
基于边缘感知深度残差网络的带钢表面缺陷检测
2023-12-04 02:58沈坤烨周晓飞费晓波陈雨中张继勇颜成钢
应用科学学报 2023年6期
沈坤烨,周晓飞,费晓波,陈雨中,张继勇,颜成钢
杭州电子科技大学自动化学院,浙江杭州310018
人眼具有从场景当中提取显著区域的能力。显著性检测旨在借助计算机模拟人眼的功能,找到场景当中人眼最感兴趣的区域。作为一项基础技术,显著性检测在目标检测[1]、图像/视频分割[2]、视频质量评价[3]和人体姿态估计[4]等领域中均受到了广泛应用。
近年来,涌现了众多显著性检测模型,显著性检测的性能得到极大提升。其中,传统的显著性检测方法大多依赖于底层线索(如颜色、形状、纹理等)构建模型,对图像进行显著性检测。主要可分为基于全局和局部对比的方法[5]、基于稀疏理论的方法[6]、中央-环绕差异机制[7]、对比特性与局部清晰特性[8]等。基于机器学习的显著性检测方法通过手工提取图像当中的对比度和颜色空间分布等特征,利用机器学习算法对图像当中的显著性目标进行检测。常见的有基于滑动窗口和带通滤波的方法[9]、基于随机森林回归算法的方法[10]和基于条件随机场的方法[11]。与上述方法不同的是,基于深度学习的显著性检测方法通过学习目标的高级特征构建模型进行显著性检测。例如,早期的有基于多尺度的卷积神经网络(convolutional neural network,CNN)模型[12]和渐进式表示学习的方法[13],通过采用CNN 提取图像中的高级特征,对显著性区域进行检测。后续大部分工作开始采用全卷积的神经网络来进行显著性检测任务,如融合全局语义信息和局部高分辨率信息的方法[14]和基于多尺度的注意反馈模型[15]。
尽管显著目标检测模型在常规图像领域已取得了卓越的效果,但对于特殊场景下的图像,其检测效果尚未能达到预期要求。于是研究人员对特殊场景下的显著性检测展开了研究,如遥感图像显著性检测[16]、对于360◦全景图像的显著性检测[17]、伪装图像的显著性检测[18]、文献[19] 提出的针对钢铁表面缺陷显著性检测任务。这里,本文聚焦于针对缺陷图像的显著性检测任务。
相较于传统图像,钢铁表面图像截然不同,存在诸如前景与背景区分度低、缺陷区域不规则且边缘过于精细、背景复杂、缺陷区域尺寸多变等现象。早期的方法常采用人工的方式对钢铁表面进行缺陷检测,耗时长、准确度低且人工成本高。为此,研究人员提出了针对钢铁表面缺陷的显著目标检测模型。文献[19] 针对于钢铁表面图像的特点,专门设计了EDRNet 模型,通过通道加权模块,加强了对缺陷区域的检测能力;但其忽略了边缘信息对缺陷区域的有效表征,导致预测结果不能很好地区分前景与背景,且预测结果的边缘粗糙。
基于此,本文针对钢铁表面缺陷,提出了边缘感知深度残差网络,用于钢铁表面缺陷的显著目标检测,从而较好地凸显缺陷区域。具体包括:1)在编码器当中引入了注意力机制,用于增强编码阶段网络对图像中不同位置区域的刻画能力;2)设计了一种基于高级语义信息提取边缘特征的方法,以此提取高质量的边缘信息,从而指导解码器获取最终的预测图,其中,边缘信息的引入有助于区分前景与背景并细化预测图的边缘,从而提高预测结果的质量;3)将残差结构引入边缘提取模块与解码器的基本块当中,以此进行边缘提取和显著特征融合,在保证预测精度的同时,提高了收敛速度。本文提出的模型收敛速度快,能够有力区分前景与背景,且能够细化预测图边缘,取得更精准的预测结果。本文进行了丰富的实验,可以看到本文提出的模型在公共数据集SD-saliency-900 上与15 个主流模型对比,在6 个指标上均取得最优结果。
1 基于边缘感知深度残差网络
1.1 整体架构
本文提出的模型以U-Net[20]为基础网络。具体网络结构如图1 所示,主要由多尺度特征提取模块,边缘提取模块和显著特征融合模块3 部分组成。
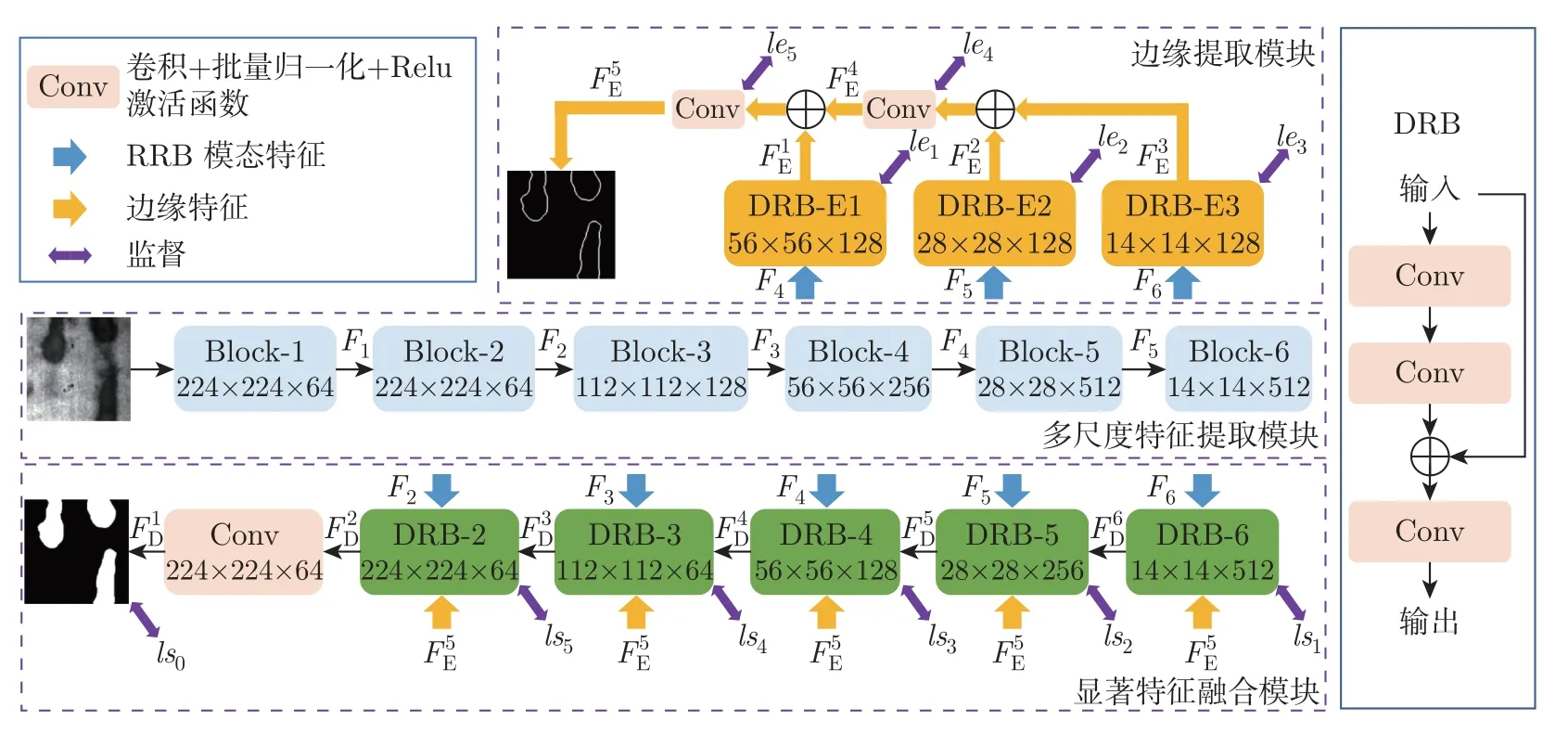
图1 用于钢铁表面缺陷显著性检测模型总体框架Figure 1 Overall framework of saliency detection model of strip steel surface defects
1.2 多尺度特征提取模块
本文多尺度特征提取模块是基于ResNet34 构建的,它由6 个卷积块组成。相邻块之间由最大池化层进行连接,用于获得输入图像的多尺度特征。为了减少信息的损失,选择用一个由64 个卷积滤波器组成的卷积层,替代了ResNet34 的第1 层。卷积核大小设置为3×3,步长设置为1。第2∼5 各模块均采用ResNet34 中的Conv2_x,Conv3_x,Conv4_x 和Conv5_x。最后,为了能够充分地提取高级语义特征,我们在第6 层添加了1 个由3 个卷积块构成的基本块。卷积块由2 个卷积层组成,每个卷积层的卷积滤波器数量为512,卷积核尺寸与步长分别为3×3 和1。同时,为了增强多尺度特征提取模块对于图像中不同区域特性的刻画能力,将高效通道注意力[21]引入该模块的各层中,用以获取高效特征表示。由此,我们可以得到多尺度特征{F1,F2,F3,F4,F5,F6}。其中,第1 层获得的特征F1的分辨率较低,不能有效地应用于后续卷积块中。于是将其舍弃,并将剩余特征传递给后续卷积块,用于提取边缘信息,以及解码生成显著性图。
1.3 深度残差模块
对于多数深度学习模型而言,解码器部分的基本块由3 个卷积层组成。但同时我们在训练过程中注意到,3 个卷积层叠加的结构使得模型收敛速度较慢,延长了训练时间。为此,在边缘提取和显著特征融合两模块中引入了深度残差模块,具体模块对比如图2 所示。图2 左边为常规基本块,其由3 个基本单元组成。(f1,f2,f3) 每个基本单元由卷积核尺寸为3×3,步长为1 的卷积层构成,后接有批量归一化操作以及Relu 激活函数。在此基础上,引入了残差结构,该结构可被归纳为
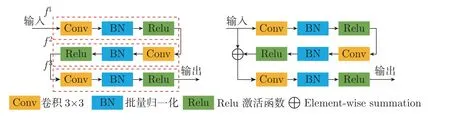
图2 常规模块与深度残差模块Figure 2 Conventional block and deeply residual block
式中:F为深度残差模块的输出;x为模块的输入;⊕表示相加;fi表示基本单元,i=1,2,3;Conv3×3表示卷积核大小为3×3,步长为1 的卷积层;BN 表示批量归一化操作;δ为Relu 激活函数。
实验结果证明,该结构在不增加参数量和不降低检测精度的前提下,极大地提高了网络训练效率,实验结果将在2.4 节详细论述。
1.4 边缘提取模块
通过对钢铁表面图像的观察可知,钢铁表面图像的显著目标区域(即缺陷区域)与背景区域的对比度较低,而且背景复杂,这使得模型难以有效区分缺陷区域。同时,我们也注意到边缘信息不仅能够体现物体边缘细节,而且还蕴含了丰富的物体位置信息。因此,我们尝试引入边缘特征,以此区分目标区域与背景区域,并提高预测图边缘质量。同时,参考已有的引入边缘信息的显著目标检测模型[22],设计了新的边缘提取模块。我们尝试利用更多语义信息来挖掘边缘特征,即采用多尺度特征提取模块提取的后3 层语义信息来生成边缘特征。在此基础上,将边缘特征应用到显著特征融合模块当中。
具体地,边缘提取模块架构如图3 所示,由多尺度特征提取模块得到的后3 层特征{F4,F5,F6}被分别输入3 个深度残差模块用于提取多尺度的边缘特征
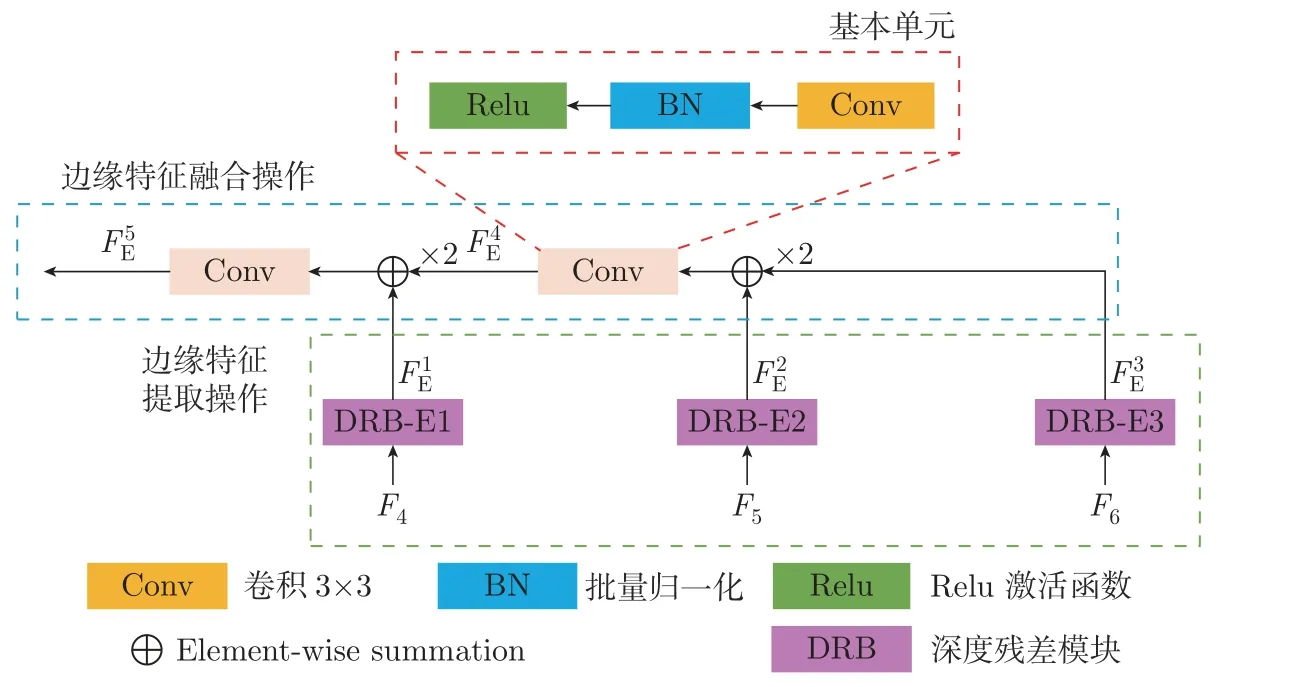
图3 边缘提取模块结构Figure 3 Boundary extraction module structure
然后,对提取到的多尺度的边缘特征进行边缘特征融合操作,该过程可表示为
1.5 显著特征融合模块
在得到多尺度特征{F2,F3,F4,F5,F6}与最终的边缘特征之后,需逐步融合特征,并得到最终的显著性图。这里,我们采用U-Net 的解码器,设计了显著特征融合模块。接下来,我们将详细介绍显著特征融合模块的具体结构与方法。
如图4 所示,显著特征融合模块由6 层组成,前5 层均为深度残差模块,用于融合来自前一层的显著特征、多尺度特征以及边缘特征。我们还在这之后添加了一个卷积核为3×3,步长为1 的卷积层作为整合操作,用于处理融合过后的显著特征。由于最后一个卷积块整合了来自DRB-2 的显著特征,且输出特征具有与输入图像相同的空间尺度,因此其输出被用于获得最终的显著性图。该过程可被归纳为
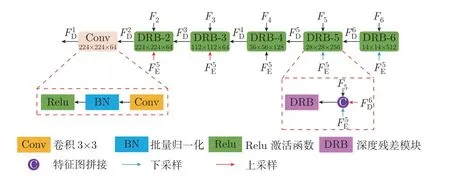
图4 显著特征融合模块结构Figure 4 Salient feature aggregation module structure
2 实 验
2.1 数据集及预处理
本文所提出的网络在钢铁表面缺陷检测公开数据集SD-saliency-900 上进行训练,该数据集包括900 幅图像,其中包含三类缺陷,分别为夹杂物、斑块和划痕,每类300 幅。这里,从每类缺陷中随机抽取180 幅图像,依此可获得540 幅图像;同时,对于前述540 幅图像,每个类别随机抽取90 幅图像,并对其进行加噪处理(椒盐噪声(ρ=20%)),由此可得加噪图像270 幅。这样,训练集共含有810 幅图像。训练时对所有图像统一调整为256×256,之后随机裁剪为224×224,用于提高模型鲁棒性。
2.2 实验设置
本文所提出的模型利用Pytorch 框架在一台装有NVIDIA GTX 2080Ti GPU 的服务器上进行训练。在训练过程中,采用交叉熵损失函数计算预测图与真值图之间的损失。在现有模型中,如文献[23] 采用了多监督机制以提升检测能力。受此启发,我们也将多监督的机制引入模型当中。多尺度特征提取模块主干部分为ResNet34[24],采用在ImageNet 上预训练的参数进行初始化,模型其余参数采用随机初始化。初始学习率为0.001,使用Adam 优化器[25]进行优化操作。本文数据集采用钢铁表面缺陷检测公开数据集SD-saliency-900[19],训练过程经过790 轮,共320 000 次迭代。
2.3 评估标准
本文采用6 个常用的指标来评价所提出模型性能,分别是准确率-召回率曲线(precisionrecall,PR)、F 值(F-measure)曲线[26]、平均绝对误差[27](mean absolute error,MAE)、加权F 值[28](weighted F-measure,WF)、结构性度量[29](structure-measure,SM)和Pratt品质因数[30](Pratt’s figure of merit,PFOM)。其中Pratt 品质因数常被用于评价预测图的边缘质量,广泛应用于检测结果边缘质量的评估,计算为
式中:PFOM 表示Pratt 品质因数;NG和NS分别表示真值图和预测图经过二值化处理后得到的实际边缘点的数量;α为比例常数,通常设置为0.1;dk表示真值图与预测图实际边缘点之间的欧氏距离。
2.4 实验结果
为了证明本文提出模型的有效性,本文与15 个主流模型进行了对比,其中包括RCRR[31]、2LSG[32]、BC[33]、SMD[34]、MIL[35]、PFANet[36]、NLDF[37]、DSS[38]、R3Net[39]、BMPM[40]、PoolNet[41]、PiCANet[42]、CPD[43]、BASNet[23]和EDRNet[19]。将以上基于深度学习方法的模型在本文所用训练集上重新训练,并将在测试集上得到的实验结果与本文实验结果进行对比,实验结果如表1 所示。从表1 中可以观察到,与其他模型相比,本文模型在3 种椒盐噪声干扰的情况下,4 个评测指标均取得了最好的效果。当前最优的EDRNet[19]在ρ=0% 时,MAE、WF、SM、PFOM 分别为0.013、0.923、0.937 和0.913,而本文模型在这4 个指标上分别为0.012、0.925、0.942 和0.915 均高于现有检测算法得到的评价结果。尤其对于ρ=20% 时,在这4 个指标上,本文模型相比于EDRNet[19],MAE 下降了17.8%,其余3项指标分别提升了1.7%、1.6% 和1.6%。实验结果证明,本文模型相比于现有方法具有更好的检测精度。
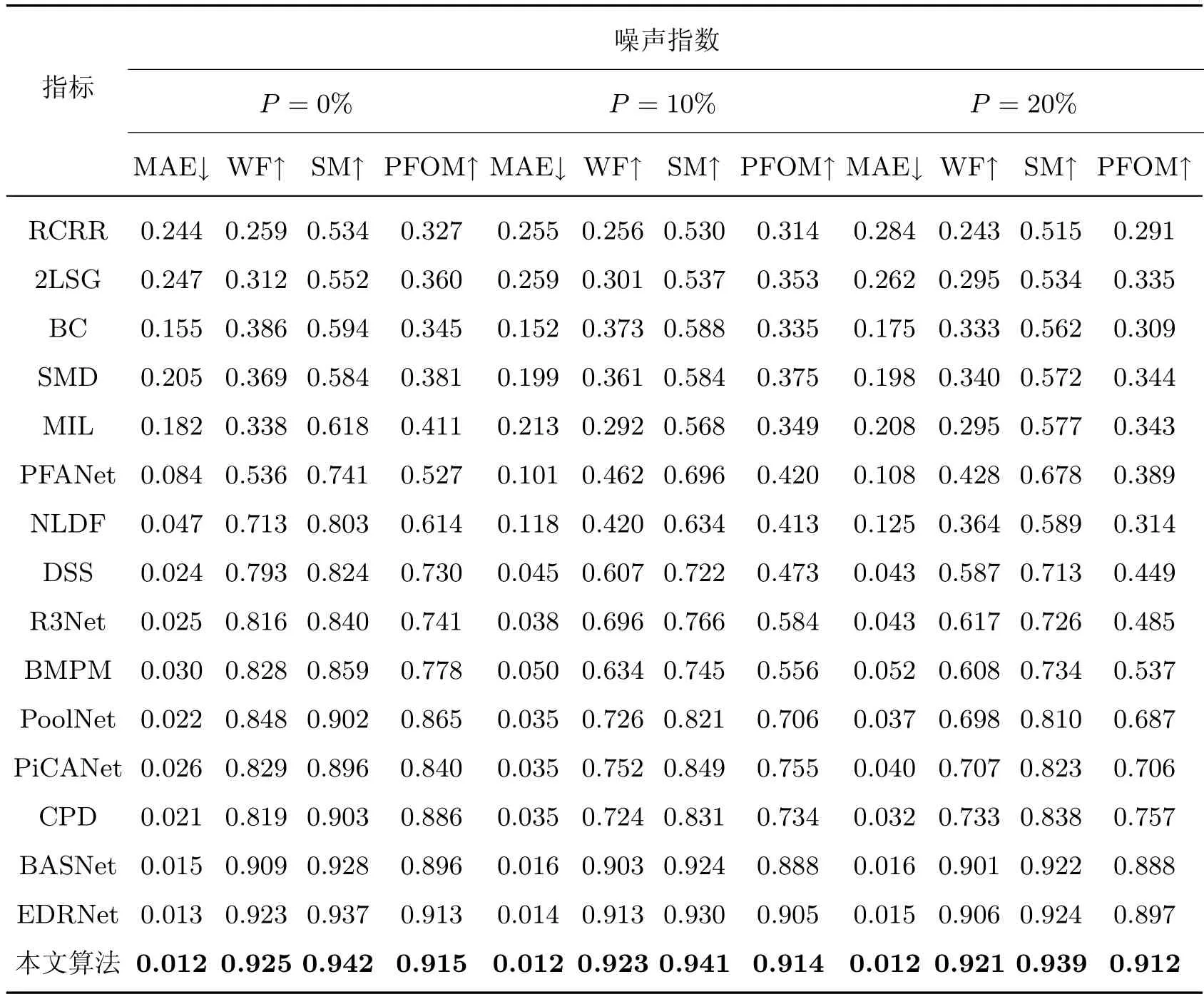
表1 各方法对比结果Table 1 Comparison results of each method
为了验证本文所提模块的有效性,去除了相应模块分别进行训练,得到了4 组消融实验结果。如表2 所示,当模型具有所有结构时,性能最佳。我们发现模型缺少高效通道注意力机制、边缘模块和深度残差模块,平均绝对误差(mean absolute error,MAE)评测结果分别下降了2.6%、4.3% 和2.6%。同时,为了证明深度残差模块可以帮助提升收敛速度,完整模型和缺少深度残差模块的模型收敛曲线如图5 所示。深度残差模块使得模型在训练过程中,损失下降更快,从而使模型加快收敛。本文模型在790 轮迭代后完全收敛,而缺少深度残差模块的模型在840 轮迭代后完全收敛,由此可证明引入残差结构能有效提升训练收敛速度。
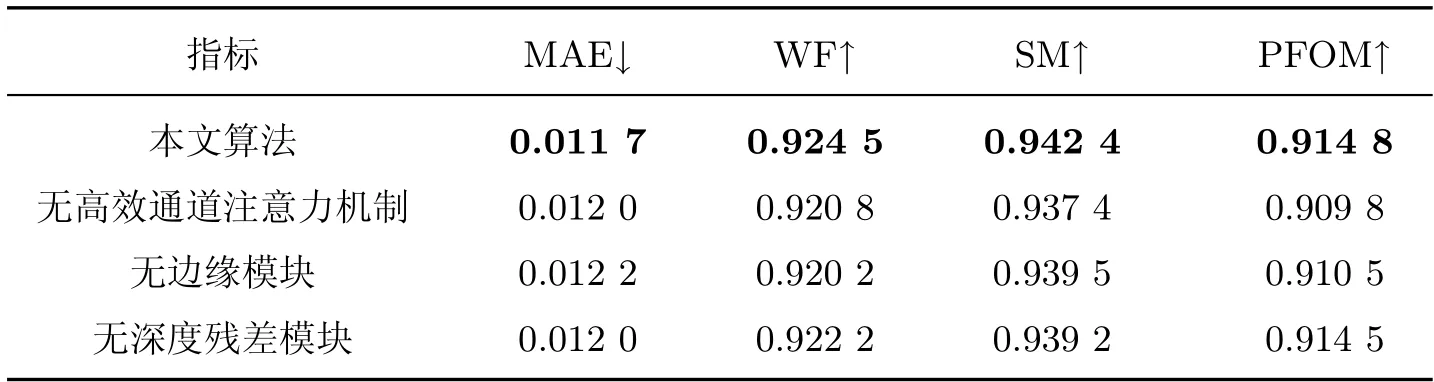
表2 本文方法缺少不同模块的对比结果Table 2 Comparison results of the proposed method without different module
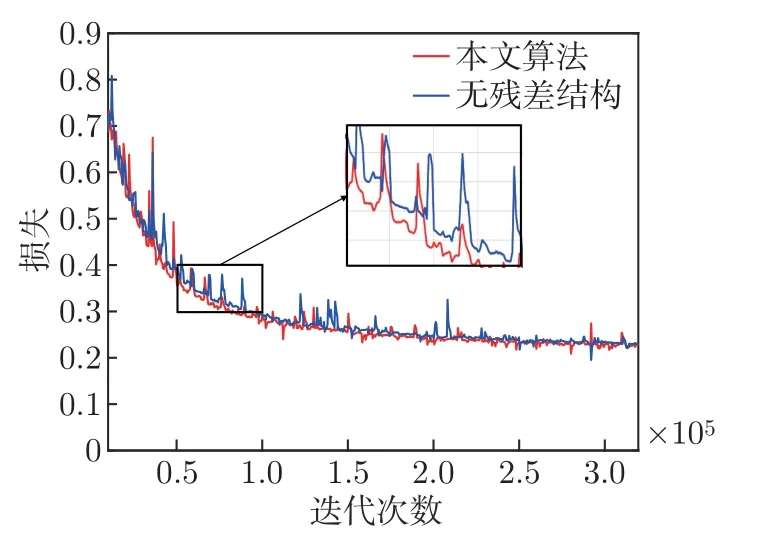
图5 训练过程收敛曲线Figure 5 Training process convergence curve
2.5 可视化结果分析
图6 展示了不同模型在3 种噪声干扰情况下的PR 曲线及F-measure 曲线对比图,从图中可以明显看到,本文模型在PR 曲线和F-measure 曲线上也明显优于其他模型,尤其在ρ=10% 和ρ=20% 时,其评测结果远高于其他模型,这也证明在噪声干扰情况下,本文模型比其他模型更具鲁棒性。
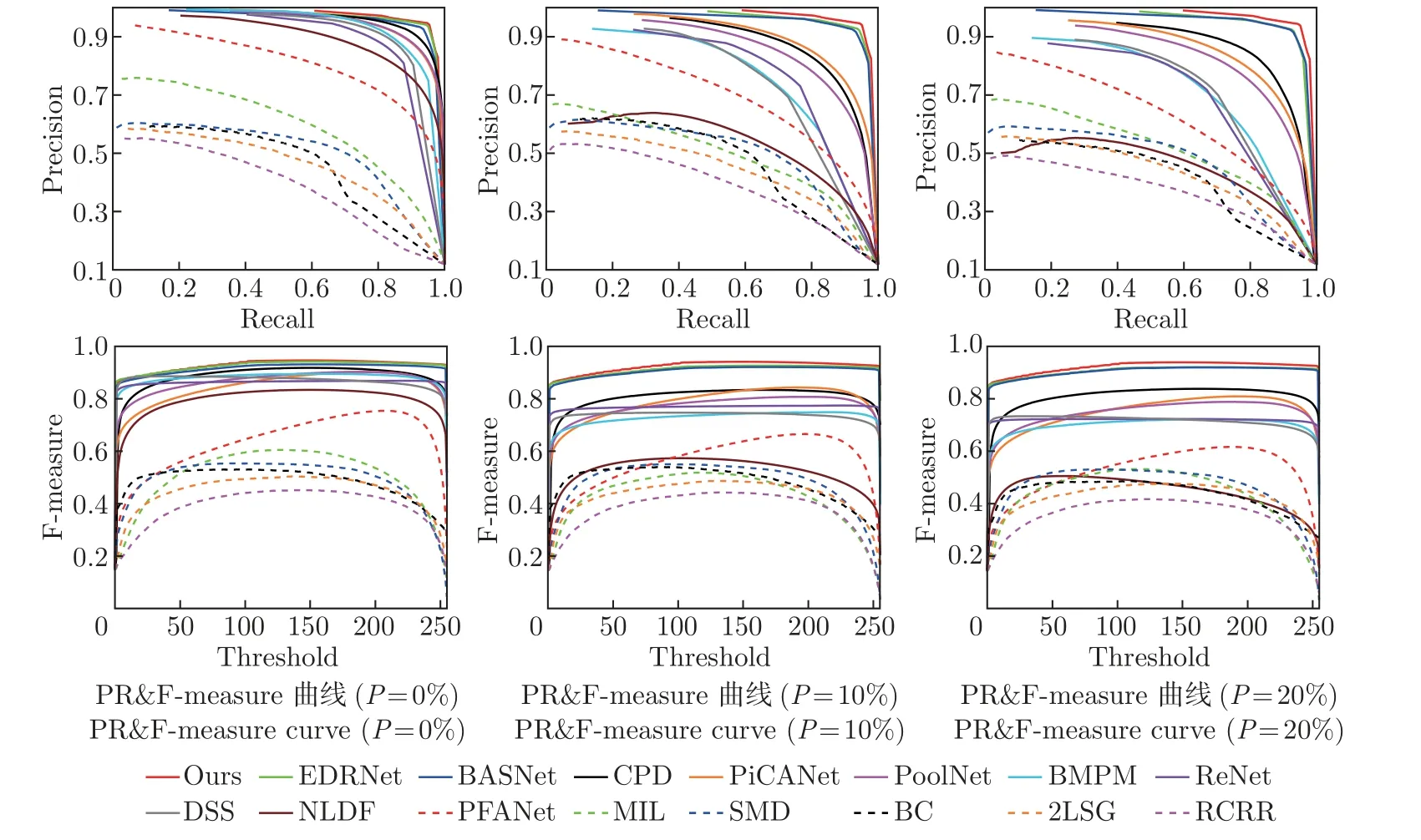
图6 各方法PR 曲线与F-measure 曲线图Figure 6 PR curve and F-measure curve of each method
图7 展示了本文模型与其他15 种模型的主观对比图,从每类当中各挑选2 幅,用于展示本文模型在不同类别上的效果。图7(a)∼(r) 分别为原图、RCRR、2LSG、BC、SMD、MIL、PFANet、NLDF、DSS、R3Net、BMPM、PoolNet、PiCANet、CPD、BASNet、EDRNet、本文算法和真值图。从图中可以明显观察到,本文模型对于检测结果的边缘具有细化能力。如图7 第2 行所示,本文所提出的算法更能聚焦到缺陷区域的边缘部分,对于细小目标的检测能力相比于其他现有检测模型有显著提升,这些均得益于边缘特征的引入,使模型能更精确地描绘显著目标与背景的交界区域;同时如图7 第3 和5 行所示,多尺度特征提取模块中通道注意力的引入,使得模型能较好地刻画不同尺寸的缺陷区域,从而对缺陷区域当中不同尺度的目标均表现出较好的检测能力。

图7 各方法主观对比图Figure 7 Visual comparison of each method
3 结语
本文提出了边缘感知深度残差显著目标检测网络。具体地,本文模型在多尺度特征提取模块当中引入了注意力机制,增强模型对缺陷区域的描述能力。同时,模型尝试引入边缘信息,边缘信息的引入能有效帮助模型区分前景与背景,并指导解码器生成精准预测图。最后,还将深度残差模块作为显著特征融合模块与边缘提取模块中的基本块,在保证检测精度的同时,提高了模型训练收敛速度。本文在公开数据集SD-saliency-900 上与当下主流的15 个模型进行了大量对比实验,实验结果表明,本文模型在MAE、F-measure 和S-measure 等多个评价指标上均取得了最优效果。在未来的工作中,我们将研究如何压缩模型大小,进一步改进模型架构,使其能够应用于更多的场合。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
自动化学报(2019年6期)2019-07-23
通信产业报(2016年44期)2017-03-13
太空探索(2016年5期)2016-07-12
河南科技(2015年8期)2015-03-11
时代英语·高三(2014年5期)2014-08-26
雕塑(2000年2期)2000-06-22
雕塑(1999年2期)1999-06-28
