
融合答案掩码的视觉问答模型
2023-11-22 01:19王峰石方宇赵佳张雪松王雪枫
中国图象图形学报 2023年11期
王峰,石方宇,赵佳,张雪松,王雪枫
阜阳师范大学计算机与信息工程学院,阜阳 236041
0 引言
视觉问 答(visual question answering,VQA)(Antol 等,2015)任务是人工智能领域新兴的一项研究内容,属于自然语言处理和计算机视觉交叉领域,具有广泛的应用前景,逐渐成为热门研究方向。视觉问答任务要求模型根据给定的问题和与问题相关的图像给出相应答案,这种需要处理跨模态信息的任务对模型有着非常高的要求。与传统的基于文本的问答任务不同,视觉问答需要模型根据图像回答对应的问题。模型不仅需要使用自然语言处理技术和图像处理技术对问题文本和图像进行处理,还需要融合这两种不同模态的特征来推理答案。相较于文本,图像模态的特征所包含信息更加复杂,模型很难理解图像中各目标物之间的语义关系和空间关系,而且文本和图像模态的特征属于不同的特征空间,在特征融合时也存在一定困难。因此视觉问答是一个复杂且困难的研究方向。
随着深度学习的发展,视觉问答模型从早期简单的特征融合分类模型转变为深度神经网络模型,准确率得到极大提升。视觉问答任务有专门的数据集,用于训练模型并衡量模型的性能。使用较为广泛的数据集VQA v2.0(Goyal 等,2017),是通过对VQA v1.0(Antol 等,2015)进行优化得到的。图1 展示了VQA v2.0 数据集的部分样本实例。在视觉问答数据集中,答案通常分为“yes∕no”、“number”和“other”3种类型,这3种类型的预测准确率也是判断一个模型优劣的重要标准。目前的模型在VQA v2.0数据集上已经有了较高的预测准确率。

图1 VQA v2.0数据集部分样本实例Fig.1 Sample examples of VQA v2.0 dataset
但Agrawal等人(2018)发现,当前的视觉问答模型容易利用数据集中答案的分布规律而不是图像与问题的结合来得到正确答案,在回答某一类问题时,预测的答案往往是训练集中此类问题出现次数最多的答案,模型在预测时仅通过问题就能够得到正确答案,说明视觉问答任务中存在严重的语言先验问题,并且模型未将图像信息充分利用,无法满足视觉问答的任务需求。为了解决这个问题,他们对VQA v2.0 数据集进行了重新分割,得到了VQA-CP v2.0(countering priors in vqa )数据集。VQA-CP v2.0 数据集的训练集和测试集中的答案分布不均衡,模型如果仅通过答案分布规律回答问题,在测试集上的预测准确率将会很低,该数据集由于能够衡量模型受到语言先验影响的程度,因此成为目前视觉问答任务最常用的数据集。当前的模型因为受到语言先验的影响,在VQA-CP v2.0 数据集上的表现并不能令人满意。
与现实生活相同,视觉问答数据集中的每一类问题都有与之对应的一类答案。例如,询问图像中物体数量的问题,答案都是“number”类型的答案,询问“是否”的问题,答案都为“yes∕no”类型的答案,这种关系是一一对应的。但是由于语言先验等原因,模型往往只通过问题和答案之间的表面关系来回答问题,没有学习到问题和答案之间这种更深层次的对应关系,存在答非所问现象。模型应该回答“yes∕no”类型的答案,却回答了“number”类型的答案,如图2所示。
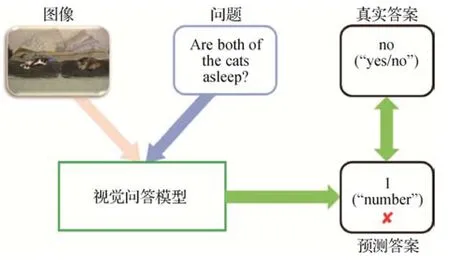
图2 答非所问现象示例Fig.2 An example of irrelevant answer phenomenon
为了缓解这一现象,本文提出使用答案掩码对模型的预测结果进行遮盖的方法,将预测结果的概率分布限制在问题对应的答案类型中,通过训练使模型学习到问题和答案类型之间的对应关系,提高模型的预测准确率。首先,通过K-means 算法对数据集中的答案重新聚类,并为每一类答案生成一个由0、1 组成的答案掩码向量。然后,使用预训练的答案类型识别模型预测输入问题对应的答案类型,并根据该预测结果选择相应的答案掩码。使用基础视觉问答模型得到初步的概率分布向量,并将问题对应的答案掩码与概率分布向量进行融合,遮盖无关答案的概率分布。最后,使用数据集中的样本对模型进行训练,优化基础视觉问答模型的网络参数,缓解答非所问现象,提高模型预测准确率。
1 相关工作
1.1 视觉问答
视觉问答任务自提出以来便引起广泛关注,其流程可以总结为特征提取、特征融合以及答案预测3个步骤(Zhou等,2015)。
视觉问答模型通常使用卷积神经网络(convolutional neural network,CNN)提取图 像特征。Simonyan 和Zisserman(2014)提出的VGGNet(Visual Geometry Group Network)和Szegedy 等人(2015)提出的GoogLeNet 是早期视觉问答模型常用的视觉特征提取器,但是由于参数量大、训练速度慢等原因,逐渐被精度更高、训练速度更快的ResNet(residual network)(He 等,2016)所取代。目前,视觉问答模型最常用是Faster R-CNN(region-based convolutional neural network)(Ren 等,2017)模型。对于问题文本,模型通常使用循环神经网络(recurrent neural network,RNN)提取特征。模型使用GloVe(global vectors for word representation)(Pennington 等,2014)获取词向量表示,并通过长短期记忆(long short-term memory,LSTM)或双向循环门控单元(gated recurrent unit,GRU)(Cho 等,2014)对词向量进行编码。基于注意力机制 的Transformer(Vaswani 等,2017)和BERT(bidirectional encoder representation from transformers)(Devlin 等,2019)也是目前常用的文本特征提取器。
在特征融合方面,Fukui 等人(2016)提出的MCB(multimodal compact bilinear)模型使用双线性池化的方法进行特征融合;Ben-Younes 等人(2017)为了解决双线性模型参数量过多的问题,提出了基于Tucker 分解的模型,在保证双线性交互的同时大量减少了模型的参数,提高了特征融合的效率;Yu 等人(2017)提出多模态分解双线性池化的方法,引入了注意力机制进行特征联合嵌入。除此之外,基于注意力机制的模型也有很好的表现。Yang 等人(2016)提出的SANs(stacked attention networks)模型通过问题对图像进行多次堆叠式的注意力引导,查找图像中与问题相关的区域并推测答案;Lu 等人(2016)提出的共同注意模型主张两个模态的特征相互引导,同时关注图像和问题的关键区域;Anderson等人(2018)提出的UpDn(up-down)模型使用自底向上和自上而下注意力相结合的方式融合特征,是视觉问答任务的经典模型,且具有良好的可扩展性,后来的模型大多都在UpDn的基础上进行改进。
除以上方面,Wu等人(2016)从外部知识库中引入了与图像、问题相关的先验知识对模型进行训练,加深模型对图像的理解。Li等人(2019)提出关系感知图注意模型,利用图关系网络和注意力机制辅助模型理解图像中各目标物之间的语义关系和空间关系,提高了模型的性能。
视觉问答模型特征提取的发展依赖于计算机视觉和自然语言处理技术的进步。在当前条件下,视觉问答模型在特征融合方面还可以进行深入研究,基于外部知识和图关系网络的模型也有广阔的研究前景。
1.2 视觉问答中的语言先验和答非所问
Agrawal 等人(2016)对视觉问答模型进行分析,发现大部分模型的泛化性很差。Jabri 等人(2016)也发现,模型仅学习答案的分布规律就能取得不错的效果。Kafle 等人(2017)对视觉问答任务的未来工作进行分析,指出需要提高模型对图像的关注并平衡数据集的偏差。Agrawal 等人(2018)明确指出,视觉问答任务中存在语言先验现象,并对数据集进行了重新划分。由于这种语言先验性,模型不能真正理解图像的内容,不能准确学习到问题和答案类型之间的联系,容易出现答非所问现象。
目前,克服语言先验的方法大致分为两类,一类是平衡数据集,另一类是通过对抗或融合的方式抵消语言先验。Chen 等人(2020)提出生成反事实样本的CSS(counterfactual samples synthesizing)模型,通过生成的反事实样本平衡数据集。Liang 等人(2020)对CSS 模型进行改进,通过对比学习使模型更加关注图像和问题的关键信息。Zhu 等人(2020)提出SSL(self-supervised learning)模型,引入自监督学习的思想,生成负样本平衡数据集并利用负样本产生的监督信号对基础模型进行指导,增加模型对图像的关注度。Cadène等人(2019)提出RUBi(reducing unimodal biases)模型,通过一个“仅问题模型”来捕获偏差,并将其预测结果生成的掩码向量与基础模型的预测结果进行融合,动态调整损耗以补偿偏差。Clark 等人(2019)提出LMH 模型,将基础模型的预测结果与“仅问题模型”的预测结果进行融合,减轻了语言先验。
对于由语言先验引起的答非所问现象,也有学者进行研究。Gokhale 等人(2020)提出MUTANT 模型,使用经过突变生成的反事实样本进行训练,并计算模型预测的答案类型与真实答案类型的损失,迫使模型学习问题和答案类型之间的关系,减少答非所问现象。Jing 等人(2020)提出的模型将问题分解为多种表示形式,计算问题类型表示和答案之间的相关性得分并映射成(0,1)之间的掩码向量,最后使用掩码向量对答案进行遮盖,进而得到预测结果。Guo 等人(2022)通过一个映射函数将融合后的问题和图像特征映射为掩码向量,并对基础视觉问答模型的预测结果进行遮盖。Agrawal 等人(2018)提出GVQA(grounded visual question answering)模型,通过问题类型预测模型对问题的答案类型进行预测,并将预测结果与基础视觉问答模型的预测结果相加。贾荫鹏(2020)将答案类型预测模型的预测结果作为“第三模态”特征,与问题和图像特征融合来预测答案。
这些方法都对缓解答非所问现象有所帮助,但是也存一些问题。MUTANT模型使用的答案类型种类较少,模型学习到的问题和答案类型之间的关系不够精确;GVQA 等使用答案掩码的模型生成的答案掩码不能消除无关答案对结果的影响;贾荫鹏在重新划分答案类别时使用了大量的人工标注,在融合“第三模态”特征时也引入了一些噪声,影响实验结果。本文方法与上述方法不同,在保证模型能够正确识别问题对应的答案类型的同时,尽可能地将答案类型划分得更为细致,使用0、1 组成的答案掩码对无关答案进行遮盖,以消除无关答案对实验结果的影响。
2 本文方法
本文方法的总体框架如图3 所示。其中,黑色箭头表示数据传输方向,黄色箭头为梯度反向传播方向,⊗为选择器,⊙为点乘。首先,对数据集中的候选答案进行聚类,并为每个答案类型C生成答案掩码mC。然后,通过答案类型识别模型预测问题对应的答案类型,并根据预测结果Pqc(C|Q)选择相应的答案掩码,使用基础视觉问答模型对输入的图像和问题进行预测,得到初步的预测结果fvqa(v,q);最后,将基础视觉问答模型的预测结果与答案掩码融合,得到最终的预测答案P,计算损失并反向传播梯度,优化基础视觉问答模型。

图3 总体框架Fig.3 Overall framework
2.1 答案掩码生成
由于数据集中的答案类型划分不够细致,使用原有的答案类型生成的答案掩码无法高效地过滤无关答案,模型无法学习到问题和答案类型之间更细致的对应关系。为了解决这个问题,首先对数据集中的答案进行聚类,由于数据集中的答案数量较多,大部分模型将出现次数超过9 次的答案作为候选答案,因此仅对这些候选答案进行聚类。不同数据集的候选答案数量不同,其中VQA v2.0中的候选答案有2 410 个,VQA-CP v1.0 有1 691 个,VQA-CP v2.0有2 274 个。图4 展示了VQA-CP v2.0 中的部分候选答案及出现次数。可以看出,数据集中各答案的数量不同,由单词和短语组成,包含颜色、数字、物体等类别。
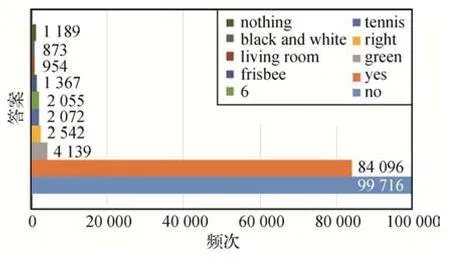
图4 VQA-CP v2.0数据集部分候选答案及出现频次Fig.4 Partial candidate answers and frequency of VQA-CP v2.0 dataset
2.1.1 答案特征提取
对答案进行聚类首先需要得到答案的向量表示。数据集中的答案包含单词和短语,并且它们之间不存在上下文关系,传统的Word2Vec(word to vector)(Mikolov 等,2013)和Glove 不能提取答案特征。由于需要对答案进行聚类,原数据集中的答案类型也不能作为真实标签训练LSTM提取答案特征。采 用CLIP(contrastive language-image pre-training)(Radford 等,2021)作为编码器提取答案特征。CLIP使用4 亿个图像、文本对来训练图像编码器和文本编码器,能够将图像映射到文本描述对应的类别中,预训练的文本编码器提取的文本特征带有丰富的跨模态信息。视觉问答任务中问题对应的答案也来源于图像,使用CLIP 提取数据集中的答案特征有利于下一步的聚类工作。
2.1.2 答案聚类
使用K-means 算法将答案聚为k类。给定答案向量集A={a1,a2,…,am},首先在A中随机选择k个质心向量U={μ1,μ2,…,μk},然后计算第i个答案向量ai和第j个质心向量μj的距离dij,将ai划分至与其距离最小的答案簇Cj中,在答案簇中重新选择新的质心向量具体为
经过多次迭代,得到最终的k个答案簇,最后根据该聚类结果对数据集中的答案类型进行修改。
2.1.3 答案掩码生成
本文方法使用答案掩码对预测结果中的无关答案进行遮盖,为每一类答案生成一个由0、1 组成的答案掩码向量,用0遮盖无关答案的概率分布。
在将答案重新分类后,为k类答案生成k个不同的答案掩码。在视觉问答任务中,同一个模型在加载数据时生成的答案标签是固定的,答案标签的每个元素都对应一个答案。对于类别Cj,首先定义一个向量s={0}n×1,n为候选答案个数。然后确定Cj中的所有答案在答案标签中的位置,并将s中对应位置的元素置为1,即得到答案掩码mj={0,1}n×1。
2.2 答案类型识别模型
得到答案掩码后,还需要选择使用哪一类答案掩码对预测结果进行遮盖。为此,设计了一个答案类型识别模型,识别问题对应的答案类型,如图5 所示。答案类型识别模型主要有两个作用。1)检验聚类结果是否满足要求。根据问题和答案类型之间的对应关系,可以通过答案类型识别模型的预测准确率来检验聚类结果是否满足需求。如果模型准确率高,说明问题和答案类型的关联性强、聚类结果好;反之则说明聚类结果不能满足要求,需要重新进行聚类。2)根据预测结果选择答案掩码。使用答案类型识别模型对问题对应的答案类型进行预测,并根据预测该结果选择相应的答案掩码。

图5 答案类型识别模型整体结构Fig.5 Overall structure of answer type identification model
本文将问题识别答案类型看作一个多分类任务,设计了一个分类模型来加以实现。给定N组样本H=,其中Qi、Ci为第i组样本的问题和答案类别,目标是学习一个映射函数fqc:Q→Ck×1,通过该映射函数可以由问题得到答案类型的预测结果。
对于输入的问题,首先通过GloVe 模型得到词嵌入,然后通过GRU 对词嵌入向量进行编码,获得问题特征向量q,最后通过分类器对答案类型进行预测。具体为
得到预测结果后,计算结果与真实标签的损失Lqc,并根据该损失优化模型参数。具体为
式中,gci表示第i个样本的真实答案类型标签。
本文方法需要根据问题选择正确的答案掩码,因此要求答案类型识别模型有较高的预测准确率。为此,使用预训练好的答案类型识别模型与基础模型进行融合,并且在训练过程中仅对基础视觉问答模型进行优化,答案类型识别模型不参与反向传播过程。
2.3 模型融合
给定N组样本D=其中Ii、Qi、ai为第i组样本的图像、问题和答案,视觉问答模型的目的是学习一个映射函数fvqa:I×Q→An×1,通过该函数可以生成n个候选答案的概率分布。
本文方法具有良好的可移植性,为了验证该方法的效果,将其与具有代表性UpDn、RUBi、LMH 和CSS模型作为基础模型进行融合。
UpDn 模型采用Glove 对问题文本进行词嵌入,并用GRU 提取问题特征向量q。对于图像,UpDn 采用基于自底向上注意力的Faster R-CNN 提取特征v。得到问题和图像特征后,UpDn利用问题特征引导图像特征生成自上而下的注意力,关注图像中的关键区域,得到答案的概率分布向量Pvqa,具体为
预测结果与真实答案标签gai的交叉熵损失LUpDn为
通过式(7)得到LUpDn后,计算梯度并反向传播,调整网络参数。
RUBi 在UpDn 的基础上增加了一个仅问题模型,该模型学习映射函数fqa:Q→An×1,根据输入的问题预测相应的答案。仅问题模型可具体表示为
RUBi将UpDn和仅问题模型融合得到最终的预测结果。具体为
式中,⊙表示点乘含义,σ表示sigmoid激活函数。
计算该结果与答案标签的交叉熵损失LQM,并计算仅问题模型与答案标签的交叉熵损失LQO,两者相加作得到LRUBi。
LMH 也引入仅问题模型减轻语言先验问题。与RUBi 的策略不同,LMH 引入的仅问题模型使用问题类型(问题的疑问词)作为输入进行预测,用于捕获数据集中的偏差。LMH 将UpDn 和仅问题模型融合得到预测结果,具体为
式中,p=fvqa(v,q),b=fqa(q),g(x)是一个可学习的函数,函数表示为softplus(ω·hi),ω为可学习的参数向量,(·)为实际点乘运算,hi为第i个样本在模型最后一个隐藏层的状态。
计算交叉熵损失LLM,为了防止g(x)=0 时模型无法学习到偏差,在损失中加入惩罚项,得到最终的损失LLMH,具体为
式中,λ为超参数,H(z)=
CSS 使用反事实样本训练模型来减轻语言先验。首先计算问题中各单词或图像的各个区域对最终答案的贡献度,然后根据贡献度确定问题的关键单词或图像的关键区域并进行遮盖,最后为其分配错误答案,得到反事实样本。CSS 模型以UpDn 为基础,在训练过程中使用LMH 的方法计算损失并优化模型。
将本文方法与基础模型进行融合。以UpDn 为例,对于输入的第i组样本,答案类型识别模型预测该组样本的问题对应的答案类型为Cj,因此选择答案掩码mj对UpDn 模型的预测结果进行遮盖,得到最终预测结果Pi。具体为
式中,vi和qi为第i组样本中的图像和问题特征向量。
最后,计算预测结果与真实答案标签的交叉熵损失Loss,并根据该损失调整基础模型的网络参数。
3 实验方案
3.1 数据集
本文使用视觉问答领域中的3 个大型公开数据集对融合模型进行训练和评估。
1)VQA v2.0 数据集。VQA v2.0 分为训练集(train)、验证集(val)和测试集(test)。该数据集的图像都来自MS COCO(microsoft common objects in context )数据集(Lin 等,2014)。训练集包含82 783 幅图像、443 757 个问题和4 437 570 个答案;验证集包含40 504 幅图像、214 354 个问题和2 143 540 个答案;测试集包含81 434 幅图像和447 793 个问题。VQA v2.0 在VQA v1.0 的基础上进行了优化,为每幅图像增加了1 个问题和对应的答案,对数据集进行了扩充。对于每个问题,都有两幅相似的图像与之对应,并且由这两幅图像得到的答案也互不相同。通过增加样本的方式平衡数据集,迫使模型关注图像来回答问题,在一定程度上减少了语言先验性。
2)VQA-CP v1.0 数据集。由于VQA v1.0 训练集和测试集的答案分布相似,对于同一类问题,模型不需要关注图像,只需要回答训练集上该类问题出现次数最多的答案就能够在测试集上取得不错的效果,存在较强的语言先验性。VQA-CP v1.0 对其进行重新分割,将训练集和测试集打乱,通过贪心算法使训练集和测试集的答案分布尽可能不同,模型无法利用语言先验性在验证集上获得好的效果。
3)VQA-CP v2.0 数据集。虽然VQA v2.0 通过增加样本的方式减轻了语言先验性,但是其训练集和验证集上的答案分布仍然相似。例如询问数量的问题,训练集和验证集出现最多的答案都为“1”,不管图像中有多少物体,模型只需要回答“1”就能在验证集上取得不错的结果,语言先验依然严重。经过重新分割,VQA-CP v2.0 改善了这种现象,图6 为数据集中较为常见的“How many”和“What color is the”类型的问题在训练集和测试集上的答案分布情况,由于答案数量较多,仅展示了出现次数最多的前5个答案及其占比情况。从图6 可以看出,VQA-CP v2.0 训练集和测试集答案分布差异较大,能够更好地衡量模型受语言先验影响的程度,是目前最常用的视觉问答数据集。本文使用模型在VQA-CP v2.0 数据集上的准确率作为衡量模型性能的主要指标。
3.2 实验相关设置
实验在Linux Ubuntu 20.04.1操作系统上进行,GPU 型号为GeForce RTX 2080 Ti,深度学习框架为PyTorch 1.7.1。实验代码均采用Python 语言编写,版本为Python 3.9.5和Python 2.7.5.
本文方法采用的基础视觉问答模型的代码均来自官方,实验中未对模型的超参数进行修改。设置聚类类别数k=6,batch_size=512,训练次数epoch=50。
4 实验结果与分析
实验主要在VQA-CP v2.0 数据集上进行,以模型在VQA-CP v2.0 测试集上的总体准确率以及在“yes∕no”、“number”、“other”3 种问题上的准确率作为衡量标准。本文虽然对数据集的答案类别进行了重新划分,但是为了保证实验结果的公平性和权威性,仍然按照原始数据集的评分标准进行评分。
本文方法选择UpDn、RUBi、LMH 和CSS 基础模型进行融合实验,为了直观地展示本文方法的有效性和可移植性,将融合后的模型与基础模型在VQACP v2.0 及VQA v2.0 上的准确率进行比较,如表1所示。

表1 本文方法融合不同基础模型在VQA-CP v2.0测试集和VQA v2.0验证集上的准确率Table 1 The accuracies of our method with different basic models on VQA-CP v2.0 test set and VQA v2.0 val set/%
由表1可以看出,融合了本文方法的4种模型在VQA-CP v2.0 数据集上的准确率都有提高,其中UpDn 和LMH 模型分别提高了2.15%和2.29%,CSS模型提高了2.02%,达到60.14%,是目前视觉问答模型在该数据集上的较高水平。RUBi、LMH 和CSS都基于UpDn 模型进行改进,这些模型虽然在VQACP v2.0 数据集上的提高了准确率,但在VQA v2.0上的效果并不如原模型。而本文方法不仅提高了模型在VQA-CP v2.0 数据集上准确率,同时也提高了大部分模型在VQA v2.0上的准确率,说明本文方法有更好的泛化性。
为进一步验证本文方法的泛化性,在VQA-CP v1.0 数据集上进行扩展实验,结果如表2 所示。可以看出,本文方法使大部分模型的准确率都有所提高。结合在VQA-CP v2.0和VQA v2.0上的表现,表明本文方法具有良好的泛化性。

表2 本文方法融合不同基础模型在VQA-CP v1.0测试集上的准确率Table 2 The accuracies of our method with different basic models on VQA-CP v1.0 test set/%
表3 展示了本文方法与一些视觉问答经典模型和表现较好的模型进行比较的结果。其中包括堆叠式注意力模型SANs(stacked attention networks )、双线性池化模型MCB(multimodal compact bilinear )、同样关注答案类型的GVQA(grounded visual question answering )模型、基于自监督学习的SSL(selfsupervised learning )模型、视觉问答经典模型UpDn、目前在VQA-CP v2.0 上表现较好的RUBi、LMH 和CSS 模型以及基于CSS 模型的CSS+LC 模型。由于目前表现最好的MUTANT 模型在生成突变样本时进行了大量的人工标注,并且使用了预训练的LXMERT(learning cross-modality encoder representations from transformers )模型(Tan 和Bansal,2019),参数量巨大,未与其进行比较。
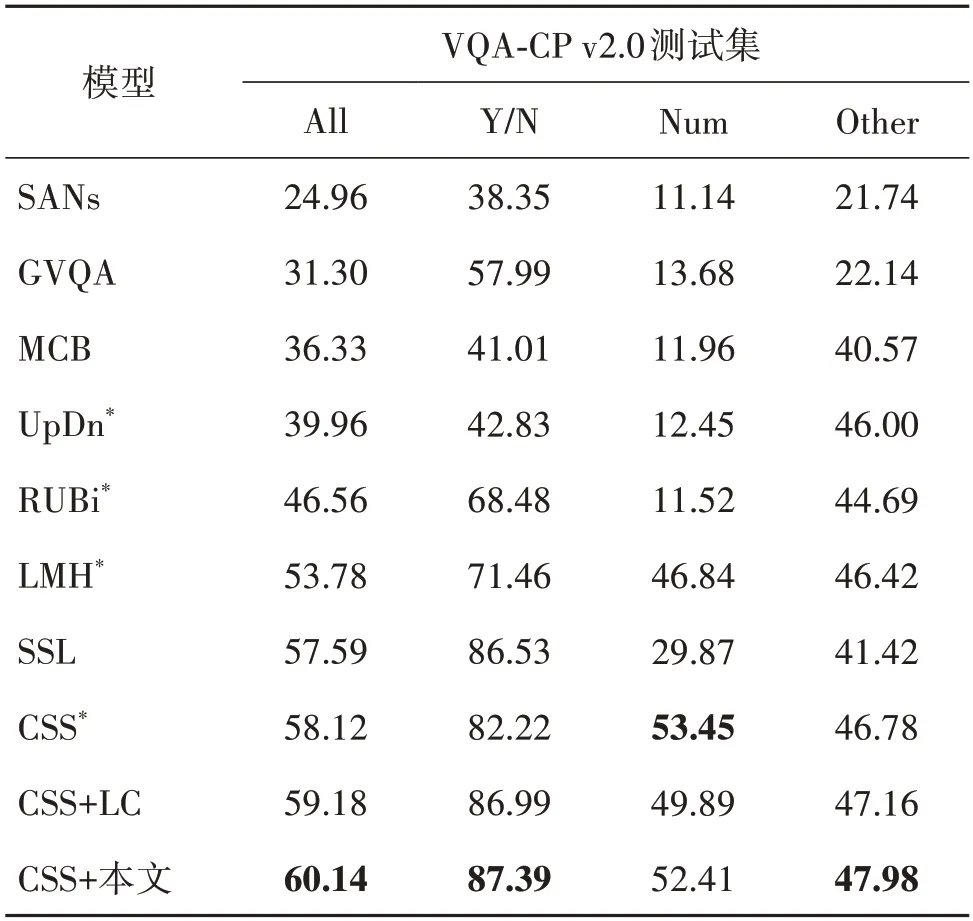
表3 不同模型在VQA-CP v2.0测试集上的准确率Table 3 The accuracies of different models on the VQA-CP v2.0 test set/%
从表3 可以看出,融合本文方法后的CSS 模型在VQA-CP v2.0 数据集上的有较好的表现,准确率优于其他模型。
本文方法在多个模型上都有很好表现,提高了模型性能。为了验证融合本文方法在提高模型精度中的作用,在VQA-CP v2.0测试集上进行消融实验,结果如表4 所示。其中,Q_CSS 代表仅遮盖问题的关键单词生成反事实样本,V_CSS 代表仅遮盖图像的关键区域生成反事实样本。可以看出,将本文方法与生成反事实样本的LMH 模型融合,可以提高模型的准确率。反事实样本和LMH 起到平衡数据集的作用,本文方法促使模型学习问题和答案类型之间的关系,从而提高了模型的性能。
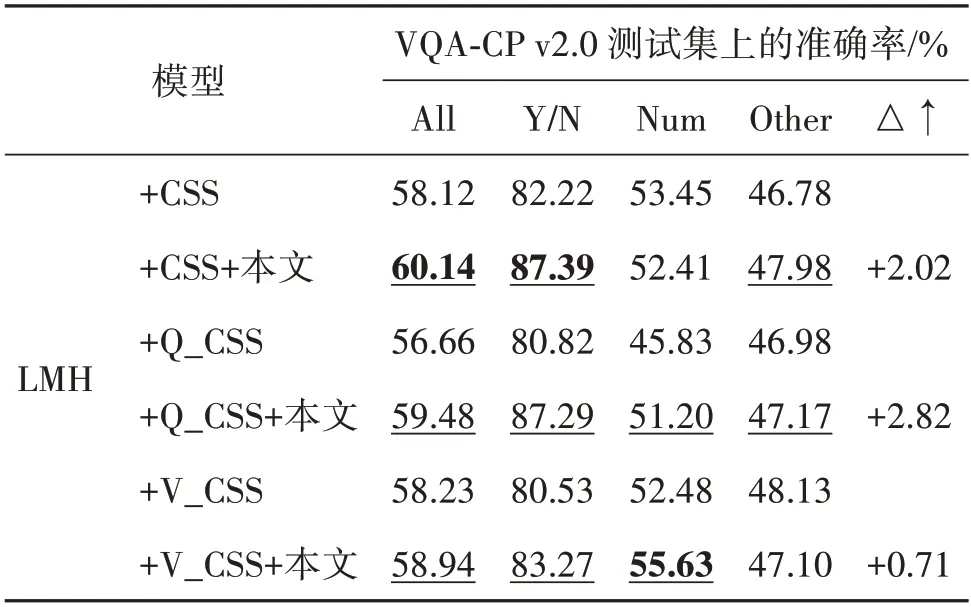
表4 本文方法在CSS模型上的消融实验Table 4 Ablation experiment of this method on CSS model
在答案聚类过程中,需指定答案类别数k,即将答案划分为多少类。超参数k对模型的准确率有一定影响。k值越大,每个答案类型包含的答案数量越少,答案掩码能够遮盖更多的无关答案,但答案类型识别模型的准确率会降低;反之,答案掩码的作用会减小,但答案类型识别模型的准确率会提高。为此进行了超参数实验,结果如图7 所示。可以看出,随着k的增大,问题类型识别模型的准确率不断降低,融合后的CSS 模型的准确率大体上也呈现降低趋势。在k=6 时,答案掩码的覆盖范围和问题类型识别模型的准确率达到平衡,模型的准确率最高,因此取k=6。将VQA-CP v2.0 数据集中的答案聚类为6 类,分别为yes∕no、number、color、time、country 和other。图8 展示了聚类前后各种答案类型在数据集上的分布情况。可以看出,聚类后数据集中的答案类别更多,每个类别所占比重较原数据集也有所不同,生成的答案掩码更加准确,模型能够学习到问题和答案类型之间更细致的关系。

图7 k取值对模型准确率的影响Fig.7 The influence of k value on model accuracy
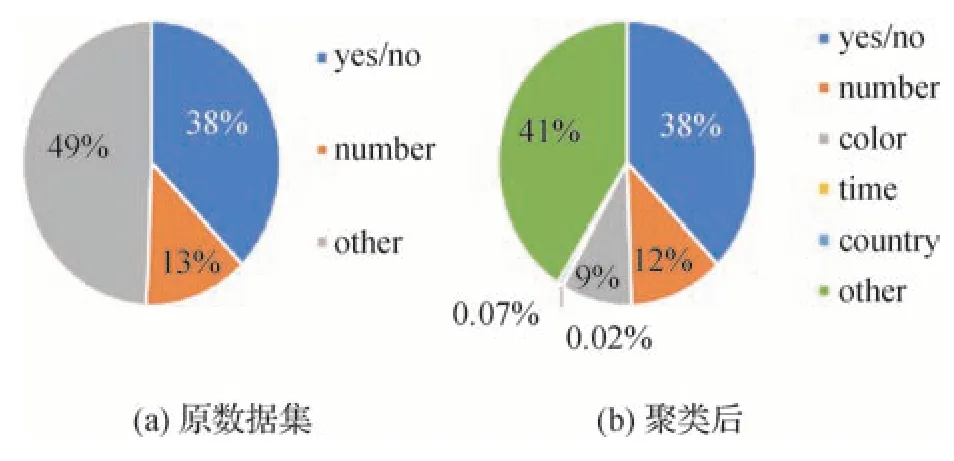
图8 聚类前后各答案类型分布图Fig.8 Distribution of answer types before and after clustering((a)original dataset;(b)after clustering)
从结果来看,本文方法在总体上提升了模型的预测准确率,提高了模型的性能。对于答非所问现象,对CSS、LMH 模型以及本文方法在VQA-CP v2.0上的预测结果进行了对比分析,本文方法改善了模型答非所问现象,达到了预期效果。图9 展示了部分实例的模型预测结果对比。

图9 部分实例的模型预测结果对比Fig.9 Comparison of model prediction results of partial examples
5 结论
本文提出一种通过答案掩码对基础视觉问答模型预测结果进行遮盖的方法,减少无关答案对最终结果的影响,通过训练使模型学习到问题和答案类型之间的对应关系。在VQA-CP v2.0数据集上的实验结果表明,本文方法能够提高模型的预测准确率。同时,在VQA v2.0和VQA-CP v1.0数据集上的实验证明了本文方法具有较好的泛化性,在VQA-CP v2.0 数据集上的消融实验证明了本文方法的有效性。本文方法能够改善答非所问的现象,提高了模型的性能。
但是,本文方法对模型准确率的提升程度有限,尤其是在VQA v2.0和VQA-CP v1.0数据集上,这说明本文方法的泛化性不够强,模型不能准确学习到问题和答案之间更深层次的关系。究其原因,是答案聚类效果不够好、答案类型识别模型准确率不够高所致。下一步的工作重心将放在提高聚类效果及答案类型识别模型准确率上。在提高聚类效果方面,可以使用其他方法获取答案特征。例如,采用视觉问答模型对每个候选答案的预测概率作为候选答案的特征进行聚类。还可以借鉴Si等人(2021)提出的答案重排序方法,将视觉问答模型预测结果中概率最高的部分候选答案归为一类,并根据问题类型对这些类别进行合并,得到最终结果。在优化答案类型识别模型方面,可以调整模型的网络结构,提高模型的预测准确率。除此之外,还可以选择性能更好的LXMERT 等模型作为基础模型与本文方法进行融合。从理论上来说,本文方法适用于各种问答任务,可以考虑将本文方法应用于其他问答任务中。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
通信学报(2019年5期)2019-06-11
中国交通信息化(2018年5期)2018-08-21
通信技术(2018年3期)2018-03-21
数学物理学报(2017年5期)2017-11-23
浙江大学学报(工学版)(2015年4期)2015-03-01
