
古籍数字化国内外研究现状分析与路径构建研究
2023-11-24 06:34:34李世钰张向先侯力铁张承坤
现代情报 2023年11期
李世钰 张向先 沈 旺* 侯力铁 张承坤
(1.吉林大学商学与管理学院,吉林 长春 130012;2.长春中医药大学基础医学院,吉林 长春 130117)
古籍是历史文化中诞生的重要文化资源,具有丰富的内容和多样的形式。然而随着时间的推移,古籍的保存受到传统记录、表现和传承方法的限制,其在长期保存上面临一定的困难与问题,如古籍载体的老化与破损、古代帝王陪葬制度、战争或政治因素导致的损毁、古籍转运过程中的佚失、转誊抄录过程中受个人意见等影响造成的删减等,所以对古籍实施数字化工程是保护内容完整的重要方式。
1949年,罗贝托布萨首先使用计算机辅助编辑了大型书籍《托马斯著作索引》,而在国内,王晓光等[1]首先引入数字人文研究,开始对敦煌壁画进行图像底层视觉的标注。伴随着数字人文研究的兴起,古籍数字化的研究内涵逐渐丰富,一方面现代信息技术的应用可以将古代文献转化为电子媒体的形式,通过光盘、网络等介质保存和传播[2];另一方面针对数字化后古籍的挖掘与利用也日益增多。目前在世界很多国家和地区都开展了古籍数字化的相关项目[3-5],涉及范围广泛,包括少数民族古籍、中医古籍、单书等内容。
可以看出,古籍数字化研究内涵日趋丰富。因此,本文旨在通过国内外古籍数字化主要研究内容,并构建古籍数字化研究路径,明确古籍数字化的研究意义与现实作用。同时从古籍数字化研究路径视角出发,藉由国内目前相对于国外古籍数字化研究的差距,找寻我国古籍数字化的不足与缺陷,探索我国古籍数字化未来的研究思路与发展方向。
1 国内外古籍数字化研究现状分析
研究借助国内外古籍数字化已发表文献,利用文献计量的方法挖掘古籍数字化研究的目的、主题与发展阶段,结合代表性文献内容分析,归纳古籍数字化文献的方法、技术与特点,为古籍数字化路径建设提供参考依据。
1.1 文献数据获取
研究以“古籍数字化”为主题方向在国内外文献数据库中进行检索,但英语中缺乏“古籍”一词的对应表述,且古籍又包含善本、手稿、拓片等形式,同时古籍数字化项目的目的多以实现古籍的数字化,构建古籍数据库与数字图书馆为成果以供整理完成的古籍可以进一步应用,因此本文使用古籍形式,即“古籍(Ancient book、Ancient Work)”“善本(Rare Book、Rare Edition)”“手稿(Manuscript)”“拓片(Rubbing)”“碑(Inscription、Monumental Writing)”与数字化相关形式,即“数字化(Digitization)”“数据库(Database)”“数字图书馆(Digital Library)”组合作为检索关键词。即中文检索式形为:SU=(古籍 &数字化)、SU=(古籍 &数据库)、SU=(古籍 &数字图书馆)等15个组合出的检索式。英文检索形为:TS=(Ancient Book AND Digitization)、TS=(Ancient Book AND Database)、TS=(Ancient Book AND Digital Library)等24个组合后的检索式在中国知网数据库CNKI和Web of Science核心合集数据库进行文献检索,检索日期为2023年1月4日。在我国国家标准化管理委员会2008年颁布的《古籍著录规则》[6]中,古籍主要是指1912年以前在中国书写或印刷的、具有中国古典装订形式的书籍。由于手稿等载体形式在现代文献同样具备,同时为了保证国内外古籍研究时间的一致性,研究根据《古籍著录规则》,剔除掉了研究对象为1912年之后的文献以及不符合古籍数字化主题的文献,最终得到了中文文献3 222篇,英文文献998篇。
图1统计了国内外古籍数字化文献年份分布,根据统计结果可以看出,国内外关于古籍数字化的研究均始于20世纪80年代中期,在这一时间数字化技术开始逐步得到应用,并在当前已得到了广泛发展。随着国内数字化技术的不断发展和国内文化遗产保护意识的提高,数字化古籍研究在国内得到了更多的关注和支持,国内关于古籍数字化的研究自2000年后增长迅速。国外研究总体呈现上升趋势,伴随着学者和社会公众对于数字资源需求的增加,相关研究在2015年后稳定在每年100篇左右,这表明古籍数字化研究逐步演变为全球性的趋势,同时也表明数字化技术在保护和传承文化遗产方面具有重要意义,得到了国际社会的广泛认可和支持。无论是国内还是国外的相关研究,在近些年都逐渐趋于稳定,其计量结果可以为古籍数字化路径建设提供成熟的依据。

图1 国内外古籍数字化文献年份分布
1.2 文献计量分析
研究利用词频统计、关键词共现与聚类及Timeline视图的方式对古籍数字化文献的研究目的、主题与阶段进行挖掘。
1.2.1 研究目的分析
文献标题是文献研究目的最直接的体现,能够包含论文的研究方法、对象与领域等内容。研究利用Jieba分词,使用Python语句对检索到的文献标题进行分词与去停用词处理,并进行词频统计,最终分别生成了国内外文献标题的词云图如图2、图3所示,用以对当前古籍数字化研究的广泛目的予以展现。
受检索式影响,中文词汇“古籍”“数字化”“图书馆”“数据库”以及英文词汇“digital”“database”“ancient”等词占比较高,但仍有许多其他词汇具有较高的词频,反映出了国内外古籍数字化的主要研究目的。
首先,图2结果显示,在国内研究进展中,古籍整理与保护是古籍数字化重要的研究目的。古籍整理与保护是保证古籍存续的重要工作,而数字化可使古籍脱离传统纸质等载体的桎梏,减少古籍的物理损耗,显然古籍数字化已成为古籍长久保存的重要手段。而在图3国外文献的标题词云图中可以看出,“recognition(认出)”“identification(识别)”等词的高词频结果同样说明国外对于古籍完整性的重视,反映出对于古代文献保护与传承的努力。
同时图2和图3反映出,国内外古籍数字化研究有各自侧重的研究对象。我国的古籍数字化研究涉及到“中医古籍”“民族古籍”等明显有国内文化特征的研究对象。而国外对“手稿”这一对象的研究相对较多,这与国外古籍多以手稿形式呈现有关。同时,由于国外包含诸多国家和地区,所以能够看出国外的研究涉及对个别文化、文明与语种的研究。如词云图中体现的与中世纪(Medieval)时代和阿拉伯(Arabic)文化相关的研究。
1.2.2 研究主题分析
关键词是一篇文献中的核心词汇,反映了论文研究中最核心的研究主题。通过对关键词的计量,可以呈现相关研究的热点方向。
研究使用CiteSpace,以检索文献的关键词作为标签进行分析,得出“古籍数字化”研究主题下关键词的共现结果。
图4和图5展示了文献检索结果的关键词共现图。其中,节点越大,表明该关键词出现的词数越多,连线表示关键词之间存在共现关系。由于获取的文献,尤其是中文古籍数字化相关文献数量较多,导致节点与连线相对密集,所以进一步计算节点的中介中心性用于衡量其中介作用,中介中心性较高的节点处在多个其他节点中间,把持节点之间的连接通道,因此中介中心性大于0.1可以认为是图中的关键节点。图4中,“数据库”节点的中介中心性达到了0.33,“数字化”“图书馆”“古籍”“古籍整理”“中医古籍”等节点的中介中心性也均大于0.1,说明这些节点被广泛提及。而在图5的英文文献关键词中,“digital library(数字图书馆)”“cultural heritage(文化遗产)”也均为中介中心性大于0.1的节点。

图4 国内古籍数字化文献关键词共现图

图5 国外古籍数字化文献关键词共现图
除高中介中心性节点以外,高频关键词同样作为关键词共现中的重要节点出现,如“古籍保护”“古籍整理”等文献标题中同样高频的词汇,在关键词中拥有100以上的高词频出现率,这进一步佐证了针对文献标题的分析结果。而在标题高频词与高中介中心性节点词及它们的近义词之外,如图4中的“元数据”“数据挖掘”“古籍利用”,图5中的“deep learning(深度学习)”“convolutional neural network(卷积神经网络)”“image segmentation(图像分割)”等词也均为各自共现图中排名在前30以内的高频关键词。
可以看出,古籍数字化研究已开始多样化发展,针对数据标准,古籍内容的挖掘与相关开发工作均有所开展,而国外在这一领域对于机器学习、深度学习等信息化技术有着相对更加具体的运用。
由国内外关键词共现结果可以看出,古籍数字化研究主题主要包含:①数字化技术的应用,包括数字化技术在古籍文献数字化、古籍整理、数字化图书馆建设等方面的应用;②数据标准化研究,主要关注如何建立符合古籍数字化标准的著录规则与分类规则,以方便数字化古籍数据的管理和共享;③信息技术在古籍数字化中的应用,主要关注如何将信息技术手段如机器学习、深度学习等运用到古籍数字化的各个方面,以提高数字化效率和质量。
研究进一步根据检索结果的关键词共现图进行了关键词聚类,以发现古籍数字化相关研究中的主要研究主题与研究方向。图6和图7分别展示了国内外研究关键词的聚类结果,中文关键词的聚类最终得到了147个类别,其中前17个类别的聚类关键词数不少于5个。这17个类别的Silhouette(聚类平均轮廓值)均大于0.801。而国外文献关键词共得到158个聚类类别,其中前15个类别聚类的关键词数量均不少于6个。这15个类别的Silhouette值均大于0.879。通常Silhouette值大于0.5即可认为聚类结果是合理的,Silhouette值大于0.7即可认为聚类结果是令人信服的。可见,本研究对于国内外研究关键词的聚类结果具有较强的说服力。

图7 国外古籍数字化文献关键词聚类图
通过左上角的参数可以看出,图6 Modularity即模块化参数为0.5993,图7为0.842,说明图中各个节点的划分效果较好。Weighted Mean Silhouette是用来衡量图中集群同质化程度的参数,在图6中达到0.8672,图7达到0.9336,说明集群同质化效果良好。
通过国内外古籍数字化文献关键词聚类结果可以看出,虽然受检索式影响导致“数据库”等词在文献标题与关键词中都作为高词频出现,但国内聚类结果所出现的“数据库”与“语料库”及国外古籍数字化文献关键词聚类中排名靠前的“creating digital libraries(建立数字图书馆)”。“small museum(小型博物馆)”等结果仍表明,古籍内容挖掘及相关开发工作是当前古籍数字化工作的重要方向,其能够挖掘古籍文献中的知识和信息,也是开展古籍内容挖掘研究与开发利用服务的重要基础。
1.2.3 研究阶段分析
研究进一步利用各年份的关键词,制作了关键词Timeline视图,如图8、图9所示,用以反映时间轴推移下国内外古籍数字化研究的发展趋势。
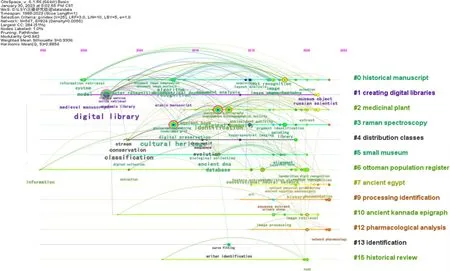
图9 国外近年文献关键词Timeline时间视图
由图8可以看出,国内对于古籍数字化的研究始于对图书馆资源以及对于古籍数据库的探索,中医古籍是最早被关注的研究对象。古籍的整理、保护在20世纪末开始被广泛提及,至21世纪初研究开始重视古籍的信息资源,开始了大量的古籍数字化转化进程,以达成存储、修复等目的,同时用于规范古籍数字化资源的元数据条目也开始制定。在2010年左右,伴随着信息化技术的发展,许多研究开始关注古籍的数据挖掘,古籍开始了由信息化到知识化的转变。如今,知识图谱等工具的运用为古籍的进一步知识服务与数字化推广提供了新的技术与方式。
图9则在标题分析与关键词词频和聚类分析的基础上,进一步揭示了国外在古籍数字化研究中对于技术的不断利用与迭代。在古籍数字化研究的早期即关注信息检索与系统的构建,相较于国内也更早地将算法运用到古籍数字化的研究中,包括图像分割与机器学习的运用,以及目前向深度学习的转变,并在如今被广泛运用于作者、手写体等古籍有关内容的识别,完成对古籍的知识发现。
1.3 文献内容分析
通过总结文献计量关于“古籍数字化”文献研究目的、主题与阶段的分析结果,可以看出古籍数字化研究主要有“研究对象选取”“数字化处理”“数字化存储”“内容深度挖掘”“古籍知识发现”“数字化平台建设”“数字化整理”“数字化保护”“古籍著录规则”“古籍分类规则”等主要研究方向。依据这些研究的特点及目的,本文进一步将其总结归类为“古籍数字化处理”“古籍数字化存储”“古籍数字化标准”“古籍数字化利用”“古籍数字化服务”5类主要内容,其对应关系如表1所示。通过选取国内外关于主要内容相关的代表性文献并进行内容剖析,可以发掘古籍数字化主要研究内容的侧重点及相关技术方法。

表1 古籍数字化研究的内容类别与主要研究方向对照表
1.3.1 古籍数字化处理
古籍数字化处理是古籍数字化的开始阶段,关注重点在于将传统古籍文本转化为数字化文本形式。在这一阶段需要选定古籍研究对象,以及使用扫描、拍照等方式形成数字化古籍文档。
在“研究对象选取”阶段,国内外古籍数字化的研究对象带有明显的地域特色与文化差异。我国的古籍数字化研究涉及“中医古籍”“民族古籍”等明显有国内文化特征的研究对象。如《爱如生系列数据库》《瀚堂典籍数据库》等都针对《伤寒杂病论》《难经》《黄帝内经》等中医经典古籍进行了数字化处理[7]。民族古籍方面,陈汝模[8]在研究中论述了福建海上丝绸之路相关古籍的内容、特征、原则及将其数字化后的意义,而对《齐民要术》《论语》等古籍的数字化也体现了国内以传统历史典籍为研究对象的特点[9-10]。国外对于“Maunscript(手稿)”这一研究对象的数字化研究更为侧重。Guido R等[11]针对500余份中世纪手稿,进行了数字化与古籍分类工作。Ladewig S L等[12]使用了高分辨率成像设备,进行《新约》手稿的数字化。
“古籍数字化处理”形成数字化古籍文档通常只作为古籍数字化相关研究的一个基础步骤,很少作为研究重点。通常扫描、拍照一类形成数字化古籍图像的方式应当是形成古籍数字化文档的有效手段。焦佳琛等[13]在文献中提到,扫描或拍照,并进行纠偏、拼接、去污、裁切及水印等处理是目前形成古籍数字化文稿的重要方式,Choro K等[14]通过使用波兰古代手稿照片对OCR(光学字符识别)手稿数字化的方法进行测试,他们认为,改进古代手稿数字化的方法应该具备适当的扫描设备,高分辨率的扫描、无损压缩、文档图像的手工校正、图像的手工调平使文本水平排列、使用具有古词汇的词典等手段以保证稿件图像的质量。
1.3.2 古籍数字化存储
“古籍数字化存储”主要是保存已形成的数字化古籍内容,以便于后续加以利用。目前已有的古籍数据库项目中,山东大学建立了易学古籍数据库[15],对易学古籍进行收集、复制、影印等工作。数据库共包括易学古籍总目数据库、易学古籍全文数据库以及易学古籍研究与知识图谱数据库,不仅存储了易学古籍数字化数据,也为进一步提供古籍服务奠定了基础。鞠斐等[16]提出,基于中国版刻古籍纺织图像的数据库架构设计,以数字形式发布、存取和利用中国版刻古籍图像。
国外如以色列国家图书馆建立的“时间旅行”数据库,采用众包的形式收集并数字化以色列历史文献[17]。印度同样建立了国家手稿中心,用于存储和保存印度数字化手稿文献[18]。Abdelhaleem A等[19]构建了一个数据库,其中包括伊斯兰遗产项目(IHP)由302位不同作家撰写的333份历史手稿,用于研究各种手写相关问题,如文本识别、作者识别、文本预处理等问题的研究。
1.3.3 古籍数字化标准
“元数据”一词在关键词中的高频出现,代表了大量的数字化古籍产生后所伴随的规则演进。当前研究中的古籍数字化标准主要分为“古籍著录规则”与“古籍分类规则”。
我国拥有相对统一的古籍著录规则,国家标准化管理委员会曾于2008年发布了《古籍著录规则》[6],其元数据包括标准号、中文标准名称、英文标准名称、发布日期、实施日期、首次发布日期、标准状态、复审确认日期、计划编号、代替国标号、被代替国标号、废止时间、采用程度、国际标准分类号、中国标准分类号、标准类别、标准页码、标准价格(元)、主管部门、起草单位在内的20项元数据标准,这也成为我国目前古籍著录的总体标准。但由于古籍内容、种类繁多,也有学者研究设定专题古籍著录规则。先巴[20]设定了藏文古籍著录规则,在著录细则上增加藏族古籍特点语义说明和限定,如古籍语种限定为藏文、古籍主题按照藏族古籍主题词分类等。国外的古籍编目系统相同普适性更强,如OCLC联机计算机图书馆可以收录众多国外文献资源编目数据。Bannay O E等[21]还利用XML语言表示的元数据和手稿注释构建了阿拉伯手稿可视化平台,加上DC元数据集合MARC著录格式等的利用,使得其适用性相对更强,且有助于馆际之间资源的交流与整合。
在“古籍分类规则”研究中,“经、史、子、集、丛”五部分类法在我国具有悠久的历史,也适用于古籍的常规分类,部分研究会进行“专题古籍分类规则”的设定与研究,但是普适性相对较差。国外关于古籍分类的分类法相对较少,但是由于计算机技术与信息技术的使用明显提高,通过自动识别、聚类等方法,能够自动提出对所获取到的古籍数据的分类结果,但显然这一结果也很难具有普适性,更换古籍数据很有可能带来分类结果的不同。
1.3.4 古籍数字化利用
古籍数字化不是单纯的形成数字文档。更好地利用数字化古籍,完成古籍内容的深度挖掘与研究,发挥数字化相对于传统文本的优势,是古籍数字化更高层级的意义与作用。
目前,古籍数字化利用主要有以下方面:一是运用“本体构建”“机器学习”“图像分割”等技术打破古籍原有文本组织结构,从而实现“内容深度挖掘”与“古籍知识发现”。二是古籍的“数字化整理”与“数字化保护”,通过数字化过程更好地进行古籍内容保存。
国外在近些年针对古籍数字化的研究采用了大量机器学习及图像处理等技术,从而完成古籍“内容深度挖掘”。Chanda S等[22]利用CNN(卷积神经网络)对法国国家档案馆所藏的14世纪初法国行政活动文件进行特征提取,并使用零次学习算法进行了中世纪单词的识别,结果达到了56.87%的识别准确率。Avadesh M等[23]对古代梵文手稿进行字母分割和图像标注,实现了对梵文手稿图像的处理,并利用卷积神经网络进行梵文单词的学习与识别,准确率达到了93.32%。倪劼[24]在文献中提出了基于流水模式的古籍汉字切分算法,该算法将古籍文献图像进行预处理,然后用投影法与图像形态学处理实现列切分,再在列基础上进行逐字切分,仿照水流的运动轨迹实现古籍中汉字的划分。“古籍知识发现”多聚焦在对古籍进行文本关联以及本体构建等研究。如周莉娜等[25]以唐诗为研究对象,构建了“诗歌—诗人”本体模型以及“面向史学的时空经历本体模型”,并在此基础上构建了知识图谱,从而挖掘并可视化出诗人与诗歌之间的关系,并解释了诗人经历的时序变化特征。
古籍数字化整理主要关注对古籍进行审阅、校勘和注释等工作,也是形成数字化古籍的前期必备工作。如张玉梅[26]按照宁夏旧方志存世价值以及时间顺序等选择进行数字化的古籍版本,如存在破损等问题则进行按原内容抄写等手动内容补全工作。国外在古籍整理过程中,除了对古籍的物理性整理以及对古籍进行编录外,还会使用一定的计算机技术来辅助整理。早在1987年,Stringer G A等[27]便设计了程序对《约翰·多恩诗集》进行逐字审核,Kaoua R等[28]则构建了一个有2 000多个从古籍中提取的插图以及1 200多个注释的数据集,并能够利用该数据集对古籍中的插图与注释构建对应关系。
古籍数字化保护是对古籍进行数字化的重要作用与意义,将古籍转化为数字形式存储,相比传统载体显然能够保存更久的时间。黄俊[29]将江西图书馆馆藏古籍进行缩微管理,从而生成了古籍的缩微图像库,尽可能地保存了古籍的内容与原貌。谭小华[30]概述了重庆图书馆的古籍数字化保护工作,除扫描、拍摄形成古籍图像之外,还对古籍进行了普查登记,形成古籍普查档案,方便古籍资料的查询以及对原版古籍的保护。国外关于“古籍数字化保护”的研究中,古籍修复成为关注重点。Grosso A M D等[31]在研究中构思了历史手稿的有效数字化保存系统,该系统可以实现手稿图像的图像采集、利用层压技术实现手稿的图像增强,并在此基础上进行半自动转录、学术编码和语言分析功能的完善,从而提升了对载体老化的手稿内容的分辨能力。
1.3.5 古籍数字化服务
古籍数字化服务是在新形式的数字化平台下提供的有关数字化古籍的相关服务,如检索、问答、古籍知识的可视化呈现等。随着信息时代的到来与移动终端的广泛普及,古籍数字化平台可以扩展古籍宣传及普及渠道,对古籍进行新形式的展示,同时使得古籍研究得以利用信息化手段,实现进一步的应用开发。
国内外已有众多对古籍数字化平台的尝试,如罗渝等[32]在西南师范大学出版社出版的《域外汉籍珍本文库》基础上构建的“域外汉籍数字服务平台”,收录了境外40余个国家(地区)近百余图书馆及个人所收藏的汉语珍本,可以提供阅读与多条件检索功能。傅宝珍[33]提出,通过构建古籍VR阅读系统、构建古籍VR阅读资源库等方式以拓宽古籍阅读渠道,加强古籍融媒体交互与知识服务能力。Russo G等[34]则在意大利那不勒斯的“Girolamini图书馆”创建一个古籍和手稿“服务中心”,该“服务中心”可以使用物联网和机器学习等技术对图书馆中数字化后的古籍进行分类,从而为信息检索提供依据。
2 古籍数字化路径构建
古籍数字化路径的构建有助于为古籍开发及传承提供系统化的研究思路与方法,从而深入挖掘其中的文化内涵和知识价值。因此,研究总结文献分析所得出的古籍数字化主要内容及其相关技术与方法,通过参考相关理论体系,梳理古籍数字化路径框架,规划路径各模块的执行内容,为古籍的保护和传承提供有力支持,并为发现古籍数字化现有研究不足及未来发展方向提供新的视角。
2.1 古籍数字化路径框架分析
伴随着数字人文的兴起,相关理论也逐步发展,这为古籍数字化路径的框架搭建及要素名称的确定提供了基础。Anderson S等[35]提出发现(Discover)、收集(Collect)、比较(Compare)、发布(Deliver)和协作(Collaborate)的不同类型的原语,称为“五原语论”,这一理论成为当前数字人文研究中应用于考古工作进程的阶段划分依据。刘炜等[36]则进一步从五原语论及其二级原语出发,对数字人文的技术体系展开探讨,提出包括“数字化技术”“数据管理技术”“数据分析技术”“可视化技术”“VR/AR技术”“机器学习技术”6类技术在内的数字人文技术体系,涵盖了当下数字人文发展的主要研究技术。
相关理论的逐步发展拓展了古籍数字化研究的内涵,数字化古籍得以被进一步开发与利用。因此,研究参考五原语论与数字人文技术体系,对古籍数字化的主要研究内容进行对应匹配,完成古籍数字化路径构建。
研究基于古籍数字化文献分析结果的5类主要研究内容,即:“古籍数字化处理”“古籍数字化存储”“古籍数字化标准”“古籍数字化利用”“古籍数字化控制”的相关代表性文献,进一步总结了5个阶段所运用的技术与方法,如表2所示。
通过将古籍数字化研究阶段所运用的技术与方法,与数字人文技术体系相匹配,可进一步将古籍数字化研究内容与五原语论中的阶段模式相对应,从而完成古籍数字化路径框架的构建。
古籍数字化的基础是完成古籍内容由传统载体向数字化载体的转变。“古籍数字化处理”中所用到的OCR技术、扫描技术等明显对应了数字人文技术体系中的“数字化技术”。以“数据库”“语料库”为代表的古籍“数字化存储”则在构建数据库的过程中需要运用“数据管理技术”进行组织。根据数字人文技术体系与五原语论的对应关系,这两项技术分别对应五原语论中的“发现”与“收集”两个环节,由于这一阶段的目的是主要完成古籍由传统载体向数字化形式的转变与保存,研究将这一部分内容总结为古籍数字化的“转化”环节。
伴随着信息技术的发展,古籍数字化的内核已不仅仅是转换载体,而且也同样经历着由信息化向知识化的转变。古籍的“内容深度挖掘”与“古籍知识发现”是新时期古籍研究的重点。这两类研究对于数据统计、知识图谱、卷积神经网络等技术均有涉及,其充分对应了数字人文技术体系中的“数据分析技术”“可视化技术”与“机器学习技术”。在五原语论中,这3种技术都涉及“比较”这一原语,意为“整合多样性信息以便可以在数字人文之间比较信息。”因此,研究将这一环节定义为“重构”,通过“重构”古籍文本内容,挖掘古籍内容关联,获取古籍内容深层次信息。
数字化古籍可通过“开发”与“利用”,依托古籍数字化平台所形成“知识服务”。同时“古籍数字化利用”中的“数字化整理”与“数字化保护”也是数字化古籍的重要应用目的。在古籍数字化平台构建中,对于“可视化技术”与“VR/AR技术”已有充分的探讨,古籍在其整理与保护过程中,也开始对机器学习等现代化技术加以应用,这3种技术集中对应了五原语论中“比较”“发布”与“协作”3项原语,体现出数字人文中“整理”“出版”与“分享”信息的现实作用。因此,研究将这一环节定义为“应用”,反映古籍数字化的实际应用层面。
“古籍数字化标准”中的“古籍著录规则”与“古籍分类规则”运用了数字人文技术体系当中的“数据管理技术”。在五原语论中,这项技术主要运用于“发现”和“协作”两个原语。“发现”主要对应古籍的“转化”环节,而“协作”环节在“重构”与“应用”中均有涉及。事实上,古籍的“转化”“重构”与“应用”也应当尽可能遵守古籍的数据管理规则,才有助于数据的全方位协同与利用,因此,研究将这一环节定义为古籍数字化的“控制”。
通过对古籍数字化阶段所运用技术的疏理,可以看出古籍数字化主要研究内容与数字人文技术体系及五原语论之间存在对应关系,如图10所示。

图10 古籍数字化路径梳理
研究最终形成了以“转化”“重构”“应用”和“控制”为4个核心环节的古籍数字化路径框架,如图11所示。

图11 古籍数字化路径框架
其中,“转化”环节主要包含古籍研究对象的选取、数字化处理与数字化存储3个部分,主要实现古籍由传统载体向数字载体的转换。“重构”环节包含“内容深度挖掘”“古籍知识发现”等内容。其实现古籍内容的多维度关联关系发现,实现知识发现与重组,是古籍实现数字化的重大优势。“应用”环节包含“数字化平台建设”“数字化整理”与“数字化保护”等内容,其主要关注古籍数字化后所能实现的功能与价值,实现古籍内容的长久性保护与现代化古籍信息传播。“控制”是指“古籍著录规则”与“古籍分类规则”等的确立,利用“数据管理”等技术实现古籍数字化过程的规范化,为整合古籍数字化资源提供规则。
2.2 古籍数字化路径内容规划
研究通过规划古籍数字化路径中的关键环节的执行内容,系统化古籍数字化的研究目的及可行方向。
2.2.1 古籍数字化转化内容规划
古籍数字化转化是古籍数字化全路径的开始阶段,也是后续路径阶段工作开展的基础。在这一阶段需要选取古籍研究对象,利用现代化技术转换古籍载体,实现古籍在终端的数字化存储。
1)古籍资源的就近选取
通过观察古籍数字化相关文献的量化分析结果可以看出,古籍数字化对象的选取具备地域特色与领域特色,这与研究所能接触到的资源密切相关。我国的古籍资源繁复,图书馆等众多类型机构都具有一定的古籍馆藏资源。就近选取可获取到的古籍资源,可以保证古籍数字化的完整性及研究人员专业知识的可信度。
2)数字化处理技术的合理选择
考虑到古籍的年代性,部分古籍的原本载体可能较脆,也可能存在一定的破损,而不同技术的成像效果与适用环境也有不同,所以针对不同古籍选取不同转化方式尤为重要。OCR技术可以实现古籍的大规模文本输入,并实现古文字体字形向现代字体字形的转换,是进行文本挖掘等深度研究的基础,因此选取合适的图片清晰度的成像方法也是进行古籍数字化研究所必须考虑的问题。
3)古籍数据库的规范化设计
大多数数据库是基于图书馆本身具有的馆藏资源,或科研院所、数字化公司、众包等方式形成,主要可以分为古籍全文数据库、古籍电子索引和古籍书目数据库[37],而其中以古籍全文数据库建设较多,利用较为广泛。
古籍全文数据库主要包含图像型、文本型和图文型3种类型[38],图文型能够提供转译及修复后的古籍内容,也可通过展示古籍图片留存古籍原有样貌,同时为古籍内容的对照提供依据。可以看出,好的古籍数据库应能够尽可能留存多样式古籍形式以充分发挥其数据留存作用,实现古籍数据的存储、组织与处理。同时能够使用数据操作语言对数据库进行查询、更新等相对完善的数据库功能。
古籍电子索引和古籍书目数据库相较于古籍全文数据库能更好地诠释了古籍数据库的数据规范问题,对于大多数古籍数据库来说,使用更为普适的元数据体系更有助于数据库之间的互联互通,并有助于跨数据库的数据利用。当然,个别专题数据库需要根据已有主题设置不同的元数据,用以保证数据的录入。
2.2.2 古籍数字化重构内容规划
古籍数字化重构意在实现对古籍内容的深度挖掘,发现隐藏知识,实现对古籍所含知识的重新组织,从而有助于更加深入地、多维度地了解古籍。
1)实体识别
实体是古籍中的重要信息载体,通常以名词的形式出现,如人名、地名、机构、药材等,是挖掘隐藏知识、找寻古籍关系的基础。挖掘古籍中的实体,需要从古籍电子文档中找寻有意义的命名实体。相对于应用已经较为广泛且成熟的英语与现代汉语,中文古籍面临着传统字体与语法的障碍。因此,在这一过程中,除了足够的领域语料之外,还需要结合自然语言处理技术与历史学者、古文学者的学术经验,将计算机与人工融合,实现语义关系的处理,并对同一实体的不同表述进行统一,从而完成实体的抽取。
2)属性对应
属性是对实体更细节的解释,可以实现对实体的全面介绍,通常可以作为一个句子中的表语出现,如人物的年龄、籍贯、药物的药性等。在古籍中,实体通常不会独立存在,而是会在上下文中予以一定的介绍,因此属性对于实现古籍的重构至关重要,丰富的属性可以为古籍提供打破原有结构的叙事维度,从更多的视角入手对古籍进行深层次剖析。
3)关系抽取
关系提供了实体之间的联系,同样也是众多自然语言处理任务的基础,可以作为句子中的宾语等形式存在。关系能够揭示古籍中实体之间的关联,在特定的语义结构中,能够加深对实体所处环境的理解。同时,对古籍实现关系抽取,也是对古籍实现进一步应用,辅助古籍数字化平台实现应用任务,如在线问答、文本注释等的基础。
2.2.3 古籍数字化应用内容规划
古籍数字化应用需要依托于系统、平台的建设或新兴的信息化手段。随着信息时代的到来与移动终端的广泛普及,古籍数字化平台可以扩展古籍宣传及普及渠道,对古籍进行新形式下的展示,同时使得古籍研究得以利用信息化手段,实现对古籍的整理、保护与进一步的应用开发。
1)多维度叙事
古籍数字化平台是古籍进行现代化内容展示的主要载体,基于古籍的内容重构,数字化平台可以从多维度对古籍内容进行新形式呈现。牛力等[39]在文章中提出“时间叙事”“空间叙事”“锁链型叙事”等6种档案数据故事结构。我国史书自古也有“纪传体”“国别体”“编年体”等区别,总体来看,古籍主要可以从“时间”“空间”以及“实体”3个维度对内容进行重新组织,而数字化后的古籍恰恰可以利用如知识图谱与时间序列模型等,充分反映古籍中实体与实体之间的关系及随时间的演化。因此,多维度的叙事模式可以更生动地展现古籍重构后所发现的隐藏知识内容。
2)宣传与普及
古籍数字化平台起到让公众了解古籍内容的重要作用。伴随着终端的广泛使用以及网络广泛而高效的信息连通,古籍数字化平台的建设势必成为公众接触古籍的内容、价值及其诞生背景等的重要渠道。上海图书馆在古籍数字化平台建设上一直广受业内好评,如搭建的中文古籍联合目录与询证平台,整合了官修目录、史志目录、藏书楼目录等中的人名、地名等数据,并在平台中提供了内容统计分析、时空及社会分析、相关可视化功能,实现古籍的联合查询、规范控制,对古籍的考证、语义关联等研究提供了实用且有效的平台。可以看出,好的古籍数字化平台,不仅能够提供阅读、搜索、询证等多方面功能,同时可以实现古籍规范整理,减轻古籍搜寻与阅读难度,从而提升公众对于古籍的了解效率。
3)保护与修复
传统古籍面临着载体老化、破损等问题,时间的推移使得古籍的保护与修复问题愈发紧迫。一方面,利用古籍数据库可以对古籍进行规范化整理,进行字符编码、元数据指定、古汉语对应等工作,辅助传统古籍的物理化保护与数字化古籍的规范存储;另一方面,借助计算机对古籍图像等进行处理,可以打破肉眼限制,对古籍的年份等进行判定,丰富古籍背景信息,甚至对古籍内容进行修复。
2.2.4 古籍数字化控制内容规划
古籍的数字化控制阶段为整个古籍数字化路径提供参考标准与规则,从数据库设计到古籍的内容挖掘,从古籍数字化系统的建设到内容保护,都应对标准体系加以控制,从而增加古籍数据互联互通的可能性。
1)著录规则
古籍由于其历史的复杂性及数量众多,导致题名复杂,用语繁复,制定著录规则可以明确古籍的著录范围、原则与条目,明确古籍的基本信息。因此,遵循标准化的古籍著录规则可以尽可能地增强古籍著录的普适性,减少馆际古籍资源之间的引用壁垒,加强在古籍数据库中的检索覆盖范围,增加检全率与检准率。目前,除去我国公布的标准化的《古籍著录规则》外,北京大学图书馆也曾基于数字图书馆规范建设的目的,设立了一套古籍描述元数据著录规则[40],与国家标准存在部分条目重叠的同时,也为图书馆古籍著录提供了参考。国外的古籍著录研究多依托于图书馆等中心或机构,力求覆盖世界上大部分的文献资源编目数据。而对于如民族古籍、领域古籍等内容,普适著录规则难免出现不能完全适用的情况,但著录条目也应尽可能在标准化规则下开展。
2)分类规则
古籍分类同样是古籍整理过程中的重要工作环节,对题材与体裁均纷繁复杂的古籍进行分类,可以辅助用户在使用古籍数字化平台时的检索与浏览行为,节省目标古籍查找时间,同时提升古籍数字化平台中推荐算法应用的准确性,提升用户可接触到的古籍范围。我国之前颁布了《中国古籍善本书目》,整体分为经、史、子、集、丛5部,并在各部下方又分出类、属等,属之下又根据情况进行了复分。而《全国古籍普查平台分类表》则在经史子集4部分类的基础上,合并或新建类从部与新学部,用于解决“类书”与“丛书”之间的重复问题以及近代部分古籍的划分问题。与著录规则类似,采用标准化分类规则有助于古籍普查等工作,对用户及研究人员提供更好的引导作用。应尽可能在标准化规则基础上根据自身资源特点进行细致类目划分,从而为古籍整理与古籍平台设计提供一定的依据和范式。
3 国内古籍数字化研究不足
研究结合国内外古籍数字化研究现状,基于古籍数字化路径视角,从古籍数字化路径各环节的规划内容角度分析当前国内古籍数字化的研究不足。
3.1 古籍数字化信息技术应用不足
当前我国的古籍数字化研究更多专注于古籍数字化平台的构建,但其仅为古籍数字化路径中的一步,不论是从古籍的内容正确识别、挖掘,还是从古籍的整理与保护等角度,都需要对古籍中的深层次内容进行探索与分析,如古籍模糊内容识别分析、古籍内容知识发现等。这些超出人工范畴目的的实现离不开各类数字化与信息化技术的应用。国外在古籍数字化进程中已经充分利用各类机器学习技术等大量信息技术对古籍进行文本和特征识别等工作,达到了较高的准确率。国内研究对于利用数字化和信息化技术来实现古籍内容的挖掘和延伸仍存在不足,且涉及算法辅助古籍内容的挖掘和识别的研究也多使用成熟算法,对算法的改进仍有较大空间。
3.2 古籍控制阶段规则难以互通
我国因历史悠久,以及具有丰富的文化积累与文明体系,在时代变迁中产生了多民族、多主题、多形式的古籍,为我国的文化传承提供了丰富素材与宝贵的财富。但同时,我国古籍因其内容与形式上的不同,同样有很多学者在研究中构建了专题古籍的元数据标准,虽方便了古籍专题数据库的构建,却也导致了多种古籍著录规则的出现,这为数据库内容互通带来了一定的困难,使得统一的古籍著录规则被利用率有限。
同时,国内目前也缺乏一个能够面向古籍整体进行分类的标准。我国很多图书馆与数字化平台会利用“经、史、子、集”传统类目以及中图法等元数据标准对古籍进行分类,但这些分类法并不完全面向古籍数据库构建且细化程度不够,导致不同图书馆与平台之间,同一古籍所处的类目不同。这同样会导致馆际数据互通的混乱,导致馆际数据互通过程中的存储资源的浪费。
3.3 古籍数字化平台功能相对基础
从文献分析结果可以看出,国内目前构建了许多古籍数字化平台,内容丰富,完善了众多图书馆馆藏体系。但同时,目前的古籍数字化平台架构大多基于阅读和检索的功能,所提供的服务相对基础和单一。通过国外的古籍数字化平台建设可以看出,很多平台以及古籍数据库都加入了数据统计与分析的能力,引入云计算、物联网、机器学习等方法,直接利用平台内的古籍数据,进行大量深层次分析。显然,将数字化平台赋予这类技术更有利于将古籍资源与学术研究相结合,研究人员可以直接利用平台中的资源进行高学术层次的数据分析,这使得研究过程中的数据获取与数据分析进程都得到了简化,降低了研究过程中第三方软件的培训过程与使用成本,有助于加强古籍研究成果的转化。
3.4 缺乏古籍资源的互联互通
国内古籍数据库面临的一个主要问题是古籍资源的互联互通缺失,古籍数据库之间缺乏有效的连接和交互,这导致了古籍资源的碎片化和孤立化。美国OCLC平台为各个图书馆提供了一个统一的资源共享网络,使得图书馆之间能够共享书目数据、馆藏信息和数字资源,方便研究者查找并获取全球范围内的图书馆藏书,不受地域限制,极大地拓宽了其获取古籍资源的渠道和范围。然而在国内,各个古籍数据库之间缺乏标准化的数据格式和共享协议,导致了资源的孤立性和重复建设。研究者往往需要在多个数据库之间进行繁琐的搜索和转换操作,以获取所需的古籍信息,限制了研究效率和深度。
4 国内古籍数字化研究发展方向
4.1 坚持古籍数字化转化过程中的中国特色及学科融合
我国的古籍数量繁多,种类、题材多样,在古籍数字化对象选取中,应坚持选用“中国特色”古籍,进一步深耕我国各类古籍文献。同时也应尝试将研究目光投向稀有的、冷门的、濒临失传的古籍文献,加快此类古籍的数字化进程,为古籍的保护以及古籍数字化新的领域研究打下基础。
同时,古籍数字化不能仅仅局限于对古籍的研究与理解,计算机技术、信息技术等多学科的内容也需要在其中扮演重要角色。因此,在未来关于古籍数字化的研究与项目中,需要将文献学、历史学、计算机、信息资源管理乃至材料学等学科充分融合,对各学科技术实现充分利用,发挥古籍数字化所涉及的相关学科的长处,才能更充分地实现古籍的整理与数字化转化,尽可能地保留古籍所携带的信息。
4.2 加强古籍数字化资源之间的互联互通
古籍数字化存储所用的数据库及重构后的知识组织平台是数字版古籍重要的资源载体,是对古籍进一步研究利用的重要数据来源。未来,应当在古籍数字化控制所涉及的元数据标准体系的基础上对古籍存储平台的架构进行改善,同时尽可能设置数据库之间的接口,探索建立互联互通机制。通过制定共享标准、建立数据交换平台和推动合作共建,国内的古籍数据库可以实现资源的整合和共享,使研究者能够更便捷地访问和利用丰富的古籍资源,推动古籍研究的深入发展,以达成各古籍数据库与知识平台之间的互联互通,实现资源共享,扩大古籍数字化研究的数据可选择范围,从而保证数字化古籍的利用效率与研究的深化。
4.3 完善古籍数字化控制阶段各类标准体系
在未来,针对古籍的著录、技术、管理和工作流程上,都可以进一步开发并完善相关的标准体系,以及在已有标准下进行说明或细化。政府和权威机构可以组织、领导相关工作,从而出台规范化、统一化、实用性高的标准化体系,在保证体系得到细化的同时,也保证其可借鉴性,从而促进资源的广泛利用。如果能够在已有标准体系的基础上设计充分细化的古籍著录规则与分类体系,将有助于规范化古籍数字化研究,以相对统一的标准体系涵盖专题古籍内容,提升相关研究的借鉴与接续能力,有助于古籍数字化平台、数据库与图书馆之间的互联互通与资源共享,加强数字化古籍的整体性与规范性。
4.4 加强古籍数字化技术的开发与利用
充分利用现有的信息化技术,通过语义分析与关联,对古籍内容进行深层次探索,改进算法使之更符合古籍语言规律,从而挖掘古籍内容中的隐含信息,形成知识发现是当前形势下古籍数字化的一项重要任务。目前,知识图谱等可视化模型的构建越来越受到重视,其是知识发现的重要表现形式,所能生成的结构化数据有助于被研究人员进一步利用,为古籍数字化平台的智能化功能开发提供研究基础。而知识发现及其重组与可视化是挖掘、抽取并理解文本内容的重要方式,也是深刻理解古籍含义的重要研究目的。有效的知识发现有助于古籍的整理与保护,以及古籍中的重要信息和价值的传承。因此,加强古籍数字化技术的开发与利用,充分结合信息技术以驱动对古籍的知识发现是未来古籍数字化研究中的重要方向,是增强古籍研究利用、提升古籍价值的重要手段与途径。
4.5 开展面向用户需求的古籍数字化平台服务
古籍数字化的目的,则是能够实现信息挖掘与知识发现,保留并提升古籍价值,并为古籍的相关研究提供基础。因此,通过面向用户需求构建新的数字化平台应用应是未来古籍数字化平台建设的重要方向。随着技术的发展与研究的逐渐深入,未来有着大量的服务于用户的应用可以被推广与使用到古籍数字化平台上来。如辅助阅读的古汉语字典、纪年换算以及论坛功能等,都可以辅助用户对古籍进行理解乃至交流,是现有基础功能的深化形式。另外,为了方便信息挖掘与知识发现,字/词频统计、主题聚类、地理空间模型、主体与关系关联及相关内容的可视化功能均可作为应用被提供,减少研究中的时间及人力成本,充分满足用户需求。
5 结 语
本文利用Python以及CiteSpace等相关软件与技术,对国内外古籍数字化主题文献的研究现状进行了分析,找出了包括研究对象选取、数字化处理、数字化存储在内的10项古籍数字化主要研究内容。文章进一步将古籍数字化主要研究内容与五原语论及数字人文技术体系相对应,构建出了古籍数字化路径,为古籍数字化工作及古籍进一步开发提供参考。
通过分析结果可以看出,我国目前关于古籍数字化的研究在技术运用、平台服务、标准化体系构建与完善等方面还有进步空间。在未来,我国古籍数字化研究应加强信息技术使用,提升学科融合能力,开发面向用户的数字化平台应用,并进一步完善古籍数字化标准体系,从而为古籍信息化挖掘与知识发现提供有效地帮助,为提升古籍利用价值以及更好地保护传世古籍做出更大的贡献。
猜你喜欢
汉字汉语研究(2021年3期)2021-11-24 01:34:10
纺织科学研究(2021年6期)2021-07-15 08:41:36
天一阁文丛(2020年0期)2020-11-05 08:28:06
福建基础教育研究(2019年1期)2019-09-10 07:22:44
福建基础教育研究(2019年1期)2019-05-28 08:39:49
天一阁文丛(2018年0期)2018-11-29 07:48:08
金桥(2017年5期)2017-07-05 08:14:41
财经(2017年2期)2017-03-10 14:35:35
中国卫生(2016年2期)2016-11-12 13:22:30
财经(2016年15期)2016-06-03 07:38:02
