
用于驾驶员分心行为识别的姿态引导实例感知学习
2023-11-22 01:19李少凡高尚兵张莹莹
中国图象图形学报 2023年11期
李少凡,高尚兵,张莹莹
1.淮阴工学院计算机与软件工程学院,淮安 223001;2.江苏省物联网移动互联技术工程实验室,淮安 223001
0 引言
分心驾驶是交通事故的主要原因,约有80%的交通事故都是由驾驶员分心造成的(Tian等,2013),因此对其进行针对性的分析对预防交通事故尤为重要。
基于静态图像和视频的动作识别一直是计算机视觉的经典问题,吸引了众多学者对其开展研究。然而由于车内狭小的环境和驾驶员分心时体态变化过于微小的问题,这些方法(Simonyan 和Zisserman,2014;Donahue 等,2015;Tran 等,2015)并不适用于驾驶员分心行为识别,另外构建通用的行为识别算法还具有很大难度。
分心驾驶检测就检测手段可分为以下3 类:基于生理数据的检测方法、基于车辆行驶状态的检测方法和基于计算机视觉的检测方法。基于生理数据的检测需要驾驶员佩戴特殊的生理设备,对驾驶员有入侵且成本高。利用车辆行驶时的参数(车速、方向盘转角和油门等)对驾驶员进行分心检测,这种方式由于个人驾驶习惯的差异,准确率难以保证。相较于前面两种方式,基于计算机视觉的方法仅需要一个摄像头就能对驾驶员行为进行检测,这种方法成本低、准确率高且对驾驶员无入侵。
El Khatib 等人(2020)将对驾驶员视觉分心进行检测的指标分为以下几个种类:驾驶员看向路中心的时间和频率(percent road center,PRC)、眨眼的频率、视线偏移的时间和驾驶员的头部姿态角度。
Li等人(2021)利用dlib检测出人脸的68个关键点后,通过计算人眼闭合的频率来判定驾驶员是否处于疲劳状态。Singh 等人(2021)利用深度神经网络对驾驶员头部进行姿态估计来预测驾驶员的注意力时长。潘剑凯等人(2021)建立驾驶员眼部的自商图与梯度图共生矩阵模型用以判定人眼的开闭状态,提升了面部遮挡情况下的疲劳驾驶检测准确率。LRD等人(2022)提出了一种基于视觉表观的视线估计MAGE-Net(more appearance gaze estimation network)来对驾驶员进行分心检测,MAGE-Net 仅用少量的参数就在MPIIGaze(max planck institut informatik gaze)数据集上取得了最好的性能。
目前基于计算机视觉图像分类对驾驶员进行分心行为识别的方法主要分为基于传统手工特征的方法和基于深度卷积神经网络(convolutional neural network,CNN)的方法。
1)在之前的研究中,传统手工特征通过许多方法对分心驾驶进行检测,Guo 和Lai(2014)利用颜色和形状信息对驾驶行为进行检测。Yan 等人(2014)联合运动历史图和金字塔式梯度方向直方图进行驾驶员的行为识别。Sharma 等人(2012)在多个尺度上进行密集的尺度不变特征变换(scale-invariant feature transform,SIFT)进行特征采样,模拟每个图像局域对于分类的贡献,然后采用支持向量机(support vector Machine,SVM)对带有权重的热力图进行分类。
2)深度卷积神经网络在各个领域均取得了巨大的成功,其中也包括驾驶员分心行为识别。Koesdwiady等人(2017)利 用VGGNet(Visual Geometry Group network)对驾驶员进行分心检测。蔡创新等人(2020)建立了一个安全可靠的距离模型来对可能发生的交通事故进行预警。汪长春等人(2022)提出一种轻量化的目标检测网络来对前方车辆进行精准的检测跟踪,根据自车和前车辆距离来对司机进行相应提示。Hu 等人(2019)则对神经网络进行迁移学习来改善分心驾驶行为识别的效果。Li 等人(2022)提出了一种结合Depth-wise 卷积和Point-wise卷积的轻量化网络OLCMNet(octave-like convolution mixed network)对驾驶员行为进行识别,在嵌入式设备Nvidia-TX2 上实现了实时检测。Tran 等人(2020)提出了一种基于双摄像头的驾驶员行为检测系统,使用来自双摄像头的数据进行融合效果要优于单摄像头数据输入的结果。Wu 等人(2021)利用人体姿态估计获取手部特征并与人体骨架数据进行多特征融合来对驾驶员进行行为识别。Abouelnaga 等人(2018)通过生成大量滑动窗口结合神经网络对手部和脸部进行检测,并将相应的脸部和手部图像送入神经网络中对驾驶行为进行识别。Eraqi 等人(2019)利用多元高斯朴素贝叶斯分类器对人体肤色进行分割并联合滑动窗口检测的手部区域特征组合成一个多融合的神经网络对分心行为进行识别。庄员和戚湧(2021)提出一种基于伪3D 卷积神经网络与注意力机制的驾驶疲劳检测方法,通过提升重要特征相关度,实现了复杂环境下的驾驶员疲劳检测。Behera 和Keidel(2018)利用姿态估计推理得到的身体部位置信图和部位向量场,并将这两部分特征直接拼接到DenseNet 的主干网络Conv3 层特征之后,利用拼接后特征对行为进行分类。
然而,以上方法大都集中利用图像层级的特征对驾驶员行为进行识别,环境噪声和视角多变的问题依然没有得到很好的解决。人体骨架数据广泛地运用于动作识别中,与传统的RGB 图像相比,人体骨架数据在面对复杂环境中的视角不一、光照变化和人体特征变化等问题有着较强的鲁棒性。驾驶员的手部相关区域对驾驶员分心行为识别有着较强的语义线索作用,能为当前行为识别任务提供更加细粒度的表征。如玩手机和喝水时,左右手区域的视觉特征和空间位置存在显著差异,在驾驶员行为识别属于辨识性的特征,因此对这种辨识性的特征进行针对性的分析是有必要的,而人体骨架恰好可以帮助进行更加准确的手部区域定位。以往的驾驶员行为识别也有通过目标检测或人体姿态算法对驾驶员身体部分进行解析(Wu 等,2021;Abouelnaga 等,2018;Eraqi 等,2019;Behera 和Keidel,2018)。Abo等人(2018)、Behera 和Keidel(2018)利用传统检测器检测身体部位,但是容易受到复杂场景干扰。Wu等人(2021)、Behera 和Keidel(2018)虽然利用人体姿态估计获取人体信息,但存在两点不足:其一,都是进行单一的特征提取,缺少对实例级别上下文特征的挖掘;其二,没有研究空间位置对驾驶员行为识别的线索作用。
因此,从实例级别特征出发,本文提出了一种姿态引导的实例感知学习网络进行行为识别,如图1所示。结合目标检测和人体姿态估计,去获取人体的多种实例信息,其中蓝色框代表全局信息、黄色框代表人体信息、绿色框代表手部信息、红色框代表手部空间信息。获取到手部相关特征和人体相关特征并构建相应的感知学习模块,同时利用提取到的左右手空间位置信息对驾驶员动作进行识别。

图1 实例特征的检测及推理Fig 1 Instance feature detection and inference
本文主要贡献为:1)利用人体骨架数据在不同环境下的强鲁棒性去引导网络学习关键特征。2)设计实例感知模块充分获取上下文语义信息。3)利用手部相关特征构建双通道交互模块来对关键空间信息进行表征,首次探索空间位置信息对驾驶员行为识别的线索作用。
1 姿态引导的实例感知学习网络
人体关键部位信息在驾驶员识别中扮演着重要角色,对人体和手部信息的准确定位显得至关重要。YOLO(you only look once)(Redmon 等,2016)是一种高效的单阶段目标检测算法。通过对目标直接进行分类和回归大幅提升了检测速度,在工业界应用广泛。HRNet(high-resolution network)(Sun 等,2019)是一种高分辨率人体姿态估计网络。和以往的姿态估计网络的串行结构不同,HRNet为并连结构,通过并行连接高分辨率到低分辨率特征图,可以一直保持高分辨率,并通过重复跨并行卷积执行多尺度融合来增强高分辨特征信息。HRNet是现阶段人体姿态估计领域的最优网络结构之一,兼顾了参数量和准确度。本文采用YOLOv5 对人体进行检测,然后采用HRNet进行姿态估计,获得驾驶员人体关键点。如图2 所示,通过检测到的人体框和关键点信息获得人体信息和手部信息,全局信息为整幅图像,人体信息为黄色框,手部信息为绿色框。利用人体信息和整幅图像的全局信息构建人体感知流,利用手部和人体区域组成手部感知流,将手部相关特征构建双通道交互模块组成空间流。以此组建成一个多分支的深度神经网络,使用全连接层得到各个类别的置信度得分后,再将不同分支的置信度得分进行融合得到最终的结果。
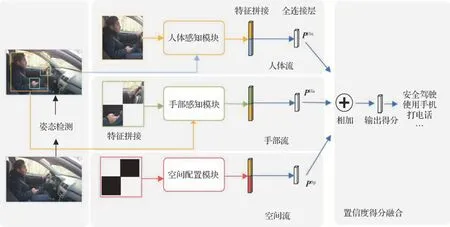
图2 姿态引导的实例感知学习网络结构Fig.2 Overall model architecture of the pose-guided instance-aware neural network
1.1 实例感知学习模块
为了获取不同实例特征间的依赖关系,提出了一种实例感知学习模块用来捕捉上下文语义信息。图3 为本文提出的实例感知模块结构中的手部感知流示例。以手部感知流为例,其中黄色检测框xh代表实例特征人的区域,绿色检测框xl,xr分别代表左右手的区域。
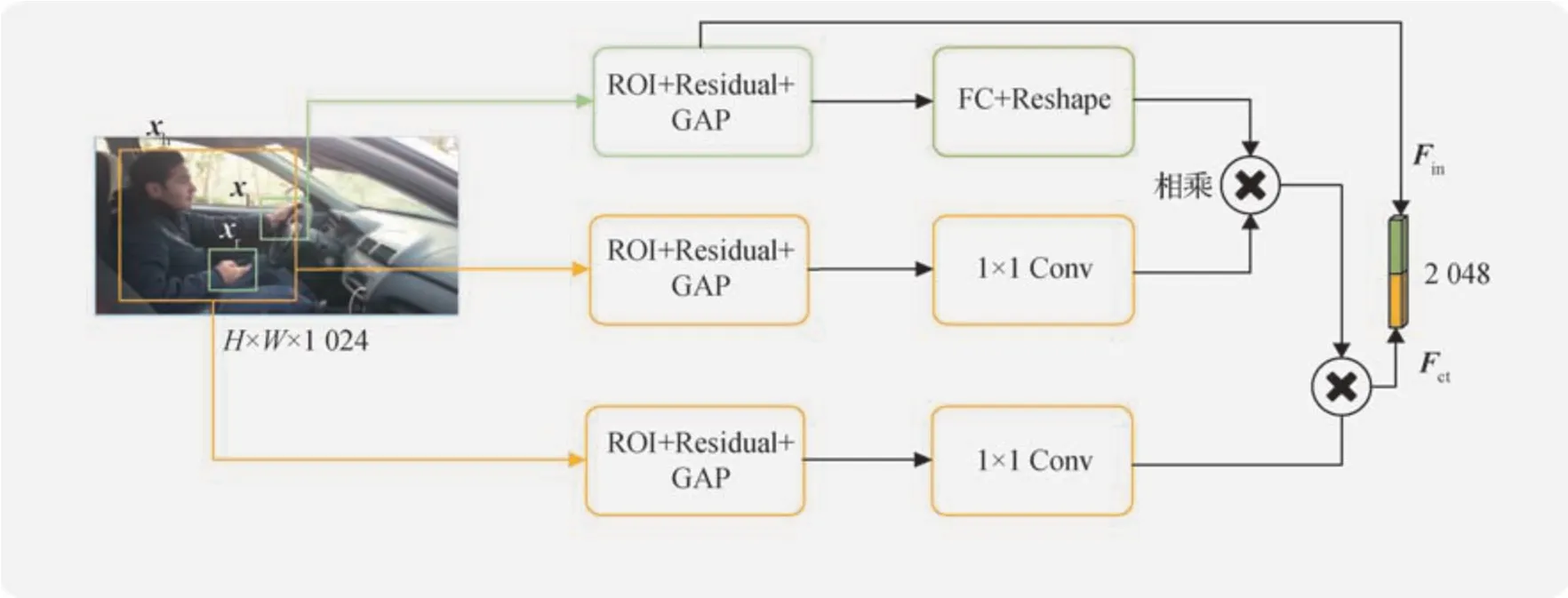
图3 实例感知模块Fig.3 Structure of the instance aware block
1)实例特征的提取。利用YOLOv5 对人体区域进行检测,并保留最大占比人体框xh作为驾驶员人体框。手部区域的特征能够为驾驶行为识别提供更加细粒度且更具辨识度的表征,然而手部区域的定位和获取却比较困难。为了解决这个问题,利用检测出的人体关节点获取手部区域。
手部区域的长宽Wh×Hh设定为人体关节点手腕至手肘的长度的1∕3。
式中,Cw和Cb代表手肘和手腕的坐标,Len为长度计算函数。得到人体和手部的实例特征的区域之后,利用区域坐标所勾勒出的感兴趣区域(region of interest,ROI)对实例特征区域进行池化操作获取视觉特征。具体运算是在ROI 后加入一个残差块(residual block,Res),之后进行全局平均池化(global average pooling,GAP)得到视觉特征向量。考虑到左右手对某些特定的动作存在的联合线索作用,对获取到的左右手特征图进行拼接得到手部特征。具体为
式中,F为图像经过主干网络ResNet50(residual neural network 50)的特征图,Res{}代表残差块,GAP为全局平均池化,⊕为特征值向量之间的拼接运算,Xl和Xr为左右手的视觉特征。Fin为实例对象特征,当特征分支为手部感知流时,即in 为ha 时,Fin为手部特征,当特征分支为人体感知流时,即in为hu时,Fin为人体特征。通过ROI+Residual+GAP 这个模块,有效避免梯度消失和爆炸的同时,又获取了比原先更加丰富的特征,得到了对行为识别更为关键的实例级别对象特征。对于部分手部无法检测的极端情况,将手部特征的所有通道值都设为0,这种不可见的手部特征对于像去后面拿东西这种行为能提供重要线索。
2)实例特征上下文感知学习。实例特征的上下文信息在行为识别中扮演着重要角色,周围的背景能够对驾驶员的行为检测起到一定的促进作用。为了能够让次级的实例特征对周围信息进行感知,这里通过对xh检测框的区域进行特征提取获得周围上下文信息Xh。为获得感知系数矩阵,将Fin和Xh都映射到相同维度的空间,通过向量点乘的方式计算特征间的自相关性,然后通过softmax 层获取相关度系数矩阵。具体为
式中,Xh为当前实例特征的上下文信息,W{}代表映射矩阵,Conv1×1代表卷积核大小为1 × 1 的卷积,⊙代表哈达玛积运算。将相关系数矩阵对应乘回上下文特征矩阵Xh,得到融合了实例特征语义信息的全局特征。具体为
式中,Fct为实例特征的全局特征,σ为sigmoid 激活函数,PHa当前手部感知流分支得分,PHu为当前人体感知流分支得分。
1.2 双通道空间交互模块
这个分支用来学习双手之间的空间特征,主要任务是利用双手的空间特征来辅助模型对驾驶员行为进行识别,并利用空间特征对视觉特征进行优化。
双手的空间特征为驾驶员行为分析提供了重要的线索,如正常驾驶和其他异常驾驶如玩手机、抽烟等行为,双手的位置有显著差异。以往的驾驶行为分析缺少研究空间位置对驾驶行为识别的线索作用,Chao 等人(2018)提出了一种双通道特征模块对人物的交互任务进行识别。本文将其构建思想引入到驾驶员行为识别任务中,作为空间特征构建部分。
1)空间注意力窗口定位。如图4 所示,通过姿态关节点得到两个xl,xr手部区域框之后,将两个区域包含的最小区域作为一个注意力窗口,并将注意力窗口以外的像素移除。

图4 空间特征构建图Fig.4 Structure of the spatial feature block
2)双通道空间特征图构建。为了能让神经网络学习到空间相关位置信息,将两个手部区域框转换成一个双通道的二值图像。其中第1 个通道除了左手部区域的值是0 之外,其他区域的值全是1,而第2个通道除了右手区域的值是1之外,其他区域的值全是0,将二值图重塑为64 × 64 像素并进行相应的补零操作,以此生成一个能够输入到深度神经网络中的双通道的二值空间配置图Bh,之后将Bh送入深度神经网络中获得空间特征,具体为
式中,αh为空间特征向量,代表两只手的空间配置信息。二值空间配置图Bh将两只手的区域定义在不同通道,因此可利用深度神经网络去学习两只手的空间关系。
3)视觉特征优化。αh在辅助进行预测的同时,利用空间特征对视觉特征进行优化。
以上将本文网络模型结构的两种分支类型的输出做出了阐述,分别是实例感知模块和双通道交互模块。最后将3 个分支的输出结合相加得出模型的预测结果。
式中,P则为模型最后的预测结果,长度为目标分类数。
1.3 损失函数
为了能够全面高效地学习实例级别的特征,本文构建了3 个分支的神经网络,包含人体分支、手部分支和空间分支。3 个分支均采用交叉熵损失函数进行损失计算。具体为
式中,LCe代表交叉熵损失函数,PHu,PHa和PSp分别为人体分支,手部分支和空间分支最后一层输出的概率分布,c为图像的真实标签值,LHa,LHu和LSp则代表各个分支的损失值。总的损失函数定义为
式中,LTo为3个分支损失的总和,在网络模型反向传播时一起对网络进行性能优化,最终收敛的模型充分考虑了实例对象的视觉和空间特征。
2 实验与分析
2.1 实验数据集
2.1.1 三客一危分心驾驶数据集
本文建立了一个三客一危分心驾驶数据集(three passengers and one dangerous chemical vehicle distracted driver dataset,TOV)。三客一危指的是客运车、校车、旅游车和危化品运输车这类大型车,这类车辆驾驶舱结构和小型车有明显差异,发生交通事故的后果相对比较严重。因此,对这类车型环境中的驾驶员分心行为进行针对性的分析是有必要的。数据来自交通监管平台所提供的车内监控视频数据,共780 段视频,634 GB,每段视频分辨率为1 280 × 720 像素,帧率为15 帧∕s。图5 为数据集中5 个动作里的一些样例图,分别是安全驾驶、左顾右盼、打电话、使用手机和抽烟。如图5 所示,车内的环境相对复杂多变,视频监控的摄像头安装的位置并不是固定的,而是安装在驾驶员不同的角度,这种多视角有效提升了数据的丰富程度,但同时也给检测带来挑战。首先人工将长监控视频中的带有分心行为的短视频剪切出来,然后将短分心行为视频截取成一帧帧的图像,选取其中有代表性的帧作为数据集。

图5 三客一危分心驾驶数据集样例图Fig.5 Examples of three passengers and one dangerous chemical vehicle distracted driver dataset((a)C0 safe driving;(b)C1 looking around;(c)C2 talking on the phone;(d)C3 playing the phone;(e)C4 smoking)
三客一危分心驾驶数据集总共包括31 694幅图像。其中26 095 幅作为训练集,8 699 幅作为测试集。表1为数据集的具体描述。

表1 三客一危驾驶数据集Table 1 Details of three passengers and one dangerous chemical vehicle distracted driver dataset
2.1.2 AUC分心驾驶数据集
Eraqi 等人(2019)发布了AUC 数据集。数据集由10个不同国家的志愿者完成,将AUC视频数据集随机分割为3∶1 比例的训练测试数据集。图6 是AUC 数据集10 个动作的样例图,分别为C0 安全驾驶、C1右手打字、C2右手打电话、C3左手打字、C4左手打电话、C5 调试收音机、C6 喝水、C7 拿东西、C8化妆和弄头发、C9 与乘客说话。数据集总共有图像17 308幅,其中12 977 幅用于训练,4 331 幅用于测试。

图6 AUC分心驾驶数据集样例图Fig.6 Examples of AUC distracted driver dataset((a)C0 safe driving;(b)C1 text right;(c)C2 talk right;(d)C3 text left;(e)C4 talk right;(f)C5 adjust radio;(g)C6 drink;(h)C7 reaching behind;(i)C8 hair and makeup;(j)C9 talk to passengers)
2.2 实现细节
采用了ResNet 50(He等,2016)作为主干特征提取网络,ResNet 网络采用在ImageNet(a large-scale hierarchical image database)(Deng 等,2009)数据集上训练过的权重作为预训练模型,模型输入的尺寸缩放到224 × 224 像素。网络训练采用交叉熵损失函数对网络模型的权重进行更新,损失函数的输入为各个分支的预测值和当前样本的标签值。初始化学习率初始设为1E-2,算法训练的批次大小为64,采用momentum 进行优化,同时将学习率衰减权重设置为0.000 5,训练的批次为50 个epoch。实验在Python3.8 和PyTorch1.8 的深度学习框架上进行,使用的操作系统为Centos8.0,GPU 是一块显存为16 GB的英伟达Tesla V100。
2.3 结果和分析
采用准确率(accuracy)、召回率(recall)和混淆矩阵等指标对分类性能进行评价。将本文方法在三客一危驾驶数据集的测试集上和一些常见的网络模型和方法进行比较,同时在公开数据集AUC 上和其他方法进行了比较。表2为本文方法和ResNet50在三客一危数据集上的结果,可以看出本文方法在各类别上的召回率和总体准确率最高,其中整体准确率高出ResNet50 网络模型7.5%,各个类别的召回率均得到提升,C0 正常驾驶和C4 抽烟的召回率分别提高了13%和15%。正常驾驶时两只手的位置很靠近,并且手握方向盘手势相似且相关区域背景都是方向盘,本文方法能够有效学习到两只手的相对空间位置和视觉特征,因而召回率得到了提升。在抽烟场景中烟属于很小的物体,在神经网络中非常容易被忽略掉,但本文方法利用姿态去引导网络注重学习这部分特征,并对吸烟时显著的双手区域的空间特征进行学习,有效提升了这方面的召回率。由结果可以看出本文方法在各类别上的召回率和准确率均表现优异。
表3 为本文方法和其他模型的参数量和计算量的比较,可以发现,本文方法虽相较于ResNet50网络模型参数量和计算量有所增加,但是各类的准确率提升明显。相较于DenseNet(densely connected con-volutional networks)和Fusion方法具有显著的优势。
为了进一步验证本文方法的有效性,在公开数据集AUC 上进行了性能测试,与I3D-two stream(Moslemi 等,2019)、Fusion(Alotaibi 和Alotaibi,2020)、AlexNet+HOGfeatures(Arefin 等,2019)、DenseNet+LatentPose(Behera 和Keidel,2018)、GAWeighted Ensemble(Abouelnaga 等,2018)和OWIPA(Koay 等,2021)算法进行了比较。实验结果如表4所示,本文方法取得了96.17%的准确率,算法的准确率优于其他方法。
图7 和图8 分别为本文方法在AUC 数据集和自建三客一危数据集上的测试混淆矩阵,其中,行代表真实类别,列代表预测的类别。矩阵每个方格中的数值分别代表预测类别的样本数量和所占比重。

图7 AUC数据集测试混淆矩阵Fig.7 Confusion matrix of AUC driver dataset

图8 三客一危驾驶数据集混淆矩阵Fig.8 Confusion matrix of three passengers and one dangerous chemical vehicle distracted driver dataset
混淆矩阵中,对角线上的数值即为预测正确的结果,而其他数值则为预测错误的结果。在AUC 数据集中,计算得知,本文方法整体的准确率和召回率均为96.17%,然而,图7 中C7 类别代表的去后面拿东西行为的召回率仅有93.69%,这是由于当驾驶员拿到东西的时候,一只手离开画面,导致模型无法定位到那只离开画面的手,因次也就无法获取手部的空间特征和视觉特征,从而无法捕捉手部之间的微小差异。C9 类别所代表的和乘客说话行为的召回率仅为95.33%,有23 个样本被错误预测为安全驾驶。这是因为C9 驾驶员和乘客说话行为与C0 正常驾驶行为时两者手部差异不明显,模型会产生部分误判。在三客一危驾驶数据集上,整体准确率为96.97%,然而C1 类别所代表的左顾右盼行为较低,仅为89.91%,其中8.3%的样本75 幅图像被误判为C0 类别正常驾驶行为,有2.6%的样本67 幅正常驾驶行为被错误预测为左顾右盼行为,这是由于左顾右盼这种状态下驾驶员的体态变化比较微小,多数通过脸部变化才能区分,易与正常驾驶混淆,因此模型难以区分正常驾驶行为和左顾右盼行为。
为了直观分析3 个分支对应loss 使用不同权重时对识别结果的影响,对空间分支、人体分支和手部分支的loss 分别设置α、β和γ这3 个权重系数,并对设置不同的权重系数的模型进行实验来观察对识别结果的影响。其中当一个权重系数发生变化时,其余权重系数固定为1,实验结果如图9所示。
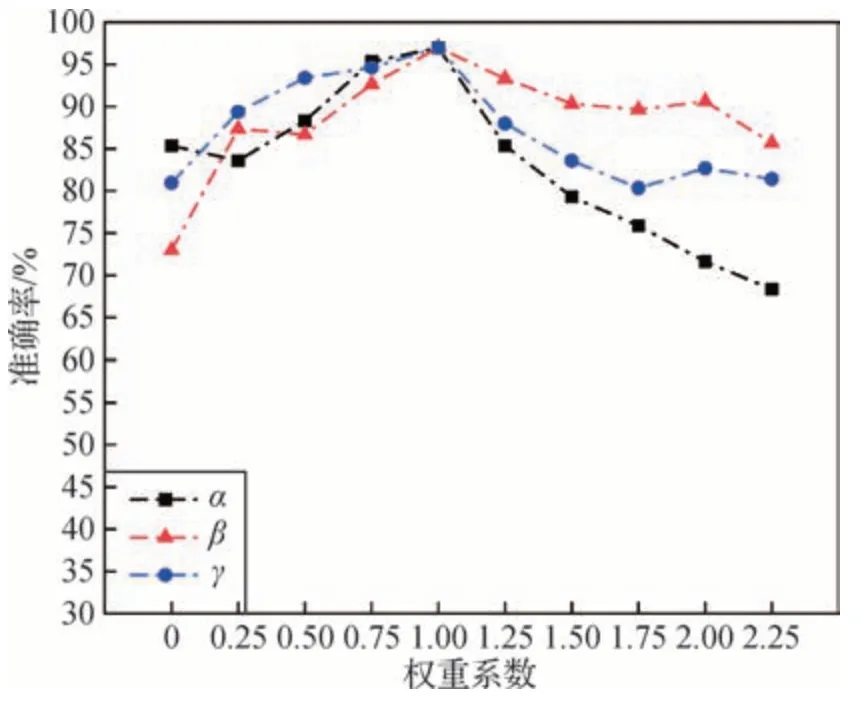
图9 测试集准确率变化曲线Fig.9 Test set accuracy change curve
由图9可以看出,当各个单独分支所占的loss函数权重系数增长到1 时,模型准确率达到最高,而当单独分支的权重系数继续增大时,准确率开始逐渐下降,这是因为随着其中一个单分支的权重系数逐渐增大,它就逐步成为主导模型更新的loss 函数,这就会抑制其他分支的loss 函数对模型参数更新的影响,导致准确率持续走低。由实验曲线看出,当权重系数为2.25 时,β权重系数所代表的人体分支占主导的模型准确率为85%以上,高于α权重系数所代表的空间分支占主导的模型准确率68%。因为人体分支占主导能够给模型提供足够的视觉特征,因而能够获得较高的准确率,而仅空间信息来指导网络模型进行参数更新不够全面,因此准确率偏低。
2.4 消融实验
为了验证本文方法各个组件的有效性,本文对各个分支进行了相应的消融实验。实验结果如表5所示,其中,Human 代表人体感应分支,Hand 代表手部感应分支,Spatial 代表双通道空间交互分支。所采用的基准网络模型均为ResNet50 网络,对应每个数据集实验的第1行。
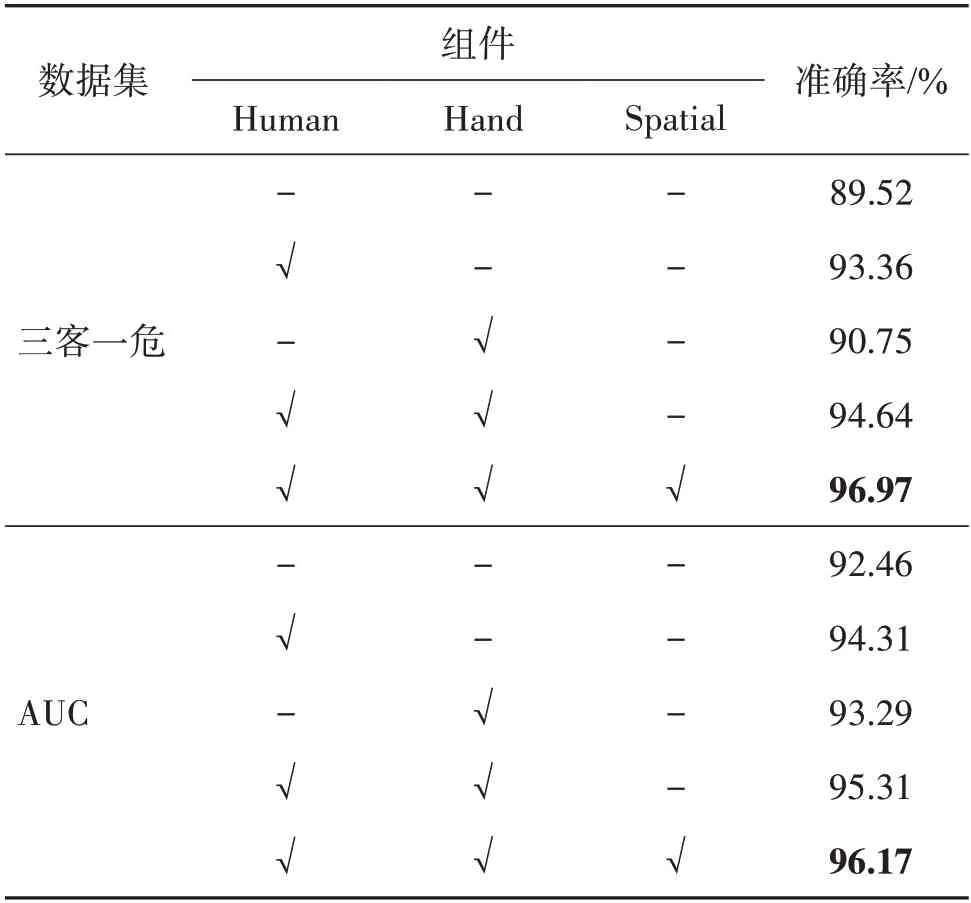
表5 消融实验Table 5 Ablation study
由表5 中可知,本文方法在单独引入人体分支时,准确度提高了3%,这说明基于目标检测的人体分支抑制了部分背景噪声,而当单独使用手部分支时,准确度有所下降,这是因为单手部特征对于模型分类还是不够充分,随着人体分支、手部分支、空间分支都引入到多流网络中时,准确率达到最高。由结果可以看出,在自建的三客一危数据集上,提升较为显著,而在公开数据集上提升却不是特别大,这是由于自建数据集存在的视角多变、环境杂乱、体态多样的问题。而姿态引导的实例感知学习网络能有效减少这些外部因素的干扰,让模型集中去学习那些有益的特征。
消融实验的结果表明本文方法所提出组件可以有效改善驾驶员行为识别的结果,当结合人体分支、手部分支和空间分支时,准确率达到最高。在自建大型车驾驶员数据集上提高了7.5%的准确度,在公开数据集上也提升了3%以上。由实验结果可以看出,本文提出的结合人体检测和姿态估计的驾驶员行为识别方法在复杂环境和视角多变的驾驶环境下有更好的表现。
3 结论
针对驾驶员行为识别类间差异小的问题,本文提出了一种姿态引导的实例感知学习网络用于驾驶员行为识别。结合目标检测和人体姿态估计获取人体和手部区域作为实例级别的特征并设计感知学习模块,利用手部相关区域构建双通道交互模块来对关键空间信息进行表征。通过构建实例级别的特征感知学习到不同驾驶行为之间微小的表征差异,实现了复杂环境下的驾驶员行为检测。
对比实验结果表明,本文方法在自建复杂环境数据集上和公开数据集上的准确率均优于其他模型。相较于传统的基于RGB模型、人体骨架引导的方法在复杂环境数据集下效果提升明显,有效降低了背景杂乱、视角不一、光照和驾驶员体态变化所带来的影响。消融实验表明,本文提出的双通道交互模块能够提升模型的准确率,从侧面证明了驾驶员双手的空间位置对于识别驾驶员行为有着重要的线索作用。
但是,由于定位这些实例级别的特征区域需要进行目标检测和姿态估计,前置的检测会消耗一定的时间,这往往会降低本方法的实用性。因此,下一步工作就是针对这一问题,提高辨识速度。未来将着重从这方面入手,采用弱监督的学习方法来对实例特征进行检测定位,辅助网络进行驾驶员行为识别,改善辨识速度慢的问题,提高方法的实用性。
猜你喜欢
实用手外科杂志(2022年2期)2022-08-31
学生天地(2019年28期)2019-08-25
数学物理学报(2018年1期)2018-03-26
实用手外科杂志(2015年4期)2015-08-27
中华皮肤科杂志(2014年4期)2014-12-19
中国药业(2014年21期)2014-05-26
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
山西大同大学学报(自然科学版)(2014年3期)2014-01-23
疯狂英语·口语版(2013年1期)2013-01-31
