
Radio Frequency Fingerprinting Identification Using Semi-Supervised Learning with Meta Labels
2023-12-10 11:36TiantianZhangPinyiRenDongyangXuZhanyiRen
China Communications 2023年12期
Tiantian Zhang ,Pinyi Ren,* ,Dongyang Xu ,Zhanyi Ren
1 School of Information and Communications Engineering,Xi’an Jiaotong University,Xi’an 710049,China
2 Shaanxi Smart Networks and Ubiquitous Access Research Center,Xi’an 710049,China
Abstract: Radio frequency fingerprinting(RFF)is a remarkable lightweight authentication scheme to support rapid and scalable identification in the internet of things (IoT) systems.Deep learning (DL) is a critical enabler of RFF identification by leveraging the hardware-level features.However,traditional supervised learning methods require huge labeled training samples.Therefore,how to establish a highperformance supervised learning model with few labels under practical application is still challenging.To address this issue,we in this paper propose a novel RFF semi-supervised learning(RFFSSL)model which can obtain a better performance with few meta labels.Specifically,the proposed RFFSSL model is constituted by a teacher-student network,in which the student network learns from the pseudo label predicted by the teacher.Then,the output of the student model will be exploited to improve the performance of teacher among the labeled data.Furthermore,a comprehensive evaluation on the accuracy is conducted.We derive about 50 GB real long-term evolution (LTE) mobile phone’s raw signal datasets,which is used to evaluate various models.Experimental results demonstrate that the proposed RFFSSL scheme can achieve up to 97% experimental testing accuracy over a noisy environment only with 10%labeled samples when training samples equal to 2700.
Keywords: meta labels;parameters optimization;physical-layer security;radio frequency fingerprinting;semi-supervised learning
I.INTRODUCTION
Recently,with the massive deployment of light lowpower smart devices in internet of things (IoT),all those devices are connected intensively to provide low-cost,anytime,and anywhere connectivity [1–6].Device authentication is the first step required to maintain the connectivity and done respectively through high-layer cryptographic or physical-layer authentication approaches [7–9].However,the cryptographic protocols work hard under massive connections and requirements of secure transmission due to the huge connection and computational overheads [10–12].Furthermore,physical-layer authentication usually can obtain a better trade-off between security transmission and overheads [13].As shown in Figure 1,our paper mainly focus on establishing a lightweight physical-layer authentication which is commonly realized by utilizing radio frequency fingerprinting(RFF)characteristics.One of the profound security challenges in physical-layer authentication is how to keep scalable and reliable with low overheads and few labels towards future 6G applications,such as industrial scenario,autonomous vehicles and edge computing[14].
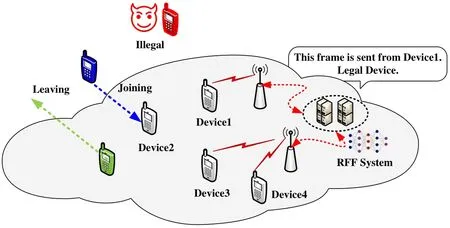
Figure 1.Typical architecture of deep learning-based RFF systems.
RFF identification is such an emerging technique by employing unique device-specific hardware-level features,such as phase noise,in-phase/quadrature(I/Q) imbalance,sampling offset,and harmonic distortions [15–18].In principle,the RFF characteristics,which are embedded in signal waveform and cannot be tampered,can provide desirable accuracy guarantee [19,20].Traditional RFF techniques always need huge computing resources.Therefore,with the deployment of massive intelligent devices,traditional approaches are no longer applicable[21].Deep learning(DL)has been involved in practical RFF identification application and able to exploit the features which can’t be extracted by traditional methods[22–24].Besides,various DL methods can employ the large scale non-linear neurons and achieve quick identification and high precision through the RFF [25–28].These existing RFF techniques based on DL are suitable for the steady-state scenario [29–31].The sampled time signal series are treated as the input of convolutional neural networks (CNNs) to train the network models[32].
In traditional supervised learning,all the training samples should contain true labels.However,the true labels of samples are often unavailable in practical applications.Another DL method named semisupervised learning(SSL)can utilize an amount of unlabeled and few labeled samples.It is a key component in the field of pattern recognition,speech and natural language processing.It can fully mine the distribution characteristics of training samples.Therefore,SSL attracts more attention from academia and industrial researches [33,34].However,there still exist several key challenges.
· Traditional supervised DL based RFF identification requires a large amount of true labeled samples to guarantee the accuracy performance[31].It is time-consuming to process labels in largescale datasets under practical applications.How to achieve a remarkable performance by utilizing few amount of labeled samples becomes an urgent problem in practical application[25,35].
· The hardware impairments in radio frequency(RF) circuit are usually complex and hard to extract.Traditional methods can’t fully extract the subtle RFF features efficiently.How to design a self-training network to fully extract the hidden subtle features from collected raw signal samples is a key challenge[36,37].
· Furthermore,duo to the distortion of channel,models always operate on the non-stationary data,some subtle features will be submerged by noise and multi paths which significantly decreases the identification accuracy under wireless channels [38].Therefore,it is critical to ensure the robustness of RFF identification accuracy in practical environment.
To address those issues above,we in this paper consider a novel semi-supervised learning method that only needs very few labeled samples and achieves state-of-the-art identification accuracy on the existing datasets compared to other baseline models [33,34].Specifically,the main technical contributions in this paper are organized as follows:
1) About 220 GB LTE E-UTRA test model (LTEETM) raw signal samples under Simulink platform are collected.The influence of channel distortion,model construction and training parameters are comprehensively evaluated among the simulation datasets.Results show that when the size of training samples is equal to 450,the identification accuracy at the lowest signal noise ratio(SNR)deteriorates about 18%under RFFResNet.With the increase of training samples,the impacts of channel distortion gradually decrease.
2) About 50 GB signal samples are collected from 30 mobile phones under practical application.Firstly,the anomaly detection is applied to find the corrupt transmission signal samples.Then,all the original frames are divided into sub-samples which contains 8192 discrete samples and labeled with the device ID.Furthermore,the complete datasets will be delivered to the elaborately designed model for RFF feature extraction.
3) A robust and efficient semi-supervised learning framework is proposed to classify massive devices with few labeled samples.Furthermore,the optimization of model structure and training parameters are evaluated.Results show how the optimization is done jointly through self-learning and achieve up to 97% identification accuracy while requiring merely about 10% labeled data under 2700 training samples.The remarkable performance is discussed in Section V.
The remainder of this paper is organized as follows.In Section II,the related works about RFF based on traditional methods and machine learning are discussed.The discussion of RFF system and the proposed RFF semi-supervised learning(RFFSSL)framework is presented in Section III.Datasets collection strategy and experimental setup is highlighted in Section IV.The experiment results and potential research fields are investigated in Section V.Finally,concluding remarks are drawn in Section VI.
II.RELATED WORKS
In recent years,RFF identification technologies have attracted extensive attentions from academic and industrial researchers[39].The main focus of early research on RFF was about how to extract the device statistics features [40].However,traditional schemes brought huge computational complexity and couldn’t guarantee the identification performance.Briket al.[1] combined the different independent traditional radio frequency features,such as carrier offsets,in-Phase quadrature (IQ) mismatch and transients to identify IEEE 802.11B cards.However,all those feature’s extraction requires extremely ideal transmission environment and signal quality.It can not be satisfied in practical situations and the 99% accuracy of ideal application is not always accessible.Nguyenetal.[2]proposed a novel method to extract the features by non-parametric Bayesian.They tested Gaussian mixture model and Gibbs sampling method both in simulation and experiments.Results show that such statistical methods rely on very precise assumptions of transmitter model.Xuetal.[21] provided a detailed survey of RFF and analyzed the shortcomings of existing methods.Dudczyketal.[40]presented a method to classify the radars by using graphical representation.Furthermore,a remarkable method by transforming and analyzing the basic feature’s distribution was investigated.Pengetal.[41] designed a hybrid and adaptive scheme which includes modulation,differential constellation trace figure,frequency offset and I/Q mismatch.Those characteristics are combined smartly with different weights.Results have shown that hybrid classification scheme performed well,and the features can be blended together to achieve the identification.
Recent works have confirmed that RFF identification accuracy can be improved significantly by utilizing remarkable DL framework in wireless system[22,42].Ferdowsietal.[43] proposed an efficient machine learning framework based on a long short-term memory(LSTM)which can extract stochastic features from collected signal.Result demonstrated that LSTM which is different from the traditional iterative calculation can be applied to extract the RFF feature.Gritsenkoetal.[44] proposed a novel method which can detect a new device without retraining model.The results confirmed that the strange devices can be identified through ingenious design of network models.Therefore,the model structure design is the guarantee of identification performance.Jianetal.[45] researched radio fingerprint scalability issues existing in amount devices and found that a deeper structure is not always better.Besides,removing channel by partial equalization does not always give better results.The reason is that the partial equalization may destroy the real radio fingerprint.This paper provided a new idea for RFF extraction in wireless communication and how to obtain real RFF features from noised signals is extremely important.Al-Shawabkaetal.[38]provided an evaluation of the identification accuracy among large-scale datasets obtained from 20 universal software radio peripheral(USRP)devices.Experiment results proved that how channel noise impacts the identification accuracy significantly on the defense advanced research projects agency(DARPA)datasets.
However,all the deep learning models above require numerous accurately labeled datasets,and can not avoid the impact of channel noise through adaptive learning.Pengetal.[46] proposed a novel RFF schemes by utilizing heat constellation trace figure and slice integration cooperation to improve the features extraction efficiency and robustness.This method confirmed that it can achieve efficient feature extraction through automatic learning and enhancement.Zhangetal.[47] focused on the RFF identification in a low signal-to-noise ratio(SNR)scenario through an adaptive filter.Experimental results demonstrated that the proposed scheme can achieve 99.91% identification accuracy and bring subtle impact on bit error rate.However,this scheme requires signal processing in transmitter side which limits the promotion of proposed scheme.
Arazoetal.[37] proposed an impressive machine learning method which learns features from unlabeled training samples by generating soft pseudo-labels by using pre-trained network predictions.However,this paper does not consider the problem of insufficient accuracy of the pre-trained network.Furthermore,the training framework’s complexity,robustness and extension of training datasets are not fully evaluated in practical application.Traditional supervised learning which cannot fully exploit the subtle distributed feature information hidden behind the raw wireless signal[22,23,48].Besides,an amount of labeled training data is required to guarantee the convergence of model.In this work,an efficient semi-supervised learning framework are established to achieve a remarkable identification accuracy with few labeled samples based on practical large-scale datasets.
III.SYSTEM MODEL AND SSL ARCHITECTURE ANALYSIS
3.1 System Model Description
As shown in Figure 2,there existsKuser equipments(UEs)and one receiver in RFF experiment system.For simplicity but without loss of generality,there is an assumption that RFF identification process arises before further processing of relevant signal.As shown in Figure 2a,the signals from each UE in baseband domain,after being IQ modulated,are converted to analog signals through several non-linear operations.Before the final transmission,band-pass filter,variable gain amplifier (VGA) and high-power amplifier(HPA) are the necessary modules for signal processing.At the receiver side,the wireless signal will be further processed by a series of modules such as RF band-select filter,low-noise amplifier(LNA),and analog to digital convert (ADC).As we can see,all the non-linear characteristics caused by different modules form the unique features of device.The collected RF data consists of real signal samples,which are selected and exploited for deep learning.
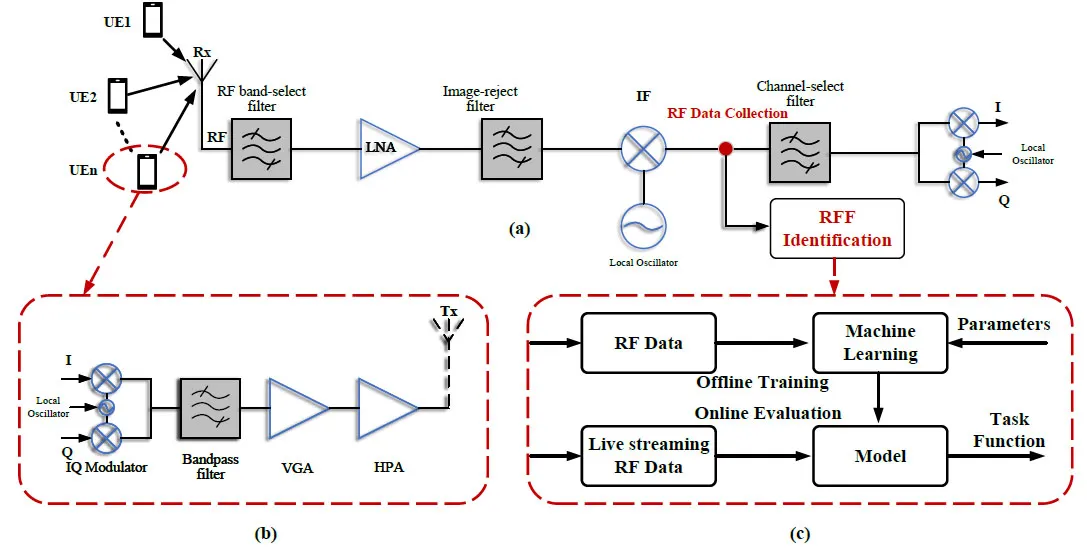
Figure 2.Illustration of RFF identification architecture. (a)Workflow diagram of time series signal collection in receiver side.(b)The nonlinear structure of the transmitter mainly includes I/Q Modulator,VGA,HPA and so on. (c)RFF framework of deep learning which includes training,testing and parameters optimization.
The typical transmitter architecture is shown in Figure 2b.RFF features are embedded when signal pass through those non-linear modules.The actual hardware impairments are the stable,unchanging subtle features which can be extracted for identification[41].Furthermore,in order to explore the modules’ ideal performance and the practical non-linearity,a typical complete wireless communication modules are constructed by Simulink.Then,simulation datasets are established by utilizing this platform.Finally,the typical machine learning architecture which contains whole training and evaluation process is shown in Figure 2c.Offline training process is applied to guarantee the network model convergence.Then,the optimized model can be deployed to realize the online identification.
3.2 Basic Principles of Radio Frequency Fingerprinting
In this section,an illustration of the basic principles of RFF is provided systematically.As shown in Figure 3a left,it shows how offset and gain errors which is the main characterize part of the linearity error affect the transfer curve of an ADC.Offset error is the difference between center of the least significant bit(LSB) and ideal ADC with the same bits.LSB is treated as converter’s quantization interval.The difference between center of most significant code and ideal ADC named gain error which just like Figure 3a right shows.Furthermore,ADC’s normalized linearity errorsGADCcan be defined by
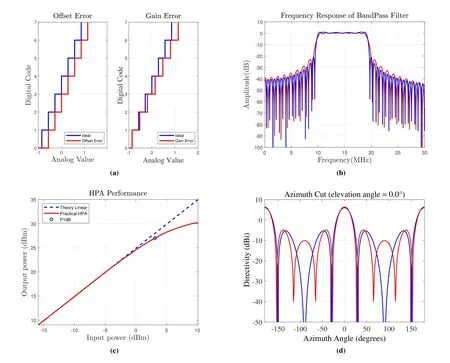
Figure 3.Non-linearity features of different RF modules. (a) ADC/DAC converting error which includes offset and gain error. (b) Filters’ impairments which is mainly reflected in the pass-band fluctuation and cut-off frequency. (c) Nonlinear characteristics of amplifier. (d)Inconsistency of antenna radiation.
whereVfulldenotes the full-scale range of the ADC andEoffsetrepresents the non-linearity error.Radio frequency(RF)filter is a circuit responsible for filtering the signal of specific frequency band.
As shown in Figure 3b,it is obvious that the attenuation-frequency characteristicGFilteris obviously different from another,although these two filters meet actual needs of practical application.Radio frequency remote unit(RRU)is an important part of typical LTE base station.It is mainly responsible for converting low-speed digital baseband signal generated by digital baseband unit (BBU) into highfrequency RF signal,amplifying and transmitting analog signal to wireless channel through power amplifier and antennas.High power amplifier is the import part for RF signal power enhancement and will bring nonlinear characteristicsGAmp.It can be observed from Figure 3c that the gain of output signal are not constant with the different power of the input signal.
Antennas can generate electromagnetic field radiated by the applied time-varying voltage or current.So that,in LTE system,antenna is the bridge of different mobile devices and base station.Every device’s antennas have its own radiation efficiency and characteristics although all of them meet the practical needs.Just like Figure 3d shows,the gain of antennas with four dipoles is slightly different due to the spacing error.These exiting subtle nonlinear characteristics will influence the waveform and become an integral part of the RFF features.The DC component of analog IQ signal is the main source of carrier leakage.IoffsetandQoffsetrepresents the relative value of the respective signal amplitudes just like Figure 4.The carrier rejection can be denoted by following factorα
Furthermore,the imbalance can be measured byGIQ
In order to verify and evaluate the non-linearity of different modules above.Several mobile devices’raw RF signals in open filed environment based on the RFF processing flow as shown in Figure 2c.The collected signalxican be defined by
wheresiis the original signal,GFilterandGAmpdenotes the impairments of filters and amplifier.Besides,Gis the unique fingerprint features which formed by the several modules imperfections mentioned above.As shown in Figure 4,four different devices show relatively obvious differences from the perspective of constellation.The difference between device 2 and 3 is slightly small,but there exist differences of the statistical distribution.Therefore,the RFF features based on hardware impairment is stable and can be further mined and processed.Although,the relevant mathematical models to describe the RFF of devices are established.However,in fact,there are still some subtle characteristics that cannot be accurately described by mathematical models.Fortunately,a typical CNNs model has numerous nonlinear neurons which is suitable for efficient feature extraction.
3.3 Proposed Semi-supervised Learning Architecture
In order to establish a suitable network model for onedimension signal processing,the traditional ResNet is modified to adapt one-dimensional signal[29].From Figure 5,it is obvious that the ID and Conv Block forms the RFFResNet which has a deeper construction.The extra layers can quickly learn the characteristics of the input samples to improve the model convergence.In revised RFFResNet model,the network parameters scale is only about half of that in original two-dimension ResNet.In order to comprehensively evaluate the performance of proposed model,a horizontal comparison is made with other typical network structures at the end of this paper.
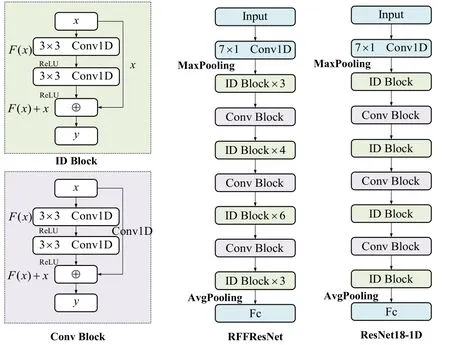
Figure 5.The proposed novel CNNs network which will be trained with the raw one-dimension raw signal.
In this paper,the collected raw signals are directly input to the network model.Whereas the typical ResNet has several advantages such as easy optimization,alleviating gradient disappearance and network degradation.The key advantage of proposed RFFRes-Net is the special residual structure.Firstly,the input signals will be processed by convolution kernels with the size of 7×1.Then,the total 64 convolution kernels are applied,and each kernel can extract the subtle radio frequency features.Besides,there exists an activation function which is designed for reducing the gradient vanishing[22].Furthermore,ReLu is treated as the activation function which has a certain property of sparsity.So that,the model can maintain the important core information and ignores the fluctuations.Finally,cross entropy is defined as the loss function of network model to guide the convergence of global optimal parameters[29].The final result is calculated by softmax function which obtains the final approximate probability of each class according to the following
whereWyijrepresents the weight of network andxidenotes the output of previous layer.fyjdenotes the prediction probability of inputx.Then,it will be normalized into probability distributionp(yj|x)by Eq.(5).In addition,the softmax function is also convenient to solve the partial derivative during the weight backpropagation.
As shown in Figure 6a,supervised learning is a typical method that infers a complex decision function from labeled training data.However,semi-supervised learning in Figure 6b,i.e.labeled and unlabeled samples are jointly applied to support the model learning,is an important research topic.As shown in Figure 6c,a pre-trained teacher network guides the learning process of student network.Besides,the key method of reducing pseudo-labeling over-fits caused by confirmation bias is to add augmentation.Experiment results have confirmed that pseudo-labeling alone can outperform consistency regularization methods [37].However,a definite teacher network may generate inaccurate pseudo labels which will cause the wrong guiding information for student network.Therefore,the trained student network can not acquire a significantly better performance due to the bias of information.To overcome the drawbacks above,authors in [34] proposed mutual learning to reduce the bias.As shown in Figure 6d,the student and teacher networks form a parallel cycle process of mutual learning and influence.Firstly,the student network learns from the pseudo label predicted by the teacher model.Secondly,the teacher network modifies and improves its own performance based on the student’s output among labeled samples.To elaborate the mutual learning process,the student network canonical cross entropy loss function of student network based on unlabeled samples can be expressed by
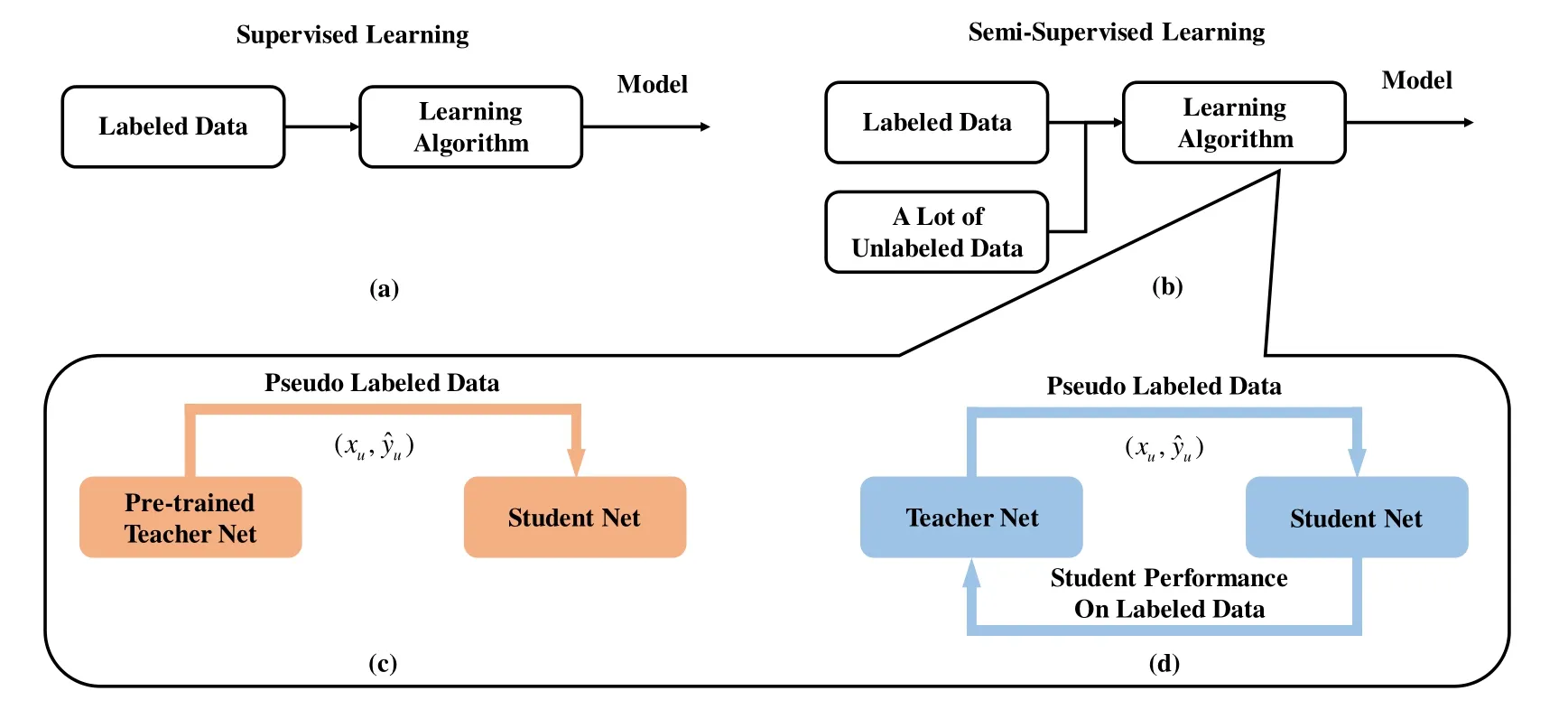
Figure 6.Different deep learning architecture. (a)Supervised learning which infers a functional ML task from labeled data.(b)The basic idea of SSL is to find the distribution of data and build a model with unlabeled and labeled samples. (c)A fixed pre-trained teacher network generates pseudo labels for student network learning. (d)Two models learns from each other until to acquire the optimized weight.
wherevsdenotes the student network parameters andvtrepresents the parameters of teacher network.Besides,(xu,xl) is the unlabeled and labeled training samples.ylis the corresponding labels of samples from datasets.T(),S() is the whole training process of network.C()is applied to calculate the crossentropy between different distributions.During the training process,the aim is seeking the minimum value of student cross-entropy.So that,this optimizing problem can be expressed by
He brought the stranger into his hall, and after they had supped went again to speak to Morgiana in the kitchen, while the Captain went into the yard under pretence26 of seeing after his mules, but really to tell his men what to do
Furthermore,the final expression can be obtained by substituting Eq.(9)into Eq.(8).
To solve the minimized problem above,the derivatives can be computed by
wherevsis independent withvt.Furthermore,it can be rewritten into the simplified expression
From Eq.(15) we can find that there is no dependency betweengsandvt, except via.Then,the Eq.(15)can be rewritten as

For simplicity but without loss of generality,terms in Eq.(17)can be calculated through Monte Carlo approximation.Then,the student network parameters based on unlabeled samples can be updated through Eq.(12).Therefore,the final gradient∇vtLlcan be expressed by Eq.(18).Considering the changes involved in the teacher’s optimization process,the training of student relies on objectives in Eq.(7).More interestingly,stochastic gradient descent(SGD)is applied to update the network parameters which are selected to provide information during the teacher onestep approximation.Therefore,the parameters updating procedure of two different networks can be denoted by
Only few labeled and a large amount of unlabeled data is needed to train the model when SSL is applied to RFF identification.Because of the feature composition is different from traditional image classification,the unsupervised data augmentation(UDA)in[34]operation is canceled,which further reduces the amount of training calculation,and the results show that the accuracy performance only has a slight fluctuation.Firstly,the weight initialization of teacher and student network is applied.Then,the pseudo labels of unlabeled datasets are generated by teacher network and update the student’s weight with pseudo label samples.Finally,updates the teacher and student’s weight through SGD.The detailed workflow of RFFSSL is shown in Algorithm 1.
IV.DATASETS DESCRIPTIONS AND EXPERIMENTS SETUP
4.1 Simulation Based Datasets
In order to make full evaluation of the different radio frequency characteristics hidden in the waveform,it is reasonable to adopt a simulation platform for generating the datasets.For simplicity but without loss of generality,the LTE frequency division duplex (FDD)ETM-1.1 is achieved in the simulation system.The operating center frequency is 1.8/2.0 GHz and the bandwidth is 3MHz.Table 1 displays the system modules’parameters mainly including I/Q,VGA and HPA.All parameters in the table are used to characterize the nonlinear characteristics of each module.Besides,raw signal samples are collected under different SNR with Gaussian distribution channel.At the side of transmitter,each transmission frame contains 10 symbols,and each symbol consists of 3840 discrete samples.Then,about 50000 different transmission frames for each device are collected under specific SNR of[5,10,13].All the samples are processed into real sig-nal and saved for subsequent training.The total collected samples of all devices is about 220 GB.Furthermore,the results show that the lower SNR will weaken the recognition accuracy of signal features,which will be discussed in Section V detailed.
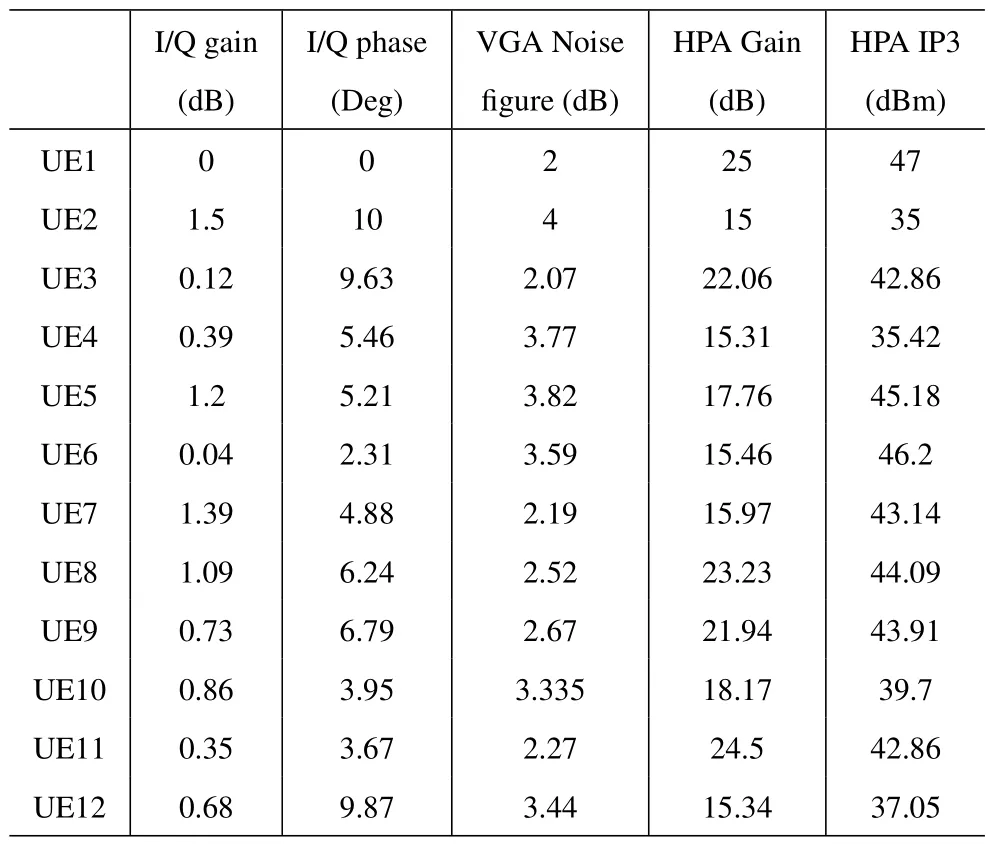
Table 1.Different RF parameters of simulation datasets.
4.2 Practical Scenario Datasets
To derive the practical datasets,a practical collection system based on LTE is constructed as shown in Figure 7.Then,the raw time signal samples are collected from 30 mobile phones which is listed in Table 2.The base station(BS)is configured as FDD mode and operating at down-link frequency:1.82 GHz and up-link:1.725 GHz.The signal sampling rate is 122.88 MHz.In collecting system,two different sounding reference signal(SRS)symbols are located in symbol 4 and 11 of transmission frame.The collected signal length is 8192 per-symbol before further demodulation.As shown in Figure 8,the collected raw time signal is located at the working band and there exists several characteristics out of band.Through long-time static acquisition of all devices,nearly 40000 transmission frames for each mobile phone are obtained,with a total of datasets about 50 GB,which can be used to evaluate the ability of various complex networks to extract device fingerprint features.
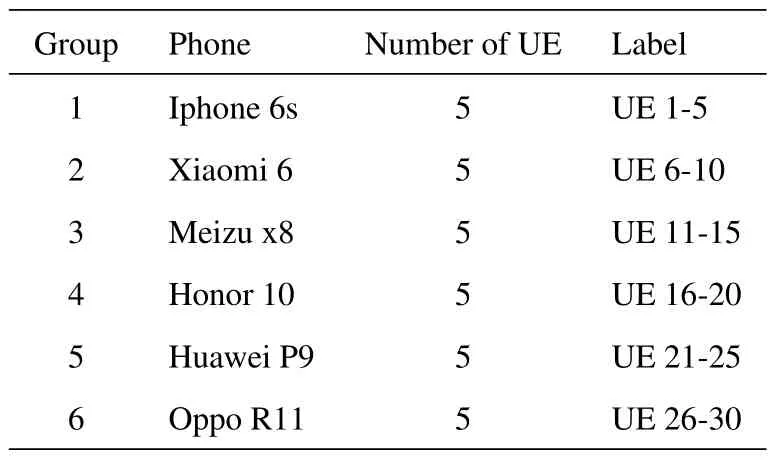
Table 2.List of mobile phones during experiments.
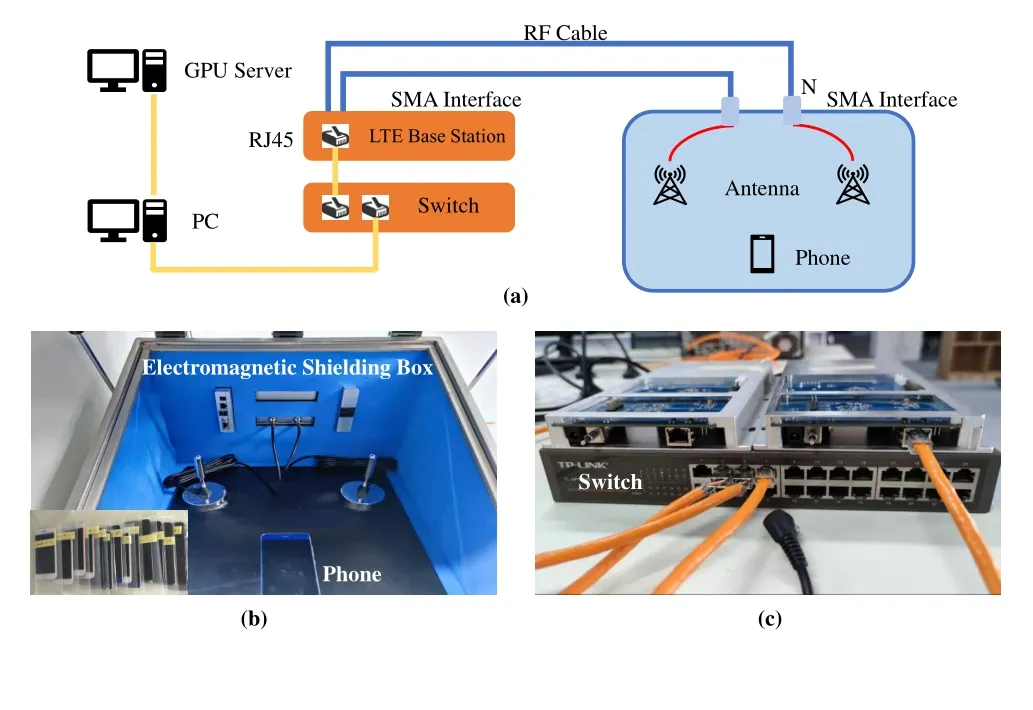
Figure 7.Experiment architecture of practical data collection.

Figure 8.Normalized LTE single waveform frame and the corresponding spectrum.
In order to evaluate RFF identification compared to two-dimensional network model,all collected samples should be transformed to time-frequency domain by short-time Fourier transform(STFT).The obtained frequency domain diagram is saved as the corresponding image,and is used as the input of baseline network.Normalization and dimension expansion will be applied for the preprocessing operation [35].On this basis,the training and testing datasets are established both in one-dimension raw series and twodimensional.
V.EXPERIMENT RESULTS AND DISCUSSION
5.1 Methodology and Performance Metrics
The related network models are implemented by Keras with TensorFlow 2.3 backend on an NVIDIA CUDA enabled GPUs.For both datasets,one-dimension raw signals and transformed two-dimension images are both evaluated.If two-dimension network model is evaluated,normalization and dimension expansion are applied.For each task,datasets will be divided into testing and training datasets according to the ratio of 3 : 7.Furthermore,80% training samples are used to train the model and adjust the weight parameters of the model.20%samples are used as the validation set to determine hyperparameters in each training epoch.The testing datasets are applied to evaluate the identification accuracy and robustness of the trained models.During the training process of RFFSSL,a small amount of labeled samples are selected as the input of student network,and the rest as unlabeled samples for auxiliary learning.In order to accurately evaluate the network model,the accuracy of single symbol recognition is defined as system performance indicator,which is the fraction of correctly predicted slices over the total number of samples.At the same time,the recognition rate of per-transmissions can be calculated by the accuracy of a single symbol,which can provide evaluation from different perspectives and be more stable.
5.2 Identification Performance Analysis of Simulation Datasets
For fully evaluating the impact of SNR based on different models,STFT is applied to transform the raw signal into corresponding images.Besides,this simulation datasets are collected underSNR=[5,10,13]with 12 different simulation devices.For investigating the influence of SNR and the scale of training datasets,the proposed RFFResNet is compared with a benchmark model named ResNet18-1D.It can be seen from Figure 9a that higher SNR will bring benefits for identification with same number of training samples.When SNR equals 10 dB and slicenum is 490,the RFF identification accuracy of ResNet18-1D is only about 54%which is lower about 27%compared to RFFRes-Net.Compared to the case when SNR equals 13 dB,87% identification accuracy can be achieved by RFFResNet with the minimum training samples.However,with the SNR decreasing to 5,the identification accuracy deteriorating rapidly.By carefully constructing the RFFResNet for improving the efficiency,the RFFResNet significantly outperforms ResNet18-1D.With the scale continuous increase of training datasets,the impacts of SNR towards recognition results is also decreasing.
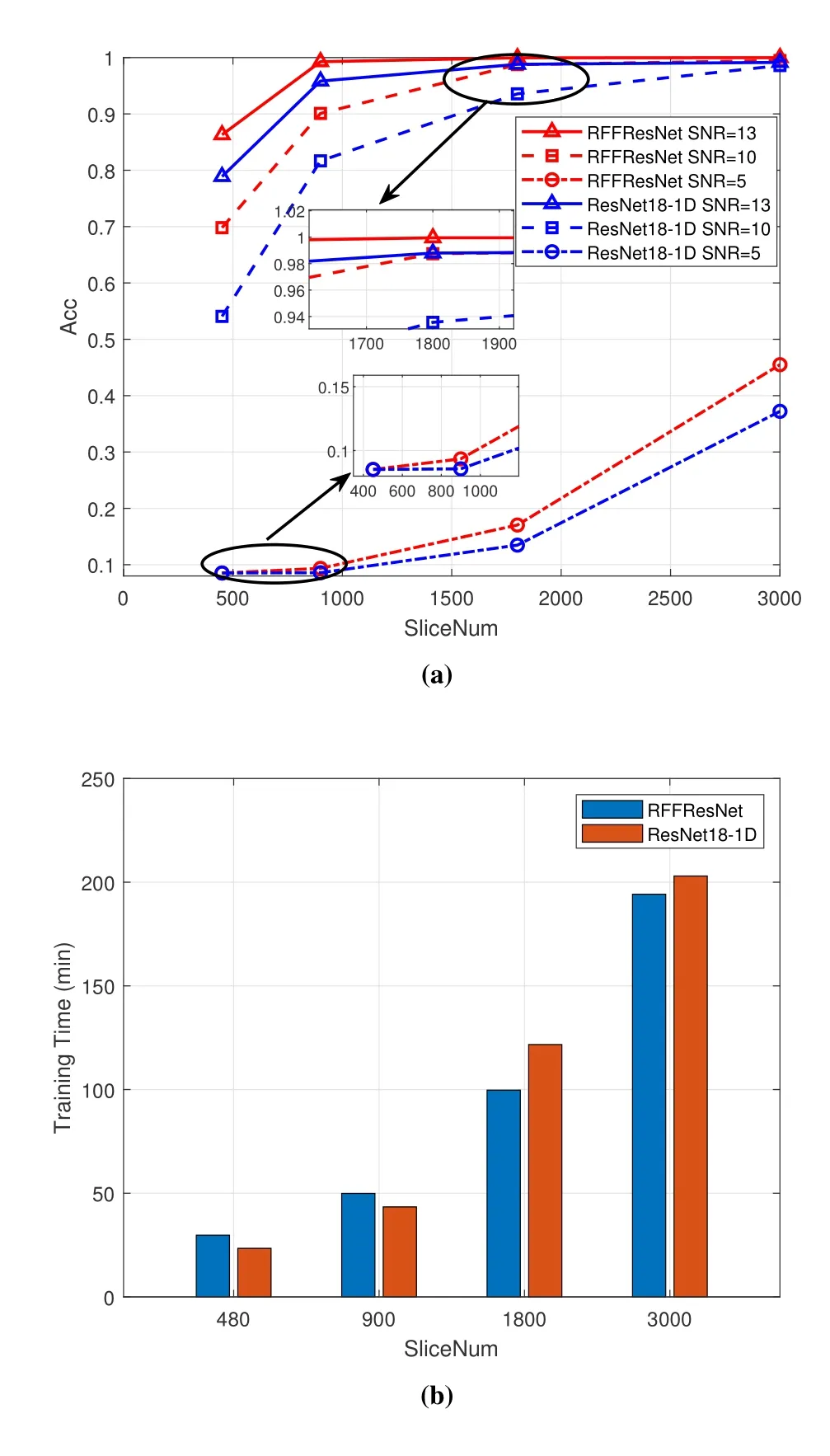
Figure 9.Experiment results analysis based on simulation datasets. (a)Identification accuracy against different training slicenum and SNR. (b) Training time cost of different models when SNR=13.
Besides,to assess the network training process,statistical analysis of training cost is performed in Figure 9b.From the chart,we can find that RFFResNet’s learning converges more faster when training samples more than 1800 and its training computation is slightly higher than ResNet18-1D when slicenum is less than 1000.The criterion for the end of model training is that the identification accuracy is no longer increased,rather than a fixed number of epochs.When the training scale is small,RFFResNet needs more training time to converge due to the more ID blocks and cannot fully learns.But,RFFResNet can accelerate convergence of the network model when the training scale is large by solving the degradation problem,vanishing gradient problem and extracting the features more efficiently.If the training epochs are a fixed number,RFFResNet will spend more training time in general.
It should be noted that the SNR here is corresponding to simulation channel and not completely equivalent to the actual LTE system SNR threshold for demodulation.During the process of model training,both the accuracy and loss are critical to evaluate the model’s learning performance.The purpose of training is to learn the subtle RFF features which constructed by Table 1 and predict the devices’ label as accurately as possible.It can be observed from Figure 10 that accuracy and loss of training process is more stable than validation because the weight adjustment direction is closely related to the size of learning batches.Besides,both the accuracy and loss converge rapidly when SNR equals 13 and in general a few epochs are sufficient for model learning.Additionally,it is shown in Figure 10a and 10c that more training data will incur higher accuracy and there exist some certain fluctuations in the term of validation accuracy when SNR is lower.These results demonstrate that datasets with higher SNR will promise an efficient converge of learning and enough training samples guarantee the remarkable performance of identification.
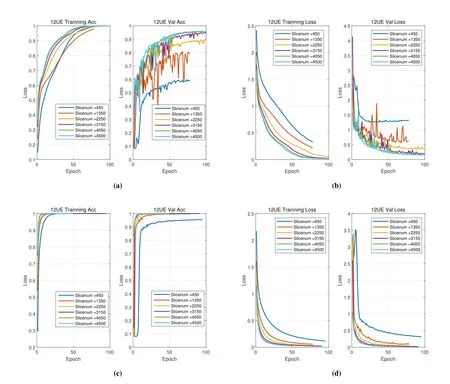
Figure 10.Model training and validation process based on simulation datasets. (a)SNR=10 acc via epoch. (b) SNR=10 loss via epoch. (c)SNR=13 acc via epoch. (d)SNR=13 loss via epoch.
5.3 RFFSSL Performance Analysis Among Practical Datasets
Large scale labeled datasets are an essential part of the supervised learning.However,it is difficult to obtain large-scale datasets with labels under practical application.Beyond supervised learning,semi-supervised learning is an efficient method which can extract the RFF features only rely on few labeled samples.RFFResNet is applied as the teacher and student initial network to implement the RFFSSL framework which is explained in Section 3.3.During the experiment,only few labeled samples are selected and the rest are treated as unlabeled samples to assist the mutual learning of the two models.The key mechanism of RFFSSL is that teacher network learns the weight feedback of students under pseudo labels to further improve its performance and generate more accurate soft labels for student learning.
As shown in Figure 11a,different models performance are evaluated among the practical datasets.
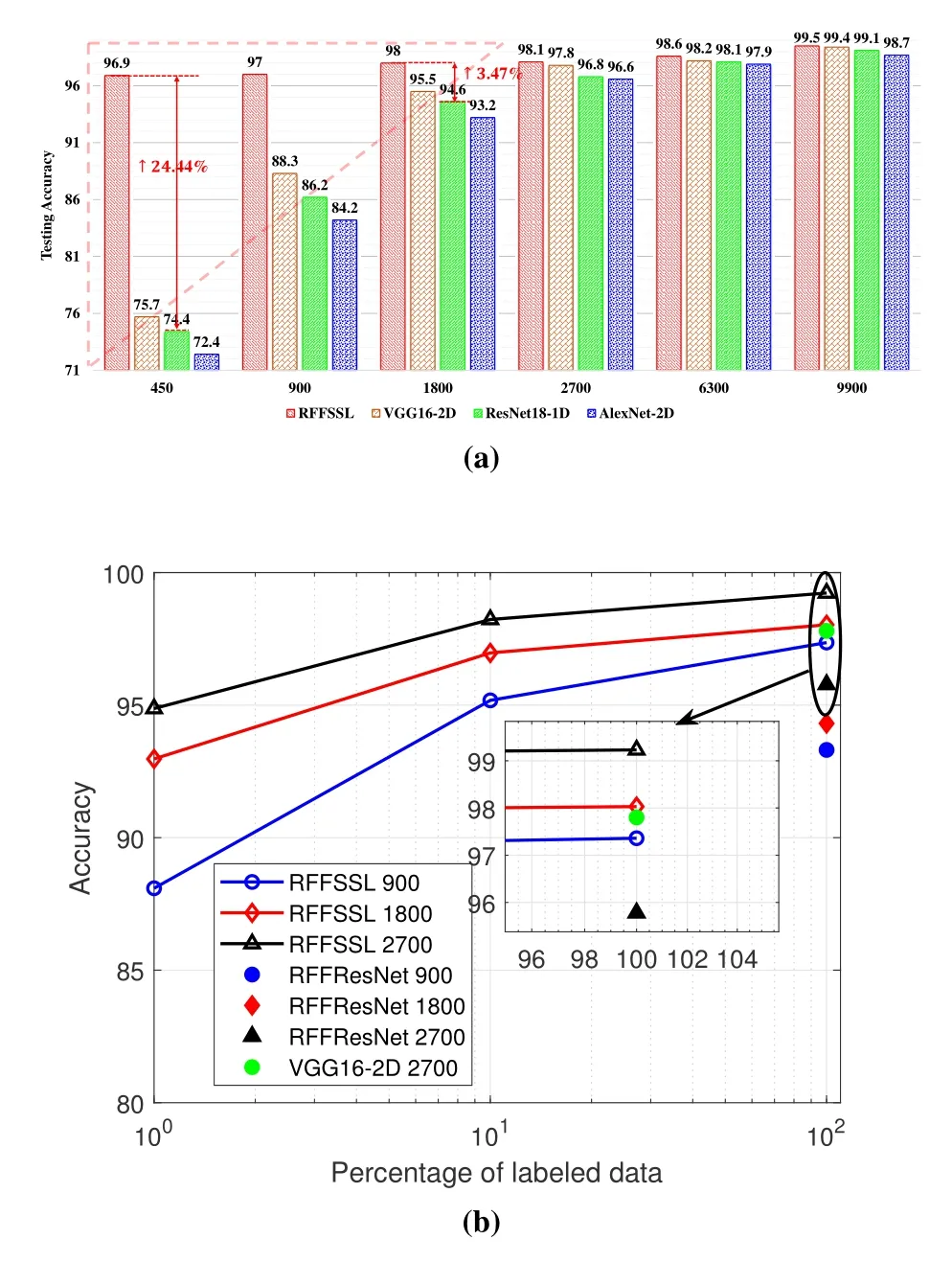
Figure 11.Experiment results analysis based on practical datasets. (a)Identification accuracy of supervised learning and RFFSSL against labeled samples. (b)Identification accuracy of RFFSSL with different percentage of labels.
It is obvious that RFFSSL achieve about 97%identification accuracy with only 500 labeled training samples and some unlabeled data.Meanwhile,the benchmark model AlexNet-2D [22] only get about 73%accuracy which is much lower than 97%.Furthermore,when the number of training samples is large enough to 9900,the performance difference between RFFSSL and other supervised learning (SL) methods becomes smaller,and the overall accuracy tends to 100%.The VGG16-2D shows a better identification performance than ResNet18-1D and AlexNet-2D,due to more network parameters.Besides,the accuracy of RFFSSL under 900 is closed to SL model under 9900,which means that RFFSSL can achieve better performance with small-scale labeled samples when SL model needs large-scale labeled samples.Those results suggest that the unlabeled data is labeled correctly by employing mutual learning between student and teacher network.Therefore,RFFSSL can achieve a better performance under practical application which always only contains small-scale labels which is highlighted triangle area in Figure 11a.Therefore,RFFResNet is more suitable for actual scenes where numerous accurate labels cannot be obtained.
In Figure 11b,various percentages of labeled data are examined by RFFSSL and compared with its’SL models under different training samples.It can be seen from this chart that RFFSSL achieves almost 95.78% identification accuracy with only 10%of labeled training samples,better than the supervised learning with 100%of labeled instances and the same model when the total training samples equal to 900.With the increasing of percentage of labeled samples,the RFFSSL can achieve a higher identification accuracy.When trained with 100% of the available labels,the performance of RFFSSL fully surpasses SL models.These excellent properties have confirmed the benefit of student and teacher’s efficient feedback learning.The RFFSSL training need about 300 minutes when the training sample equal to 2700.On the contrary,the supervised learning method only need about 240 minutes.The reason is RFFSSL need two models collaborative learning.Summarized from Figure 11,it can be concluded that the consistent gains have proved the benefit of internal distribution characteristics deviation of devices’RFF features.
As shown in Figure 12,a 30 × 30 confusion matrix is applied to evaluate the performance of different models,where 30 is the total classes of datasets.Thex-axis of confusion matrix correspond to the predicted labels and they-axis represents the true class.Diagonal and off-diagonal elements correspond to correctly and incorrectly classified observations,respectively.It can be observed from Figure 12a 12b that the more training data the better performance will be achieved.Besides,all those mis-predicted labels are in the same groups which includes phones of same series which imply that the RFF features among groups are easier to distinguish.From Figure 12c 12d,it can be observed that RFFSSL model achieves a higher accuracy compared to supervised learning model RFFResNet.Besides,all those wrong predictions occurred in 4-th group and a higher accuracy is obtained with the training samples grows.Indeed,those two mis-predicted devices are similar to each other in the high dimension features’ space.Compared to the RFFResNet,a conclusion can be drawn that RFFSSL model can extract devices’ features effectively.The key mechanism of RFFSSL is able to generate better pseudo labels and training in parallel to optimize the student network parameters.Particularly,when the training data is huge or labeling is difficult,the RFFSSL still exhibits a remarkable performance.
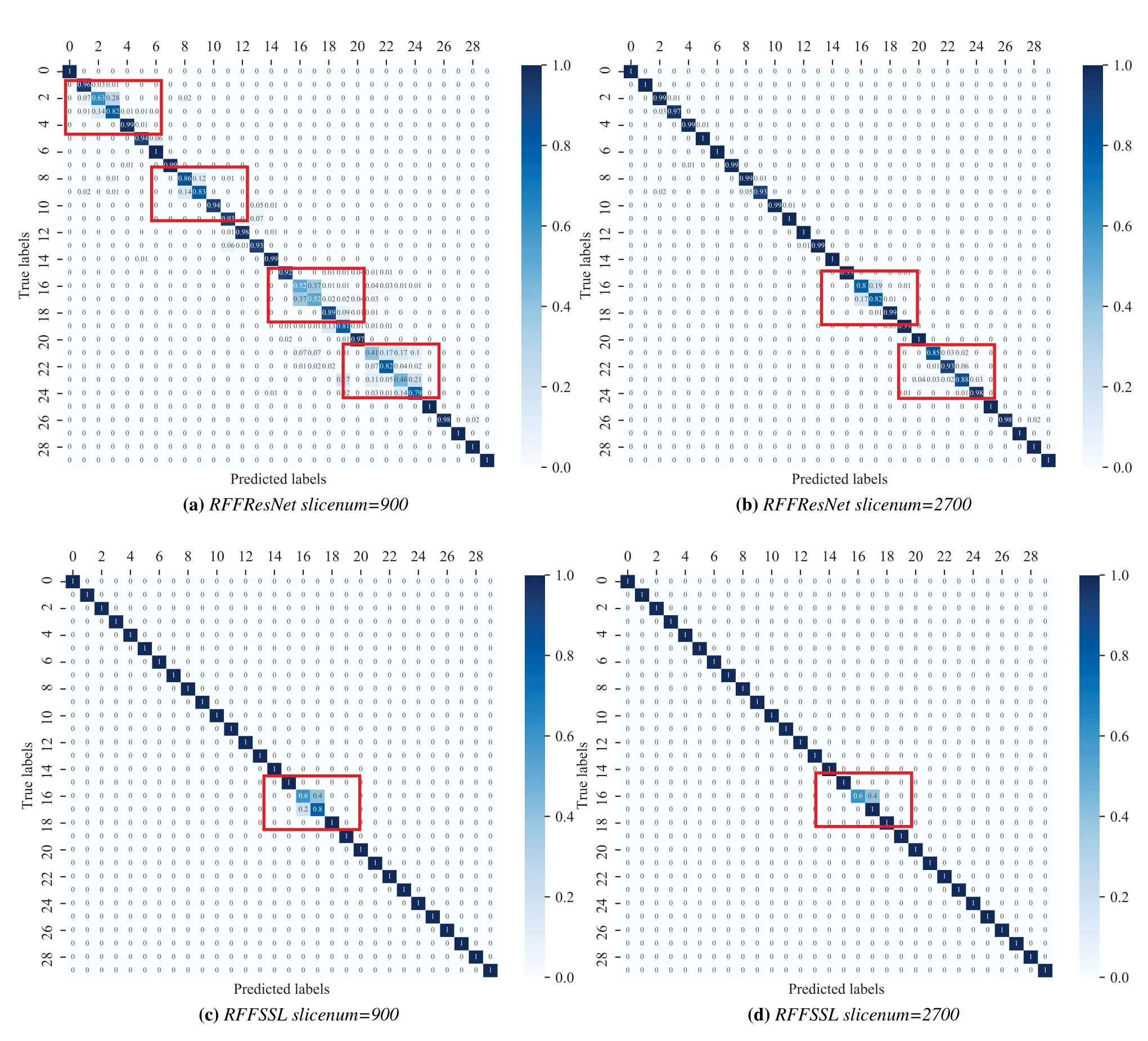
Figure 12.Identification accuracy confusion matrix with different model and training samples.
VI.CONCLUSION
In this paper,superiority analysis of RFF in terms of identification performance on both simulation and LTE practical datasets is provided.Besides,the impact of different SNR,model construction and the datasets scale among the identification accuracy are discussed.Furthermore,we proposed a novel semi-supervised learning method RFFSSL which only needs few labeled samples guiding the model to extract RFF features from the unlabeled samples.Finally,the RFFSSL model is experimentally validated among the practical datasets.It can be observed that the identification accuracy improved with the amount of labeled data increases under both SSL and SL training framework.RFFSSL model only needs about 10% of labeled data to achieve up 97% accuracy of RFF identification when the total samples equal to 2700.Experimental and numerical results have illustrated that the proposed RFFSSL identification is a promising solution for physical-layer authentication.However,the RFFSSL model training procedure is somewhat slow and expensive.Besides,the configuration of training hyper-parameters needs slightly tuning according to the distribution characteristics of datasets.Our future work will focus on improving the training efficient,robustness and accuracy of the RFFSSL architecture under extremely complex environment.
ACKNOWLEDGEMENT
This work was supported by Innovation Talents Promotion Program of Shaanxi Province,China(No.2021TD08).

- China Communications的其它文章
- IoV and Blockchain-Enabled Driving Guidance Strategy in Complex Traffic Environment
- LDA-ID:An LDA-Based Framework for Real-Time Network Intrusion Detection
- A Privacy-Preserving Federated Learning Algorithm for Intelligent Inspection in Pumped Storage Power Station
- Secure Short-Packet Transmission in Uplink Massive MU-MIMO Assisted URLLC Under Imperfect CSI
- Multi-Source Underwater DOA Estimation Using PSO-BP Neural Network Based on High-Order Cumulant Optimization
- An Efficient Federated Learning Framework Deployed in Resource-Constrained IoV:User Selection and Learning Time Optimization Schemes