
改进型YOLOv4-tiny的轻量级目标检测算法
2023-12-11 07:11:24郭明镇申红婷候红涛罗子江
计算机工程与应用 2023年23期
郭明镇,汪 威,申红婷,候红涛,刘 宽,罗子江
贵州财经大学 信息学院,贵阳 550025
随着卷积神经网络(convolutional neural network,CNN)的发展,YOLO[1](you only look once)系列算法检测凭借速度较快、准确率较高的特点,成为当下主流的目标检测算法,在智慧交通、智能监控、军事目标检测等方面[2]具有广泛的应用价值。目标检测的发展趋势要求检测算法具备精良的准确性和优异的实时性,同时要求算法所占内存较小,便于部署在移动端。
目前,以轻量性为设计理念而提出的YOLOv4-tiny[3]算法,在实时检测任务中取得良好的检测性能。王长清等人[4]基于YOLOv4-tiny在主干网络引入大尺度特征图优化策略和金字塔池化模型,从而提高特征图的多尺度融合效率,丰富边缘细节信息,且检测精度方面也有所提升。朱杰等人[5]在YOLOV4-tiny 中增加SPP[6](spatial pyramid pooling)模块和PAN[7](path aggregation network)模块,引入标签平滑策略[8],从而提高模型在复杂场景下对小目标和遮挡目标的适应能力。卢迪等人[9]通过SPP模块将全局和局部特征进行融合,丰富特征图的表达能力,减少网络参数,提升YOLOv4-tiny网络的处理速度。以上的YOLOv4-tiny 算法虽然在检测精度与速度方面有所提升,但也存在以下不足:(1)主干网络的特征图在传递过程中所需算力较大,且卷积核的选择方案不完善,从而导致特征提取的速度和效率不足;(2)特征图的多尺度融合效率较低,边缘细节信息损失程度较大;(3)主要的计算模块算力较大,不易部署在RK3288 开发板一类的嵌入式设备上;(4)Mosaic[10]数据增强方法会随机截取无目标或者目标过小的图像块,从而导致样本数据的浪费问题。
针对以上不足之处,本文提出一种基于CSPRDWConv模块的轻量级网络CSPRDW,相关工作如下:(1)借鉴CNN 在ImageNet 数据集[11]中的特征提取器,选用两个残差块替代YOLOv4-tiny 基准网络中计算块的特征提取器,从而设计出快速有效的主干网络,大幅提升算法在计算资源受限的RK3288开发板上的推理速度;(2)对附带标签的图像样本进行改进的Mosaic 数据增强,以便截选更多的目标物体,过滤掉过小的目标物体,从而提升检测精度;(3)通过NEON 指令对训练后的检测模型进行优化,并将卷积层与BN 层[12](batch normalization,BN)融合,减少BN层的推理时间,加快检测模型的推理进程。
实验证明,本算法在1080Ti 硬件上达到1 308 FPS的实时检测速度,在RK3288 开发板上的推理时间缩减至150.6 ms,检测速度是YOLOv4-tiny 基准网络的近4倍,mAP达到22.31%,相比于基准网络提升0.61个百分点。对比已有的算法并通过大量的实验验证,结果表明本文改进的YOLOv4-tiny 算法在嵌入式设备的检测中更为流畅和高效,整体性能和效率优于已有的算法,具有较强的可移植性、实时性、鲁棒性以及较高的实用价值。
1 算法概述
1.1 YOLOv4算法概述
2020 年,Bochkovskiy 等人[13]提出YOLOv4,如图1所示的YOLOv4 中:(1)CSPDarknet53 模块增强网络学习能力,降低计算量和所占内存大小;(2)SPP模块增大感受野的同时分离出价值度最高、代表性最强的特征;(3)PAN 模块代替YOLOv3 中的特征金字塔网络[14](feature pyramid networks,FPN)作为多尺度融合模块,加快顶层信息与底层信息的汇合进程。YOLOv4 实现检测速度和检测精度的最佳权衡,但是YOLOv4算法检测过程复杂、算力较大,对设备的性能要求过高,不适用于嵌入式系统。
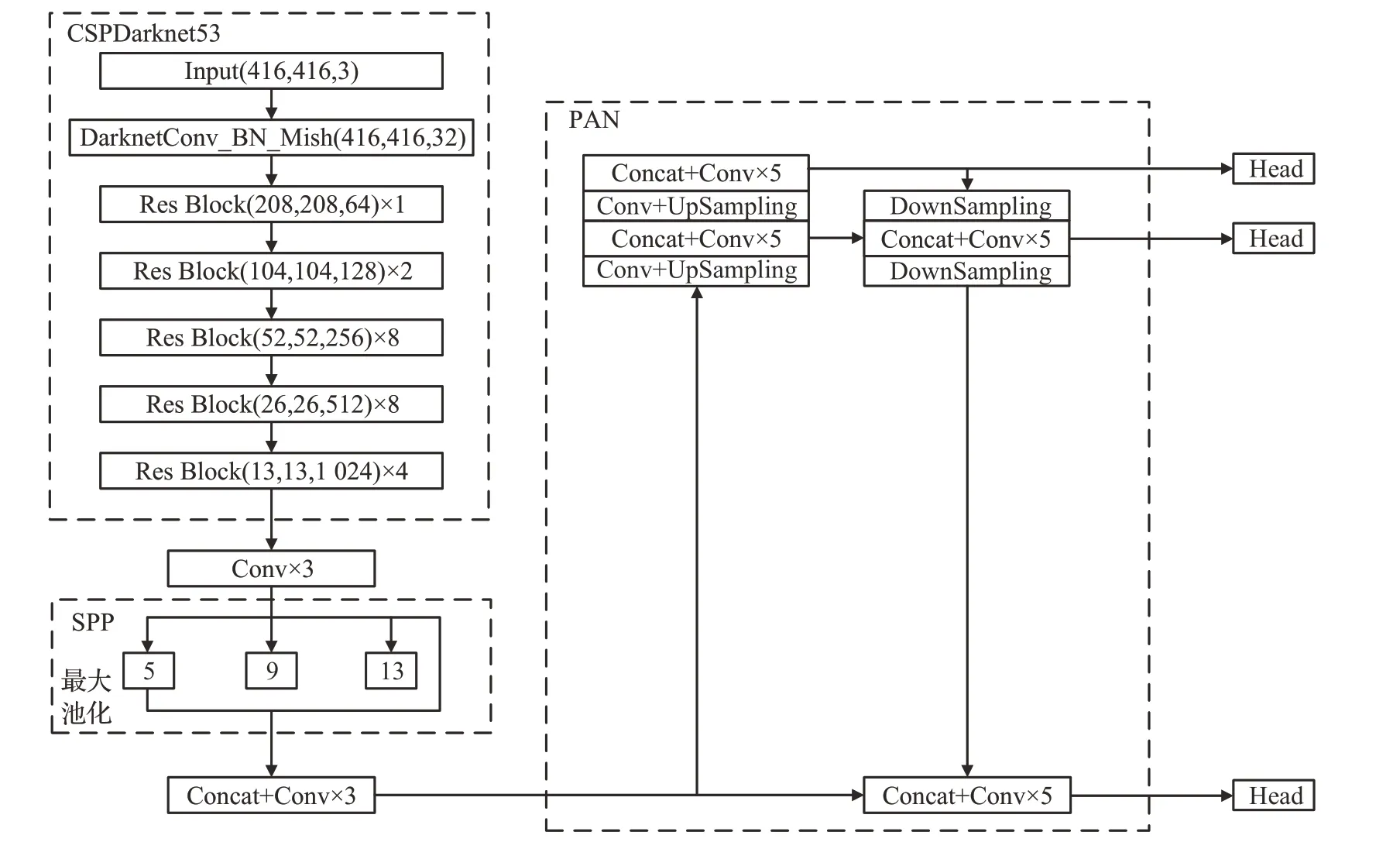
图1 YOLOv4的网络结构Fig.1 Network structure of YOLOv4
1.2 YOLOv4-tiny
2020 年,Bochkovskiy 团队[3]正式发布YOLOv4-tiny,YOLOv4-tiny 是为嵌入式系统设计的轻量化架构。如图2 所示的YOLOv4-tiny 设计思路为:(1)选用CSPDark net53-Tiny 进行特征提取;(2)FPN 模块代替SPP 模块和PAN 模块;(3)使用两种尺度预测网络对目标进行分类和回归预测。YOLOv4-tiny 牺牲一定程度的检测精度以换取检测速度的大幅提升,速度由62 FPS提升至371 FPS,但移植到RK3288 开发板上其速度仅为1.8 FPS。
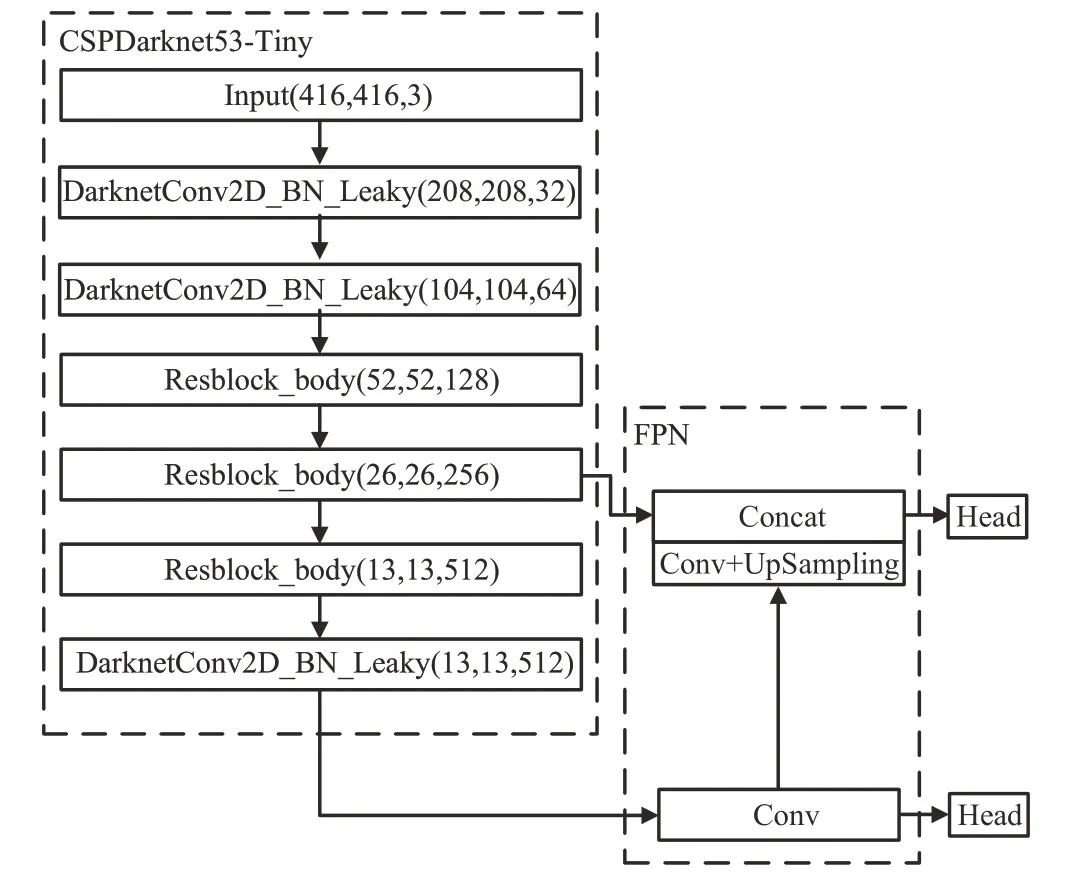
图2 YOLOv4-tiny的网络结构Fig.2 Network structure of YOLOv4-tiny
2 改进的YOLOv4-tiny算法
改进的YOLOv4-tiny网络,即YOLOv4-tiny-CSPRDWConv(YOLOv4-tiny-cross stage partial residual depthwise convolution),包括预训练阶段的分类网络和训练阶段的检测网络,整个学习阶段被分为共性学习阶段和特性学习阶段。如图3 所示的分类神经网络为基于ImageNet数据集的预训练网络,包含大小为224×224×3 的输入端、3个CSPRDWConv模块、5个下采样模块、全局平均池化层以及softmax层,最后输出图像的类别判定结果。分类网络的结构组成如表1 所示,其中Conv2d 表示卷积操作,DownSample为含3×3小卷积核的下采样模块,B-DownSample 为含5×5 大卷积核的下采样模块,t表示膨胀因子(可按需调整t的大小)。预训练模型使得检测网络学习类别特征信息,为后面的检测模型做准备,预训练后的模型参数不再是随机初始化所得而是基于共性特征信息,从而减轻模型在检测任务中的学习负担。

表1 分类神经网络的结构Table 1 Structure of classification neural network

图3 分类网络结构图Fig.3 Classification network structure diagram
如图4所示,基于COCO数据集的检测网络由输入端、主干网络、Neck部分和检测头四部分组成:(1)输入端中图像大小为416×416;(2)主干网络选用预训练后的分类神经网络的特征提取部分;(3)Neck 部分中,将FPN 结构替换为YOLOv4 的PAN 结构并增加弱SPP模块,将原SPP 模块的四分支结构改造为三分支结构;(4)检测头为YOLOv4-tiny基准网络的检测头;(5)通过NEON指令对训练后的检测模型进行优化,并将卷积层和BN层融合。分类网络与检测网络输入大小相异,故在预训练阶段使用{224,320,416}不同输入大小的图片进行交替训练,使检测模型适应不同尺度的输入。
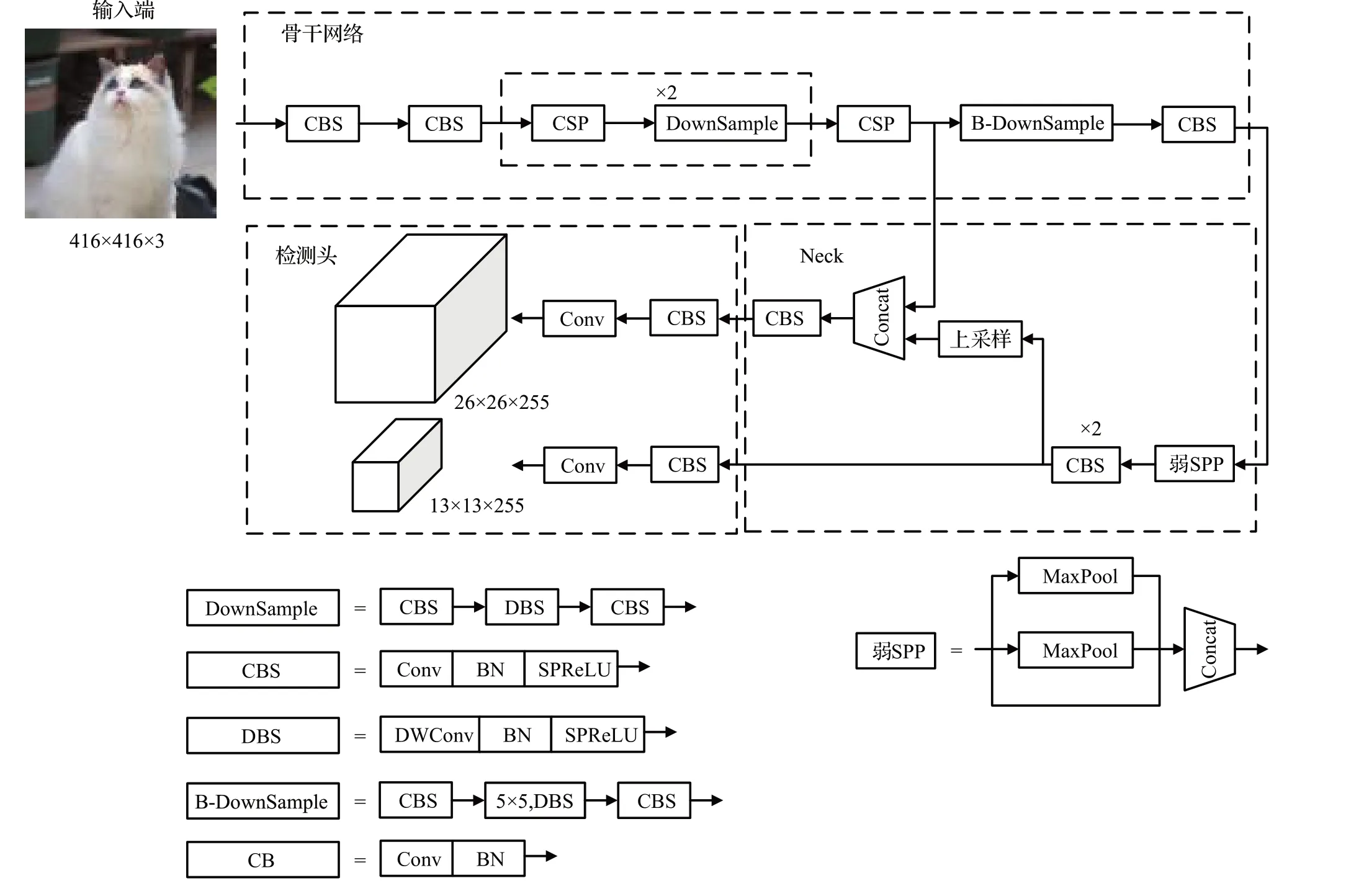
图4 检测网络结构图Fig.4 Detection network structure diagram
2.1 CSPRDWConv模块
如图5(a)所示,原YOLOv4-tiny计算模块使用PCB架构的CSPOSANet构成主干网络[3],该计算模块与同输入同输出的标准卷积的Flops 比较公式如式(1)所示。式(1)中c′ 表示该输出通道数,k表示卷积核的大小,w′和h′分别表示输出特征图的宽和高。

图5 主干网络改进模块Fig.5 Backbone network improvement module
YOLOv4-tiny在1080Ti GPU上的检测速度可达到371 FPS,但移植到RK3288 开发板上速度仅为1.8 FPS。故针对YOLOv4-tiny中的计算块算力较大、特征提取效率较低以及在RK3288开发板上的运行速度较慢的问题进行改进,从而设计出CSPRDWConv模块。CSPRDWConv模块也通过CSPNet[15](cross stage partial net)进行跨阶段连接以加快网络的推理速度,如图5(b)所示;但在改进模块中使用残差块和3×3 深度可分离卷积(depthwise separable convolution,DWConv)进行空间映射,然后连接无非线性激活函数参与的BN层,以免特征图信息受损。
图5(b)中,输入特征图被Slice 层切分为通道数相等的两部分,其中一半进行特征映射;另一半与特征映射的输出特征图拼接后,通过1×1的标准卷积层得到整个模块的输出特征图。CSPRDWConv模块在保持相同精度的前提下,进一步加快模型的检测速度,CSPRDWConv 模块与同输入同输出的标准卷积的Flops 比较公式如式(2)所示:
首先从支撑补偿重力的角度,研制了一种“杠杆+配重”结构形式的新型重力补偿装置。该装置利用静力平衡原理消除重力影响,在不同工况下可以通过调节配重的位置来调节补偿力的大小,从而更好满足重力补偿的要求。通过分析伸杆支撑组件支撑力精度以及试验,证明了该补偿装置的有效性和合理性。
式(2)中,c′、w′、h′分别为该模块的输出特征图的通道数、宽和高,k表示卷积核的大小。该模块的算力是YOLOv4-tiny计算模块的3/k2倍(k≥3),适当缩减算力规模可使得整个模块在保持精度的同时大幅提升推理速度。
2.2 卷积核的选择
大小超过1×1的卷积核才能体现感受野的作用,且卷积核越大感受野越大,所获得的全局特征越完整,但卷积核过大会降低检测速度。虽然大卷积核可以由连续的小卷积核代替,以增大网络深度可以学到更多的特征(例如1 个7×7 的卷积核可以由3 个3×3 的卷积核代替),但同时也增加梯度消失和过拟合的风险。
本文在选择卷积核时,考虑精度与速度的性能平衡,避免算力和深度过大带来的问题。如图6 所示,在MobileNetv1[16]和MobileNetv2[17]上使用不同尺寸的卷积核进行性能测试,初阶段中卷积核越大模型精度越高,但当卷积核的尺寸超过某一值后,模型的准确率开始下降,因此选用的大卷积核应设有尺寸上限。
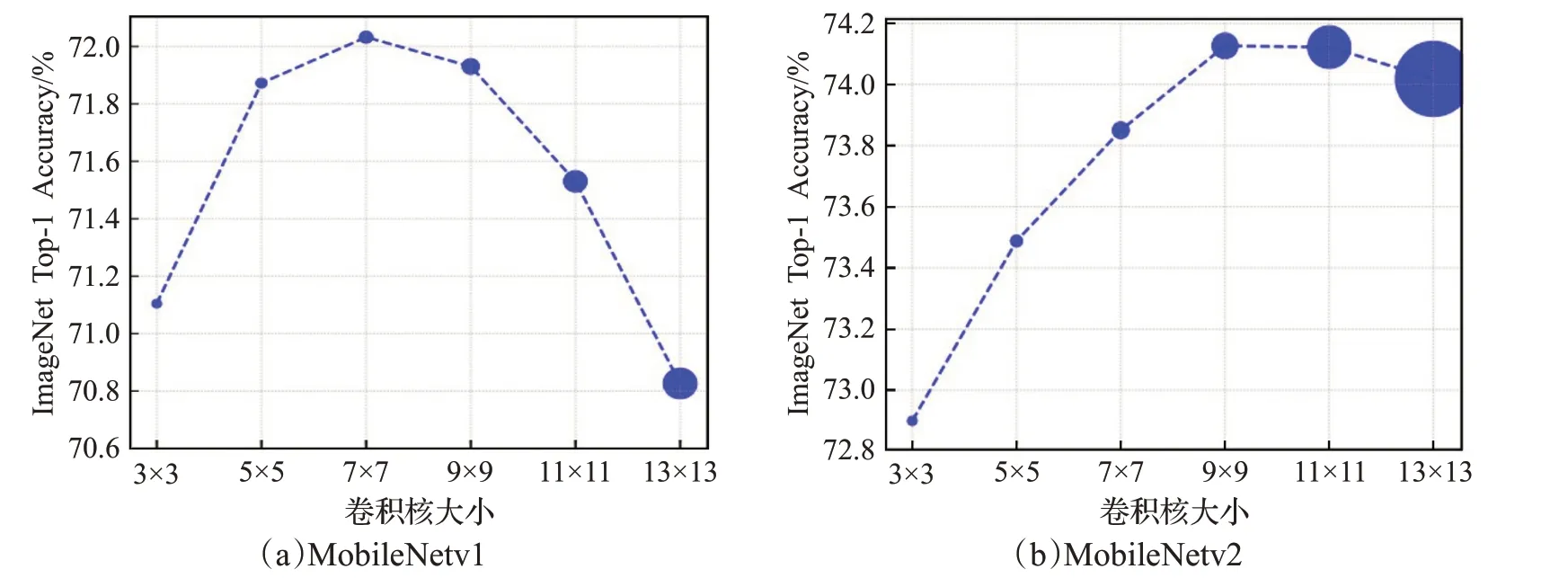
图6 不同大小的卷积核对模型精度的影响Fig.6 Effect of different sizes of convolution kernels on model accuracy
过多的大卷积核不利于算法在嵌入式设备上运行,PP-YOLO[18]的卷积层均选用小卷积核,只在尾部使用5×5 的大卷积核,这与全局使用大卷积核的效果近似。基于以上分析,本文在主干网络的尾部,最后一次压缩特征图时使用5×5的DWConv,而其他的卷积层皆为小卷积核,以确保模型低延迟和高准确度的特性。依照此思想构造的B-DownSample模块使得分类模型的Acc提升0.07个百分点,检测模型的mAP提升0.11个百分点。
2.3 Neck的选择
SPP 可在同一特征图的不同尺度上提取特征并进行池化操作,将任意尺寸的输入图像转换为相同尺度的输出。与YOLOv4-tiny基准网络不同,本文的改进算法保留SPP 模块,图7(a)为多支路SPP 模块,其中conv为卷积层,max 为最大池化层,n×n代表池化核大小;图7(b)为YOLOv4 中的SPP 模块,包含4 个支路,分别是3 个核大小不同的最大池化模块和1 个跳跃连接,池化核大小分别为{5,9,13},该模块将四个分支的特征图进行concat操作,然后传至下一层;为使得YOLOv4-tiny算法更适合部署在嵌入式设备,构建如图7(c)所示的弱SPP模块。弱SPP模块融合多重感受野,利用局部特征和全局特征来提高目标检测的精度,在提升模型精度的同时,(与YOLOv4中的SPP相比)节省约30%的算力。
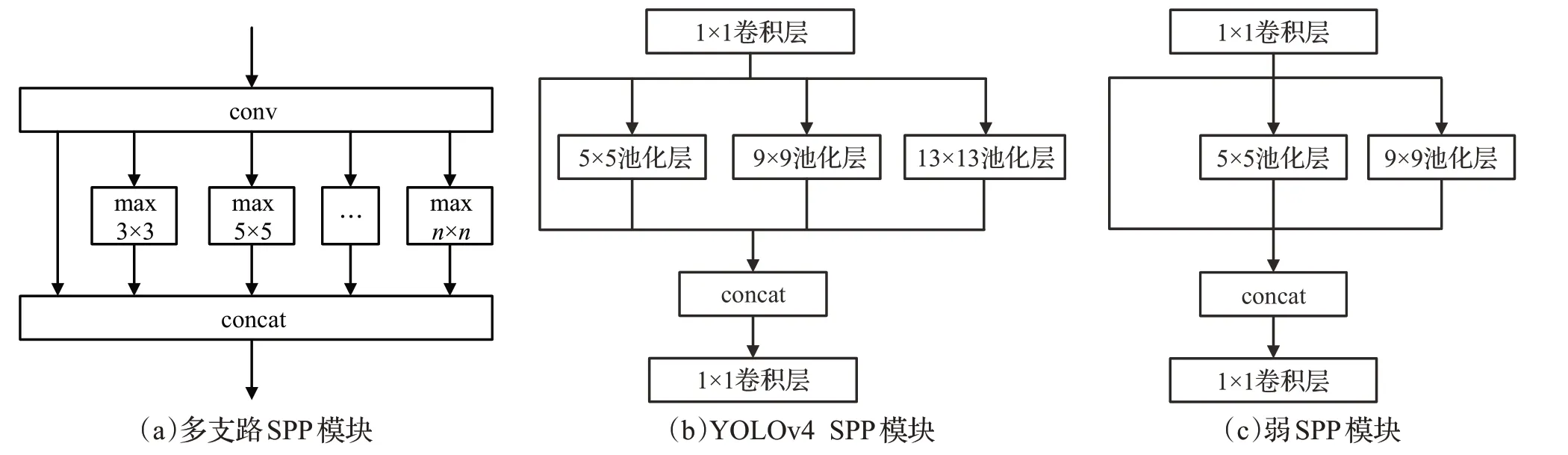
图7 SPP结构对比图Fig.7 SPP structure comparison diagram
3 数据增强与实验环境
3.1 实验环境与参数设置
本文的目标检测模型针对资源有限的嵌入式设备,实验平台为RK3288开发板,其GPU为ARM Mail-T764,可连接USB摄像头。使用caffe深度学习框架。通过Eclipse交叉编译器、NEON指令、WinSCP和PUTTY软件,实现模型从Windows操作系统到RK3288开发板的部署工作。
本文基于ImageNet数据集所搭建的分类网络的初始学习率为0.1、权重衰减系数0.000 04、动量为0.9、power为0.5;在训练过程中前1 000迭代次数使用warm-up机制,选择性能最优的模型作为目标检测的预训练模型。基于COCO 数据集所搭建的检测网络的初始学习率为0.01、权重衰减系数为0.000 5、动量为0.9,power为0.5;在训练过程中前1 000迭代次数使用warm-up机制,且前1 000 迭代次数特征提取部分的卷积全部设为不学习,之后再放开学习。
3.2 改进的Mosaic数据增强
YOLOv4中使用的Mosaic数据增强分为4个步骤:(1)每次从数据集中随机读取4 张图像;(2)分别对4 张图像随机进行翻转、缩放、色域变化等操作;(3)将4 张图像按顺时针排放,然后利用矩阵的方式截取4张图像的固定区域;(4)将截取区域拼接为一张新的图像样本,并变换对应的标签。
原有的Mosaic 先将4 张图像进行普通的数据增强操作,然后将操作后的图像拼接在一起,这导致模型的训练速度降低。原有的Mosaic利用随机剪裁操作选定固定区域,但裁剪图像时并未统计图像中真实框(ground truth,GT)中心坐标的均值,从而裁剪出残缺的GT;并且会随机截取出8(a)中无目标或者图8(c)中目标过小的图像块,造成数据样本的浪费,从而导致模型无法充分利用样本,拟合数据时模型精度会有所损失。

图8 改进的Mosaic流程示意图Fig.8 Schematic diagram of improved Mosaic process
为弥补原有Mosaic 数据增强的不足之处,本文对Mosaic数据增强进行改进,改进的Mosaic的流程如图8所示,通过GT 和标签防止随机截取出无目标或者目标过小的图像块;并且先不对图像进行普通数据增强等操作,而是Mosaic 之后再进行翻转、缩放、色域变化等操作。改进的Mosaic效果图如图9所示,图9(a)右下方的塔尖中并不包含检测目标,而经过改进的Mosaic后,图9(b)中每个图像块都包含有效的目标;图9(c)左上方和左下方的目标过小,而图9(d)中筛选掉过小的目标。改进的Mosaic节省数据增强进程的时间,且充分利用每个图像块以及过滤物体过小的目标,使得模型更易于训练。

图9 改进的Mosaic数据增强Fig.9 Improved Mosaic data augmentation
4 实验结果与分析
4.1 评价指标
本次实验以准确率(accuracy,Acc)、平均精度均值(mean average precision,mAP)和每秒传输帧数(frames per second,FPS)作为检测模型的性能评价指标。相关评价指标的含义与计算公式如表2所示,mAP为平均精度(average precision,AP)的均值。在图像的分类任务中,Acc常被用作衡量模型分类能力的指标,Acc值越大意味着模型的分类器越优良;FPS指每秒处理图像的数量,体现模型的运算能力,FPS 值越大则模型的运算能力越强大;mAP 是衡量模型的分类和检测能力最直观的指标,在很大程度上能够同时体现模型的定位和分类能力,mAP值越大则说明模型性能更为优异。

表2 相关评价指标Table 2 Related evaluation indicators
4.2 消融实验
本文的消融实验以YOLOv4-tiny为基准,验证改进模块分别在预训练阶段和训练阶段中的优化作用。不同因素对分类网络训练的影响结果如表3所列,每项改进模块均对分类模型有着不同程度的贡献,其中改进模块2引入的改进Mosaic对网络的贡献略高于改进模块2的Mosaic。YOLOv4-tiny-CSPRDWConv 选用改进的Mosaic、CSPRDWConv 计算模块、B-DownSample 模块(5×5 大卷积核的下采样模块),使得Acc 值较初始YOLOv4-tiny提高了0.87个百分点。
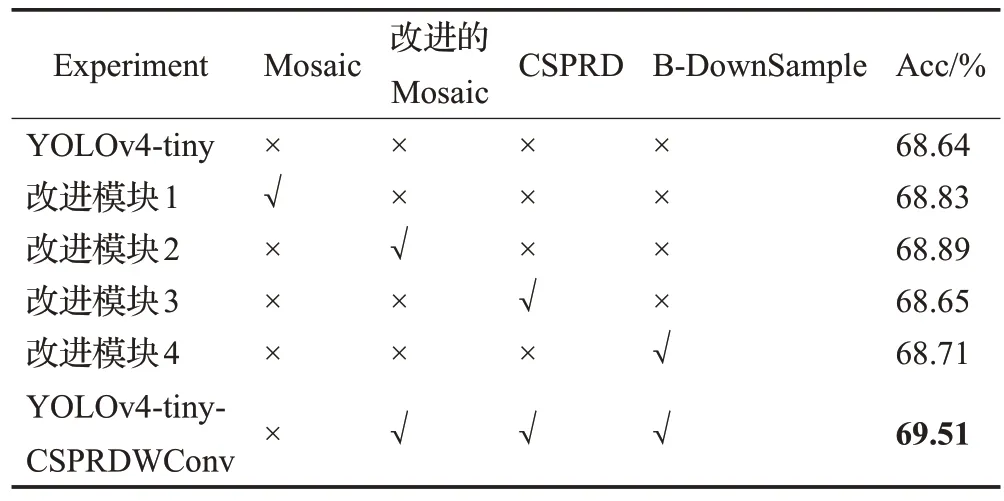
表3 分类网络的消融实验结果Table 3 Results of ablation experiments for classification network
不同因素对检测网络的影响结果如表4,观察mAP可知,表中所列的因素对检测模型的影响均为正。YOLOv4-tiny-CSPRDWConv 引入改进的Mosaic、CSPRDWConv 计算模块、B-DownSample 模块和弱SPP模块,使得平均精度较YOLOv4-tiny基准网络增加0.94个百分点。将改进模块4的SPP替换为改进模块5的弱SPP 后,虽然平均精度下降了0.03 个百分点,但运算速度却提升0.4 倍,牺牲微乎其微的精度来换取速度的大幅提升,以此达到精度与速度的最佳平衡。
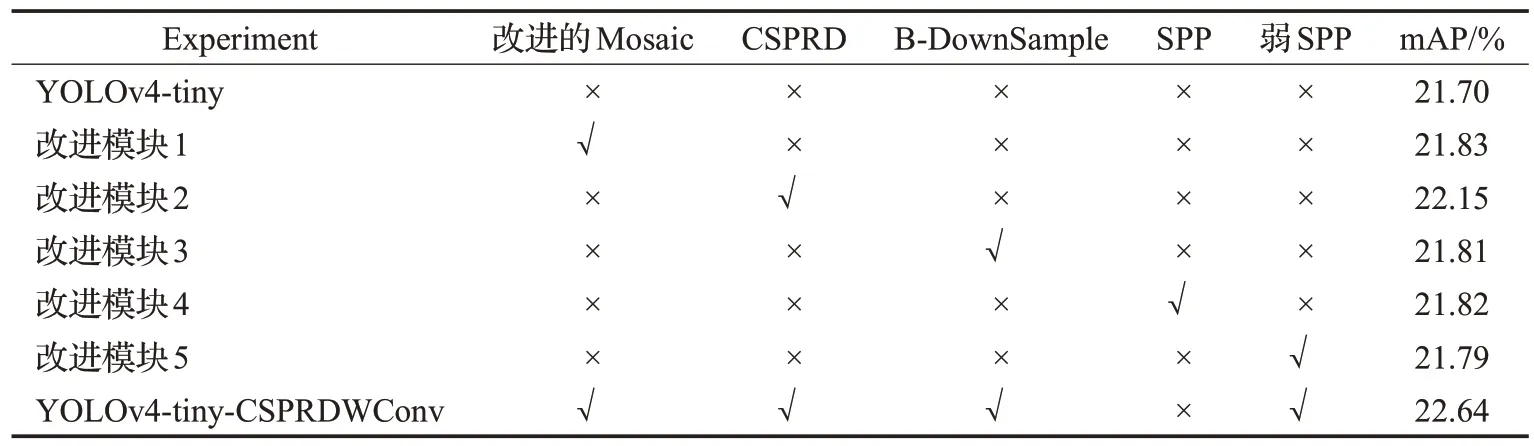
表4 检测网络的消融实验结果Table 4 Results of ablation experiments for detection network
表4中,SPP模块的池化核大小为{k=1,5,9,13},4条支路并行;弱SPP 模块池化核的大小为{k=1,5,9},3条支路并行。
4.3 对比实验及结果分析
为更加具体、清晰地体现本文算法的速度优势,将改进的YOLOv4-tiny模型与YOLOv3-tiny、YOLOv4-tiny以及YOLOv5n 等模型进行对比实验,模型使用相同的COCO数据集来进行训练、验证。不同算法的性能对比结果如表5 所示,大型网络算法(例如YOLOv4)的检测精度明显优于轻量级网络算法(例如ThunderS146 和YOLOv4-tiny);但是大型网络算法的检测速度较低,且模型体积过大,无法流畅地在嵌入式设备上运行。本文提出的检测模型在保证检测精度的前提下,其检测速度皆明显快于当下的主流检测器。当输入大小为224×224时,本文的模型抽取三个不同阶段(7、14、28)的特征层进行检测,检测精度提升0.61 个百分点,检测速度更是达到1 308 FPS,为YOLOv4-tiny的近4倍。引入改进的Mosaic 较无Mosaic 时提升了0.91 个百分点,这说明改进的Mosaic适用于该轻量级网络。
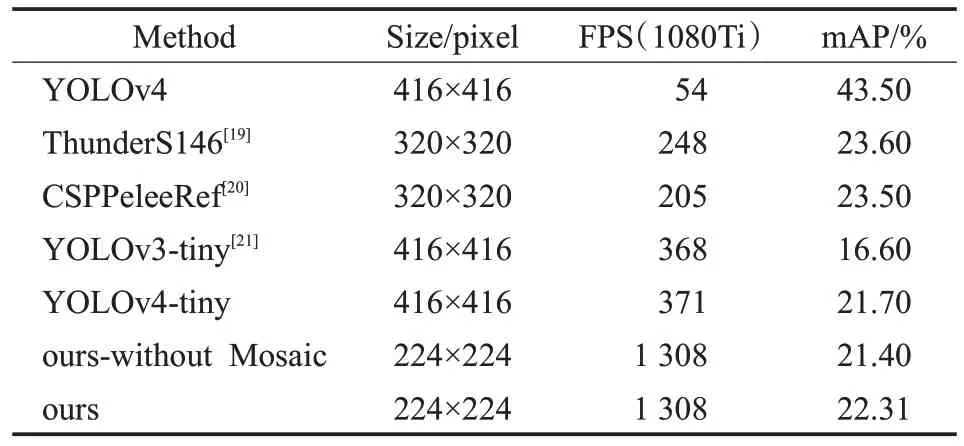
表5 GPU上的实验对比结果Table 5 Analysis of experimental results
将不同模型移植在RK3288 开发板上,得到如表6所列的性能结果对比,YOLOv4-tiny-CSPRDWConv网络将卷积层和BN层融合在一起,并通过NEON指令将速度提高3倍;卷积层和BN层未融合时,模型的推理时间为145.6 ms,融合之后的推理时间缩减至130.1 ms。YOLOv4-tiny-CSPRDWConv网络的输入大小为224×224时,其平均精度比YOLOv3-tiny 增加4.8 个百分点,检测速度提升7 倍之多;相比于YOLOv4-tiny 网络,YOLOv4-tiny-CSPRDWConv网络在平均精度提升0.61个百分点的基础上,算力不及原有算力的三分之一,检测速度加快四倍之多,该对比实验结果验证了本文改进方法的有效性。
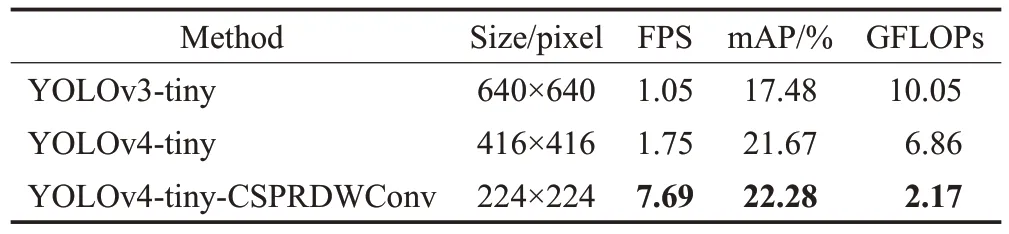
表6 检测模型移植后的速度对比Table 6 Speed comparison after porting detection model
为进一步验证本文模型在不同场景中的检测能力,建立包含办公室、酒店、电梯、户外4 个场景的测试集。图10 展示了不同场景下的实验效果,将收集到的图像进行目标检测,检测结果图则通过不同颜色的边框加以区分。测试结果表明本模型适用于大目标、小目标、多目标、交叉密集目标以及多种复杂场景的目标检测,表现出优良的泛化和精准的定位能力,具有较高的实用价值。

图10 目标检测结果图Fig.10 Graph of target detection results
5 结束语
为使得可部署在嵌入式设备的YOLOv4-tiny算法更为轻量、快速、高效和精准,本文在原有的YOLOv4-tiny算法之上,提出一种基于CSPRDWConv 模块的轻量级网络,并使用改进的Mosaic 数据增强来提升检测精度。除此之外,本文还在主干网络的尾部即最后一次压缩特征图时使用5×5的深度可分离卷积(其他的卷积层皆为小卷积核);Neck中加入弱SPP模块;并通过NEON指令对训练后的检测模型进行优化,将卷积层与BN层融合。上述改进技巧在保证检测精度的同时,大幅加快检测模型的推理进程。
实验表明,本算法在1080Ti的硬件上达到1 308 FPS的实时检测速度,检测速度为YOLOv4-tiny基准网络的近4 倍,mAP 达到22.31%,相比于基准网络提升了0.61个百分点。在RK3288开发板上的检测速度约为8 FPS,mAP 为22.28%。虽然本文的改进算法在RK3288 开发板上的检测中,较其他相关目标检测算法更为流畅和高效,但对于一些性能更低的嵌入式设备本算法仍有待改进;且在小目标检测以及大面积遮挡检测中,本文的改进算法还存在一定的提升空间。下一步会将关注点集中在数据增强和强化学习,并将实时的目标检测的面向对象推广至更低端的边缘嵌入式设备,从而开发出可部署在嵌入式系统的、性能更为优良的轻量级目标检测算法。
猜你喜欢
小猕猴智力画刊(2022年4期)2022-05-25 02:29:38
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中学生百科·大语文(2021年4期)2021-05-12 18:04:07
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2018年11期)2018-08-04 03:25:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
发明与创新(2016年5期)2016-08-21 13:42:44
测绘科学与工程(2016年5期)2016-04-17 06:51:15
电子设计工程(2015年3期)2015-02-27 12:03:45
电视技术(2014年19期)2014-03-11 15:38:20
