
基于双重注意力与精确特征分布匹配的车辆重识别
2023-12-11 07:11潘旭光郭晓燕刘香兰
计算机工程与应用 2023年23期
徐 岩,潘旭光,郭晓燕,刘香兰
山东科技大学 电子信息工程学院,山东 青岛 266590
车辆重识别(vehicle re-identification,Vehicle Re-ID)任务是跨非重叠区域的指定车辆检索问题,旨在利用跨区域的“公安天网”系统对指定的目标车辆进行追踪和查找。通过车辆重识别技术的加持,不仅能节省人工查看视频寻找嫌疑车辆的时间成本,还能为刑侦工作提供可靠的线索和依据,对提高交管人员的工作效率、助力交通数字化转型以及安防追踪具有重要意义。车辆重识别系统需要对全网监控设备下的车辆进行查找与追踪,当给定车辆图像,系统需要将查询图像利用表征学习在车辆数据库中训练并提取车辆的特征向量,然后将学习的车辆特征和候选图像库中的其他摄像头拍摄的图像利用度量学习进行相似度判别,从中匹配到最相似的图像并输出结果,从而实现车辆的再次识别。
随着对车辆实时检索需求的不断增加,车辆重识别作为一项富有挑战性的任务在智能交通研究界受到了越来越多的关注,然而一些客观因素和主观因素对其检索性能产生了一定的影响,主要体现在以下两个方面。如图1所示,一是客观因素,包括光照强度、姿态与视点变化、部分遮挡、背景杂乱以及分辨率变化,这些因素导致所拍摄车辆图像的质量和风格因监控摄像头和拍摄的环境场景的不同而存在着数据分布的严重偏差,因此重识别模型的域泛化能力差,即在源域训练好的模型面对未知分布的目标域时,重识别精度会大幅度降低。二是主观因素,首先由于各大车企所生产的车辆属于工业生产线流水作业所产出的,其具有相似的视觉外观,故两种不同品牌、型号和类型的车辆从背面或正面看起来也会非常相似,即车辆存在类间相似性;其次由于被拍摄的车辆图像所在的环境场景和视角不同,同一辆车在监视网络的不同时间和地点看起来也有不同,即车辆存在类内差异性。因此,如何克服域偏移(domain shift)和车辆这种刚性物体本身存在的类间差异小、类内差异大的问题对车辆重识别的研究具有重要意义。

图1 真实交通场景下车辆重识别存在的挑战Fig.1 Challenges of vehicle Re-ID in real traffic scenarios
为了解决上述问题,本文提出一种基于双重注意力与精确特征分布匹配的车辆重识别方法,通过设计一个全局分支和逐深度多尺度特征金字塔分支的双分支框架来融合全局特征和局部特征,并引入Tuplet边际损失(Tuplet margin loss)[1]以克服现有深度度量损失函数仅依赖于精心挑选的样本对或三元组来实现快速收敛的不足。其关键算法包括双重注意力机制和精确特征分布匹配,前者从空间和通道两个域来获取细粒度注意力信息,而后者从增强源域的域多样性出发,将精确特征分布匹配的风格迁移策略应用于浅层网络,有效提升了车辆重识别的跨域性能。本文的主要贡献如下:
(1)针对车辆重识别过程中对车辆细粒度特征提取能力不足的问题,设计了一种双重注意力机制来高效建模全局上下文信息以增强对车辆细粒度特征的提取能力。同时,提出了一种逐深度多尺度特征金字塔结构,整合不同尺度特征层的多层次信息,并将输出的车辆特征采用特征图分割的思想来突出局部细粒度信息,进一步提升模型对车辆细粒度信息的敏感度。
(2)针对目标域和训练域的数据分布不一致所导致模型性能出现大幅度下降的挑战因素,利用基于精确特征分布匹配的域泛化方法EFDMix(exact feature distribution mixing)[2]来降低不同数据集之间存在的数据分布差异,减小域偏移,实现数据增广。
(3)在公开数据集VeRi-776 及VehicleID 上进行单域和跨域实验,验证了提出的基于双重注意力与精确特征分布匹配方法在车辆重识别问题上的性能优于主流算法的性能。
1 相关工作
为了使车辆Re-ID 模型可以适应不同数据分布下未知的目标车辆数据库,一方面,相关研究者利用生成对抗网络(generative adversarial networks,GAN)技术[3]将源于的图像样式迁移到目标域中,从而减小不同数据集之间存在的领域风格差异。如Wei等人[4]最早提出一种用于重识别领域的生成对抗网络PTGAN,该算法是在CycleGAN[5]的基础上改进而来,用于学习各数据集之间的风格信息并进行风格转换,从而能够大幅度缩小域间风格差异。同年,Deng等人[6]在CycleGAN[5]和孪生网络的基础上构建了一种新的风格转换方法SPGAN,该算法可以保留风格转换前后图像的自相似性以及转换后的源域图像与目标域图像的域不相似性,从而有效地增强模型的无监督域自适应能力。后来,Peng等人[7]以生成对抗网络为基础,设计了一种双分支对抗网络来完成图像与图像之间的内容和风格转换,缩小了不同数据集之间的差异,然后利用融入注意力机制的卷积神经网络进行模型训练。接着又提出一种新的渐进自适应学习方法,其在源域采用数据适配模块,生成与未标记目标域具有相似数据分布的图像作为“伪目标样本”,并提出一种加权标签平滑损失来平衡伪标签的置信度[8]。
另一方面,利用聚类思想为不同风格的车辆数据集打上高质量的标签,然后将生成的数据传送到卷积神经网络中用于模型训练,反复迭代,最终使得模型在不同风格的数据集下都具有良好的性能[9]。如Bashir等人[10]提出了一种渐进式无监督学习方法来将预训练的深度表示转移到未知域,在聚类方法和卷积神经网络的微调之间迭代,以改进在不相关的标记数据集上训练的初始化重识别模型。Wang等人[11]利用聚类算法将训练集划分成多个域间子集,然后通过每两个域间子集之间的风格迁移来生成跨领域的数据从而实现数据增强。由此看来,目前的研究工作大多是利用生成对抗网络生成的图像实现数据增广,但由于合成数据与真实场景的数据之间存在着领域差异和特征偏差,简单地添加合成数据来训练模型取得的效果非常有限。
当前存在的车辆Re-ID模型对相同品牌、相同车型的车辆细粒度特征提取能力较弱,因此为进一步地提取车辆丰富的特征信息,提升模型对细粒度特征的表达能力,Wang等人[12]提出了一种方向不变特征嵌入模块,通过方向不变特征嵌入,可以基于20 个关键点位置提取不同方向的车辆局部区域特征,但实际上并不是所有关键点都包含鉴别性信息。He等人[13]提出了一种部分正则化区分特征的方法,该方法增强了对细微差异的感知能力。Suprem 等人[14]构建了一种适应于车辆重识别的全局和局部注意力模块,以确保网络同时对全局和局部特征进行提取,并运用注意力机制和局部关键区域的特征信息进行车辆重识别。尽管上述方法可以捕获到局部细节并充分利用,并提高了模型去感知同种型号车辆细微差异的能力,但大多数方法并没有考虑车辆的多尺度信息。
2 网络结构
本文所设计的网络是以WideResNet50(WRN50)[15]为骨干网络的双分支框架,即由一个全局分支和一个逐深度多尺度特征金字塔分支组成。与车辆重识别领域应用最多的ResNet50相比,WRN50从减少网络深度、增加网络宽度的视角改善了ResNet50的模型性能和训练速度。网络的整体结构如图2所示。
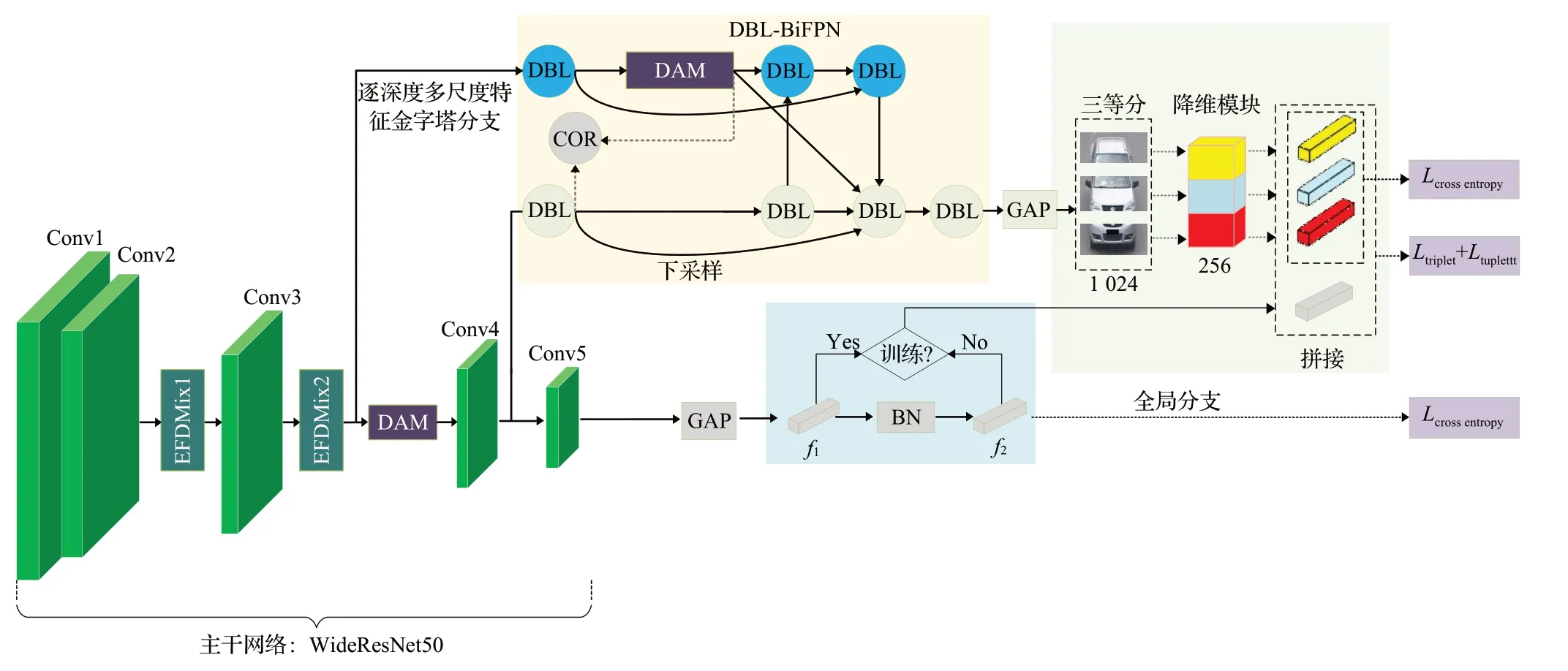
图2 整体网络结构图Fig.2 Overall network structure diagram
首先,在骨干网络的第四个残差块(Conv5)后构建了全局分支以用于提取目标车辆的全局性信息。为了有效鉴别车辆重识别中相同车型、外观相似但身份不同的车辆,在骨干网络的第二个残差块(Conv3)之后插入本文所提出的双重注意力机制;在对骨干网络的输出进行全局平均池化操作之后,2 048维的向量被作为全局特征f1进行传递,之后利用BNNeck(batch normalization neck)对全局特征f1进行归一化处理得到归一化特征f2。在训练阶段将特征f1和f2分别用于优化欧氏距离和余弦距离,以避免多种损失同时优化一个特征向量时产生损失震荡的问题。另外,由于前期的卷积层对样式信息进行编码,因此将EFDMix[2]模块嵌入到WRN50的第一个残差块(Conv2)和第二个残差块(Conv3)后以增强模型的域泛化能力。
其次,在骨干网络的第二、第三个残差块(Conv3和Conv4)后引出逐深度多尺度特征金字塔分支以获得车辆图像的更多局部细节。该分支主要由一个两层的多尺度特征提取模块DBL-BiFPN 和一个基于PCB[16]的横向三分块结构组成。DBL-BiFPN的输出经过一个平均池化操作和降维模块将1 024的维度信息压缩到256,从而用于优化训练过程中逐深度多尺度特征金字塔分支的分类损失。
最后,将全局特征f1和逐深度多尺度特征金字塔分支的输出特征进行融合形成网络的全局-局部特征,并在交叉熵损失和难样本挖掘三元组损失的基础上,引入Tuplet边际损失对网络模型进行联合优化。
2.1 双重注意力机制
注意力机制本质上就是对输入进行权重分配,即先对图像中的部分信息进行选择性地忽略,然后采用自适应的方式对所有信息进行重新加权,使得重要的信息会被赋予相对较大的权重,以广泛应用于深度学习中[17-19]。目前在车辆重识别领域应用的注意力机制主要分为空间注意力机制和通道注意力机制。然而,空间注意力往往仅考虑局部区域的信息,无法建立远距离的依赖。非局部(non-local)注意力[20]根据映射像素之间的相似性生成一个加权掩码,然后计算一个位置的响应作为所有位置特征的加权和,从而产生全局感受野,但计算成本太高。通道注意力多数只关注通道内部信息的综合,没有考虑到全局上下文信息的重要性。CBAM[21]综合考虑了通道和空间两路的注意力信息,但获取注意力信息的方式是独立的,是依次推断注意力图,还是无法有效捕获长程上下文信息。
针对以上所述,本文在全局上下文网络(global context network,GCNet)[22]和通道注意力模块(channel attention module,CAM)[23]的基础上设计了一种新的注意力框架——双重注意力机制(dual attention mechanism,DAM)。如图3 所示,DAM 通过并行两路获取注意力信息,一路是在空间域,另一路是在通道域。

图3 DAM注意力机制Fig.3 DAM attention mechanism
在空间域中,首先执行一个全局注意力池化,引入深度可分离卷积[24]和Softmax 函数来获得注意力权重,通过将注意力权重和输入特征矩阵进行相乘来获取全局上下文特征,然后利用瓶颈操作来减少计算量。这里的深度可分离卷积Wv1和Wv2是为了降低参数量并进一步提取特征信息。此外,还将GELU(Gaussian error linear unit)激活函数引入空间域以提升模块的整体性能。在GELU之前引入层归一化(LayerNorm)克服了两层特征转换带来的优化难度,充当了有助于泛化的正则化器。全局上下文模块的具体结构如图3 所示,其中r为缩放因子,公式如下:
其中,Zi表示模型的输出;Np(即Np=H×W)是特征映射中的位置数;是全局注意力的权重;Wk、Wv1和Wv2均为深度可分离卷积;δi=Wv2GELU(LN(Wv1(·)))表示瓶颈转换。
在通道域中,分别对原始特征矩阵I做Reshape(C×H×W),Reshape 和转置操作(H×W×C),将得到的两个特征图相乘再通过Softmax 得到通道注意力图X(C×C),然后将X与I做矩阵乘法,再乘以尺度系数β,再Reshape 为原来形状(C×H×W)得到通道加权矩阵A,将A与I相加得到通道注意力的输出矩阵B。最后将原始输入矩阵I、全局上下文模块的输出矩阵以及通道注意力输出矩阵B进行特征聚合得到DAM 的注意力输出矩阵I*。通道注意力模块的具体结构如图3所示,公式表示如下:
其中,X矩阵指的是通道注意力图,xji为X矩阵的每一个元素,下标ji表示第i个通道对第j个通道的影响,故通道注意力输出矩阵B中的每个元素表示为:
其中,β为尺度系数,初始化为0,并逐渐学习分配到更大的权重。公式(3)显示每个通道的最终特征是所有通道的特征和原始输入特征的加权和,其对特征映射之间的长期语义依赖进行建模,有助于增强对车辆特征的辨别能力。综上,两个模块的特征聚合表示公式如下:
基于上述分析,DAM 不仅具有对全局上下文进行建模的优点,而且能够计算所有通道之间的加权和来捕捉通道间的依赖性,使模型不仅学习车辆的轮廓信息,还能聚焦于车辆的鉴别性特征,抑制杂乱的背景信息,从而能够增强模型的细粒度特征提取能力。
2.2 EFDMix风格迁移模块
虽然卷积神经网络在学习判别性特征方面表现出了显著的能力,但它们对未知领域的泛化能力往往很差。为了克服车辆重识别的跨域性能衰退的问题,本文在模型中引入了EFDMix[2]方法,该方法利用精确特征分布匹配(exact feature distribution matching,EFDM)[2]对高阶特征统计量进行有效和隐式的匹配,以增强领域泛化中的交叉分布特征。给定输入数据X∈RB×C×HW和样式数据Y∈RB×C×HW,B、C、H、W分别表示批次大小、通道维度、高度和宽度,EFDM是以通道的方式进行应用,故其公式可以定义为:
其中,o表示排序匹配算法的复杂度,排序匹配是通过匹配两个排序后的向量来实现的,τi和ki是其索引符号,表示停止梯度操作。
为了生成更多样化的混合车辆风格的特征增强,通过EFDM对排序向量进行内插,得到精确的特征分布混合EFDMix为:
其中,λ表示从实例出发的混合权重,并从Beta 分布中取样λ:λ~Beta()α,α;α∈(0,∞)是一个超参数,本文设定α=0.1。值得注意的是,当λ=0时,EFDMix退化为EFDM。
由于早期的卷积层对车辆的样式信息进行编码,而后期则倾向于捕获语义内容,因此将EFDMix模块引入到WRN50 的Conv2、Conv3 残差单元之后,以0.5 的概率来决定是否在训练阶段的前向通道激活EFDMix,并在测试阶段将其停用。具体来说,将源域的车辆图像进行训练,在给定输入特征X的情况下,将输入特征X(源域数据集)沿批次维度随机洗牌得到混合样式特征Y(目标域数据集),从而将输入转换为输入域和目标域之间的中间域,减小数据集之间的风格差异。
2.3 DBL逐深度卷积滤波器
传统的CBL 卷积层作为网络的一个基本组件,一般由卷积层、批量归一化(batch normalization,BN)层和ReLU(recitified linear unit)激活层组成,但这种结构存在着网络收敛比较慢的问题。为此设计了一种适合重识别网络的新型卷积层结构——逐深度卷积滤波器(DO-Conv-BN-LeakyReLU,DBL),其由逐深度过参数化卷积层(depthwise over-parameterized convolution,DO-Conv)[25]、BN 层和LeakyReLU 激活函数组成,结构如图4所示。

图4 CBL和DBL结构对比图Fig.4 CBL and DBL structure comparison diagram
DO-Conv 是在传统卷积操作中加入了额外的深度卷积操作,构成一个过参数化的卷积层,过参数化的优势是其所使用的多层复合线性运算可以在训练阶段之后合并成紧凑的单层表示,使得在推理时只使用一个层,从而将计算量减少到完全等同于传统卷积层。此外,与传统卷积相比,DO-Conv具有更快的收敛速度,并且在不增加网络推理计算量的前提下提高网络性能。除此之外,网络还使用了LeakyReLU 激活函数代替原来的ReLU激活函数,以提升网络的整体性能。
2.4 DBL-BiFPN逐深度多尺度特征金字塔结构
加权双向特征金字塔网络(bidirectional feature pyramid network,BiFPN)[26]是针对目标检测任务所提出的,如果直接应用到车辆重识别任务中会存在网络收敛较慢和模型性能不理想等问题。因此,将DBL 卷积层应用于传统BiFPN 结构并在原模型的基准上加强了跨层级交互以增强对车辆特征的充分复用。DBLBiFPN的关键是一个上下对称的结构,如图5所示。由于浅层区域的特征可以保留图像中更多的细节,同时维度较低的特征也会减少分支内需要学习的参数量,因此,将WRN50 的第二个残差块(Conv3)和第三个残差块(Conv4)的浅层特征作为逐深度多尺度特征金字塔分支的输入P1和P2。

图5 DBL-BiFPN结构图Fig.5 DBL-BiFPN structure diagram
具体来说,逐深度多尺度特征金字塔分支首先从DBL卷积层开始,将骨干网络浅层区域输入的不同通道数的特征图维度转换为统一的256,然后四个DBL卷积层将不同尺度的特征进行自底向上和自顶向下的方式聚合。其中DBL卷积层采用了3×3大小的卷积核,自底向上的连接是通过一条最近点内插来实现以增加特征图的大小;相反,自顶向下的连接是通过使用2×2 卷积核的最大池化来实现。其次,在每层的第一个DBL 卷积层到输出节点之间增加了一条类似于ResNet残差结构的额外路径进行下采样操作,以便在不增加太多代价的情况下融合更多的车辆特征,下采样操作如图5中的曲线箭头所示。同样地,跨层级连接也增强了对车辆特征的充分利用。另外,这里还使用双重注意力机制和交叉正交化(cross orthogonality regularization,COR)[27]来减少协同冗余,并进一步促进了模型不同分支之间的多样性。最后,在全局平均池化之后引入基于PCB[16]的分块结构,有效抑制了车辆图像中的背景信息干扰并能够突出车辆局部信息。其中横向切割后的三个分块分别对应于车辆图像的上、中、下三个区域,并将全局特征f1和横向分割模块的输出特征进行拼接形成模型的全局-局部特征,再通过损失函数进行相似性判断。
2.5 损失函数
为了使网络模型具有更好的预测能力,本文在以往Re-ID领域常用的交叉熵(cross entropy,ce)损失和难样本挖掘三元组(hard mining triplet)损失的基础上,引入了Tuplet边际损失[1]对网络模型进行联合优化。
与三元组、对比损失函数通过挑选样本来实现快速收敛的思路不同,Tuplet边际损失是从输入的每个小批次中随机选择样本来使用。具体来说,Tuplet边际损失隐含地提高了困难样本的权重、降低了简单样本的权重,同时在角度空间中引入了一个松弛的余量以缓解最困难样本的过拟合问题。此外,Tuplet边际损失还通过分解特定类别的信息来解决对内变化的问题,以提高其普适性,因此本文将其与上述两种损失函数联合优化训练模型。假设x∈X表示车辆数据,y∈Y表示其标签,Tuplet边际损失的目的是学习一个具有小的类内距离和大的类间距离的判别性特征嵌入f(x),即:
与三元组损失类似,这里的xa表示基准车辆,xp表示正样本车辆,xn表示负样本车辆。Tuplet边际损失的计算公式如下:
θap表示f(xa)和f(xp)之间的角度;θani是f(xa)和f(xni)之间的角度;s表示超球体半径的尺度因子;松弛余量β≥0,本文设置β=0.2。
最终网络的总损失Ltotal是由交叉熵损失、难样本挖掘三元组损失以及Tuplet 边际损失按照一定的比例叠加而成,其中λ代表Tuplet 边际损失的权重系数,具体计算如公式(10)所示:
3 实验与分析
3.1 数据集与实验设置
为了验证本文方法的有效性,在车辆重识别的两个公共基准数据集进行了广泛的实验,即VeRi-776[28]、VehicleID[29]。数据集的详细信息如表1所示。

表1 数据集信息Table 1 Dataset Information
在训练阶段,车辆图像被重新设置为384×128,然后通过随机翻转、随机擦除、随机裁剪以及随机补丁来进行数据增强。同时,将Adam 优化器用于优化模型,初始学习率为0.000 035,学习率衰减步长为[60,90],学习率衰减因子设置为0.1。
3.2 评价指标
本文所有实验均使用Rank-n、平均准确率均值(mean average precision,mAP)和累计匹配(cumulative match characteristic,CMC)曲线作为评价指标。其中Rank-n指的是遵循某种相似度匹配规则对车辆进行特征匹配后,检索结果中前n张车辆图像中存在正样本车辆的概率,即在第n次以内匹配正确的概率,常使用Rank-1和Rank-5;mAP是平均准确率(average precision,AP)的平均值,通过将查准率和查全率进行结合来度量车辆重识别;CMC 曲线通过计算前n个结果与查询集中属于同一车辆的概率来直观展示出重识别的准确性。
3.3 消融实验分析
3.3.1 双分支网络的有效性验证
为了验证全局分支和逐深度多尺度特征金字塔分支对网络性能的影响,仅使用交叉熵损失对网络进行优化,并在VeRi-776 数据集进行消融实验,实验结果如表2所示,其中加粗表示最佳结果。

表2 不同分支在VeRi-776上的实验结果Table 2 Experimental results of different branches on VeRi-776 单位:%
从表2 可以看出,引入以WRN50 作为骨干网络的全局分支比以经典ResNet50作为骨干网络的全局分支具有更好的性能,mAP 与Rank-1 分别提升了1.14、0.58个百分点。相较于以ResNet50作为骨干网络的双分支网络,同样以WRN50 作为骨干网络的双分支网络在mAP和Rank-1指标上具有更优秀的表现,mAP与Rank-1 分别提高了0.94、0.54 个百分点。为进一步验证两种骨干对模型的影响,利用Grad-CAM++技术对ResNet50和WRN50网络进行了可视化处理,如图6所示,可以看出两种网络的关注点均在车辆身上,但WRN50 对年检标志这种局部信息也有所关注,进而使网络学习到更丰富的车辆细粒度特征。因此,后续实验均以WRN50 为骨干的双分支网络展开。
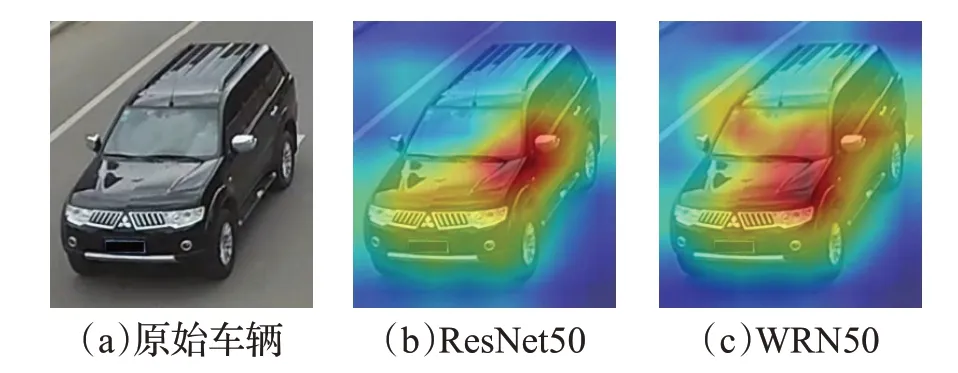
图6 两种骨干网络的热力图对比Fig.6 Heat map comparison of two backbone networks
3.3.2 注意力机制的影响
如图7 所示,从VeRi-776 数据集中选择了4 张不同类型的车辆图片,利用类激活热力图观察在浅层主干(Conv2)添加DAM后网络对车辆图像的关注点。通过对比添加和未添加DAM 后的可视化结果可知,所设计的注意力能较好地关注图像中信息量丰富的区域,如第一张图片添加DAM 后,网络对年检标志这种细粒度信息更加关注;第二张是一辆出租车,对出租车的再次识别往往是利用车顶灯牌这类独有的属性标志,经观察可知,添加DAM 后网络能将以前在护栏上的关注点转移到车辆顶部区域,较好地对车辆前景与背景信息进行区分。第三张和第四张分别是紧挨护栏的皮卡车与侧向行驶的黑色轿车,在未添加DAM时,网络对车辆的关注点较为分散,添加DAM后,网络的关注分布均集中在车身上,证实了模型对车辆关键特征的提取能力。

图7 未添加DAM与添加DAM的热力图对比Fig.7 Comparison of heat map without DAM and with DAM
进一步地,针对DAM 注意力机制在模型中的放置位置,以全局分支、逐深度多尺度特征金字塔分支以及交叉熵损失为基础模型,其实验结果如表3 所示。其中,实验1 表示在WRN50 的Conv2 后添加双重注意力模块,实验2 表示在WRN50 的Conv3 后添加双重注意力模块,实验3 表示在WRN50 的Conv4 后添加双重注意力模块,实验4 表示在WRN50 的Conv5 后添加双重注意力模块,实验5表示在逐深度多尺度特征金字塔分支内添加双重注意力模块,实验6 表示在WRN50 的Conv3 后以及逐深度多尺度特征金字塔分支内均添加双重注意力模块。从实验结果可以看出实验6 的模型性能最优,因此本文选取实验6 的DAM 放置位置。另外,在不同位置放置双重注意力模块所对应的CMC 对比曲线如图8所示。

表3 DAM在模型中不同放置位置的实验结果Table 3 Experimental results of different placement of DAM in model 单位:%

图8 DAM在模型中不同放置位置的CMC曲线Fig.8 CMC curves for different placements of DAM in model
为了验证双重注意力机制的先进性,以表3 实验6的配置为基础,对5种注意力机制在VeRi-776数据集上进行了实验,其对比结果如表4 所示。从表4 的实验结果可以看出本文提出的双重注意力机制效果最佳,相较于全局上下文网络GCNet[22],其mAP提升了1.09个百分点、Rank-1 提高了0.98 个百分点;相较于通道注意力模块CAM[23],其mAP提升了0.92个百分点,Rank-1提升了0.77 个百分点;相较于非局部注意力机制Non-Local[20]和CBAM[21],注意力机制也有显著的性能提升。

表4 5种不同注意力机制的实验结果Table 4 Experimental results of five different attention mechanisms 单位:%
3.3.3 DBL-BiFPN分支的影响
为了验证DBL-BiFPN的先进性,将BiFPN和DBLBiFPN在VeRi-776数据集上进行了实验,结果如表5所示。从表中数据可以得出,DBL模块对BiFPN性能的提升做出了贡献,其mAP相比于CBL结构提高了0.4个百分点,Rank-1精度提高了0.5个百分点。

表5 DBL模块对BiFPN影响的实验结果Table 5 Experimental results of effect of DBL module on BiFPN 单位:%
另外,为了确定特征图横向分割的次数对模型效果的影响,在VeRi-776 数据集上开展了实验,实验结果如表6 所示。可以看出,车辆被等分为3 块时模型性能最佳,验证了粗略地分割会导致模型无法捕获精确的车辆细粒度信息,而分割得越精细会引入一些边缘毛刺信息,难以有效地对车辆特征进行提取。

表6 特征图水平分块个数的实验结果Table 6 Experimental results of number of horizontal chunks of feature map单位:%
3.3.4 风格迁移模块的影响
为了验证EFDMix 风格迁移模块处在网络不同深度位置对跨域性能的影响,在VeRi-776 与VehicleID 数据集上进行了跨域消融实验。在实验中,两个数据集分别作为源域和目标域,对于VehicleID数据集,本文选取最有测试难度的Test2400 作为测试集,实验结果如表7所示。从表7 中可以看出当源域和目标域源自不同数据集时,由于图像风格的差异,模型性能会急剧衰退,但在网络较浅的卷积层后迁入基于精确特征分布匹配的风格迁移模块时跨域性能得到了极大的改善,不仅证实了风格信息是由CNN 的浅层所捕获的,也验证了本文利用高阶统计量进行特征增强改善了源域的领域多样性,提高了训练模型的域泛化能力。

表7 EFDMix在模型中不同放置位置的跨域实验Table 7 Cross-domain experiments with different placement of EFDMix in model 单位:%
3.3.5 损失函数的影响
为了验证各损失函数的有效性,本文在基础网络之上分别添加了难样本挖掘三元组损失和Tuplet 边际损失,在VeRi-776数据集的对比实验结果如表8所示。从表中可以看出当引入3种损失联合训练时mAP和Rank-1评价指标最优,这是由于Tuplet边际损失的松弛余量不仅改变了正样本对和负样本对中的成对距离的分布,还迫使损失更加关注“适度硬的三元组”。因此,松弛余量通过降低在最难的三元组上过拟合的风险,改善了基于Tuplet的损失函数的性能,验证了本文在车辆ReID领域引入Tuplet 边际损失的必要性和有效性。为了验证不同权重的Tuplet边际损失对于模型性能的影响,还对权重系数进行消融实验,如表9 所示,可以看出λ=0.000 125时,模型性能最佳。

表8 3种不同损失函数的实验结果Table 8 Experimental results of three loss functions单位:%

表9 Tuplet边际损失不同权重系数值的实验结果Table 9 Experimental results for different weighting factor values of Tuplet’s marginal loss 单位:%
3.4 对比实验分析
3.4.1 单域方法对比实验
表10 为本文所提出的方法与已有方法在VeRi-776数据集上进行性能对比,包括DAVR[7]、GLAMOR[14]、MBNA[18]、MSA[30]、MsDeep[31]、VSCR[32]、CFVMNet[33]、PGAN[34]、HPGN[35]、GiT[36]。相比于同样使用全局和局部特征的GLAMOR[14]模型,本文将不同尺度上的车辆细粒度特征进行整合以提升模型的精度和域泛化性能,而不仅仅是将全局特征和局部特征进行拼接。总的来看,本文所提出算法在VeRi-776数据集上的mAP为80.91%,Rank-1为96.62%,均达到了较高的精度,验证了模型在单域车辆重识别的有效性。

表10 单域方法在VeRi-776数据集上的实验结果Table 10 Experimental results of single-domain approach on VeRi-776 dataset 单位:%
另外,本文对所提出方法在VeRi-776数据集上的部分测试结果进行了检索结果可视化,结果如图9 所示,第一列表示待检索的车辆图像,第二列到第六列表示模型检索正确的前五项,绿框表示检索正确,红框表示检索错误,可视化结果表明本文模型具有良好的特征表达能力。

图9 本文模型在VeRi-776数据集上的部分推理结果Fig.9 Partial test results of vehicle re-identification model on VeRi-776 dataset
在VehicleID 数据集上,对比的方法包括DAVR[7]、MSA[30]、QD-DLF[37]、HSS-GCN[38]、LRPT[39]。其中,“—”表示文章未给出此结果。将这些方法在VehicleID的三个测试集Test800、Test1600以及Test2400上进行的对比实验,结果如表11 所示,可以看出,本文所提算法在三个测试集上的mAP 和Rank-1 均达到了较高的精度,验证了模型在单域车辆重识别上的有效性。

表11 单域方法在VehicleID数据集上的实验结果Table 11 Experimental results of single-domain approach on VehicleID dataset 单位:%
3.4.2 跨域方法对比实验
为了充分检验所提方法的域泛化性能,在VeRi-776和VehicleID 数据集进行了跨域对比实验,实验结果如表12 所示。从跨域实验结果中可以看出,本文方法在VeRi-776→VehicleID的测试中,mAP和Rank1分别达到48.52%和38.70%,在VehicleID→VeRi-776的测试中,mAP和Rank-1 分别达到39.13%和70.00%,跨域结果相较CycleGAN[5]、GLCAM-Net[40]及DAVR[7]这类较优异的跨域模型,其mAP和Rank-1有显著提升,证明了所构建模型不仅可以在单域测试时展现良好的性能,而且在跨数据集测试时也表现出了应对未知数据分布时的泛化性能。
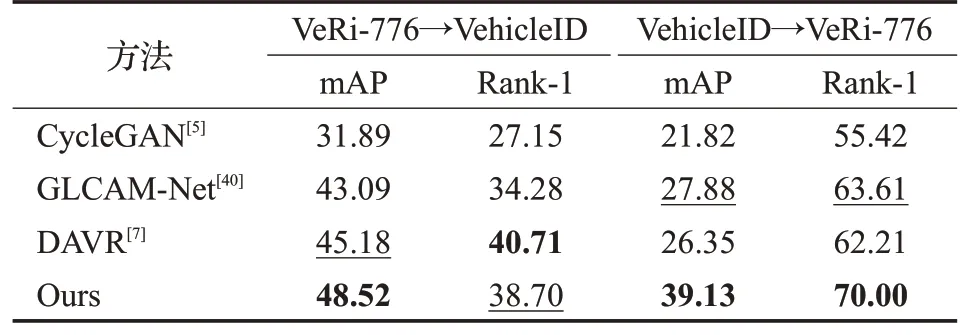
表12 跨域车辆重识别任务的对比实验Table 12 Comparison experiments of cross-domain vehicle re-identification tasks 单位:%
4 结束语
为解决车辆Re-ID模型细粒度特征提取能力弱以及不同数据集之间存在的域间风格差异所导致的车辆重识别效果不佳的问题,本文提出了一种基于双重注意力与精确特征分布匹配的车辆重识别方法,该方法综合考虑了车辆的全局特征和局部金字塔特征。使用WRN50骨干网络和双重注意力机制以更好地提取车辆的细粒度特征;使用逐深度多尺度特征金字塔结构来应对车辆图像中不同尺度的复杂信息;加入EFDMix风格迁移模块以平滑域间风格差异;引入Tuplet边际损失函数对网络进行优化,缓解了最困难样本的过拟合问题。本文所提出的算法在两个大型车辆数据集上的实验结果表明,该算法能有效提升车辆重识别的单域和跨域性能。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
小雪花·成长指南(2022年1期)2022-04-09
数学小灵通·3-4年级(2021年5期)2021-07-16
今日农业(2019年15期)2019-01-03
金桥(2018年4期)2018-09-26
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
