
LDA-ID:An LDA-Based Framework for Real-Time Network Intrusion Detection
2023-12-10 11:37WeidongZhouShengweiLeiChunheXiaTianboWang
China Communications 2023年12期
Weidong Zhou ,Shengwei Lei ,Chunhe Xia ,Tianbo Wang
1 Key Laboratory of Beijing Network Technology,Beihang University,Beijing 100191,China
2 School of Cyber Science and Technology,Beihang University,Beijing 100191,China
Abstract: Network intrusion poses a severe threat to the Internet.However,existing intrusion detection models cannot effectively distinguish different intrusions with high-degree feature overlap.In addition,efficient real-time detection is an urgent problem.To address the two above problems,we propose a Latent Dirichlet Allocation topic model-based framework for real-time network Intrusion Detection(LDA-ID),consisting of static and online LDA-ID.The problem of feature overlap is transformed into static LDA-ID topic number optimization and topic selection.Thus,the detection is based on the latent topic features.To achieve efficient real-time detection,we design an online computing mode for static LDA-ID,in which a parameter iteration method based on momentum is proposed to balance the contribution of prior knowledge and new information.Furthermore,we design two matching mechanisms to accommodate the static and online LDA-ID,respectively.Experimental results on the public NSL-KDD and UNSW-NB15 datasets show that our framework gets higher accuracy than the others.
Keywords: feature overlap;LDA-ID;optimal topic number determination;real-time intrusion detection
I.INTRODUCTION
The scale and complexity of networks are rapidly expanding,and people are facing increasingly complex attacks.According to the Report [1],by 2022,14.6 billion IoT devices will be linked to the internet.Cisco checks 47 terabytes of Internet traffic every day and analyzes 28 billion flows.Therefore,it is essential to study how to detect network intrusion more effectively.There are two challenges in network intrusion detection.
For one thing,network intrusion feature overlaps seriously.Attackers usually simulate regular traffic to avoid being detected,and different attacks share some kernal operations;thus,both of these situations will result in excessive feature overlap.We map the 41-dimensional features of the NSL-KDD dataset to the 2-dimensional plane and observe the degree of feature overlap.As shown in Figure 1,there is a severe feature overlap of the five types of intrusions,especially inside the black circle.However,the existing detection methods[2–5]are more suitable for detecting attacks with low feature overlap.
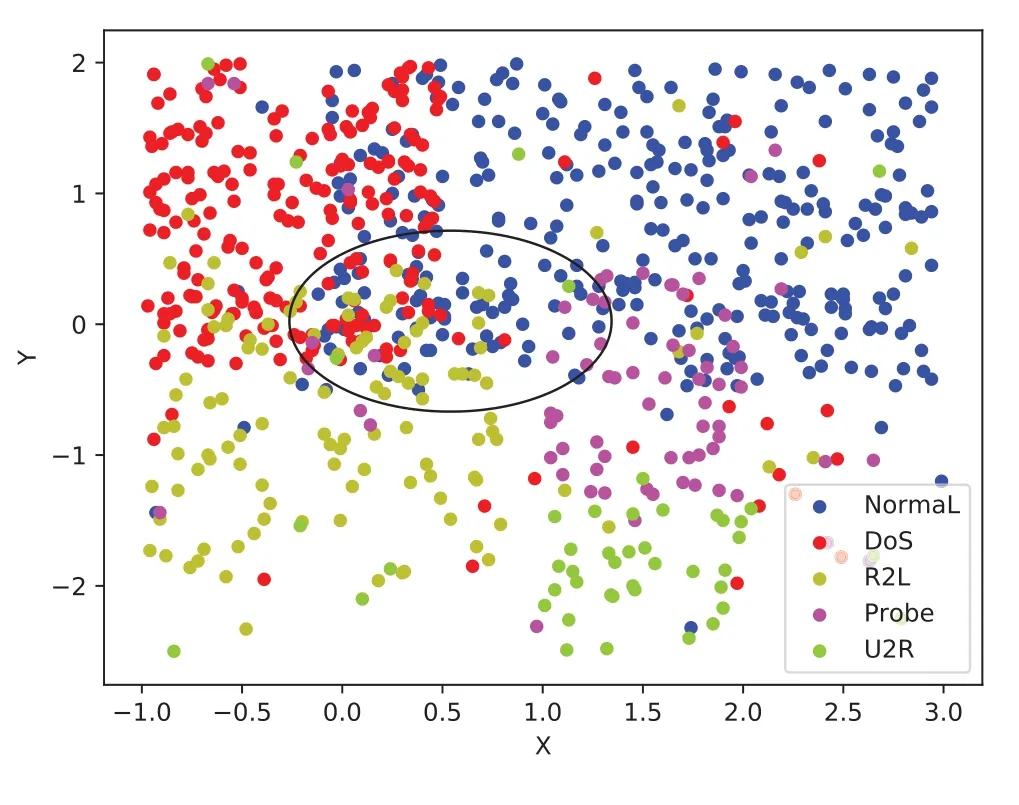
Figure 1.Feature overlaps in the NSL-KDD dataset. The inside of the black circle indicates that the features are highly overlapped.
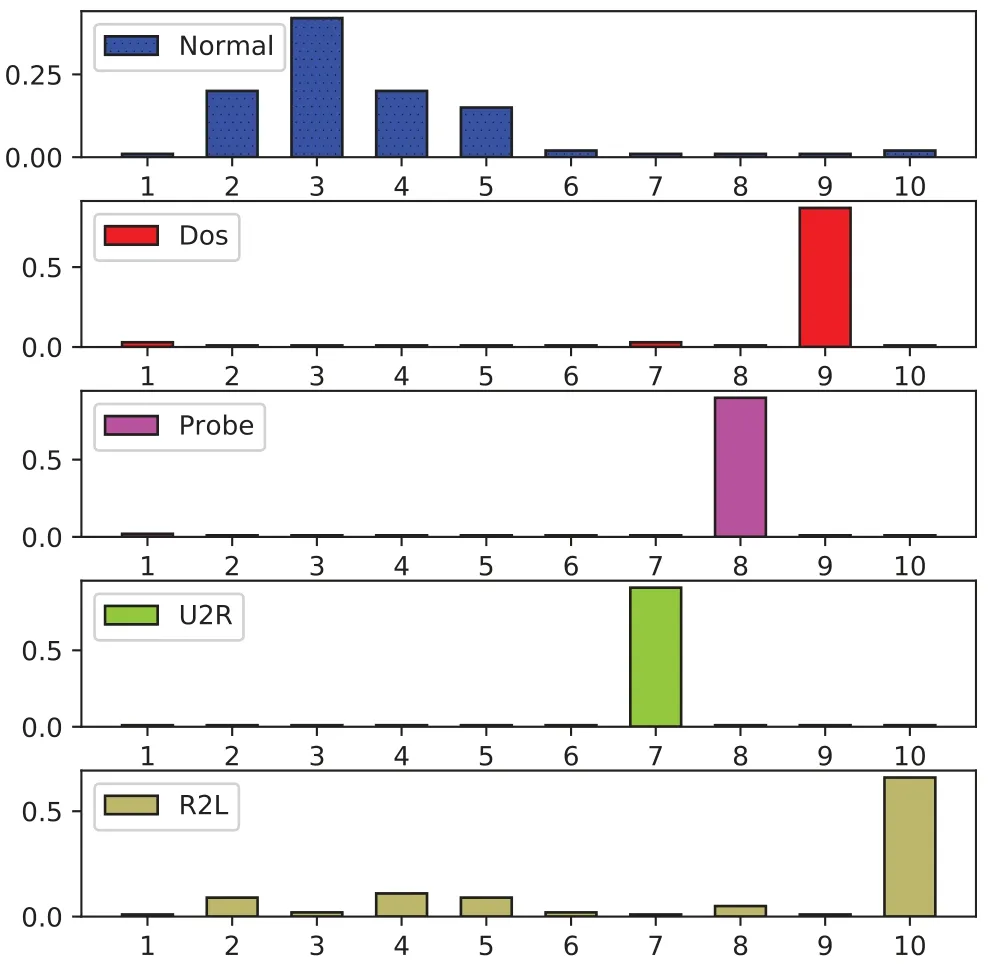
Figure 2.DTD for the NSL-KDD dataset. The topics can be used as the feature for each document (intrusion). The topic number is set to 10. The X-axis denotes the topic,and the Y-axis denotes the topic weight.
The topic model is a powerful tool to extract the latent semantic structure of a bunch of essays,i.e.,the latent topic can be the feature for a document.Moreover,the LDA topic model [6,7] can automatically learn relatively independent semantic features and present the features in a relatively intuitive way.Therefore,we employ the LDA model to transform the original feature space to a probability topic space,which can alleviate the excessive overlap of features in different intrusions,as shown in Figure 1.When applying the LDA model,we regard a type of intrusion data as a document,and treat the extracted topic as latent intrusion behavior.We use topic distribution to characterize an intrusion and generate the Document-Topic-Distribution(DTD)matrix to describe multiple intrusions.To distinguish various types of intrusions better,we expect to get a perfect DTD shown in Figure 4(d).Since the number of topics is the key to influence the DTD,our problem is to determine the ideal topic number.Moreover,prior researchers frequently ignored other areas in favor of the one topic that carried the most weight.The single topic selection strategy can result in weak performance since it ignores some semantic elements.In summary,we are faced with the challenge of specifying the optimum number of topics and selecting multiple suitable topics.
For another thing,we lack efficient real-time detection method.The static LDA model is not suitable for real-time detection.The word distribution variables of the LDA model depend on the total data.When new data arrives,we must train the entire model using the complete data (i.e.,including the original and new data),resulting in a lot of replication computation.Moreover,when there is a drift evolution of online intrusion data,the static LDA model focuses on finding the global optimum and neglects the changes brought by the new data,which leads to a decrease in real-time detection performance.Thus,an online computing mode of the LDA-ID model is urgently needed,which can improve the computing efficiency in the face of stationary data and improve the online detection performance facing drift data.
To solve the above problems,we propose an LDAbased framework for real-time network intrusion detection.The main contributions are as follows:
1.We propose an LDA-ID framework consisting of static LDA-ID and online LDA-ID to mitigate the feature overlap and achieve real-time detection efficiently.
2.We provide two metrics (topic Overlap Degree and topic Dispersion Degree) to evaluate the DTD’s quality and to establish the ideal topic number.
3.We propose two different topic selection methods and corresponding matching mechanisms (i.e.,Topic-Distribution-based and Word-Distributionbased).
4.We carry a series of experiments on the public NSL-KDD and UNSW-NB15 datasets to evaluate our LDA-ID framework.Experimental results show that our framework has higher accuracy than the previous models.
The structure of the paper is as follows: Section II introduces the related works of feature overlap and detection based on the LDA model.We describe the knowledge of the LDA topic model and state the problems unsolved by the current LDA models in Section III.Section IV gives a detailed introduction to the LDA-ID framework.We present the experiments in Section V.The last Section VI concludes this paper.
II.RELATED WORKS
2.1 Feature Overlap in Network Intrusion Detection
In terms of mitigating feature overlap,existing methods usually distinguish between different intrusions by setting rules [8,9].It is equivalent to setting unique features for each type of intrusion,which is more effective for known intrusions.Mitchell et al.[10]proposed an intrusion detection method that converts behavior rules into a state machine.Thus,the device that is monitoring its behavior can easily check whether it deviates from its behavior specification based on the converted state machine.Mabu et al.[11] proposed a probabilistic classification algorithm based on multi-dimensional probability distribution and combined with the traditional Genetic Network Programming associated rules mining algorithm for performance assessment in network intrusion detection,expanding the differences in different types of intrusion features.Batiha et al.[12]used a hybrid evolutionary fuzzy classification and regression algorithm to evolve the detector and constructed and optimized features based on genetic programming and differential evolution.The method expanded the difference between the extracted features and strengthened the capabilities of the wireless sensor network intrusion detector.However,when there are many types of intrusions,in the face of unknown attacks and zeroday attacks,prior knowledge is insufficient to set better rules for each kind of intrusion effectively.
Some research focuses on expanding the feature difference of different intrusions based on the models’characteristics.Fisher discriminant analysis models[13,14]can be used to alleviate feature overlap.Cotae et al.[13] used the method to detect low-speed DoS attacks and determined the Fisher discriminant function according to the smallest difference within the group and the largest difference between the groups simultaneously.The method is conducive to expanding the feature difference for different attacks.Some scholars use the K-means clustering method [15,16]to expand the feature difference.Vasumathi et al.[15]first used the weighted k-means clustering algorithm to cluster the input dataset and then used the artificial neural network to train the clustering information to extract more discriminative features.Tang et al.[16]divided network traffic into multiple clusters and then used the ratio of UDP traffic to TCP traffic to distinguish lowspeed DoS attacks from normal traffic.However,the effects of the above methods are usually limited.
2.2 Detection Based on LDA Topic Model
The LDA topic model is used by some researchers for feature extraction[17–19],classification [20],certification,and anomaly recognition[21–23].In[17],the authors extracted the unique behavior feature based on the LDA model.They chose the single topic with the most weight as the user’s unique behavior feature.Xie et al.[18]adopted the LDA model to process the time series driving data and then extracted the unique driving mode and the driving behavior of the user.Chen et al.[19] taken into account the subject matter of the television program being watched as well as the time stamp of the viewing behavior in order to capture the inherent viewing mode and unique interest.In [20],Mori et al.used the Labeled Latent Dirichlet allocation (L-LDA) to classify worker motions obtained from sensors into four fundamental processes.LLDA automatically learned characteristic motions,so there is no need to define and identify motion features.The model got 86.9% recall in experiments using the assembly process data.Akrouchi et al.[21] proposed a fully automatic LDA-based weak signal detection method,consisting of two filtering functions:the weakness function aimed at filtering topics,which potentially contains weak signals,and the potential warning function,which helps to extract only early warning signs from the previously filtered topics.This approach could detect the risk of the COVID19 pandemic at an early stage.In[22],Kasaei et al.proposed an open-ended 3D object recognition system that concurrently learns both the object categories and the statistical features for encoding objects.They proposed an extension of LDA to learn structural-semantic features (i.e.,visual topics),from low-level feature cooccurrences,for each category independently.In this way,the advantages of both the (hand-crafted) local features and the(learned)structural-semantic features have been considered and combined efficiently.
However,the above methods usually pick up only one topic whose weight is the largest for each document.Thus,lots of semantics information is lost,specifically when the topic number is too large.The single topic with the maximum weight is too small to be a unique feature for a document.Consequently,we need to select suitable topics in the generated DTD.In addition,the topic number and DTD matrix are closely related.An inappropriate topic number will lead to topic overlap or dispersion.Thus,the focus on classification is to determine an optimal topic number to generate a suitable DTD.The topic perplexity[24,25]is a commonly used indicator that characterizes the degree of uncertainty about which topic a document belongs to.It does not,however,distinguish the distinct topic.In [26],the topic stability was measured by repeated LDA operation and clustering.However,this indicator may cause systematic errors.The researchers evaluated the topic coherence by selecting popular topic words and using a set of top-level keywords[27,28].Moreover,the above indicators are all word-based and thus unsuitable for classification.As a result,we require a topic-based indicator to determine the optimal topic number.
III.PROBLEM STATEMENT
In this section,we first describe the knowledge of the LDA topic model and Jensen-Shannon(JS)divergence.Then we state the problem of adopting the LDA model to intrusion detection and the problem of realtime detection.
3.1 Background Knowledge
LDA Model.The LDA model is a type of statistical model for discovering a set of topics that describe a collection of documents.A topic is a distribution of words with probabilities,and a document is a distribution of topics with probabilities.According to the LDA topic model,a documentmis generated like this:1.For each topick∈{1,...,K},
(a) draw a distribution over vocabulary words
βk~Dirichlet(η).
2.For each documnetm,
(a) draw a vector of topic proportions
θm~Dirichlet(α).
(b) for each wordωm,nin documentm,
i.draw a topic assignment
zm,n~Multinomial(θm);
ii.draw a word
ωm,n~Multinomial(βzm,n).
Where the notationsDirichlet(·) andMulti-nomial(·)represent Dirichlet and Multinomial distribution with parameter(·),respectively.The meanings of other variables are included in Table 1.Probability graph representation of LDA is shown in Figure 3.
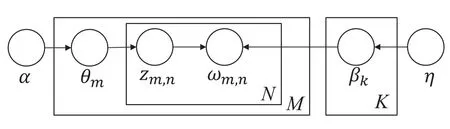
Figure 3.Probability graph representation of LDA model.
According to the probability graph of LDA model,we can write the joint probability distribution formula like Eq.(1).In general,givenα,ηandωm,we infer word distributionβ,topic distributionθmand topic assignment of an articlezm.
JS Divergence.KL divergence(DKL)and JS divergence (DJS) are general methods for calculating distribution similarity.Assume thatP(x) andQ(x) are two distribution functions,the calculation formula ofDKLandDJSis shown as Eq.(2).
3.2 Problems Statement
3.2.1 Problem of Applying LDA Model
In the LDA topic model,the topic is the latent feature for each intrusion.After the training,we generate anM×KDTD matrix,whereMis the number of documents andKis the number of topics.=1.0,whererepresents the weight of topickin documenti.The goal of mitigating the feature overlap is to select a unique topic for each intrusion in the DTD matrix.Thus,the ideal DTD must satisfy the following conditions: each document is 100% weighted and corresponds to a distinct topic.The first half of the matrix is anM×Munit matrix.Refer to Figure 4(d),where the purple box denotes the distinct topic.
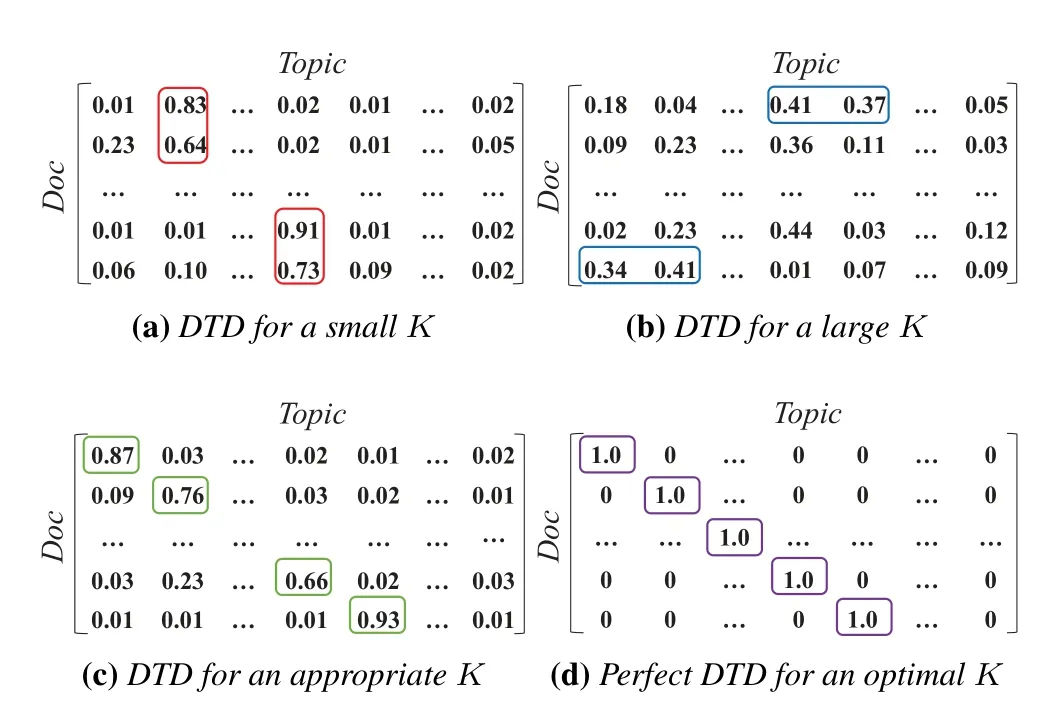
Figure 4.DTD for different topic number K.
The distribution of topic weights is closely related to topic numberK.In reality,there are two scenarios:
(1)Topicoverlap: Some high-weight topics appear in multiple documents at the same time,as illustrated in Figure 4(a),the formal representation is Eq.(3).
(2)Topicdisperse: The topic weight distribution is scattered,with no significant representative topics,as shown in Figure 4(b),the formal representation is Eq.(4).
Thus,neither single topick1 nor topick2 is appropriate to be the feature.Otherwise,due to the topic disperse in documentiand the single topick1 selection,thesamples may be misclassified to other documents.τintervaldenotes a threshold of weight difference andτmaxdenotes a maximum threshold of weight.
Therefore,to avoid the topic overlap and disperse,we need to determine the optimal value ofKso that the generated DTD is close to the perfect DTD.For example,the suitable DTD in Figure 4(c).The application of the LDA model can be formulated as Eq.(5).
whereADTDKandPDTDKdenote the actual and perfect DTDs of topic numberK,respectively.Numtopicimplies the maximum topic number threshold.Thus,we need an indicator to quantitatively evaluate||PDTDK-ADTDK||.
3.2.2 Problem of Real-time Detection
In the face of real-time intrusion detection tasks,we focus on how to detect efficiently.According to the literature [7],the time complexity of the LDA model is:
whereNiterdenotes the number of iterations,Mrepresents the total number of documents in the corpus,Kis the number of topics,anddenotes the average length of documents.Among them,NiterandMare highly coupled.According to Eq.(6),the complexity of the LDA model is too high to handle online detection on large-scale data.Therefore,we need to design an online LDA model.We take into account the online model from two angles: (1)Little batches of data are used for inference,hence the online algorithm ought to converge more quickly.(2) In order to accommodate the continuous evolution of intrusion data,the model should provide the continuity of parameter changes.In other words,it has the ability to record drift data.
IV.LDA-ID FRAMEWORK
4.1 Architecture of LDA-ID
The LDA-ID architecture is shown in Figure 5,which can be separated into a client side and a server side.The server side consists of the database of all intrusion data and the static LDA-ID module.The database stores the formatted data from the client side.The server side runs at regular intervals based on historical experience.The global topic and word parameters are obtained by the static LDA-ID model from all intrusion data and then periodically initialize parameters of the online LDA-ID.The key technology in the static LDA-ID module is the determination for optimal topic number,which is the base of the matching module.
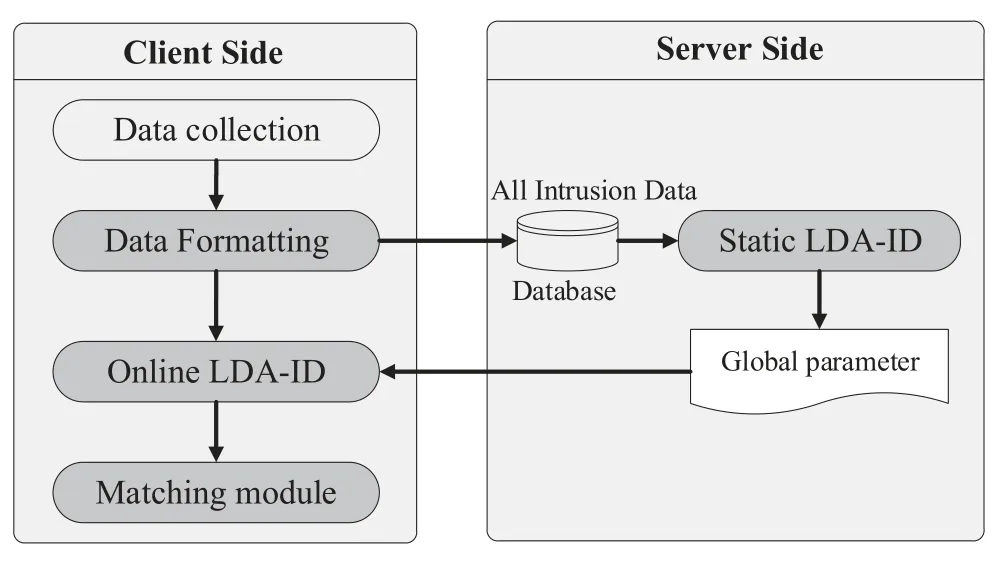
Figure 5.Architecture of LDA-ID.
The client side implements real-time intrusion detection,including the data collection,data formatting,online LDA-ID,and matching module.The data formatting module is to convert the raw characteristic data into limited words for LDA model.All of the formatted data is stored in the server side database as the input for the static LDA-ID.The online LDA-ID has high timeliness and low dependence on computation and storage.It makes full use of the global parameters obtained by the static LDA-ID to detect continuously arriving new data.It also updates itself with new data after detection.
In the testing phase,we propose two feature extractions and corresponding matching mechanisms to detect new intrusion data.One is the multi-topic selection,multi-topic reconstruction,and the corresponding Word-Distribution-based matching mechanism.It can generate the unique feature for each intrusion and thus mitigate the feature overlap.The other is the non-topic selection and the corresponding Topic-Distributionbased matching mechanism,which is much suitable for real-time detection.The details of the LDA-ID framework are described in the following sections.
4.2 Data Formatting
The data formatting module is to convert the raw characteristic data into limited words and then construct documents for every type of intrusion.
4.2.1 Tokenization
Tokenization is the task of chopping the characteristic data into words.There are two types of raw intrusion data:
(1)Categoricalattribute.E.g.,the network service with almost 70 types,such asaol,auth,bgp,etc.Thus,this kind of intrusion data is converted directly to words(i.e.{Serviceaol,Serviceauth,···}).
(2)Continuousattribute.E.g.,the duration of the TCP connection takes values from 0 to 58329.Because the physical meaning of some adjacent values is consistent,it is unnecessary to convert each value into a word for such continuous attribute data.Furthermore,using too many words in the LDA model will lengthen the training time and reduce the effect.As a result,we segment the continuous attribute data based on its value distribution.
4.2.2 Document Construction
We use the Bag of words model to represent the intrusion sample after tokenization.We can treat an intrusion sample as a sentence,and use one sample to represent a type of intrusion.It is called the sentencelevel representation.Or we can count multiple samples of the same intrusion type to represent a type of intrusion.It is called the document-level representation.The literature [29] has a theoretical analysis that too short documents are awful for training LDA due to the sparse document-level word cooccurrences.Therefore,we use the short text aggregation strategy to combine sentence to document.We randomly select some samples and combine them into a new document for each type of intrusion.We verify the effects of text aggregation strategies in the experimental section.
4.3 Static LDA-ID and Optimal Topic Number Determination
This section describes the static LDA-ID process model and the optimal topic number determination.The static LDA-ID process is as Eq.(7).
where{S1,...,SR}indicatesRsamples selected randomly from the same type.It constitutes a document for an intrusion just as a document consists ofRsentences.θdenotes the topic distribution.
After training,we get the DTD and then we define two indicators of topic Overlap Degree and Dispersion Degree to quantitatively assess ||PDTDK-ADTDK|| (see Eq.(5)).The DTD and Topic-Word-Distribution by LDA-ID are shown in Table 2.
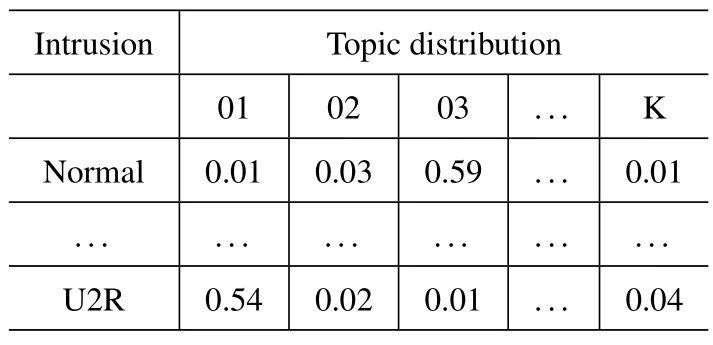
Table 2.Details of topic distribution and word distribution.
(1)Overlap Degree:the extent to which topics appear in multiple documents simultaneously.
(2) Dispersion Degree:the extent to which topics scatter within a single document.
4.4 Online LDA-ID Based on Momentum Decay
The static LDA-ID is a global learning model,and it requires a complete pass through the entire corpus each iteration.Therefore,it may be slow to large data,and it is not naturally suited to settings where new data is constantly arriving.Thus,we propose a suitable real-time processing method (i.e.,online LDAID),which updates the estimation of the topics as each mini-batch or single sample is observed.Online detection requires high timeliness,and thus we use the variational inference method to solve LDA-ID.Variational inference is empirically shown to be faster than and as accurate as Markov Chain Monte Carlo [30],which makes it an attractive option when applying to online learning for large data.Therefore,we need to conduct the online computing model of variational inference.
Variational inference can be regarded as an extension of the Expectation-Maximization (EM) algorithm.It uses variational hypothesis and EM algorithm to estimate the hidden variablesθ,β,zand model parameterα,ηof the LDA model.When we use the EM algorithm,we calculate the expectation based on the conditional probability distribution of the hidden variables in step E.And then,we maximize this expectation in step M to get the updated posterior model parameters.The problem is that in the E step,due to the coupling ofθ,βandz,it is difficult to find the conditional probability distribution of the hidden variables.Thus,we use the variational hypothesis to remove the coupling relationship between the hidden variables,i.e.,all the hidden variables are assumed to be formed through their independent distribution.We use the variational distribution formed by each independent distribution to approximate the conditional distribution of hidden variables,specifically,the posteriorp(θ,β,z|ω)is approximated by a simpler distributionq=q(z|φ)q(θ|γ)q(β|λ)as shown in Figure 6,in whichq(z),q(θ)andq(β)are parameterized by variational parameterφ,γandλ,respectively.Then,the problem of reasoning the distribution of hidden variables is transformed into the estimation of variational parameters and is finally equivalent to the problem of maximizing Evidence Lower Bound(ELBO)L.
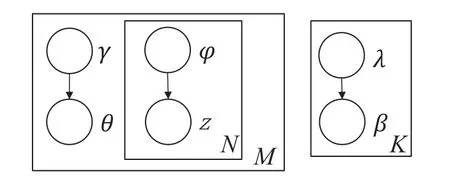
Figure 6.The dependence among hidden variables θ,β,z and variational parameters φ,γ,λ simplified by the variational hypothesis.
The iterative update formula ofφ,γandλare obtained by maximizingL.Then we use the EM algorithm,in the step E,fixλand iteratively updateγandφuntil convergence;in the step M,updateλgivenγandφ.When the variational parameters converge,we fix the variational parameters and update the model parameterαandη,and the algorithm ends with convergence of all the parameters.And then we get the topic distribution and word distribution.
Based on the idea of momentum decay,we propose an online variational inference algorithm for LDA-ID with the decay factor decreases with time.We updateλusing a weighted average of its previous value and current update valueλkw.The decay factor given toλkwisρt=(τ0+t)-μ,whereµ∈(0,1]andτ0≥0 control the attenuation rate of the new sample’s influence on the model.In dynamic detection,we need to get the optimal estimation of the population using added local information.We multiply byDwhen calculatingλkw,whereDhas a big value,and it can be set as the size of the large corpus.The convergence of the algorithm is proved in papers related to momentum decay,and it is also proved from the perspective of the stochastic natural gradient algorithm in literature[31].
The online variational inference for LDA-ID is shwon in Algorithm 1.Note thatγin variational distributionq(θ|γ) has the same dimension withθ.θtkdenotes probability of topickin documents at timet,andγtkcorresponds toθtkone to one.In the same way,βtkdenotes probability of wordwin topick,andλkwcorresponds toβkwone to one.ntwdenote the number of occurrences of the wordwin documents at timet.
Based on the above updating method,the gradients of each new sample can be related instead of being independent.Thus,the parameter update direction of each time depends on the gradient of the current data and is affected by the previous parameter update direction.Therefore,our online model is well suited to the drift data.

4.5 Feature Extraction and Matching Mechanism
To ensure the accuracy of static LDA-ID,we design a multi-topic selection and Word-Distribution-based matching mechanism.To ensure the efficiency of real-time detection,we propose a non-topic selection and corresponding Topic-Distribution-based matching mechanism.
4.5.1 Multi-Topic Selection and Word-Distribution-Based Matching Mechanism
The method of selecting only one topic for a document ignores other topics with slightly lower weights,resulting in lower detection performance.The sum of the weights of the Top-K topics almost covers the main components of the DTD matrix.However,the topicOverlapDegreewill rise,and the detection accuracy will drop,if you choose too many topics.Hence,for each document,we select the Top-K(K-unfixed)topics that are most appropriate.With the topic count being adjustable,we design a multi-topic selection technique for each document.According to Algorithm 2,we choose several topics for each document when the maximum weight is less thanτmaxor the difference of top-2 weights is less thanτinterval.We choose topics with weights no less thanτmin,until the sum of the weights is not less thanτsum.

We suggest a mechanism for matching multiple topics.Suppose that the topics chosen are:〈topick1,topick2,...,topickt〉.Ptopickisignifies the topicki’s weight.In order to create a feature for documentm,we reconstruct a new topic
A topic’s practical meaning is formed by a linear combination of words with varying weights and semantic associations.Eachtopickis associated with a word distributionβk.Thus,the documentmis characterized by the word distribution
We convert each record of test data (i.e.,sample)into words according to the data formatting method.We obtain a word distribution(βsample) by computing how many words a record has and how often each word occurs.The similarity between each document in theMdocuments and thesampleis determined using JS divergence.Lastly,the sample is assigned to the documentmwhich has the smallestvalue.
4.5.2 Non-Topic Selection and Topic-Distribution-Based Matching Mechanism
We classify the test sample from the perspective of topic distribution and classify the test data into the documentmwith the smallest similarityDJS(θm;θsample),whereθmis used as the feature for documentm(intrusion type ofm).
According to the Figure 6,Topic distribution variableθonly depends on variational parametersγ,So we need to obtainγupdated based on the new samples.Based on the results of the trained variational parameterλ,the variational parameter inference ofγcan be made directly,and the corresponding inference update is shown in Eq.(13).
whereγskandφsωkiteratively updated untilγskconverges,Ψ denotes the digamma function,nsωdenotes the number of occurrences of the wordωin documents,whenγskconverges,we can get topic distributionq(θs|γsk)(i.e.θsample)of the new sample.
In this method,we do not select topics for each document but directly use the topic distribution as the feature of each document.This method does not require feature selection and set the hyper-parameters(i.e.τsum,τmax,τminandτinterval).Thus,it is more convenient and much suitable for real-time detection.
V.EXPERIMENT AND EVALUATION
This section demonstrates the performance of the LDA-ID framework.We evaluate the effectiveness of our framework from the following aspects:
1.DetectionperformanceoftheLDA-IDframework: We compare the overall detection performance of our LDA-ID framework with previous intrusion detection models.
2.EffectivenessoftheonlineLDA-IDmodel: We compare the detection accuracy and training time of the online LDA-ID with the static LDA-ID.
3.Availabilityofthetopicoverlapdegreeanddispersiondegree: We compare these two metrics with the mainstream perplexity method to determine the best number of topics.
4.Efficiencyofdifferenttopicselectionandmatchingmethods: We compare the detection performance of the Word-Distribution-based and Topic-Distribution-based matching mechanisms.
5.Effectivenessofdataformatting: We compare the detection performance of our data formatting and existing methods
5.1 Datasets and Metrics Description
The public NSL-KDD [32] and UNSW-NB15 [33]datasets were used to evaluate our framework.Table 3 and Table 4 respectively show the value distribution of different types of attacks on the two datasets.The NSL-KDD dataset contains one type of normal network flow data and four types of attack data.Each sample contains a 41-dimensional attribute and a class label.The UNSW-NB15 dataset contains one type of normal data and nine types of typical attack data.Each sample contains a 42-dimensional attribute and a class label.
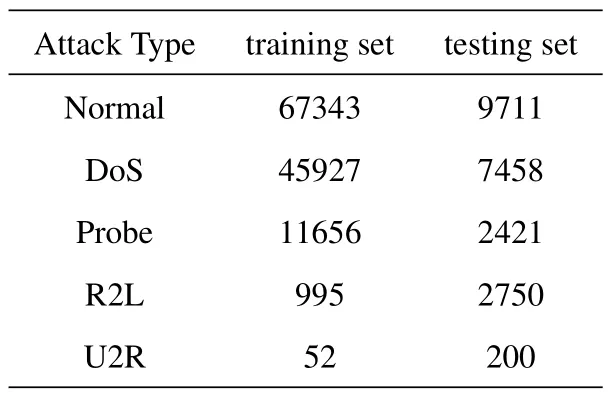
Table 3.The NLS-KDD dataset value distribution.
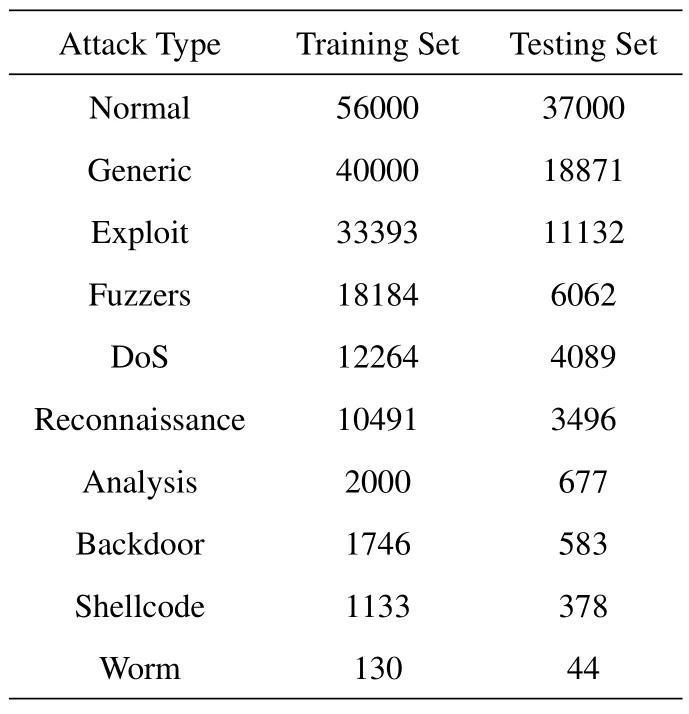
Table 4.The UNSW-NB15 dataset value distribution.
In this work,Accuracy (ACC),F1-measure (F1),false-negative rate (FNR),and false-positive rate(FPR) were used to quantify detection performance.We used a Windows 10 machine with an Intel Core i5-7500 CPU and 32 GB RAM to deploy our proposed framework.
5.2 Overall Detection Performance of LDA-ID
This section describes the overall performance of LDA-ID and the previous models(i.e.,K-means,support vector machine (SVM),Random Forest (RF),Bayes Network(BN),Convolutional Neural Networks(CNN),and Deep Learning Network (DNN)).At thedata formatting stage,each attribute was divided into several segments.Finally,we got 151 and 278 segments for the NSL-KDD and UNSW-NB15 datasets,respectively.When generating the DTD,we set hyperparametersα,ηto 0.01 to favor the unique topic in each document and adjusted amount of iterations to 5000.
The example of generated DTD matrix for different intrusions in the NSL-KDD dataset is shown in Figure 2.We can see that the topic distributions in various attacks are quite different.Thus,it is conducive to extracting unique features for each intrusion.The experimental results on the NSL-KDD and UNSW-NB15 datasets are shown in Tables 5 and 6,respectively.
In the NSL-KDD dataset,the ACC and F1 of the LDA-ID are higher than the other models.Compared with the previous models,our model improves the ACC by 1.85%.Meanwhile,the FNR in our LDA-ID model is much lower than the other models.Althoughthe FPR in our model is higher than those in the BN and RF models,their ACCs are much lower than those of our model.
In the UNSW-NB15 dataset,the ACC and F1 of the LDA-ID are also higher than the others.Compared with the existing models,our ACC is improved by 1.29%.Our model has a lower FNR and FPR than the competing models.The experimental results on the NSL-KDD and UNSW-NB15 datasets illustrate the advantages of our LDA-ID framework.
5.3 Effectiveness of Online LDA-ID
We conduct two experiments to evaluate the effectiveness of the online LDA-ID.Firstly,we test the accuracy of static LDA-ID and online LDA-ID when the same number of documents with distribution drift were observed.We sample 12 batches from the train set of NSL-KDD,and each batch draws 3000 samples.To construct the drift data,we set different sampling ranges for each batch as shown in Figure 7.
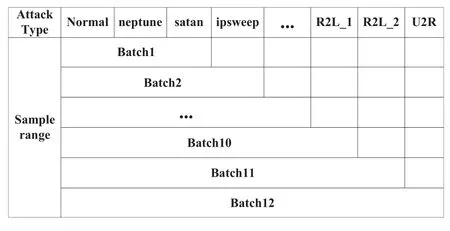
Figure 7.Drift data obtained from sampling at different ranges.
The sampling range of each batch is one more category than that of the previous batch,and the additional category with fewer than 1000 is sampled in priority.The train set of NSL-KDD includes four major categories with 22 attacks,and we combine it into 14 categories by merging some classes with too few numbers.The R2L category is evenly divided into two parts,R2L_1 and R2L_2.As the data grows,the distribution of each type of intrusion evolves.Thus,we input these 12 batches into the model successively to simulate the online scene of the drift data.We ran online LDA-ID withµ=0.5,τ0=200,and the number of documents processed at timetis set to 200.The higher the accuracy,the faster the convergence of the model is.Figure 8 shows that the online LDA-ID converges much faster than the static one does.The results also support the reasonableness of deploying online LDAID on the client side.
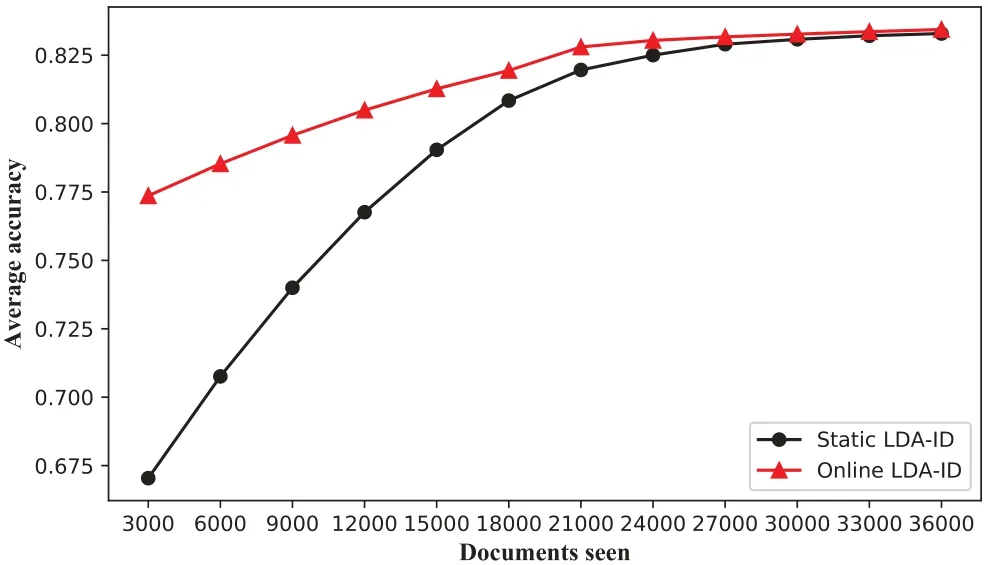
Figure 8.Accuracy on the drift data as a function of number of documents analyzed.
Secondly,we test the effectiveness of incremental calculation of online LDA-ID under different incremental data proportions.We construct the training set of NSL-KDD into 40,000 documents (R=52,Each type of intrusion constructs 8000 documents) in the data formatting stage,and we randomly divide those documents into two parts randomly and evenly.The first 20000 documents,called the prior data,are used to train the initial model,just as the online LDA-ID is initialized by the global parameters obtained by the static model.The remaining 20,000 samples are divided evenly into ten pieces to input to the model successively.The random equalization of data ensures that there is little data drift in incremental processing.We conduct online LDA-ID withµ=0.7,τ0=100,and the number of documents processed at timetis set to 200,and ran static LDA-ID withiterations=2000.
We simulate the scenario of incremental computing.Figure 9 shows the performance and elapsed time of the online LDA-ID at different ratios of incremental data to prior data.Online LDA-ID is demonstrated dramatically faster than and as accurate as the static one.More specifically,when the ratio is below 80%,online LDA-ID has a more stable performance advantage.However,when the ratio is over 80%,the performance declines may be due to overfitting.In terms of training time,online LDA-ID takes an order of magnitude less time than static LDA-ID.
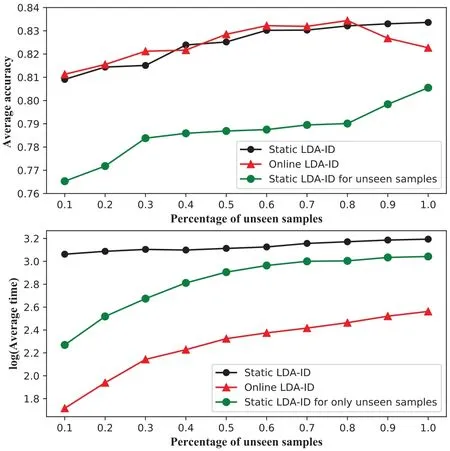
Figure 9.Effectiveness of incremental calculation of online LDA-ID under different incremental data proportions. The horizontal axis represents the ratio of newly added data to prior data. Static LDA-ID represents the retraining model with the set of prior data and newly added data,while the green line denotes the training model with only newly added data.
5.4 Availability of Topic Overlap Degree and Dispersion Degree
We plot the actual curves of various topic numbers in order to confirm the availability of topic Overlap degree and Dispersion degree.The NSL-KDD dataset only contains five different types of network flow data,so when the topic number is too high,the topic weight becomes more dispersed.So,as illustrated in Figure 10(a),we depict those two curves with topic numbers ranging from 5 to 50.Unfortunately,in practice,the topic weight is too dispersed when the topic count exceeds 40.Some samples’maximum weight is less than 0.3,which leads to lower accuracy.As a result,the optimal topic number cannot exceed 40.Meanwhile,the higher the Dispersion Degree and the lower the topic Overlap Degree,the better the testing effect.The Top-5 ideal topic number,as determined by the Overlap Degree curve,is[8,39,25,20,12],while the Dispersion Degree curve indicates that[8,20,39,26,23]is the Top-5 ideal topic number.Hence,“8”is found to be the most advantageous topic number.
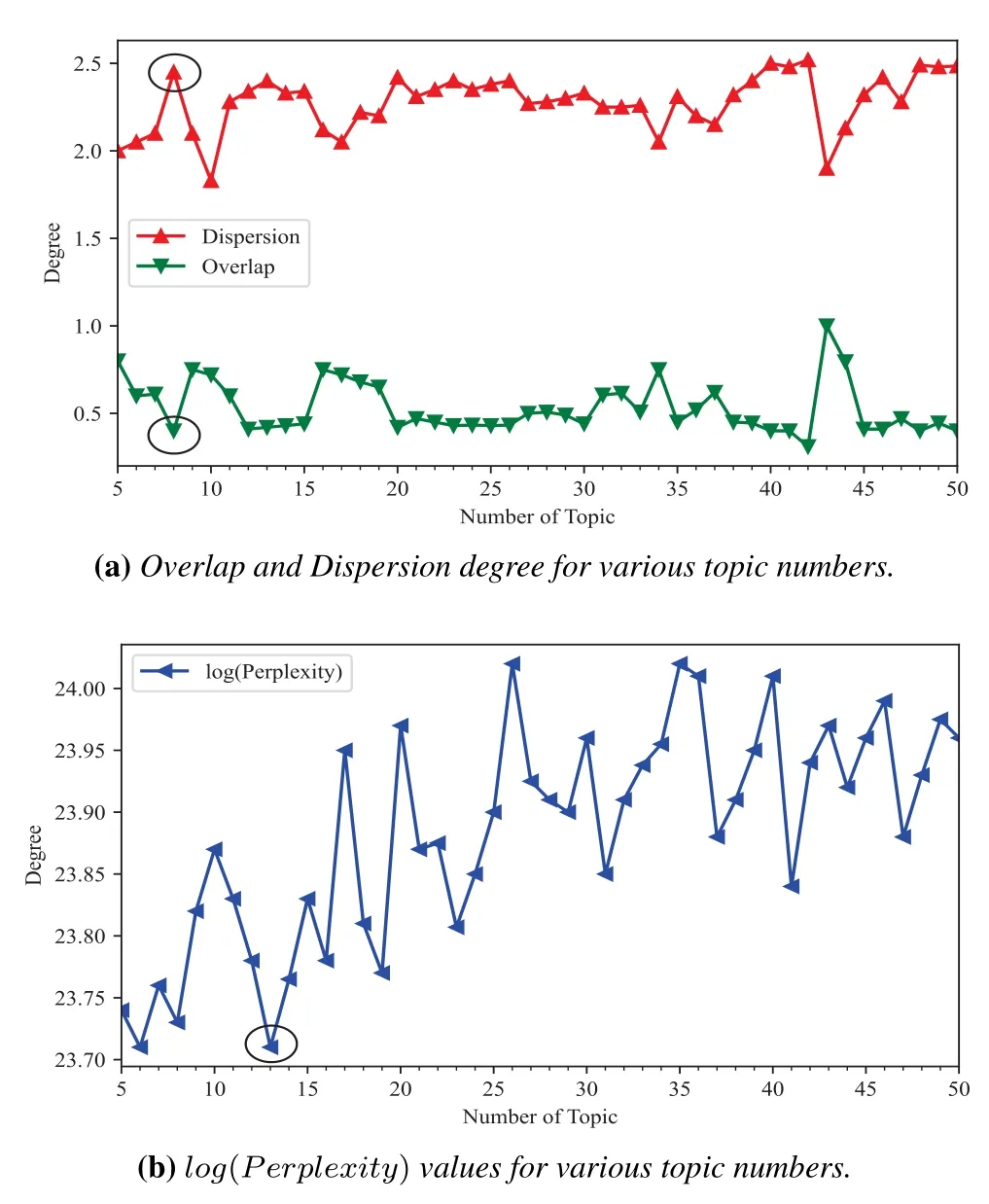
Figure 10.Selection of the optimal number of topics based on two evaluation metrics.
The optimal topic number is commonly determined using thePerplexitydegree(see Eq.(14))in the current method [7].The symbolwmrepresents a word in the test documentm,and the symbolNmrepresents words’count in the test documentm.The lower the Perplexity level,the greater the effect.The Top-5 optimal topic number is[13,6,8,5,7]based on the log(Perplexity)curse(see Figure 10(b)).As a result,“13”is determined to be the best topic number.
We test the accuracy with various topic counts.Figure 11 shows that when the topic number is“8”rather than “13”,the accuracy is at its highest level.The topic Overlap degree and Dispersion degree indicators hence outperform Perplexity in terms of effectiveness.The outcomes of the experiment support the viability of our approach.
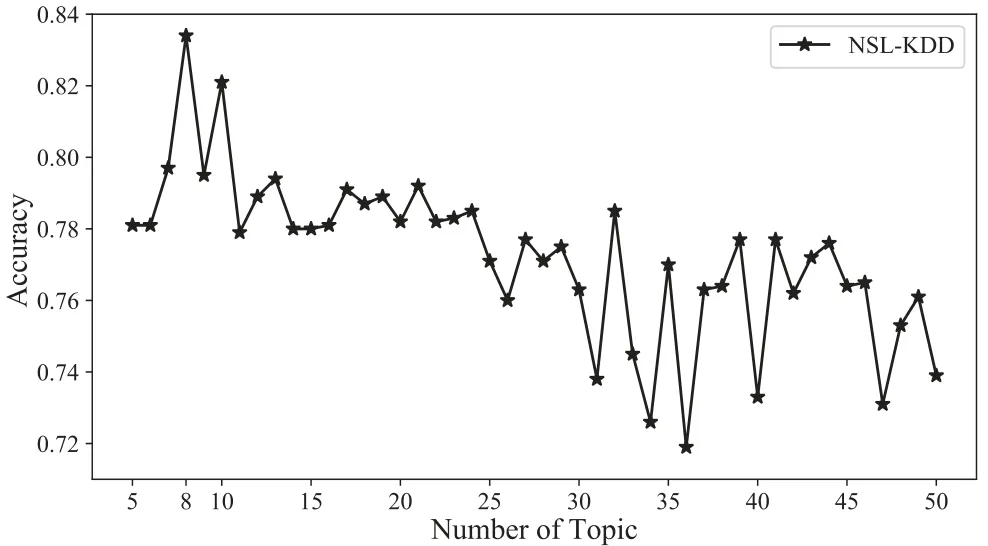
Figure 11.Accuracy of different topic numbers.
5.5 Efficiency of Different Topic Selections and Matching Methods
5.5.1 Effectiveness of the Multi-Topic Selection and Word-Distribution-Based Matching Mechanism
In this section,we test the impact of different topic selection algorithms on accuracy using Word-Distribution-based matching mechanism on NSLKDD dataset.The total weight of the top-4 topics makes up a significant chunk,so we evaluate the accuracy of the Top-1 and Top-4 topic selections.We chose 0.6 as the highest weight threshold reference the literature[16]and drop the topics with a weight of less than 0.1.During the experiment,multiple topics are chosen when the Top-1 topic weight is less than 0.6 until the cumulative weight is greater than 0.8.The effect of Top-1,Top-K (K=4),and multi-topic selection on accuracy is depicted in Figure 12.The Top-1 topic selection approach is clearly much worse to the others as can be seen.In most topic numbers,especially when the topic number is small,our multi-topic method outperforms the Top-K(K fixed)method.Also,the multitopic selection resembles the Top-K selection when the number of topics is large.
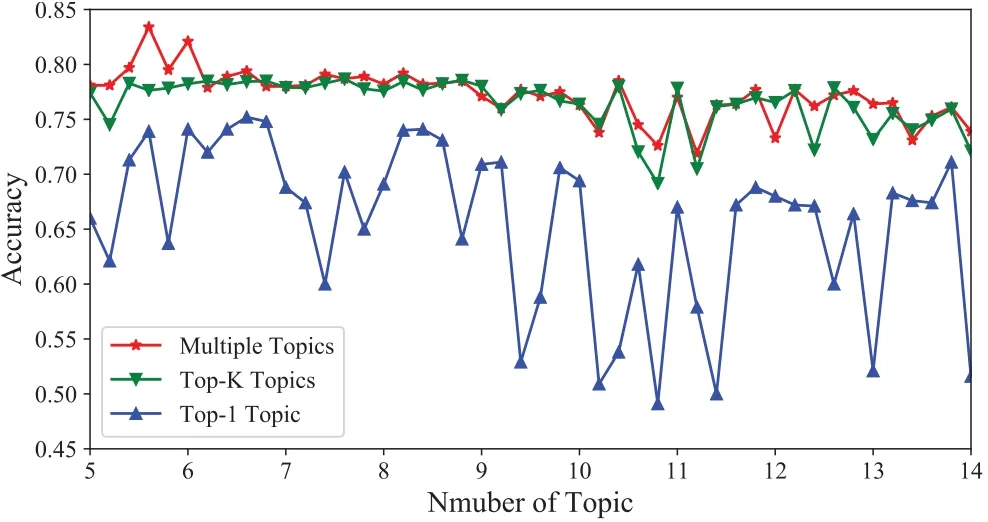
Figure 12.Accuracy of different topic selections.
5.5.2 Convenience of the Non-Topic Selection and
Topic-Distribution-Based Matching Mechanism This section presents the Non-topic selection and Topic-Distribution-based(TD)matching mechanism’s convenience,compared with the multi-topic selection and Word-Distribution-based (WD) matching mechanism.The experimental results are shown in Table 7.Although the accuracy of the WD method is higher than those of the TD method on the NSL-KDD and UNSW-NB15 datasets,the TD method is much more convenient.The TD method does not require topic selection and therefore does not require hyperparameters(e.g.τsum,τmax,τmin,andτinterval),which varies greatly in different conditions.Moreover,the accuracy of the TD method also maintains a higher value.And it is also higher than the other models in Table 5 and Table 6.
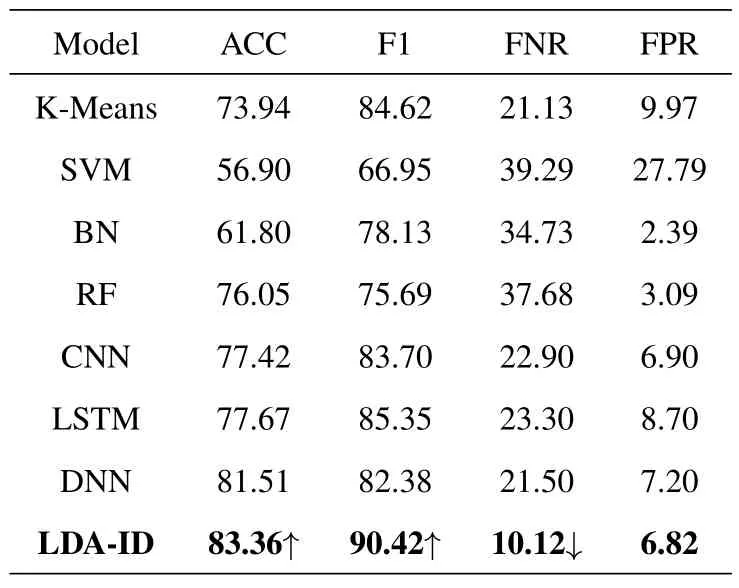
Table 5.The average performance (%) of different detection methods for multi-classification on the NSL-KDD dataset[34].
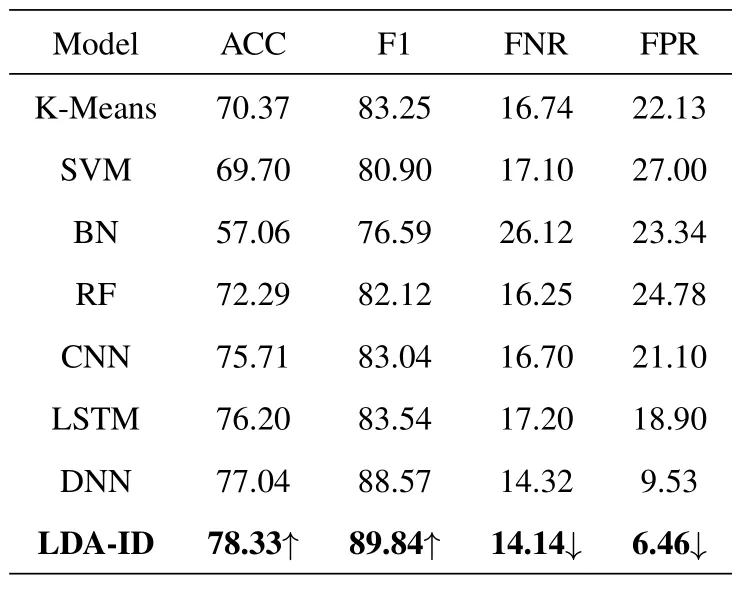
Table 6.The average performance (%) of different detection methods for multi-classification on the UNSW-NB15 dataset.
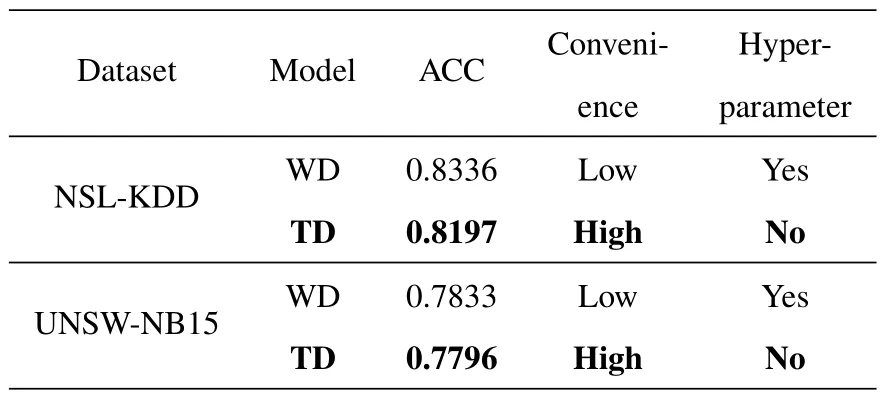
Table 7.Comparison of the Word-Distribution-based(WD)and Topic-Distribution-based(TD)matching mechanisms.
5.6 Effectiveness of Data Formatting
This section tests the effectiveness of the sentencelevel representation and document-level representation in the data formatting stage on the NSL-KDD (a document consists of 52 sentences)and UNSW-NB15(a document consists of 200 sentences),respectively.In Table 8,the detection accuracy of the document-level representation is much higher than the sentencelevel representation both on the static and online LDAID methods.The experimental results verify the disadvantage of the LDA model in processing short texts and confirm the effectiveness of the text aggregation strategy proposed in this paper.
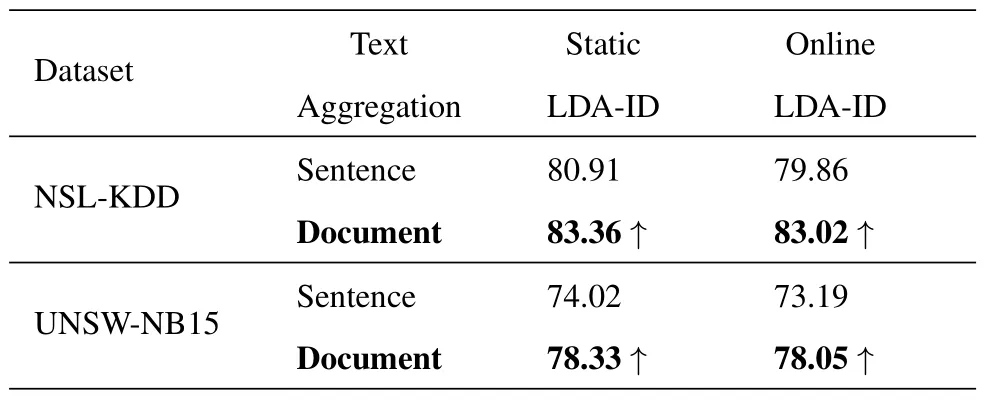
Table 8.The average detection accuracy (%) of the sentence and document aggregation strategies.
VI.CONCLUSION
In this paper,we propose a novel LDA-ID framework that can mitigate feature overlap and deal with realtime detection.For the feature overlap problem,we reframe the intrusion detection issue as one of selecting the LDA model’s ideal topic number.To assess the quality of the DTD and than choose the ideal topic count,we suggest using the topic Overlap Degree and Dispersion Degree.Additionally,in order to extract the particular characteristic for each intrusion,we build a topic reconstruction mechanism and a more adaptable multi-topic selection approach.For the real-time detection problem,we propose the online LDA-ID model to avoid retraining using the total data every time new data is coming.It makes full use of the parameters by the previous model training for tine-tuning,which can improve the computing efficiency in the face of stationary data and improve the real-time detection performance facing the drift data.The proposed non-topic selection and corresponding Topic-Distribution-based matching mechanism are much suitable for real-time detection.To evaluate the effectiveness and robustness of our LDAID framework,we carry on a series of experiments on the public NSL-KDD and UNSW-NB15 datasets.The experimental results prove that our LDA-ID framework outperforms the previous models in terms of detection accuracy.
ACKNOWLEDGEMENT
Weidong Zhou and Shengwei Lei contributed equally to this work.This work was supported by the National Natural Science Foundation of China (Grant No.U1636208,No.61862008,No.61902013) and the Beihang Youth Top Talent Support Program (Grant No.YWF-21-BJJ-1039).

- China Communications的其它文章
- IoV and Blockchain-Enabled Driving Guidance Strategy in Complex Traffic Environment
- Multi-Objective Optimization for NOMA-Based Mobile Edge Computing Offloading by Maximizing System Utility
- A Privacy-Preserving Federated Learning Algorithm for Intelligent Inspection in Pumped Storage Power Station
- Secure Short-Packet Transmission in Uplink Massive MU-MIMO Assisted URLLC Under Imperfect CSI
- Multi-Source Underwater DOA Estimation Using PSO-BP Neural Network Based on High-Order Cumulant Optimization
- An Efficient Federated Learning Framework Deployed in Resource-Constrained IoV:User Selection and Learning Time Optimization Schemes