
Deep Reinforcement Learning for IRS-Assisted UAV Covert Communications
2023-12-10 11:37SongjiaoBiLangtaoHuQuanjinLiuJianlanWuRuiYangLeiWu
China Communications 2023年12期
Songjiao Bi ,Langtao Hu ,Quanjin Liu ,Jianlan Wu ,Rui Yang ,Lei Wu
1 School of Electronic Engineering and Intelligent Manufacturing,Anqing Normal University,Anqing 246133,China
2 School of Computer and Information Engineering,Fuyang Normal University,Fuyang 236037,China
Abstract: Covert communications can hide the existence of a transmission from the transmitter to receiver.This paper considers an intelligent reflecting surface (IRS) assisted unmanned aerial vehicle(UAV)covert communication system.It was inspired by the high-dimensional data processing and decisionmaking capabilities of the deep reinforcement learning (DRL) algorithm.In order to improve the covert communication performance,an UAV 3D trajectory and IRS phase optimization algorithm based on double deep Q network(TAP-DDQN)is proposed.The simulations show that TAP-DDQN can significantly improve the covert performance of the IRS-assisted UAV covert communication system,compared with benchmark solutions.
Keywords: covert communication;deep reinforcement learning;intelligent reflective surface;UAV
I.INTRODUCTION
With the increasing attention to the security of wireless communication,protecting user privacy becomes progressively challenging.An emerging and cuttingedge covert communication technology,also known as low probability of detection communication,which ensures that the detection probability of the warden can be ignored.Compared to existing encryption technologies and physical layer security that cannot mitigate privacy problems by detecting the presence of the legitimate transmissions [1],covert communication preserves a higher level security and privacy [2–6].
Because of its controllable mobility and on-demand deployment,UAV has emerged to the public and often used in the military [7–13],more attention has been paid to covert communication.The performance of UAV’s communication system is still restricted by the limited service duration and lack of communication link servers [14].In response to the above problems,IRS can enhance signal power.In addition,IRS can be easily installed on the walls and ceilings of buildings,which involves little complexity[15].IRS technology has been widely used in UAV communications system[16–22].In[21],the authors propose an IRSassisted RL based secure WBAN transmission scheme that enables coordinators to jointly optimize the sensor encryption key and transmit power,as well as the IRS phase shift,to prevent active eavesdropping.IRS technology has been broadly studied in covert communication systems[7,23,24]and the covert performance has been greatly improved.In [7],the performance gain was improved by jointly designing the transmit power and IRS reflection coefficients,and the authors developed a penalized successive convex approximation algorithm to solve this design problem.In[23],the covert energy efficiency maximization problem was formulated by jointly optimizing power control,passive beam formation,and UAV trajectory.The authors in[24]proposed an IRS based approach to improve the communication covertness,the key idea is to use an intelligently controlled metasurface to reshape undesirable communication conditions that could reveal covert information.
UAV 3D placement is designed in UAV covert communications [25],maximize system covert performance under covert constraints by jointly optimizing the 3D trajectory and transmit power of the UAV.In[26],trajectory and resource allocation are jointly optimized using method successive convex approximation (SCA) in UAV covert communications,and the trajectory of UAV is optimized on 2D horizontal plane.These optimization schemes have high complexity and are difficult to deploy in the actual system,because the state of UAV system always changes dynamically.Against this problem,in recent years,artificial intelligence(AI)technology has been successfully applied to wireless communication network [27–32].DRL is one core machine learning tool of AI.The agent in DRL can learn intelligently from the high dynamic and complex wireless environment,and make smart decisions in real-time.DRL can solve complex problems with non-convex characteristics in modern networks,and obtain the optimal solution without complete and accurate network information.
In a nutshell,this paper studies the optimization of the UAV 3D trajectory and the IRS phase based the DRL algorithm.UAV for the purpose to find the optimal 3D trajectory to maximize the covert transmission rate of the system while satisfying the covertness constraint.The simulations show that our proposal can achieve the higher covert performance and satisfy the covert constraint,which verifies the feasibility of our proposed scheme.
II.SYSTEM MODEL
2.1 Channel Model
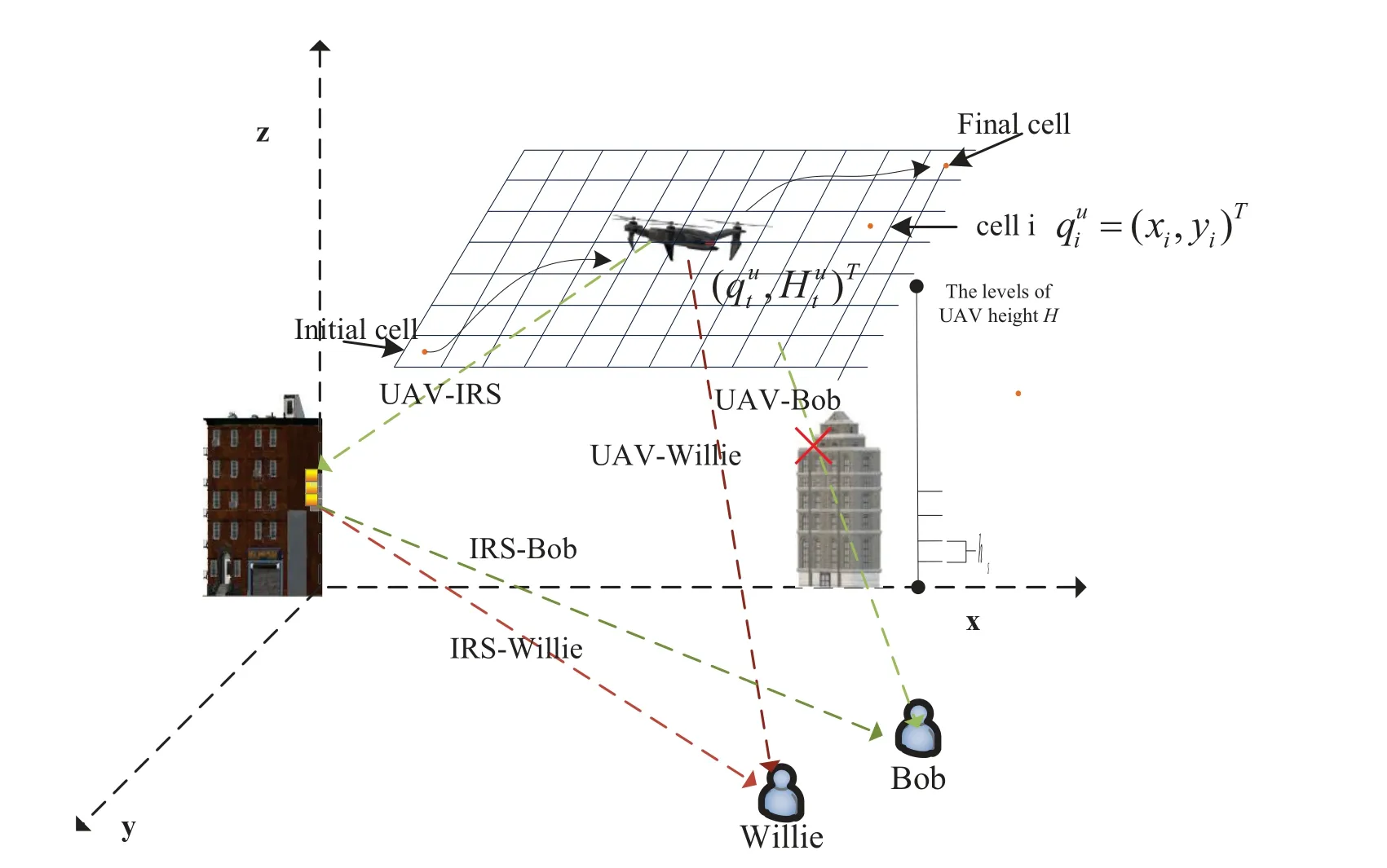
Figure 1.IRS-assisted UAV covert communication system.
wherePis the transmission power of the UAV.Bis the channel bandwidth,andare the noise variance of them-th user and Willie respectively.
To evaluate the possibility of direct connections between the UAV and Willie and between the UAV and userm.We have considered an air-to-ground channel model for the urban environment of[33].In time slott,pwt,pmtrepresents the blocking probabilities between the UAV and Willie and between the UAV and usermrespectively,which are shown as,
2.2 Willie’s Binary Hypothesis
For covert communication,Willie determines whether Alice and Bob are communicating by means of energy detection based on the basic theory of signal detection.The energy detector is the optimal detector,and the detection method can be abstracted into a binary hypothesis test,
yw[i] represents the signal received by thei-th channel at Willie.The channel signal transmitted by UAV is defined ass(i),∀i∈[1,2,...,L],wheres(i)∈CN(0,1).Lis the number of delay by the covert communication channels constrained.H0represents the null hypothesis meaning that the UAV does not send messages to the user,andH1represents the alternative hypothesis meaning that the UAV transmits the message to the user.nw[i]~CN(0,is the noise variances at Willie.
D0andD1can be thought of as a binary decision in favor ofH0andH1.Willie’s false alarm probability and missed detection probability are denoted asPF[t]=P(D1||H0),PM[t]=P(D0||H1) respectively.The total detection error probability isζ[t]andζ[t]=PF[t]+PM[t].The goal of UAV is to make Willie’s total error probabilityζ[t]in each slot close to 1,
where 0≤ε≤1.According to the requirement of covert communication,εis a sufficiently small positive value.
In covert communication system,Willie wants to minimize the total detection error probabilityζ[t] so that it can judge if the transmission exists.The optimal test to minimizeζ[t] is the likelihood ratio test,which is expressed by the following formula(10)[7],
D(P0‖P1) is the KL-divergence ofP0andP1,expressed as[7],
In a covert communication system,D(P0‖P1)≤2ε2is a stricter constraint thanζ*[t]≥1-ε,whereεis a sufficiently small value to determine the degree of hidden constraints of the system.D(P0‖P1)≤2ε2is used as the system’s covert communication constraints[34].
2.3 Transmission From UAV to m-th User
The corresponding SINR atm-th user is given by,
the first part is the signal received bym-th user through the IRS when the UAV direct link is blocked,and the second part is the signal received bym-th user without UAV obstruction.Then the achievable rate of them-th user in time slottis expressed asRmt[34],
wherecmt∈{0,1}indicates if information is transmitted to them-th user in time slott.
(15b) indicates the covert performance constraints;(15c) denotes the user scheduling in the time slott;(15d)represents the total transmission task constraint;(15e) and (15f) respectively represent the UAV horizontal speed and vertical speed constraints;(15g)represents the UAV flight height constraint;(15h) represents the flight time constraint of each time slot.
III.DEEP REINFORCEMENT LEARNING ALGORITHM DESIGN
In this paper,we use reinforcement learning algorithm based on discrete-time Markov Decision Process(MDP),which maximizes the cumulative reward obtained in a limited action and state space.In this section,the TAP-DDQN algorithm is designed based on the DDQN algorithm.First of all,the optimal phase shift is calculated,and then the main elements of MDP are introduced.The IRS-assisted UAV covert communication DDQN network structure is shown in Figure 2.
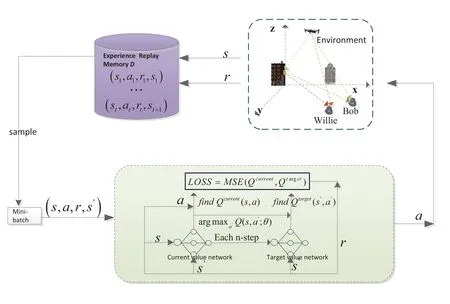
Figure 2.IRS-assisted UAV covert communication system network structure.
3.1 Phase Shift of IRS
The phase shift can be optimized in the IRS-assisted UAV covert communication system.In time slott,when UAV transmits signal to them-th user,is expressed as[35],
In order to maximize the covert rate available for them-th user,we obtain,
which means the phase alignment of the signal is realized at them-th user.can be expressed as,
3.2 TAP-DDQN Algorithm Design
In this task,the agent is the UAV,the action space includes locations,flight time of the UAV and user scheduling,the state is the current position of the UAV,and the reward is based on the legitimate user’s signal under the satisfaction of the concealment constraint.The agent(i.e.,the UAV)can obtain state information from the environment,make autonomous decisions,and generate optimal actions.
Usually MDP is defined as four-tuple{S,A,R,γ},and the necessary elements are designed as follows.
S:Srepresents the set of agent states.represents the state of the agent in time slottand∈S.It is determined by the coordinates of the current UAV,namely
The horizontal position of the UAV when it moves to the next slot can be expressed as
whereqt∈qqqu≜{(xu,0),(-xu,0),(0,yu),(0,-yu),(0,0)}indicates that the UAV moves east,west,north,or south,or remains in the current position respectively.For the vertical position of the UAV in the next slot,it is
whereht∈HHHu≜{hu,-hu,0}and it indicates that the UAV rises,falls,or remains at the current location.
whereD(P0||P1)-2ε2is the covertness level constraint.k1andk2are reward function multipliers.
γ:γis the discount factor used to balance current rewards with future rewards,whereγ∈(0,1],and the value is adjusted according to the specific situation at the time of the experiment.In this paper,we take 0.9.
We propose an algorithm based on DDQN to optimize the trajectory of UAV.If the UAV flies out of the service area or exceeds the maximum flight time,the agent will be punished accordingly to constrain the agent for communicating better.The generated samplesare stored in the experience replay memory.
IV.NUMERICAL RESULTS
This section verifies the numerical results of the proposed TAP-DDQN algorithm through simulation,and compares the numerical results with the system without IRS-assisted and the IRS-assisted system with random phase shift.

UAV flies within the given area of service,andmusers are randomly assigned to the service area assigned to UAV.=[0,0]T,qqqR=[500,500]T,hR=50,qqqw=[700,420]T,d=L=100 [7].The simulation setting is shown in Table 1.
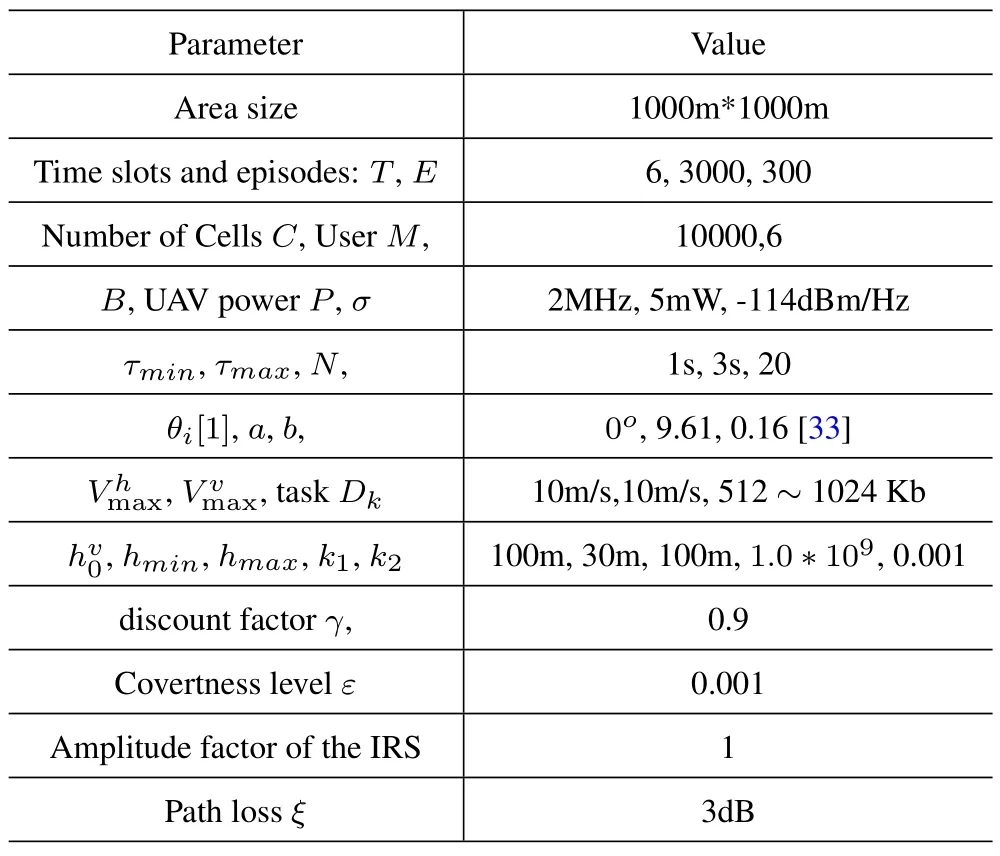
Table 1.Parameter setting on simulation.
In the proposed TAP-DDQN algorithm,the neural networks are considered to be a two-layer deep neural network,the hidden layer having 20 neurons and the activation function as the Relu function.Each episode contains 3000 time slots.RMSProp optimizer is used to train deep neural networks.The action space can beobtained asanum,whereanum.In this algorithm,the three-dimensional coordinates of the UAV are used as the input layer,and the number of elements is 3.The number of neurons in the hidden layer is 20,the output layer is the number of actions (anum),and the calculation amount of one training is 3×20+20×anum.Then the overall complexity isO(E×T×(3×20+20×anum),whereErepresents the number of episodes,andTrepresents a episode the number of training steps.The training complexity of the proposed algorithm is high,but once the reinforcement learning is trained and the prediction is made,the complexity of the algorithm is very small.
Figure 3 shows the cumulative distribution function (CDF) of the Bob’s signal power of the four schemes in TAP-DDQN and DQN algorithms.The signal power of the four schemes all show an increasing trend,however,the IRS-assisted UAV scheme proposed achieves the higher signal power.The optimization effect of DDQN is compared with DQN(DQN_IRS) can be seen from Figure 4,the algorithm framework in this paper overcomes the problem of high Q value of DQN by separating the selected actions from the target Q value generator,and thus obtains better optimal rewards than DQN.In Figure 4,as the number of iterations increases,the reward function gradually converges.From Figure 3 and Figure 4,we can easily observe that the proposed TAP-DDQN algorithm(DDQN_IRS)can achieve the highest value,followed by the value based on the DQN algorithm.In terms of random phase shift(DDQN_IRS random),IRS can significantly improve the covert performance after the phase shift is optimized.As for the system that does not deploy IRS (DDQN_without IRS),the covert performance is the worst.
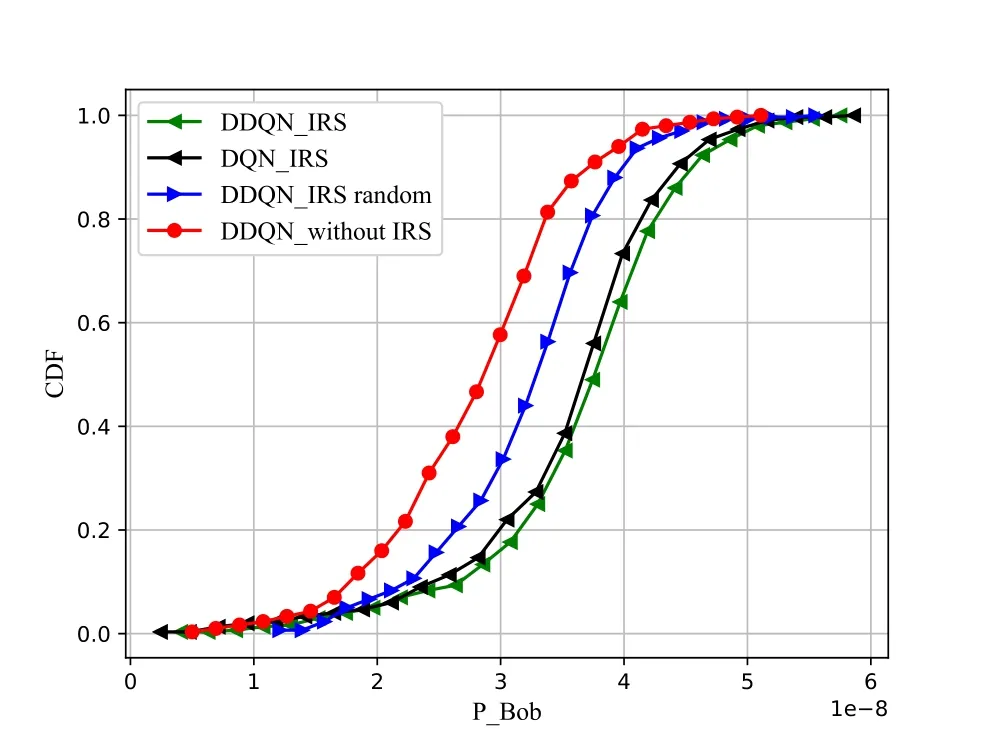
Figure 3.The CDF of Bob’s signal power under four schemes.
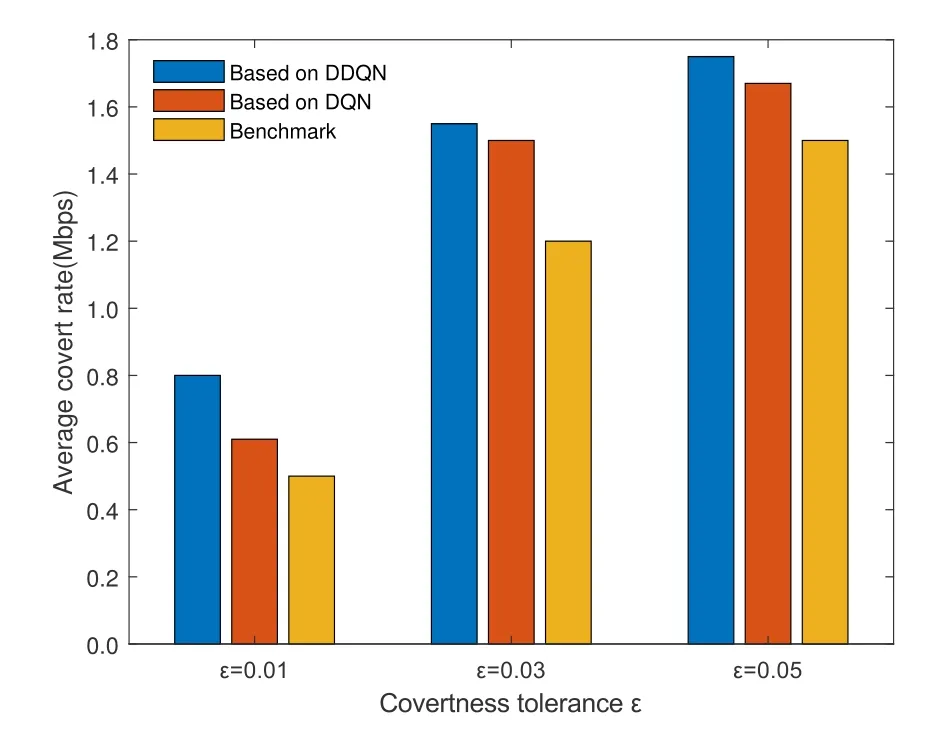
Figure 5.Average covert rate versus ε.
We compare with the benchmark algorithm[26],in which the authors maximize the average covert rate of the system based on the iterative algorithm of the block coordinate descent method with the height of the UAV fixed at H=100 m.In order to keep the parameters consistent with the literature [26],we optimize the 2D trajectory of the UAV and fix the height of the UAV to 100m.Figure 6 compares the changes of the average covert rate of the system for different covert constraints of the three algorithms.From the figure,it can be seen that the average covert rate of the system gradually increases with the increase of the covert constraint factor.The three algorithms are DDQN-based algorithm,DQN-based algorithm and benchmark algorithm,and it can be seen that the average covert rate obtained by the DDQN-based algorithm is the largest in the three cases,followed by the DQN-based one,and the average covert rate value obtained by the benchmark algorithm is the smallest,which shows that the algorithm based on deep reinforcement learning is higher than the benchmark-based algorithm,which verifies the feasibility of our scheme.
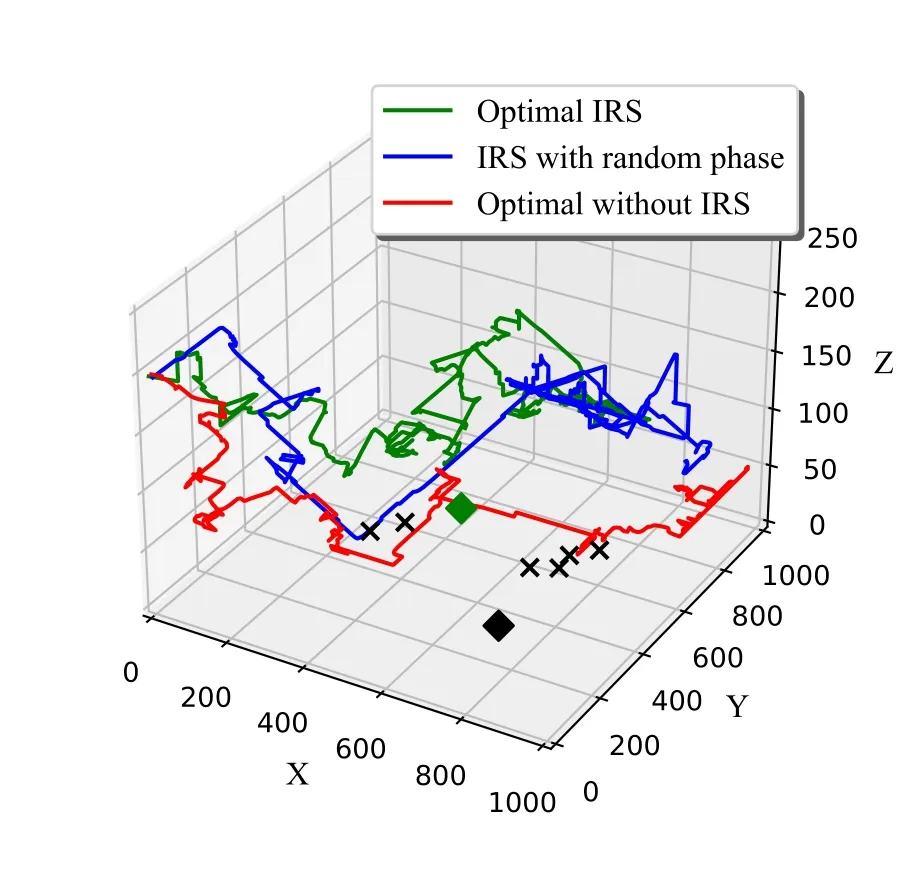
Figure 6.The 3D trajectory diagram of UAV.
Keeping UAV away from Willie as much as possible during communication is for the purpose to reduce the probability of legitimate user transmissions to be discovered by Willie.The IRS-assisted UAV scheme proposed in this paper is compared with the IRS using random phase shift and the system without IRS.Figure 6 and Figure 7 show the 3D trajectories of UAV flight and the 2D planes respectively,where IRS and Willie are indicated in green and black diamonds,respectively.It can be seen that the UAV without IRS is closer to Willie,which obviously leads to the information exposure and the IRS-assisted UAV solution satisfies the covertness services required by users.This verifies the feasibility of our proposal.
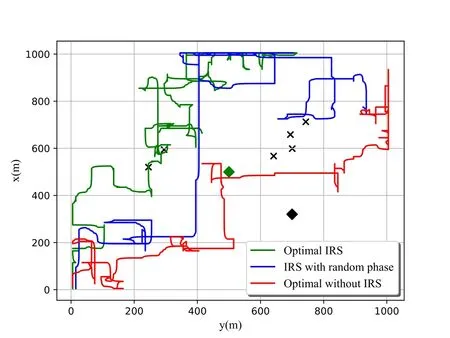
Figure 7.The 2D floor plan of UAV.
V.CONCLUSION
In order to improve the covert rate of the IRS-assisted UAV wireless communication system,this paper proposes the TAP-DDQN algorithm for the joint optimization of the UAV 3D trajectory and the phase shift of the IRS.The goal is that in the presence of Willie,the presence of the transmission from the transmitter to the transmitter can be hidden receiver to maximize the average covert rate.The simulation results show the TAP-DDQN can achieve the highest covert performance compared with the system using no IRS and the system with IRS but with no employment of the optimal passive phase shift.Future research work will focus on more complex covert communication scenarios,where multiple UAV control base stations are used to serve legitimate users and prevent UAV dynamic eavesdroppers.

- China Communications的其它文章
- IoV and Blockchain-Enabled Driving Guidance Strategy in Complex Traffic Environment
- LDA-ID:An LDA-Based Framework for Real-Time Network Intrusion Detection
- A Privacy-Preserving Federated Learning Algorithm for Intelligent Inspection in Pumped Storage Power Station
- Secure Short-Packet Transmission in Uplink Massive MU-MIMO Assisted URLLC Under Imperfect CSI
- Multi-Source Underwater DOA Estimation Using PSO-BP Neural Network Based on High-Order Cumulant Optimization
- An Efficient Federated Learning Framework Deployed in Resource-Constrained IoV:User Selection and Learning Time Optimization Schemes