
基于Transformer的脊椎CT图像分割
2023-11-22 01:20卢玲漆为民
中国图象图形学报 2023年11期
卢玲,漆为民
江汉大学人工智能学院,武汉 430056
0 引言
脊椎疾病已成为当代高发疾病且呈年轻化发展趋势,因此其诊断和治疗尤为关键。随着人工智能技术的不断发展,智能化诊断的需求不断提高。在计算机辅助诊断下,使用分割算法分割出脊椎CT(computed tomography)影像中的感兴趣区域,结合三维重建技术,可使医生直观清晰地观察和剖析病灶区域,为模拟手术路径及外科手术方案制定提供理论支撑,提高诊断效率和正确率。然而由于脊椎结构复杂,脊椎CT 影像中存在噪音干扰,脊椎边缘模糊,分界不清等问题,加剧了脊椎分割的难度。
随着人工智能技术和深度学习方法的迅猛发展,基于卷积神经网络(convolutional neural network,CNN)的深度学习算法在医学图像分割领域上取得了显著成效。Long 等人(2015)提出了首个端对端的针对像素级预测的全卷积神经网络(full convolutional networks,FCN),解决了语义级别的图像分割问题。但FCN 对细节信息不敏感,分割不够精细,针对此问题,Ronneberger 等人(2015)提出了一种基于FCN 的U-Net 图像分割模型,采用编码器—解码器结构及跳跃连接的设计模式,将浅层特征和深层特征进行融合,实现更精细的分割。由于U-Net 结构自身特点及医学图像结构固定、具有多模态等特点,使得U-Net 在医学图像分割上表现良好,成为医学图像分割的基准。由于卷积运算固有的局限性,导致基于CNN 的分割模型如U-Net存在长距离交互受限等问题。Transformer(Vaswani 等,2017)集成全局自注意力机制,可捕获长距离的特征依赖,在自然语言处理(natural language processing,NLP)取得了广泛的成功。Dosovitskiy 等人(2021)基于此提出了ViT(vision Transformer)模型,在图像识别任务中获得了更高的性能。此后,Transformer 便更广泛地运用到计算机视觉领域,并表现出巨大的优势。由于Transformer的计算量很大且不能有效地捕获区域特征,考虑到CNN 获取局部特征及Transformer 捕获全局特征的优势,许多研究人员将U-Net和Transformer进行结合并应用到语义分割任务(Chen 等,2021;Guo 和Terzopoulos,2021;Azad 等,2022)中,以捕获局部和全局特征,获得更好的分割性能。
基于深度学习的分割方法已在脊椎图像的分割问题上有了成功应用。刘忠利等人(2018)基于FCN提出卷积、反卷积神经网络模型对椎骨进行全自动分割。李贤和何洁(2018)使用3D 全卷积网络分割椎骨,缩短了分割时间,分割效果较好。Kolařík 等人(2019)使用3D Dense U-Net 分割胸椎和腰椎。田丰源等人(2020)使用AttentionNet(Sekuboyina 等,2017)定位脊椎,再使用改进的Dense-UNet(Li 等,2018))分割脊椎,分割精度优于传统Dense-UNet。金顺楠等人(2021)将尺度残差模块及通道注意模块引入到U-Net 网络中分割脊椎椎骨,获得了较高的分割精度及分割效率。基于深度学习的方法在医学图像分割上效果显著,但对分割精度有了更高的要求。
由于大多数对脊椎图像的研究工作是基于CNN 模型开展的,存在一定的局限性,分割精度还有待提升。Transformer近年来才被应用到计算机视觉领域中且取得了一定的成功,但在脊椎CT图像的分割任务上研究甚少。故本文以脊椎CT 图像作为研究对象,旨在提出一种基于Transformer 的分割算法,结合CNN 与Transformer 的优势,实现对脊椎CT图像的高效自动化分割,提高脊椎分割精度。主要研究内容包括:1)结合Transformer、注意力门控机制(attention gate,AG)(Oktay 等,2018)及U-Net 网络,提出一种CNN 与Transformer 的混合分割模型TransAGUNet(Transformer attention gate U-Net),实现脊椎CT 图像的自动化分割,以解决U-Net 远距离传输受限、Transformer局部特征识别不足等问题,进一步提升脊椎分割精度。TransAGUNet 为编码器—解码器结构,编码器采用CNN 和Transformer 混合架构,获取丰富的局部与全局信息,其结构类似于TransUNet 的编码结构。解码器由CNN 架构组成,在跳跃连接中融入AG,将得到的注意力图与解码器上采样获得的特征图进行拼接,融合低层与高层特征从而实现更精细的分割。将经过跳跃连接后拼接的特征图进行两次卷积操作,增强网络对脊椎的特征提取能力,再进行一次1 × 1 卷积降维,减少网络参数量;2)设计对比实验和消融实验,验证模型的有效性。实验使用Dice Loss 与带权重的交叉熵之和作为损失函数,以解决正负样本分布不均的问题。将提出的模型在VerSe2020(vertebrae segmentation)数据集上测试,分割结果在其余6 种CNN 分割模型及Transformer与CNN混合分割模型中最佳。
1 基于深度学习的医学图像分割模型
1.1 CNN分割模型
基于卷积神经网络(CNN)的分割模型已成功地应用在众多医学图像分割任务中,如脑肿瘤分割(赵奕名 等,2020)、胸部多器官分割(吉淑滢和肖志勇,2021)、淋巴结分割(刘羽 等,2022)等。由于U-Net(Ronneberger 等,2015)在医学图像分割上取得了很好的效果,一系列U-Net 的变型网络模型被相继提出。Oktay 等人(2018)提出Attention U-Net,将提出的注意力门控机制(AG)与U-Net 相结合,首次在医学图像的CNN 中使用soft attention,增加了模型对前景像素的敏感度,基于网格的AG 使注意力系数更关注局部区域特征,抑制无关区域。之后,Xiao等人(2018)针对视网膜血管成像限制及光源干扰等分割任务的难点提出了Res-UNet(residual U-Net),该模型将残差网络ResNet(residual neural network)(He等,2016)和U-Net 进行了融合,增加了网络的深度,防止过拟合,提高了模型的准确度。Zhou 等人(2018)基 于DenseNet(dense network)(Huang 等,2017)思想提出U-Net++,使用密集的跳跃连接,通过特征叠加的方式整合不同的特征,是一种深度监督的编码器—解码器网络。Jha 等人(2019)提出Res-UNet++,在Res-UNet 的基础上对图像的后处理部分使用了条件随机场(conditional random filed,CRF)及测试时数据增强(test time augmentation,TTA),使用空洞空间卷积池化金字塔模块(atrous spatial pyramid pooling,ASPP)代替Res-UNet 中的桥接部分,分割性能优于Res-UNet,在难以分辨的息肉问题上表现优异。Huang 等人(2020)提出U-Net3+,表示U-Net++虽然使用了密集的跳跃连接,但未充分利用多尺度提取足够信息,因此在U-Net3+中提出了全尺度跳跃连接(full-scale skip connections),精度较U-Net++有一定的提升。虽然这些方法可在一定程度上提高医学图像的分割精度,但仍存在长距离交互受限、全局信息提取不足等问题。
1.2 Transformer分割模型
Transformer(Vaswani 等,2017)最初应用于自然语言处理并在很多任务中获得了巨大的成功,如释义短语生成(Egonmwan 和Chali,2019)、语音识别(Shi 等,2021)及语音合成(Chen 和Rudnicky,2022)等。受此启发,研究人员将其运用到计算机视觉领域,在图像分类(Dosovitskiy 等,2021)、语义分割(Strudel 等,2021)等计算机视觉(computer vision,CV)任务中应用广泛。Dosovitskiy 等(2021)提出的ViT 模型较传统的CNN 有更高的性能。ViT 模型将输入图像分成固定大小的图像块Patches,然后通过线性变换得到Patch embedding,并使用Position embedding 编码位置信息,再将经过以上处理的Patches 输入到Transformer 的编码器中进行特征提取,最后通过多层感知机(multi-layer perceptron,MLP)完成分类。Segmenter(Transformer for semantic segmentation)(Strudel 等,2021)是基于ViT 改进的纯Transformer 图像语义分割模型,是一种完全基于Transformer的编码器—解码器架构,编码器采用ViT类似结构,解码器使用逐点线性映射或mask Transformer,可以很好地捕获全局上下文信息,提高了图像分割性能。
1.3 CNN 与Transfomer混合分割模型
对于医学图像分割问题,大部分的研究工作是基于CNN 分割模型展开的,近年来由于Transformer在计算机视觉领域取得了重大的突破,研究者将CNN 与Transformer 相结合,提出的混合分割模型较仅有的CNN 模型更具全局特征提取能力,在医学图像分割问题上取得了进一步成功。Chen 等人(2021)提出的TransUNet 分割模型首先利用 CNN(ResNet50)提取低级特征,然后使用ViT 进行编码,对全局交互进行建模,并结合跳跃连接,在Synapse多器官分割数据集上分割性能优于U-Net、Attention U-Net,成为医学图像分割的强大替代方案。随后,一系列基于CNN 与Transformer 的混合分割模型相继提出,如TransBTS(Transformer brain tumor segmentation)(Wang 等,2021)、nnFormer(not-another Transformer)(Zhou 等,2022)、TransNorm(Transformer spatial normalization)(Azad 等,2022)等。TransBTS 首次使用3D CNN中的Transformer分割MRI(magnetic resonance imaging)脑肿瘤,编码器首先使用3D CNN 提取空间特征图,然后将特征图映射并改进后的tokens 传入Transformer 中进行全局建模,解码器采用渐进式上采样得到预测的分割图,在BraTS2019(brain tumor segmentation)数据集上进行测试,分割性能优于最先进的3D MRI脑肿瘤分割方法。TransNorm 从Transformer 模块中推导出一个空间归一化模块,与跳跃连接后的特征图进行拼接,自适应校准跳跃连接路径,在Synapse、ISIC2017(international skin imaging collaboration)、ISIC2018 这3 个经典的医学图像分割数据集上均取得了较好的分割性能,分割精度高于TransUNet。
2 本文方法
针对脊椎CT 图像分割,本文结合Transformer、AG 和U-Net,提出一种CNN 与Transformer 混合分割模型TransAGUNet(Transformer attention gate U-Net),构成编码—解码结构,其模型结构如图1 所示。编码结构采用 CNN 与Transfomer 混合架构,具体由ResNet50 与ViT 模型(Dosovitskiy,2021)组合构成,与TransUNet(Chen 等,2021)的编码结构类似。对于输入的脊椎图像,首先通过ResNet50 提取低级特征,保留3 次下采样对应的特征图,然后进行块编码(Patch embedding)与位置编码(Position embedding),将得到的patches 输入到Transformer 编码器中,学习长期上下文依赖关系,提取全局特征。在解码部分前3 层的跳跃连接中融入AG,得到下采样特征图对应的注意力图(attention map),再与下一层经过上采样后的特征图进行拼接,然后进行两次普通卷积及一次1 × 1 卷积进行解码。最后一层将上一层上采样后的特征图通过两次普通卷积与一次1 × 1卷积,最后进入二分类器,逐像素区分前景和背景,得到脊椎分割预测图。
2.1 编码器
2.1.1 Embedding
模型编码器中的Embedding 部分包括Patch embedding 和Position embedding。用H、W表示图像的高、宽,C表示图像通道数。对于输入维度为H×W×C的图像,Patch embedding 操作将 图像重 塑(reshape)成维度为N×P2×C的patchesxp。其中,N=HW∕P2,每个patch 的大小为P×P,通道数为C,分别用表示,然后使用线性投影E将patches 映射到D维空间。为了保留patches 的空间信息,对其叠加Position embedding,用Epos表示。整个过程可表示为
式中,z0表示经过Embedding 层后得到的特征图,E∈,Epos∈RN×D。
2.1.2 Transformer编码器
Transformer 编码器将图像经过Embedding 得到的patches作为输入,其整体结构如图1(b)所示,由n层构成,本文采用的n为12。每一层由多头自注意力(multi-head self-attention,MSA)和多层感知机(MLP)模块组成。其中MLP 由两层线性层组成,两层均使用GELU(Gaussian error linear unit)作为激活函数。Transformer encoder第n层的输出可表示为
式中,LN代表层标准化操作(layer normalization)(Ba等,2016),zn表示经过编码后的图像表示。
2.2 解码器
2.2.1 注意力门控机制
CNN 在对形变程度较大的医学图像进行分割时,通常采取的做法是先定位,确定感兴趣区域(region of interest,ROI),再进行分割。注意力门控机制AG 参数计算量小,很容易与CNN 模型进行整合,将CNN 与AG 进行结合,也可达到此效果。AG自动学习目标的外形和尺寸,突出显著特征,抑制无关区域的特征响应,通过基于概率的soft attention 替代定位模块,无需划分ROI,通过少量计算量来提高模型的敏感度与准确率。AG 的具体结构图如图2所示。

图2 AG结构图Fig.2 AG structure diagram
首先将经过上采样后维度为H×W×C的特征图xu与经过CNN提取的维度为H×W×C的特征图xs进行并行处理,分别使用3 × 3的卷积及批归一化(batch normalization,BN)操作得到维度为H×W×(C∕2)的和,再将与对应元素相加,然后进行ReLU(rectified linear unit)操作,随后进行1 × 1 输出通道数为1的卷积操作,再使用BN、sigmoid激活函数得到维度为H×W× 1的注意力系数权重α,最后使用xs乘以α,得到维度为H×W×C的注意力特征图xr。
2.2.2 解码结构
解码器采用的是CNN 架构,使用二维双线性上采样2 倍率逐层恢复图像尺寸。在跳跃连接自下而上的3层中融入AG 结构,将浅层特征与高层特征进行融合,实现精细分割。以第3 层结构为例,首先将CNN 提取的特征图xs∈RH′×W′×C′经过AG 得到注意力特征图xr,再将xr与下一层经过上采样后的特征图xu在通道维度上进行拼接,得到特征图x1∈RH′×W′×2C′;然后进行两次3 × 3输出通道数为C′的卷积操作,使用ReLU 激活函数,得到特征图x2∈RH′×W′×C′;再使用1 × 1 输出通道数为C′′的卷积操作降维,得到特征图x3∈RH′×W′×C′′。本文4 次上采样后设置的输出通道数分别为[256,64,32,16],最后一次上采样特征图经过两次3 × 3 及一次1 × 1 卷积操作后,得到特征图x∈R2H′×2W′×16,解码器具体结构如图1(a)所示。
2.3 损失函数
2.3.1 带权重的交叉熵损失函数
交叉熵损失(cross entropy loss,CE Loss)是基于分布的损失函数,网络训练过程中梯度下降更新快,常作为分类器的损失函数,对每个类别的权重相同,计算式为
式中,N表示样本个数,m表示样本分类数,yij表示真实值,pij表示预测值。
对于医学图像分割任务,往往是对CT切片后的图像进行逐像素分类,划分前景和背景区域。通常伴随前景和背景分布不均的问题,即背景像素偏多,前景像素偏少的情况,导致模型训练更易于学习背景特征,而很难学习前景特征,从而降低模型对前景区域的分割精度。因此对CE Loss进行改进,从而得到带权重的交叉熵损失(weighted cross entropy loss,WCE Loss),对较少类别进行加权,计算式为
式中,wj为每个类别的权重。
2.3.2 Dice Loss
Dice Loss 由Milletari 等人(2016)为应对语义分割任务中正负样本不平衡问题而提出。来源于用来评估样本相似度的度量函数Dice 相似系数,计算式为
式中,X和Y分别表示真实和预测轮廓区域所包含的点集。
Dice Loss 是一个区域相关的损失函数,即当前像素点的损失及梯度值与该点及其他像素点的预测值及真实结果(ground truth)相关。Dice Loss 对于固定大小的正样本区域计算的损失是相同的,且在训练过程中更倾向于挖掘前景区域,从而在一定程度上解决正负样本不均的问题。
本文主要分割出脊椎与非脊椎部分,即逐像素区分前景和背景两类。为解决脊椎图像前景和背景像素不平衡问题,且考虑到Dice Loss 训练不稳定,在极端情况下会出现梯度饱和现象,因此结合WCE Loss 进行改进,在模型训练中采用Dice Loss+WCE Loss作为损失函数,从而提高模型的分割精度。
3 实验
3.1 数据集及预处理
实验使用的CT 数据集来自于国际医学图像计算和计算机辅助干预协会(Medical Image Computing and Computer Assisted Intervention Society,MICCAI)2020 年举办的脊椎分割挑战赛数据集VerSe2020(Löffler 等,2020)。VerSe2020 包含训练集和测试集各100 例,包括颈椎(C1-C7)、胸椎(T1-T12)和腰椎(L1-L5),是目前为止最大的脊椎分割数据集,其分割真实图像由专业医生手工标注。从100 例数据集中分别筛选出72例、8例作为本次实验的训练集、验证集,然后在测试集中随机选取16 例作为本次实验的测试集。
首先将选取的CT 数据统一调整为RAI(right anterior inferior)方向,再进行切片处理。由于相邻片非常相似,防止产生过多冗余数据,本次实验采取间隔2 片进行切片操作,将3D 体素数据转化为2D图像,并舍弃只含有背景部分的图像,最终得到训练集图像3 168 幅,验证集图像403 幅,测试集图像774 幅。为了减少网络训练计算量,将所有图像均裁剪为256 × 256 像素,并转化为对应数据集的npy(numpy)文件,以提高数据读取速度。
3.2 实验环境
实验基于Ubuntu16.04操作系统,使用4块显存为8 GB 的NVIDIA GeForce GTX 1070Ti 显卡,分布式数据并行(distributed data parallel,DDL)模式进行多卡并行训练,使用Python3.8 作为开发语言,开发框架为PyTorch1.11。实验batch size 设为8,epochs为100,使用梯度下降法(stochastic gradient descent,SGD)优化器,初始学习率设为0.04、动量为0.9、权重衰减率为0.000 1。学习率采用动态更新策略,在每一次迭代中根据学习轮次线性降低。使用正态分布对数据进行初始化,在编码和解码阶段加入BN层以加速网络收敛。
3.3 评价指标
本文主要采用Dice 相似系数(Dice similarity coefficient,DSC)、均交并比(mean intersection over union,mIoU)、召回率(recall)、精确率(precision)和像素准确率(pixel accuracy,PA)作为评价指标来评估模型对脊椎CT 图像的分割性能。其中,使用mIoU 和PA 作为评价指标,不仅考虑到对脊椎的分割,同时考虑到对背景的精确识别,通过混淆矩阵(confusion matrix)来实现。
3.4 对比实验
为客观评估提出方法的分割性能,在相同实验环境及数据集下,将提出的CNN 与Transformer 混合分割模型TransAGUNet 与优秀的CNN 分割模型U-Net、Attention U-Net、U-Net++、U-Net3+及CNN 与Transformer 混合分割模型TransUNet、TransNorm 的测试结果进行对比,实验结果如表1所示。

表1 不同模型在VerSe2020数据集上的分割结果对比Table 1 Comparison of segmentation results of different models on the VerSe2020 dataset
由表1 可见,U-Net模型脊椎分割的Dice 系数为0.743 1,其余各模型较此均有一定的提升。其中,Attention U-Net 在CNN 架构的对比分割模型中Dice系数提升最为显著,提升了2.38%,可见Attention U-Net 在U-Net 的基础上融入AG 后,模型的性能得到了显著地提升,因而本文在模型设计过程中考虑到了AG 的融入。提出的TransAGUNet 模型在Dice系数、mIoU 及召回率这3 个评价指标上都取得了最好的结果。TransAGUNet所得的Dice系数为0.787 8,较CNN 分割模型U-Net、Attention U-Net、U-Net++、U-Net3+分别提升了4.47%、2.09%、2.44%,2.23%,较Transformer 与CNN 混合分割模型TransUNet、TransNorm 分别提升了2.25%、1.08%;mIoU 达到了0.895 2,与以上6 种分割模型相比,分别提高了0.78%、0.42%、0.06%、0.32%、0.93%和1.14%,反映了TransAGUNet分割结果与真实值的高相似度;召回率达到了0.848 7,表明模型能较准确地识别前景部分;PA达到了0.994 0,由于背景部分占比较大,PA值主要反映了对模型对背景的精确识别能力。综上可知,本文提出的模型分割结果与真实值相似度较高,能较好地识别前景与背景,分割性能优于其余6种模型,有效地提升了脊椎CT图像的分割精度。
3.5 消融实验
3.5.1 提出的解码结构及AG对模型性能的影响
TransUNet是目前较新的、分割性能较优的CNN与Transformer 混合分割模型,从表1可知,其Dice 系数与mIoU 均高于U-Net。由于提出的模型与TransUNet 的Backbone 部分类似,较TransUNet 相比,主要体现在解码结构及跳跃连接部分的不同,为了更好地反映提出的CNN 解码结构及在跳跃连接部分融入AG 对模型性能的影响,以TransUNet 作为基准,设置相应的消融实验,实验结果如表2 所示。其中,Model1 与TransUNet 相比改变了解码结构,Model2 在Model1 的基础上在跳跃连接部分加入了AG,即本文提出的TransAGUNet模型。
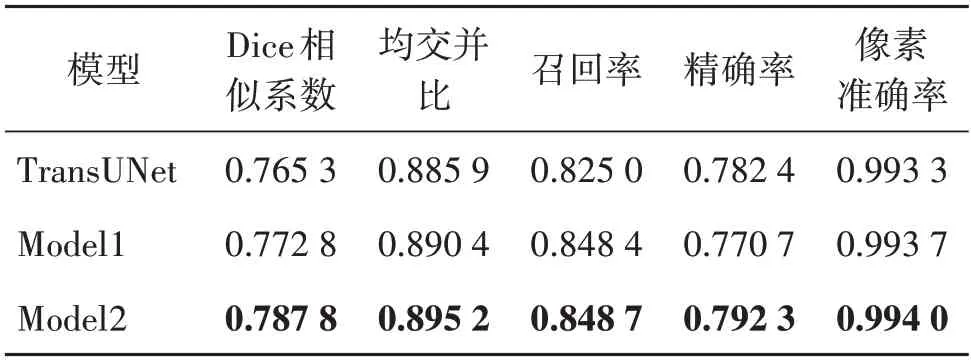
表2 提出的解码结构及AG对模型性能的影响Table 2 The influence of proposed decoding structure and AG on model performance
从表2 可见,TransUNet 的Dice 系数为0.765 3,mIoU 为0.885 9,召回率为0.825 0。Model1 与TransUNet 相比,性能有了一定的提升,Dice 系数、mIoU及召回率分别提升了0.75%、0.45%和2.34%。由此可见,本文设计的解码结构可有效地融合编码结构提取的特征,恢复图像大小。Model2 在Model1 的基础上Dice 系数提升较大,提升了1.5%,可知加入AG 后,增强了对显著特征的提取能力,分割性能得到了明显提升。
3.5.2 AG连接数量对模型性能的影响
为了进一步探究AG 在跳跃连接中的连接数量对模型性能的影响,在模型结构中的跳跃连接中使用不同数量的AG 进行实验,实验结果如表3 所示。其中,AG=0 表示在跳跃连接中不加入AG,即为上文中的Model1,AG=3 即为本文所提出的TransAGUNet 模型。从表3 可见,Dice 系数随跳跃连接中AG 数量的增加而增加,不加入AG 所得到的Dice 系数最小,在1∕2、1∕4、1∕8 分辨率尺度上的3 个跳跃连接中加入AG,所得的模型性能最优。

表3 AG连接数量对模型性能的影响Table 3 The Influence of the number of AG connections on the model performance
3.6 分割结果可视化对比
为了将本文模型与TransUNet 模型的分割结果进行更直观的展示与对比,在测试集上将两者的分割预测图均转化为灰度图,并选取部分数据,其结果同输入图像及标签的对比如图3所示。其中,第1幅测试图的分割部位为C1-C7 和T1-T2;第2 幅测试图的分割部位为T10-T12 和L1-L5;第3 幅测试图的分割部位为T2-T12和L1-L5。

图3 分割结果可视化对比图Fig.3 Comparative visualization of segmentation results((a)input images;(b)ground truth;(c)TransUNet;(d)ours)
从图3(c)中可见TransUNet 在第1 幅分割图中对脊椎分割细节上缺乏一定的敏感度,存在误分割现象,错将背景预测为颈椎椎骨;在第2 幅分割图中存在欠分割现象,未能完整分割出最后一节的腰椎椎骨结构;在第3 幅分割图上既错将背景预测为胸椎椎骨,又缺乏对腰椎的完整分割。图3(d)中即提出的模型中在跳跃连接加入了AG 结构后,加强了对椎体结构的识别能力,语义信息丢失问题也得到了改进,欠分割问题大大减少,分割结果更接近标签值,分割性能更好。
4 结论
本文结合Transformer、AG 和U-Net,提出一种CNN 与Transformer 混合分割模型TransAGUNet,实现对脊椎CT 图像的全自动分割。TransAGUNet 使用Transformer 和CNN 混合架构作为编码器,提取语义和远程上下文特征;使用CNN 结构作为解码器,在跳跃连接部分加入注意力门控机制AG,加强对显著目标区域的特征提取,抑制无关区域;使用Dice Loss与带权重的交叉熵之和作为损失函数以解决正负样本不均衡的问题。实验结果表明,本文模型与其余6 种对比网络模型包括CNN 分割模型及Transformer 与CNN 混合分割模型在脊椎CT 图像的自动分割任务上取得了最高的分割精度,同时表明在Transformer 与CNN 混合分割模型中加入注意力门控机制能有效地提高脊椎CT 图像的分割精度。本文算法对使用深度学习算法分割脊椎CT 图像的研究工作提供了重要参考,但仍存在分割细节不足的问题,如对于部分腰椎结构未能完整分割出来,模型设计仍有改进的地方,这也是今后要研究的重点。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
成都信息工程大学学报(2018年3期)2018-08-29
自动化学报(2018年7期)2018-08-20
华人时刊(2017年15期)2017-10-16
电子设计工程(2017年20期)2017-02-10
电子器件(2015年5期)2015-12-29
电测与仪表(2014年13期)2014-04-04
