
Dynamic Spectrum Anti-Jamming with Distributed Learning and Transfer Learning
2023-12-10 11:36XinyuZhuYangHuangDelongLiuQihuiWuXiaohuGeYuanLiu
China Communications 2023年12期
Xinyu Zhu ,Yang Huang,* ,Delong Liu ,Qihui Wu ,Xiaohu Ge ,Yuan Liu
1 Key Laboratory of Dynamic Cognitive System of Electromagnetic Spectrum Space,Ministry of Industry and Information Technology,Nanjing University of Aeronautics and Astronautics,Nanjing 210016,China
2 The 723 Institute of CSSC,Yangzhou 225001,China
3 School of Electronic Information and Communications,Huazhong University of Science and Technology,Wuhan 430074,China
4 School of Electronic and Information Engineering,South China University of Technology,Guangzhou 510641,China
Abstract: Physical-layer security issues in wireless systems have attracted great attention.In this paper,we investigate the spectrum anti-jamming (AJ) problem for data transmissions between devices.Considering fast-changing physical-layer jamming attacks in the time/frequency domain,frequency resources have to be configured for devices in advance with unknown jamming patterns (i.e.the time-frequency distribution of the jamming signals)to avoid jamming signals emitted by malicious devices.This process can be formulated as a Markov decision process and solved by reinforcement learning (RL).Unfortunately,stateof-the-art RL methods may put pressure on the system which has limited computing resources.As a result,we propose a novel RL,by integrating the asynchronous advantage actor-critic (A3C) approach with the kernel method to learn a flexible frequency pre-configuration policy.Moreover,in the presence of time-varying jamming patterns,the traditional AJ strategy can not adapt to the dynamic interference strategy.To handle this issue,we design a kernelbased feature transfer learning method to adjust the structure of the policy function online.Simulation results reveal that our proposed approach can significantly outperform various baselines,in terms of the average normalized throughput and the convergence speed of policy learning.
Keywords: A3C;anti-jamming;reinforcement learning;spectrum;transfer learning;wireless system
I.INTRODUCTION
With the rapid development of wireless communication technology and artificial intelligence,security issues in wireless networks are of increasing severity[1,2].A study conducted by Hewlett-Packard (HP)showed that 70% of Internet of Things (IoT) devices are vulnerable to various attacks when connected to the Internet [3].Moreover,it is reported that IoT devices such as networked sensors can suffer from the issues in physical-layer security,e.g.illegal wiretapping[4,5] and denial of service attacks [6,7].This paper focuses on the jamming in frequency-domain channels [8].That is,interference emitted by malicious devices (MDs) intrinsically decreases the signal-tointerference-plus-noise ratio (SINR) by transmitting jamming signals to wireless channels,such that the receiving devices may not successfully decode desired signals[7,9].Unfortunately,traditional anti-jamming(AJ)scheme e.g.frequency-hopping spread spectrum and direct-sequence spread spectrum,may not adapt to the dynamic jamming patterns(i.e.the time-frequency distribution of the jamming signals)[9,10].
Device-to-Device(D2D)communication,which allows direct communication between two devices without the assistance of other infrastructures,is one of the key technologies enabling the IoT [11,12].Nowadays,spectrum AJ has been recognized as a significant issue for physical-layer security in the context of D2D communications [13].This paper addresses the spectrum AJ problem for data transmissions between a receiving device (RD) and a sending device (SD),focusing on investigating fast adaptation of spectrum AJ policies to dynamic jamming.Considering the limited signal processing capability of the devices (e.g.IoT devices),full channel state information (CSI) may not be obtained by executing channel estimation with pilot signals.Hence,we exploit a non-data-aided(NDA)SINR estimation-based method to learn the spectrum occupancy,so as to preconfigure the frequency-domain channel for data delivery prior to each transmission.Moreover,due to the highly jamming environments,the transmission time interval,which is referred to as timeslot for simplicity of presentation,has to be short [14].This means that frequency-domain channels have to be configured without the knowledge of the jamming pattern for devices in advance,where the decision-making process can be formulated as a Markov decision process(MDP)and solved by reinforcement learning(RL).
In the literature,Q-learning-based algorithms or their variants [15–17] were utilized to solve such an MDP problem.Nevertheless,these works exploit the lookup table method to optimize a deterministic frequency pre-configuration (FP) policy.Such an approach may suffer from the well-known curses of dimensionality,where the state space with respect to decision-making can grow exponentially with the number of frequency-domain channels,resulting in an unacceptable convergence speed of the policy in practice.In order to handle this issue,deep Qnetwork(DQN)was proposed,where neural networks can be exploited to approximate Q-value-table [18–21].However,due to the numerous neurons,DQN may cause high computational complexity not only in the training phase but also in the inference phase[22].In order to tackle the challenge,we exploit a set of basis functions,i.e.Gaussian kernel functions(GKFs) [23,24],to approximate the parameterized policy functions [25,26],as well as the state-value functions.Note that neural networks consisting of GFKs can approximate functions with a singe layer of neurons,i.e.GFKs.
The speed of learning FP policies is vital for spectrum AJ.This is reminiscent of the distributed framework of asynchronous advantage actor-critic(A3C),in the context of RL.It was reported that A3C can offer a higher learning speed than Q-learning and DQN,given benchmark environments of the Atari games and the TORCS 3D car racing simulator[27].Unfortunately,applying A3C to spectrum AJ is nontrivial,as it is impossible to let a SD execute multiple frequency configurations output by various FP policies simultaneously.To handle this issue,we draw on an experience replay approach [28] to implement distributed learning [29–31]based on the A3C framework.
It is worth noting that in the aforementioned spectrum AJ techniques as in [16–19],once the FP policies are learned,the FP policies remain constant,due to the assumption of stationary wireless environments.This means that in the presence of changes in the jamming pattern,off-the-shelf methods[16–19]may completely relearn the FP policies,so as to cope with the new jamming pattern.Intuitively,relearning can introduce tremendous time consumption,which is detrimental to establishing the capability of adapting to dynamic jamming patterns.On the contrary,in the context of unmanned aerial vehicle-assisted communications[32],transfer learning(TL)were employed to reduce the time consumption of policy learning for reinforcement learning in an unknown environments.Basically,the learning can be accelerated by exploiting past knowledge [33].Inspired by this,in this paper,a kernel-based feature TL method is proposed.Different from off-the-shelf methods that reuse partial neural network layers[32],the proposed method dynamically adjusts feature vectors online by analyzing the similarity between the newly obtained feature vectors and the past feature vectors.Our contributions are in four folds.
First,we design a novel spectrum AJ scheme for wireless devices suffering from stringent constraints on signal processing and transmit power.In contrast to the pilot-based CSI acquisition which is common in cellular communications,NDA SINR estimationbased approach is designed to enable low-power RD to estimate the spectrum situation.Based on this,an RL-based intelligent algorithm is proposed for RD to pre-configure frequency resources for low-power SD in advance to avoid fast-changing jamming signals delivered by MDs.
Second,to fully unlock the potential of RL-based methods in quickly learning the jamming-resistant FP policies,we propose a kernel-based distributed asynchronous advantage actor-critic (KDA3C) algorithm to tackle the jamming attacks in the frequency-domain channel from MDs.In contrast to off-the-shelf deep networks with static structures,the algorithm can build scalable neural networks that characterize state values and policies with flexible sets of GKFs,such that the FP policy can be well optimized for a mixture of a variety of jamming signals.
Third,to accelerate the convergence of the algorithm in the presence of changes in the jamming pattern,a kernel-based feature TL method is developed for KDA3C,which is then referred to as kernel-based feature TL for distributed A3C(KFTLDA3C).
Fourth,interesting observations are made in simulations.By performing the KDA3C algorithm,the SD can conduct transmission but avoid jamming signals emitted by MDs.Moreover,in the presence of changes in the jamming pattern,KFTLDA3C outperforms various baselines,in terms of average normalized throughput and the speed of convergence.
The remainder of this paper is organized as follows.Section II establishes the system model and formulates the design problems.In Section III,we propose approaches to solve the design problems.We analyze the simulation results in Section IV.Conclusions are drawn in Section V.
Notations: Matrices and vectors are in bold capital and bold lower cases,respectively.The notations(·)T,(·)*,||·||,〈·〉and|·|represent the transpose,optimized solution,2-norm,inner product and modulus,respectively.In particular,|D| represents the number of elements in the setD.The notationE[x]is the expectation ofx.The notation∇θfmeans the gradient with respect toθfor a functionf.
II.PRELIMINARIES
2.1 System Model
As shown in Figure 1,in a certain timeslott,the SD delivers information to the RD through a preconfigured frequency-domain channelc∈{1,...,C}(or at frequencyc).In the meanwhile,LMDs transmit jamming signals at various frequencies to disrupt the communication between devices.In order to avoid jamming signals,the RD has to perform sequential decision-making with the uncertain jamming pattern,according to instantaneous rewards of the amount of successfully received data (i.e.normalized throughput) and the observed spectrum occupancy state.In this paper,we assume that the control link will not be jammed by MDs.The signal transmitted by the SD can be designated as,while the jamming signal emitted by MDlin timeslottcan be designated asrespectively.Letrespectively represent the channel gain of the channel between the SD at frequencycand the RD and that between the RD and a certain MDlat frequencyc,in timeslott.The received signal at frequencycin timeslottcan be expressed as
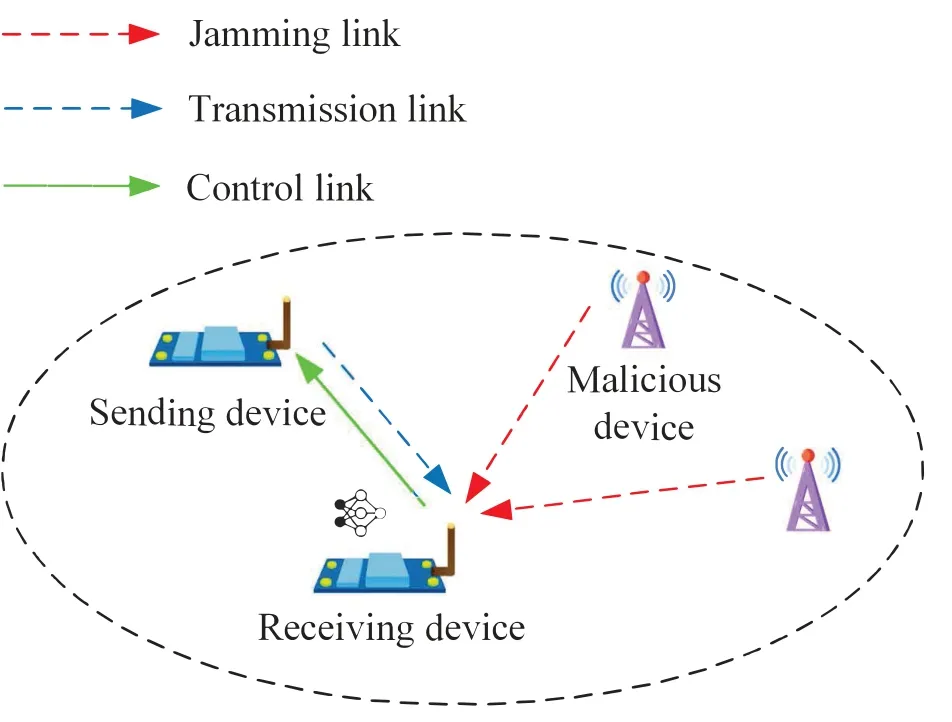
Figure 1.Data transmissions between wireless devices in jamming environments.
2.2 Problem Formulation
We model the dynamic spectrum decision-making process as a MDP[35].The spectrum occupancy state at frequencycin timeslottis denoted asst,c,which can be obtained from the RD with Table 1.In particular,the“Absence”and“Presence”are assigned as 0 and 1,respectively.The environment state is defined as a set of channel status ofThhistorical timeslots,which is denoted by st=.A setSis defined to collect states of spectrum situation of all channels in one timeslot.Since the complex jamming patterns such as intelligent jamming,jamming actions may be related to earlier historical channel status [18].The actiona stands for the FP result of SD in timeslott,whereλt=and a=[1,2,..,C]T,at∈A,A={1,2,...,C}.The transition probability for the statesttost+1when taking actionais denoted asp(st+1|st,a),which is unknown to the RD,due to the unknown jamming pattern.The instantaneous reward can be obtained as follows.If the chosen channel is jammed by MDs,rt=-Rs;otherwise,rt=Rf,whereRsandRfare both positive constants.The policy of the MDP is defined as a functionπ,which is a probability distribution in action space.To find the optimal FP that enables the SD to avoid jamming signals emitted by MDs(or maximizes the long-term average normalized throughput),we solve the optimization problem∀s∈Sgiven as

Table 1.Spectrum occupancy state extraction.
whereγis a discount factor.
As shown in Figure 2,in the request&ACK frame,the SD sends the data transmission request to the RD for applying the available frequency-domain channel to communicate with the RD.The RD returns an acknowlegement(ACK)to the admitted SD via the control channel.Then,in framek,k=1,2,...,the SD performs data transmission while the RD executes the spectrum occupancy state estimation.In the meanwhile,the KFTLDA3C algorithm,which is elaborated in the next section,performs FP decision-making and outputs the frequency-domain channel to be exploited in the next frame.Finally,the RD returns the result of FP via a control channel to the SD.
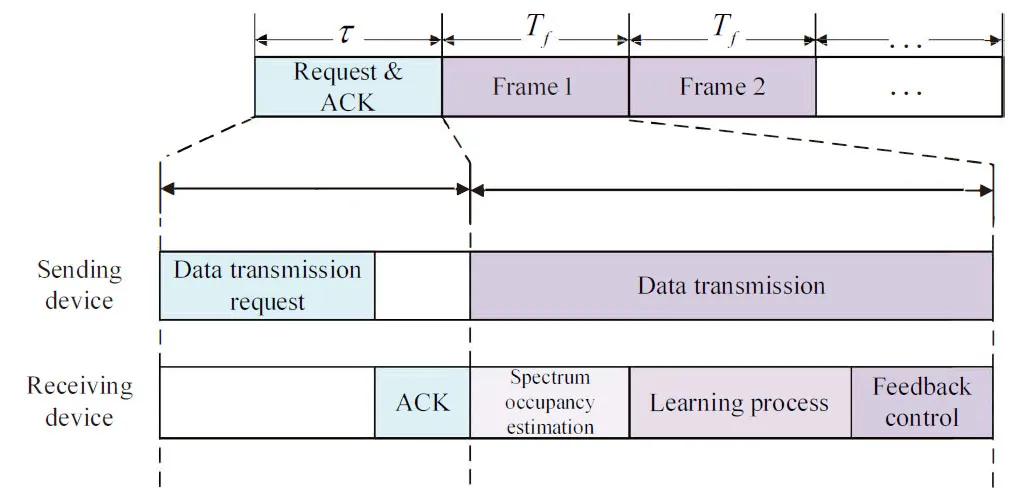
Figure 2.Timing relation for Request&ACK,data transmission and learning process for data transmission.
III.THE PROPOSED METHOD FOR SOLVING THE DYNAMIC SPECTRUM ANTI-JAMMING PROBLEM
3.1 Kernel-Based Distributed Asynchronous Advantage Actor-Critic Algorithm
To cope with the unknown transition probabilityp(st+1|st,a),we propose an asynchronous decision method for advantage actor-critic to solve the problem(3).Intuitively,given an experience replay buffer,we can employ multiple virtual workers to asynchronously take experience samples (each of which consists of an observed state,an executed action,a reward value and a new state resulting from the action[28]),so as to learn the FP policy in a parallel manner.By this means,the policy is essentially learned under a distributed framework.We then elaborate on the proposed kernel-based distributed asynchronous advantage actor-critic algorithm.
Actor-Critic NetworkWe setKworkers with the same structure of AC networks.Each AC network consists of an actor-network and a critic-network.The actor-network acts on spectrum decisions with a policy function.We employ the softmax function to be the policy function of workerkas
Given a thresholdµ,ifδt>µ,Dq,k,t-1∪xt;otherwise,xtis not added toDq,k,t-1.Therefore,the computational complexity of the ALD test for a certainDq,k,tcan be computed asO(5(dq,k,t-1)2+3ThC+4).
Update for Parameters in Each WorkerWe divide total timeslots into several equal time periods,and each period lasts forTstimeslots.A experience replay buffer utilized to store sample (st,at,rt,st+1)is defined.In particular,thei-th sample in the experience replay buffer is denoted as.At the beginning of the algorithm,we obtain some samples through random decision-making to initialize some parameters.We initialize global sets of policy function and state-value function (i.e.),and global weights(i.e.).Then,the global sets and global weights are copied to sets and weights of workers.At the beginning of each time period,we randomly select a policy function of a worker to make a spectrum decision.In timeslott,the chosen worker decides with its current policy and stores the sample into the experience replay buffer.
In particular,the chosen worker does not update its policy function and state-value function.The other workers randomly selectdssamples from the experience replay buffer to update their weights of GKF networks by n-step temporal difference(TD)error update method independently.Forj=ds,ds-1,...,1,the gradient of policy function for each worker can be computed by performing
Afterwards,dwq,kanddwv,kare utilized to update thewq,kandwv,kby executing the following
Update for Global ParametersWhent=mTa,Ta=nTs,m∈N+,n≥K,we need to update the parameters for all workers by the global update model,which consists of two parts: the global feature update and the global weight update.A weighted average method is designed to update the global weights using the parameters obtained by all workers.
If the number of feature vectors varies across workers,we need to make the dimensionality of the weight vector consistent for all workers by a zero-filling operation.Hence,the parameters of the weights to be updated can be further expressed as.We update the global weights by taking a weighted average method by using weights of all workers as
3.2 Kernel-Based Feature Transfer Learning Method
Furthermore,given a thresholdη0,ifη≥η0,the jamming pattern is changed and the set can be emptied to relearn the feature vectors.However,this approach may not be an effective way to address dynamic jamming environments,especially when jamming patterns are similar.As a result,we designed a kernel-based feature TL-based approach to reuse part of feature vectors of policy and state-value functions.The process of the proposed spectrum AJ scheme has been drawn in Figure 3.
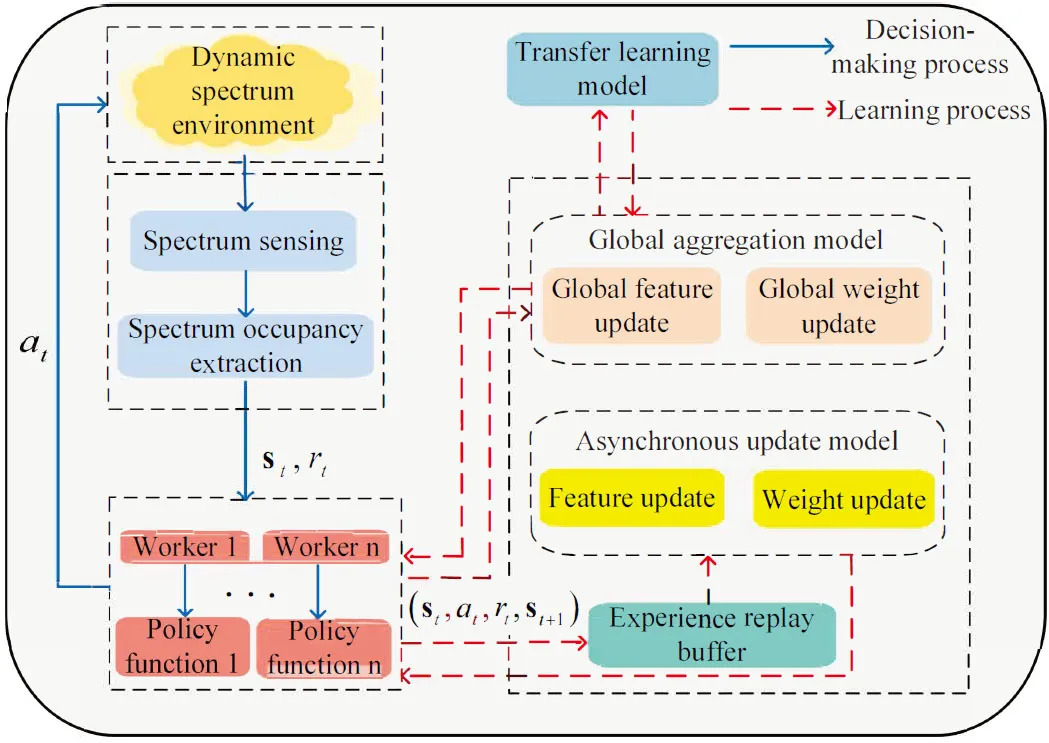
Figure 3.The process of intelligence spectrum AJ scheme.
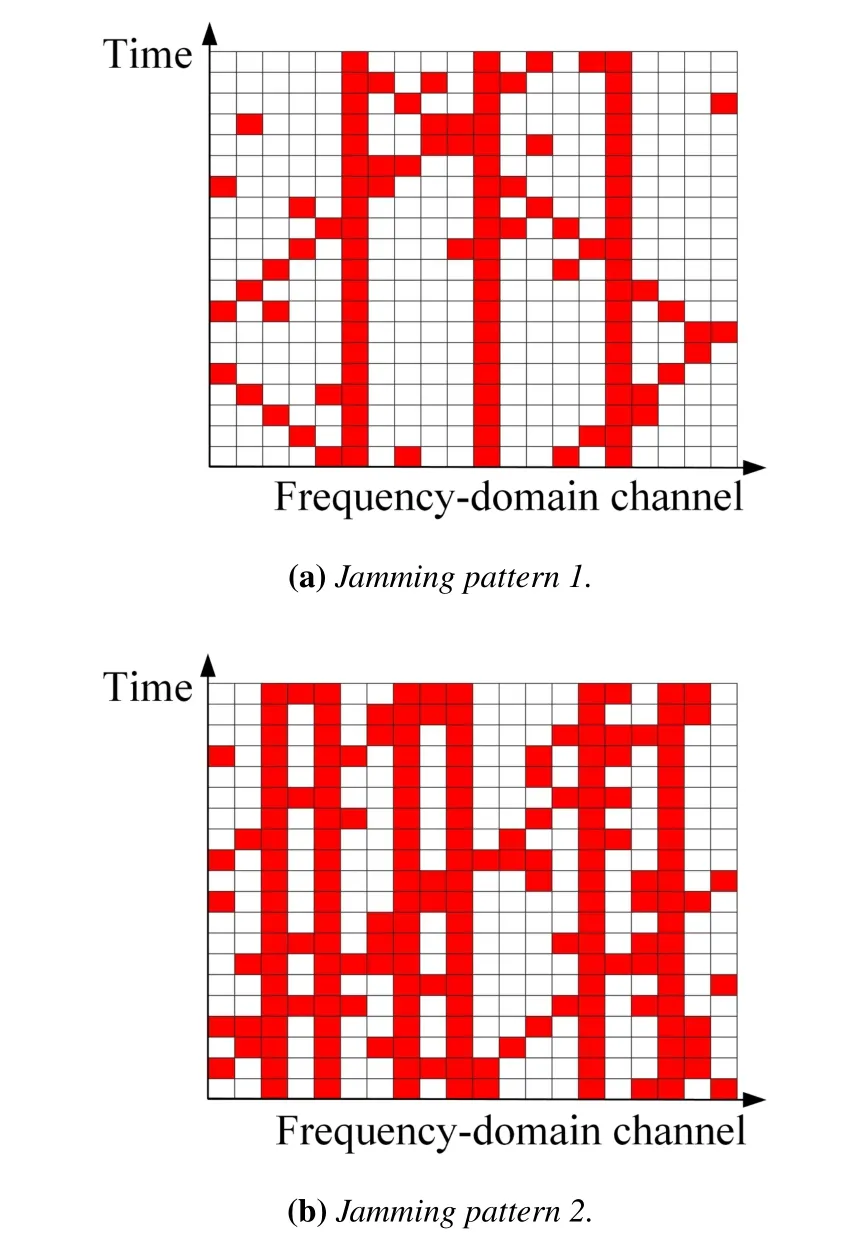
Figure 4.The rectangles in red and white represent jamming signals and no jamming signals,respectively.
When the RD determines that the jamming pattern has changed,it continues to perform the KDA3C algorithm for learning the FP policy.The TL-based algorithm works at global update time i.e.t=mTa,m∈N+.Moreover,we reset hyperparameters for RL(i.e.βq,k,tandβv,k,t).The maximum size ofanddenoted asnq,maxandnv,maxare preset before performing the TL-based algorithm.

and remove thej-thfeature vector from.The matrixshould be updated by removing the corresponding column and row of thej-thfeature vector.Ifj≥2,this problem can be solved by employing the matrix transformation technique[38]:
where Ijis the unit matrix of sizejand 0 is the allzeroes matrix of adequate dimensions.

IV.SIMULATION RESULTS
The proposed algorithm is compared to five baselines:DQN-based method[28],AC method with fixed GKFs (Fixed-AC),kernel-based AC (KAC),kernelbased Q-learning (KQL) [26] and random decisionmaking.
Figure 5 depicts that as the ratios of successful transmission achieved by the RL algorithms converge,those achieved by KDA3C KFTLDA3C,KAC and KQL are higher than 15% of those achieved by the Fixed-AC and DQN,in the presence of the jamming pattern 4a.As the jamming pattern turns into the jamming pattern 4b,it can be seen from Figure 5 that the ratios of successful transmission achieved by KFTLDA3C,KDA3C,KAC and KQL experience a decline,since the learned FP policies can not adapt to the new jamming pattern.Once the change is recognized,KDA3C,KAC and KQL initialize all the sets to learn new policies,while KFTLDA3C performs the TL-based method to adjust the learned policy online.Then,the ratios of successful transmission achieved by the aforementioned four RL-based algorithms start to increase and finally converge to 1.However,compared to the ratio achieved in the presence of jamming pattern 4a,Fixed-AC and DQN respectively achieve lower convergence speed and a lower ratio of successful transmission in the presence of jamming pattern 4b.This observation demonstrates that online feature learning can benefit the RL-based algorithms,such that the FP policies can always be adapt to dynamic jamming patterns.Moreover,the ratio of successful transmission achieved by KQL can converge more quickly than KAC.That is due to the fact that the convergence of the average reward can lead to the convergence of the learned FP policy,due to the straightforward relation between the instantaneous reward and the FP action.
It can be inferred from Figure 5 that the distributed framework can benefit the proposed KDA3C and KFTLDA3C algorithms,such that the convergence speed of the two proposed methods has better performance than other kernel-based algorithms.The reason lies in that theKworkers train the FP policy with the samples from the experience replay buffer.This method can alleviate the effect of correlation between samples and improve the accuracy of the training FP policy.Moreover,as the jamming pattern turns into the jamming pattern 4b,KFTLDA3C adopts the TLbased method to reuse the part of the learned GKF networks,while KDA3C,KAC and KQL remove all feature vectors from sets and train new policies,such that the ratio of successful transmission achieved by the KFTLDA3C can converge to 1 earlier than other algorithms.This can be confirmed by the observation made in Figure 6,where the proposed KFTLDA3C algorithm can remain the number of decision-making features.
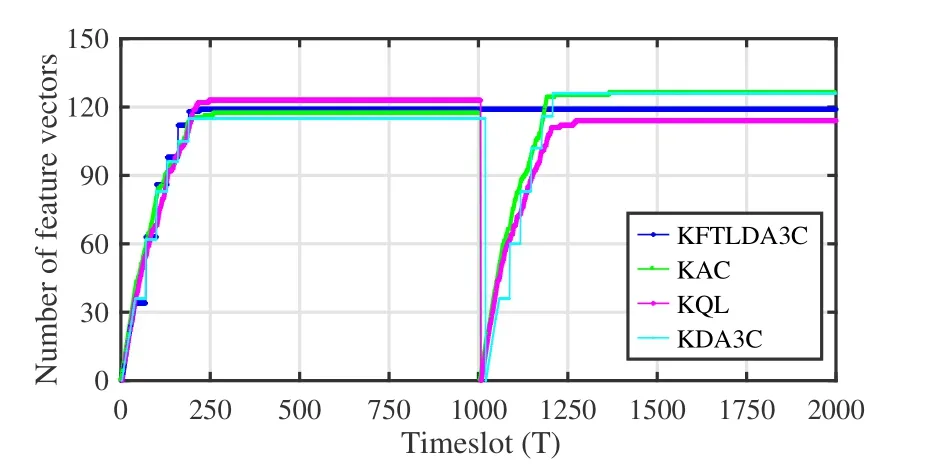
Figure 6.Number of feature vectors of the global policy function.
Figure 7 compares the proposed KDA3C and KFTLDA3C algorithms to various baselines,in terms of the average normalized throughput.All the RL-based algorithms perform better than random decision-making.Thanks to the capability of admitting decision-making features online,the KDA3C,KFTLDA3C,KAC and KQL algorithms can be adaptive to changes in the jamming pattern and dynamically optimize the FP policies.The average normalized throughput achieved by these algorithms converge to higher values than that achieved by the Fixed-AC and DQN algorithms where feature vectors of policy functions are fixed.Moreover,the average normalized throughput achieved by the proposed algorithms is higher than other baselines,while KFTLDA3C achieves the highest value in all algorithms in the presence of jamming pattern 4b.The explanation of the observation is the same as the discussion about the fact that the ratios of successful transmission obtained by the proposed algorithms converge more quickly than those achieved by the KAC and KQL algorithms in Figure 5.Intrinsically,this is due to the advantages of the experience replay buffer and training the FP policy with distributed learning and transfer learning.
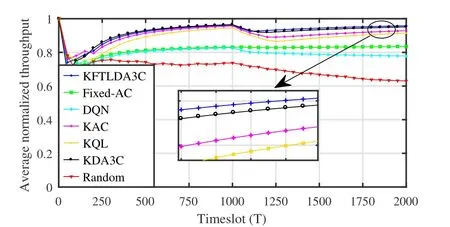
Figure 7.Comparison of the proposed KDA3C and KFTLDA3C algorithms and various baselines,in terms of the long-term average normalized throughput.
In Figure 8 to 10,we analyze the properties of TLbased method,in the presence of three types of the maximum number of feature vectors in the seti.e.Type 1:nq,max-20,Type 2:nq,maxand Type 3:nq,max+20.The proportion of the past and newly obtained feature vectors after exploiting the TL-based method can be derived from the relationship between the similarity of jamming pattern 4a and 4b and the maximum number of feature vectors.Figure 8 depicts that as the maximum number of feature vectors increases,the proportion of past feature vectors becomes larger.Moreover,as the limit of the maximum number of feature vectors decreases,the number of past feature vectors to be removed increases.

Figure 8.Proportion of newly obtained feature vectors and past feature vectors in the set
It can be drawn from Figure 9 that the number of feature vectors remains unchanged after about 6 iterations of global updates.The convergence of the number of feature vectors means that the FP policy is convergence,thus ensuring the algorithm converges.Figure 10 compares KFTLDA3C algorithm in the presence of different types of set sizes.In addition,KDA3C without relearning(WReL)feature vectors and KDA3C with relearning feature vectors(ReL)are also set as baselines.It can be drawn from Figure 10 that Type 2 and Type 3 have better performance than others.Since Type 1 only reuses 10% past feature vectors,it needs more timeslots to learn newly obtained feature vectors and consumes more timeslots to obtain the optimal FP policy that enables the ratio of successful transmission to converge to 1.Moreover,KDA3C with different types outperforms WReL and ReL.WReL only exploits the ALD test to determine whether feature vectors are added to the set.Without transferring,the FP policy with fixed decision-making feature can not adapt to the dynamic jamming pattern,resulting in the worst performance in terms of the ratio of successful transmission.ReL empties the sets(i.e.,Dq,k,tandDv,k,t)and relearns the feature vectors so it takes longer to reach the optimal FP policy.
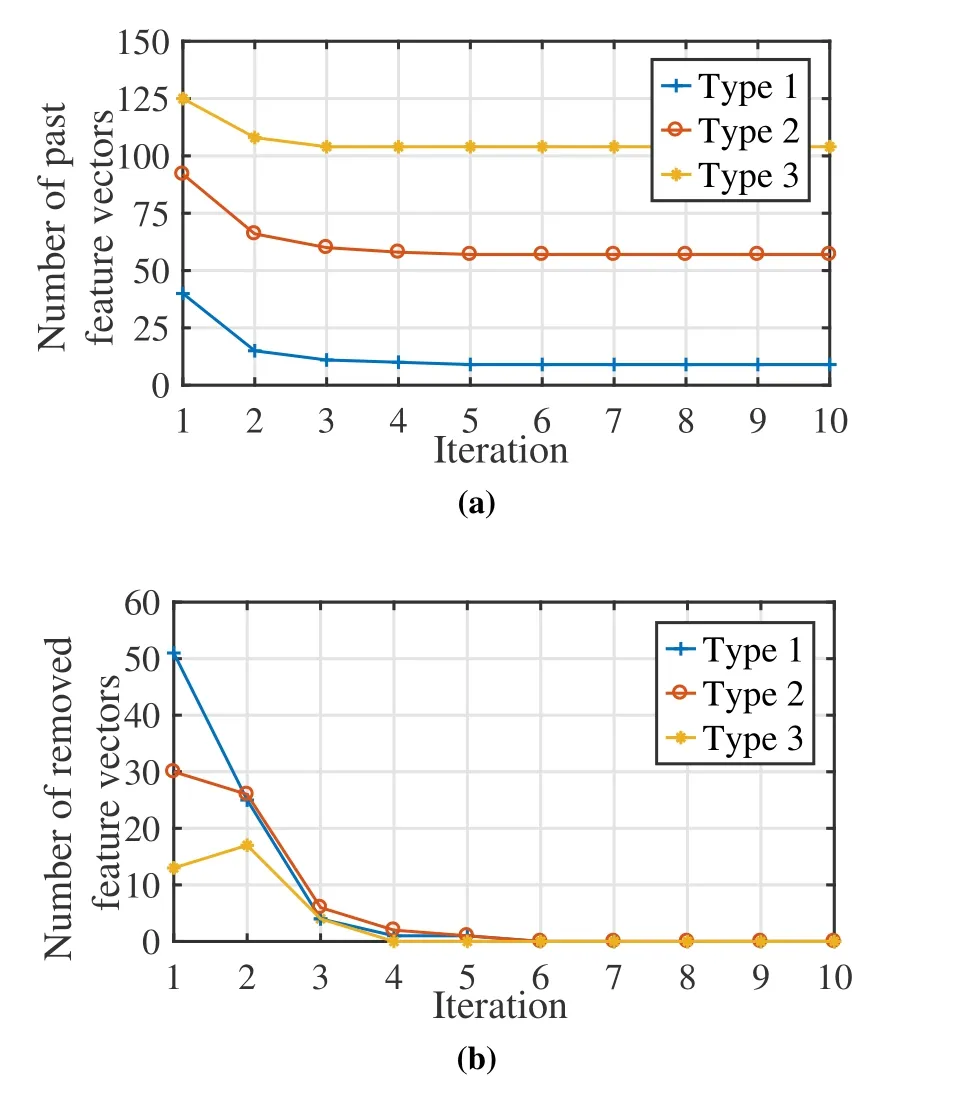
Figure 9.Changes in the number of newly obtained feature vectors and past feature vectors in the set
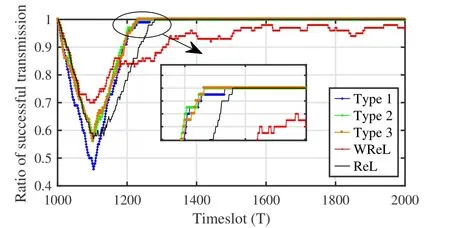
Figure 10.Comparison of different types of TL methods,in terms of the ratio of successful transmission.
In Figure 11 and Figure 12,we compare the performance of the proposed method in the presence of various path loss.Due to decreases in SINR,the RD may not successfully decode the transmit signal,resulting in inaccurate spectrum occupancy extraction.Figure 11 depicts that due to the inaccurate spectrum occupancy state,the proposed algorithm needs more feature vectors of policy functions and state-value functions to do decision-making.Furthermore,the proposed algorithm utilizes inaccurate spectrum occupancy states to do decision-making,leading to poor performance in terms of the total normalized throughput,as shown in Figure 12.The total normalized throughput decreases with increasing path loss.However,the performance of the proposed algorithm is still better than random decision-making in the same path loss.
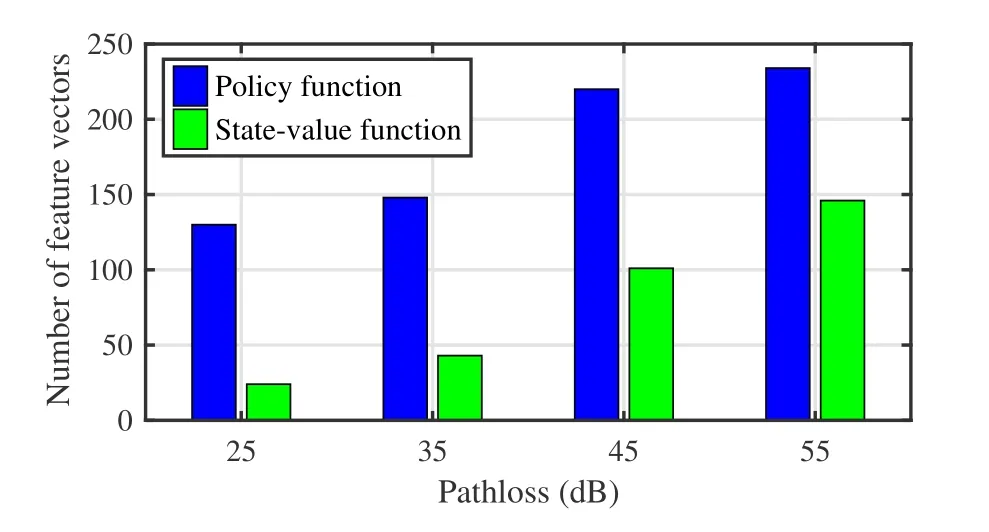
Figure 11.Number of feature vectors in the presence of various path loss.
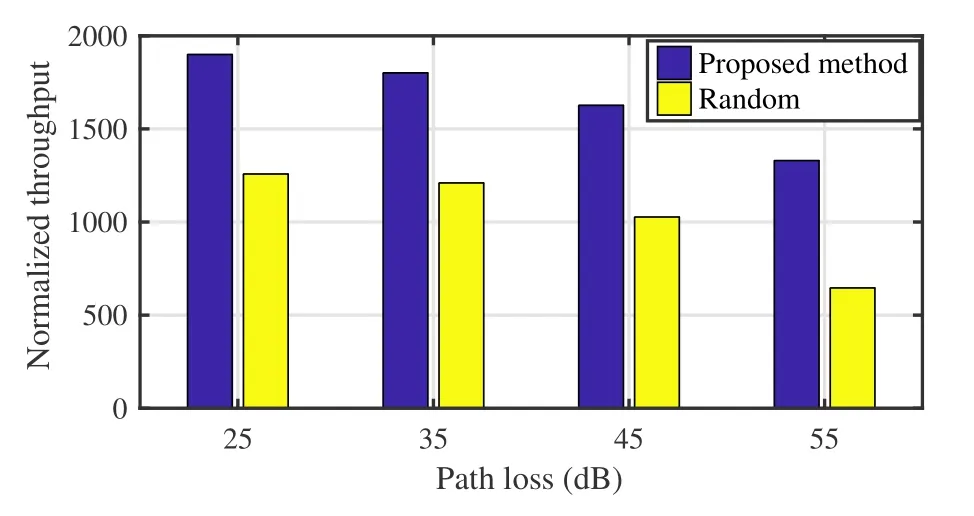
Figure 12.Comparison of the proposed method and the random decision-making,in terms of the total normalized throughput,in the presence of various path loss.
V.CONCLUSION
In this paper,we have proposed an intelligent spectrum AJ scheme for wireless networks.The KDA3C algorithm has been proposed to cope with jamming attacks in the frequency domain.In order to handle the issue of dynamic jamming patterns,we have designed a kernel-based feature TL method to accelerate the convergence speed of policy learning for KDA3C.Simulation results illustrate that KDA3C makes policy learning more efficient and accurate than various baselines.Moreover,KFTLDA3C can reduce the time consumption of policy learning in the presence of changes in the jamming pattern.As a future work,the dynamic spectrum AJ problem in a large-scale wireless network that involves more devices can be further investigated.
ACKNOWLEDGEMENT
This work was partially supported by the National Natural Science Foundation of China under Grant U2001210,61901216 and 61827801,the Natural Science Foundation of Jiangsu Province under Grant BK20190400.

- China Communications的其它文章
- IoV and Blockchain-Enabled Driving Guidance Strategy in Complex Traffic Environment
- LDA-ID:An LDA-Based Framework for Real-Time Network Intrusion Detection
- A Privacy-Preserving Federated Learning Algorithm for Intelligent Inspection in Pumped Storage Power Station
- Secure Short-Packet Transmission in Uplink Massive MU-MIMO Assisted URLLC Under Imperfect CSI
- Multi-Source Underwater DOA Estimation Using PSO-BP Neural Network Based on High-Order Cumulant Optimization
- An Efficient Federated Learning Framework Deployed in Resource-Constrained IoV:User Selection and Learning Time Optimization Schemes