
基于人文计算的藏医古籍服务平台知识服务功能设计研究
2023-11-24 06:34张心祺张承坤
现代情报 2023年11期
刘 佳 张心祺 张承坤
(1.吉林大学商学与管理学院,吉林 长春 130012;2.长春中医药大学基础医学院,吉林 长春 130117)
藏医文化是中国传统医学文化的重要组成部分,深受儒释道文化的影响,具有鲜明的民族特色与中国特色。藏医是世界四大传统医学之一,以青藏高原医学理论与实践为基础,融合中医学、印度医学等各类医学精华,具有系统的理论体系、用药特色和独特的临床疗效。藏医古籍文献作为藏医文化和藏医知识的重要载体,是藏族人民在特殊自然环境中不断摸索和创造出的智慧结晶,是少数民族医学中珍贵的文化遗产。习总书记在党的二十大报告中指出:“加大文物和文化遗产保护力度,加强城乡建设中历史文化保护传承,建好用好国家文化公园”[1]。藏医古籍既是凝聚藏医知识和藏族文明的瑰宝,也是坚定文化自信、深化文明交流互鉴的依据。在大数据、知识图谱、数据挖掘等智能信息技术空前发展的背景下,源于“人文计算”的数字人文的发展,为古籍资源的开发与利用注入了新的活力与思路,也为书写在医学古籍上的文字在新时代绽放异彩带来了新的契机。
在国家“实施国家古籍保护工程”“统筹推进古籍整理出版数字化,建设包括古籍资源在内的中华文化资源数据库”等重要政策的推动下,2018年,青海省藏医药研究院发文称600余种藏医药古籍文献借数字化重获“新生”。2021年,国家“藏医药产业技术创新服务平台公共服务体系建设”项目通过验收,建成了藏汉双语平台门户网站、信息管理系统和藏医药知识产权信息管理系统,建立了藏医药文献、藏医药标准规范、藏医诊疗技术、藏医瘟疫病防治等18个藏医药科技资源数据库。藏医学古籍的数字化建设为其深度开发与利用奠定了重要的基础。
但是,当前的藏医资源数据库大多只是在文献层面实现信息的组织与发布,对藏医古籍知识内容缺乏足够的描述、挖掘与提取,导致现有藏医资源平台信息服务价值较低,无法为藏医学研究与藏医药的开发创新提供足够的支持与保障。为了进一步深度开发与利用藏医古籍知识资源,本文尝试以藏医古籍服务平台为基础,探讨综合运用人文计算技术实现藏医古籍知识服务功能的方法。
1 相关研究进展
国内外学术界早已关注传统医学文献的深度组织与开发利用。在基础建设方面,Kvitting A S等[2]在关于全科医学知识库建设的研究中提出,全面系统的医学文献知识库有利于临床医务人员的医学实践以及领域内相关人员的教育实习。Naghizadeh A等[3]在对传统医学通用本体和知识库的研究中指出,在解决概念本体的构建问题时,通过文本挖掘和人工检查来保证提取术语的全面性,弥合传统医药之间的差距,有助于指导未来的药物发现研究。童丽等[4]借鉴计算机技术和统计学方法,提出藏药数据挖掘平台的设计思路。在此基础上,叶西多杰生等[5]阐述了藏文和藏医古籍文献数字化现状,并基于知识元对藏医本草语义元数据进行了描述。娘本先等[6]探索了基于Web数据库技术的藏医古籍本草知识库的构建思路,并指出具有知识检索和知识推理能力的知识库,是当前藏医古籍整理、传承和创新研究中的重要内容。李雪等[7]经过5年的整理,首次以藏文、汉文、英文和藏文拉丁文转写作为国际规范和标准及成果进行推广,首次以信息化平台建设的形式对藏医药古籍文献进行永久性数字化保存、保护及传播,并以发明专利、著作权登记等形式对藏医药古籍文献进行知识产权的保护。卡着杰等[8]指出,建设藏医学文献数据库在一定程度上是保护藏医学术再生的有效措施,并在后续研究中详细阐述了青海省藏医药研究院和中国中医科学院建设的藏医药文献整理与共享服务平台的设计与实现[9]。文成当智等[10]则整理总结出由“编号—方源—名称—组成—效用—附录—备注”七位一体的主体框架和18个展开项共同构成的藏药方剂底层数据架构,为方剂知识库构建与知识发现奠定了基础。
数据挖掘技术在病症诊断和用药规律的研究中受到学者重视。更藏加[11]从古籍和现代著作数据库中筛选治疗HAPC、HAPE的方剂文本,采用文献计量与数据挖掘等技术,对方剂配伍规律与常用药物作用机制进行研究,并通过临床试验,验证了药物的临床疗效;聂佳[12]从古籍和数据库中搜索高原病方剂并建立藏医药防治高原病方数据库,运用关联规则、熵聚类等数据挖掘技术发现用药组方规律及配伍原则,运用靶点预测等数据挖掘方法研究具体药物对高原病治疗的作用机制,为药物—疾病作用机制的发现提供新思路;罗彬[13]将数据挖掘技术、推荐算法与藏医用药理论结合,借助青海省藏医院积累的电子病历数据,设计并实现了藏医用药决策支持原型系统,辅助医生进行临床用药决策。上述研究均需以自行搜集、整理相关的藏医文献资源和知识资源为前提,已有藏医文献数据库并不能为科研工作者的学术研究提供足够的知识检索、辅助分析等功能支持。
藏医古籍文献的知识组织与知识服务方面的研究仍然较少,已有文献谈及藏医文献服务平台的综合性服务功能,信息检索、可视化分析、数据挖掘等,但较少文章从为专业用户服务的视角对藏医古籍服务平台的知识服务功能设计与实现方法进行研究。
藏医古籍是藏医学的主要知识来源,记载了古代的医学理论知识与实践经验,蕴含丰富的哲学思想和生命科学信息,将知识服务功能应用于藏医古籍服务平台中,可以为藏医学研究者、从业者、医生等提供更加精准、专业的服务,对藏医知识与经验的传承与创新具有重要的价值。
2 面向人文计算的藏医古籍知识组织
对藏医古籍知识资源进行更精细的知识表示与语义组织是数智时代文化遗产保护与活化的必然要求,也为人文计算在藏医知识研究中的新发展提供了充分的资源基础与保障。本文采用语义知识本体与知识图谱来实现对藏医古籍知识的描述与可视化展示。知识图谱本质上是真实世界中存在的各种实体、概念及其关系构成的语义网络图,用于形式化地描述真实世界中各类事物及其关联关系[14]。知识图谱由模式层和数据层构成。模式层用于描述知识结构模型,通过概念与概念之间的关系呈现,数据层包含具体的数据内容,通常以三元组的形式来进行描述。领域本体是描述特定领域知识的一种专门本体,是将领域的知识概念与概念间关系以结构化的形式进行表示的方法,并具有一定的推理能力。本文以藏医古籍知识本体模型为模式层构建藏医古籍知识图谱。
2.1 藏医古籍知识本体模型设计
藏医古籍服务平台的知识组织是基于本体方法构建知识图谱来实现数据建构的。基于本体的知识图谱能够清晰展示专业知识及知识间的关联,为数据挖掘、知识发现与知识推理提供数据基础。本文所设计的藏医古籍服务平台主要面向藏医学研究人员、医生、从业者提供专业知识服务,从用户需求考虑,在构建藏医古籍本体模型时,主要从古籍内容知识与古籍文献知识两个层面来描述藏医古籍知识。
古籍具有重要的文献价值和文物价值,是古籍形式和藏医知识的统一体。古籍文献知识的描述与表示,对于古籍的辨伪、校勘、研究中版本的选择具有重要意义。笔者利用CNKI,以“藏医*古籍*版本”“古籍*版本”“古籍*著录”“古籍*信息组织”为检索词获取与藏医古籍文献特征相关的研究论文,并以《中国中医古籍总目》《古籍著录细则》《中华古籍总目编目规则》作为古籍文献信息的补充,共同作为文献本体构建的语料,提取藏医古籍载体的相关概念。根据相关文献内容,总结、归纳概念之间的关系,综合复用古籍本体与中医文献元数据,形成藏医文献本体模型,由题名类、版本类、语种类、形态类、时间类、地点类、人物类、组织类8个核心类构成,用于藏医古籍文献知识的描述。
《四部医典》是一部集藏医药医疗实践和理论精华于一体的藏医药学术权威工具书,被誉为藏医药百科全书,为藏医药学中最系统、最完整、最根本的一套理论体系[15],是各藏医学院和藏医医院以及各大寺院的医明学院必学的基本教材。本文藏医古籍内容本体的构建以《四部医典》为主要参考资料,由于其内容集藏医理论与实践于一体,因此所构建的藏医古籍内容本体能够覆盖藏医学的理论与实践知识。依据《四部医典》的内容与体系结构,并参考中医古籍本体、中医古籍知识图谱的相关研究论文,对藏医药学的知识体系、知识内容进行分析,形成对藏医知识内容结构的初步认识。根据《四部医典》的知识内容,藏医知识可分为理论知识和实践知识两大类,在各章中选取部分原文,用Excel提取原文中的术语、上位术语,术语的概念和概念来源,结合原文注解、词句特点解析语料结构,利用《简明藏医辞典》等工具书和研究论文,确定上位术语与术语的定义,确定与藏医知识内容相关的概念,在分别确定概念含义的基础上,对这些概念之间的关系进行进一步分析,参考传统中医药学语言系统的语义网络框架(ISO/TS 17938-2014),以及在藏医研究论文中提出的概念之间的关系,提取并确定藏医古籍知识概念关系,将从古籍内容中提取的关系与已有成熟标准进行对照,进一步细化概念关系,构建藏医古籍内容本体模型。图1展示了藏医古籍的本体模型。

图1 藏医古籍知识本体模型
藏医古籍知识概念之间形成了18种概念间关系,表1具体描述了关系的含义与表示形式。

表1 藏医古籍知识概念关系表
2.2 藏医古籍知识图谱
在此基础上,利用分词、实体识别与关系抽取等知识处理技术,从《四部医典》中进行实体识别与关系抽取,并采用人工验证和修改的方式,手动验证自动构建的实体数据,并修复其中的错误、遗漏和重复,确保数据抽取的准确性。利用neo4j图数据库存储藏医古籍知识数据,以可视化的形式展示藏医古籍的知识与知识关联,如图2所示,并以此为数据基础,设计藏医古籍服务平台。

图2 部分藏医古籍知识图谱
3 基于人文计算的藏医古籍服务平台知识服务功能设计
为了向平台用户提供优质的知识服务,藏医古籍服务平台从3个方面进行功能设计,分别是以知识图谱为基础提供知识检索服务,基于知识图谱推理算法提供藏医知识推理服务,以用户偏好为导向提供知识推荐服务。在此实践中,知识服务效果具体体现在两个方面:提高藏医古籍服务平台对用户需求的匹配度,为藏医学研究提供细粒度数据支持;提高藏医古籍服务平台对用户需求的判断精准度,主动、准确推荐迎合用户专业兴趣的藏医古籍知识。
3.1 基于语义查询扩展实现知识检索功能
藏医古籍知识图谱蕴含丰富的藏医知识以及知识之间的关联关系,为藏医语义知识查询提供了标准化的知识表示。在进行知识图谱查询时,尽管三元组查询具有很强的表达能力,但因为他们在实施查询时执行严格的布尔匹配,查询结果比较局限,所以为三元组查询配备灵活的查询机制是非常必要的。本文基于藏医知识图谱的语义关系对检索关键词进行扩展,以提高知识图谱检索的效率与效果。
3.1.1 语义查询扩展算法
基于语义查询扩展的藏医古籍知识检索设计的重点在于扩展关键词的选择与检索结果的排序。
首先需要对用户的检索需求进行解析,确定查询的实体对象,即检索关键词。扩展关键词的选择则基于藏医古籍知识图谱的概念图谱与实例图谱。将用户的检索关键词映射到藏医古籍知识图谱中对应的概念,然后再根据藏医古籍知识图谱中的语义关系对概念进行扩展。具体的扩展方式包括根据藏医古籍知识图谱的概念结构关系向检索概念的同义词扩展,向上位概念与下位概念扩展,向相关概念扩展,以及根据实例知识图谱向概念的相关实例扩展。上述扩展方式在知识图谱中大多表现为上下位的关系,对于概念节点距离相同的情况,需要依据概念之间关系类型的不同,确定扩展概念对检索结果的重要性程度。概念节点之间的距离,以及概念节点间的关系类型决定了概念间的语义相似度,是确定查询扩展范围的主要依据,也是检索结果排序的重要依据。
根据藏医古籍知识的结构特征,综合采用基于路径距离的相似度、基于信息内容的相似度、基于概念属性的相似度与基于子节点重合度的相似度来进行概念对的相似度计算。
对于路径距离的相似度计算,应用Leacock等提出的概念语义距离相似度计算公式[16],在计算概念的相似度时,综合考虑概念之间的最短距离与其在概念图谱中的最大深度:
(1)
RCPN(c1,c2)表示概念c1和概念c2在知识图谱中的最近公共父节点,dp(RCPN(c1,c2),c1)表示概念c1和概念c2的最近公共父节点在概念c1所在的概念图谱中的深度,max(dp(c1))表示概念c1所在概念图谱的最大深度。
信息内容相似度计算上,参考许飞翔等[16]提出的结合概念关系贡献度的方法来计算信息内容相似度:
(2)
IC(c1)和IC(c2)分别表示概念c1和c2包含的信息量。sr(c1,c2)表示概念关系的贡献度,对于概念关系贡献度的计算,将藏医古籍知识图谱中的关系类型具体划分为同义关系、继承关系、整体与部分关系、同位关系、空间关系、时间关系、因果关系与条件关系。综合考虑概念关系的重要性程度,并根据领域专家的建议,为具体的概念关系赋予不同的权重。
在基于概念属性的相似度计算上,借鉴张忠平等[17]提出的综合计算属性名称、属性数据类型和属性值3个要素的相似度计算方法。对于概念c1的属性a和概念c2的属性b之间的相似度计算公式为:
Simab(a,b)=ω1×sim(aname,bname)+ω2×sim(atype,btype)+ω3×sim(avalue,bvalue)
(3)
其中,name、type、value分别对应属性名称、属性数据类型和属性值,ω1+ω2+ω3=1表示属性名称相似度、属性数据类型相似度和属性值相似度的权重和。当两个概念之间有m个共有属性时,可以计算出m个属性相似度结果,设每个相似度结果的权重为ωk,则两个概念间属性的相似度计算公式为:
(4)
参考许飞翔等[16]提出的子节点重合度的相似度计算思想,两个概念之间具有的相同子节点的数量越多,说明两个概念之间的相似度越高。根据子节点重合度计算概念相似度的公式为:
(5)
LN(c1∪c2)表示概念c1和概念c2所包含的子节点集合中全部元素的个数,LN(c1∩c2)表示概念c1和概念c2子节点交集中元素的个数。
综合以上算法,根据不同相似度计算方法对语义的作用程度,得出知识图谱中概念c1和概念c2之间语义相似度的计算公式:
Sim(C1,C2)=ωSimsd(c1,c2)+θ(Simpr(c1,c2)+Simic(c1,c2)+Simln(c1,c2))
(6)
其中,ω和θ是权重,ω+θ=1,ω>θ。
根据上述方法,可以以藏医古籍知识图谱为基础,确定基于检索关键词的语义扩展范围,并据此确定检索结果的排序。
3.1.2 语义查询扩展算法应用于知识检索的优势
语义查询扩展算法充分利用了藏医古籍知识图谱中丰富的概念与概念之间的语义关系进行扩展检索。在用户表达出的原始查询意图的基础上,通过进一步扩充检索关键词的方法,在不牺牲检索精度的同时,提高了检索的召回率。综合多种概念相似度算法的结果排序方式,既能够满足用户精确检索的需求,同时通过对相关藏医古籍知识的展示,能够进一步挖掘藏医古籍服务平台用户的潜在需求,帮助用户发现自己不熟悉但却有重要启发意义的藏医领域知识,因此,语义查询扩展算法对于专业知识检索具有较好的适用性与检索性能。
3.2 基于知识图谱推理算法实现知识推理功能
为了能够深入探索和挖掘藏医古籍中的知识资源,为专业医学工作者提供科研辅助与支持,藏医古籍服务平台采用Qu M等[18]提出的RNNLogic算法,通过神经网络增强符号规则的方法,利用规则生成器生成高质量的逻辑规则,利用推理预测器识别有用的规则并改进规则生成器,二者互相增强,生成更高质量的逻辑规则,在学习高质量规则权重的基础上,得出更准确的知识推理结果,为藏医古籍知识挖掘、方剂配伍规律与诊疗方法的研究提供辅助支持。
3.2.1 基于逻辑规则的知识图谱推理算法
应用RNNLogic方法来对藏医古籍知识图谱中给定查询的概率分布进行建模。设Pdata(G,q,a)是一个训练数据的概率分布,G是藏医古籍知识图谱,由(h,r,t)三元组构成,也可以表示为r(h,t),q=(h,r,?)是一个查询,a=t是答案。给定知识图谱G和查询q,目标是预测正确答案a,即对概率分布p(a|G,q)建模。
本文采用迭代联合训练规则生成器和推理预测器的方法来不断提高推理结果的准确性。

pθ(z|q)=Mu(z|N,RNNθ(·|r))
(7)
对于一个查询q,推理预测器pw(a|G,q,z)的任务是使用一组规则z在藏医古籍知识图谱G上推理并预测查询q的答案a。推理预测器定义了答案a是正确答案的概率。使用对数线性模型进行推理。对于每个查询q,基于一个组合规则可以在藏医古籍知识图谱中找到不同的路径,得到不同的候选答案。设A为一组候选答案的集合,这些候选答案可以通过规则组的任一逻辑规则被发现,对于每个候选答案e∈A,可以计算出每一个候选答案e的标量得分。
(8)
每个候选答案e的得分是通过计算每个规则贡献的得分之和得到的,通过对藏医古籍知识图谱中找到答案的每条基础路径求和得到候选答案e的得分。而对于每个规则标量权重的计算,依据嵌入算法为每个实体引入一个嵌入,将关系建模为实体嵌入上的旋转运算符。对于从头实体到尾实体规则的每个基础路径,根据旋转运算旋转头实体的嵌入,可以获得接近尾实体嵌入的一个嵌入,将这个嵌入和尾实体嵌入之间的相似度作为对每个路径的可靠性和一致性的度量。这种方法能够计算每个路径的相似度,可以使不同的候选答案得到更精确的得分。通过使用softmax函数就能进一步确定项目e是查询q的答案的概率。
(9)
在每次训练迭代中,首先根据规则生成器生成的规则更新推理预测器,然后使用期望最大算法(Expectation-Maximization算法)更新规则生成器,算法包括Expectation和Maximization两个步骤。在Expectation步骤中,可以将每条规则的得分作为对规则质量的评估。这里主要考虑了两个因素:一是推理预测器pw,它的计算方式为一个规则对正确答案的贡献分数减去该规则对其他候选答案贡献的平均分。如果一个规则对真实答案给出较高的分数,而对其他候选答案给出较低的分数,认为这一规则可能更重要;二是规则生成器pθ,通过计算每个规则的先验概率并使用概率进行正则化,选取得分最高的规则作为规则集来训练规则预测器。在Maximization步骤中,进一步用这些高质量的规则来更新Expectation步骤中规则生成器的参数。对于每个数据实例,将对应的规则集作为训练数据的一部分,通过最大化规则的对数似然值来更新规则生成器。推理预测器的反馈被应用于规则生成器。通过这种方式,规则生成器将学会只生成高质量的规则供推理预测器进行推理,这样就减少了搜索的空间,并能产生更好的推理结果。
scorew(e)=MLP(AGG({vrule,|P(h,rule,e)|}rule∈I))
(10)
vrule是每一个规则的一个向量嵌入,P是通过规则发现的从头实体到尾实体的基础路径的数量。AGG是一个聚合器,它的目标是把路径数作为聚合权重,聚合所有规则嵌入向量vrule。得到聚合嵌入后,MLP神经网络就会进一步将嵌入投影到候选答案e的标量分数上。使用藏医古籍知识图谱嵌入可以进一步提高候选答案的标量得分。知识图谱嵌入方法能够推断出可信度评分,来判断(h,r,t)是有效的三元组的可能性。在此基础上,将逻辑规则得分与知识图谱嵌入得分相结合,得到关于得分的函数,再次对得分应用softmax函数来计算候选答案e是正确答案的概率,再通过最大化每个实例的可能性来优化推理预测器,从而保障推理结果的准确性与推理的高效性。
3.2.2 基于逻辑规则的知识图谱推理算法的优势
在藏医古籍服务平台应用基于逻辑规则的知识图谱推理算法的优势在于,同时运用逻辑规则训练规则生成器和推理预测器,两者能够相互增强,推理预测器为训练规则生成器提供有效的奖励,规则生成器通过提供高质量的规则来改进推理预测器。和以往采用隐式方式发现简单规则的算法不同,本文所应用的算法显式地训练规则生成器,能够生成更复杂的逻辑规则,并且能够通过推理预测器的反馈动态更新规则生成器,规则生成器由此学会只生成高质量的规则供推理预测器进行推理,既提高了推理的可解释性,也可以逐步提高藏医古籍知识推理的效率。基于知识图谱嵌入的知识推理方法,更适用于在藏医学研究这类对推理精度和可解释程度要求较高的领域中应用。藏医古籍服务平台的推理结果将为藏医组方规律、配伍原则、药物—疾病作用机理与医疗方法的研究提供重要的辅助与支持。
3.3 基于偏好传播算法实现推荐功能
为了充分利用藏医古籍知识图谱进行用户推荐,平台采用Wang H等[19]提出的RippleNet知识图谱感知推荐模型,利用用户偏好在知识实体集合上的传播,通过知识图谱中的链接自动迭代地发现用户的潜在兴趣层次,根据用户对候选相关知识项目的偏好分布,预测用户对知识图谱内相关知识的点击概率,从而实现可解释的知识推荐功能。
3.3.1 偏好传播算法
藏医古籍知识图谱中包含丰富的藏医古籍知识实体以及实体之间的联系。知识图谱中的这些复杂联系为通过知识链接探索用户偏好成为可能。RippleNet模型根据用户的检索历史和知识图谱链接,抽取与用户节点相连的N跳实体节点,并利用这些实体节点的嵌入更新用户的嵌入,通过用户嵌入和知识项目嵌入的点积预测推荐结果。
在具体实施过程中,给定交互矩阵Y和知识图谱G,用户u的k跳相关实体集合可定义为:
(11)
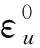
用户u的k跳波纹集合可以定义为:
(12)

为了以更细粒度的方式对用户和藏医古籍知识项目之间的交互进行建模,使用偏好传播技术来确定用户在其波纹集合中的潜在兴趣。每个知识项目v都可以用项目嵌入来表示。给定项目嵌入v和用户u的1跳波纹集合,1跳波纹集合中的每个三元组(hi,ri,ti)通过将项目v与这个三元组中的hi和ri进行比较来确定相关概率,即通过在关系Ri空间中计算项目v和头实体的相似度来确定相关性概率。
Pi=softmax(vTRihi)
(13)
在获得相关概率后,将波纹集1跳距离的尾部实体总和乘以相应的相关概率,返回向量。这一向量作为用户u的检索兴趣偏好对项目v的一阶响应。
(14)
用户的检索兴趣沿着波纹集合中的链接,从其历史检索兴趣转移到1跳相关实体集合,这样就实现了检索偏好的传播。
重复偏好传播的过程,可以获得用户不同阶数的多个响应,通过组合所有阶数的响应,可以计算用户u关于项目v的嵌入。
(15)
最后通过计算用户嵌入和项目嵌入的点积,输出预测的推荐结果。
(16)
通过这种方式,RippleNet模型沿着知识图谱中的链接传播用户的历史检索偏好,发现用户对藏医古籍知识图谱内相关知识的潜在兴趣,以此为依据进行知识推荐。
3.3.2 偏好传播算法的优势
在藏医古籍服务平台上应用偏好传播算法的优势在于,RippleNet感知推荐模型将基于嵌入和基于路径的方法相结合用于知识图谱感知推荐中。RippleNet是一个用于知识图谱感知推荐的端到端的框架,通过在藏医知识图谱中迭代传播用户的检索偏好,自动发现用户的多层潜在兴趣。通过偏好传播将知识图谱嵌入方法自然融入到知识推荐中,无需手工操作,系统可以自动发现从用户历史检索记录中的检索项到相关的知识项目的可能的路径。同时,藏医古籍知识图谱中丰富的知识链接,有助于提升知识推荐结果的准确性、多样性和可解释性。
4 藏医古籍服务平台知识服务的实现效果
在藏医古籍服务平台试验过程中,初步整合了3部藏医古籍中的部分数字资源,在平台上提供藏医知识检索、知识推荐和知识推理等知识服务功能。基于知识图谱的扩展查询,使平台能够从文献、内容多角度全面呈现用户查询知识项目的整体知识架构;应用知识推理技术能够帮助藏医古籍服务平台用户发现藏医知识间的潜在关联;使用用户偏好传播算法使平台能够准确依据用户检索偏好推荐平台知识内容。根据专业研究人员的使用体验反馈,平台根据用户的检索历史所推荐的信息能够准确反映用户的需求,推荐的内容符合专业研究人员的检索与阅读兴趣,平台不仅能够提供具体的知识内容,还能够提供内容来源,并能够为藏医学研究提供具体的数据支持。藏医古籍服务平台知识服务的实现效果如下:
4.1 知识检索功能实现效果
在藏医古籍服务平台中,可以在检索结果返回界面中观察到基于知识图谱的语义查询扩展功能的呈现效果,如图3所示。以“冰片七味方”检索关键词为例,藏医古籍服务平台页面左边呈现的是文献检索的结果,系统根据用户输入的检索关键词,在知识图谱中进行概念匹配检索,并根据藏医古籍知识图谱的概念结构关系,向“冰片七味方”的同义概念、上位概念与下位概念扩展,返回了包含检索词“冰片七味方”及其近义概念或相关概念的文献列表;平台页面右边是根据检索关键词“冰片七味方”和知识图谱语义扩展生成的藏医古籍知识信息,根据概念语义扩展算法,将与检索词“冰片七味方”语义相似度较高的方剂组成、方剂用法、方剂疗效的知识呈现出来,图片中的知识图谱中呈现了以“冰片七味方”节点为中心的相关知识内容。

图3 基于知识图谱语义扩展实现知识检索效果图
4.2 知识推理功能实现效果
在藏医古籍服务平台中,知识推理的实现主要是通过知识分析的功能,以知识图谱与关联数据来呈现的,如图4所示。以“肺病”为检索词,在平台的知识分析功能中,展示了平台中与肺病相关的疾病共有54种,治疗肺病的相关方剂共有43种,由221种药物制成。通过药物出现的频次数据可知,竹黄、红花、白糖、小豆蔻是组成方剂的主要药物。本文应用提出的基于逻辑规则的知识图谱推理算法,对规则生成器和推理预测器进行联合训练。规则生成器根据查询中的关系生成组合逻辑规则并计算规则的概率,对于“肺病”的查询,推理预测器使用一组规则在藏医古籍知识图谱上推理并预测查询的答案,基于组合逻辑规则,可以在图谱中找到不同的路径,得到不同的候选答案,通过对候选答案标量得分的计算,依据嵌入算法计算其与尾实体嵌入的相似度,以此作为对候选答案路径可靠性与一致性的判断依据。在平台中,以相关疾病链接与相关方剂链接的形式展示了知识推理的结果。根据推理,肺湿水、肺热、肺痈、热塞、热痛等疾病与检索疾病的相似度较高,而丁香六味方、景天独味汤、草河车独味汤等是相似度较高的治疗方剂。通过知识图谱中可以直观地观察到节点的聚合关系,辅助专业人员根据病因、疾病、症状等节点的关系分析病机与病理,判断治疗疾病的核心药物与组方规律。

图4 知识推理功能实现效果图
4.3 知识推荐功能实现效果
藏医古籍服务平台根据用户的检索历史发现、预测用户对藏医古籍知识图谱内相关知识的潜在兴趣与偏好,从而实现可解释的检索结果推荐功能。如图5所示,左右两侧呈现了不同的用户采用同一检索词“冰片七味方”进行检索所返回的检索结果。左侧的用户是初次利用平台进行检索,系统根据检索词判断其检索的是一种药剂概念,在检索结果中主要返回了“冰片七味方”作为药剂的检索结果。而右侧是老用户的检索结果,平台根据这一用户的检索、浏览历史判断用户的偏好,预测用户对藏医古籍知识图谱上相关知识的点击概率,并在检索结果中将预测的内容返回在检索结果列表中。通过后台数据了解到在用户以往的检索历史中,曾利用关键词“尿色赤黄”“肝痛”进行检索,同时该用户还在平台上浏览过与“热症”相关的文献内容,由此,系统形成了对这一用户偏好的判断,根据输入的检索词,系统预测该用户对知识图谱上相关知识的偏好,在检索结果中优先推荐相关结果给用户。

图5 知识推荐功能实现效果图
5 结 语
保护和传承中华民族文化资源具有重要的意义。人文计算技术的发展与数字人文的兴起,为少数民族文化的传承、保护与传播带来了新的模式与机遇。本文针对藏医古籍服务平台的知识服务功能进行研究,将人工智能算法应用于藏医古籍知识的开发与利用,以期为藏医学研究人员与医生用户提供更专业、精准、优质的知识内容服务。在未来的研究中,将进一步完善和丰富藏医古籍知识图谱,基于藏医古籍知识图谱设计更为丰富和智能的服务功能,提高服务的精准度与智慧化,为藏医学研究与藏族文化传播提供智慧支持与保障。
猜你喜欢
信息安全与通信保密(2023年8期)2023-10-12
加油站服务指南(2022年6期)2022-07-28
汉字汉语研究(2021年3期)2021-11-24
天一阁文丛(2020年0期)2020-11-05
湖北农机化(2020年4期)2020-07-24
天一阁文丛(2018年0期)2018-11-29
通信电源技术(2018年3期)2018-06-26
金桥(2017年5期)2017-07-05
中国民族医药杂志(2016年2期)2016-05-14
中国民族医药杂志(2016年6期)2016-05-09
