
基于交叉熵的节点重要性排序算法
2023-12-06 07:50龚志豪代冀阳杨智翔
电子科技大学学报 2023年6期
龚志豪,蒋 沅,代冀阳,杨智翔
(南昌航空大学信息工程学院 南昌 330063)
随着网络科学的发展与进步,复杂系统已深入人类社会的各个领域,复杂网络作为刻画复杂系统的工具,在生态、社会、经济、交通等诸多系统中有着重要影响[1-2]。关键节点影响着网络的结构和信息传递功能,评估关键节点是复杂网络的研究热点[3-4]。一方面,快速准确地识别出关键节点并提供保护机制可提升网络的抗毁性[5]。另一方面,基于关键节点也可以提出更高效的攻击策略[6-7]。因此,设计高效的关键节点评估算法具有重要的理论和实践意义。
近年来,研究人员关于识别关键节点已有许多研究成果,经典的评估算法有基于节点邻近信息的度中心性[8]、基于最短路径数目的介数中心性[9]、基于平均距离的接近中心性[10]以及基于网络位置的K-壳分解法[11]等。其中度中心性虽然简单直接,但对邻居节点的重要性区分度较低,并且考虑的邻近信息有限,因此评估的精确性不高。介数和接近中心性仅考虑信息在最短路径上传播,而实际上传播可能基于其他可达路径,此外基于路径的算法时间复杂度较高,不适用于大型网络。而具有较低时间复杂度的K-壳分解法认为节点重要性取决于所处网络的位置,内核层节点的重要性高于边缘的节点,但对同一壳层的节点却无法进一步区分其重要性差异,并且节点在剥离时会对网络的整体结构信息造成破坏[12]。为弥补经典算法评估的局限性,文献[13]考虑节点与其相邻节点之间的相关性,提出了映射熵来评估网络中节点的重要性。文献[14]通过衡量节点的局部拓扑重合度来刻画节点间的相似性,提出了邻域相似度算法用于评估节点的重要性。文献[15]结合节点的K-壳以及信息熵,根据其分层大小依次进行迭代,可区分内层壳与外层壳中的节点重要性。文献[16]受引力公式启发,将节点的度值作为质量,并将最短路径长度作为距离,考虑了节点的近邻以及路径信息,提出了引力模型算法。文献[17]考虑节点在网络中所处的位置,提出了一种基于K-壳分解法的改进引力模型算法。
熵[18]可用于定量描述信息量的大小,当使用熵理论刻画复杂网络时,信息熵可表征节点的局部重要性,因此,可考虑用子网络的熵来表征网络整体结构的特性。如文献[19]提出了信息熵来评估复杂系统的结构特征,取得了较好的成效。文献[20]改进了K-壳值对信息熵的计算,提出了一种结合节点信息熵与迭代因子的算法。文献[21]基于非广延统计力学,提出了一种局部结构熵来量化复杂网络中的关键节点。文献[22]结合网格约束系数以及节点的K-壳中心性,基于Tsallis 熵提出了一种节点重要性识别方法。
受上述研究启发,本文提出了一种基于交叉熵的节点重要性识别算法CE+(cross entropy),该方法充分考虑了节点自身以及其周围节点信息的整体重要性,CE+的值反映了节点与其近邻节点之间的差异性,并且该算法时间复杂度仅为O(n),适用于大型网络。通过在8 个不同领域的真实网络上进行蓄意攻击实验,并选用7 种不同的节点重要性排序算法作为对比,采用单调性指标[23]、极大连通系数[24]、网络效率[25-26]以及SIR 模型[27]等指标验证了本文所提出CE+算法的有效性和适用性。
1 理论基础
假设无向未加权的网络G=(V,E), 其中V是网络G的节点集合, |V|=n,E是网络的边集合,|E|=m。A=(ai j)n×n通常表示网络的邻接矩阵,若节点i与 节点j相连,则ai j=1, 否则ai j=0。
1.1 度中心性
度中心性[9]是度量重要节点性能最基础的指标,节点的邻居节点数越多,则自身的影响力越大,其定义为:
1.2 介数中心性
当网络中某一节点i存在于其他节点之间的最短路径上并且次数越多时,则说明节点i的关键程度越高,其定义为:
1.3 映射熵
文献[13]考虑节点中所有邻域相关的局部信息,提出了映射熵来评估复杂网络中的节点中心性,定义为:
式中,M是节点i的 邻居集; D Cj是其相邻节点之一的度中心性。
1.4 邻域相似度
文献[14]综合考虑了节点的度值和邻居节点的拓扑重合度,提出了一种基于邻域相似度的评估算法,定义为:
式中,n(i)为 节点i的 邻居节点;若节点b与c无连边,则s im(b,c)=|n(b)∩n(c)|/|n(b)∪n(c)|; 若节点b与c有连边,则s im(b,c)=1。
1.5 改进的K-壳分解法
文献[15]结合K-壳分解法以及节点的信息熵,根据K-壳的分层大小依次进行迭代,每层中选择节点信息熵最高的节点,直到所有节点均被选中为止,定义为:
式中, τ(i)表 示节点i的 邻居集;
1.6 引力模型
文献[16]综合考虑了节点的邻居信息和节点间的路径信息,分别将节点的度值和最短路径长度类比为物体的质量和距离,提出了引力模型算法,计算公式如下:
式中,R表示截断半径,通常为平均最短距离的一半。由于仅考虑了截断半径内的引力,该算法也被称为局部引力模型。
1.7 KSGC 算法模型
文献[17]认为节点在网络中所处的位置是一个重要属性,因此,在K-壳分解法的基础上对引力模型进行了改进,提出了KSGC 算法用于评估节点的影响力,计算公式如下:
1.8 交叉熵
交叉熵[28]广泛应用于逻辑回归模型分析中,其定义为随机分布p和q之间的自信息差异,可用来量化两个变量之间的相似度,通常交叉熵值越大,则两个变量之间的差异性越大,其计算公式如下:
式中,x表示事件包含的信息量。对式(8)同时增减可得:
将式(9)中的前两项对数函数合并可得:
则式(10)可被定义为:
式中,H(p)为 信息熵,表示随机分布p的平均信息量;DKL(p‖q)为 相对熵,同样反映随机分布p和q之间的差异程度。因此,交叉熵作为信息熵与相对熵之和,对于随机变量的信息量及其差异性刻画更加直观。
2 基于交叉熵的节点重要性排序算法
2.1 算法构造
交叉熵可衡量随机变量所包含信息量的差异,类似地,复杂网络中不同节点之间的拓扑信息也存在差异,因此考虑引入交叉熵衡量复杂网络中节点的统计特征。
基于交叉熵的节点重要性排序算法的原理是综合考察节点自身以及其周围节点信息的整体重要性,结合这两种拓扑信息,可利用交叉熵值来量化节点分布之间的差异,若交叉熵值越大,则节点之间分布差异性越大,说明该节点代表性越高,重要性更显著。因此本文提出了基于交叉熵的算法CE+,其定义如下:
式中,j∈Γ(i)表 示节点j是节点i的 邻居节点;Ii表示节点i的异构性。考虑到度中心性可在时间复杂度较低的同时较好地反映节点及其近邻节点所构成子网络的拓扑结构,因此将Ii定义为:
由此,节点之间的异构性可得以良好的表征。在基于交叉熵的节点重要性计算方法中,通过融合中心节点与其局部节点的信息结构并相互交叉考虑,使得节点影响力的差异刻画更为准确。该算法的伪代码如下。

表1 列出了8 种不同评估算法的时间复杂度,分别包括局部、全局以及混合3 个类型的网络信息。其中CE+算法的时间复杂度与DC、LLS、ME 以及IKS 算法同为最低。

表1 不同评估算法的时间复杂度
2.2 示例分析
为初步验证CE+算法的量化分辨率与精确性,构建示例网络如图1 所示。
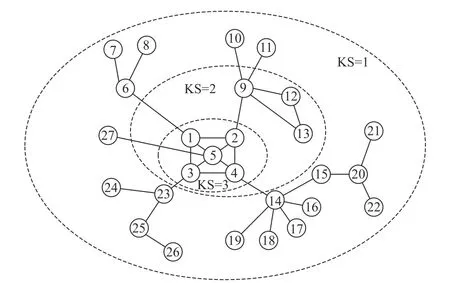
图1 示例网络
在示例网络中,以节点24 为例,其交叉熵计算过程如下:
节点24 的度值为1,其邻居节点23 的度值为3,而节点23 的其余邻居节点3、25 的度值分别为4、2,故计算节点24 的交叉熵值为0.282 4。同理,可以计算示例网络中其他节点的交叉熵值,其计算结果如表2 所示。
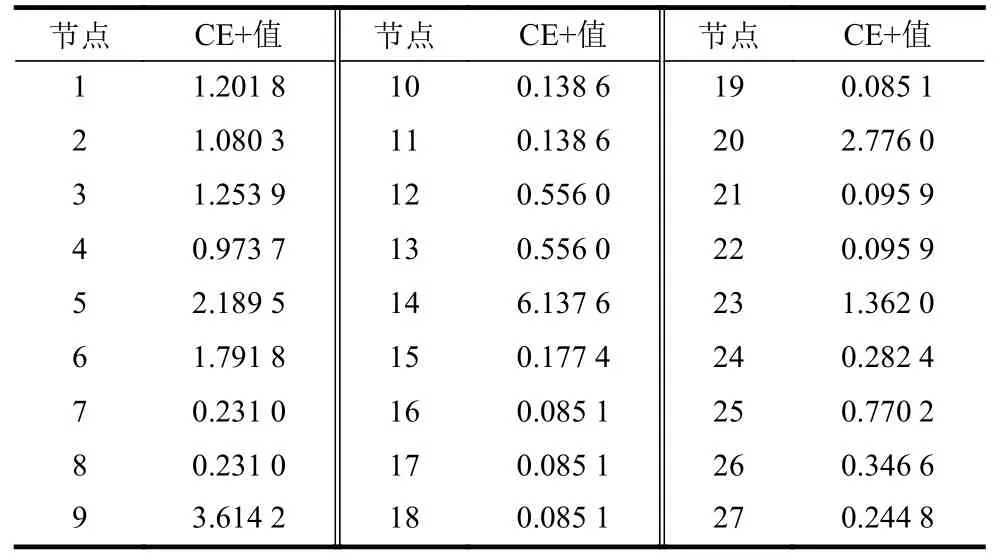
表2 各节点的交叉熵值
表3 记录了不同评估算法对示例网络中节点进行排序的结果,可以看出,KSGC 和GM 算法与本文所提出的CE+算法具有相同的排名广度,但其对首要节点的排序结果略有不同,分别移除节点4、5 和14,得出非连通子图的数量分别为2、2 和6,显然移除节点14 对网络破坏性更大。此外其余算法对网络外围节点的量化区分度较低,过于粗粒化。因此CE+算法对重要节点排序的精确性得到了初步验证。
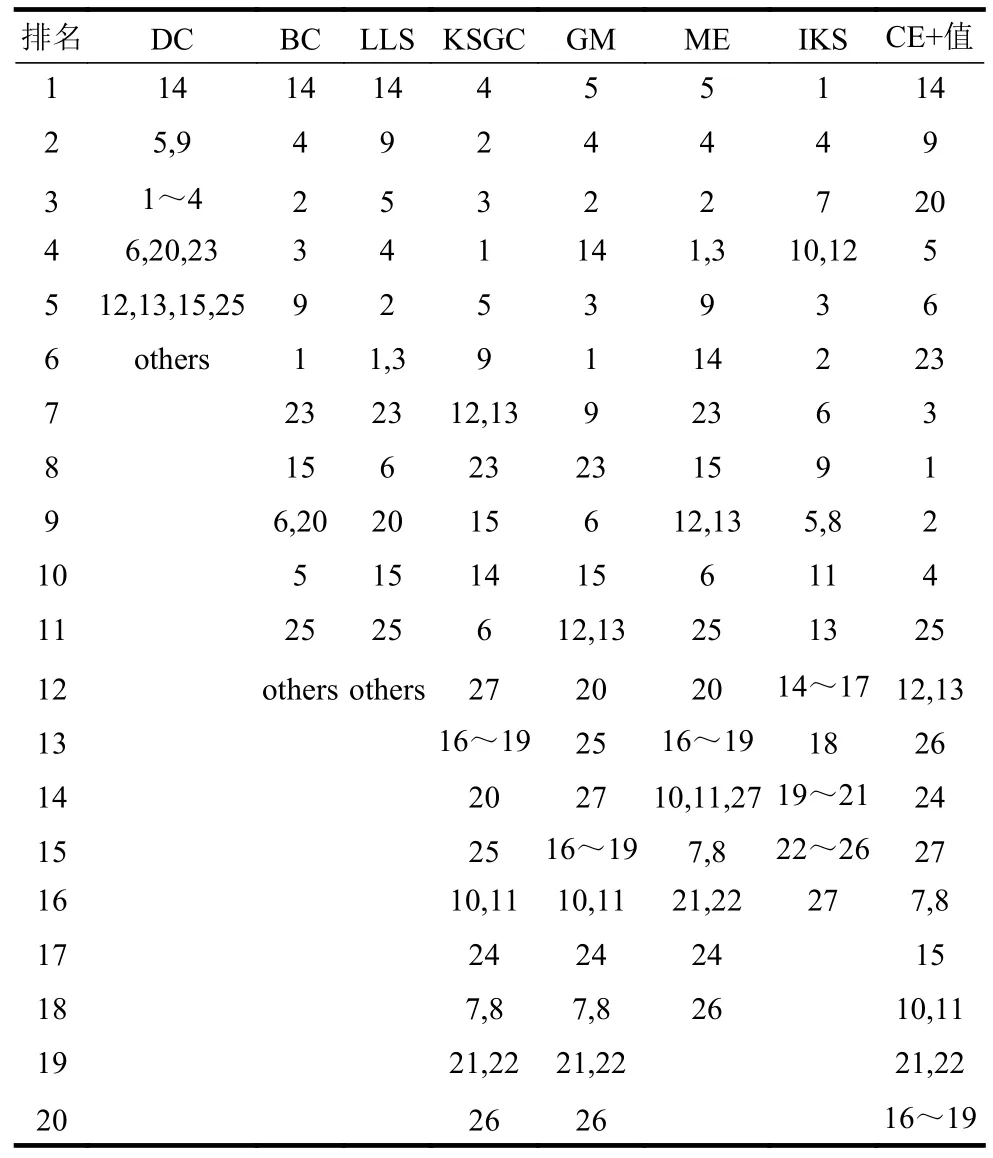
表3 不同评估算法排序结果
3 实验数据集与评价指标
3.1 实验数据集
实验选用了8 个不同领域的真实网络数据集,分别是:维基语录编辑网络Wikiquote[29]、金融网络Economic[30]、约束优化模型网络BP[31]、犯罪案件人物关系网络Crime[32]、大学生电子邮件网络Email[33]、空中交通管制网络Traffic[34]、智人细胞中的蛋白质网络Proteins[35]以及青少年朋友关系网络Adolescent[36]。表4 列出了各网络的拓扑统计参数,其中N和E分别为网络的节点总数和连边总数,D表示网络的密度,kmax表示网络节点的最大度值, 表4 8 个真实网络的拓扑统计特征及传播率 为验证CE+算法的性能,本文基于网络节点的单调关系、鲁棒性以及SIR 传播动力学模型对节点重要性进行研究。首先采用单调性指标定量分析不同算法的分辨率,其次选取极大连通系数以及网络效率指标来评估攻击节点前后网络结构和功能的变化,最后在SIR 模型上再进行传播仿真实验分析。 单调性指标[23]是通过计算节点重要性排序中具有相同排名索引的节点比例来度量节点的评估效果,定义为: 式中,R为经由节点重要性排序算法所得到的排名索引;nr表示具有相同排名索引的节点数量;M(R)∈[0,1], 若M(R)=1,则该算法完全单调,所有节点都具有不同的排名索引值。若M(R)=0,则该算法无法区分,每个节点的排名索引值相同。 极大连通系数[24]常用于评价移除网络中的节点后对极大连通子集的影响,表示为: 网络效率[25-26]常用于度量网络连通性的强弱,计算公式为: 攻击网络中一定比例的节点,若网络效率下降趋势越明显,则该算法的排序准确性越高。 SIR 模型[27]常用于验证节点传播信息与病毒的能力,在SIR 模型中,网络中的所有节点具有3 种状态,分别是易感状态S、感染状态I 以及免疫状态R。病毒传播初始时,除少数节点处于感染状态外,其他节点均处于易感状态。每个时间步长里,感染节点以β 的概率尝试感染易感的邻居节点,此外,感染节点还以µ 的概率尝试恢复为免疫节点,为不失一般性,本文设定恢复率µ =1。需要注意的是,免疫节点不会被再次感染,同样也不具有感染能力。当网络达到稳定时,传播过程结束,此时免疫节点的数量可用于量化初始感染节点的传播能力。 本文选取了度中心性(DC)、介数中心性(BC)等经典算法作为对比方法,还选取了邻域相似度(LLS)、引力模型(GM)、改进的引力模型(KSGC)、映射熵(ME)以及改进的K-壳分解法(IKS)等近期提出的性能显著的排序算法进行比较,记录8 种排序算法在8 个真实网络数据上各评估指标的实验结果。 表5 记录了本文所提出的CE+算法与其他评估算法的单调性指标,加粗数值为最优值,可以看出,CE+算法在大部分网络中均表现出较好的分辨率,并在一些网络(如BP、Adolescent)中达到了1,这说明CE+算法是完全单调的,网络中的每个节点都具有不同的排名索引值。此外,KSGC和GM 算法也表现出良好的区分度。 表5 不同评估算法的单调性指标 图2 呈现了不同评估算法模拟蓄意攻击网络所造成极大连通系数变化的趋势,其中横坐标为各评估算法排序下依次移除节点占节点总数的比例,纵坐标为极大连通系数,可以看出在8 个真实网络中,本文提出的CE+算法均表现出更好的攻击效果。在BP 和Adolescent 网络中,各算法的前期破坏效果出现了高度重合,这是因为网络的连边总数远高于节点总数,导致节点间紧密连接,而当攻击节点数达到一定比例时,CE+算法表现出了较其他算法更为明显的攻击效果。因此,CE+算法度量节点重要性的准确性得到了验证。 图2 8 个网络在各类评估算法攻击下极大连通系数变化 图3 展现了利用不同的评估算法排序依次移除节点后,对网络效率所造成的变化趋势。可以看出,在Wikiquote 网络、Economic 网络和Adolescent网络中,CE+算法相较于其他算法对网络的蓄意攻击效果更为明显,而在Crime 网络与Traffic 网络中,KSGC 和IKS 算法的攻击效果基本一致,ME 和DC 算法分别在移除节点比例达到16%以及18%时,破坏效果最明显。此外,当攻击节点比例相同时,CE+算法的破坏曲线整体下降最快,这说明此时的网络连通性最差。因此,CE+算法度量节点重要性的准确性得到了进一步验证。 图3 8 个网络在各类评估算法攻击下网络效率的变化 为从不同角度评价CE+算法的有效性和适用性,在SIR 模型中再进行传播实验分析,利用各种评估算法排序前10%的节点作为初始感染节点,传播率阈值设定为βth= 图4 反映了各评估算法中重要性排名前10%的节点作为感染节点N随时间步长t的变化趋势,可以看出当时间步长达到15 时,大部分网络趋于稳定,其中CE+算法的传播曲线具有处于稳定状态时的最高高度以及最大斜率,这说明本文所提出的算法具有最广泛的传播范围以及最快传播速率。而在BP 网络中,CE+算法的传播效果与其他算法的差异较小,是因为该网络的节点间分布密集,关联程度较高,信息具有易传播、易扩散的特点。整体来看,CE+算法相较于其他算法更能准确快速地挖掘出网络中影响能力较强的节点。 图4 8 个网络在各类评估算法下感染节点的变化 为比较不同比例的初始节点在传播达到稳态时的规模,本文分别选取模拟迭代1 000 次的Crime网络以及模拟迭代次数100 次的Traffic 网络,并分别选取各种算法排名前5%、15%以及20%的节点作为感染节点进行传播验证实验,实验结果分别如图5 和图6 所示。结合图5 中Crime 和Traffic网络图可知,BC 算法曲线趋于稳态的高度仅在初始感染节点为5%时较高,IKS 算法曲线也仅在初始感染节点比例为20%时具有较大的斜率,而CE+算法在各种比例初始感染节点下均具有显著的传播范围以及感染速率,可知CE+算法在这两方面优于其他算法,由此验证了CE+算法的有效性以及适用性。 图5 不同比例初始节点在Crime 网络上感染节点的变化 在网络科学研究中,识别复杂网络中的核心关键节点有助于提高网络的鲁棒性和抗毁性。本文基于交叉熵提出了一种新的节点性能评价排序算法,算法只需获取中心节点与其近邻节点的信息就可反映节点之间的差异性,并且时间复杂度仅为O(n),适用于刻画大规模复杂网络中节点的重要性。通过在8 个不同领域的真实网络上进行单调关系、极大连通系数、网络效率以及SIR 模型传播实验,结果表明,本文所提的CE+算法对比DC、BC、LLS、KSGC、GM、ME 和IKS 算法具有更高效的性能。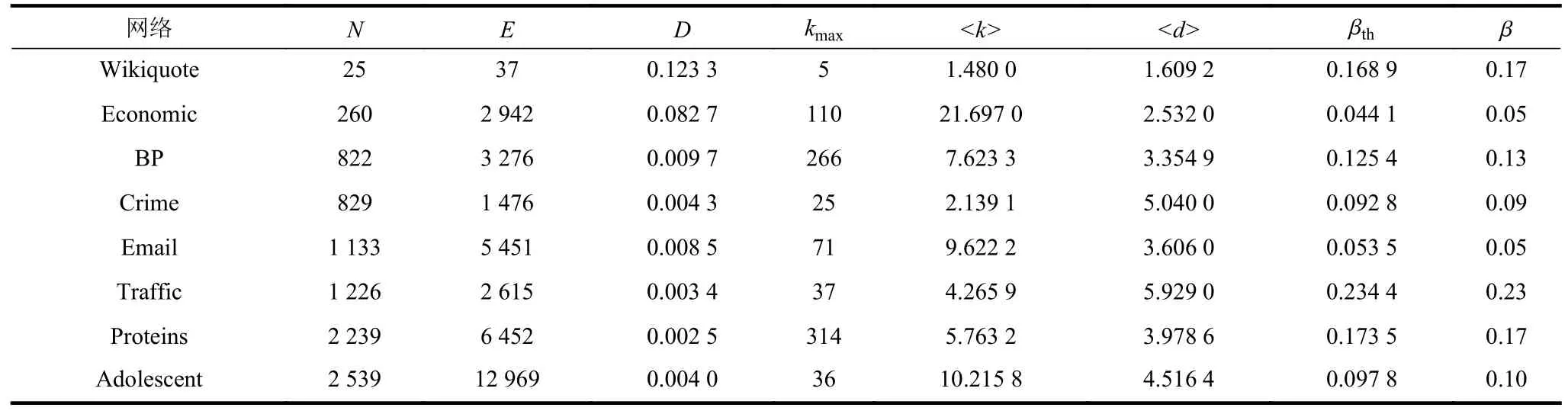
3.2 评价指标
4 实验分析
4.1 单调性指标
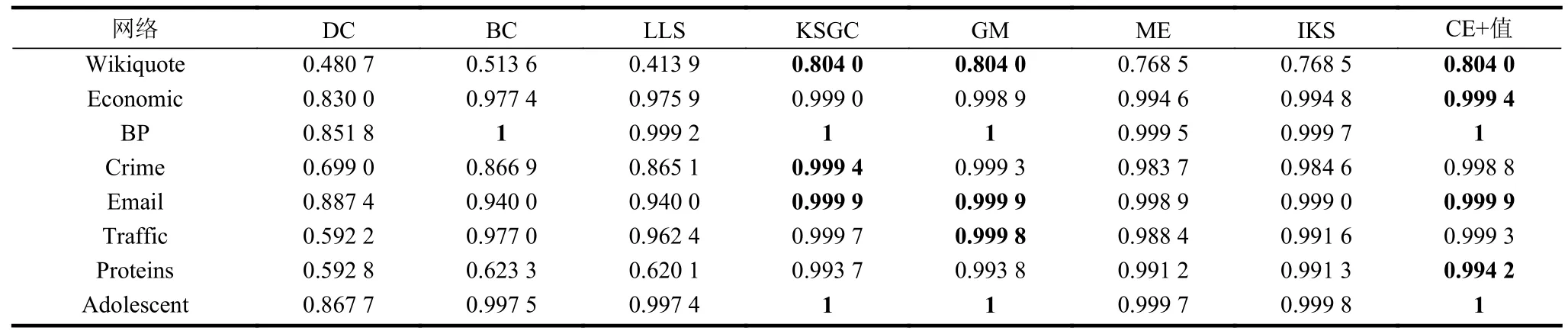
4.2 极大连通系数
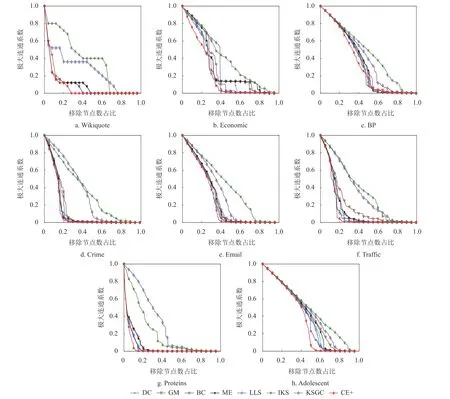
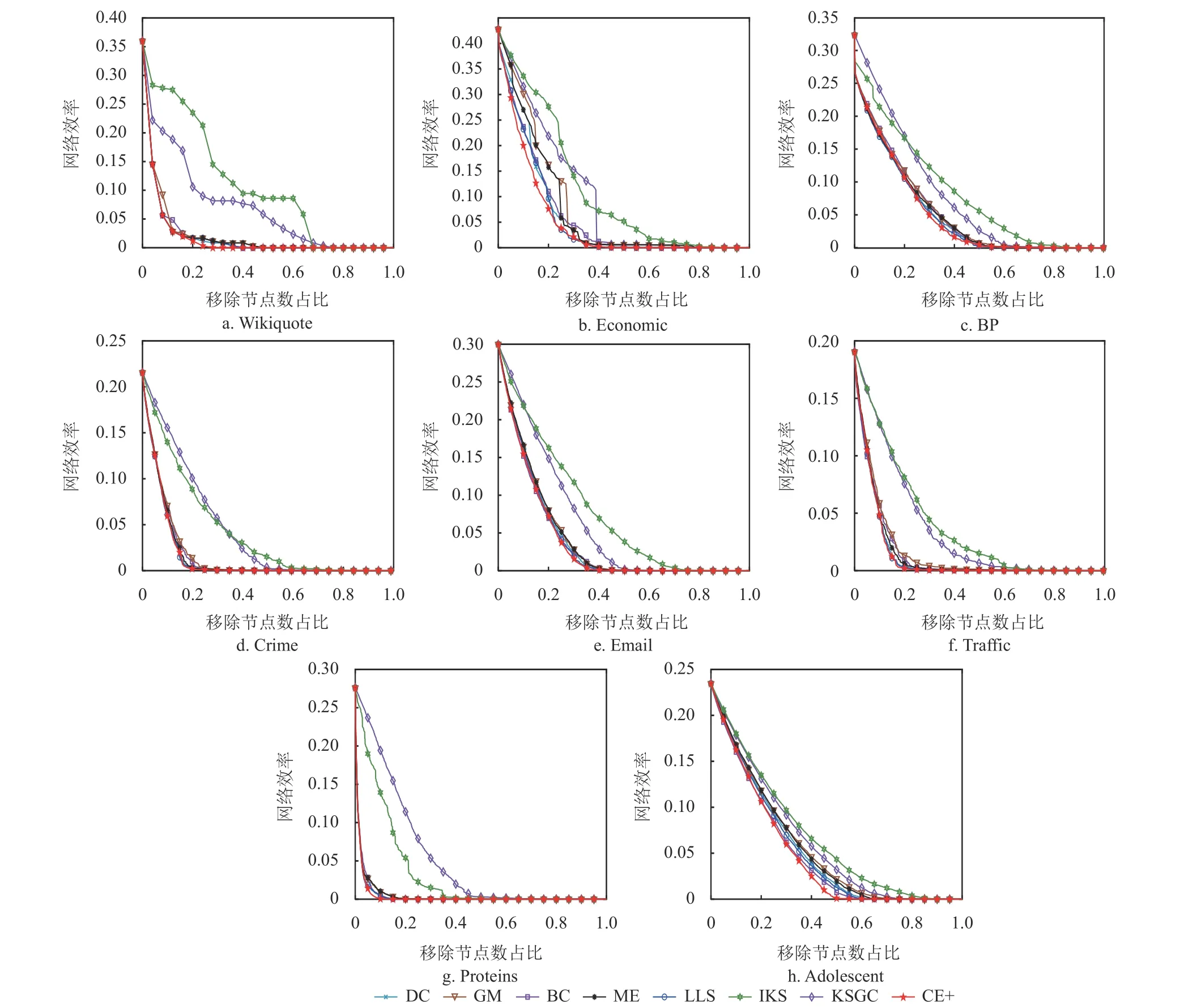
4.3 网络效率
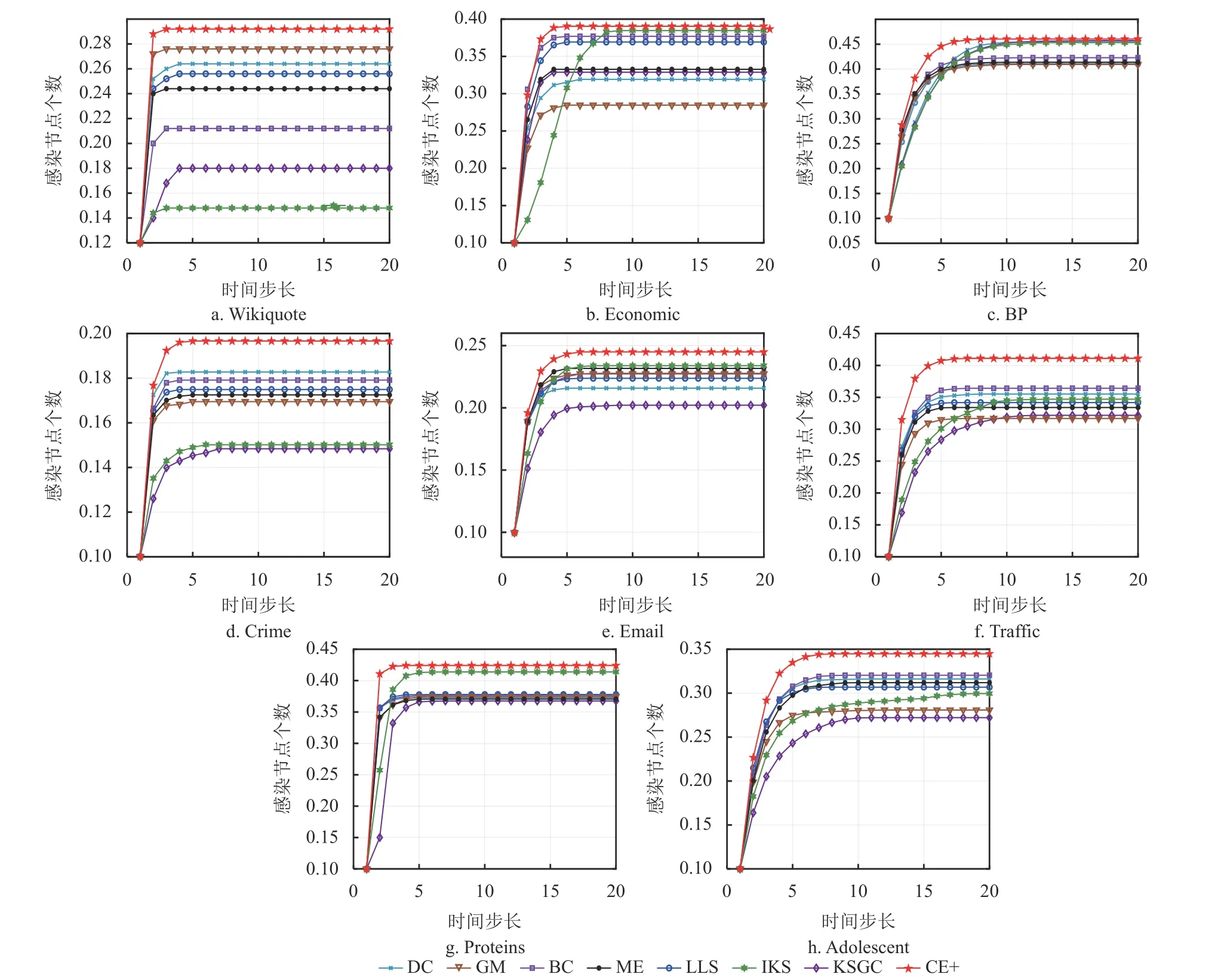
4.4 SIR 模型传播

5 结 束 语
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
数学小灵通(1-2年级)(2021年4期)2021-06-09
中国生殖健康(2020年4期)2021-01-18
科普童话·学霸日记(2020年1期)2020-05-08
甘肃教育(2020年21期)2020-04-13
初中生世界·八年级(2019年6期)2019-08-13
小天使·一年级语数英综合(2019年2期)2019-01-10
小学生导刊(低年级)(2016年6期)2016-07-02
唐山文学(2016年11期)2016-03-20
计算机工程(2015年8期)2015-07-03
