
重大舆情事件的双层区块链溯源方法研究
2023-12-11 07:11王海文孙志坚杨大伟庞铭江
计算机工程与应用 2023年23期
刘 昕,王海文,孙志坚,杨大伟,庞铭江
1.中国石油大学(华东)计算机与科学技术学院,山东 青岛 266580
2.青岛市保密技术服务中心,山东 青岛 266071
重大舆情事件影响着现实世界中热点事件的发展进程,对国家安全和社会稳定造成严重冲击,如何实现重大舆情事件的可信溯源,对于政府部门及时处置重大舆情事件,构建诚信友善的社交网络,维护国家长治久安具有重要现实意义。将区块链技术应用于社交网络可信数据存储,利用其防篡改、可溯源、匿名性、自治性等优势,可为重大舆情事件溯源提供可信数据基础,实现舆情信息发布源头追踪、用户隐私保护、舆论环境自主维护,同时为构建个性自由且和谐有序的元宇宙可信社交网络提供分布式数据存储、数据隐私保护、数据可信共享等方面的技术支撑。
在包含海量用户的社交网络中,数据来源广泛、易于篡改,且舆情信息扩散速度快、影响面广泛,导致重大舆情事件难以溯源。然而,区块链技术在网络舆情溯源方面的研究较为匮乏,同时在元宇宙中多应用于虚拟经济系统、数据共享等领域[1]。
针对上述问题,设计了一种基于双层区块链的重大舆情事件溯源方法,主要贡献如下:
(1)利用Sentence-BERT 模型的平均池化层生成各用户言论句向量并进行K-Means 聚类,计算各用户K个聚类中心间的欧式距离,设置距离阈值并计算满足阈值的聚类中心个数作为用户兴趣相似度,以用户为节点、以兴趣相似度为权值构造无向带权图,基于Leiden算法进行兴趣社区发现,用于舆情数据的社区化管理。
(2)以各兴趣社区内的用户为节点构建舆情信息链,提取用户言论关键词并计算其哈希值作为数据索引,记录用户所属兴趣社区、用户言论数据哈希、言论关键词哈希列表、言论来源区块号、用户影响力、声誉积分等数据,利用言论来源区块号形成链内索引,以各兴趣社区依据声誉积分排序选举出的领导者为兴趣社区链节点,记录各社区高影响力用户的ID 及其言论关键词哈希列表、日活跃用户数、用户发布或转发等行为的数量、用户影响力总和等社区动态属性数据,保障舆情信息的可信记录的同时实现用户隐私保护。
(3)设计基于声誉积分的激励机制,以用户及其言论属性计算用户影响力,以用户历史声誉积分与影响力为积分计算参数,奖励发表正向言论的用户、惩罚发表负向言论的用户,对声誉积分较低的用户添加警告标识,激励用户自主维护元宇宙社交网络的舆论环境。
(4)设计基于兴趣社区动态属性的活跃度计算方法,通过活跃度异常波动发现潜在的异常舆情事件,根据溯源证据链追踪异常舆情源头,基于用户节点所属社区信息发现推动舆情事件发展的群体,实现重大舆情事件的溯源。
1 相关工作
1.1 区块链技术研究现状
区块链是以分布式账本为数据存储载体,以P2P网络为通信载体,基于密码学确定所有权及保障隐私,通过分布式系统共识算法保障一致性,旨在构建价值交换系统的技术[2],广泛应用于电子商务、数字政务、信用评估、智慧物流等场景[3]。如下从信息溯源与舆情管理两个研究领域展开介绍。
在信息溯源领域,Peng 等人[4]提出了P2B-Trace 框架,设计了一个基于认证数据结构(authenticated data structure)的区块链架构来记录人员接触记录,实现了基于零知识证明的新冠密接人员验证方案;Xu等人[5]通过计算用户假名、时间戳、地理位置信息的哈希值构建TraceCode,对用户身份与行动轨迹数据脱敏,实现了强隐私保护的新冠密接人员追踪方案。上述两种方法的缺陷在于构建的全球性的单链结构公共区块链网络,在单层区块链上存储海量数据导致数据查询延迟高、溯源效率低下。Agrawal 等人[6]构建了供应链合作伙伴联盟链,建立基于智能合约的信任机制,实现了面料厂商和成衣厂商间的信息追溯;禹忠等人[7]基于联盟链架构设计了一种“代码层+管理层”的药品信息溯源智能合约,实现了业务逻辑与信息校验的分离,提高了信息溯源的效率。上述方法的问题在于联盟链架构使得供应链中各方上链需通过链上共识并生成数字证书,步骤繁琐、效率低,难以应用于大规模的上下游产业链信息溯源。陈飞等人[8]设计了一种双层溯源数据存储机制,产品各环节数据存储在本地数据库,链上仅存储供应链信息摘要,改善了区块链的可扩展性问题。该方法缺陷在于本数据库未采用分布式架构,存在数据篡改、丢失的风险。
在舆情管理领域,Sengupta 等人[9]构建了基于区块链的模型ProBlock,利用区块链存储新闻信息及新闻审核投票结果信息,确保发布的新闻不被篡改;刘峰等人[10]设计了一种单层舆情区块链,利用零知识证明机制存储网络用户的身份证号、手机号等个人身份数据作为舆情存证数据;刘嘉琪等人[11]将网信办、地方行政执法单位、国有存证机构和社交媒体平台作为链上节点共同参与信息存储,由多边跨组织、跨部门集体维护链上数据以防止数据篡改。上述方法的问题在于利用单链结构存储舆情或用户信息的原始数据,未建立数据索引导致查询效率低,且存在泄露用户隐私的风险。Chen 等人[12]提出了一种基于PoA 共识算法的虚假新闻存证方法,该方法通过信誉评分选举权威新闻机构节点对新闻内容进行验证,并记录虚假新闻信息,对虚假新闻发布者追责。该方法缺陷在于庞大数量的新闻由少数新闻机构审查,效率低下且存在共谋攻击风险。Torky 等人[13]提出了信用证明(proof of credibility)共识协议,根据不同新闻来源的Boost因子、新闻被分享的次数、新闻关注人数量等参数计算新闻的信用值,对信用值低于阈值的新闻视为谣言并记录在区块链中;Qayyum 等人[14]提出一个基于媒体身份认证的虚假新闻防治方法,利用智能合约登记、更新和撤销新闻机构的身份,利用信誉积分机制约束新闻机构的行为。上述方法的问题在于仅关注新闻媒体这一舆情信息来源,忽略了社交平台中的用户尤其是高影响力用户同样也是舆情信息的重要来源,仅约束新闻媒体的行为难以有效实现可信的社交网络。
1.2 舆情溯源领域研究现状
目前基于区块链技术的舆情溯源研究较为匮乏,传统社交网络信息溯源方法多采用复杂网络溯源技术。复杂网络中的信息溯源问题是信息扩散的逆向问题,根据信息源头数的不同,溯源方法可以分为单源识别方法和多源识别方法[15]。
在单源头溯源研究方面,Kesavareddigari 等人[16]提出了一种“Types Center”方法估计树状网络上的信息源,该方法在大型网络上的近似误差不超过感染节点数量的对数,实现了高效的信息源头识别;Yang 等人[17]提出了一种基于方向诱导搜索的高斯估计器,实现了在复杂网络中低计算复杂度的传播源定位;Rácz等人[18]基于自适应扩散协议,证明了在底层社交网络图为一个无限大的d正则树时,利用三个及以上的独立传播快照图可以保证以恒定的概率找到信息源头;Louni 等人[19]利用概率加权图量化社会网络的不确定性,基于社交网络的模块化性质识别具有不同关系强度的信息传播源;Cai等人[20]假设图上信息源头节点的子节点传播信息时间分别服从不同参数的指数分布,利用多个序列相关的快照提高溯源准确率。
复杂网络的信息溯源问题最先是从研究树图上单源头溯源的特殊情况开始,后逐渐扩展到在线社交网络中多源头溯源的实际情况[21],故复杂网络多源头溯源技术更加符合解决舆情溯源问题的实际需要。
在多源头溯源研究方面,Wang 等人[22]通过将社交网络划分为多个分区,基于似然估计对每个分区中的单个源进行定位,将多源头溯源问题转换为多个单源头溯源问题以实现信息溯源;Dong等人[23]利用“编码器-解码器”结构和基于图约束的多任务学习构建GCSSI 模型,该模型可逆向估计出各时间步的信息传播状态,最终预测出信息源头;Wang 等人[24]分析用户行为特征构建用户信息矩阵,基于用户信息矩阵来复现信息传播过程从而得到信息源头;Feizi 等人[25]将用户言论发布时间、文本特征以及内容相关度等参数融合,构建信息传播模型,优化并计算信息传播源头;Wu等人[26]提出了TraceMiner,推断社交网络用户与社交网络结构的嵌入,利用LSTMRNN对消息的传播路径进行表示和分类;于凯等人[27]提出一种基于多中心性分析的网络舆情信息源点追溯算法,有效组合5 种中心性指标来构建多中心性算法,通过大量实验找出溯源效果最好的多中心性算法,以此来精准追溯舆情信息传播源点;陈淑娟等人[28]提出了一种快速意见领袖挖掘算法,该算法利用结构特征筛选出主题社团中的意见领袖候选人,结合传播特征和情感特征挖掘主题社团中的意见领袖,在此基础上挖掘潜在信息传播源头。
上述多源头信息溯源方法通过构建信息扩散模型,分析舆情事件发生后的用户属性、言论等数据实现舆情溯源,需要进行大量复杂的运算,同时可能存在因数据篡改、缺失进而影响溯源结果的问题,无法保证溯源的时效性与可信性。与之相比,区块链的链式数据结构天然支持信息溯源,无需构建复杂模型与大量数学计算,溯源方式简洁高效,同时基于分布式存储技术、哈希算法及共识算法实现数据防篡改,可保障舆情数据及舆情信息传播过程的可靠存储,实现舆情事件可信溯源,支撑可信元宇宙社交网络构建。
2 重大舆情事件溯源方法
本文提出的舆情事件溯源方法如图1 所示。针对元宇宙社交网络拥有庞大的用户群体,在整个网络中开展舆情溯源效率低下的问题,需采取“分而治之”的策略以提高舆情事件溯源的效率。
基于用户间的兴趣相似度构造无向带权图,利用社区发现算法将用户划分为若干个大小不一的个性化兴趣社区。在兴趣社区的基础上设计了双层区块链结构,以各兴趣社区内的用户为节点,构造舆情信息链记录用户言论、所属社区、影响力、声誉积分等数据,在此基础上以各兴趣社区选举的社区领导者为节点构造兴趣社区链,记录社区高影响力用户言论关键词哈希列表、用户总数、日活跃用户数、节点影响力总和等社区动态属性数据,实现了舆情数据的分层社区化可信记录,有利于缩小舆情数据检索范围,提高舆情事件溯源效率。
以言论关键词检索兴趣社区链中潜在舆情源头社区,在舆情信息链中检索相关社区区块,多源信息以时间为序列形成多源头溯源证据链,开展舆情溯源,追踪异常舆情源头用户与群体。同时设计了基于声誉积分的激励机制约束用户行为,鼓励自主维护积极向上的舆论环境,有助于构建个性自由、和谐有序的元宇宙可信社交网络。
2.1 兴趣社区发现
元宇宙社交网络中的用户自发组织形成众多元宇宙社区,具有相同兴趣的用户聚集在一个社区中自由互动,利用这一特点,将庞大的用户群体划分为不同的兴趣社区可有效降低舆情溯源的难度。通过提取各用户言论数据的句向量,基于句向量聚类中心间距离计算用户间兴趣的相似度,利用不同用户间的相似度划分兴趣社区。当发生重大舆情事件时,以兴趣社区为单位分析并追溯各社区内的舆情数据,及时发现传播舆情事件的个人与群体,提高舆情溯源的效率与准确性。
基于用户言论的文本相似度,判断用户间是否存在相似的兴趣话题。由于社交网络用户发表的言论内容一般较短且长度不一,为了得到统一长度的句向量,在BERT 模型输出层上添加平均池化层[29],将言论文本输入模型,取每个Token的平均Embedding,获得用户言论句子的固定长度向量。在此基础上,对用户言论句向量进行归一化,利用PCA 算法将每个用户的所有言论句向量降维至2维,利用降维后的句向量进行K-Means聚类,将每个用户的所有言论向量聚类为k簇,获得用户i所有言论的k个聚类中心,记作Centeri={ci1,ci2,…,cik},分别计算用户i与用户j的k个聚类中心的欧式距离,如式(1)所示:
其中,cik坐标为(x1,y1),cjk坐标为(x2,y2)。
若某一对聚类中心的距离小于相似度距离阈值d,则认为用户言论存在相似性,记为tk=1,则用户i与用户j的兴趣相似度记为Sij=∑tk。
以用户为兴趣社区节点,若用户间相似度大于0,则用户间存在一条边,以兴趣相似度为边的权值,构建一个无向带权图用于兴趣社区发现。考虑到用户间的言论或多或少存在一些相似性,若聚类簇数与相似度距离阈值选择不合理,会导致多数用户节点之间均存在边,不利于接下来的社区发现[30],故应以社区发现结果为评价标准取两个参数的较优组合,实现对无向带权图数据的降噪。
利用Leiden 算法[31]进行兴趣社区发现,初始状态下,无向图中的每个用户节点都是一个单独的社区,遍历所有节点,尝试将节点i的所属社区修改为所有邻居节点的所属社区,并计算节点i的所属社区改变后的模块度增益ΔQ[30],如式(2)所示:
其中,m为图中所有边的权重总和,ki,in为节点i连接至邻居节点所属社区C内所有节点的边的权重总和,ki为节点i所有边的权重总和,∑tot为其他社区连接至社区C内所有节点的边的权重总和。
将节点i的所属社区随机改变为模块度增益大于0的相邻节点所属社区,模块度增益越大,节点i更有可能被划分至该社区。在第一轮移动结束后,后续轮次只遍历所属社区发生变化的节点。对所有节点重复上述步骤,直到所有节点都不能通过改变其所属社区来增加模块度。
将第一个阶段得到的社区凝聚为一个新的节点,节点的环边权重为原始社区内所有节点间的边权重之和,两个节点之间边的权值为两个原始社区间相连节点的边的权值的总和,由此形成一个新的子图。
反复迭代执行上述步骤,直到模块度不再增大,得到最终的兴趣社区发现结果,如图2所示。

图2 兴趣社区Fig.2 Communities of interest
2.2 双层舆情区块链构建
2.2.1 用户影响力计算
用户自身的影响力对于一条信息的传播的影响是巨大的。对于舆情信息,个人用户或者粉丝数较少的自媒体发布之后产生的影响可能不是很大,但是经过一些影响力巨大的意见领袖用户,例如微博大V或者是一些官方账号发布之后,舆情信息会快速传播,造成较为广泛的舆论影响[32],所以在进行舆情溯源时应当将用户对于信息传播的影响力纳入考量。用户影响力定义如式(3)所示:
其中,x1,x2,x3,x4分别为用户所有言论的被点赞总数、被转发总数、被评论总数以及用户粉丝总数,ci为xi的权重,权重的取值应当考虑各参数值对信息传播广度的影响。用户节点的影响力随着参数值增长而增长,但当参数值超过一定数量级后,用户的影响力增长应当趋于平缓,故使用ln 函数计算用户影响力。
2.2.2 激励机制
设计基于声誉积分的激励机制,在舆情信息链上部署声誉积分智能合约。分析用户言论的情感极性,若用户发表正向言论则获得积分,反之发表负向言论则扣减其持有的积分,同时展示用户在元宇宙社交网络中虚拟形象上的声誉积分或积分等级,增强高声誉积分用户的言论影响力与个人荣誉感。若某节点积分数小于警告阈值,则为该用户添加警告标识,提醒其他用户该用户很有可能是网络水军,必要时可以选择隐藏低声誉积分用户的言论,加强舆论监管力度。另外,利用区块链数据防篡改、不可抵赖的特点,可督促用户谨言慎行、对自己的言论负责,自主维护积极健康的舆论环境。
考虑到一个拥有较高声誉积分的节点发布的言论拥有更强的舆论影响力,为保障舆论态势稳定,必须解决两个主要问题:
其一,用户节点不能仅仅通过发表几次正向言论就能获得较多的声誉积分,即应该根据用户的全部言论数据来评估用户的声誉。这可以防止水军节点通过大量发布正向言论在短期内获得过多的声誉积分,以掩盖其过去发表大量负向言论的行为。其二,用户节点不能以不稳定的言论极性获得良好的声誉。良好的声誉只能通过持续地发表正向言论来获得,这可以防止拥有较高影响力的节点在其大量言论中隐藏其负向言论。
针对第一个问题,需要限制用户最近发表的正向言论获得的声誉积分,用户发表第n+1 次正向言论获得的声誉积分计算如式(4)所示:
其中,Rn为用户发表的前n次言论获得的声誉积分,参数k∈[1,n]将用户n次言论所获积分划分为前k次与后n-k次言论所获积分两个区间,参数ρ∈[0,1]调节用户前k次与后n-k次发表正向言论所获积分的权重。为了避免水军用户在短期内获得大量声誉积分,k应取较大值,ρ应取较小值。
针对第二个问题,当根据用户发表正负言论增减其声誉积分时,将用户的影响力与所获声誉积分纳入考量,将影响力与已获得声誉积分作为用户发表一次言论获得或扣除积分的计算参数。对用户i的影响力与声誉积分数值进行归一化,如式(5)、(6)所示:
其中,Ii为用户i的影响力数值,Ri为用户i的声誉积分数值,Imin、Imax为所有用户影响力的最小、最大值,Rmin、Rmax为所有用户声誉积分的最小、最大值。
用户发表一次正负向言论获得或扣除的声誉积分计算如式(7)所示:
其中,p为基础分数,w1与w2分别为影响力与声誉的权重,且w1+w2=1。通过设置不同的参数权重,可以调节对拥有较高影响力或声誉积分用户发表正负向言论时的奖惩力度。
2.2.3 共识机制
设计基于声誉积分的Raft共识算法,在领导者节点的选举规则上,将节点的声誉积分纳入考量。在舆情信息链中,各社区基于节点声誉积分的多寡选择一个领导者节点,其余节点作为跟随者节点。领导者节点负责生成并验证区块,同时将区块发送给其他跟随者节点进行记账,领导者节点通过心跳消息与其他跟随者节点保持连接,心跳消息中应包含领导者节点的声誉积分数值。若其他跟随者节点在一定时间间隔内未收到领导者节点的心跳信息,或某个跟随者节点的声誉积分值超过当前领导者节点,则跟随者节点在社区内广播选举信息,重新选举领导者节点。在兴趣社区链中,领导者节点在各社区领导者节点中选举产生,其他选举规则同舆情信息链,不做赘述。
元宇宙社交网络中的海量用户身处不同地域、时区,若在整个区块链网络中采用Gossip 协议进行通信,每个节点将接收到的消息发送给所有邻居节点,冗余数据多、传输延迟高,降低系统的共识速度与吞吐量[33]。针对该问题,设计基于兴趣社区的区块链网络分片通信机制,以兴趣社区为单位将区块链网络划分为更小的子网络,将各兴趣社区中的用户作为子网络节点,记录本社区的舆情数据,实现舆情数据的社区化管理,同时在社区内设置路由节点,路由节点记录其他社区路由节点的地址,负责与其他社区建立P2P 通信,社区领导者节点默认为社区路由节点。
考虑到系统的可用性,当社区领导者节点重新选举或领导者节点故障时,无法接收到其他社区发送的区块数据,需要选择若干节点作为备用路由节点。各社区内部完成共识并将新区块上链后,由当前社区路由节点将新区块发送至其他社区路由节点,其他社区路由节点在接收到新区块后将其发送至领导者节点,领导者节点将区块在本社区内广播上链。
2.2.4 区块链结构
以兴趣社区内每位用户作为节点构建舆情信息链,记录各用户的言论与属性数据。舆情信息链的区块头包含:区块号;当前区块哈希,为区块体数据的哈希值;前一区块哈希,为前一区块中区块头数据的哈希值;区块生成时间。
为实现舆情溯源时快速查找链上数据、锁定舆情事件源头,利用所属社区信息与言论数据,以用户间的互动关系检索相关区块形成溯源证据链。用户发布、点赞、转发、评论的内容均需生成哈希值并记录其所在区块号,对于用户原创发布的内容,言论来源区块号为当前区块号,若用户间存在互动行为,即用户点赞、转发、评论了其他用户发布的言论,则言论来源区块号为内容原始记录所在的区块号,以此形成链内数据索引。以用户ID、行为发生时间及言论内容计算用户行为哈希值,如式(8)所示:
同时,对于用户原创发布的内容,利用TextRank 算法提取用户言论内容的关键词集作为舆情溯源时的数据索引。为了保护用户隐私,链上不存储用户言论的明文数据,通过计算每个关键词的哈希值形成言论关键词哈希列表,利用关键词哈希匹配实现数据的查询与溯源。对于非用户原创的内容,言论关键词哈希列表为原始言论数据的哈希列表,避免重复计算数据哈希值。
舆情信息链的区块体包含:事务数据,包括用户ID、用户所属社区ID、用户行为类别(发布、点赞、转发、评论)、行为发生时间、用户行为哈希、言论关键词哈希列表、言论来源区块号、用户声誉积分、声誉积分警告标识、用户影响力数值;身份数据,包含用户节点公钥、社区领导者节点公钥;签名数据,利用用户节点、社区领导者节点私钥进行数字签名的事务数据。
在舆情信息链的基础上构建兴趣社区链,考虑到各兴趣社区的舆情状态变化的实时性,为了政府部门能够实时监测舆情变化,及时研判舆情态势,兴趣社区链应记录各兴趣社区的动态属性数据。同时,社区内的高影响力用户很大程度上影响着社区内舆论的走向,所以各兴趣社区内的高影响力用户的相关信息也应记录在兴趣社区链中。兴趣社区链区块头结构与舆情信息链相同。兴趣社区链区块体的事务数据包含:兴趣社区ID;社区内影响力高用户的ID 及其言论关键词哈希列表;社区用户总数;日活跃用户数;用户的发布、点赞、转发、评论行为总数;社区内节点影响力总和;身份数据包含社区领导者节点公钥及兴趣社区链领导者节点公钥;签名数据为利用社区领导者节点、兴趣社区链领导者节点私钥进行数字签名的事务数据。
2.3 重大舆情事件溯源
利用智能合约自动化执行、可信透明的优点,在兴趣社区链上部署异常舆情识别智能合约,在舆情信息链上部署舆情溯源智能合约。异常舆情识别智能合约实时监测兴趣社区链记录的各兴趣社区的动态属性数据,当发现可能的异常舆情状况时,以言论关键词检索兴趣社区链中潜在舆情源头社区,调用舆情溯源智能合约在舆情信息链中检索相关社区区块,检索到的多源信息以时间为序列形成多源头溯源证据链,分析异常舆情源头,实现重大舆情事件的早发现、早预警,为舆情事件的及时处置、避免舆情扩散蔓延提供支持。
异常舆情识别智能合约在读取兴趣社区链上的最新区块内容后,基于各社区用户总数CUsum、日活跃用户数AUsum、用户各类行为数量OPsum、社区内节点影响力总和Isum,计算各社区活跃度T,其中b1,b2,b3为各参数权重,如式(9)所示:
当社区活跃度超过一定阈值或政府部门需要对特定舆情事件进行溯源时,若社区内高影响力用户的言论关键词哈希值与舆情事件关键词的哈希值存在交集,根据用户所属社区ID及关键词哈希搜索该社区内用户的言论数据,根据区块内记录的言论来源区块号前向搜索链上数据,查找到言论的原始发布者,这样的原始发布者可能存在多个,将这些节点视作异常行为节点。计算各社区存在异常行为节点的数量与社区总活跃用户的比值,据此对各社区进行排序,发现推动舆情事件发展的个人与群体。将溯源到的用户ID、所属兴趣社区ID、用户行为哈希、言论关键词哈希列表、用户影响力等信息,形成溯源报告推送至政府部门,完成舆情溯源。
3 实验结果与分析
3.1 实验数据与环境
利用网络爬虫技术随机爬取2022 年06 月16 日至2023 年02 月23 日,新浪微博部分热点话题参与用户的ID及粉丝数量,用户发布与转发的微博文本,用户微博被转发、被评论、被点赞的数量及上述互动行为的用户ID,对数据进行清洗,删除乱码、内容无效(如微博内容为单个字符或仅有“转发微博”)、内容重复的数据后,获得405位用户的共计109 970条言论数据。本文实验硬件环境为配备Windows 10 64 位操作系统,Intel Core i7-10700 CPU 2.90 GHz 和16 GB 内存的计算机,利用VMware虚拟机安装CentOS 7操作系统,使用Pycharm、Python 3.8、Hyperledger Fabric 2.4.2、Hyperledger Caliper 0.4.2进行实验。
首先,利用Sentence-BERT 模型生成各微博用户每一条微博文本的句向量,对向量PCA降维后进行聚类,设置距离阈值并计算各微博用户间的兴趣相似度,在此基础上利用Leiden算法进行兴趣社区发现。
其次,利用Hyperledger Fabric 分别搭建两条区块链。以各兴趣社区内的用户为链上节点构建舆情信息链,将微博用户的一条言论数据及其他信息作为一条事务数据上链,链上记录用户ID、所属兴趣社区、言论数据哈希、言论关键词哈希列表、言论来源区块号、影响力、声誉积分数据。以各兴趣社区的领导者为节点构建兴趣社区链,链上记录各社区高影响力用户的ID 及其言论关键词哈希列表、日活跃用户数、用户发布、转发等行为数量、用户影响力总和数据。
3.2 参数设置及实验结果
首先,为寻找较优的社区发现参数设置方案,设置不同聚类簇数、相似度距离阈值,测试不同参数组合下对兴趣社区发现结果的影响。其次,对区块链进行查询延迟及吞吐量性能测试以验证本文方法的可行性。
3.2.1 聚类簇数设置
用户言论向量聚类簇数k的设置决定了参与相似度计算的聚类中心点的个数,影响用户间兴趣相似度的计算结果。同时兴趣社区是在用户兴趣相似度数据基础上,构建无向带权图并利用社区发现算法进行划分,因此应选择合适的聚类簇数k与距离阈值d的组合,使得用户节点之间的边数在一个合理范围内以降低数据噪声,为接下来的兴趣社区发现奠定数据基础。
为分析聚类簇数k的取值对社区发现结果的影响,需要取不同聚类簇数k及相似度距离阈值进行对比实验。本文取9个不同的相似度距离阈值进行多次实验,如3.2.2小节所示,结果表明当距离阈值过小或过大时,社区发现结果均较差,故选取低、中、高3个相似度距离阈值区间的典型值,分别取相似度距离阈值为0.3、0.6、1.0,设置三组实验,对不同距离阈值设置6个聚类簇数,考虑到过小的聚类簇数可能导致参与计算的聚类中心数过少,从而使得用户间的相似度偏小,故在实验中取最小聚类簇数为5,分析不同聚类簇数k与距离阈值d组合下,社区发现结果模块度数据,如图3所示。
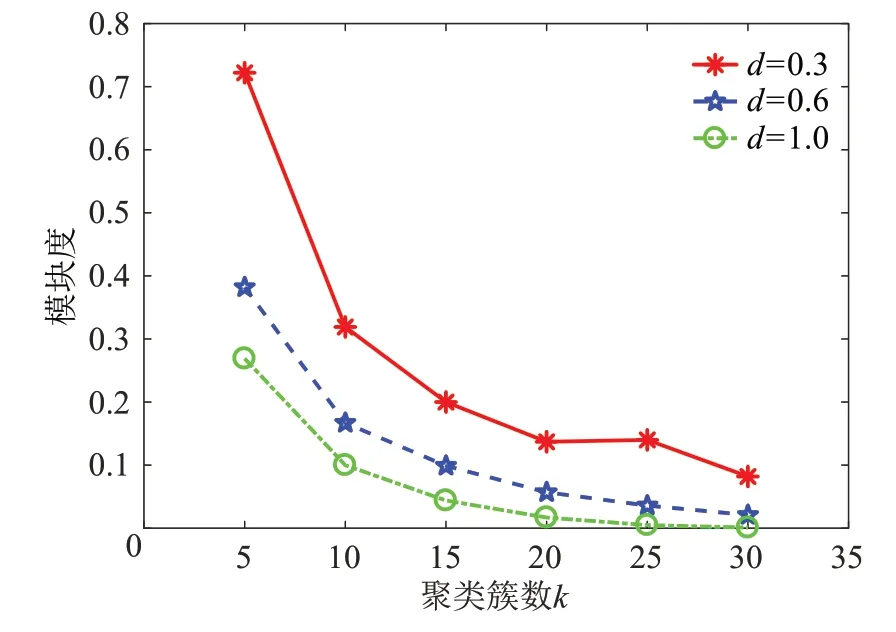
图3 模块度随聚类簇数k 与相似度距离阈值d 的变化Fig.3 Change of modularity with cluster number of k and similarity distance threshold d
由图3 可知,随着聚类簇数数量的不断增加,模块度呈现快速下降趋势,在三组实验中,不论相似度距离阈值取何值,模块度的最大值均在聚类簇数k=5 时取得。由此可知选择较小的聚类簇数可以有效提高兴趣社区发现的效果。
3.2.2 相似度距离阈值设置
相似度距离阈值的设置直接决定了用户间是否存在相似性,选择合理的相似度距离阈值d,在划分出内部连接紧密、外部连接稀疏的兴趣社区同时,尽可能覆盖所有用户节点,利用区块链的去中心化保障舆情数据安全,支撑舆情事件的高效、可信溯源。由3.2.1小节的分析可知,应取聚类簇数为5,在此基础上设置9个相似度距离阈值,分析不同相似度距离阈值下兴趣社区发现效果。由于Leiden算法执行结果具有一定随机性,取每个相似度距离阈值的5次模块度、社区数量的平均值作为最终的模块度、检测出的社区数量。
由图4(a)中数据可知,模块度与相似度距离阈值呈反比关系。随着距离阈值的增加,用户间相似度的判定更为宽松,用户节点间的边数与权重不断增加,导致各社区间的边界不清晰,模块度不断下降。当距离阈值取0.2 时,模块度最大,为0.89,相似度距离阈值取0.3 时,模块度为0.72,相似距离阈值取1.0时,模块度仅为0.27。

图4 相似度距离阈值的影响Fig.4 Influence of similarity distance threshold
由图4(b)中数据可知,随着相似距离阈值的不断增加,检测出的社区数量呈下降趋势。当相似度距离阈值取0.2时,检测出社区数量最多,达到46个,当阈值取0.3时,社区数量快速下降为20 个,取其他阈值时,检测出社区数量相对平稳。
同时由图4(c)中数据可知,参与社区发现的用户数量与相似距离阈值呈反比关系,过小的距离阈值导致过多的用户与所有用户间的相似度为0。当距离阈值取0.3 时,共有357 个用户参与社区发现,距离阈值取0.2时,仅保留了272个用户进行社区发现。
在实践中,当模块度大于0.3时,节点网络呈现出显著的社区结构[34]。如图5 所示,当相似距离阈值阈值取0.2时,仅依据模块度指标进行评价,社区发现的结果较好,但需要注意的是,此时检测出的社区多数为2~3 个节点构成的小社区,导致每个社区的言论数据有限,同时参与社区发现的用户较少。虽然可以采取将剩余的用户划为一个社区方法进行处理,但这些数量较多的未参与社区发现的用户之间可能存在社区结构,不利于舆情数据的社区化管理。
综上所述,当相似度距离阈值取0.3 时,模块度、检测出的社区数量、参数用户数量为较均衡的水平。
3.2.3 区块链性能测试
本文选择吞吐量和查询平均延迟作为性能评估指标,利用Hyperledger Caliper 进行性能测试。在区块链系统中,网络吞吐量是衡量系统性能的重要指标,它表示在单位时间内确认并写入链中的事务数量,而查询延迟则评估系统访问区块链账本的响应时间。
本文设置了六轮测试,最小事务量为100,最大事务量为5 000,每轮分4 次读写所有事务,取4 次测试数据的查询延迟、吞吐量、发送率的平均值作为本轮测试的结果。如图6 所示,在六轮测试中,仅在查询事务量为1 000 时,延迟出现小幅波动,总体而言,查询延迟并未随查询事务数量的增加而大幅上涨,延迟数据保持在一个相对平稳的水平,约为110 ms。
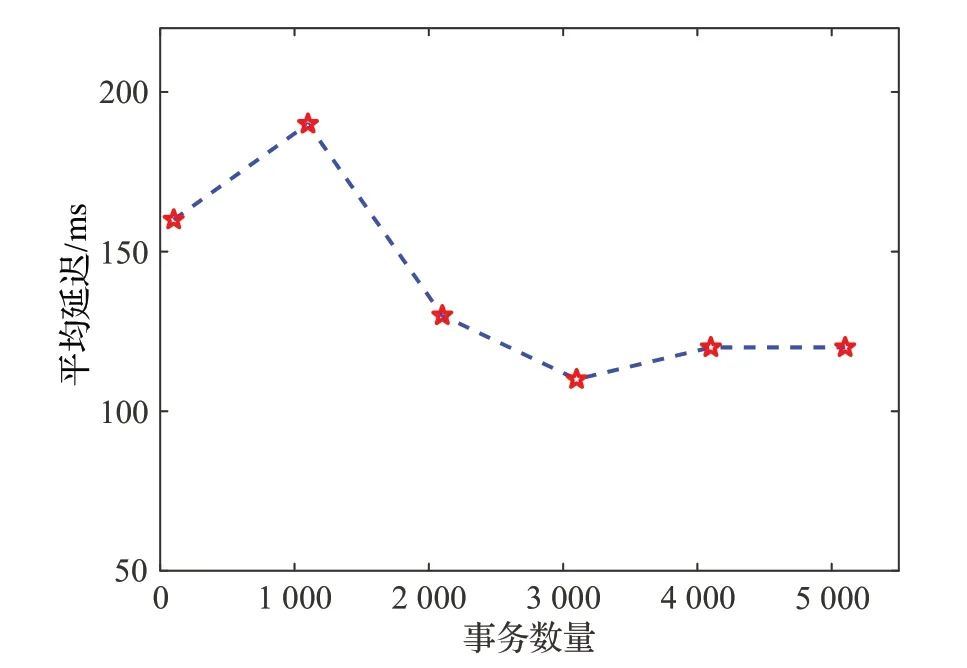
图6 查询延迟性能测试Fig.6 Query delay performance tests
如图7所示,本系统在六轮测试中吞吐量的性能表现稳定,网络吞吐量和事务发送速率大致相同,随着事务数量的不断增加,网络的总体吞吐量与发送率未出现较大波动,均在550 TPS 以上。综上所述,利用区块链系统分片通信机制与Raft共识算法,可以在处理大规模请求时保持稳定的性能,为舆情数据的可信记录与溯源提供支撑。

图7 吞吐量性能测试Fig.7 Throughput performance test
3.3 安全分析
本节将对双层舆情区块链在数据防篡改、数据完整性、隐私保护方面的安全特点进行分析与总结。
(1)数据防篡改:存储在双层区块链中的舆情数据使用节点的私钥进行数字签名,同时记录进行签名的节点的公钥,验证者可利用该公钥验证签名后数据,对区块中记录的事务数据进行核对。另外链上数据以分布式架构存放在区块链网络的各个节点中,每个节点保存相同的数据副本,元宇宙社交网络中身处不同时空域的海量链上节点使得数据难以篡改。因此本方法基于区块链的不可篡改性,既能保障链上数据的不可抵赖,也可以保证数据的完整性。
(2)数据完整性:由于社交网络用户可以对自己的言论数据进行随意修改或删除,导致溯源证据链断裂,所以利用原始言论数据进行溯源时,可能无法查找到信息的发布源头。针对此问题,本方法将每个用户的所有言论内容的哈希值上链,充分利用区块链数据的不可篡改优势,用户只能删除其发表的原始言论数据,链上数据作为用户行为的存证不会被删除,可利用完整的哈希证据链对舆情信息进行溯源。因此可以为重大舆情事件溯源提供完整的数据支撑。
(3)隐私保护:由于链上数据公开透明,所有链上节点均可读取,链上记录不应明文存储用户的隐私数据。本方法中的上链数据仅包含用户各类行为数据及言论关键词的哈希值,不存储其明文数据,其他链上节点无法获取用户的隐私数据,可以为元宇宙社交网络用户提供良好的隐私保护。
通过上述安全特点的分析可知,本方法能够保障元宇宙社交网络用户间实时互动数据的防篡改、完整性与隐私保护,支撑基于链上数据的可信舆情事件溯源,具有较好的安全性与实用性。
4 结束语
本文提出了一种基于双层区块链的重大舆情事件溯源方法,初步探索了基于区块链的元宇宙可信社交网络的技术路径。该方法基于用户间兴趣相似度划分兴趣社区,实现舆情数据社区化管理,在不存储用户原始言论数据的条件下,基于用户间互动关系与言论哈希值建立链内数据索引,检索链上不可篡改的言论存证数据形成多源头溯源证据链,在充分保障用户隐私安全的前提下实现重大舆情事件的可信溯源。同时,基于节点影响力设计声誉积分机制,以声誉积分机制约束用户行为,激励用户自主对舆论环境进行维护。
未来的研究工作可从基于图神经网络的社区发现、区块链的共识效率提升、基于言论情感极性分析的舆情态势判断等方面展开,在此基础上提出基于区块链的元宇宙可信社交网络构建的技术方案。
猜你喜欢
湘潮(上半月)(2021年4期)2021-07-20
湘潮(上半月)(2021年3期)2021-07-20
智族GQ(2019年12期)2019-01-07
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
中国民政(2016年24期)2016-02-11
计算机工程(2015年8期)2015-07-03
计算机工程(2014年6期)2014-02-28
电子设计工程(2014年12期)2014-02-27
传媒国际评论(2014年1期)2014-02-27
