
基于CAFPN 和细化双头解耦的遥感图像目标检测
2023-12-04 02:58张孙杰阚亚亚陈家豪
应用科学学报 2023年6期
熊 娟,张孙杰,阚亚亚,陈家豪
上海理工大学光电信息与计算机工程学院,上海200093
遥感图像目标检测旨在高效准确地对遥感图像中的目标进行分类和定位[1]。目前大多数目标检测器可以分为两种:两阶段检测器和一阶段检测器。两阶段检测器首先第一阶段通过区域候选网络(region proposal network,RPN)生成水平感兴趣区域(region of interests,RoI),然后在第二阶段使用共享头对目标进行类别预测和位置估计,代表算法有Faster R-CNN[2]、Mask R-CNN[3]等。与两阶段检测器相比,一阶段检测器摆脱了复杂的RPN,直接从预设候选框中预测类别及位置,代表算法有YOLO[4]、SSD[5]等。但是,由于类别不平衡,一阶段方法的检测精度通常低于两阶段方法。当面对复杂背景下小而密集的遥感目标时,一阶段方法难以在上述目标中实现最佳性能,两阶段方法利用两个阶段的共享特征增强一致性学习,从而提取更有效特征。
然而,虽然通用目标检测算法具有强大的特征提取能力,但不能有效地适用于遥感图像目标检测。不同于水平视角的自然景象,俯瞰视角拍摄的目标具有方向任意、分布密集的特征,另外船舶和车辆等纵横比大、尺寸小的目标也增加了检测难度。为了解决这些问题,针对遥感图像的目标检测器[6-9]应运而生。
由于遥感图像中目标角度的不确定性,文献[6] 通过预设不同角度、比例和纵横比的锚框来实现与目标的空间对齐,但导致了巨大的计算量。于是文献[8] 提出了RoI Transformer,该转换器从RPN 产生的水平RoI 学习得到旋转RoI,文献[9] 通过预测4 个滑动偏移量实现旋转目标的检测。上述两种方法虽采用更加灵活的表达方式减少锚框铺设,但仍然受到目标和特征之间的严重错位影响。此外,由于车辆、船舶等目标体积小,一些方法利用特征金字塔网络(feature pyramid network,FPN)[10]集成多级信息,提取具有增强语义信息的多尺度特征。文献[11] 融合不同语义层次的特征信息,提高了建筑物变化检测的精度。尽管上述结构极大地提高了网络的多尺度表达能力,但忽略了不同尺度特征之间的信息冲突,尤其对于小目标,缺乏上下文信息会阻碍性能的进一步提高。最后,文献[12-15] 实验发现,两阶段目标检测器在分类和回归两个不同的任务中共享相同的参数,但分类置信度高的边框并不能准确地匹配目标,说明两者所需特征并不相同。双头RCNN[14]通过分析网络结构发现,全连接层头适合分类,而卷积头能回归更精确的边框。MRDet[15]将回归特征解耦分别预测目标的位置、尺度和方向。这些方法虽然避免了两个任务的冲突,但只关注了目标特定类型的特征,无法自适应学习更复杂、更具辨别力的特征。
针对以上问题,本文提出结合上下文信息的特征金字塔网络(context augmentation feature pyramid network,CAFPN)以及细化双头解耦网络的目标检测算法。首先,通过捕获不同感受野的信息,将多尺度空洞卷积得到的特征进行自适应融合,并自上而下注入特征金字塔网络中,充分利用高层语义特征减轻遥感图像尺寸差异大的问题。然后,在边框回归时采用中心点偏移回归(midpoint offset regression,MOR)机制,通过6 个参数(x,y,w,h,∆a,∆b)将水平框转换为旋转框以更好地匹配目标。最后,不同于传统共享检测头进行分类回归,本文采用结合特征细化模块(feature refinement module,FRM)的双头解耦方法,通过有效融合空间注意力和通道注意力,降低背景噪声干扰,生成的特征经过极化函数构造适应各自任务的关键特征,减少分类和回归的不一致性,有效地提高检测性能。
1 本文方法
为了准确检测遥感图像中的旋转目标,本文以Faster R-CNN+FPN 为检测框架,提出基于上下文金字塔和细化双头解耦网络的遥感图像目标检测算法。总体框架如图1 所示,首先将主干网络提取的图像特征送入CAFPN,通过残差分支增强空间上下文信息,接着在RPN回归阶段采用中心点偏移回归方式,通过学习6 个参数获得旋转边框的坐标信息,最后采用双头网络结构结合特征细化模块获得适用于分类和回归不同任务的重要特征,缓解任务之间的不一致性。其中分类分支由两个全连接层组成,回归分支由一个残差块和4 个卷积头组成,残差块作用是将输入特征通道数从256 的升维到1 024。
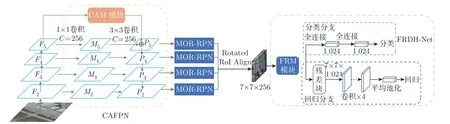
图1 网络总体结构Figure 1 Overall network structure
1.1 上下文特征金字塔
在遥感图像中,目标尺寸差异大且具有较高的类间相似性,而通用目标检测算法对输入图像进行多次下采样后造成特征信息丢失,不同尺度的特征图未能有效融合,检测目标之间不能有效地关联相似特征,导致目标漏检和误检。于是本文将上下文信息增强模块CAM 以残差形式连接构造一种金字塔结构CAFPN。如图1 所示,本文以ResNet50 为主干网络,每一阶段的最后一个特征输出表示为{F2,F3,F4,F5},Fi经过1×1 卷积进行通道降维,然后使用3×3 卷积来细化语义上下文,通过自顶向下、横向连接结构生成通道为256 的特征层{P2,P3,P4,P5}。CAM 结构如图2 所示,本文将最后一阶段的输出特征F5引入一系列具有不同空洞率{1,3,5} 的空洞卷积层,这些分离的卷积层通过融合不同感受野的特征获得丰富的语义信息,使用自适应空间融合模块[16]有效地融合这些上下文特征。为了保证原始输入特征图F5的粗粒度信息,本文将P5与经过CAM 后的输出特征图相加作为特征金字塔最顶层的特征图,将高层的语义信息通过自上而下的路径传递给低层。CAM 在实现与主干网络和后续分类和定位的子网络进行端到端训练的同时,还能够部署到基于FPN 的目标检测器中。
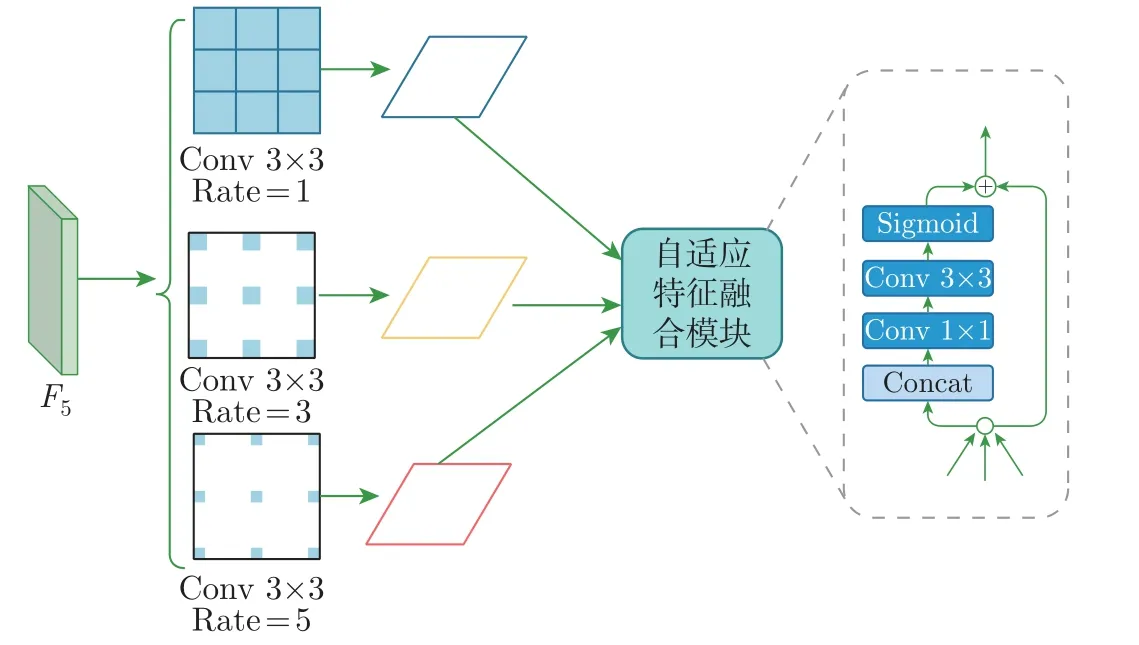
图2 CAM 模块Figure 2 CAM module
1.2 中心偏移回归
本文采用Oriented R-CNN[17]中的中心点偏移回归方法,以几乎无成本的方式生成高质量的旋转候选框。与水平框的回归方式不同,除了(x,y,w,h)表示中心点坐标、宽和高外,还通过预测得到表示旋转框所需的(∆a,∆b)两个参数,∆a和∆b是内部旋转边框相对于外部矩形顶部和右侧中点的偏移量,将水平框的4 个顶点依据两个偏移比例解耦得到旋转边框。具体原理如图3 所示。
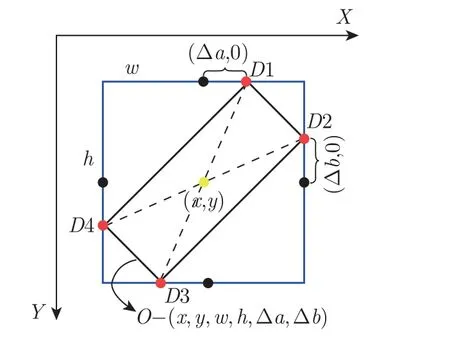
图3 中心点偏移回归原理Figure 3 Principle of midpoint offset regression
图3 中蓝色矩形框是旋转边框的外部矩形,黑点是矩形每侧的中点,红点代表旋转框的顶点,该方法在RPN 回归阶段通过学习得到的6 个参数(x,y,w,h,∆a,∆b)解码得到旋转框的4 个顶点的坐标(D1,D2,D3,D4)。在这里∆a是D1 相对于顶部中点的偏移量,∆b表示D2 相对于右侧中点的偏移量。为了将回归得到的平行四边形转换成适合于旋转目标实例的表示方式(x,y,w,h,θ),将平行四边形的较短对角线延长到与较长对角线相同的长度。从RPN 获得候选区域后,通过旋转RoIAlign[8]提取固定大小为7×7 的水平特征图用作后续的分类、回归任务。
1.3 特征细化双头解耦网络
在遥感图像目标检测中,分类和回归对特征的敏感性不同,共享特征会降低性能。CFCNet[18]通过可视化特征发现,分类所需的特征响应通常集中在物体的局部区域,如船尾和船首,回归所需的特征响应分布在目标的边缘。为了能够提取各自任务更具辨别力的有效特征,避免两者之间的特征干扰,本文提出将注意力与极化函数引导的特征细化模块FRM 与双头解耦网络有效结合,称为特征细化双头解耦网络(feature refinement double head network,FRDH-Net),FRM 详细结构如图4 所示。

图4 特征细化模块结构Figure 4 Structure of feature refinement module
为了增强特征表达能力,本文将RPN 网络得到的特征融合空间与通道注意力。首先给定输入特征F ∈RC×H×W,使用全局平均池化进行压缩操作,得到通道向量FGAP∈RC×1×1,将FGAP输入到由两个全连接层FC1、FC2 和非线性激活函数组成的多层感知机中,更好地拟合通道间复杂的相关性,提高模型的泛化能力。经过Sigmoid 函数得到通道注意力权值,计算公式为
同时,空间注意力使用不同感受野的空洞卷积来获得丰富的语义信息,为了桥梁等大纵横比的目标能被更好地检测出,卷积的感受野不仅是传统的方正视觉,还采用了膨胀率为(1,3)和(3,1)的空洞卷积,其感受野可以更贴切狭长目标。给定输入特征F ∈RC×H×W,在空间压缩的同时与4 个不同核大小的空洞卷积进行操作,生成的特征Fd ∈×H×W叠加后再经过一个3×3 卷积提取特征,最后使用1×1 卷积降低通道数,经过Sigmoid 函数得到空间注意力权值,计算公式为
通过将两个注意力图相乘,获得用于分类回归任务的注意响应图Mtotal。为了进一步细化用于不同任务的特征,本文设计极化函数H(·) 构建特征。对于分类,期望更多地关注特征图上的高响应部分,而忽略可能用于定位或带来干扰噪声的不太重要的部分,激活函数为
式中:α是用于控制特征激活强度的惩罚因子(本文设置为15)。由于高响应区域的特征足以实现准确分类,因此权重小于0.5 的无关特征被抑制。通过这种方式,分类器能够较少关注难以分类的区域,并减少过度拟合和误判的风险。
同时,对于回归分支,其有效特征往往分散在目标的边缘,为了获得目标轮廓和边缘信息来进行定位,本文使用抑制函数如下:
与分类任务不同的是,目标某一关键部分的强烈响应不利于定位。在式(4) 中,抑制函数抑制回归特征中具有高响应的区域,网络能够寻找潜在的视觉线索以实现精确定位。最后,将注意力加权特征、输入特征F和注意力响应图Mtotal通过元素相加进行合并,以获得用于精确目标检测的强大特征表示。细化特征任务为
式中:⊗和⊙表示张量乘法和元素乘法。
1.4 损失函数
对于遥感图像而言,复杂背景下的图片使网络在训练时正样本数量少,导致网络学习不充分,进而影响检测性能,因此本文引入多任务损失函数进行训练,损失函数为
2 实验
2.1 数据集与实验参数设置
1)数据集 为了验证提出方法的有效性和优越性,本文在DOTA[19]、HRSC2016[20]和UCAS_AOD[21]数据集上进行实验。DOTA 数据集是应用于遥感图像目标检测的大型数据集,包括飞机、桥梁、车辆等15 个类别。由于遥感图像分辨率高,实验将原始图像裁剪为固定大小1 024×1 024,像素重叠大小为200。HRSC2016 是一个用于船舶检测的数据集,包含有1 061 幅大小不等的图像,其中训练集436 幅、验证集181 幅和测试集444 幅。UCAS_AOD包含了1 510 幅飞机和汽车检测图片,共14 596 个实例,其中训练集755 幅,验证集302 幅,测试集453 幅。
2)实验参数本文实验以Pytorch 为框架,在NVIDIA GeForce GTX1080 的显卡上进行训练和测试。本文使用随机梯度下降算法对整个网络进行优化,动量为0.9,权重衰减为0.000 1,批处理大小设为2。训练中采用了随机水平翻转和垂直翻转作为数据增强方式。对于DOTA 数据集,以带有预训练权重的Resnet50 为主干网络训练12 个epoch,初始学习率设置为0.005,在第8∼11 个epoch 内下降到原来的十分之一,对HRSC2016 和UCAS_AOD数据集,以相同的初始学习率训练36 个epoch,在第24∼33 个epoch 内下降到原来的十分之一,损失曲线如图5 所示,网络收敛效果较好。

图5 损失函数变化Figure 5 Change of loss function
对于FPN 中的超参数设置,本文遵循Faster RCNN 算法设置,对DOTA 和UCAS_AOD数据集,本文的锚长宽比设置为[1/2,1,2]。由于船舶的纵横比较大,对于HRSC2016 数据集,锚的长宽比设置为[1/3,1/2,1,2,3]。
3)评估指标本文使用平均精度(average precsion,AP),平均精度均值(mean average precision,mAP),帧速率(frames per second,FPS)作为算法的评价指标,指标定义如式(10)∼(13) 所示
式(10) 中:P代表精确率,表示正确预测为正的样本占全部预测为正的样本的比例。式(11)中:R代表召回率,表示正确预测为正的样本占实际是正样本的比例;TP 表示被正确分为正样本的数目;FP 表示被错误分为正样本的负样本数目;FN 表示被错误分为负样本的正样本数目。式(12) 中:AP 表示对某一类别检测的平均精度,它是精确率随着召回率变化的曲线在0∼1 上的积分。式(13) 中:mAP 表示对不同类别的AP 求均值,其中n表示类别总数。
2.2 实验结果与分析
为了验证算法的有效性,本文与当前在遥感图像目标检测领域中的先进算法进行对比,如一阶段算法DAL[22]、S2ANet[23]和二阶段算法MRDet、Oriented-RCNN 等。表1∼3 分别是不同算法在3 个数据集上的性能比较。
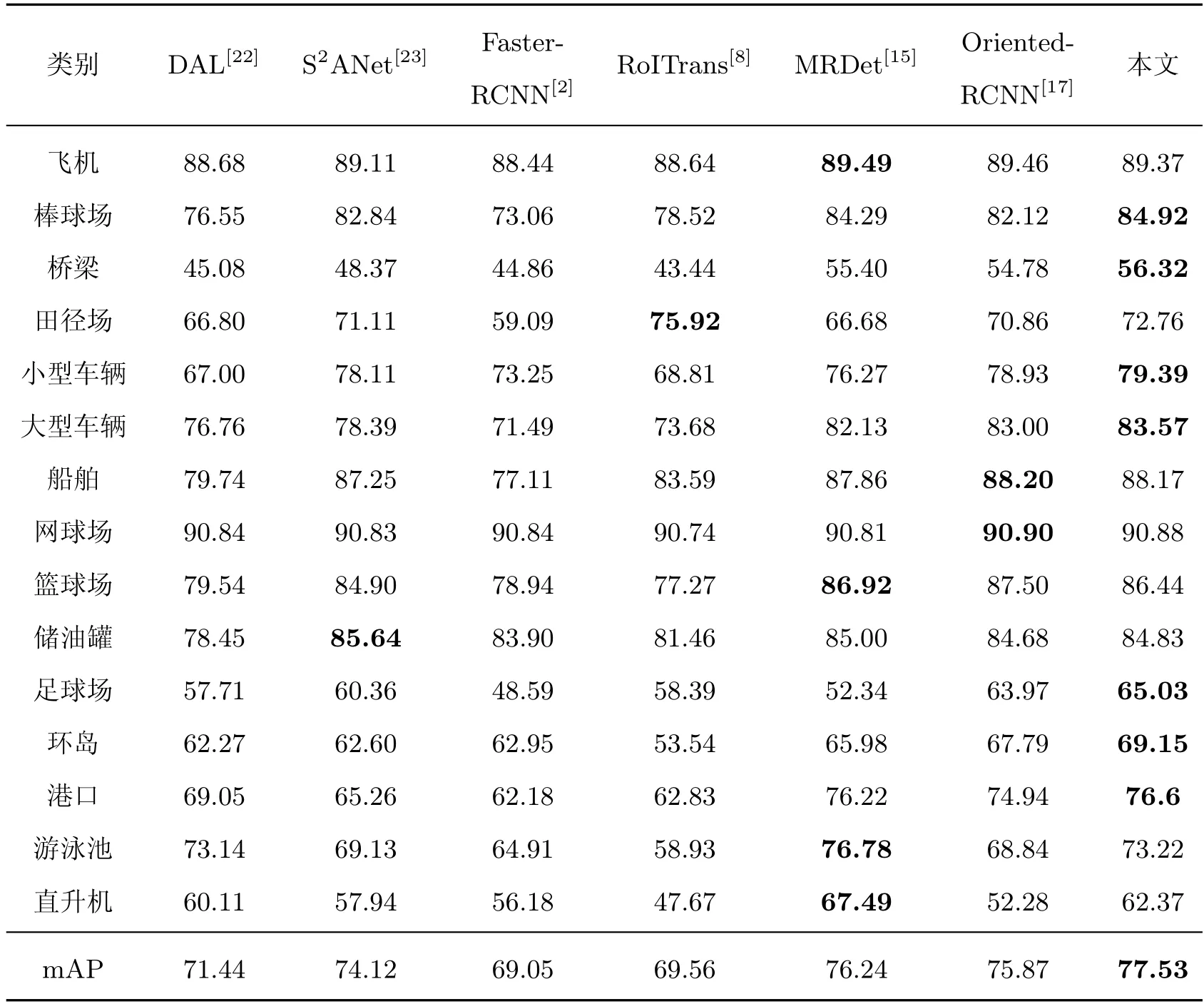
表1 不同算法在DOTA 数据集上的性能对比Table 1 Performance comparison with different algorithms on DOTA
本文方法在3 个数据集上的检测精度均取得了显著效果,对比Faster RCNN 算法,精度分别提升了8.48%,7.60%和3.10%,比提出MOR 机制的Oriented RCNN 提高了1.66%、0.49%和1.35%。其中,在DOTA 数据集上(表1),虽然一阶段方法DAL 利用新的标签分配过程,动态选择高质量的锚点,S2ANet 通过深度特征对齐来缓解分类和定位之间的不一致性,但类不平衡问题增加了密集目标的检测难度,本文利用两阶段共享特征增强一致性学习,检测性能获得了6.09% 和3.41% 的增长。MRDet 通过多头网络预测类别分数、位置、尺度和方向,解决不同任务之间的信息冲突,但复杂的网络结构加深了训练难度,本文算法只采用双头解耦分支结合FRM 模块提高有效特征获取,对比获得了1.29% 的增益,并加快了推理速度。Oriented-RCNN 提出了中心点偏移表示,本文在此基础上增强了上下文信息,提高了网络对于目标尺度的自适应能力,检测精度提高了1.66%。另外,本文方法在桥梁、车辆和港口等类别上的检测精度取得了最优值。由于符合目标狭长特点的锚框设置减少了算法微调,在HRSC2016 数据集上(表2),本文方法也达到了最优效果90.89%。本文使用UCAS_AOD 数据集进一步验证算法的鲁棒性和泛化性,实验结果如表3 所示。本文算法的检测性能明显优于其他算法,尤其在汽车类别上效果显著,对比Faster RCNN 高4.50%,比Oriented-RCNN提高1.52%,进一步说明算法的有效性。

表2 不同算法在HRSC2016 数据集上的性能对比Table 2 Performance comparison with different algorithms on HRSC2016
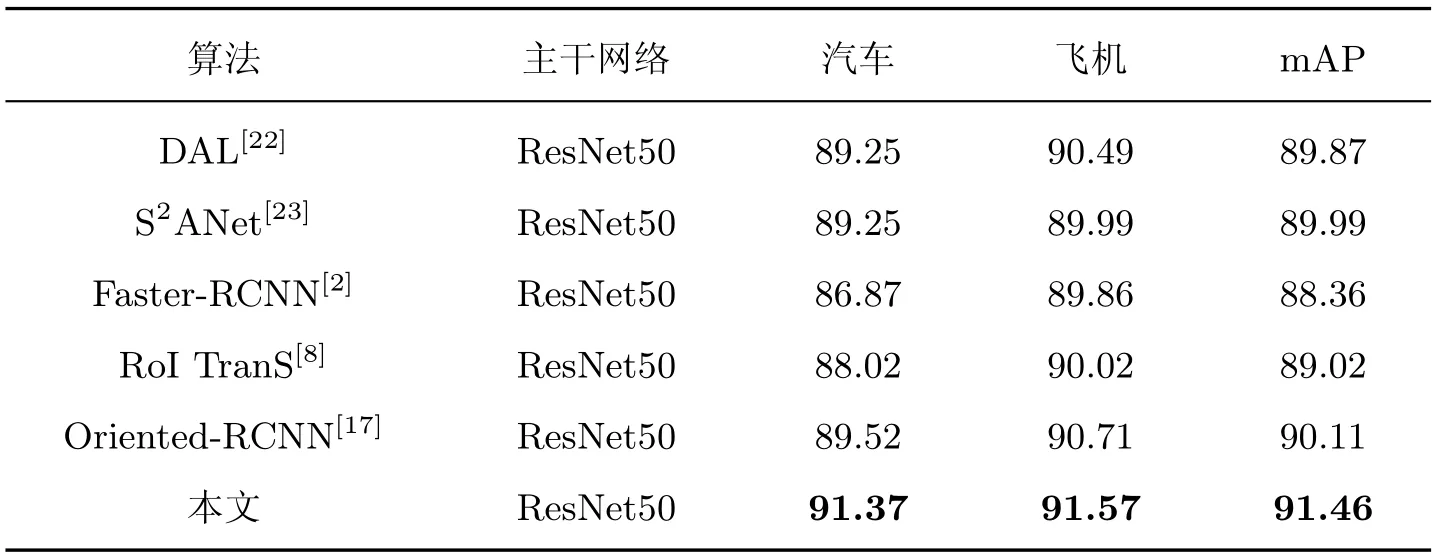
表3 不同算法在UCAS_AOD 数据集上的性能对比Table 3 Performance comparison with different algorithms on UCAS_AOD
为了兼顾算法的准确性与实时性,本文在相同的实验条件下比较了不同算法在DOTA 数据集上的精度和FPS,结果如表4 所示:对比一阶段算法DAL 和S2ANet,虽然推理速度大致下降了2 FPS 和1 FPS,但精度显著高出6.09% 和3.43%;同比两阶段算法MRDet,本文方法在精度提升了1.26% 的同时推理速度也加快了1.1 FPS。和Oriented RCNN 算法对比,由于结合更丰富的不同感受野特征,同时引入了组合注意力模块,本文在推理速度相当的情况下,检测性能也有一定提升,说明了该算法的有效性。

表4 DOTA 数据集上的速度与准确性Table 4 Speed and accuracy on the DOTA
为了进一步证明本文方法的有效性,实验对3 个数据集分别进行了可视化,效果如图6∼8 所示。在图6 中,通过可视化DOTA 数据集中15 个类别发现,当尺寸差异大的田径场与车辆存在于同一幅图像时,回归的边界框也能精确包围目标,并且几乎没有遗漏小目标,说明结合不同感受野特征有效地覆盖了不同尺寸的目标,缓解了卷积过程中小目标信息流失的问题。在图7 中,对于HRSC2016 数据集中大长宽比的船舶,MOR 机制的引入能够更好的学习边框的坐标信息,长锚框预设结合FRM 模块中的狭长感受野信息,能实现精准确回归。在图8 中,对于UCAS_AOD 数据集,特征细化模块通过空间和通道注意力的有效融合,抑制了噪声干扰,有效地检测出复杂背景下密集排列的小目标,进一步证明了该算法的有效性。

图6 DOTA 数据集可视化检测结果Figure 6 Visualization of detection results on the DOTA

图7 HRSC2016 数据集可视化检测结果Figure 7 Visualization of detection results on the HRSC2016

图8 UCAS_AOD 数据集可视化检测结果Figure 8 Visualization of detection results on the UCAS_AOD
2.3 消融实验
2.3.1 各模块消融实验
本文选择引入MOR 机制的Faster RCNN 算法作为基线在DOTA 数据集上进行消融实验,逐步将提出的方法集成到基线模型中,以证明改进模块的有效性。本文首先将共享头替换为双分支结构,通过对卷积头和全连接头进行不同任务的对比实验,结果从表5 看出,当使用共享全连接头时,检测精度达到75.82%,而当卷积做分类,全连接做回归时,精度下降了6.98%。因此,本文提出卷积做回归,全连接做分类,效果有所提升,以此作为FRM 模块的结构基础。加入CAM 模块,本文通过增大感受野有效地避免了卷积过程中小目标的信息流失,检测精度提升了0.8%,在FRM 模块的改善下,网络通过抑制噪声干扰,提取有效特征,精度进一步提高了1.27%。同时,该算法在保证推理速度相当的情况下,检测性能提升,进一步证明了本文算法的鲁棒性和有效性。
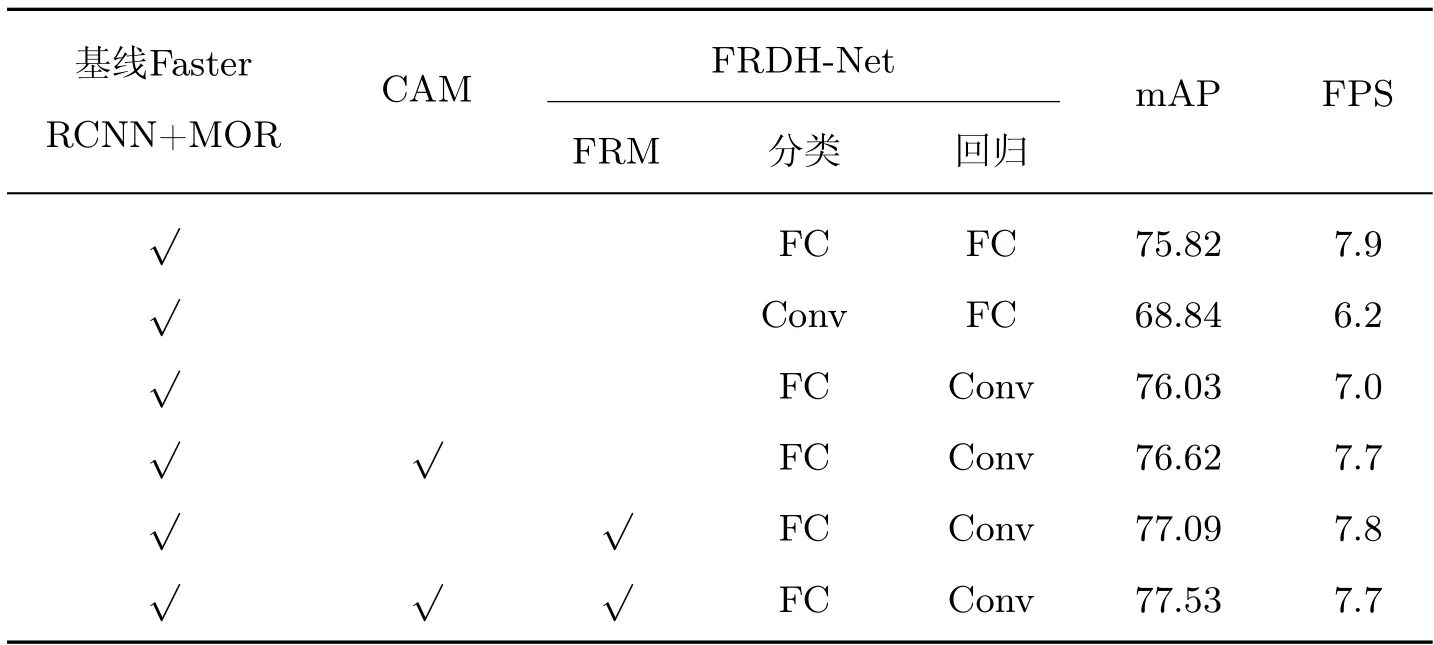
表5 模块消融实验Table 5 Module ablation experiment
加入CAM 模块后,对本算法的结果与基线算法进行可视化对比,结果如图9 所示,图中第1 行为基线算法效果图,图中第2 行为本文算法效果图。在兼顾高分辨率目标准确检测的同时,CAM 模块也改善了边缘位置和复杂背景下的小目标检测,如图9(a) 中右上角边沿的泳池及图9(b) 中树木里的小型车辆,避免了基线算法的漏检情况。另外,由于有效地结合上下文信息,对于图9(c) 中飞机尾翼的影子,本文方法避免了错检情况,说明上下文信息有利于解决语义冲突。加入FRM 模块后,对提取的特征进行可视化处理,如图10 所示,改进方法可以有效地提取不同任务所需的关键特征。图10(a) 为原始图像,图10(b) 提取的回归特征均匀分布在目标周围,这有助于识别目标边界并准确定位目标。图10(c) 分类特征更多地集中在对象最可识别的部分,比如船首或船尾部分,避免目标其他部分的干扰,使分类结果更准确。

图9 CAM 模块有效性分析可视化Figure 9 Visualization of validity analysis of CAM module

图10 分类和回归任务细化特征可视化Figure 10 Visualization results of refinement features for classification and regression
2.3.2 不同空洞率效果验证
为了使F5特征能够通过增大感受野覆盖不同尺寸的目标,有效地提取上下文信息,本实验设置不同空洞率,实验结果如表6 所示。本文设置{1,1,1}、{2,2,2}、{1,3,5}、{2,4,8}4 种不同的空洞率分别进行实验,对比基线网络,精度分别提升了0.62%,0.32%,0.80%,0.45%,说明增大感受野可以提升算法性能。其中{2,2,2} 的空洞率比{1,1,1} 效果差,原因是使用该膨胀率更多关注大尺寸目标,而忽略了小目标。当使用{1,3,5} 空洞率时,实验性能改善达到饱和,可视化如图9 所示,对比基线网络,本文算法改善了复杂背景下的边缘目标漏检情况,图9(a) 中边缘位置的泳池和图9(b) 中复杂背景下的车辆,能够被精确地框选出来,因此本文选取空洞率为{1,3,5}。
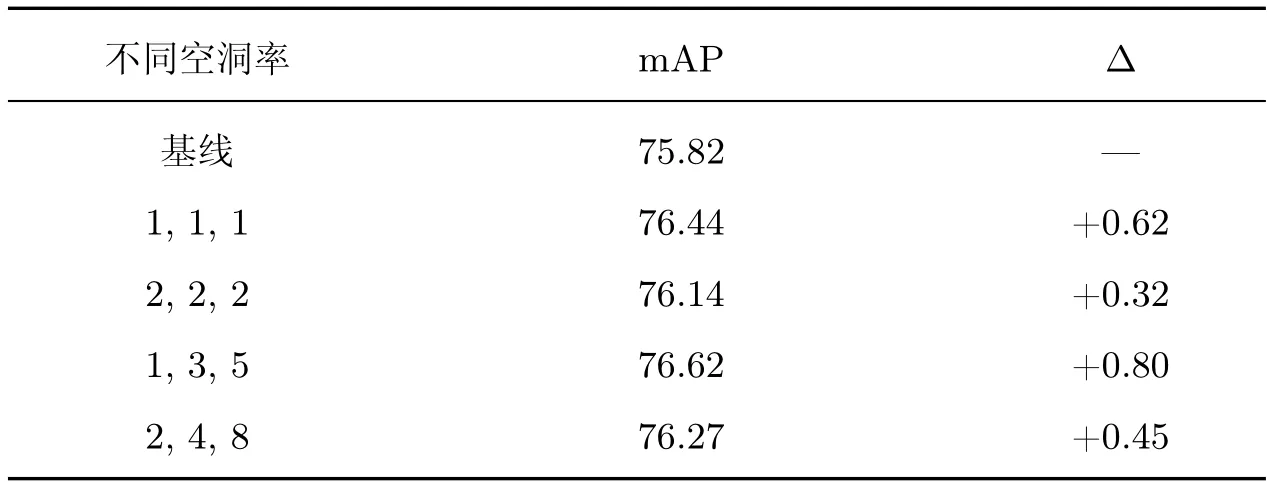
表6 不同空洞率实验Table 6 Experiments with different dilations
2.3.3 不同注意力机制研究
为了学习更具判别信息的特征,本文将空间注意力与通道注意力进行有效融合,使对特征筛选的效果达到最佳。为了验证该模块的有效性,本文将不同的注意力机制嵌入到算法网络中进行训练,实验结果如表7 所示,对比加入的几种注意力机制,可以有效提升算法的检测精度。加入SE 注意力,通道注意力能够使网络更加关注有效通道的特征图,抑制复杂的背景噪声,更好地保留小目标信息,检测精度增长了0.66%;加入CBAM 注意力,空间注意力和通道注意力的结合操作,对特征空间位置及不同通道重新进行权重赋值,降低池化对细节特征的弱化,效果又得到了进一步提升,对比基线网络增加了0.73%,说明空间与通道注意力的组合可以更好地学习特征,受此启发,本文的注意力模块通过元素相加合并,结合不同感受野的空间注意力让网络更加精确定位遥感图像中的目标位置,获得用于检测的更强大特征表示,检测精度提升了1.27%。
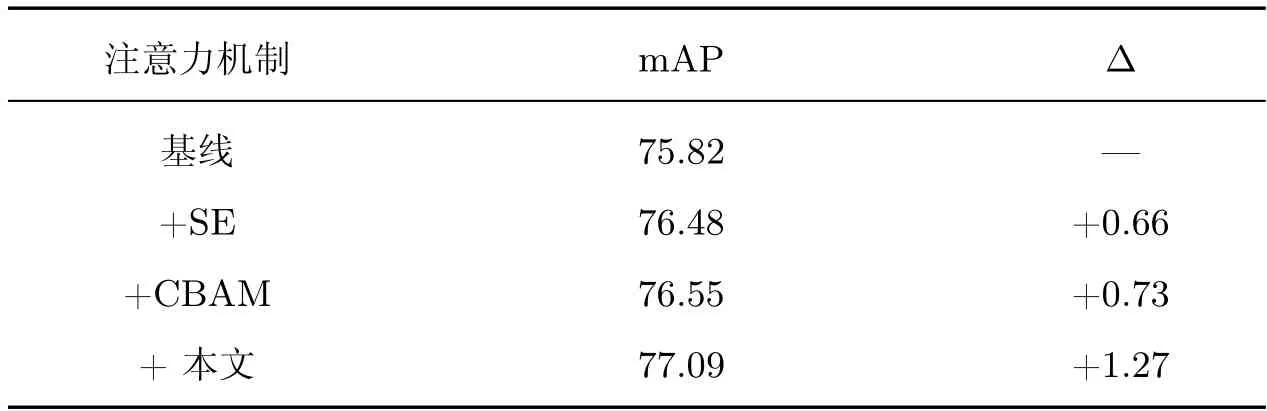
表7 不同注意力机制对网络的影响Table 7 Influence of different attention mechanisms on network
3 结语
针对遥感图像背景复杂以及图中的检测目标小、方向任意问题,本文提出了一种有效的遥感图像目标检测算法。首先,为了解决边缘信息和小目标信息丢失的问题,在特征提取阶段有效地融合不同感受野特征,利用丰富的上下文信息提高了网络对于目标尺度的自适应能力;其次,通过引用MOR 机制生成高质量的旋转框,可以更准确地包围狭长的小目标;最后,利用融合空间与通道注意力模块进行特征增强,极化函数对特定任务进行特征筛选,提高了目标的检测性能。在公共遥感数据集DOTA、HRSC2016 和UCAS_AOD 上进行的实验结果表明,所提方法比先进的算法有显著的提升效果,证实了本文网络的有效性。然而,多类别数据集中不同类别之间的性能不平衡仍然存在,主要因为直升机、桥梁、足球场等目标的实例数目比较少,网络无法充分学习。因此,在未来工作中,将重点放在低精度的目标实例学习中,同时损失函数的改进对检测性能也有很大的提升空间。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
测绘科学与工程(2016年5期)2016-04-17
电子设计工程(2015年3期)2015-02-27
电视技术(2014年19期)2014-03-11
