督的估计指标UnQE从而得到最终的质量估计向量H,本 文尝试在融合单独的无监督质量指标时对比了以下两种融合策略: ·Concatenation - 将向量直接按维度进行串联拼接 H=[[CLS]embdding;UnQE] (7) ·Multiplication - 将向量互乘: H=[[CLS]embdding*UnQE] (8) 为了比较上述提出的两种不同融合策略对最终性能的影响,所以在特征融合的QE框架中,本文在中英数据集上进行了一组对比实验,结果如表3所示,结果为基线模型采用两种不同的融合策略和无监督QE指标MC-seq进行融合. 表3 两种融合策略的结果Table 3 Result of two fusion strategies 为了估计翻译质量估计系统的性能,通常使用皮尔逊相关系数(Pearson correlation coefficient)、斯皮尔曼相关系数(Spearman correlation coefficient)、平均绝对误差(MAE)和均方根误差(RMSE).皮尔逊相关系数是体现了人为打分与机器自动打分之间线性相关的重要评价指标.同时为了体现这两个打分向量的单调性走向分布是否一致,使用了斯皮尔曼相关系数来估计自动打分排名与人工打分排名之间的排名分布相关性.MAE和RMSE作为协助评价指标,与以上所述这两个评价指标不一样,它们的分数越低,代表系统性能越好. 从表3中的结果可以看出,串联拼接的融合策略优于直接相乘的融合策略,这可能是因为当1024维的隐藏层向量乘以单维的特征向量时,得到的结果向量中携带的隐式信息重叠,导致融合的结果向量的特征冗余.然而,串联拼接的融合方法根据维数将每个向量直接拼接,该方法不修改每个特征的任何维度内容,使每个特征所携带的信息得到充分表达,特征信息量之间的增加互补使得特征融合的效果更加理想.因此,在下文中,仅对使用效果良好的串联拼接的融合方法的系统性能进行了比较和分析,包括同时融合多个无监督评价指标时,都采用串联拼接的方法. 最终结果:为了比较无监督质量估计框架中抽取出来的单一特征和不同特征组合对翻译质量估计的影响,本文在控制变量条件下进行了几组对比实验,并根据实验结果分析了每个特征对整体性能的影响.在表4中,baseline表示仅使用有监督的TransQuest基线模型,+表示基于基线模型所融合的特征名称.表中给出了人工打分DA和机器自动估计分数之间的皮尔逊相关性和斯皮尔曼相关性的结果.在对4种语言对的实验中,4种不同的无监督QE特征的不同组合都进行了融合实验.与没有融合特征的基线相比,整合的结果在所有4组语言对中都取得了一定的改进,不管是单独还是组合融入.尤其是在单独融合MC-Seq时,结果的提升幅度是最大. 表4 DA和机器自动估计分数之间的皮尔逊相关和斯皮尔曼相关结果Table 4 Result of pearson correlation and spearman correlation between DA and machine automatic evaluation score 不同的组合融入:忽略不同语言对之间的差异,仅针对不同的特征组合融合效果来看,也就是通过纵向观察表4中的最终效果.当单独融合集成MC-Seq时,基线的提升效果最大,最终机器对译文质量估计的预测精准度最高.通过具体分析,可以发现,在皮尔逊相关系数方面,添加MC-Seq后的系统优于仅集成了Seq或者MC-Sim的系统. 其中MC-Seq优于Seq的原因是因为在获取MC-Seq的过程中使用了不确定性量化的MC-dropout,这使得在神经网络的训练过程中,对迭代中的某一层神经网络,随机选择并暂时隐藏屏蔽其中的一些神经元,然后进行训练和优化,在下一次迭代中,继续随机隐藏屏蔽一些神经元,直到训练结束.由于神经元被随机隐藏屏蔽为零,每个批次都在训练不同的神经网络.通过这种方式,模型的泛化性变的更强,减少隐藏层节点之间的交互作用,因为它不会太依赖于某些局部特征,并且可以有效的减少过拟合现象.使用dropout后,模型的不确定性量化提高了机器打分与人工打分的相关性,与融合Seq相比,融合MC-Seq所携带的信息能更准确地反映译文与源语言之间的映射关系,从而提升融合后模型对译文质量估计的准确性. MC-Sim指标是衡量通过干扰模型参数产生的最大似然假设之间的可变性,也就是同一源文产生的不同译文之间的相似性.尽管这一指标可以估计无监督质量估计中的译文质量,但这一特征并没有显著改善提升基线的效果,其中包含的特征信息不能在基线模型的隐藏特征向量基础上提高译文质量估计的效果.由于Seq和MC-Seq之间的信息冗余,两者都是译文序列的概率分布期望值,但MC-Seq的效果更好,所以选择了两者中性能更好的MC-Seq并与MC-Sim相互组合拼接融入.与单独仅集成融合MC-Sim相比,结果有所改善,但是略差于单独集成融合MC-Seq,这也验证了单独集成融合MC-Seq的改善效果最好,且组合比单独集成融合的效果更差. 图3中的两个散点图显示了验证集中1000个句子的机器自动估计的分数与人工评分DA评分之间的相关性.以语言对En-Zh为例,图3上边显示的是基线模型,没有融入任何特征,图3下边显示的是融入MC-Seq后的分布.两个散点图中的人工DA评分(z_mean)都是一样的,因此其在散点图中的分布是固定的. 图3 基线(上)和+MC-Seq(下)的机器自动估计打分(predicted z_mean)和人工评分(z_mean)之间的相关性散点图Fig.3 Scatter plots for the correlation(En-Zh) between machine automatic evaluation score(predicted z_mean) and standardized DA score(z_mean) for baseline(up) and +MC-Seq(down) 通过比较机器自动估计打分(predicted z_mean)在两个图中的分布,可以发现,通过融入添加特征MC-Seq后,predicted z_mean的分布更接近z_mean,更加收敛于z_mean.这进一步证明,添加MC-Seq后模型获得的预测分数与人工的DA分数具有更高的相关性,判断更准确. 不同资源的语言对:通过观察4种语言对之间的结果,高资源语言对和低资源语言对的最终结果也有很大差异.与基线相比,融合MC-Seq方法的Pearson相关系数在En-De和En-Zh的高资源语言任务中分别增加了4.88%和5.83%,而在Si-En和Ne-En的低资源语言任务中仅增加了1.58%和1.56%.虽然相同的特征对不同的语言对都有着促进的作用,但影响的程度是不同的.本文猜测,是因为高资源语言对的翻译句子质量优于低资源语言对(有着较高的人工DA平均分数). 表5中的数据就是为了验证这个猜想.在融合MC-Seq特征后,本文对4种语言对的最终结果进行了再分化实验.本文将验证集中的1000个句子分为两部分:z-mean大于0和z-mean小于0,其中z-mean的数值越大,代表句子的人工平均DA分数越高,句子的整体质量越好.表中的两行数据分别代表句子数和皮尔逊相关系数.从表中的数据可以看出,当z-mean大于0时,4种语言对的Pearson系数都高于z-mean小于0的Pearson系数,这表明特征MC-Seq更有助于预测句子质量更好的最终翻译. 表5 以z-mean为界限,将1000条句子分为两部分Table 5 Taking z-mean=0 as the boundary,the 1000 sentences set are divided into two parts 在高资源语言对En-De和En-Zh中,z-mean大于0的句子数分别为567和617,远远超过在低资源语言对Si-En和Ne-En中的493和416,这也证明了本文前面的猜想,因为在高资源语言中,译文质量好的句子比在低资源语言中要多,因此,更有助于预测高资源语言对的最终译文的质量. 在句子层面的翻译质量估计任务中,本文从无监督的质量估计系统开始,在无监督方法中,从NMT系统中提取的指标可能包含丰富的信息源,这些信息源使用了一系列基于NMT模型的softmax输出概率分布而变形的指标,它可以弥补有监督QE模型中预测器阶段对语料学习不充分的问题,补充加入源文本与对应翻译之间映射信息.针对这种情况,本文提出了一种质量估计方法,该方法以无监督译文质量评价的估计指标为特征,并将其融合集成到有监督译文质量评价中.实验结果表明,该方法提高了句子级翻译质量估计任务中机器自动评分与人工评分之间的相关性.同时,这项工作可以以各种方式扩展,首先,这一思想可以应用于不同级别的质量估计模型,例如单词级别或文档级别;其次,其他无监督的质量估计指标也可以进行组合和融入.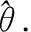
2.2 基线模型
3 融合无监督质量估计指标的质量估计方法
4 实验与分析
4.1 实验设置
4.2 实验结果

4.3 实验分析
5 结 论
猜你喜欢
中国神经再生研究(英文版)(2022年2期)2022-08-08
人大建设(2020年4期)2020-09-21
水利经济(2020年3期)2020-02-22
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
人大建设(2017年2期)2017-07-21
小学生学习指导(低年级)(2017年6期)2017-02-16
人大建设(2017年9期)2017-02-03
浙江人大(2014年4期)2014-03-20
