
基于深度学习框架的长序列大坝监测缺失数据插补模型
2023-11-28 02:14吉同元李鹏飞
水利水电科技进展 2023年6期
雷 未,王 建,吉同元,李鹏飞
(1.河海大学水利水电学院,江苏 南京 210098; 2.华设设计集团股份有限公司,江苏 南京 210014)
通过大坝安全监测手段获得的大量监测数据可为大坝运行状态提供评价依据。然而,由于仪器故障、系统停机、传感器老化、人为干扰等因素,不可避免地会发生监测数据丢失的情况,这给大坝安全的客观诊断带来了困难。测点的部分数据缺失不利于数据综合利用而影响整体安全评价;同时也会影响监测量可视化过程线的完整性。因此,需要针对大坝监测缺失数据提出一个有效的插补模型,以提高大坝结构监测的数据可靠性。本质上,传感器缺失数据的重建,特别是针对大坝效应量缺失数据的重建可以被认为是一个回归问题,可以通过因果模型建立外部荷载和大坝响应之间的关系来预测缺失部分的数据[1]。然而,在实际工程中大坝的行为可能取决于不可获知的变量因素,对于成熟的监测模型也可能存在环境资料缺乏的情况,无法为因果模型提供完整的特征数据。此外,也可以通过附近测点来判断目标测点的缺失值。这种插补模型通过分析测点序列的相似性,将高相似度的测点引入输入特征集来调控缺失部位的插补结果[2]。但当实际工程中的测点分布较稀疏,找不到目标测点的高相似度测点,或该高相似度测点也存在相同时间段的数据缺失问题时,这种插补方式将不再适用。本文从监测量自身时间序列的角度,探究监测量在时间轴上的变化规律,结合过去监测值与未来监测值的发展趋势对中间缺失数据进行插补。
目前,常用的缺失数据插补方法有拉格朗日插值法、均值法、最大频率法等[3],这些方法理论简单,操作方便,可以为少量零散的缺失部分提供较为准确的插补值。当面对长时间段的数据缺失情况时,通过以上填补技术则往往难以获得高精度的填补数据。近些年国内外学者将许多新兴的技术手段融入其中,并提出了很多优化插补模型,如支持向量机[4]、XGBoost[5]、高斯过程回归[6]等。以上研究均是以传统机器学习算法为导向,为解决数据缺失问题提供了较好的技术支持,但浅层机器学习算法依赖于一些需要人工设定的超参数,技术人员的操作经验决定了模型的训练效果。随着神经网络技术的发展,更加复杂层次的深度学习在相关领域中已取得重大突破[7-9]。深度学习存在两个重要的分支——循环神经网络(recurrent neural network,RNN)[10]与卷积神经网络(convolutional neural network,CNN)[11]。RNN在传统神经网络的基础上嵌入反馈、循环结构,具备记忆功能,但其结构相对简单,只能设置为神经元之间权重共享的连接形式,因此RNN在梯度传递方面存在缺陷,无法解决长时依赖问题,从而无法得到预期的结果。长短期记忆神经网络(long short-term memory,LSTM)作为RNN的一种变体,弥补了RNN的梯度缺陷,被广泛应用于时间序列的预测分析[12-13]。CNN通过利用局部相关性和权值共享的思想,极大地减少了网络参数,提高了训练效率,更容易搭建超大规模的深层网络。因此,CNN常被用于实现图像识别[14]、图像分类[15]以及目标检测[16]等。
本文提出一种基于深度学习框架的双向CNN-BiLSTM-Attention大坝监测缺失数据插补模型。该模型融合CNN与双向LSTM(BiLSTM)的算法优势,以提取大坝监测量时间轴的全局特征,同时引入注意力机制(Attention)来捕捉长时间序列中的依赖关系,进一步优化插补过程。此外,针对中间长序列缺失部位,按插补时间步递减的权重融合时间序列正反向插补值,消除时间步累计误差以提高插补精度。
1 双向CNN-BiLSTM-Attention大坝监测缺失数据插补模型
1.1 CNN
作为深度学习的代表算法之一,CNN是一种包含卷积计算的具有深度结构前馈神经网络。与传统模型相比,CNN可以实现网络结构中的参数共享,减少了模型训练计算所需的内存。一维卷积神经网络主要由输入层、卷积层、池化层、全连接层和输出层组成。输入层接收完整的历史观测变形数据。一维卷积层将预设的卷积核应用于历史观测数据时间轴的特征提取,卷积核在输入数据上滑动产生的一维滤波处理大坝监测数据y通常可以表示为
(1)
式中:xi-j+k为输入时间序列;wj为卷积核的权重矩阵;b为偏差;k为卷积核个数。
得到滤波后的大坝变形特征数据后,需要通过池化层进行维数压缩,以减少后续模型构建的计算量,同时赋予这些特征平移不变性,保证特征的可识别性。然后将这些降维特征与全连接层的神经元连接起来进行非线性回归计算,最后通过输出层输出预测结果。
1.2 LSTM
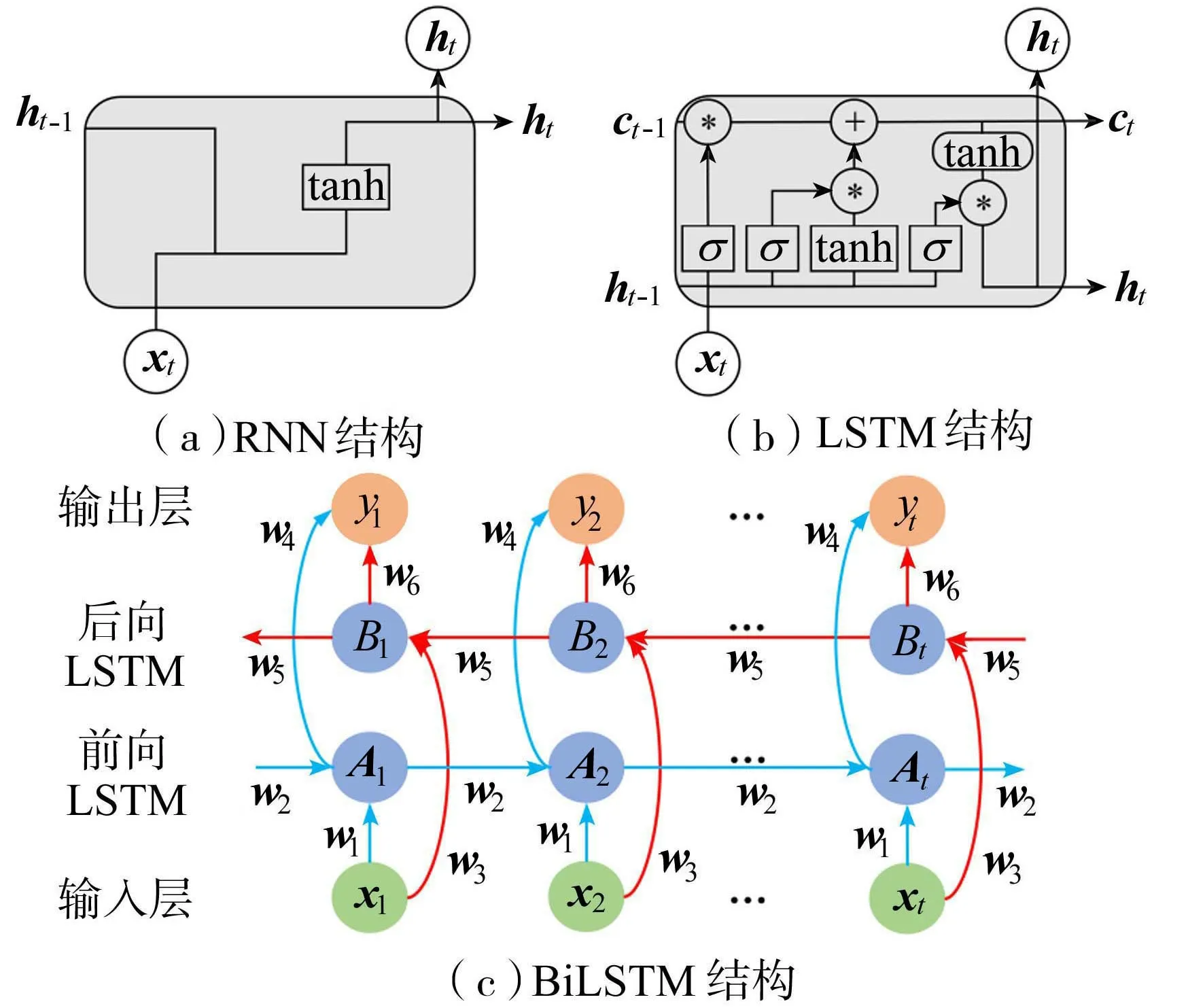
图1 RNN、LSTM 与BiLSTM结构
在LSTM基础上,进一步引入双向LSTM(BiLSTM),BiLSTM由分别获得前部和后部特征的前向LSTM和后向LSTM组成。与LSTM相比,BiLSTM当前循环单元的状态受前后数据的影响,因此在处理时间序列数据时可以更好地掌握整个数据流的信息。BiLSTM的结构如图1(c)所示。图中xi为输入数据,yi为输出数据,wi为权重。前向LSTM的隐藏层状态Ai和后向LSTM的隐藏层状态Bi以及BiLSTM的输出数据按以下方程进行处理:
Ai=f1(w1xi+w2Ai-1)
(2)
Bi=f2(w3xi+w5Bi+1)
(3)
yi=f3(w4Ai+w6Bi)
(4)
1.3 注意力机制
注意力机制源于人脑的视觉信号处理模式,通过快速扫描信息以获取人们想要关注的焦点与目标区域,无用的信息将被忽略。在深度学习中,注意力机制根据不同特征信息分配权重,对关键信息分配更大权重,不重要的内容则分配较小权重,这种差异化的权重分配使得信息处理更加高效。
注意力机制的基本思想是从海量数据中提取对后续预测更有用的信息,而实现该目标的本质是计算LSTM隐藏层的输出序列,即训练后的输入特征向量,进而得到特征权重向量,从中找到更重要的影响因素,使信息处理更高效和准确。
1.4 模型构建步骤
双向CNN-BiLSTM-Attention大坝监测缺失数据插补模型框架如图2(a)所示。该模型构建步骤如下:①构建CNN-BiLSTM-Attention深度学习框架,采用Conv1D和池化层组成的卷积层提取监测数据的内部特征,其中Conv1D提取监测数据时间轴的局部特征,池化层进一步压缩局部特征并生成特征的关键信息;②搭建BiLSTM隐藏层,从卷积层提取的局部特征信息中迭代学习,生成动态变化的全局特征;③将全局特征输入Attention层,利用注意力机制对全局特征通过加权方式进行重要性筛分,挖掘监测数据的时间相关性,过滤冗余信息以突出对插补结果影响更为关键的重要特征;④将Attention层与一个全连接层衔接,通过全连接层的激活函数输出最终的插补结果。此外,为了防止过拟合现象,在卷积层后添加Dropout层随机丢弃部分神经元,以提高模型的泛化能力与训练速度。
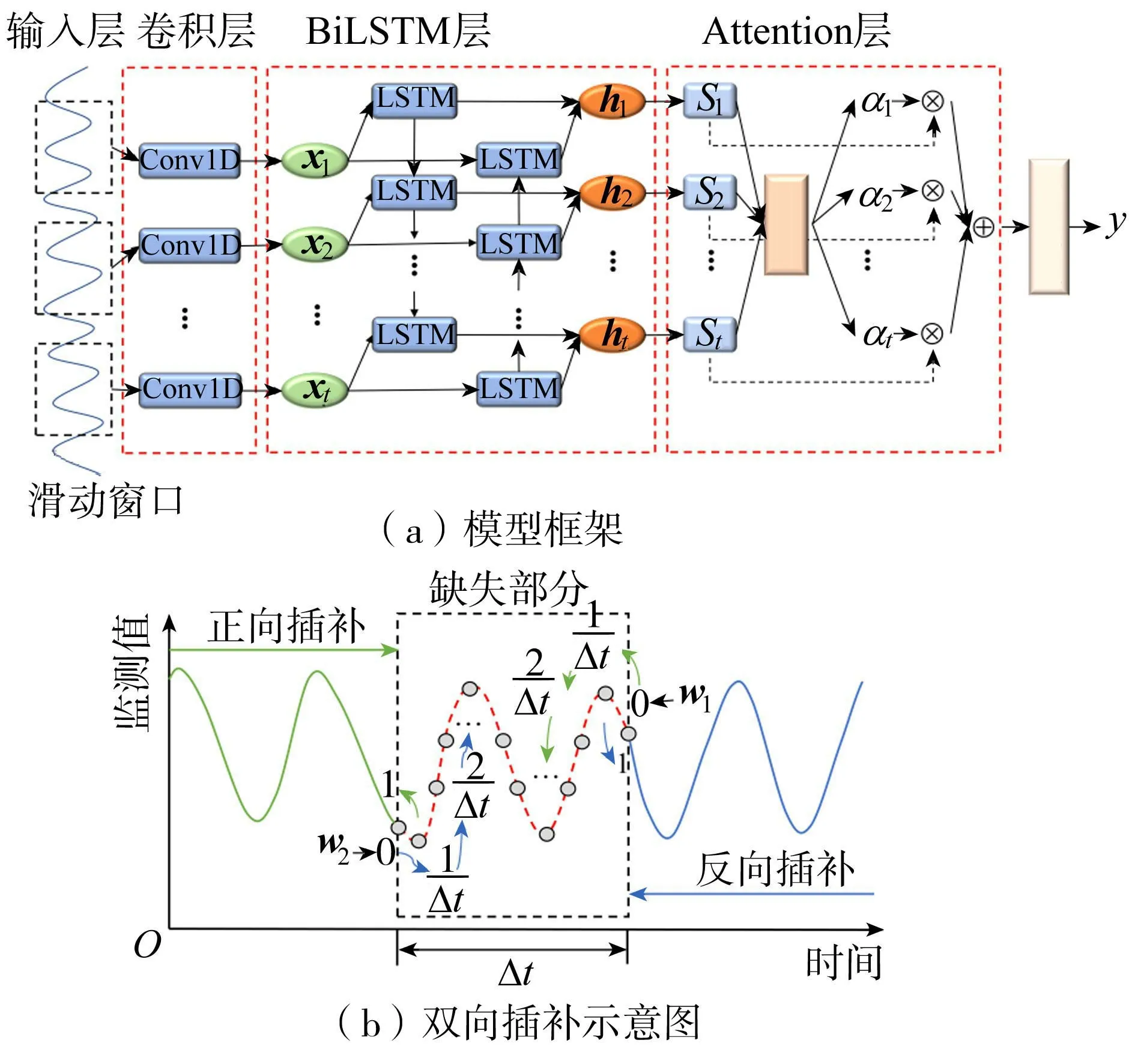
图2 双向CNN-BiLSTM-Attention大坝监测缺失数据插补模型
时间序列插补采用滑动窗口模式,即由窗口内的数据插补下一时刻的监测量,伴随着窗口的滑动,插补值逐渐被更新到窗口内,但这种插补方式会造成插补误差逐步累加。针对中间监测数据缺失的情况,本文采用双向插补模式来对缺失部分进行插补,即通过正向插补与反向插补方式,从时间序列两端同时对缺失数据进行插补,再按插补时间步递减的权重对两组插补值加权平均,二者结果互补形成新的插补值以避免插补误差在时间步中累积增加。如图2(b)所示,假设缺失部分的数据总时间步为Δt,正向插补过程的第1个插补值的权重为1,第2个插补值的权重为1-1/Δt,依此类推,最后1个权重为0,则记正向插补结果y1的权重为w1=(1,1-1/Δt,…,0)。同理,反向插补结果y2的权重为w2=1-w1=(0,1/Δt,…,1),由此获得插补模型最终的插补值为w1y1+w2y2。
2 工程实例
本文使用的模型测试数据来自某水电站工程的大坝变形监测数据。该工程始建于1937年,1985年建立真空激光测坝变形系统并开始观测。拦河坝为混凝土重力坝,共由60个坝段组成。选取11号坝段1985年1月11日至2010年3月22日的水平位移作为研究对象,人为删除中间段部分数据,采用双向CNN-BiLSTM-Attention大坝监测缺失数据插补模型进行数据填补以验证该模型的性能。
2.1 数据预处理
以水平位移监测数据为例,取11号坝段1985年1月11日至2010年3月22日共612组的历史测值作为训练集,分别删除两段长序列监测数据作为测试集(图3):①缺失部位Ⅰ对应1995年9月15日至1997年4月17日的30组监测数据;②缺失部位Ⅱ对应2000年4月11日至2001年11月15日的20组监测数据。

图3 11号坝段水平位移样条插值
采用时间序列插补模式对缺失部位进行插补,所分析的研究数据需为等间隔时间测值以避免时间效应误差,但实际监测数据资料为不等间隔时间观测,因此需要采用插值技术将其变为等时间间隔时间序列。这里采用三阶样条插值法对监测数据进行规整,如图3所示,每天取1组插值数据,则612组原始数据变为9200组插值数据。从图中可以看出,样条插值法对于少量零散的缺失数据插补效果较好,能基本覆盖原始数据的变化曲线。然而,对于长时间的数据缺失,其插补效果尚不能满足精度要求。
以滑动窗口模式对时间序列进行分析训练,设定窗口尺寸为L,即以当前时刻的前L个连续监测值推算当前监测值。插补模型的输入数据(特征)为{yt-L,…,yt-2,yt-1},模型的输出数据(标签)为yt。依照此方式,将数据集重构成特征集与标签集。为提高损失函数收敛速度、防止梯度爆炸,在训练模型前需将数据按公式(5)进行标准化处理,使数据全部落在[0,1]区间内。通过插补得到缺失部分的插补值后,再利用公式(6)对其进行反标准化处理,将数据恢复到实际监测范围内。
(5)
(6)
2.2 模型训练
基于Python软件深度学习框架keras搭建CNN-BiLSTM-Attention缺失数据插补模型。根据Chen等[17]的建议,应使用至少3个年度周期进行建模方可得到较好的训练结果。以缺失部位Ⅰ为例,本次训练设置正向插补滑动窗口尺寸为1200,反向插补滑动窗口尺寸为1600。表1给出了反向插补模式下的神经网络模型结构(总参数201401个,可训练参数201401个,不可训练参数0个),训练时采用Adam优化算法更新各层网络的参数。图4为模型在正向与反向训练时损失函数的变化情况,可以看出损失函数在训练过程中变化稳定,且总体呈下降趋势,反映了模型较好的训练性能。

表1 反向插补模式下的神经网络模型结构
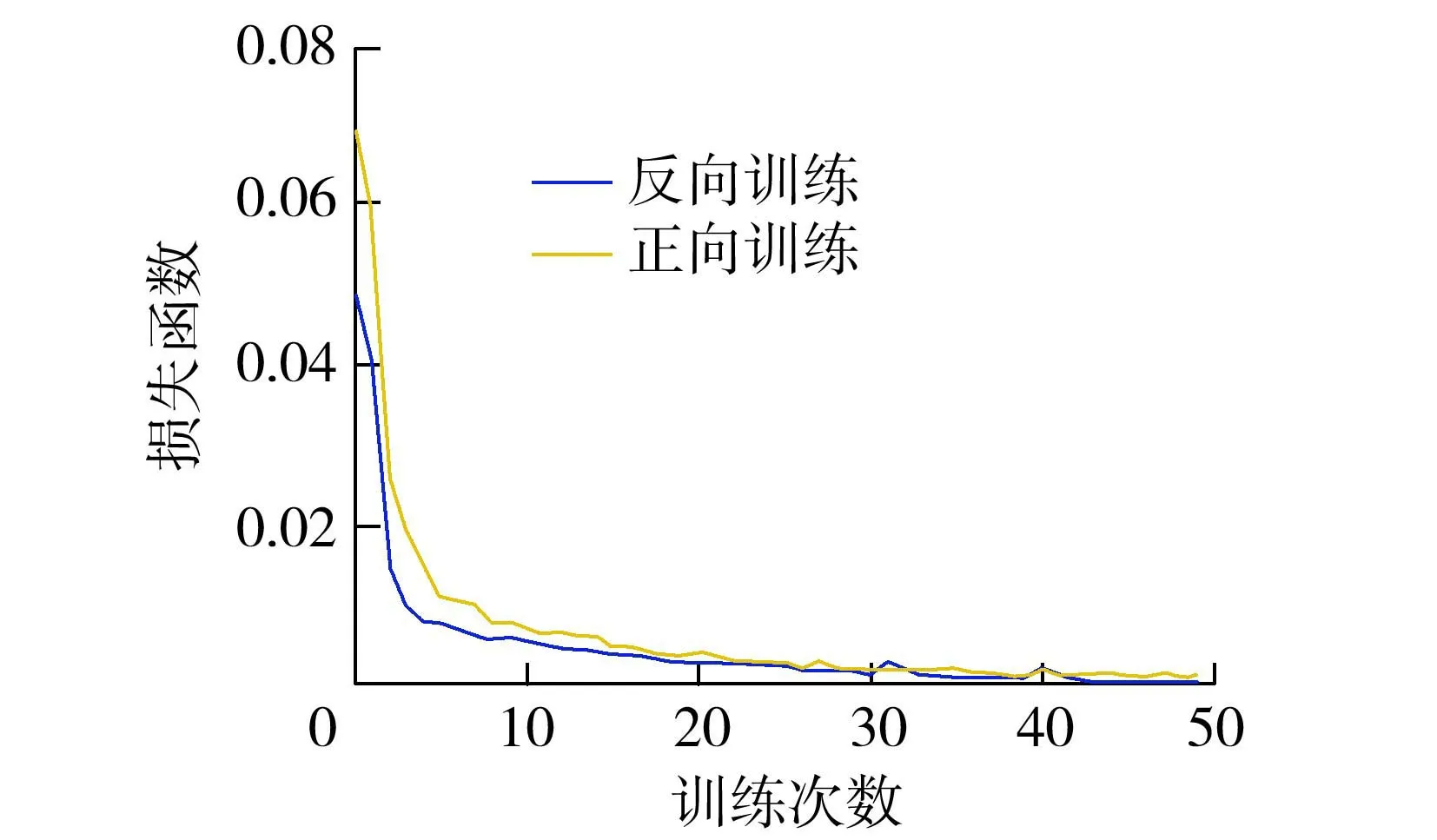
图4 模型训练的损失函数曲线
基于CNN-BiLSTM-Attention大坝监测缺失数据插补模型,缺失数据的正向插补与反向插补结果如图5所示。从图5可以看出,该模型两个方向均可获得较好的插补结果,但也反映了插补过程中时间步的累计误差。时间序列插补方式是由滑动窗口内的监测值组合插补下一个时刻未知值,并将窗口滑动一步(去掉第1个实测值,在末尾添加获得的插补值),形成新的窗口监测值组合。依照这种方式不断滑动窗口,直至所有的缺失数据均被插补。随着插补过程的推进,这种方式会将插补误差逐渐累加,使得插补值的走向逐渐偏离真实监测值。
为了消除这种累积误差,同时使两个方向的插补结果更好地融合,按插补时间步递减的权重对两组插补值加权平均,从而使得误差较小的插补值作为最终插补值的决定因素。如图5所示,融合后的计算结果很好地将正反向插补优势阶段组合在一起,其插补值与实测值的拟合程度优于单向插补结果。
2.3 模型对比
选择平均绝对误差(MAE)、均方根误差(RMSE)和决定系数(R)这3个评价指标,定量表示模型插补值f(xi)与实测值yi之间的误差。
为进一步体现本文所搭建的神经网络模型的优势,选取Spline、RNN、LSTM依照双向插补模式分别对缺失数据进行插补,其插补结果的误差对比如表2所示。由于Spline模型对于长时间段缺失数据的插补效果不佳,其误差指标和拟合程度均不如神经网络模型,故而未对Spline插值结果的误差指标进行计算。图6、图7分别为4种模型缺失部位Ⅰ、缺失部位Ⅱ插补结果与实测值的差异。基于3种神经网络模型,通过时间步递减的权重融合后的结果相较于单向插补值的精度都得到一定的提升。LSTM的插补精度总体高于RNN,但单向插补结果易出现较大的偏差,其插补性能无法得到稳定的保障。
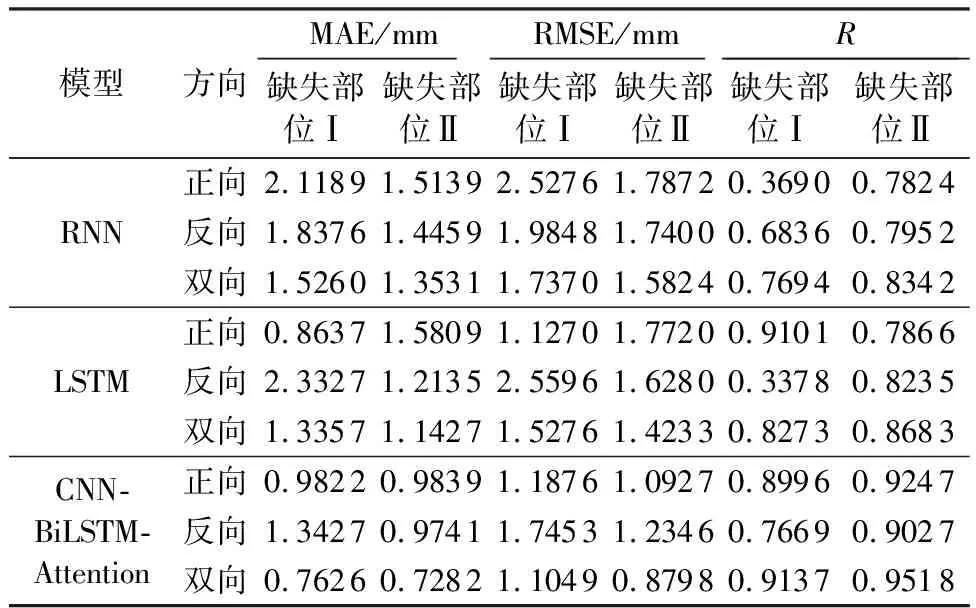
表2 各模型插补误差对比
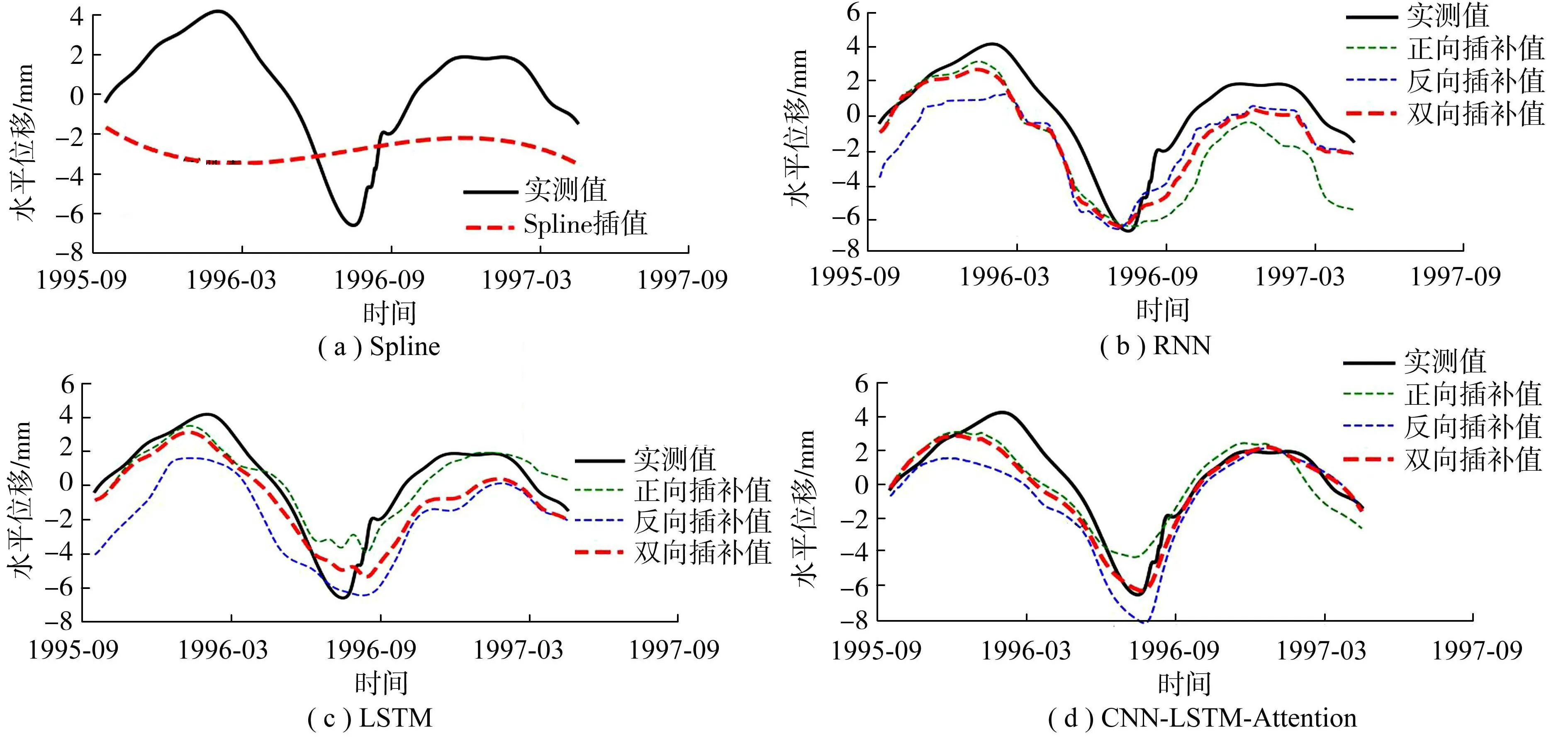
图6 各模型缺失部位Ⅰ插补结果与实测值的差异
本文所搭建的CNN-BiLSTM-Attention双向插补模型在正向与反向插补过程中均展现了较佳的插补性能,其双向融合插补值更为贴近实际监测值。这是因为CNN从原始时间序列中学习并提取时间轴上的局部特征,BiLSTM再根据局部特征提取全局特征后,冗余或非关键的特征被引入会影响最后的插补精度。此时,采用注意力机制来提取序列的关键特征,捕捉长时间序列中的依赖关系,克服了传统LSTM模型的不足。因此,CNN-BiLSTM-Attention网络能更有效地优化插补过程,从而提升插补精度。
2.4 插补效果
基于CNN-BiLSTM-Attention双向插补模型,对11号坝段水平位移缺失数据进行插补,结果表明插补值与实测值基本吻合。此外,为了验证该插补模型针对其他坝段监测量的插补效果,选取14号坝段的扬压力、渗流量以及垂直位移的监测序列,分别对中间缺失部位进行插补,表3为各效应量最终的插补误差,其中垂直位移插补值与实测值的吻合效果更好,扬压力与渗流量的插补值相较实测值稍有偏差,但总体趋势一致。
3 结 论
a.搭建了CNN-BiLSTM-Attention神经网络框架,CNN从原始时间序列中学习并提取时间轴上的局部特征,BiLSTM再根据局部特征提取全局特征,注意力机制捕捉长时间序列中的依赖关系,进一步优化插补过程。在工程实例中,这种神经网络框架展现了比RNN以及LSTM神经网络模型更优越的插补性能。
b.针对监测量中间缺失部分,提出了双向插补模式,并按插补时间步递减的权重对两向插补值加权平均,使误差较小的插补值主导最终插补结果的走向。工程实例表明,双向融合插补值与实测值的拟合程度优于单向插补结果,其处理长序列监测数据缺失问题时具有较高的插补精度。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
铁道通信信号(2019年11期)2019-05-21
北京航空航天大学学报(2018年1期)2018-04-20
百科知识(2018年6期)2018-04-03
振动工程学报(2015年1期)2015-03-01
全球定位系统(2015年4期)2015-02-28
电测与仪表(2014年3期)2014-04-04
电视技术(2014年19期)2014-03-11
中国三峡(2013年11期)2013-11-21
