
基于知识关联度的科学论文扩散效果预测研究
2023-11-15 05:56李悦马亚雪张宇孙建军
现代情报 2023年11期
李悦 马亚雪 张宇 孙建军


摘 要: [目的/ 意义] 基于早期施引文献与科学论文的知识关联对科学论文扩散效果进行预测, 有助于从价值反馈角度前瞻性识别高影响力学术论文, 为科研人员建立科学研究成果早期学术影响力评估体系提供参考。[方法/ 过程] 测度早期施引文献与目标科学论文在主题、期刊和作者3 个层面的关联程度, 采用线性回归与负二项回归模型, 挖掘3 种类型的知识关联度与目标科学论文扩散效果(即扩散速度、广度和强度) 的内在关联机制; 在此基础上引入机器学习算法对科学论文的扩散效果进行预测, 剖析3 类知识关联特征在预测任务中的重要性排序。[结果/ 结论] 神经科学领域的实证分析显示, 主题关联与目标科学论文的扩散速度呈正相关关系, 与扩散广度和扩散强度呈倒U 型关系; 期刊关联会抑制目标科学论文的扩散速度, 但能够正向影响其扩散强度与扩散广度; 作者关联仅对扩散强度有稳定的正向影响; 基于主题关联与期刊关联可以实现对科学论文扩散速度的有效预测, 但难以预测扩散广度和扩散强度。随机森林模型在扩散速度预测中性能最佳, 主题关联特征的重要性高于期刊关联。
关键词: 扩散效果预测; 引文扩散; 知识关联度; 早期施引文献
DOI:10.3969 / j.issn.1008-0821.2023.11.006
〔中圖分类号〕G250 252 〔文献标识码〕A 〔文章编号〕1008-0821 (2023) 11-0073-12
基于引证关系的科学文献扩散是洞察科学发展脉络、揭示知识扩散机制的重要途径[1] 。文献间的引用作为知识扩散的外在表现, 展现了原有知识的积累与传递特征。对科学论文扩散效果进行早期预测有助于快速识别领域内的高质量文献, 为科学研究成果早期学术影响评估体系的构建提供依据, 是知识管理领域长期关注的重要问题。
当前研究大多利用文献计量特征与替代计量特征对扩散效果进行预测。例如, Wang F 等[2] 证实基于作者因素与论文内容因素可以部分预测学界广泛扩散的论文, 期刊影响、引用参考文献数量等文献计量特征也被认为是有效的预测指标[3] 。替代计量特征(如Altmetric 得分)则通过文献在社交媒体上的表现对高影响力的学术论文进行识别[4] 。随着研究的深入, 同行评审文本[5] 、论文元数据[6] 等文本信息也被用于提升模型预测效果。早期施引文献作为新知识的采纳者, 能够给出对目标科学论文知识价值的快速反馈并吸引更多的采纳行为[7] , 被用于科学论文扩散效果的早期预测。研究发现, 早期引用数量、首次引用时间对科学论文扩散效果存在积极影响[8] , 即早期存在的积累优势会使科学论文在扩散后期更容易受到引用。然而, 仅基于引用数量进行测度难以揭示施被引文献间的深层次语义关联和知识复杂性, 也无法避免自引和虚假引用现象可能带来的负面影响[9] , 这导致计数类指标难以准确反映学界对目标科学论文的价值反馈。因此, 构建多维评估方法剖析早期施引文献特征与科学论文扩散效果的内在联系, 并据此预测论文扩散效果显得至关重要。
知识关联展现了关联对象在语义信息上多角度多层次的联系, 是测度科学文献间内在关联的重要指标[10] 。从知识关联层面解析早期施被引文献的内在联系, 能够多维度揭示早期施引文献对目标科学论文知识价值判定情况。当前研究主要从内容特征(如研究主题等)与外部特征(如期刊、作者等)两个方面对文献间的知识关联进行测度[11] , 前者反映了文献间的底层知识联系, 后者展现了文献的显性知识关联。整合科学文献间的内容特征与外部特征以测度早期施引文献与科学论文间的知识关联,有助于全面揭示施被引文献的内在联系, 从学界价值反馈的角度实现对广泛扩散科学论文的早期预测。
鉴于此, 本研究聚焦早期施引文献与科学论文的知识关联度, 探究知识关联度对科学论文扩散效果的预测能力。首先, 构建施被引文献间主题关联、期刊关联与作者关联的测度指标, 剖析早期施引文献与目标科学论文的知识关联特征; 然后, 采用最小二乘法(OLS)与负二项回归模型, 探究早期施引文献与目标科学论文扩散效果(即扩散速度、强度和广度)的关联机制; 最后, 把科学论文扩散效果预测问题转化为二分类任务, 将前序实验中与科学论文扩散效果具有显著关联的因素作为输入特征,训练机器学习模型对科学论文扩散效果进行预测。
本研究基于神经科学领域(Neuroscience)的科学论文开展实证分析, 主要考虑到该领域涉及生物医学、基础生物学、化学等多个子领域[12] , 相关文献可能在不同类型的学科中进行扩散, 因而提高早期施引文献与目标科学论文知识关联特征的区分度, 有助于发掘不同特征对目标科学论文扩散效果的影响。
1 相关研究
1.1 科学论文扩散效果预测研究
科学论文是知识的重要载体, 基于引证关系预测科学论文的扩散效果是知识管理领域的热点问题[13] 。已有研究主要将预测任务定义为回归问题和分类问题, 其中, 回归问题主要通过论文相关特征预测特定时间点的被引情况, 涵盖传统回归、机器学习、深度学习等方法; 分类问题则依据引文分布规律提升模型泛化性[14] , 多利用机器学习方法探究。早期研究者在回归预测方面广泛采用线性回归, 例如, Yu T 等[15] 通过多元回归构建了论文、作者、期刊等特征与论文被引情况间的关系, 并预测论文发表5 年后的被引频次。程子轩等[16] 使用逐步回归预测图书情报领域期刊被引频次, 识别了10 个显著影响因素。随着技术的发展, 机器学习方法逐渐被应用于论文扩散预测研究。Yan R 等[17] 引入了机器学习方法并比较梯度提升决策树、随机森林等模型的预测性能, 发现CART 分类回归树具有最佳预测表现, 其中作者的专业性和期刊影响力是显著影响因素。此外, 深度学习作为机器学习的一个特殊分支, 也被引入到预测模型中。Ruan X 等[18]采用了四层反向传播(BP)神经网络模型预测论文未来某个时间段的总被引频次, 发现BP 神经网络的性能明显优于其他6 个基线模型; 在预测效果方面, 低被引论文的准确率高于高被引论文。Ma A等[6] 进一步引入Bi-LSTM 深度学习模型, 设置两层共32 个神经元提升科学论文扩散效果的预测能力。然而, 一些研究指出被引频次预测具有长尾效应, 不适合采用回归方式进行预测[19] 。由于绝大多数文献积累的被引频次较少, 导致传统的回归分析难以准确度量论文的被引频次。因此, 部分学者将预测任务转化为分类问题, 常用方法包含支持向量机(SVM)、贝叶斯网络(NB)、K 近邻(KNN)、逻辑回归(LR)、决策树(DT)、袋装法(BAG)、随机森林(RF)、自适应增强(AdaBoost)算法等。例如, Wang M 等[20] 对天文学和天体物理学领域的219 篇论文进行了分类, 并使用由5 个决策树分类器组成的多分类器系统来进行预测。其研究表明,论文作者和期刊的声誉有助于提高论文的被引频次预测效果。
特征选择是科学论文扩散效果预测的关键步骤。目前相关研究集中于探索论文、期刊和作者相关特征对科学论文扩散效果的预测能力。在论文特征方面, 论文的主题直接体现其研究内容, 具有预测未来扩散效果的潜力[21] , 已有研究从主题的关注度[22] 、新颖性[17] 和多样性[23] 3 个维度进行评估。此外, 参考文献的数量[24] 、权威度[25] 与多样性[26] 以及论文类型[27] 都是影响论文扩散的重要因素。在期刊特征方面, 一些研究表明高影响力的期刊上发表的论文具有更高的可见性[28] , 然而, 也有研究发现期刊并非是影响预测论文扩散效果的因素[29] 。此外, 出版物被引量、刊载论文数、期刊语言类型也对论文扩散具有一定影响[30] 。在作者特征方面, 著名作者因其在研究领域的高声誉往往享有较好的扩散效果[31] , 马太效应进一步加强了这一现象, 使高被引作者的论文更容易获得其他论文的引用[25] 。有趣的是, 虽然有研究表明国际合著能增加论文的被引率[24] , 却也有研究并不支持这一观点[28] 。此外, 自引率、h 指数、作者所属机构等特征也被证实对扩散效果造成影响[17] 。随着科技和互联网的发展, 基于学术网络的拓扑结构特征[32] 与基于社交网络的替代计量特征[4] 也逐渐被用于预测研究。
1.2 早期施引文献与文獻扩散效果
早期施引文献体现了采纳者对新知识的快速反馈情况, 对该群体的特征进行研究, 能够体现学界对目标科学论文的早期认可度, 有助于预测论文扩散效果。相关工作大致分为两类, 其一侧重于分析早期被引量对科学论文扩散效果的影响。其中, 学者普遍认为论文早期被引量、下载量等动态指标是预测文献扩散的重要因素[33] , 被引量的早期分布状态还可以用来识别科学睡美人文献[34] ; 也有学者从社交媒体的角度考察扩散效果, 发现早期引文数与Twitter 提及数显著相关[35] 。例如, Bai X 等[36]利用梯度增强决策树模型确定了早期的被引频次是论文扩散的最重要因素, Wang M 等[37] 通过决策树算法对天文与天文物理学领域的20 年论文扩散情况进行预测, 发现前5 年被引是关键的预测特征。
另一类研究集中于分析早期施引速度对扩散效果的影响。相关工作发现, 早期被引速度可以预测未来被引情况[23] , 首次被引时间越短的文章知识扩散速度越快[38] , 在相关科学领域影响越大[39] 。例如, Hilmer C E 等[40] 研究了应用经济学与农业期刊论文被引频次的影响因素, 发现如果论文在发表后的第一年被引用, 其后续被引次数会显著增加,平均多出2 6 次, 并从3 个方面对此进行了解释:首先, 存在着“富者愈富” 的马太效应; 其次,快速被引可能表示该论文质量较高, 从而吸引更多读者引用; 最后, 快速引用也可能触发广告和信号传递效应, 让论文迅速受到学界注意。
然而, 上述研究大多关注早期施引者的“量”对扩散效果的提升作用, 较少研究该群体的“质”在其中的作用机制, 为此, 本文从知识关联视角出发, 构建三维指标量化早期施引者的知识特征, 探究其与科学论文扩散效果间的关联机制, 最终实现对科学论文扩散效果的预测。
1.3 科学论文的知识关联研究
知识关联反映了关联对象在语义信息上多角度多层次的相似性特征[10] 。当前研究主要从概念界定、结构分析以及指标应用3 个方面对科学文献间的知识关联展开研究。早期学者着重探讨知识关联的概念与特征, 并从小世界现象等视角出发探讨知识关联的理论基础[41] , 揭示其相互性、传递性、隐含性等特征[10] 。随着其内涵进一步明确, 学者逐渐针对知识关联的分类展开讨论。赵蓉英[42] 从网络的角度将知识关联分为隶属性关联、同一性关联、相关性关联3 类; 高继平等[43] 从知识元的内在联系, 将其分为引用关联、共被引关联、耦合关联等。随后, 知识关联被广泛应用于信息管理、金融科技、疫情应急等领域, 其中信息管理领域的学者大多从知识关联的角度发掘文献或学科背后的知识结构关系。Park H W 等[44] 结合引文分析法与社会网络分析法, 借助有向图揭示通信领域高被引期刊间的关联程度, 进而探究学科背后的知识结构关系; 阮光册等[45] 则结合主题模型、共词分析与关联规则, 揭示文本挖掘领域论文的知识关联结构。
然而, 上述研究着重关注应用知识关联揭示特定期刊或学科领域的整体知识结构, 如何通过科学文献间知识关联实现对扩散效果的预测仍待探索。为此, 本研究从主题关联、期刊关联与作者关联3个维度剖析施被引文献间的知识关联特征, 探究该特征与目标科学论文扩散效果的关联机制, 并基于此实现对科学论文扩散效果的早期预测。
2 研究设计
2.1 问题定义与任务设计
为预测目标科学论文扩散效果, 本文将扩散效果位于前10%的论文视为广泛扩散的论文, 并将该问题转化为有监督的二分类任务: 首先构建传统的多元线性回归模型, 并采用逐步回归法筛选出对科学论文扩散效果具有潜在预测价值的知识关联特征; 然后, 根据回归模型的分析结果, 选取对扩散效果产生显著影响的知识关联特征作为输入变量,借助决策树、支持向量机等预测模型对目标论文的扩散效果进行预测; 最后, 将不同的机器学习预测算法进行综合比较与评估, 以寻找预测性能最优的模型, 并在此基础上探讨预测特征的重要性及其影响机理。
2.2 数据收集与处理
本研究以PubMed Central(PMC)作为数据源获取生物医学领域相关文献, 并关联微软学术图谱(Microsoft Academic Graph, MAG) 数据[46] 分析文献扩散效果。数据的收集与处理流程如图1 所示。
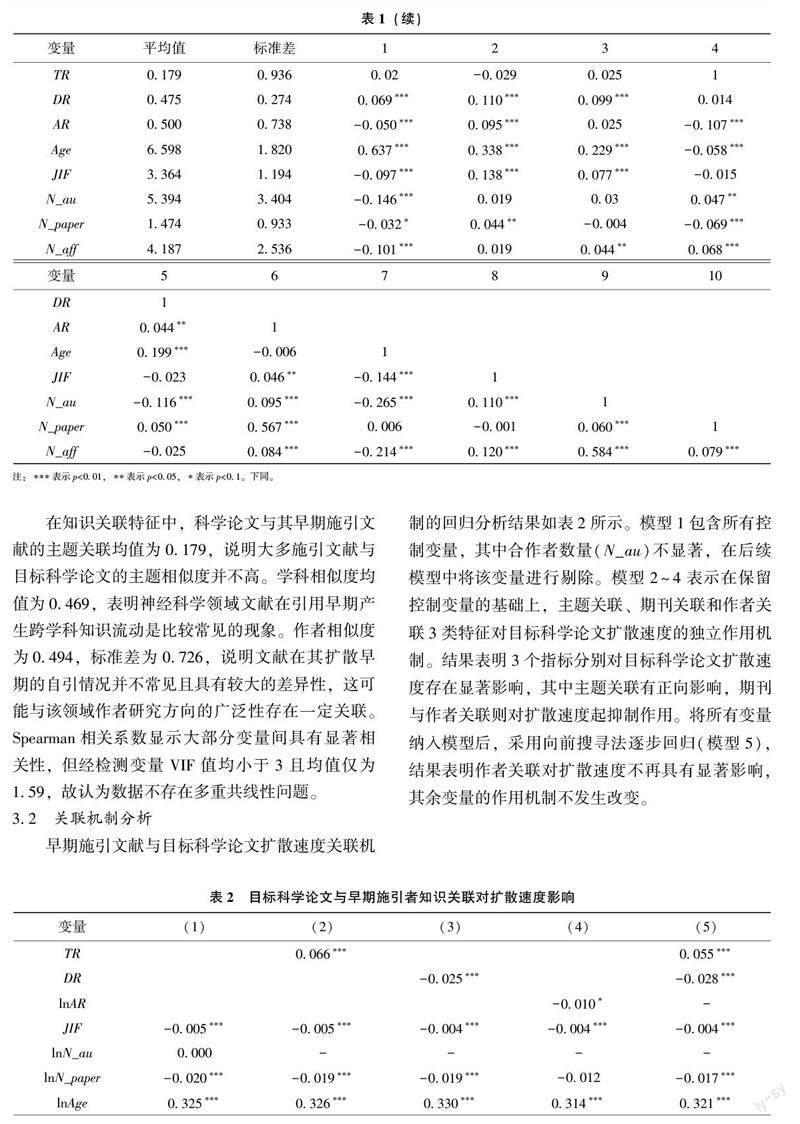
首先, 从PMC 数据库中提取文献的PMCID、DOI等基本信息(共计3 524 897条), 借助MAG 数据库利用文献DOI 建立文献的引证关系; 其次, 筛选早期施引文献均在PMC 数据库中的候选目标科学论文(共计110 998篇); 第三, 根据目标科学论文的ISSN 关联Web of Science(WoS)中期刊引用报告的(Journal Citation Reports)学科类别, 剔除学科分类缺失的文献后, 获取神经科学领域目标科学论文(共计2 635篇)及其施引文献; 最后, 提取目标科学论文及其早期施引文献(共计6 907篇, 去重)的元数据计算知识关联度和跨机构合作数量等控制变量, 并提取目标科学论文的完整施引文献(共计23 293篇)的发表年份、引用数量、ISSN 字段计算目标科学论文的扩散速度、强度与广度。
早期施引文献的定义参考前人的研究, 以目标科学论文发表两年内的引证作为早期施引文献[47] 。此外, 在计算指标时有两个问题需要说明: ①在WoS 学科分类时采取“全计数” 的统计方法, 即若文献a 发表于期刊B, 其在WoS 中同时被归属于学科m 与学科n, 认为文献a 同时对两个学科产生影响[12] ; ②本文采用Sinatra R 等[48] 提出的方法对作者姓名进行消歧后, 为每个作者赋予唯一ID并进行作者关联性计算。
