
数字人文视角下藏医学古籍知识发现研究
——以《四部医典》为例
2023-11-24 06:34:34梁世豪李昕娱王文欣宋雪雁
现代情报 2023年11期
沈 旺 梁世豪 李昕娱 王文欣 宋雪雁
(吉林大学商学与管理学院,吉林 长春 130012)
藏医学古籍是藏族人民医学智慧的汇集,是我国宝贵的医学资源。从古至今遗留下来的藏医学经典古籍有《医学大全》《无畏的武器》《月王药诊》《四部医典》《晶珠本草》等,蕴含着大量可挖掘利用的内容信息。数字人文(Digital Humanities)起源于人文计算(Humanities Computing),其目的是将数字技术融入学术研究,以解决人文领域存在的问题。在数字人文领域,研究热点涉及文化遗产、GIS技术应用、语料库建设、数字档案以及数字图书馆等,相关技术包括知识图谱、关联数据、IIIF、人工智能等。数字人文技术的发展,推动着人文社科领域相关资源开发利用新途径的发现。本文以藏医学经典古籍《四部医典》为例,运用统计分析、关联分析、聚类分析、可视化技术等方法工具,挖掘藏医学古籍中的病症关系、病因关系、用药规律以及可能的新处方,并通过可视化图片呈现,拟为研究藏医学古籍知识发现提供一种可行的思路,有助于藏医学古籍的开发与利用,也有利于藏医学的发展与传播。
1 研究回顾
1.1 藏医学古籍研究
通过对国内外藏医学古籍以及数字人文领域现有文献研究的梳理发现,由于藏医学古籍的民族特性,国外相关研究甚少,仅有Dhondrup W等[1]利用层次分类对《四部医典》中5种疾病的病因关系进行了可视化分析。国内相关研究较为丰富,曹明泽等[2]梳理了藏药发展史,占堆等[3]以时间为线梳理了藏医药学的发源、发展以及未来。梁成秀[4]对《四部医典》的编撰进行了解读,不过更多学者的研究重点在挖掘藏医药古籍中蕴含的用药思想与规律。文成当智等利用复杂网络等分析方法,发掘出藏医学用药倾向“食疗加药物,药物加治法”的规律,从藏医药学的“味性化味”理论出发,揭示藏医学用药规律的科学内涵[5-6]。旦增米吉等[7]从《四部医典》中含有印度獐牙菜的处方出发,挖掘藏医学用药配伍规律。
1.2 数字人文研究
数字人文主要指的是以数字化的资源为对象,利用一系列的数字技术对其进行收集、加工和利用,以此来实现知识发现的过程[8]。数字人文相关研究主要涉及数字人文工具开发、数字人文整体情况研究、数字人文项目借鉴研究以及人文资源实例研究。
首先在工具开发方面,国外研究较丰富。Moretti G等[9]开发了能帮助人文学者在数字环境中进行大量文本数据分析的工具——ALCIDE。基于3个不同的数字人文项目,Zwaan J M等[10]介绍了可视化工具Storyteller,相较于其他可视化工具,其具有能交互式展示复杂数据的优势。Terras M等[11]为解决人文学者在计算上存在的技术障碍,通过实例研究探索最能满足人文学者研究需求的高性能计算设施。Arnold T等[12]将重点放在对词袋、词频模型的超越,通过使用核心编程语言编写的软件包R,以便能对数字人文相关的文本分析进行更人性化的研究。
其次在数字人文的整体情况研究方面,Joo S等[13]运用文本挖掘技术,聚焦数字人文近10年的研究热点与趋势,发现文化遗产、地理信息、语义网等关键词。国内,刘炜等[14]为促进数字人文的整体发展,将数字人文的理论结构与方法论在宏观层面进行了深入探讨。周晨[15]ADDIN以WoS核心合集数据为基础进行内容分析,发掘了目前国际上数字人文的发展现状、研究热点等情况。邓君等[16]以CNKI的文献为数据基础,利用文献计量学等方法技术研究了我国数字人文的研究热点与发展情况,并进行了可视化展示。Su F L[17]通过社会网络分析并借助可视化工具,对数字人文研究中有关跨国合作的主题、模式、结构等进行了深度研究。李娜[18]回顾并梳理了国际数字人文近20年的文献研究,探寻了其热点主题、演化路径以及知识基础等内容。
数字人文项目借鉴研究,文献研究主要在国内。郭金龙等[19]在综述数字人文领域文本挖掘技术的相关应用后,重点介绍了欧美发达国家(地区)在其中的前沿实践,期望为我国数字人文的发展与转型寻找可借鉴之处。徐志玮[20]以“挖掘数据挑战”项目为例,研究了国际合作视角下数字人文的研究现状,为国内相关部门提供决策参考。
最后,对于数字人文的研究更多集中于案例研究。国外,Earley-Spadoni T[21]通过实例研究的方法探讨了如何通过数字人文拓宽地理空间技术在考古上的应用,使考古学家受益。Hoeve C D[22]论证了利用数字人文技术进行家谱和家族史研究的可行性以及重要性,为家谱研究提供了思路。Hu S F等[23]利用有关尼泊尔语言的文献资料,展示了一种基于Web的多媒体制图,在集成地理空间数据的同时还可以集成多媒体数据。Fedeli A[24]通过语言编码与数字编辑对古兰经手稿文本进行了研究,并提供了一个可进行多协作工作的跨国、跨文化系统,在数字编辑手稿以及数据多协作处理方面有重要意义。Plets G等[25]通过实例,研究出了针对于大量考古文本的文本挖掘方法,帮助追踪、分析以及情境化考古术语的变化。国内,赵思渊[26]利用《中国地方历史文献数据库》阐明数据化与文本挖掘的实现路径,并提出以元数据为基础的针对数据库这一新文献形态的方法论。邓君等[27]利用中国历史人物传记资料库(CDBD)中的清代进士数据源并借助于数字技术对其进行剖析,实现了对于清代进士群体的社会网络关系的知识发现,为传统的人文研究提供了新的研究范式。夏翠娟等[28]以两氏家谱为例,详细阐释了关联数据在家谱中的应用与作用。欧阳剑以大量古籍文本为基础,采用一定分析挖掘方法,帮助深层次开发与利用古籍,是一次对模式创新的尝试。Huang J J等[29]提出一个新的社会网络研究框架,帮助人们理解和分析历史人物的社会关系,并通过中国传记数据库中的项目数据验证了其有效性。张毅等[30]以方志数据库的建设为例,结合国内外数字人文发展情况,对如何活化利用特藏资源进行了说明。李斌等[31]以《左传》知识库为研究对象,利用各种语言处理技术,为古籍文本内容的标记和结构化人文知识库的构建提供了创新性方法。常博林等[32]以《资治通鉴》为研究对象,成功构建了基于词和实体检索并且能够进行知识挖掘的知识库,同时利用时间序列分析,挖据出了历史中人、地、事所蕴含的信息。岑萧萍等[33]以《易经》为例,利用文本挖掘以及可视化,挖掘并展示了六十四卦中存在的联系,提供了新的中医古籍挖掘思路。汤萌等[34]以《石仓契约》为研究对象,利用元数据和可视化等方法技术,率先探索了这些方法在进行民间账簿资源挖掘的可行性。
从上述研究中可以看到,采用数字人文的方法对古籍文献进行深度开发与利用是当前的研究趋势。因此,本文选择藏医学古籍资源作为研究对象,运用数据挖掘可视化分析方法,提出数字人文视角下的藏医学古籍知识发现过程并进行可视化分析,展现藏医学古籍数据价值的内涵。
1.3 知识发现研究
随着不断的完善,知识发现的定义也在随着社会的进步不断地发展。最初的定义追溯到了1996年法耶德所认为的,知识发现是从大量的数据中鉴别出有效模式的非凡的过程[35]。而国内研究对于知识发现的定义则更为贴切,大多数的学者认为知识发现是指对大量的积累的数据进行挖掘和分析,并从其中获取有效的、有用的以及新颖的可以理解的知识[36]。近年来,互联网的进步带来了海量的数据,挖掘其中有价值的知识已经成为众多学者研究的热点。尤其是在医学领域中,为了支持和辅助临床决策,大量的学者对疾病、病症以及药物的内在关联进行挖掘和研究,诞生了众多研究成果。虞红蕾等[37]构建了经方领域的消渴病知识图谱,并在此基础上进行知识发现和知识查询,对于中医药智能问诊、临床辅助决策都有重要的意义。安欣宇等[38]采用路径发现,链路预测从知识图谱中挖掘了知识之间的隐含关联,发现了38种治疗精神分裂症的药物之间存在隐含关联,为发现潜在的治疗精神分裂症疾病的药物提供了相应的帮助。蔡妙芝等[39]提出了基于SPO语义三元组的疾病知识发现模型,以糖尿病为例揭示了糖尿病相关的以及常见的并发症、检测手段及治疗方式,为疾病的临床诊疗和日常防控提供了借鉴。
从上述研究来看,对医学领域中相关知识进行挖掘对于疾病的治疗和预防都有十分重大的意义,这也是本文将《四部医典》作为研究对象的原因之一。
2 研究对象与研究过程
2.1 研究对象
本研究以藏医学古籍《四部医典》为研究对象,选用版本[40]为1987年上海科学技术出版社出版的,由宇妥·元丹贡布等著、马世林等译注的中译本,在超星图书馆获得电子资源。此译注版本以多个版本的藏文《四部医典》为基础进行译注,行文更符合现代汉语习惯,在保证内容完整性的前提下更易于理解与分析内容。《四部医典》是公元8世纪由著名藏医药学家宇妥·元丹贡布编著,被誉为“藏医药百科全书”。全书共有4部,包括《总则本》《论述本》《密诀本》和《后序本》,共156章。第一部纲领性地介绍了人体的生理、病理、诊断及治疗。第二部详细介绍了人体的生理解剖及疾病发生的原理、原因和途径等。第三部详细论述了各类疾病的诊断和治疗。第四部介绍脉诊、尿诊及各种方剂的配方、功效和用途以及外伤的疗法等。《四部医典》中包含藏医学种种,有着关于藏医学方面最根本、最完整、最系统的理论体系,其内容可以为藏医学古籍知识发现提供充分的数据支持。研究数据主要来源于《四部医典》的第三部《密诀本》和第四部《后序本》。《密诀本》中依照内科疾病、热疾、腑脏疾病、私处疾病、零星杂症、疮症等分别叙述病因、病缘、症状、治法等。《后序本》中从脉诊、尿诊开始,再叙述汤剂、散剂、丸剂等消除疾病的方法,以及催吐药、滴鼻药剂、各类导剂等疾病排除方法,最后再是针刺放血、灸法、药浴等外用治疗方法。此两部分内容是《四部医典》中重点叙述的部分,占据大部分篇幅,包含了藏医学关于疾病诊断、治疗、用药等几乎所有内容,保证了内容分析的全面性。
2.2 研究过程
本文主要利用Python、Gephi、R语言等工具软件,按照文档识别与校对、数据分词与提取、数据存储、数据分析处理、数据可视化、结果阐释的研究过程,最终实现知识发现。
藏医学古籍知识发现的过程如图1所示。①文档识别与校对阶段:主要是对《四部医典》PDF资源进行OCR识别与人工校对,重点对将进行数据分析的部分校对;②文本分词与提取阶段:针对分析需要,从第三部《密诀本》中分词提取了疾病名称、疾病症状、疾病部位以及部分疾病病因等相关实体。从第四部《后序本》中分词提取了方剂类型、处方用药以及主治疾病等相关实体,存储在对应数据库或工具表中为数据分析处理做准备;③数据分析处理阶段:这一部分主要是针对古籍中的不同内容采取不同的方法分析处理。病症关系分析进行了疾病症状的聚类分析以及疾病部位的关联分析。病因关系分析进行了词云分析以及关联分析。用药规律分析进行了方剂类型、药材种类、主治疾病的统计,然后进行药材的聚类分析以及关联分析。最后通过聚类分析和关联分析的综合运用进行新处方的预测分析。该环节主要使用Python软件以及R语言来完成,是整个研究的核心部分;④数据可视化及结果阐释阶段:针对分析结果利用相关可视化工具方法得到可视化结果图以及结合藏医学基本理论,阐释分析结果,完成藏医学古籍知识发现,可视化的过程包括利用Python的Matplotlib绘制条形图、散点图来实现可视化。利用其中的Wordcloud库进行词云可视化,以及利用Gephi软件和R语言以及SPSS26.0进行关联网络图可视化。
3 藏医学古籍《四部医典》知识发现
3.1 文本识别及人工校对
文本识别和人工校对是研究的起点,其结果直接影响了研究的准确性。因此,在本阶段当中,笔者依托于超星图书馆所获得的《四部医典》的电子资源,其版本在上一章中进行了具体说明,利用Acrobat Pro DC来进行OCR识别。为了保证本研究的真实性和权威性,对OCR的结果按照电子资源进行人工校对以避免出现识别结果和真实电子资源不符的情况。此外,还选取了其他平台同版本的电子资源同OCR结果进行比较,最大程度上保证了文本识别结果和数据资源的一致性。
3.2 文本分词及实体提取
藏医学古籍《四部医典》的知识发现主要是通过两个部分来呈现的,首先是文本的分词以及实体提取,这一部分的结果是整个研究的基础,其次是数据处理和可视化阶段。
医学古籍不同于其他的文本形式,在《四部医典》中无论是在病症、病因还是处方当中,许多词汇是以标点符号来进行分割的,因此这在一定程度上减轻了分词的工作量。所以在文本分词中,本研究利用Python的Jieba分词的基础上,同时采用标点符号划分的方法来对经过OCR后的文本进行分词。如在原始文本的处方中,药材之间用“、”“,”来进行隔断,因此可以根据标点来将不同的药材进行分割,根据标点分词在一定程度上减轻了分词的工作量且提升了效果。对于较为生僻的药材以及词汇,采用输入词典的方法来确保不会出现预期以外的单词,如对于“喜马拉雅紫茉莉”的处理,将其规定为一个词组以避免其出现“喜马拉雅”和“紫茉莉”拆分为两个词组的情况。
在实体提取阶段,由人工方式来对涉及的实体进行识别和提取,主要对《四部医典》的《密诀本》《后序本》中所涉及的疾病的病因、病症、药方等进行提取得到了相应的疾病病因、疾病病症以及药方实体。
在数据处理和可视化的阶段,本文通过对藏医学古籍《四部医典》的内容进行聚类分析、关联分析、词云分析、统计分析,得到了病症关系、病因关系、用药规律、预测新处方等分析的分析结果,然后采用相应的技术手段将其进行了可视化展示并对其结果进行了相应的解读和阐释。
3.3 病症关系分析及可视化
在本节中,针对疾病的症状、疾病的发生部位分别进行聚类分析以及关联分析。在聚类分析中使用K-means聚类方法以期获得不同疾病的症状之间的区别和联系。在关联分析中采用Apriori算法并根据不同疾病发病部位的信息建立了关联网络,以期获得不同疾病发病部位之间的潜在关联。最后,利用Matplotlib函数与Gephi软件分别进行散点图和关联网络图可视化,更好地解读聚类分析和关联分析的结果。疾病症状聚类散点图中,同一形状颜色的点代表同一类别。疾病部位关联图中,每个节点代表一个部位,节点越大代表疾病部位出现次数越多,节点间连线,反映了疾病部位之间联系的强弱,权重越大代表联系越强。
3.3.1 疾病症状类别分析可视化
由于不同的疾病在症状上存在一定的相似性,因此病症聚类分析利用疾病症状的相似性聚类,以期将疾病划为多个类,探索同一类别下疾病与症状间的情况,以此更好地区分不同疾病的相似症状,提高诊断的准确性。病症关系分析中,提取了《密诀本》中的不同疾病及其症状的实体,采用手肘法确定了聚类所形成的簇为4,利用Python进行K-means聚类分析,如图2所示。疾病症状聚类结果中,蓝色圆点、绿色圆点、红色五角星和天蓝色圆点分别属于聚类类别0、1、2、3。
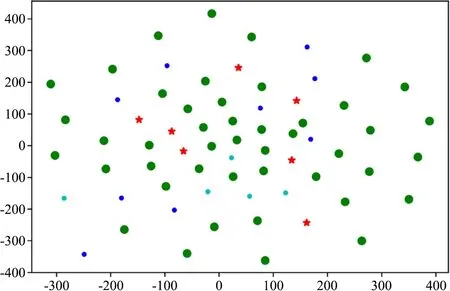
图2 疾病症状聚类结果
从整个聚类分析的结果来看,可以直观看到类别1数量最多,而类别0中的疾病有不消化症、胃病、大肠病、便秘等,症状排在前几的也是呃逆、疼痛、肠鸣、不消化,与腹泻、肠胃等疾病有关,此类别下还有痼疾痞块、脾病等,说明它们之间在症状表现上有一定相似性。类别1的数量较多,有45种疾病,涉及的疾病种类更多样化,如头部疾病、口腔病、眼病、鼻病、耳病等,症状上多是疼痛、肿胀、发痒、发热、刺痛、口苦等,说明这些疾病常见的症状主要是疼痛发痒等。类别2症状上多是疼痛、肿胀、刺痛、肠鸣、胀满,涉及的疾病相比较而言多是与溃烂、疮症等相关,还有就是脏腑、内脏等疾病。类别3多是失眠、热症、疼痛、刺痛、尿色等症状,全是与热症有关的疾病。
关于疾病的诊断,从症状上来看,疼痛、刺痛等相关症状出现频率最高,这也是身体最直观的反应。从整体上来看,不同的疾病的症状表现有其特殊性,病症聚类分析通过疾病症状进行聚类,可以帮助梳理疾病在症状表现上具有的相似性,提高诊断的准确性。
3.3.2 疾病部位关联网络可视化
疾病的发生往往涉及到多个部位,因此在疾病部位的关联分析中,本节利用从《密诀本》中提取的疾病及其发病部位的实体信息,据此建立了不同疾病发病部位之间的关联并进行了可视化的分析。图3为关联可视化图,可以清晰地看到藏医学对疾病的认知是从身体的各个部位出发的,在进行疾病诊断时需要多方面考虑。
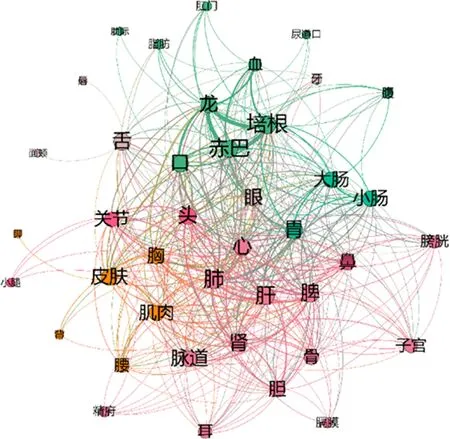
图3 疾病部位关联图
藏医学理论中,龙、赤巴、培根是藏医学独特的身体部位称呼。在图3中看到代表它们的点不仅硕大,并且之间的连线权重也大,说明它们不仅在疾病部位描述中出现的次数多,而且经常同时出现,联系十分紧密。这种情况也再次印证了龙、赤巴、培根是藏医学基础理论的三大因素。此外,可视化中心部分呈现的疾病部位——口、头、心、眼、胃等,也涉及到身体各个部位,连线亦错综复杂,体现了藏医学认为身体部位不是孤立的而是相互联系的思想。
3.4 病因关系分析及可视化
本节主要选取了《密诀本》中部分疾病的“病因”“病缘”“疾病分析”3个部分内容进行病因关系分析,选择的疾病与热症相关——未成型热症、陈旧热症、扩散热症、虚热症、伏热症、热症扩散、浊热症、紊乱热症8种疾病。
在藏医学理论当中,疾病的病因主要是指产生疾病的根本原因,而病缘则是指被引发的条件,可以具体划分为“生发”“积发”“具体外缘”。生发是指可以使得疾病多样化的条件,积发是指可以让疾病集聚明显的爆发的条件,具体的外缘则主要指的是可以使得疾病明显、迅速的爆发。这3种形式均为藏医学理论中的病缘,仅仅是因为表现的形式有所区别。
病因往往和疾病的产生相关,而病缘往往与疾病的发生相关,了解和把握疾病病因的关系,厘清疾病病缘的产生,对于把握整个疾病的爆发具有十分重要的意义。所以,在本节中,首先对疾病的病因在分词的基础上进行了词云展示,以期迅速获得与病因相关的信息中藏医所重点关注的对象。其次,针对于病因病缘间的关系进行了关联分析及可视化。关联可视化的节点有疾病名称、疾病病因、疾病病缘以及疾病分类,权重相同,着重展示疾病在病因方面的联系。
3.4.1 病因词云分析可视化
病因的词云分析当中,利用《密诀本》中与热症相关的病因实体,对病因中所出现的词汇进行了词频统计,然后利用Python形成了热症的词云图。病因词云分析突出展示了在藏医学中被反复高频提及的词汇,有利于迅速抓住藏医学中的核心要素。在词云图中可以直观地看到龙、赤巴、培根这三大藏医学专用名词在病因分析中也占突出位置,再次印证龙、赤巴、培根在藏医学中的重要地位,是藏医学的理论基础。还可以清晰地看到此次分析的疾病种类——未成型热症、陈旧热症、扩散热症、虚热症等。除了上述的关键词之外,年龄、自性、境域、时刻、饮食、起居等病因病缘也较为突出,展现了藏医学在诊断疾病病因时的基本情况。词云展示结果如图4所示。

图4 热症词云图
3.4.2 病因病缘关系分析可视化
病因关系分析可视化有助于了解疾病产生上的相似性,帮助疾病预防。在病因关系分析当中,提取《密诀本》中有关热症的疾病及其病因的实体,因为不同的热症在病因、病缘及病缘的产生上存着一定的相似性,因此,据此且基于Apriori算法建立不同热症的病因、病缘之间的关联并进行可视化分析。如图5所示,不同的疾病中涉及到了不同的病缘,但是不同的病缘的产生存在着相似趋向,因此从这个角度来看,虚热症、未成型热症、紊乱热症、热症扩散以及伏热症在外缘形成上存在一定的相似性。如虚热症的外缘为外缘虚热,其形成多与年龄、境遇、时刻、病体等因素相关。未成型热症的外缘为外缘未成型以及外缘扩散,其形成多与自性、年龄、时刻等因素相关。伏热症的外缘为外缘隐伏其产生多与年龄、病体等因素相关。因此,上述阐述所涉及的热症及其外缘的产生上几乎受到了一致因素的影响。其中紊乱热症、伏热症、热症扩散在病因涉及部位上更具相似性,其大多都涉及到了肝、肾、心等部位;未成型热症、陈旧热症、浊热症、扩散热症间在病因病缘上存在着一定的关联,如未成型热症和陈旧热症之间存在着夹风陈旧热症的表现,而浊热症和陈旧热症在外缘上都是外缘陈旧等诸如此类的关联。了解病因关系有利于医生全面把握不同疾病之间的关系,判断其他潜在疾病,从整体上制订治疗方案,这也体现了藏医学中相互联系的思想。

图5 热症病因关系图
3.5 用药规律分析及可视化
关于用药规律的分析首先进行用药基本情况统计,之后再依据每组处方的药材情况分别进行聚类分析与关联分析。本节中,K-means聚类分析展现的是用药相似性之间表现的主治疾病、方剂类型的关联情况,而基于Apriori算法的关联分析展现了藏医学的常用药材与常用药材组合,节点代表的每一种药材,权重代表使用的药材之间的关联强弱程度。
3.5.1 用药基本情况统计
用药基本情况分别对方剂类型、处方用药以及主治疾病进行了统计。如图6所示,用以分析的用药数据中方剂类型共有15种,数量从多到少依次是散剂、汤剂、泻药配方、草药配方等。其中散剂配方数量遥遥领先,共有123方,接着是汤剂74方,泻药配方50方,草药配方40方等,方剂种类大多还是消除疾病的处方。
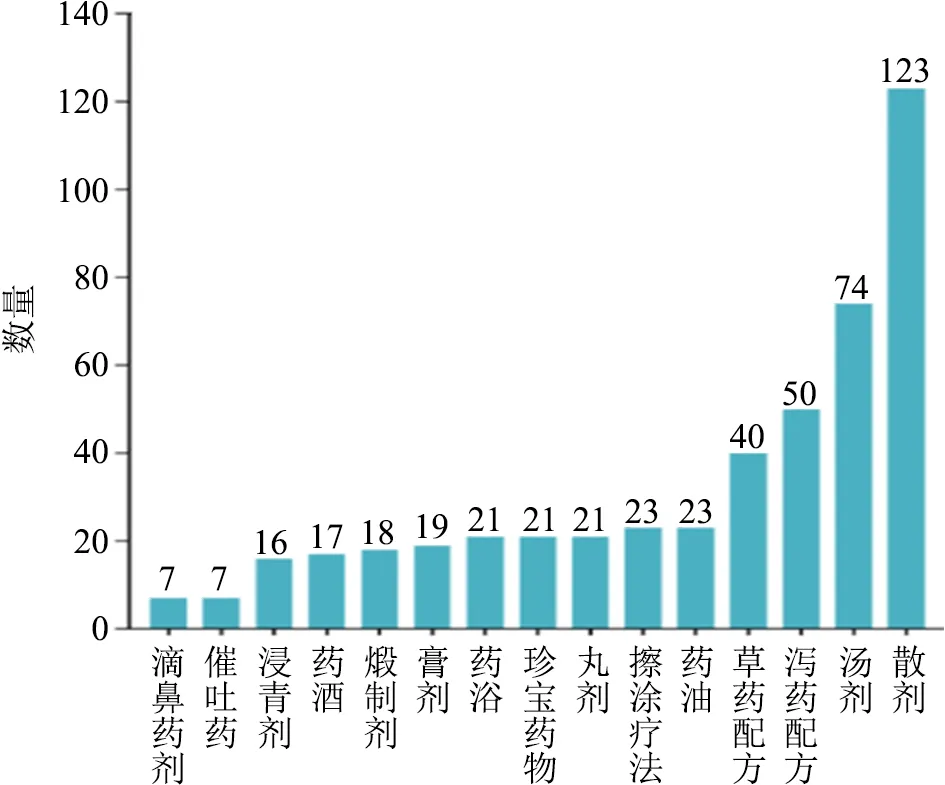
图6 方剂类型统计情况
其次,对处方整体用药情况进行统计。因涉及药材种类繁多,只截取了前20进行可视化展示。如图7所示,可以清楚地看到诃子、荜茇、小豆蔻、红花、白糖的数量相比较其他药材明显更多且差距较大,而后续药材使用数量的差距就开始变小,但其他药材使用量差距较小。从表1剩余部分药材统计情况中,也可以观察到药材使用频次的差距也是十分小的。

表1 剩余部分药材统计情况
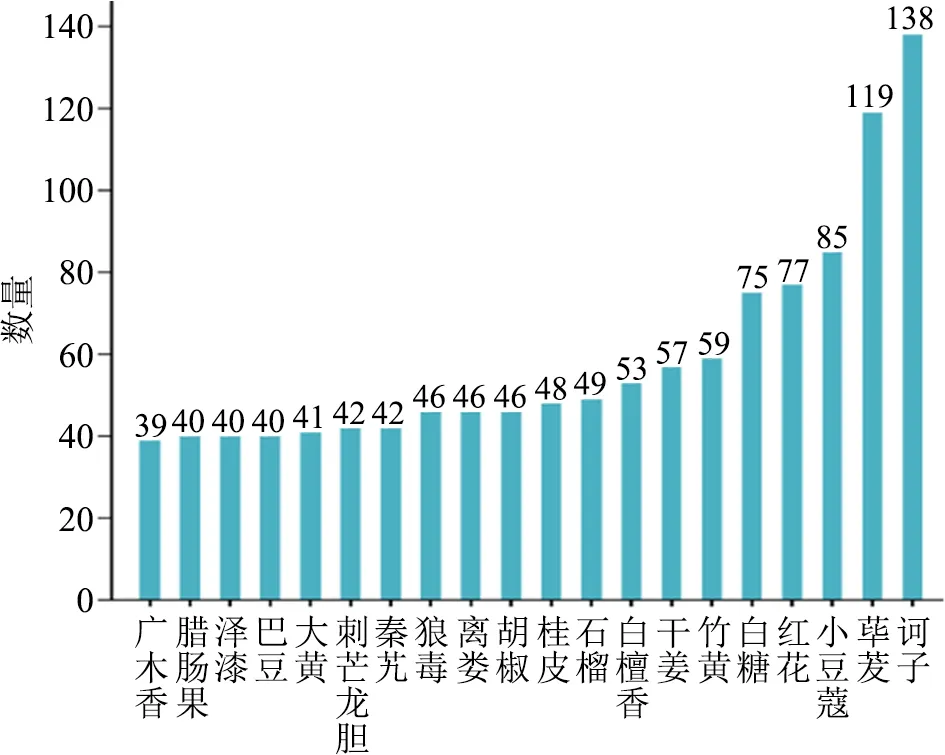
图7 药材统计情况
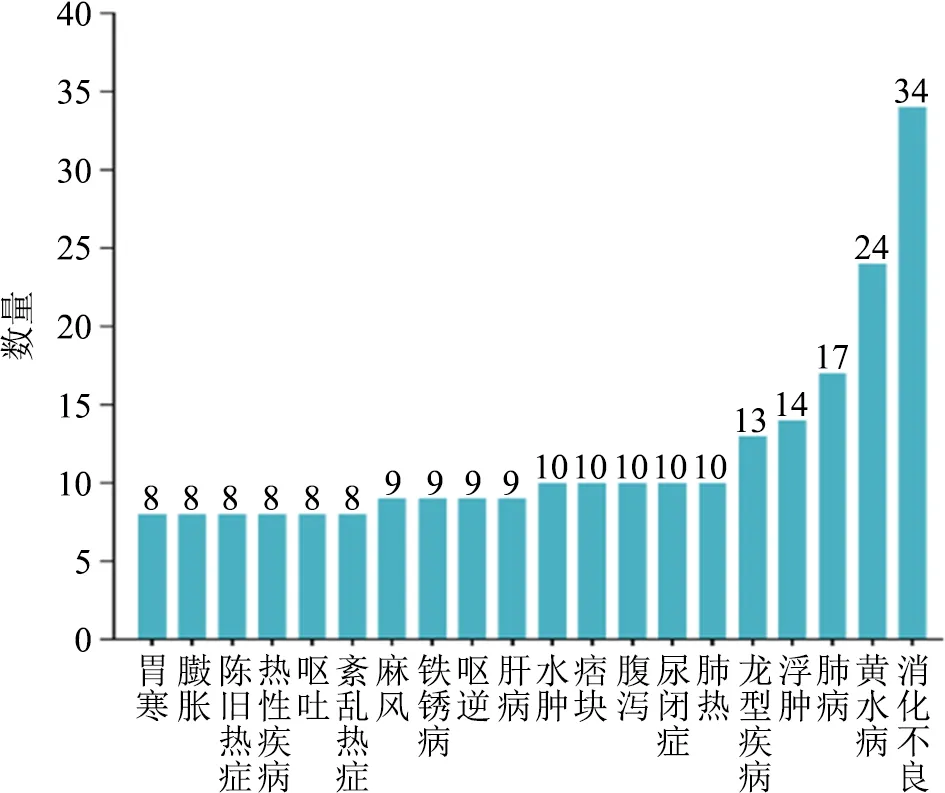
图8 主治疾病统计情况
用药药材的统计是对藏医学用药的整体了解,这可以看出藏医学用药偏向于生活常见食材,这反映藏医学优先考虑以食养病的思想。同时药材统计中一些较为罕见的药材,也将藏医学与其他医学用药方面的特殊性区分开来。
最后是对主治疾病的统计,可以看到消化不良以及黄水病排在前列,数据中也有不少关于热症的疾病。《密诀本》中就提到很多关于热症的讲述——热症的总治法、未成型热症、虚热症、伏热症、陈旧热症等,因此《后序本》中关于热症治疗也不少。此部分的统计是对藏医学主治疾病的基本了解,也为后续新处方预测分析的疾病选择做了前期了解。
3.5.2 药材关联分析可视化
基于Apriori算法的药物关联分析,其目的是探寻藏医学在治疗疾病时所使用药材间存在的关联与规律。药材关联分析利用了《密诀本》中不同疾病治疗所需的药方实体,根据不同的药材在不同处方的共现来建立不同药材之间的关联并进行了可视化分析。如图9所示,可以清晰地看到较为突出的点有诃子、红花、荜茇、白糖、小豆蔻、白檀香、竹黄等,这些药材同样是出现频次最高的几类药物,说明它们是藏医学用药的重要药材。接着观察线条的权重,可以直观地看到药材间关联的紧密程度,即哪些药材之间同时使用的频率更高。
蓝色线条中,以诃子为中心的药物——刺芒龙胆、离娄、巴豆、腊肠果、泽漆、白檀香等,相互之间联系就很紧密。此外,红花、竹黄、小豆蔻、荜茇之间的联系同样十分紧密,再向外桂皮、胡椒、石榴、白糖等的联系也较为突出。从图中还能观察到部分药材的联系是独立的,由于参数设置的原因,不能说这些独立的药材与其他药物之间没有联系,只能说明关联很弱。
可视化结果直观地展现了药材的重要性以及药材之间关联的强弱,这些关系反映出藏医学用药的常用药材以及常用药材组合,为理清藏医学用药规律有极大帮助。
3.5.3 药材类别分析可视化
在药物类别分析中提取了《密诀本》中不同处方的方剂类型实体以及药材实体,是根据处方用药情况进行K-means聚类,观察聚类结果中同一类别下药剂类型和主治疾病的情况。图10为聚类可视化结果,蓝色圆点、绿色圆点、红色五角星、天蓝色圆点、紫色五角星分别代表聚类类别0、1、2、3、4。图中可以直观地看到天蓝色圆点最多,即类别3数量最多,结合整个聚类分析结果,类别0中数量最多的药剂类型是散剂与丸剂,主治疾病大多是消化不良,用药药材前几有胡椒、荜茇、生姜、藏红盐、小豆蔻等;类别1中则是泻药配方数量最多,主治疾病中脉病、头部疾病以及涉及五脏六腑的占比较多,药材中泽漆、诃子、刺芒龙胆、大黄、狼毒等排在前列;类别2最多的仍是散剂,其次是膏剂、药油,疾病上突出的是热症相关疾病,药材则是红花、竹黄、白糖、诃子、牛黄等;类别3中是汤剂、散剂,主治疾病上主要是黄水病、消化不良和龙型疾病,药材主要有诃子、秦艽、地衣、紫草、黄连等;类别4最多的仍是散剂,主治疾病则是消化不良、呕逆、肺病、腹泻和痔疮,药材主要有荜茇、小豆蔻、干姜、桂皮、石榴等。

图10 药物聚类结果

图11 中药使用频率统计图
聚类结果体现出了不同主治疾病之间的联系,并且对于发现同类疾病新的治疗药物具有一定的参考价值,这同时也体现了不同的药剂类型在治疗不同疾病时的一种相似性,如研究发现散剂在治疗消化不良以及与消化系统相关的疾病中使用最多,泻药的配方多和内脏相关等,这些发现对于理解藏医的医学思想有巨大的帮助。当然不同疾病需要不同类型的药剂,这同时也说明了在藏医学中认为,不同的药剂类型对于疾病的治疗效果也是存在着差异的。
3.5.4 方剂药材偏向性分析
考虑到每一类方剂数量不等,对各种类型方剂在不同类别中的占比进行了统计,如表2所示。方剂类别占比情况有助于了解不同方剂中使用药材的偏向性。类别分布中,泻药配方在类别1中占比最大,而其他方剂几乎没有出现在此类别中,可以看出泻药配方在药材使用上与其他方剂差异较大。
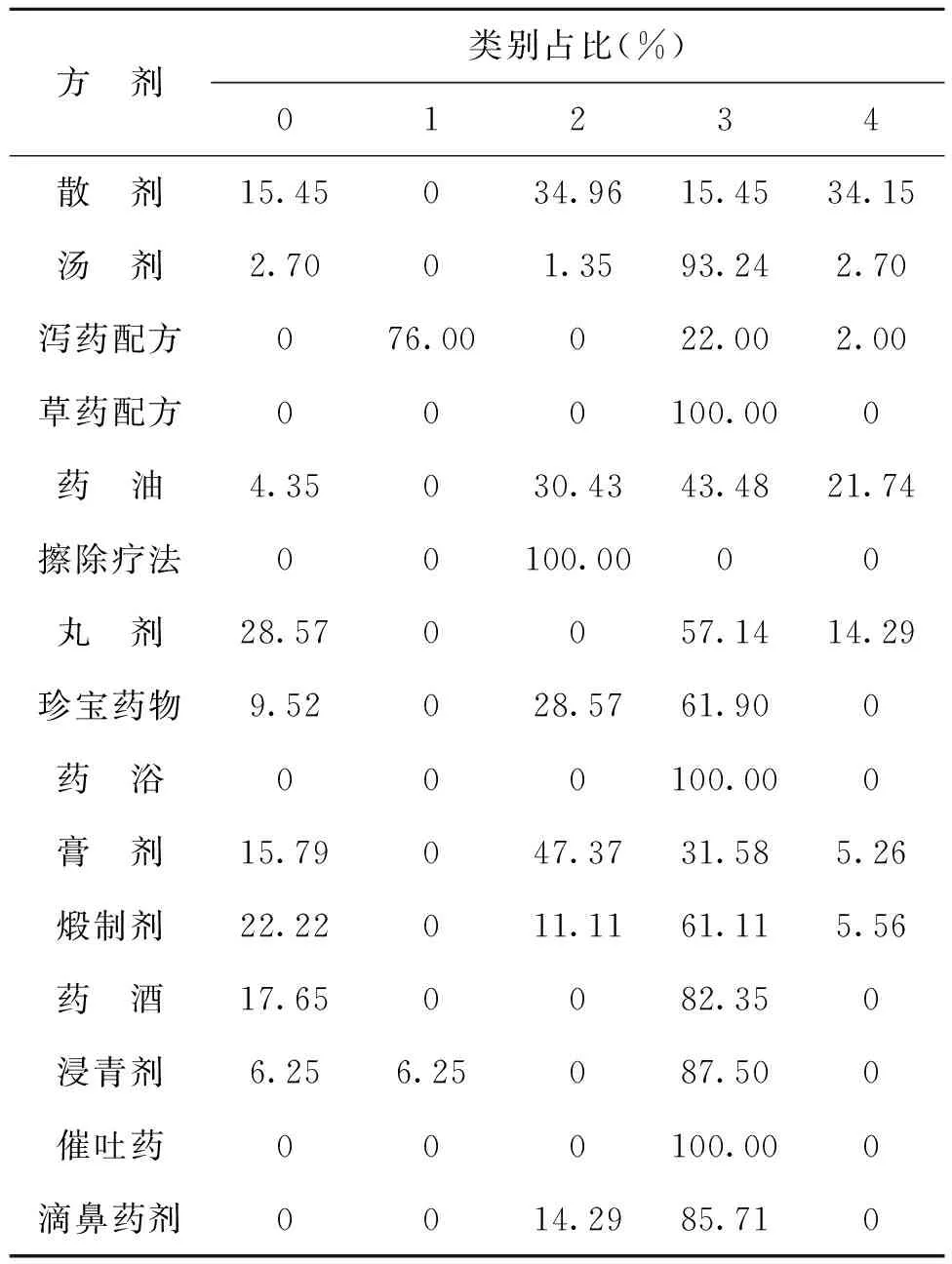
表2 各方剂类别占比情况
从表1来看,药材的使用偏向性除了受到疾病的影响以及药物作用效果的影响,同样也受到了药物使用方法的影响,不同的药物要根据其特性来组成不同的药剂,以此来最大程度地保留药材效用。如汤剂在类别3中占比最大,该类目下的诃子、秦艽、地衣、紫草、黄连、广木香、沙棘等药材都是汤剂惯常使用或可考虑使用的药材。
3.6 新处方预测分析
新处方预测是利用该类疾病现有处方的用药规律预测新的用药处方[41],本研究选取的是主治疾病与热症相关的处方进行新处方预测分析。数据主要来源于《四部医典》的《密诀本》以及《后序本》与治疗热症相关的处方,共有124个处方被录入到R语言中进行数据分析。
这些处方所处理的热症包括热症总治、陈旧热症、扩散热症、伏热症、紊乱热症、寒热、浊热症、热症扩散治疗法、虚热症、未成型热症共10个方面。
这些数据输入到R语言中进行数据分析,同时也对处方中的药材名称进行了统一,以此来确保药方的准确性。同时,为了保证研究的严谨性,也对相应的处方根据《中华本草》进行了合理完善。药材规范如表3所示。

表3 藏医药材规范表
首先利用R语言的itemFrequency的数据分析功能,对与治疗热症相关的药物进行用药频次统计,结果如表4所示。

表4 藏医治疗“热症”方剂中使用频次前20的药材
使用频次从高到低排列,依次为红花、竹黄、诃子、牛黄、檀香、秦艽、砂仁、藏茵陈、川乌,这体现这些药物在治疗热症方面为藏医比较常用的药材。“红花”作为藏医中治疗“热症”最为常用的一味药材,它的使用率达到了30%左右,红花是藏医中应对热症效果比较出众的一味药材。当然,其中也发现一些有趣的现象,如在藏医用药中大部分的药物均为藏医比较独特的药材,如藏茵陈、哇夏嘎等,但白糖在藏医治疗热症方面使用频率较高,与此相类似的是中医药中的“白砂糖”也是一味清热的药物,从这一方面来看,可以看到除藏医其用药的独特性以外,在某些方面与传统的中医还存在一些关联。
基于关联规则的藏医治疗“热症”的组方规律分析中,将支持度设为0.06,置信度设为0.09,得到基于124个处方的58条关联规则数据。在关联数据的处理中使用了比较经典的Apriori模型,在这一模型中常用的衡量标准有支持度(Support)、置信度(Confidence)以及提升度(Lift),支持度在本研究中被认为是某一药物出现的频次,置信度则是指某对或者某几个药物共同出现的频率,提升度则是指前一个药物出现对于后一个药物出现的提升水平,这反映出关联规则的有效性。下面给出支持度、置信度以及提升的公式定义[42]:
Sup(藏药)=P(藏药)
ConF(关联规则)=P(后一味藏药|前一味或几味藏药)
Lift(关联规则)=P(后一味藏药|前一味或几味藏药)/P(藏药)
将前10条的关联规则按照其提升度的从低到高排序,如表5所示。

表5 Confidence>0.09前20关联规则排序
在上述的药物关联图中,可以看到节点的大小表示该节点的置信度的大小,而颜色的深浅则表示关联规则的提升度,基于124个处方所发现的关联规则提升度均在合理的区间。
从图12可以看到,不同的药物根据其之间的相似性分别成为了不同的类别,地衣、黄连、秦艽、紫草、大株红景天的距离比较近,说明这几味药材在治疗热症方面是比较常用的药材组合。中间的部分,以红花为中心,向外扩展链接了竹黄、牛黄以及丁香等,这说明红花作为一个重要的中心节点,在藏医中常常与其他药材进行组配治疗。右边则是诃子、毗黎勒以及余甘子,这3味药材是藏医中俗称的“三果”,是治疗热症中极为常用的药材组合。

图12 “热症”药物关联图
通过上述的关联规则的展示以及可视化,可以直观地看到藏医在治疗“热症”方面比较常用的药物组合以及藏医常用的核心药物,这对于理解藏医的用药思路以及治病思路有很大的帮助。
通过关联规则的呈现得到了藏医的核心药物,在此基础上选取治疗热症中使用率较高的前20味药材来进行新处方的知识发现。
首先对前20味的药材进行数据处理,本文将这20个药材在每个处方中出现的情况,定义为二分类变量,结果如下:

将处理好的数据输入到Spss26.0中进行数据处理,利用系统聚类的方法进行聚类,将最小聚类数量约定为5,最大聚类数量约定为10,利用组间链接的方法形成新的聚类,结果如图13所示。
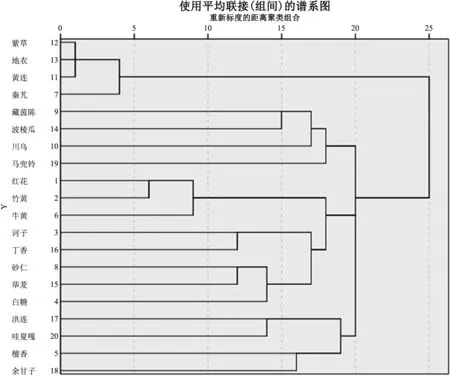
图13 新方生成的层次聚类结果
此部分目的在于,依托于高频的治疗热症的药材,根据他们之间的相似度距离来形成新的处方,先前的研究将新处方生成均为3~5味的药材组合[43],所以据此将本研究新处方的药材组合约定为3味、4味以及5味药材,形成的备选处方如表6所示。以上就是利用藏医治疗热症的处方所形成的新处方预测,从数据处理的角度看来,利用药物之间的关联规则形成新的治疗方案,是未来值得去探索的一个方向。这些研究成果有利于医学领域发现新的治疗方案,为现有的治疗提供一个参考。本研究只是从数据层面提供一个基本的探索方向,新处方的具体效用还需实践进行检验。

表6 基于层次聚类的藏医治疗“热症”的新处方预测
4 结 语
本研究从数字人文视角出发,以《四部医典》这一经典藏医学古籍为内容主体,利用文本分词、统计分析、关联分析、聚类分析、可视化技术等相关工具方法,对《四部医典》中的《密诀本》《后序本》分别进行病症关系分析、病因关系分析、用药规律分析以及新处方预测分析,挖掘藏医学古籍价值内涵,推动藏医学古籍的传承和利用。
在技术上,利用统计分析、关联分析、聚类分析等方法,提取藏医学古籍中可用的数据信息,对数据进行整理,得到可进行分析的结构化数据,为藏医学古籍内容挖掘提供了一个可探索的方向。在内容成果上,主要有以下几点:①对疾病症状的聚类分析不仅能得到疾病的类目情况,还梳理出疾病在症状表现上具有的相似性,有助于疾病诊断;②病症的关联分析印证了龙、赤巴、培根在藏医学中的重要地位,还体现出人体是一个整体的系统,身体各部位之间紧密联系;③病因分析中,龙、赤巴、培根等是重要的疾病发病的部位,境域、时刻、年龄等是大部分疾病的病缘,这些也体现出藏医在诊断疾病病因中的基本情况信息;④病因关系的分析展示了不同热症之间的关联关系,这有利于了解不同疾病在疾病产生时的相似性,帮助疾病预防;⑤从用药统计情况来看,藏医的处方种类比较多,其中散剂、汤剂类别的处方最多,从药材来看,诃子、荜茇、小豆蔻、红花、白糖等是藏医最常见的药材,而这些药材的统计也体现了藏医以食养病的思想,在治疗方面,消化不良、黄水病以及与热症相关的疾病是处方主治最多的疾病;⑥药物的关联分析,直观地展现了诃子、红花、荜茇、白糖、小豆蔻、白檀香、竹黄等各种药材的重要程度和关联情况,有助于了解藏医学药物组合情况以及新处方预测;⑦药物的聚类分析,得到了药材相似性体现出的主治疾病之间的联系,并且这种药材的相似性,有利于挖掘出同类疾病下新的治疗药物,以及能帮助了解不同方剂中使用药材的偏向性;⑧新处方预测是对关联分析与聚类分析的综合运用,得到了热症疾病的核心药物组合,进而得到新的用药处方,为新处方的开发提供了参考方向。
本文以藏医学古籍《四部医典》为例,探索藏医学古籍知识发现的新路径,对藏医学古籍资源乃至中医学古籍资源的开发利用有一定贡献,但还存在一定的提升空间。藏医学古籍《四部医典》共四部,其中第一、二部主要内容是藏医学基本理论,第三、四部主要内容是疾病的治法和药方,本文依据数据挖掘需要,将数据来源划定为第三部和第四部,未来需要将第一、二部纳入到研究范围,进一步完善研究成果。除此之外,藏医学领域中的其他有价值的古籍也是值得关注的研究对象,从而构建完整的藏医学古籍知识发现和利用体系。
猜你喜欢
汉字汉语研究(2021年3期)2021-11-24 01:34:10
中国兽医杂志(2021年6期)2021-11-11 06:14:10
现代畜牧科技(2021年5期)2021-07-20 08:07:54
天一阁文丛(2020年0期)2020-11-05 08:28:06
天一阁文丛(2018年0期)2018-11-29 07:48:08
西藏研究(2017年3期)2017-09-05 09:45:12
金桥(2017年5期)2017-07-05 08:14:41
临床医药文献杂志(电子版)(2017年11期)2017-05-17 04:47:58
西藏科技(2016年9期)2016-09-26 12:21:41
西藏科技(2016年5期)2016-09-26 12:16:39
