
基于用户相似性选择及标签距离的推荐算法
2023-12-04 02:58陈学谦
应用科学学报 2023年6期
苏 湛,陈学谦,艾 均,黄 忠
上海理工大学光电信息与计算机工程学院,上海200093
随着互联网可用信息的爆炸式增长,利用有效手段访问和处理信息变得至关重要。推荐系统(recommender systems,RS)可以帮用户筛选和过滤信息,找到感兴趣的物品。推荐系统的任务是预测目标用户对待预测物品的评分或对目标用户进行物品推荐。预测是指通过预测用户对一个新物品的评价或评分,来判断用户是否会喜欢某个物品。推荐是指给用户推荐一个可能会喜欢的物品清单[1]。如果推荐工作得当,用户可以更高效、方便地找到自己需要的物品或信息,商家也可以将自己的产品提供给真正感兴趣的用户,从而提高效益、节约成本。推荐算法在网站[2]、音乐[3]、电影[4]等多个领域得到了广泛的研究和应用。因此,关于推荐系统性能提升的研究具有重要意义。
目前推荐系统包括基于协同过滤的推荐,基于内容的推荐技术和混合推荐技术三类[5]。
基于协同过滤算法推荐系统又可以分为基于记忆的协同过滤算法(memory-based collaborative filtering,Memory-Based CF)和基于模型的协同过滤算法(model-based collaborative filtering,Model-Based CF)[6]。
基于记忆的协同过滤算法包括基于用户的协同过滤算法(user-based,CF)[7]和基于物品的协同过滤算法(item-based,CF)[8]。基于用户的协同过滤算法主要利用评分数据来计算用户之间的相似性,根据相似性选择目标用户的邻居用户,通过邻居用户的评分信息预测目标用户对待预测物品的评分值[9]。计算相似性的常用方法有Pearson 相似系数、余弦相似度、欧氏距离等[1]。基于物品的协同过滤算法则是通过计算物品之间的相似性,对目标用户进行推荐[10]。
基于模型的协同过滤算法包括基于聚类模型[11]、最大熵模型[12]和矩阵分解[13]等协同过滤算法。基于模型的协同过滤算法通过数据降维、抽象特征、概率统计等方法与机器学习模型相结合[14]。通过建模,用已有的部分稀疏数据来预测空白物品和数据之间的评分关系,找到评分最高的物品推荐给用户。文献[15] 提出的Slope One 算法是基于模型的协同过滤算法,通过计算物品之间的距离,然后以线性方式进行预测。
基于内容的推荐算法是应用最早的推荐算法,主要应用于信息检索和信息过滤[16],又可以分为基于启发式和基于模型两类。基于启发式的算法有K 最邻近(K-nearest neighbor,KNN)算法和聚类算法,基于模型的算法有贝叶斯、聚类算法和神经网络等。基于内容的推荐算法基本思路是通过用户过去喜欢的物品,为用户去推荐和他过去喜欢的物品相似的物品。基于内容的推荐算法将物品的属性分解成多个标签,分析目标用户评价过的物品所对应的行为信息(如评论、点赞、收藏、加购物车、购买等),通过寻找出与过去喜欢相似的物品生成推荐列表。其优点是用户之间具有独立性、新的物品可以立刻得到推荐,但也存在物品特征提取难、无法挖掘用户潜在兴趣、冷启动等问题。
混合推荐技术主要分为加权型、切换型、交叉型、特征组合型、瀑布型、特征增强型、元层次型等[17]。一些研究表明,混合RS 算法比单独基于内容或CF 算法能给用户更好的推荐。尽管过去几年推荐系统领域的研究数量不断增长,但基于内容的方法和CF 方法仍然存在一些挑战。而混合技术通过将多种算法结合,克服了单个算法的缺点,改进了推荐系统的性能,能够达到预期的效果[18]。然而,混合推荐技术还存在复杂度高、适用性低等缺点。
近年来,深度学习技术发展快速,已成为数据挖掘和机器学习领域的新兴热点,极大地改变了推荐体系结构,并为提高推荐系统的性能带来了更多机会。深度学习可以捕捉非线性的用户项关系,将更复杂的抽象编码表示为更高层的数据[19],但也存在可解释性差、时间复杂度高等问题。
随着时代的发展,出现了越来越多的互联网应用与服务,当推荐系统面对种类繁多的任务时,难免会暴露一些问题。比如:预测或排序准确性低、准确性与多样性难以同时提高、算法可扩展性不足、冷启动、稀疏数据的处理、保护用户隐私等[11]。
本文针对推荐系统中准确性低、算法可扩展性不足的问题,提出了基于用户相似性选择及标签距离(user similarity selection and label distance,SSLD)算法。该算法首先在数据集中测试得到最佳的相似性阈值,并以该阈值为基准对用户进行相似性的筛选,选出合适的用户作为待预测用户的邻居。然后利用物品标签信息,将用户对物品的评分映射为用户对物品标签的评分,从而计算出用户距离。最后改进并利用距离预测公式进行预测。
1 基于用户相似性选择及标签距离算法
本文基于距离模型算法的基础上进行改进,例如Slope One 算法计算了所有用户之间的距离,没有使用用户之间的相似性。本文将用户相似性引入该算法,同时将用户之间对物品的评分距离演化成用户之间对物品不同标签的评分距离,形成基于用户相似性选择及标签距离的算法。算法的整体思想结构如图1 所示,先将相似性大于阈值的用户作为邻居,再计算待预测用户与邻居用户在物品标签上的距离,最后预测用户对物品的评分。
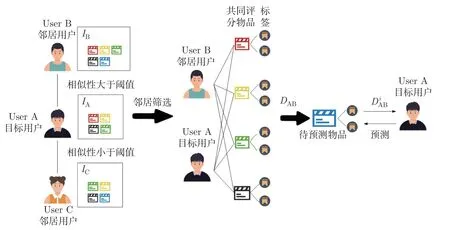
图1 算法整体思想结构图Figure 1 Algorithm overall thought structure diagram
1.1 相似性计算及选择
基于距离模型算法简单,但没有将用户之间的相似性考虑在内,因而运行时间短、精度不高。基于此,本文在算法中加入用户的相似性。同时考虑到每个用户有自己不同的邻居数,用户与不同的邻居相似性各有不同,高相似性的邻居值得参考,低相似性的邻居不仅参考意义不大,还会干扰其他用户的预测评分。为了最大化降低平均绝对误差(mean absolute error,MAE)和均方根误差(root mean squared error,RMSE)[20],用皮尔逊相似性[1]公式计算用户之间的相似性。相似性的阈值设置为[-1.0,1.0],间隔为0.1,低于阈值的相似性用户将会被筛选掉,不参与后续步骤的计算。皮尔逊相似性(PCC)、MAE 和RMSE 的计算公式如式(1)∼(3) 所示。
式中:rui为用户u对物品i的评分;为用户u对所有物品的平均评分;Iu为用户u看过的电影集合。
MAE 和RMSE 表示预测值与实际值的平均误差,MAE 和RMSE 的值越小,说明预测越准确。
两个数据集中不同相似性阈值的误差值如图2 所示,横坐标表示不同的相似性阈值,纵坐标表示误差值的大小。图2(a) 为Movie Lens 数据集中的误差值,当阈值Sh=0 时,SSLD 算法的MAE 和RMSE 值最小,预测精度最高,MAE 的值约为0.659,RMSE 的值约为0.864,预测效果最为理想。图2(b) 为Netflix 数据集中的误差值,当阈值Sh=0.1 时,SSLD 算法的MAE 和RMSE 值最小,预测精度最高,MAE 的值约为0.712,RMSE 的值约为0.909,预测效果最为理想。通过图2 也可以得知本文算法针对不同的数据集,需要寻找其最优阈值,以获得最优的预测结果,不同数据集的最优阈值会存在不同。
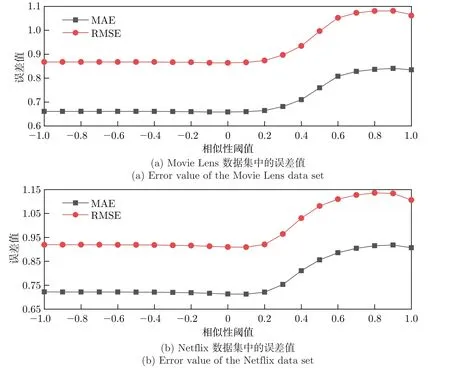
图2 两个数据集中不同相似性阈值的MAE 与RMSE 值Figure 2 MAE and RMSE values of different similarity thresholds in two datasets
1.2 物品标签
传统协同过滤算法往往只关注用户对物品的评分,而忽略了物品包含标签等信息。因此,本文将物品标签信息提取出来,将用户对物品的评分映射为用户对不同标签的评分,从而提高预测精度与排序精度。
根据筛选后用户对物品的评分,假设共有m个用户对n个物品评过分,用户集合表示为U,物品的集合表示为I,划分数据集为训练集Training Set 和测试集Test Set。设在推荐系统当中每个物品均存在一个或多个标签g,g ∈G,G是标签的集合,设集合G的长度为t,则G={g1,g2,···,gt}。本实验数据集中的物品为电影,共有19 个标签,即t=19,如表1所示。
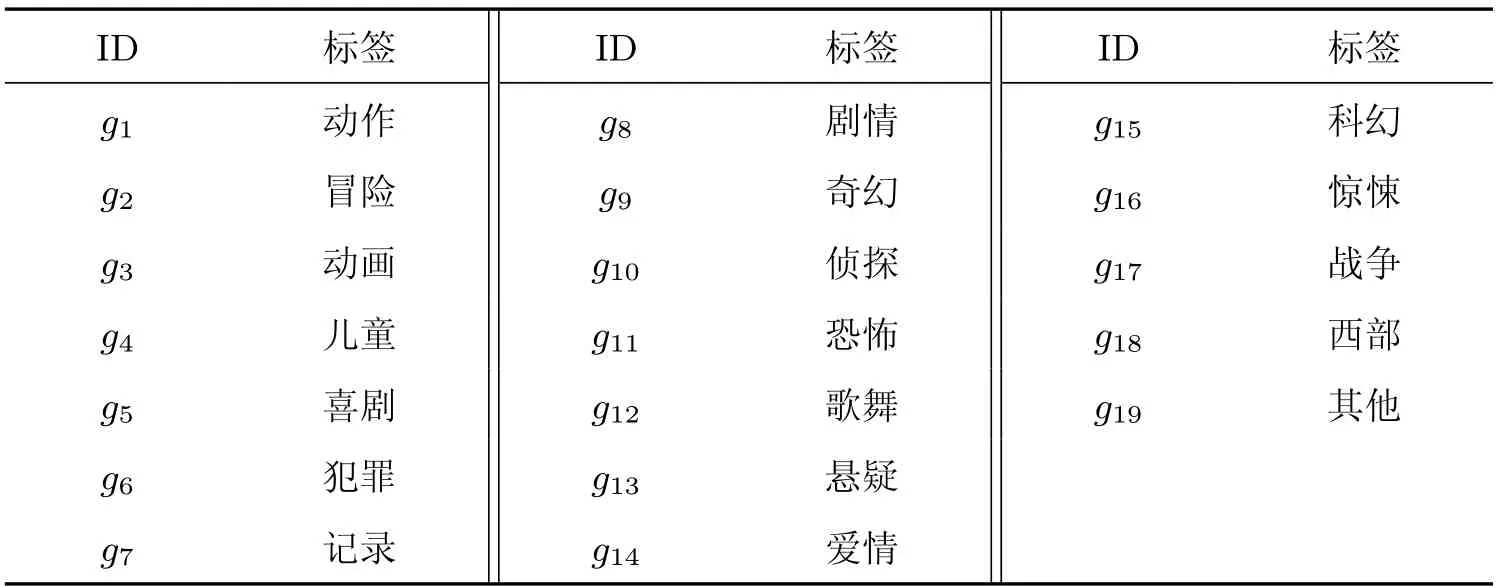
表1 电影标签划分Table 1 Movie label division
矩阵R表示一个U-I关系,R是一个m×n的实数矩阵,rui表示是用户u对物品i的评分。同样的构建一个邻接矩阵A为m×n的二值矩阵,γui为矩阵A的第u行第i列元素,取值为
每部电影均存在一个标签向量Gi,Gi是一个1×19 的向量,Gi=(gi1,gi2,···,gik,···,gi19),其中gik定义为
由此,可以得到用户、物品和物品标签这3 个节点构成的复杂网络。用户和用户之间通过物品来连接,每个用户与多个物品相连,同样的每个物品又可以连接多个用户,如果某用户评价过某物品,说明某用户与物品之间存在连边。用户与标签节点之间也不直接相连而是通过物品节点进行连接,物品节点与标签节点相连说明这个物品包含有这个标签,否则不存在连边。
1.3 用户平均距离计算
基于上述网络模型,在传统推荐算法中计算出两个用户有共同连边的物品评分差值,通过求连边数平均值作为平均距离。这样的距离不会因为预测对象的不同而存在差异,可以理解成用户的平均距离与待测物品无关,但实际每个人对不同物品会从不同的角度出发。因此,本文提出了一种基于不同标签度量节点之间的平均距离推荐算法。不同的平均距离定义如下:
1)全局平均距离全局平均距离是将两用户或两物品之间的平均近距离分解到不同的标签上,不同标签的平均距离代表两用户或物品在这个标签上距离的大小,全局平均距离可以用来反映用户和物品的综合情况。
2)局部平均距离局部平均距离是根据待测物品来决定的,通过待测物品从全局平均距离当中提取到包含标签的平均距离值,这也是目标用户进行预测的重要依据。
3)元平均距离元平均距离是平均距离的最小单位,全局平均距离和局部平均距离都是由元平均距离组成的,元平均距离是每个标签上所对应的平均距离值。
本模型以基于用户的协同过滤为例,对网络中的两个用户节点u和v,其全局平均距离Duv为
式中:n为数据集中的物品数量;γui为用户u对物品i是否评分;同理,γvi为用户v对物品i是否评分;rui为用户u对物品i的评分值;rvi为用户v对物品i的评分值;Gi是物品i的标签向量。Di是一个对角矩阵,每一个对角元素表示物品i包含标签gt被用户评价次数的倒数,计算公式为
式中:Duv是用户的全局平均距离,该值为一个向量,由元平均距离组成,每个元平均距离就是某个标签上的距离的大小;Duv从整体上反映了用户之间的距离情况。
1.4 评分预测公式
在获得筛选过的用户对的全局平均距离后,可以用目标用户u对待测物品i进行预测评分。预测可以分为两个步骤:
步骤1生成用户对局部平均距离由于得到的Duv是全局平均距离,并不能直接参与目标用户预测物品,全局平均距离反映的是用户之间的综合距离情况,对于某个特定物品,不会有全部的标签特征,它只能使用局部平均距离反映该物品的距离情况,所以最重要的是对待测物品生成对应的局部平均距离。例如,在目标用户u预测待测物品i时,需要计算目标用户u在当前预测环境当中包含物品i的特征的局部平均距离,相应公式为
步骤2预测得到所有用户的标量平均距离后,按照该值对目标用户进行评分预测,预测公式为
2 实 验
2.1 数据集
为了比较不同预测方法的结果,本文选取Movie Lens 和Netflix 两个著名的数据集[12]对多个算法进行性能测试。
Movie Lens 数据集从电影推荐网站中收集了由162 000 名用户,62 000 部电影,共25 000 000条评分信息组成的数据,在本实验中采用100 kB 数据集,其中包括了610 个用户对9 742 部物品的100 836 条评分数据。
Netflix 数据集是Netflix 举办公开竞赛算法中所用的数据集,旨在评选出预测电影用户收视率的最佳算法。Netflix 数据集包含了48 万个匿名用户对1.7 万个电影标题超过1 亿次评分。其中评分范围为1∼5,间隔为1。本文随机抽取1 000 个用户作为实验数据集进行实验。
为了从有限的数据中更好地评估模型性能,本文基于十折交叉验证将数据集分成10 份,每次都留不同的1 份作为测试集,剩余9 份作为训练集,进行10 次实验,最后取平均值。通过与对比算法预测结果在不同评价指标下的对比来验证本文算法的性能。
2.2 对比算法
为了证明本算法的有效性,本文将SSLD 算法与Slope One 算法、用户观点传播(user opinion spreading,UOS)算法[21]、分配协同过滤(resource allocation,RA)算法[22]、基于相似性网络的社团发现与预测加权(modulized improved opinion spreading,MIOS)算法[23]、基于巴氏距离协同过滤(collaborative filtering based on bhattacharyya distance,Bhattacharyya)[24]、基于信息熵的协同过滤(using entropy for similarity measures in collaborative filtering,Entropy)[25]、基于用户行为概率协同过滤(rating prediction in recommender systems based on user behavior probability,UBP)[26]等几种算法进行比较。
1)Slope One 算法核心思想是计算出两个用户之间的平均距离,然后以y=x+b的方式来进行预测。
2)用户观点传播算法将用户观点分为正面和负面,从而判断用户之间的相似程度。
3)资源分配协同过滤算法是利用推荐系统当中链路预测的概念来提高性能。其思想是在计算用户的相似性时,受欢迎的物品应当影响最小,因为大多数用户喜欢受欢迎的物品,所以它们不适合做被推荐时的参考物品。RA 是一种基于受欢迎程度的局部相似性度量,它对两个用户的值取决于两个用户的共同评分物品评分程度。共同评分的物品越受欢迎,其RA 相似性指数就越低。而且,根据共同评分的物品数量的增加,RA 的值增加,计算出的相似性更可信。
4)基于相似性网络的社团发现与预测加权算法通过考虑用户类型选择偏好之间的相似性、用户评级分布之间的相似性以及基于用户评级的物品之间的相似性来构建复杂网络。将相似性计算结果作为链路的权值,将对象视为网络中的节点。在此基础上,可以获得社区检测结果,并考虑社区信息进行链路预测。
5)基于巴氏距离协同过滤考虑了两个用户间评分值的概率之间的相关性,又考虑了共同评价物品的分数相似性,最后还加上了用户之间的杰卡德相似性。
6)基于信息熵的协同过滤算法将信息熵概念引入至相似性的计算,通过计算用户之间的信息熵,改进用户之间的相似性。
7)基于用户行为概率协同过滤算法考虑用户间共同评分的基础上,进一步考虑了用户对不同物品所含各类标签的选择概率。
2.3 评价指标
本实验采用平均绝对误差(mean absolute error,MAE)、均方根误差(root mean squared error,RMSE)来评估算法的预测准确性。采用半衰期效用指标(half life utility,HLU)[27]、平均折扣累计利润(discounted cumulative gain,NDCG)[28]和排序准确度(sorting accuracy,SA)来评估算法的排序准确性,最后在算法多样性和可拓展性上进行比较。
2.3.1 预测准确性指标
MAE 和RMSE 表示预测值与实际值的平均误差,MAE、RMSE 值越小,说明预测越准确。MAE 和RMSE 如式(2)∼(3) 所示。
2.3.2 排序准确性指标
HLU 表示推荐物品的评分与真实评分的差距,同时HLU 认为用户在浏览推荐物品时,用户兴趣会随着物品排序下降而呈指数形式下降,用户兴趣下降的越慢,HLU 得分越高,所以HLU 得分也越大越好。HLU 计算公式为
式中:m为推荐列表的数目;rui为用户u对物品i的评分;为用户u对物品评分的平均值。h为系统的半衰期,本文h取2。HLU 得分越大,说明系统在有限的个数要求下的排序结果越好。
NDCG 认为,系统按照用户的喜爱程度排序能够增加用户体验,将用户喜欢的物品排在前面能够获得较高的得分,排序越往后,得分越低。NDCG 的公式为
式中:DCG 是一个用户列表的排序得分,前b个结果重要程度相同,Ri是用户的喜欢得分,如果用户对该物品的评分超过平均值,表示用户喜欢,Ri取值为1,否则取值为0。NDCG 是DCG 的归一化,取值为0∼1 之间,其值越大,说明系统将用户喜爱的电影排在前面的能力越强,系统推荐能力越好。
在评判一个推荐系统的效果时,对物品的预测评分准确与否固然是一个很重要的判断依据,但是当遇到需要为用户提供一个包含多个物品的列表的组合推荐情况时,这个列表中多个物品之间的相对顺序也是一个重要的判断依据。排序精度为预测评分生成的推荐列表的准确度,从前(上)到后(下),用户的实际评分应该从高到低。
假设在一个推荐列表中,若某个物品的位置与其评分在此列表中的排名相同,则可判断这个物品处在此列表中正确的位置上,正确取1、错误取0,具体判断公式为
式中:Si、Sj为推荐列表中用户对第i、j个位置物品的实际评分;I为指示函数如式(18) 所示。当括号内式子成立时,函数值取1,反之取0;L为推荐列表;OS(Si) 为推荐列表中第i个位置的物品的判断值。
按照这种假设,对于某个推荐列表,如果其中物品的排序与用户对这些物品的评分排序越接近,则认为推荐系统的SA 值越高。因此SA 值越高代表推荐系统越能把更准确的物品优先推荐给用户。排序准确率能反映推荐系统对组合推荐的总体正确率,在计算完推荐列表中每个物品的判断值后,再利用式(19) 即可得到此列表的SA 值。
式中:分子可解释为推荐列表中物品排序正确的总数目;分母为当前推荐列表的长度,即列表中物品的数目;由此可知SA 值越高越好。
2.3.3 多样性指标
多样性是衡量单个推荐列表中物品之间差异程度的评价指标。本文采用衡量物品度值大小的方法来衡量推荐列表的多样性。列表里两个被推荐的物品的度值差异越大,物品之间的差异就越大,推荐列表的多样性也就越大。用来度量单个推荐列表公式为
式中:n是推荐列表中物品数目;ki是物品i的度值;是当前推荐列表所有物品度值平均值。分子也是推荐列表中物品度值的样本标准差,标准差越大代表列表内度值分布越广泛。Diversity 为最终的多样性结果,其值越大,代表推荐列表多样性越好。
2.3.4 可扩展性指标
本文可扩展性指标为算法花费时间和需要邻居的数目(Neighbor-Used)。算法花费时间越少,表明算法在实际应用中可以更快速地为目标用户进行推荐。Neighbor-Used 表明选取多少个邻居保存到数据库中对目标用户进行预测,选取的邻居越少,占用系统资源越少,算法的可拓展性越好。
2.4 实验结果分析
2.4.1 预测准确性指标对比
图3 表示SSLD 算法和不同算法在两个数据集上的MAE 和RMSE 值。图3 中横坐标表示邻居数量,单位为个。图3(a)∼(b) 表示各算法在Movie Lens 数据集和Netflix 数据集中的MAE 值,图3(c)∼(d) 表示各算法在Movie Lens 数据集和Netflix 数据集中的RMSE值。Slope One 算法基于所有用户之间的距离进行预测,所以预测准确性指标不会随着邻居数的增加而改变。本文算法在预测之前对符合相似性阈值的用户进行筛选,并计算用户间的距离,所以预测准确性指标也不受邻居数量的影响。
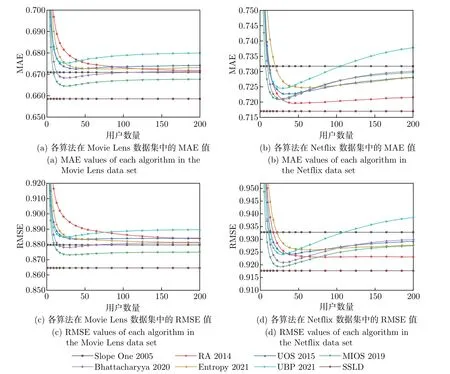
图3 两个数据集中各算法的MAE 和RMSE 值Figure 3 MAE and RMSE values for each algorithm in the two datasets
相较于Slope One 来说,SSLD 算法的MAE 值在Movie Lens 数据集上平均降低了1.84%,在Netflix 数据集上平均降低了2.01%。相较于其他算法,SSLD 算法在两个数据集上MAE 的值都有所降低。
相比于Slope One 算法,SSLD 算法的RMSE 值在Movie Lens 数据集上平均提高了1.72%,在Netflix 数据集上平均提升了1.62%。RMSE 加大了误差的惩罚,实验表明SSLD 算法能提高预测的准确度。表2 和3 表示SSLD 在两个数据集上相比于其他算法MAE、RMSE的降低百分比。降低百分比数值越大,则说明SSLD 相较于对比算法预测精确度提升越大。从表2 和3 中可以得出SSLD 算法的预测准确性优于其他算法。
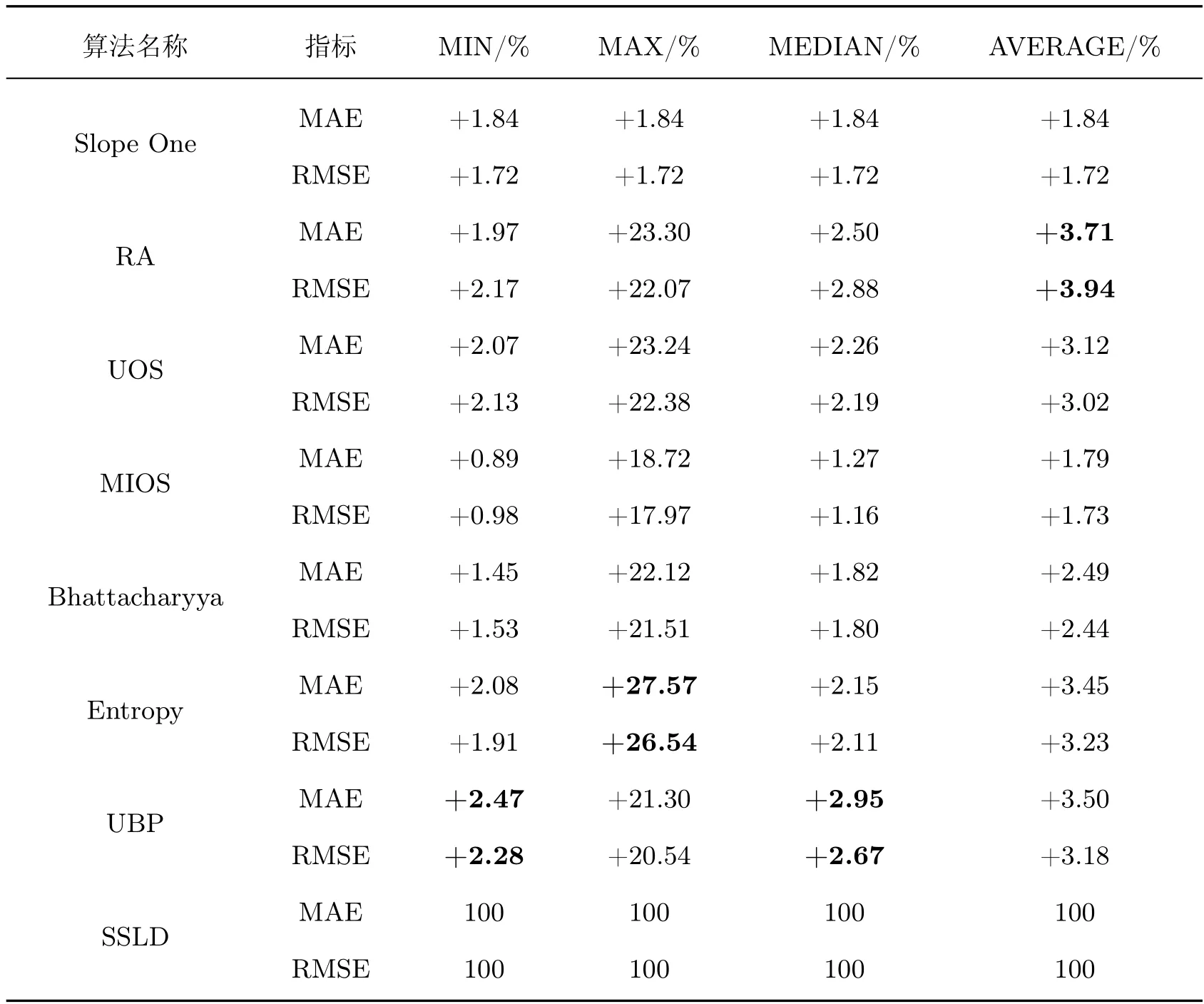
表2 Movie Lens 数据集中SSLD 算法相比对比算法MAE 与RMSE 降低百分比Table 2 Percentage reduction of MAE and RMSE of SSLD algorithm in Movie Lens dataset compared with other algorithms
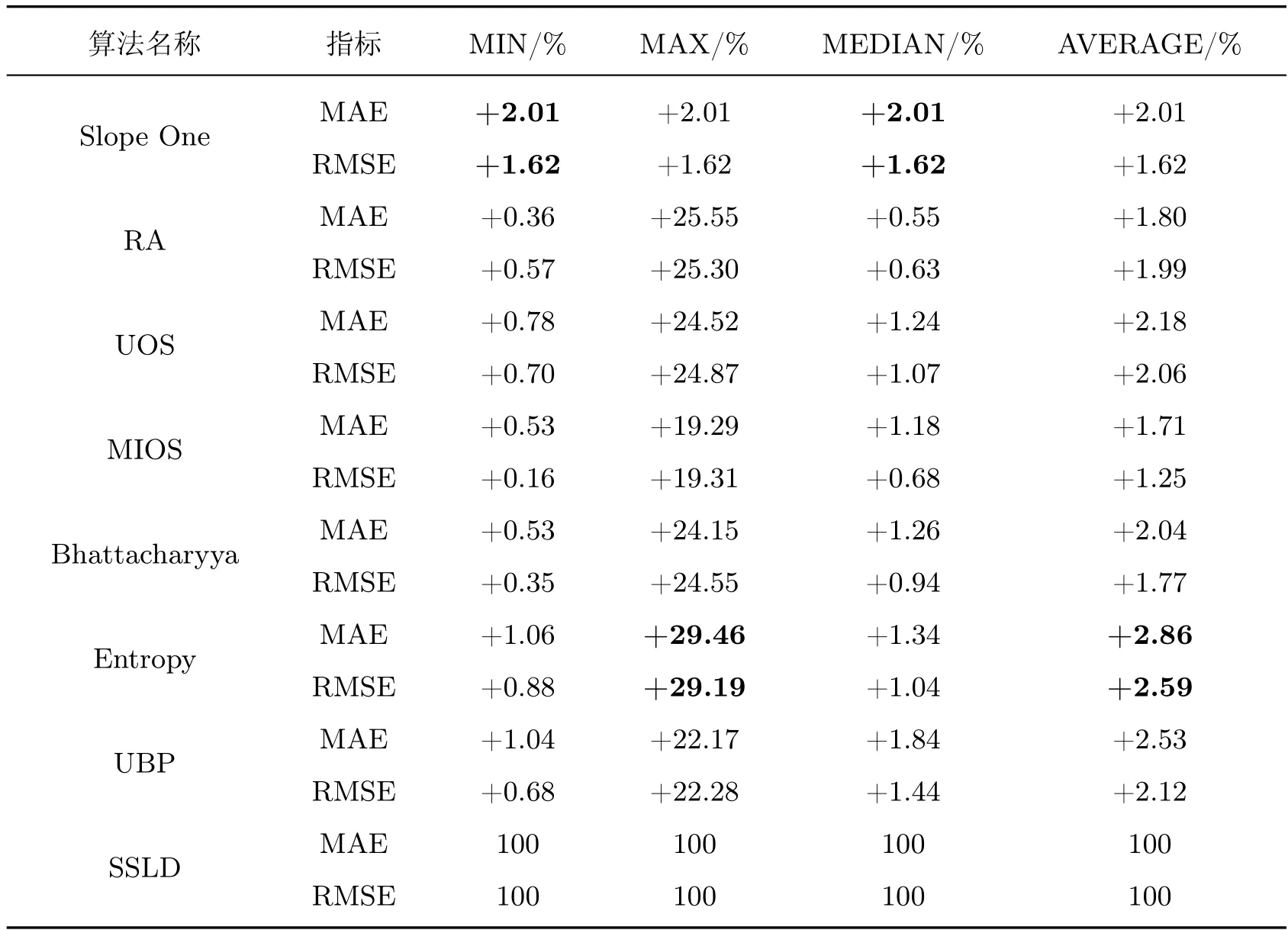
表3 Netflix 数据集中SSLD 算法相比对比算法MAE 与RMSE 降低百分比Table 3 Percentage reduction of MAE and RMSE of SSLD algorithm in Netflix dataset compared with other algorithms
2.4.2 排序准确性指标对比
图4 表示了SSLD 算法和不同算法在两个数据集中的HLU 和NDCG 结果(越大越好)。横坐标表示邻居数量,单位为个。图4(a)∼(b) 表示各算法在Movie Lens 数据集和Netflix数据集中的HLU 值,图4(a)∼(b) 表示各算法在Movie Lens 数据集和Netflix 数据集中的NDCG 值。与预测准确性指标同理,Slope One 算法与SSLD 算法的排序准确性指标不受邻居数量的影响。
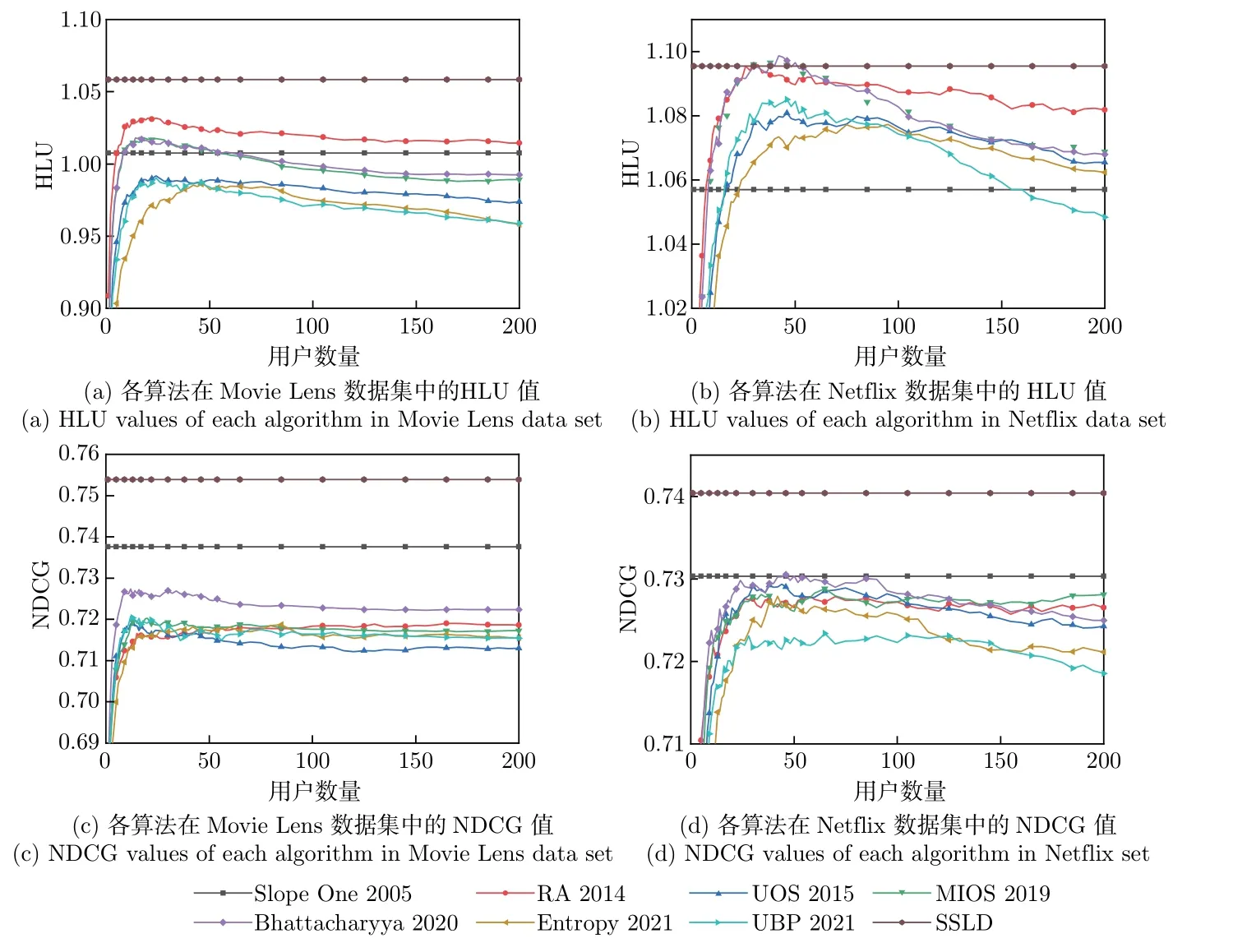
图4 两个数据集中各算法的HLU 和NDCG 值Figure 4 HLU and NDCG values of each algorithm in the two datasets
SSLD 算法相比于其他算法HLU 指标有显著的提升,相比于Slope One 算法,SSLD 算法的HLU 值在Movie Lens 数据集上提高了5.06%,在Netflix 数据集上提升了3.64%,说明SSLD 算法在推荐系统中,生成推荐列表可以极大满足用户的需求。
SSLD 算法相比于其他算法的NDCG 指标也有显著提升,相较于Slope One 算法,SSLD算法的NDCG 值在Movie Lens 数据集上平均提高了2.22%,在Netflix 数据集上平均提升了1.38%。这同样说明了SSLD 算法在推荐系统中,生成推荐列表时的相关性非常高,用户更喜欢的物品会优先出现在推荐列表的前列,推荐列表的排序质量很高。相较于其他推荐算法来说,SSLD 算法能够提升用户对推荐系统的满意程度。
表4 和5 表示在两个数据集上NDCG、HLU 的提升百分比。提升百分比数值越大,说明SSLD 算法相较于对比算法排序性能提升越高。从表4 和5 中可以看出SSLD 算法的排序性能整体优于其他算法。
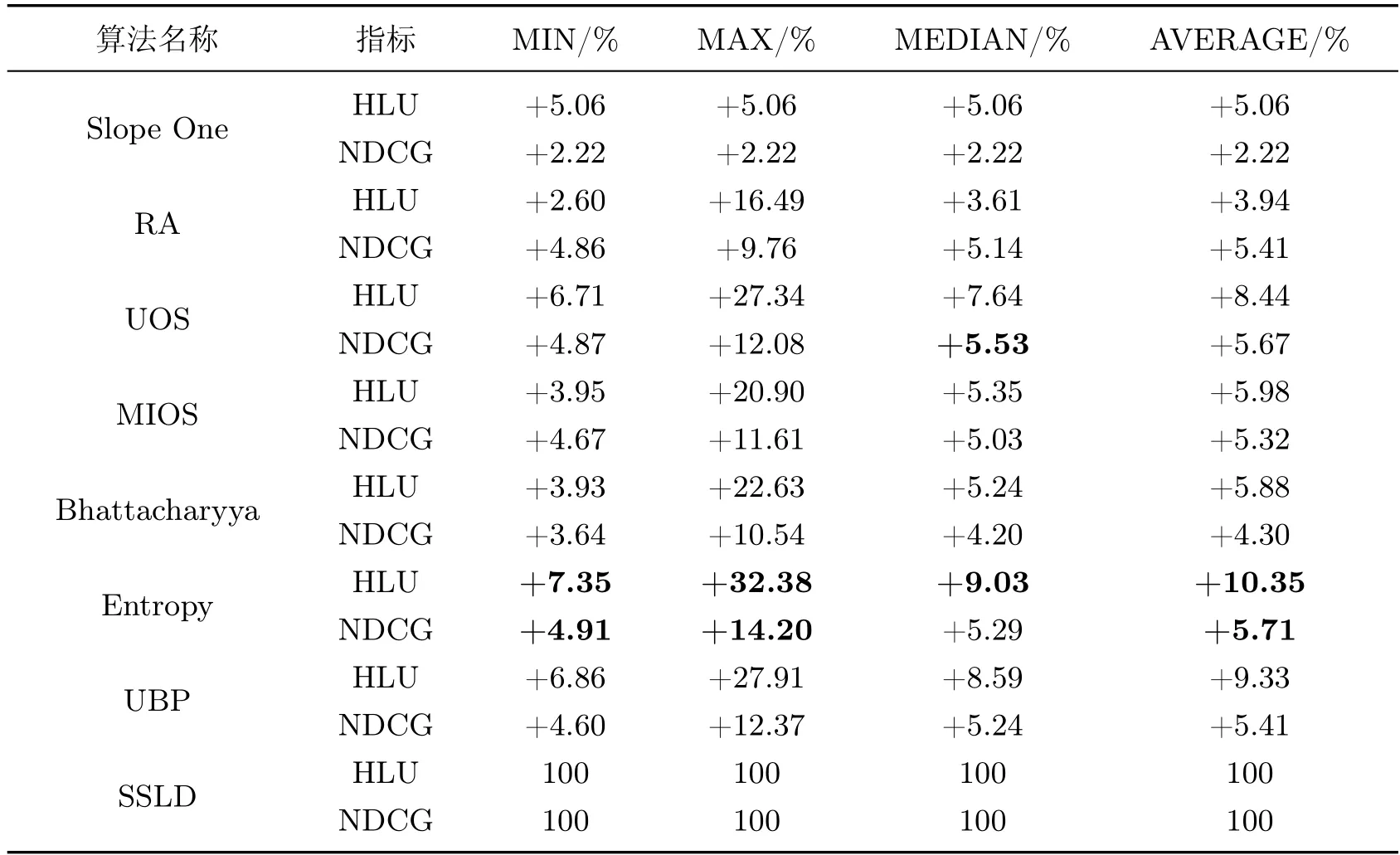
表4 Movie Lens 数据集中SSLD 算法相较于对比算法HLU 与NDCG 提升百分比Table 4 Percentage improvement of HLU and NDCG of SSLD algorithm in Movie Lens data set compared with other algorithms
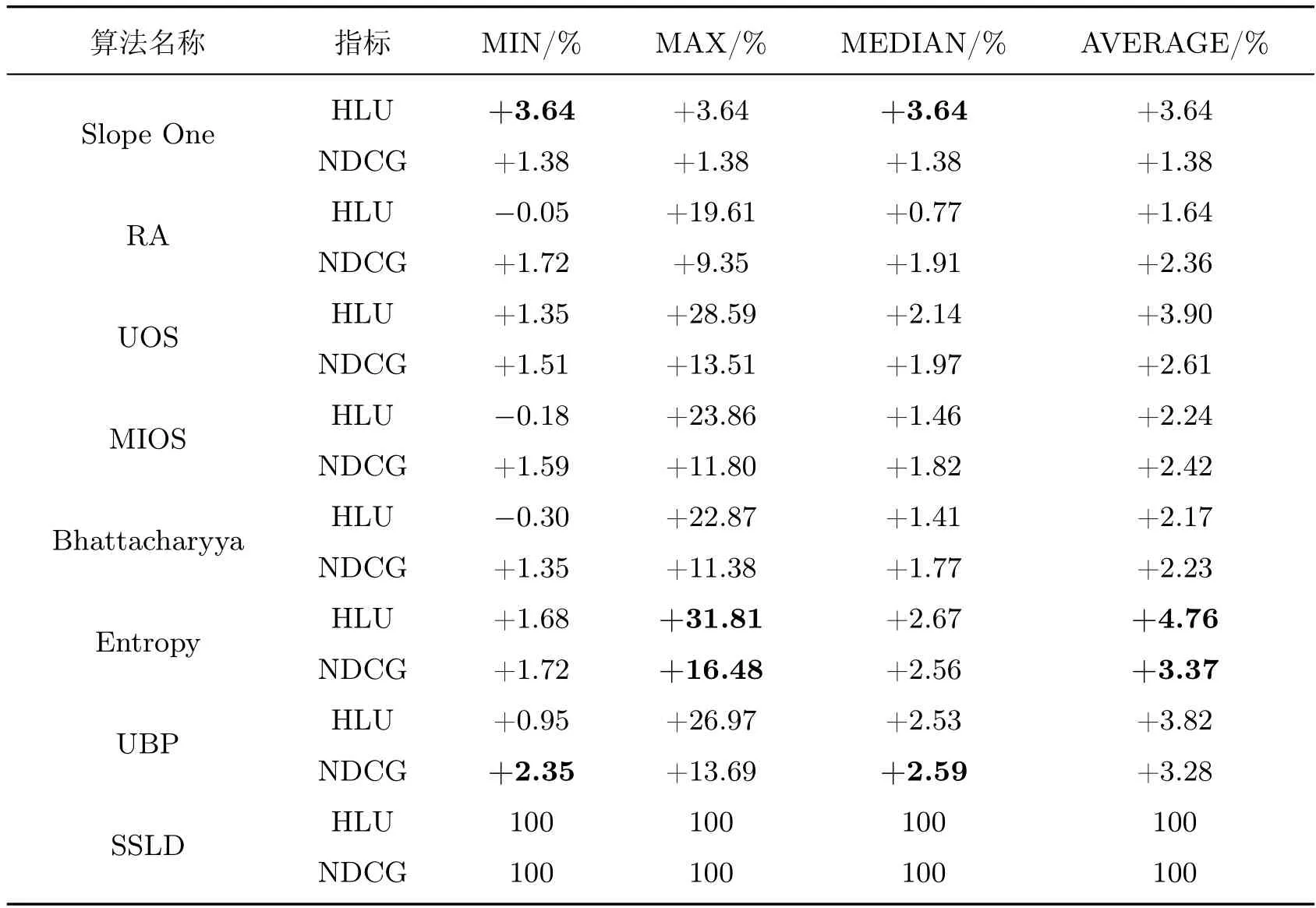
表5 Netflix 数据集中SSLD 算法相较于对比算法HLU 与NDCG 提升百分比Table 5 Percentage improvement of HLU and NDCG of SSLD algorithm in Netflix data set compared with other algorithms
图5 表示SSLD 算法和不同算法在两个数据集中的Sorting Accuracy 结果(越大越好),横坐标表示不同算法选取的邻居数量,单位为个,图5(a) 为Movie Lens 数据集中各算法在不同邻居下的Sorting Accuracy 值,图5(b) 为Netflix 数据集中各算法在不同邻居下的Sorting Accuracy 值。
不难看出,在Movie Lens 数据集中,SSLD 算法的得分最高。在Netflix 数据集中,RA、MIOS、Bhattacharyya 这3 个算法在邻居数量约为40 时,Sorting Accuracy 得分与SSLD 算法相似,但随着邻居数量的增加,3 个算法的得分值开始下降。综上可以说明,SSLD 算法在排序精确度指标上,领先于其他算法。
2.4.3 多样性指标对比
图6 表示SSLD 算法和不同算法在两个数据集中的Diversity 结果(值越大表示推荐的结果越新颖),横坐标表示不同算法选取的邻居数量,单位为个。图6(a) 为Movie Lens 数据集中各算法在不同邻居下的Diversity 值,图6(b) 为Netflix 数据集中各算法在不同邻居下的Diversity 值。与预测准确性指标和排序准确性指标同理,Slope One 算法与SSLD 算法的多样性性指标不会随着邻居数量的增加而改变。
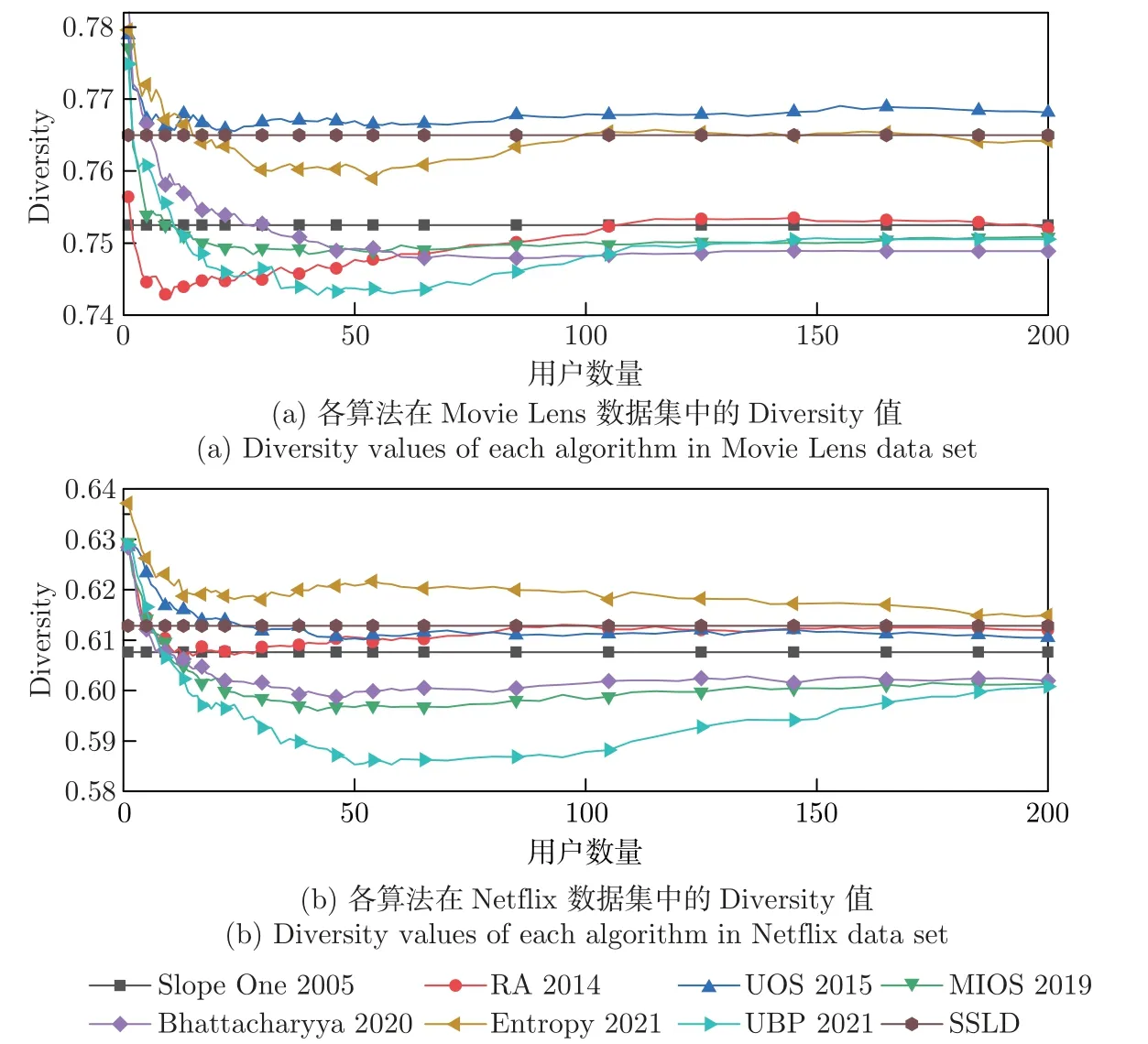
图6 两个数据集中各算法的Diversity 值Figure 6 Diversity values of each algorithm in the two data sets
由图6 中可以看出,在Movie Lens 数据集中,SSLD 算法不如UOS 算法,与Entropy 算法接近,但相比Slope One 算法提升了1.66%。在Netflix 数据集中,也与Entropy 算法接近,但相比于Slope One 算法提升了0.86%。这表明SSLD 在实现低误差的同时,可以拥有良好的多样性。
2.4.4 可扩展性指标对比
图7 表示算法在两个数据集中预测所需的邻居用户数量,图7(a) 为各算法在Movie Lens数据集中预测所需要的邻居用户数量,图7(b) 为各算法在Netflix 数据集中预测所需要的邻居用户数量。其中Slope One 和SSLD 算法使用固定的用户数量进行预测,所以不会随着数据集中邻居用户数量的增加而变化。相较于Slope One,SSLD 可以选取更少的用户对目标用户的喜好物品进行预测与推荐。在两个数据集中,Slope One 分别平均需要51 和114 个邻居用户。而SSLD 算法只平均需要32 和60 个邻居用户,大大节约了邻居用户数据所需要的储存空间。基于近邻协同过滤的算法,曲线接近重合,是因为采用的邻居数非常相似,不同的是相似性的度量值。该类算法在邻居数量为30∼40,算法可以达到最高精度,虽然在最高精度时所用邻居数量比SSLD 约少10 个,但SSLD 具有更高的精度。
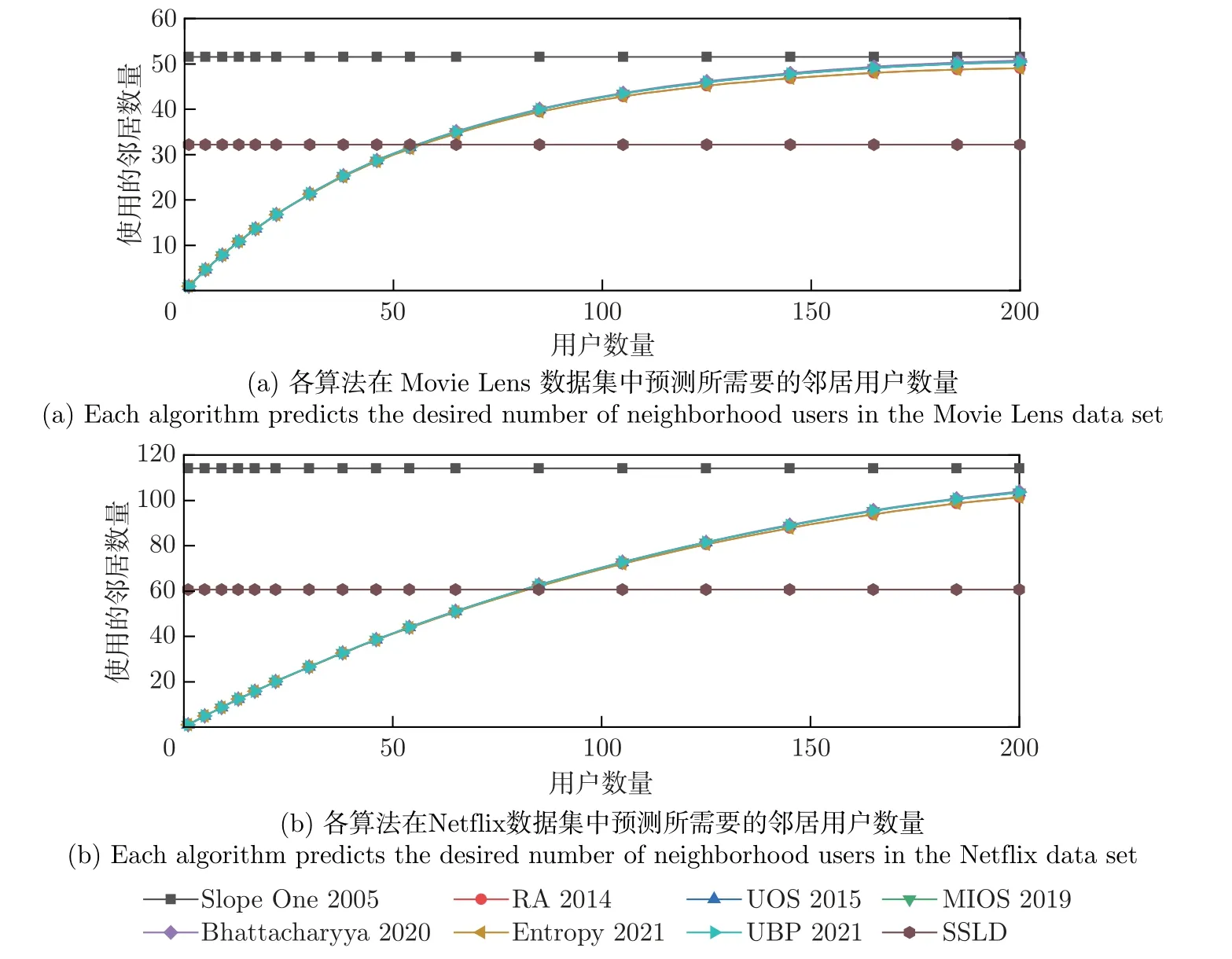
图7 两个数据集中各算法所需要的邻居数量Figure 7 Number of neighbors needed for each algorithm in the two data sets
图8 表示每个算法在两个数据集中运行所需的时间。由图8 可知,在Movie Lens 数据集中,SSLD 算法比近些年的算法所需的时间少。在Netflix 数据集中,SSLD 算法所需的时间最少。这表明SSLD 算法可以快速地推荐物品给目标用户,用户可以更快地得到反馈。
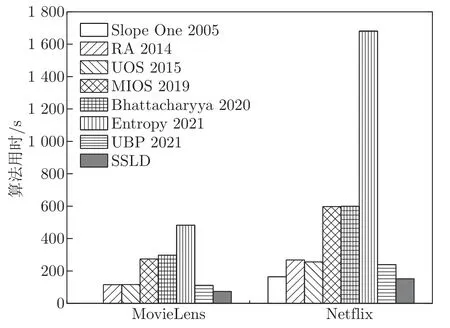
图8 各算法在两个数据集中运行所需要的时间Figure 8 Time required for each algorithm to run in two data
3 结语
针对推荐系统中存在的预测及排序精度不高、可拓展性不足等问题。本文从物品的标签特性出发,计算物品之间的标签距离,同时结合相似性选择,提出基于用户相似性选择及标签距离的算法。
实验结果表明,与几种最新的推荐系统算法相比,SSLD 算法在预测和排序准确性、可扩展性方面具有显著的优势。SSLD 算法可以在较短时间内,寻找少量的相似邻居,预测和排序得更精确。例如,在两个数据集的MAE 指标上,SSLD 算法相比较于其他算法提升了1.71%∼3.71%,在RMSE 指标上平均提升了1.62%∼3.94%,HLU 指标上平均提升了1.64%∼10.5%,在NDCG 指标上平均提升了1.38%∼5.71%。与Slope One 相比,本文方法所需的邻居约减少了50%。同时,也揭示了在推荐系统中可以利用多标签的信息等差异,提升推荐系统的效果。
虽然本文算法取得了不错的效果,但仍有不足之处。比如SSLD 在多样性指标中的排名表现并不理想,需要进一步研究SSLD 多样性不佳的原因,可以进一步为用户推荐新颖的物品。同时可以尝试将深度学习等技术与本文算法进行结合,提高算法的适用性。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
小学生学习指导(低年级)(2022年5期)2022-05-31
小学生学习指导(中年级)(2021年4期)2021-04-27
疯狂英语·初中天地(2021年11期)2021-02-16
河北画报(2020年8期)2020-10-27
课堂内外(初中版)(2020年5期)2020-06-19
少年漫画(艺术创想)(2019年2期)2019-06-06
浙江大学学报(工学版)(2016年2期)2016-06-05
中学生数理化·中考版(2015年10期)2015-09-10
小天使·一年级语数英综合(2015年8期)2015-07-06
