
面向层次结构数据的增量特征选择
2023-12-08 11:48折延宏黄婉丽贺晓丽
计算机与生活 2023年12期
折延宏,黄婉丽,贺晓丽,钱 婷
1.西安石油大学 理学院,西安 710065
2.西安石油大学 计算机学院,西安 710065
在大数据时代,数据标签类型和数量急剧增加,标签之间往往具有某种特殊的关系,其中层次结构[1-3]最具有代表性,包括树结构和图结构。标签具有层次结构的分类问题是当今的研究热点。用层次结构进行大规模分类学习有很大的优势,对于超多类问题,可以利用层次结构将超多类问题分解为多个子类学习任务,能有效提高建模的效率。
基于粒计算思想的分层分类建模是一种符合人脑认知规律的数据建模方法。Bellmund 等人[4]在Science上发表的论文认为人脑认知和思维过程依靠多粒度的知识层次结构完成。Aronov等人[5]在Nature上发表的论文认为人脑的思考和认知过程所形成的知识呈现出一种低维的几何结构。文献[6]给出了一种在样本标记粒度不够细化的情况下利用层次信息进行建模的方法。文献[7]给出了一种能同时体现共有特征与固有特征的分层特征选择方法。在实际应用中,用户需求的多层次/多粒度也决定了挖掘任务的多层次/多粒度特征。而粒计算是模拟人类思考和解决大规模复杂问题的自然模式[8-10]。模糊粗糙集是粒计算中的一个重要模型,因此利用模糊粗糙集对具有层次结构的数据进行粒化处理可以更充分地学习数据中蕴含的信息。
目前,模糊粗糙集[11-12]在处理平面分类(与分层分类相对应)问题中已有许多应用。许多学者将模糊粗糙集理论应用到特征选择(也称为属性约简)中,采用依赖度[13-14]、条件熵[15-16]、辨识矩阵[17]和相对辨识关系[18-19]等作为特征选择的评价指标。基于依赖函数的启发式算法[11]是模糊决策系统求约简的先驱工作。之后Bhatt 等人[20]定义了一个紧凑域来降低文献[11]的时间复杂度。Hu 等人[21]提出了基于信息熵的模糊粗糙集的特征选择算法。为了找到合适的约简,Tsang 等人[22]引入了基于辨识矩阵的方法来处理模糊粗糙集。Chen 等人[18]提出了样本对选择方法来搜索可识别矩阵中的所有最小元素,只使用所有的最小元素来寻找模糊决策系统的约简。Wang等人[14]提出了一种基于模糊粗糙集的特征选择拟合模型,以更好地反映所选择特征子集的分类能力。
模糊粗糙集理论于2019 年首次被应用到分层分类特征选择的研究中[23],文中利用类别之间的层次结构,用排他策略、包含策略和兄弟策略来缩小负样本空间,从而减少求解下近似的计算量,提出基于兄弟策略的依赖度计算算法和特征选择算法。排他策略与平面的分类相同,即如果A 是正样本,A 以外的其他样本是负样本,在该策略下的负样本搜索空间非常大,因此使用合理的策略非常重要,目前大多关注的是兄弟策略,该策略只把A的兄弟节点中样本看作负样本,这种策略考虑的是同层次的横向关系,忽略了不同层次之间样本的关系。包含策略比兄弟策略更复杂,不仅考虑同层的横向关系,也考虑上下层之间的父子关系。然而,已有的研究工作大多关注的是兄弟策略,相比而言包含策略考虑的层次范围更广,可以更好地弥补兄弟策略未能考虑上下层关系的缺点,这也是本文使用包含策略的一个研究动机。
此外,已有的分层分类的特征选择研究大多利用标签的层次关系构建正则项、最小化损失函数和正则项,基于此建立优化模型[24-27]。然而,上述的方法都是针对静态数据集。现实场景中数据是不断动态增加的,相应地,一些基于动态数据信息的增量学习方法[28-32]被提出。然而,这些方法大多局限于平面分类中,分层分类中涉及的较少。Fan 等人[33]介绍了一种基于多核模糊粗糙集的增量层次分类方法,但它们更侧重于目标概念的粗糙近似的更新,而不是特征选择。Luo 等人[34]提出了一种迭代的增量粗糙集方法。而在分层分类下考虑使用包含策略的模糊粗糙集的增量研究也非常必要。
综上,本文研究的动机如下:(1)在分层分类问题中,考虑模糊粗糙集的增量可以更好地模拟现实数据。(2)已有的研究大多针对的是数据标签只分布在叶子节点,现实世界中标签具有任意性,研究标签分布在任意节点更具有现实意义。(3)包含策略能够更好地学习标签之间的层次信息,更适合应用标签分布在任意节点的场景中。
因此,将针对标签具有树结构,且标签分布在叶子节点和内部节点情形的动态数据集,将包含策略应用到模糊粗糙集模型中,基于此研究分层分类的增量特征选择算法。基于文献[23]提出一个基于包含策略的模糊粗糙集模型,设计一个非增量特征选择算法,并引入增量机制,即当有新样本加入时,研究下近似、正域和依赖度的增量更新策略。由此,本文设计一个增量特征选择算法,并提出基于两种不同策略的增量特征选择框架。最后,通过数值实验验证所提算法是有效的。
本文主要贡献如下:
(1)提出基于包含策略的模糊粗糙集模型,并设计基于该模型的非增量特征选择算法;
(2)在该模型中引入增量机制,提出增量更新方法,以及基于包含策略的依赖度更新算法和增量特征选择算法,两个版本的增量特征选择框架;
(3)研究动态数据集,且标签分布在内部节点和叶子节点,使得所提算法适用范围更广。
1 预备知识
本文所使用的符号含义如表1所示。

表1 符号描述Table 1 Symbol description
使用高斯函数[36]来计算模糊T-相似关系:
其中,σ为参数,为x与y之间的距离,a(x)为x在属性a下的值。
序对(Dtree,≺)[23]用来描述决策类的层次结构,Dtree={d0,d1,…,dl},其中d0为根节点,不是真实的类,l是类的个数。“≺”代表“子类”关系且满足以下条件:(1)反对称性∀di,dj∈Dtree,如果di≺dj,那 么dj⊀di;(2)反自反性∀di∈Dtree,di⊀di;(3)传递性∀di,dj,dk∈Dtree,如果di≺dj,dj≺dk,那么di≺dk。
例 1图1 是一个Dtree的示例,Dtree={d0,d1,…,d6},其中d0是树结构的根节点,不是真实的标签,不参与求子孙节点和包含节点的运算。以d1为例,d1的子孙节点为des(d1)={d3,d4},d1的包含节点inc(d1)={d1,d3,d4},d1的包含负节点(d1)={d2,d5,d6}。
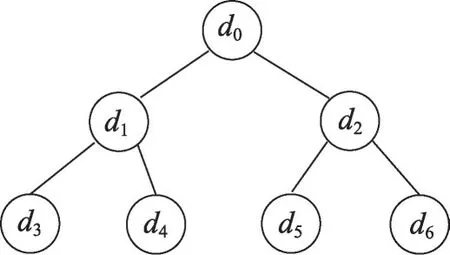
图1 标签的树结构示例Fig.1 Example of tree structure for labels
2 基于包含策略的非增量特征选择
本章先研究基于包含策略的模糊粗糙集模型,基于此,设计非增量依赖度计算算法和非增量特征选择算法。
2.1 基于包含策略的模糊粗糙集模型
在分层分类问题中,负样本只是选取了U中除di其余样本的一部分,因此当x∉di时,不一定满足为了下近似具有更好的性质,将文献[23]中基于包含策略的下近似修正如下。
定义1在分层决策表中,RB是由B⊆C导出的模糊T-相似关系,di的下近似可以定义为:
定义2在分层决策表中,RB是由B⊆C导出的模糊T-相似关系,关于属性集B的正域可以定义为:
通过定义2可以得出以下结论。
由性质1 可知依赖度关于属性集的变化是单调的,这是依赖度可以作为特征选择的评价指标的依据。下面基于定义3 提出一个适用于分层分类的属性约简定义。
2.2 算法
基于包含策略的依赖度的定义,本文提出非增量依赖度计算算法和非增量特征选择算法。
记RB(x,y) 中的 (DB(x,y))2为(x,y)。称为距离平方矩阵。将简记为(Dtree)。
算法1基于包含策略的非增量依赖度计算算法(Inc-NIDC)
算法1 是基于包含策略的非增量依赖度计算算法。第1 步初始化为大于1 的数,第5 步计算距离平方矩阵,时间复杂度为O(|C|);第4~10 步是计算,由于第2 步和第3 步是个双循环,第4~10步被计算了|d1|+|d2|+…+|dl|=|U|次,因此第2~13步的时间复杂度为O(|C||U|2);第14 步是计算关于B的依赖度。综上,算法1的时间复杂度为O(|C||U|2)。
算法2基于包含策略的非增量特征选择算法(Inc-NIFS)
算法2是基于包含策略的非增量特征选择算法。“rem”表示剩余属性,“red”表示属性约简。第2 步是求U的划分,时间复杂度为O(l|U|)。第3 步计算每个di∈U/Dtree的包含负节点和包含负样本,时间复杂度为O(l2)。第4步通过Inc-NIDC计算(Dtree),时间复杂度为O(|C||U|2)。第5~12 步通过Inc-NIDC 计算依赖度,采用启发式思想添加属性,时间复杂度为O(|C|3|U|2)。第13~19 步删除B中的冗余属性直到满足定义4 中的第二个条件为止,时间复杂度为O(|C|2|U|2)。综上,算法2的时间复杂度为O(|C|3|U|2)。
3 基于包含策略的增量特征选择
本章首先研究基于包含策略的模糊粗糙集的增量更新方法,然后基于此研究其增量算法,并基于两种特征选择策略提出两个版本的增量特征框架。
3.1 基于包含策略的模糊粗糙集的增量更新方法
本节首先研究当分层决策表加入一些新样本时,下近似的增量更新方法,进而探究正域以及依赖度的更新方法。
3.1.1 下近似的增量更新
将样本分为x∈U和x∈ΔU两种情况来研究下近似的变化。
(1)情况1:x∈U。
首先寻找U中的下近似可能发生变化的节点。当使用包含策略时,下近似可能发生改变的节点与新加入样本所属的节点有关(这里的节点也是决策表中的类)。从定义1中,可以看到y的范围影响下近似的变化。现假设新加入样本在同一个类dt中,如果di(x∈di) 的包含负样本中含有dt的样本,即dt∈Dtree(des(di)∪{di}),则di的下近似可能改变。由于这些节点关系较复杂,将问题转化为寻找下近似不受加入样本影响的节点。当dt∈des(di) ∪{di}时,di的下近似不会改变。等价于存在新加入样本的类为dt,在anc(dt)∪{dt}中的节点下近似不会发生改变。也就是Dtree(anc(dt) ∪{dt})中节点的下近似可能会发生变化。将所有下近似可能发生变化的节点集合记为
(2)情况2:x∈ΔU。
ΔU是新加入的样本,在原分层决策表中没有计算过x在所属类的下近似中的隶属度,因此需要额外而下近似的变化只与y有关,只判断加入样本后每个节点的包含负节点是否有新加入样本。

表2 原分层决策表的示例数据Table 2 Example data of original hierarchical decision table
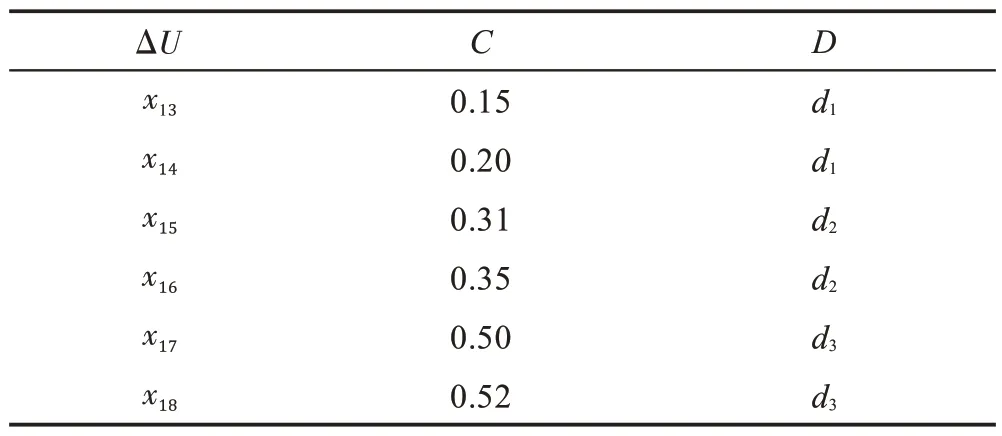
表3 添加样本的示例数据Table 3 Example data of incoming samples

图2 添加样本时树结构变化Fig.2 Change of tree structure while incoming samples
3.1.2 正域的增量更新
3.1.3 依赖度的增量更新
通过定理3 和定义3 可得到以下依赖度的增量更新定理。
3.2 算法
基于模糊粗糙集的增量更新方法,设计一个基于包含策略的依赖度更新算法、增量特征选择算法和两个版本的增量特征选择框架。
算法3基于包含策略的依赖度更新算法(Inc-IDU)
算法3 是基于包含策略的依赖度更新算法。第2~10 步是增量更新S中样本正域的隶属度,对这部分样本的正域隶属度进行求和,时间复杂度为;第11~13 步是计算U-S中样本的正域隶属度之和,时间复杂度为O(|U-S|);第14~19步是计算ΔU中样本的正域隶属度之和,时间复杂度为。综上,算法3 的时间复杂度为
算法4基于包含策略的增量特征选择算法(Inc-IFS)
算法4 是基于包含策略的增量特征选择算法。第2 步求ΔU的类划分,时间复杂度为O(l|U|);第3 步计算,时间复杂度为O(k) ;第6 步通过Inc-IDU“Inc-NIDC+”和“Inc-NIDC-”的时更新依赖度,时间复杂度为间复杂度为O(|U|2),第7~15 步为添加属性策略,从剩余属性中一直添加属性,直到满足定义4 中的条件(1)为止,此时间复杂度为O(|C|2|U|2);第16~23 步为删除冗余属性策略,删除B中的元素,直到满足定义4的条件(2)为止,此时间复杂度为O(|C||U|2)。综上,算法4 的时间复杂度为O(|C|2|U|2)。
综上易得,算法4的时间复杂度小于算法2的时间复杂度。另外,由于算法3的时间复杂度也小于算法1的时间复杂度。
接下来,基于两种策略提出两个增量特征选择框架,用以解决批处理大规模数据集的分层分类问题。先将训练集划分为N份子数据集,当不同的子数据集加入当前数据集T时采用两种不同的策略寻找属性约简。策略1(对应算法5):在每次子数据集加入时只执行添加属性策略,当第N个子数据集都完成上述策略后再执行删除冗余属性策略;策略2(对应算法6):在每次子数据集加入时执行添加属性策略和删除冗余属性策略。
算法5增量算法的框架1(Inc-IFS-v1)
算法6增量算法的框架2(Inc-IFS-v2)
由于策略1 只进行一次删除冗余属性策略,从理论上看,Inc-IFS-v1 的运行时间小于Inc-IFS-v2。
4 实验分析
本章先从运行时间、所选择特征个数、FH测度(基于F1的分层分类准确率度量)[37-38]和平均TIE 四个指标将FFS-HC[23]与本文所提的Inc-NIDC、Inc-IFSv1 和Inc-IFS-v2 进行对比。然后对Inc-IFS-v1 和Inc-IFS-v2 进行参数ε敏感度分析。最后通过实验结果对所提的三个特征选择算法进行评价。
TIE(tree induced error)为树诱导误差[39],TIE 值会随着样本量的增多而变大。平均TIE不受测试样本量影响,可以更好地度量算法性能,因此这里采用平均TIE 来表示算法性能
4.1 实验设计
实验环境:Intel®CoreTMi5-7200U CPU@2.50 GHz 2.71 GHz 12.0 GB,MATLAB R2016a。
数据集:表4 是在分层分类问题中经常使用的数据集,这些数据集的真实标签在叶子节点,由于树结构中父子节点存在语义关系,子节点样本隐含在父节点中,为了构造出本文所研究类型的数据集,把叶子节点中部分样本的标签提升为其祖先节点,并使每个节点中的样本尽可能地均匀分布,此时标签的个数记为d′,如表4 所示。
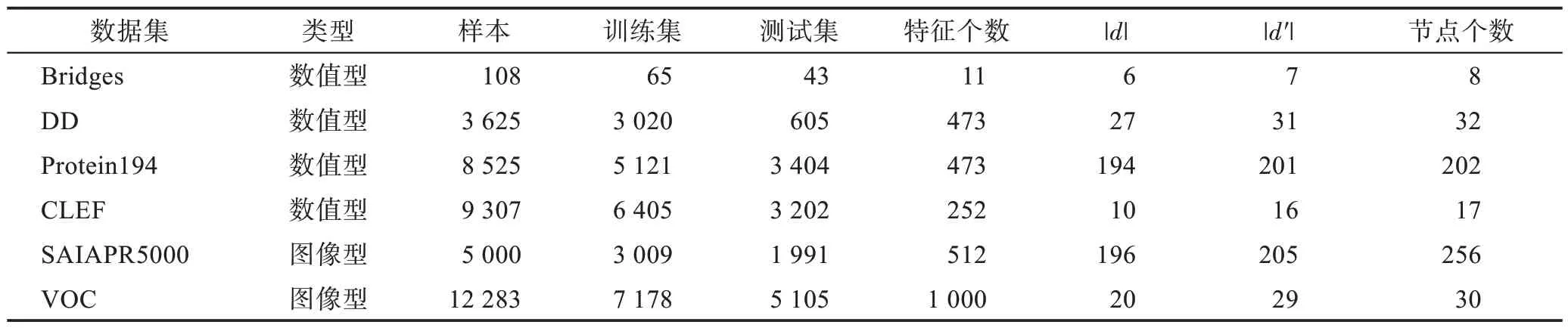
表4 数据集Table 4 Datasets
为了使上层节点具有子节点样本尽可能多的信息,将每个叶子节点中样本按一定比例随机划分份数为dlayer,向上层节点划分。numsamples表示该节点中样本个数,numnodes表示该节点的父节点的子节点个数,dlayer表示需向上泛化的层数。该比例大小也会随着向上泛化的迭代过程而动态变化。这样既使叶子节点均匀,又使上层节点的样本分布均匀,且尽可能均匀地包含下层节点样本,可以避免样本分布的不平衡。
分类器:支持向量机(support vector machine,SVM[40])、K 近 邻(k-nearest neighbors,KNN[41])(k设为常用值3)、随机森林(random forest,RF[42])。
数据处理:(1)对数据集进行最大最小归一化处的层数。该比例大小也会随着向上泛化的迭代过程而动态变化。这样既使叶子节点均匀,又使上层节点的样本分布均匀,且尽可能均匀地包含下层节点样本,可以避免样本分布的不平衡。
分类器:支持向量机(support vector machine,SVM[40])、K 近邻(k-nearest neighbors,KNN[41])(k设为常用值3)、随机森林(random forest,RF[42])。
4.2 四个算法对比
这部分,通过对比FFS-HC[23]、Inc-NIFS、Inc-IFSv1 和Inc-IFS-v2 算法的运行时间、所选特征个数、FH测度和平均TIE 来评价所提的三个算法,结果如表5和图3、图4所示。

图3 4个算法所选特征个数对比Fig.3 Comparison of the number of selected features for 4 algorithms

图4 4个算法的FH值对比Fig.4 Comparison of FH for 4 algorithms

表5 算法FFS-HC、Inc-NIFS、Inc-IFS-v1和Inc-IFS-v2的运行时间对比Table 5 Comparison of running time for FFS-HC,Inc-NIFS,Inc-IFS-v1 and Inc-IFS-v2 algorithms 单位:s
参数设置:Inc-NIFS、Inc-IFS-v1 和Inc-IFS-v2 中令ε=0.01,σ=0.2,N=10。
表5 是FFS-HC、Inc-NIFS、Inc-IFS-v1 和Inc-IFSv2的运行时间。加粗表示运行时间最短。在Bridges数据集上Inc-NIFS 的运行时间最短,这是因为这个数据集太小,而样本又分多次到达,导致增量计算时间较长;而在其他大规模数据集上除了SAIAPR 外,Inc-IFS-v1 的运行时间最短,且与FFS-HC 和Inc-NIFS 的运行时间差距非常大。尤其在VOC 数据集上,FFS-HC 约是Inc-IFS-v1 的7.3 倍,Inc-NIFS 约是Inc-IFS-v1的68.5倍。在SAIAPR5000数据集上,Inc-NIFS 约是Inc-IFS-v1的311.8倍。从实验中也可以看出在所有数据集上Inc-IFS-v1 比Inc-IFS-v2 的时间效率更高。
图3 是FFS-HC、Inc-NIFS、Inc-IFS-v1 和Inc-IFSv2 的所选特征个数。在所有数据集上FFS-HC 所选特征个数小于其他3 个算法;Inc-NIFS、Inc-IFS-v1 和Inc-IFS-v2 所选特征个数基本上区别不大;FFS-HC在SAIAPR5000 数据集上所选特征个数远远小于其他3个算法。
图4 是FFS-HC、Inc-NIFS、Inc-IFS-v1 和Inc-IFSv2 的FH测度,其中PF 表示全部特征,加粗表示4 个算法中FH值最大的。本文分别在分类器SVM、KNN和RF 上对比不同算法的效果。在数据集DD 上,算法之间的FH测度受分类器的影响,4 个算法的FH值在分类器SVM 和KNN 上都大于PF,而在分类器RF上却均小于PF;在VOC数据集上,FFS-HC的FH值在KNN 和RF 上最大,其余数据集上Inc-NIFS 的FH值最大的情况居多,有些情况下,Inc-IFS-v1 最大。在大部分数据集上,Inc-NIFS、Inc-IFS-v1 和Inc-IFS-v2之间的FH值基本一致,相差不超过1 个百分点。因此,可以充分说明Inc-NIFS、Inc-IFS-v1 和Inc-IFS-v2可行并且有效。
表6 是FFS-HC、Inc-NIFS、Inc-IFS-v1 和Inc-IFSv2 的平均TIE 值对比。加粗表示在对应分类器下平均TIE 值最小。平均TIE 值越小,表示算法越好。从全部数据集上看,SAIAPR5000 数据集上的算法的平均TIE 值大于其他数据集,说明在SAIAPR5000 这个数据集上分类误差都大于其他数据集;从算法角度看,在分类器SVM上Inc-NIFS更占优势,但是这些算法差别不大,相差不超过0.3。整体来看,FFS-HC、Inc-NIFS、Inc-IFS-v1 和Inc-IFS-v2 的平均TIE 几乎没有差别。
综合表5、表6 和图3、图4,从运行时间上看,Inc-IFS-v1的时间效果最好,Inc-IFS-v2次之;从分类效果上看,Inc-NIFS、Inc-IFS-v1 和Inc-IFS-v2 都不低于FFS-HC,且3 个算法之间差别不大。综合时间和分类效果,Inc-IFS-v1 能在最短时间内完成特征选择,且最大程度地保证分类精度。
4.3 Inc-IFS-v1 和Inc-IFS-v2 的参数敏感性分析
本节从运行时间、所选择特征个数、FH测度方面分析 Inc-IFS-v1 和 Inc-IFS-v2 的 ε 在{0.05,0.01,0.005,0.001,0.000 5,0.000 1}上的敏感度,参数σ=0.2,N=10,结果如图5~图7所示。
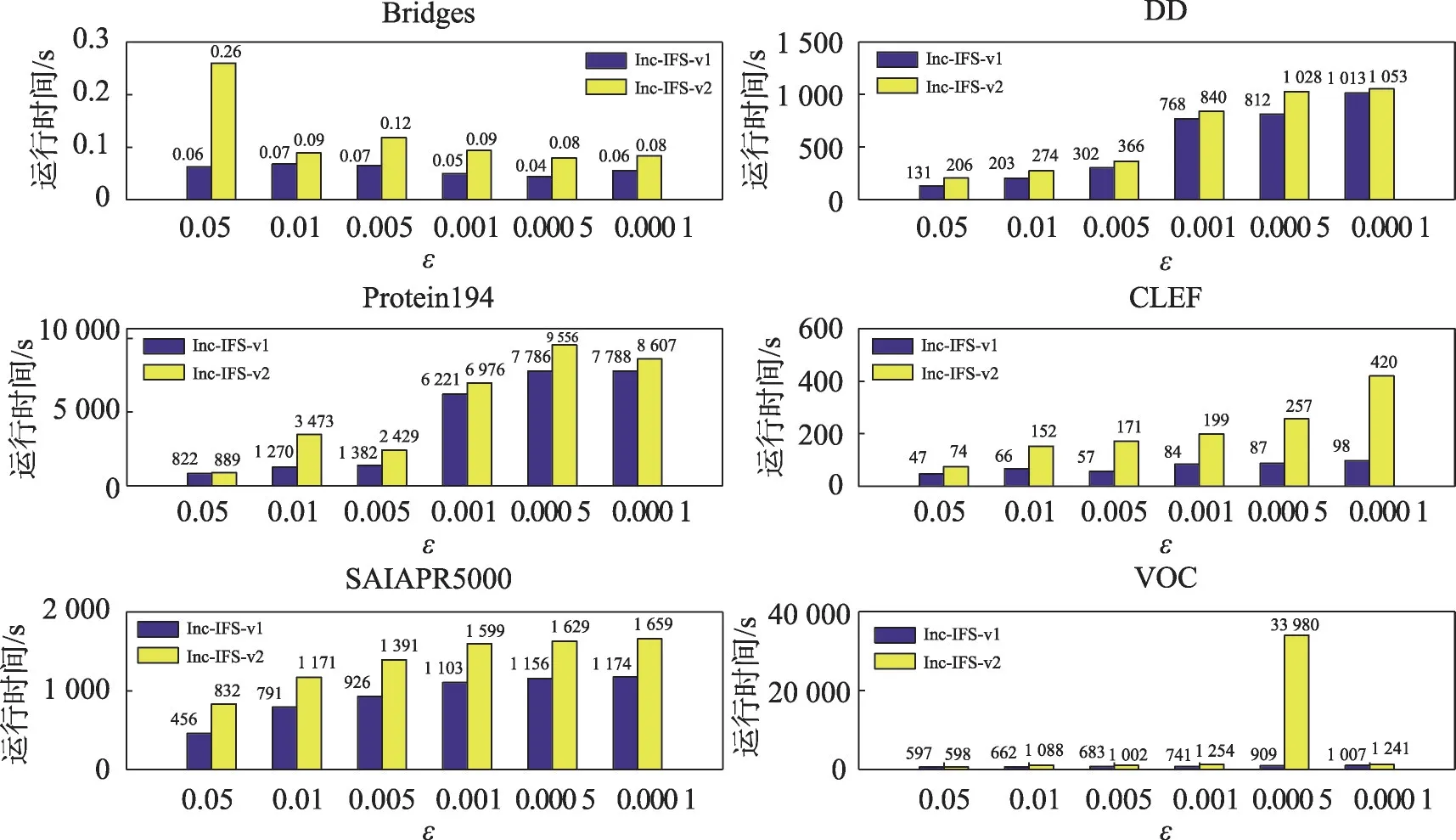
图5 Inc-IFS-v1和Inc-IFS-v2的运行时间对比Fig.5 Comparison of running time for Inc-IFS-v1 and Inc-IFS-v2
图5 是Inc-IFS-v1 和Inc-IFS-v2 随着阈值ε 的减小运行时间的变化。阈值ε越小,而添加属性的条件就越严格,对应的运行时间就越长。在VOC 数据集上,Inc-IFS-v2 的运行时间远远大于其他参数,可能因为在这个参数下每次到达子数据集都会进行添加属性和删除冗余属性策略,而再次增加样本后原属性约简总不满足,需要再次添加属性和删除冗余属性,VOC 有1 000 个属性,会使运行时间差距更明显。综合来看,Inc-IFS-v1 和Inc-IFS-v2 的运行时间随着阈值减小变长,并且Inc-IFS-v1的运行时间总小于Inc-IFS-v2。
图6 是Inc-IFS-v1 和Inc-IFS-v2 所选择特征的个数比较。从图中可以看到,阈值ε越小,属性约简的条件越严格,Inc-IFS-v1 和Inc-IFS-v2 所选择特征的个数越多,且Inc-IFS-v1 和Inc-IFS-v2 所选择特征的个数基本差别不大。在VOC数据集上,当ε=0.000 5时,Inc-IFS-v1只挑选了7个特征,在CLEF数据集上,当ε=0.005 时,Inc-IFS-v2 只挑选了1 个特征。这可能因为这种情况下许多特征作为冗余属性被删除,而这些少量特征仍然符合约简定义。
图7 为Inc-IFS-v1 和Inc-IFS-v2 的FH值。在DD数据集上,阈值ε<0.005 时,Inc-IFS-v1 和Inc-IFS-v2的FH值在分类器SVM 和KNN 上减小。可能是因为随阈值ε减少,所选特征个数变多,多了一些干扰性特征,使得分类精度下降。整体上看,随着阈值ε的减少,Inc-IFS-v1 和Inc-IFS-v2 的FH值呈不明显的上升趋势。综上,Inc-IFS-v1 和Inc-IFS-v2 的分类精度随着阈值ε的变化,敏感性较弱。
综合图5~图7,从时间上看,随着阈值ε变小,Inc-IFS-v1 和Inc-IFS-v2 的运行时间越长,即运行时间的敏感性较大;从所选特征个数和分类精度看,随着阈值ε变小,在有些数据集上分类精度有上升趋势,在有些数据集上没有明显变化。
5 总结与展望
本文给出了包含策略和基于包含策略的模糊粗糙集新的形式化定义,提出了基于包含策略的模糊粗糙集模型,并设计了一个非增量特征选择算法Inc-NIFS。然后引入依赖度的增量机制,设计距离平方矩阵来缩短添加属性过程的时间。由此,提出了增量特征选择算法Inc-IFS,以及两种增量特征选择框架Inc-IFS-v1 和Inc-IFS-v2,两者效率均高于Inc-NIFS,且Inc-IFS-v1的效率最高。
除了样本增加外,还包括特征添加和特征值动态变化的情况。分层分类学习中,可以选择的策略也多种多样,除了包含策略,还有兄弟策略、排他策略、排他兄弟策略、排他包含策略等。这些均可作为未来的研究工作。在未来的研究中,将考虑随着样本到达,基于兄弟策略的模糊粗糙集增量,与本文所提的算法进行对比分析;将研究在特征动态增加的情况下基于包含策略、兄弟策略以及其他策略的增量机制。
猜你喜欢
科教导刊·电子版(2021年6期)2021-05-06
价值工程(2018年20期)2018-08-30
中国人口·资源与环境(2017年12期)2018-01-05
电子制作(2017年23期)2017-02-02
厦门理工学院学报(2016年3期)2016-11-10
广东石油化工学院学报(2016年3期)2016-05-17
西北工业大学学报(2015年4期)2016-01-19
四川师范大学学报(自然科学版)(2015年1期)2015-02-28
软科学(2014年12期)2015-02-03
振动工程学报(2014年4期)2014-03-01
