
伪激光点云增强的道路场景三维目标检测
2023-11-22 01:19晋帅李煊鹏杨凤张为公
中国图象图形学报 2023年11期
晋帅,李煊鹏,杨凤,张为公
东南大学仪器科学与工程学院,南京 210096
0 引言
目标检测是计算机视觉中的基础任务,利用图像或激光雷达点云进行目标定位及分类。目前,以Faster R-CNN(fast region-based convolutional neural network)(Ren 等,2017)及YOLO(you only look once)(Redmon 等,2016)系列为代表的二维目标检测算法日趋成熟。近年来,自动驾驶从概念设计阶段向实际应用阶段迈进,二维目标检测缺乏目标准确的三维空间信息,无法为车辆规划和控制系统提供足够的感知信息。三维目标检测不仅包含目标的类别信息,还包含目标的朝向、尺寸及位置信息,成为当下研究热点。
自动驾驶中的传感器包括单目相机、双目相机、激光雷达、毫米波雷达和超声波雷达等。其中激光雷达作为最常用的传感器之一,有较强的结构感知能力,不易受天气及光照影响,其点云提供精确的目标距离信息,并且表征形式简单。点云也有其缺点:1)存在数据稀疏性问题,随着距离增加,目标几何信息衰减严重;2)对于点云呈现相似的目标容易误检;3)多数目标检测网络需要对点云进行数据预处理工作,例如体素化等,增加了算法复杂度。
图像信息作为另一类常用数据形式,研究深入且使用广泛。图像具有丰富的色彩与纹理,信息密度高,利用图像进行二维目标检测的技术更为成熟。在三维目标检测领域,基于图像的方法仍与基于激光雷达点云的方法在三维目标检测性能上存在较大差距,主要原因在于图像本身无法提供深度信息,相邻像素可能在3D空间中有显著深度差,在三维位置回归任务和鸟瞰图预测任务中准确性较低。
在真实的自动驾驶场景中,道路环境复杂多变,无法依赖单一传感器。自动驾驶汽车往往配备多种传感器,通过多源数据融合,提升感知能力。如何利用图像的丰富纹理信息以及激光雷达点云的精确几何信息进行有效融合成为研究重点。激光雷达点云的主要问题在于随着目标距离激光雷达的距离增大,目标反馈点云区域稀疏,有效信息大大减少。例如,在KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago)数据集(Geiger 等,2012)中,车辆目标中心点的空间分布如图1(a)所示,激光雷达点云的数量分布如图1(b)所示。两者分布极为不符,对于20 m以外的路段,点云数量占比远远小于车辆数量占比,这说明远处的点云目标存在稀疏性的问题。因此,本文尝试从增强点云目标稠密度的角度,对小目标检测能力进行提升。
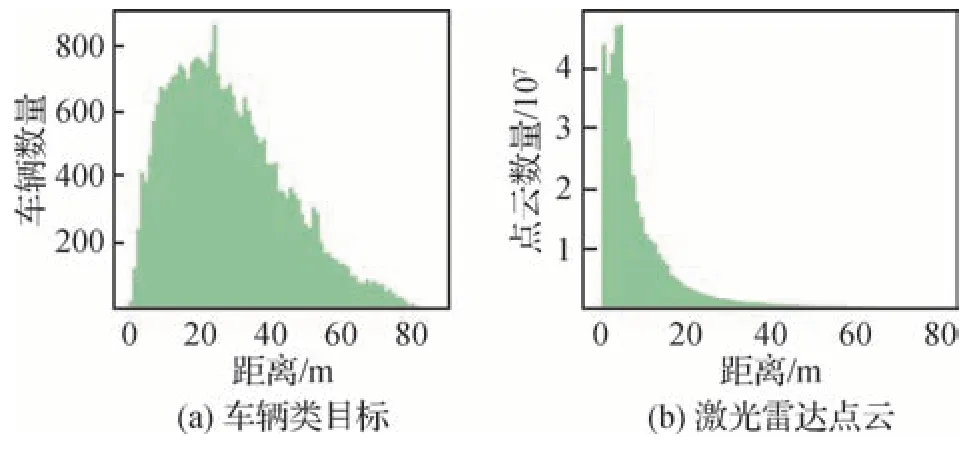
图1 车辆及激光雷达点云区间分布图Fig.1 Distribution map of vehicle and LiDAR point cloud intervals((a)vehicle class object;(b)LiDAR point cloud)
点云补全是一种提升点云稠密度的方法,由部分点云生成完整点云。使用人工合成数据集进行训练,如ShapeNet(Wu等,2015),通过在计算机辅助设计(computer-aided design,CAD)模型表面均匀采样若干点云形成真值。KITTI 这类自然采集的道路场景数据集缺乏稠密点云作为真值,点云补全算法无法大规模训练预测,因此使用点云补全提升稀疏点云的数量不可行。
受伪激光雷达算法将图像映射到三维空间形成伪激光点云的启发,本文通过双目图像数据提取深度信息,利用原始点云对图像深度图进行深度校正,减少深度误差。为了减少背景伪激光点云的影响,使用语义分割网络获取图像的前景区域,仅将前景区域对应的校正深度图映射到三维空间中生成伪激光点云(下文简称伪点云),根据不同的观测距离,对伪点云采取不同的采样策略,距离越远采样线数越高。将采样后的伪点云与原始激光点云进行融合,使用基于激光点云的检测器进行三维目标检测。
本文具有如下贡献:
1)提出一种伪激光点云增强技术,利用点云精确的深度信息对图像深度图进行校正,利用图像稠密的像素信息对点云的稀疏性进行补偿,挖掘并结合两者优势,有效改善了点云稀疏性带来的小目标检测精度低的问题。
2)采用语义分割模块,在不引入背景点的前提下极大增加了前景点数量比重;采用采样模块,针对点云稀疏性的特征,按照观测距离补偿不同线数的伪点云,大幅降低伪点云数量,提升了网络模型的检测性能。
3)本文方法适用于所有基于点云的三维目标检测网络。通过使用KITTI 数据集评估,实验结果表明,本文算法实现了对多个最新网络框架在三维目标检测及鸟瞰图检测精度上的提升,其中对小目标的3D检测性能提升尤为显著。
1 相关工作
三维目标检测算法有两种划分标准。一种分为基于区域提议的方法和一阶段方法(Guo 等,2021);另一种分为单模态算法和多模态算法(Qian 等,2022)。本文按照数据来源的划分标准进行区分,即单模态算法与多模态算法。单模态算法数据来源单一,主要分为基于图像和基于点云的三维目标检测算法;多模态算法通常利用图像与激光点云数据融合作为输入。
1.1 基于图像的三维目标检测
基于图像的三维目标检测与二维目标检测思想一致,以图像为输入进行目标检测,按照数据来源分为基于单目视觉与双目视觉的目标检测方法(曹家乐 等,2022)。Chen等人(2016)以单目图像为输入,采用滑动窗口直接从三维空间中采样前景对象。Mousavian 等人(2017)利用神经网络和2D 物体检测框的几何约束,回归3D 物体检测框。Liu 等人(2020)认为2D 检测会引入噪声影响3D 检测,删除了2D 候选区域的生成。Stereo R-CNN(Li 等,2019)同时检测双目图像的目标并关联,额外增加预测稀疏关键点和对象尺寸的分支。戴坤等人(2022)设计了融合策略选择方法,结合特征金字塔及双注意力机制提升模型对空间信息和通道特征的敏感性。
受基于点云的三维目标检测算法大获成功的启发,Pseudo-LiDAR(Wang 等,2019)利用深度估计网络从图像获取深度图像,将原图像结合深度信息得到伪激光点云,采用激光雷达检测框架进行检测。Pseudo-LiDAR++(You 等,2020)对双目图像的深度估计进行改进,调整了网络结构和损失函数,使伪激光点云更精确地分布。
在基于图像的三维目标检测算法中,图像的特点在于信息稠密,拥有丰富的色彩信息与纹理信息,能够较精确地检测出远处的小物体。此外,相机的成本较低。但以上这些方法仅利用图像的颜色属性和纹理信息,结合先验知识来设计网络模型,达到检测性能的提高。图像缺乏深度信息,在三维空间中的定位准确性不高。因此获得准确的深度估计是目前研究中的难点,也是提高检测精度的关键。
1.2 基于点云的三维目标检测
点云数据存在不规则性,一种方法是将点云转换为规则排列的体素数据。VoxelNet(Zhou 和Tuzel,2018)将点云划分为一定数量的体素,对非空体素进行特征提取,经过3D卷积层学习更深层次的特 征。SECOND(sparsely embedded convolutional detection)(Yan 等,2018)引入了稀疏3D 卷积代替VoxelNet 中的3D 卷积层,降低了内存使用,提高了检测速度。PointPillars(Lang 等,2019)将点云转化为一个个柱体,随后转化为伪图像,采取二维卷积网络提取特征,该方法的检测速度达到62 Hz。CIASSD(confident IoU-aware single-stage object detector)(Zheng 等,2021)通过预测交并比(intersection over union,IoU),对分类得分进行校正,从而缓解分类置信度和定位精度之间不对齐的问题。基于体素的方法计算较为高效,但是体素的离散化过程会导致点云一定的信息量化损失,划分的体素过小会导致计算量的三次方增加。
随着研究的推进,学术界愈发重视点云数据本身的特性,如无序性、稀疏性和分布不均等。Point-Net(Charles 等,2017)不对点云数据进行预处理,直接从点云中学习点的特征。针对点云的置换不变性,采用最大池化对称函数提取点云数据的特征。进阶版网络PointNet++(Qi等,2017)针对PointNet局部特征使用不足的问题,提出多层次特征提取结构。PointRCNN(Shi 等,2019)是使用原始点云的两阶段目标检测方法。第1 阶段对点云语义分割,为前景点生成包围框;第2 阶段进行微调及多任务回归。Yang 等人(2020)针对PointRCNN 速度较慢的问题,删除了特征传播层及第2 阶段微调过程,重新设计了集合抽象层和点云采样策略。SASA(semanticsaugmented set abstraction)(Chen 等,2022)网络进行了前景点与背景点的分割。使用多层感知机(multilayer perception,MLP)对点特征进行编码,赋予前景点较大的分数,使用该分数去加权最远点采样的距离信息,使得前景点分离出来。IA-SSD(instanceaware single stage detection)(Zhang 等,2022)设计了可学习的、实例感知的下采样策略来分层次地选择目标前景点。
点云和体素的方法各有优点,Shi等人(2020)将基于体素方法的卷积高效和基于点方法的感受野可变两种优势结合,He 等人(2020)提出结构感知单阶段3D 目标检测器,除基于体素的骨干网络外,还添加了一条基于点级别监督的辅助网络,引导骨干网络学习更好的特征。
基于点云的方法检测精度最高,但是以上方法普遍存在算法复杂、处理速度较慢的问题;基于体素的方法往往计算效率较高,但是不可避免地存在量化损失。基于原始点云的方法不需要进行体素化等数据预处理流程,但是算法耗时更高;基于体素点云融合的方法通常具备较高的检测精度,但是存在算法复杂、模型庞大等问题。
1.3 基于融合方法的三维目标检测
基于图像和激光雷达点云融合主要分为两类方法,一类是采取串行的方式,后一阶段的特征提取依赖于前一阶段。例如Qi 等人(2018),通过成熟的二维目标检测器在图像上定位前景区域,随后延伸到空间中形成三维边界视椎体,在此区域内进行三维目标检测。Wang 和Jia(2019)在图像前景区域生成一系列视椎体,利用PointNet(Charles 等,2017)网络对每个视椎体的逐点特征聚合为视锥特征向量。Vora等人(2020)将激光点云映射到语义分割后的图像中,把每一类别的语义分割分类分数添加到对应位置点云上,对点云进行特征增维操作。
另一类方法采取并行的方式,在特征空间中融合 多模态。MV3D(multi-view 3D networks)(Chen等,2017)将点云鸟瞰图、前视图和图像的特征进行融合。AVOD(aggregate view object detection)(Ku等,2018)在MV3D 的基础上,将底层数据信息和高层语义信息结合,提高了小目标的检测精度。EPNet(Huang 等,2020)使用语义特征图增强点云特征,将原始点云与图像逐点建立了映射关系。3DCVF(3D-cross view fusion)(Yoo 等,2020)设计了自动校准投影算法,将图像特征与点云鸟瞰图特征保持最高一致性。严娟等人(2020)提出一种结合混合域注意力与空洞卷积的检测方法,引入空间域注意力突出图像区域特征,引入通道域注意力提取关键通道特征,结合空洞卷积与注意力机制,扩大感受野并获得全局感受野的关键特征。
以上的方法存在一定的局限性,串行融合方式中三维目标检测性能过度依赖前一阶段的二维目标检测,并行方式中在特征空间中融合多模态的方式则会弱化点云数据与图像数据本身具有的特征。本文注重数据的预处理,图像数据与点云数据应相辅相成,利用点云精确的深度信息对图像生成的深度图进行校正,利用图像稠密的像素信息对点云的稀疏性进行补偿,实现图像点云数据的有效融合。
2 模型方法
2.1 整体框架
本文方法整体流程如图2 所示。将双目图像作为深度估计网络的输入,预测深度图像。将激光雷达点云投影至平面获得点云深度图,与图像的深度图一同送入深度校正模块,生成校正后的深度图像。对图像应用语义分割网络,获得车辆的前景区域,将语义分割图与校正深度图一同经过前景分割模块的处理,前景区域对应的深度图映射到三维空间中生成伪点云,仅保留车辆前景点,称此时的点云为前景伪点云。最后前景伪点云在0~20 m、20~40 m、40~80 m 的区间内分别执行16、32、64线的下采样,与原始点云融合,形成融合点云。此时的融合点云比原始点云具有更多前景点,对于远处的目标,点云数量大幅增加,改善了小目标点云的稀疏性,有利于网络对目标的回归。最后使用基于点云的目标检测网络对目标进行分类、回归的多任务学习。

图2 网络整体流程图Fig.2 The whole pipeline of our proposed network
2.2 子模块介绍
本文方法依据功能分为5 个子模块:深度估计网络、深度校正模块、语义分割网络、前景分割模块和采样模块。
2.2.1 深度估计网络
深度估计算法主要分为单目深度估计,如DORN(deep ordinal regression network)算法(Fu 等,2018);或双目深度估计,如PSMNet(pyramid stereo matching network)算法(Chang 和Chen,2018)。本文采用精度较高的PSMNet 算法作为深度估计网络。双目深度估计算法的主要原理为,使用基线距离为b的一对相机,以左右相机图像为输入,使用深度估计网络PSMNet生成视差图D。深度图Z的计算为
式中,Z(u,v)和D(u,v)分别代表在左图像坐标系下像素(u,v)的深度和视差,u和v表示每个像素在图像坐标系的位置信息,fU为左相机的水平焦距。
PSMNet网络具体流程如下:
1)将左右相机的图像输入到权值共享的卷积神经网络中进行初步特征提取。
2)采用空间金字塔池化(space pyramid pooling,SPP)结构提取像素点多尺度邻域信息,SPP 模块分别采用64 × 64、32 × 32、16 × 16 和8 × 8 这4 个尺度的平均池化,生成左右图像特征图,兼顾全局特征与局部特征的提取。
3)通过左右图像的特征图生成4 维向量的代价容量(cost volume)。
4)通过多层三维卷积对4 维向量的cost volume中的信息进行进一步融合和提取,得到三维的cost volume,随后进行视差回归得到深度图。
2.2.2 深度校正模块
由于深度估计的误差随着深度的增加呈二次增长,目标距离越远,误差越大。虽然深度估计误差可以随着图像分辨率的增加而得到缓解,但过高的图像分辨率会急速增加计算成本。本检测方法是基于图像与点云融合的方法,使用具备精确深度的点云数据,可对深度图的误差进行校正。图3 为校正前后的深度图。

图3 校正前后的深度图Fig.3 Depth maps before and after correction((a)before correction;(b)after correction)
深度校正模块的主要原理是,将激光雷达点投影到深度图中,点云所对应的部分像素具有精确深度,这部分像素可以称为地标像素,地标像素反投影得到的伪点云称为地标伪点云。校正后的深度图具备以下特性:在全局上,与激光点云对应的地标像素具有精确深度;在局部上,应保留从深度图反向投影的伪点云的形状结构。
将激光雷达点云表示为L,其投影的激光点云深度图表示为G。图像深度图表示为Z,其反投影的伪点云表示为PL。伪点云通过将深度为z的像素坐标(u,v)转换为3D 点(x,y,z)来获得。本模块以激光雷达点云L和伪点云PL为输入,具体流程如下:
算法1:GDC(graph-based depth correction)算法(You等,2020)
输入:深度图Z∈Rn+m,其对应的伪点云PL∈R(n+m×3),原始点云深度图G∈Rn。
输出:校正后的深度图Z′ ∈Rn+m。
1)输入匹配。在伪点云之间建立有向K最近邻(K-nearest neighbor,KNN)图表征局部形状,该图以适当的权重将每个3D 点连接到其KNN。假设激光点云数量为n,深度图像素数量为n+m,则地标像素数量为n,伪点云总数为n+m。地标伪点云个数为n,剩余m个伪点云没有匹配。将图像深度图表示为Z∈ Rn+m,激光雷达点云深度图表示为G∈ Rn。
2)构造权重。为伪点云的KNN 图构造权重,忽略n个地标伪点云的精确深度信息,使用它们的预测深度。令Ni表示第i个点的k个邻域点,权重矩阵表示为W∈ R(n+m)×(n+m),其中,Wij表示点i和点j之间的边权重。选择权重作为重建Ni其余点深度的系数,使用最小二乘法计算这些权重。
3)深度校正。校正后的深度图表示为Z′∈Rn+m,也可表示为Z′=[Z′L;Z′PL],Z′L∈ Rn,Z′PL∈ Rm。将n个地标伪点云的深度更新为Z′L=G,依据给定的G和权重矩阵W使用稀疏矩阵求解Z′PL,使用权重重建其余的点。具体来说,更新剩余点的深度Z′PL,使得任何点的深度仍然可以使用权重W重建为其KNN 深度的加权和。例如,对于某个地标伪点云i,当它的深度被校正为Gi后,那么它在Ni中的邻点也必须被校正,使得此外,继续纠正邻点的邻点,最终少数n个点的深度在整个图中传播。
2.2.3 语义分割网络
本文使用语义分割网络获取图像的前景区域,语义分割也称像素级分类问题,网络的输入图像与输出图像的分辨率相同。本文采用HRNet(Wang等,2021)作为语义分割网络。
HRNet 网络的输入为已经下采样4 倍的特征图,网络主要分为4个阶段与1个回归头。每个阶段相比于前一个阶段,扩充一个分支,该分支的输出特征降采样2倍,通道数扩充2倍。HRNet将多个分辨率的特征图并联,并设计了交互模块以实现不同分辨率的特征图之间的信息交互,其详细结构如图4所示:同分辨率的特征图保留不做计算;需要增加分辨率的特征图使用双线性插值上采样,使用1 × 1 卷积将通道数统一;需要降低分辨率的特征图使用步长为2的3 × 3卷积,最后将多个特征图相加。

图4 HRNet的交换单元Fig.4 The switching unit of HRNet
回归头部分将所有分辨率的特征图统一为同一分辨率并融合,分辨率低的特征图进行上采样。
2.2.4 前景分割模块
图像的像素信息更加丰富,图像转换成的伪点云与原始点云相比,拥有更多的点数据。经统计,生成的伪点云数据约为原始点云数据的4 倍左右。如图5(a)(b)所 示,伪点云的点数量远多于原始点云。

图5 激光雷达点云、伪点云和前景伪点云Fig.5 LiDAR point cloud,pseudo-LiDAR point cloud and foreground pseudo-LiDAR point cloud((a)LiDAR point cloud;(b)pseudo-LiDAR point cloud;(c)foreground pseudo-LiDAR point cloud)
本文目标在于使用图像生成的伪点云来改善小目标点云的稀疏性,此外,深度估计并非完全准确,存在一定的误差,因此转换而来的伪点云也存在一定的误差,且随着距离的增长误差逐渐变大。本文考虑仅保留伪点云中的前景点,即落在车辆上的点,剔除背景点,如图5(c)所示。
本文设计了前景分割模块,如图6 所示,通过语义分割网络,得出图像中的前景部分,即图中的绿色部分,在生成伪点云的过程中,仅将深度图对应的前景区域转换为伪点云。

图6 前景分割模块效果图Fig.6 Illustration of foreground segmentation module
深度图的像素坐标(u,v)与伪点云坐标(x,y,z)的对应关系为
式中,u和v代表深度图每个像素在图像坐标系的位置信息,R代表深度图对应的语义分割图中的前景区域,z表示每个像素对应的深度信息,cU和cV代表焦点在图像坐标系的坐标,fU和fV表示相机在x和y方向的焦距。
本文以深度为桥梁构建起图像坐标与三维坐标之间的关系。对伪点云高于激光雷达1 m 的数据进行了剔除,将所有伪点云数据的反射率设为1。
2.2.5 采样模块
过度稠密的伪点云信息有时会降低系统性能。前文已分析了激光雷达点云在距离较近的区域内,点云数量十分庞大,随着距离的增加,点云数量急剧减少。可以考虑减少对于距离较近的点云的补充,对距离较远、较稀疏的点云给予更强的补充。
本文方法对伪点云降采样,降低伪点云稠密度。首先限定可采样伪点云的几何空间,在竖直方向,常见64 线激光雷达发出的64 条光束分布于激光雷达所在水平面-24.8°~2.0°的区间内,本文方法模拟激光雷达,将可采样伪点云的俯仰角限制于此区间,但不考虑-23.6°~-24.8°的区域,合计范围25.6°。在水平方向,将偏航角范围限制在水平面内激光雷达x方向左右各偏45°的区间内,合计范围90°。
假设伪点云下采样线数为H,每一线伪点云数量为W。将俯仰角划分为H份,对H份区间赋予下标,表示为[0,1,2,…,H-1],每一份度数为dθ。将偏航角划分为W份,对W份区间赋予下标,表示为[0,1,2,…,W-1],每一份度数为dψ。具体为
设某一点数据坐标为(x,y,z),该点为第R线的第C个点。若计算出的R <0,则将其置为0;若R>H-1,则将其置为H-1,C同理。若有多个点计算结果相同,则保留最后一个点的数据作为采样点数据。具体为
式中,ψ和θ分别为当前点的偏航角度与俯仰角度。
在激光雷达坐标系下,对x方向的0~20 m、20~40 m、40~80 m 的区间内分别将伪点云下采样到16、32、64 线,设每一线伪点云的个数为1 024。图7 为未采样和车辆伪点云分别采样至64、32、16 线的效果图。为增强可视化,伪点云被绘制为球体。
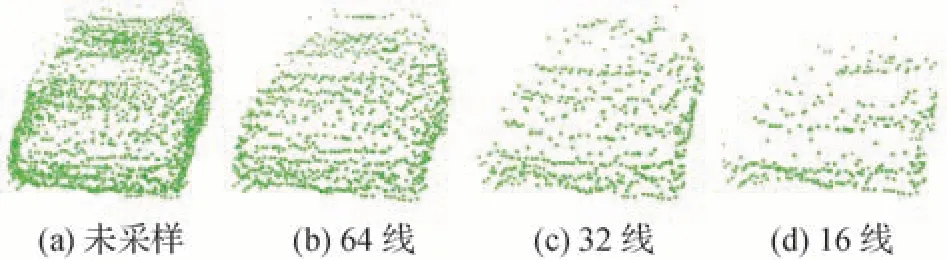
图7 车辆伪点云不同采样线数示意图Fig.7 Schematic diagram of different sampling lines of vehicle pseudo-LiDAR point cloud((a)not sampled;(b)64 lines;(c)32 lines;(d)16 lines)
将激光雷达点云与采样后的前景点云融合,即可得到融合点云。融合点云如图8 所示,红色为原始点云,绿色为前景伪点云。在原始点云的基础上,伪点云大大增加了场景中前景点云的数量。

图8 融合点云Fig.8 Fused point cloud
3 实验
点云补全作为一种稠密化点云的方法,与本算法的功能类似。为突出本文算法的创新性,设计了本文算法与点云补全方法的目标检测对比实验,并对实验结果进行了可视化及讨论分析。
为验证算法的有效性,在KITTI 数据集上进行实验验证,检测目标为车辆。对SECOND(Yan 等,2018)等5 种三维目标检测模型进行训练与验证。使用交并比为0.7 时的平均精度(average precision,AP)作为评估指标,对比原模型与使用本文方法后在鸟瞰图(bird-eye view,BEV)和3D 视角下算法的验证集评估结果。设计了消融实验,以SECOND 算法为骨干网络,研究深度校正模块、前景分割模块及采样模块的有效性。最后,统计了各模块的运算时间及存储开销,并给出优化措施。
3.1 点云补全的对比实验
3.1.1 数据集分析
点云补全数据集分为两类:提供真值的数据集(如ShapeNet)与不提供真值的数据集(如KITTI)。提供真值的数据集由人工合成,如ShapeNet 由8 个类别的30 974 个CAD 模型组成,在网格表面上均匀采样16 384 个点创建完整点云,训练集一般从点云对象中采样2 048 个点作为网络输入,采样8 192 个点作为真值。KITTI 目标检测数据集的局部点云稀疏,没有完整点云作为真实值,因此无法使用KITTI进行模型训练,只能进行预测。
本实验采用PoinTr 算法(Yu 等,2021)作为点云补全基准算法,PoinTr 算法采用编码器—解码器结构进行缺失点云生成。点云补全对KITTI 数据集的格式要求为只包含单个车辆的点云数据及对应的真值包围框的八顶点坐标。KITTI 用于目标检测的点云场景中一般包含若干目标点云及大量背景点云,因此需自制测试数据,根据标签及标定文件提取出所有的汽车包围框顶点数据及点云数据。
3.1.2 实验结果
使用PoinTr 算法官方提供的KITTI 预测模型作为推理模型,对自制的测试数据集进行预测。
图9 为点云补全实验的部分可视化结果,左侧为输入点云,右侧为补全后的点云。输入点云的稀疏程度不同,补全结果差距巨大。当输入点云较稠密、汽车整体结构完整清晰时,利用模型可较完整地补全汽车;当输入点云稀疏、只保留汽车小部分结构时,利用模型补全的结果较差或无法实现对汽车的补全。由此可见,没有数据集真值的点云补全是不可靠的,无法进行后一步的目标检测。

图9 点云补全效果图Fig.9 Illustration of point could completion
本文方法与点云补全的目标检测对比实验如图10和图11所示。图10为KITTI训练集编号000007的左相机图像。图11 为000007 号数据中的3 辆汽车的原始点云、本文方法生成的融合点云及点云补全效果对比图。车辆1的原始点云数量为195,使用本文方法后融合点云数量为202,由于原始点云集中在车尾,点云补全结果差。车辆2 的原始点云数量为21,使用本文方法后融合点云数量为91,点云数量增加,已大致呈现车辆头部的形状,由于原始点云大多集中在汽车头部,点云补全结果差。车辆3的原始点云数量为5,形状为一字排开的5 个点,使用本文方法后融合点云数量为63,点云数量明显增加,已大致呈现车辆头部的形状,由于车辆3 点云稀疏,无法进行目标检测,点云与道路等背景点噪音高度相似,无法进行点云补全。

图10 KITTI数据集000007号图像Fig.10 Image No.000007 in KITTI

图11 车辆真值、融合点云和点云补全对比图Fig.11 Comparison diagram of vehicle ground truth,fused point cloud and point cloud completion((a)vehicle ground truth;(b)fused point cloud;(c)point cloud completion)
点云补全仅以点云为输入,利用部分点云生成稠密的完整点云,注重结构与细粒度,可实现高保真的3D 形状重建,但网络计算量大,且只能使用人工合成数据集,无法解决当前的KITTI 等大型数据集目标检测任务,点云补全生成的稠密点云也不适用于大多数检测网络。本文方法以点云和图像为输入,是一种多模态融合方式,对目标进行伪点云补充,改善稀疏性,注重目标几何信息的增加,可以使用KITTI等自然数据集。本文方法更具通用性。
3.2 目标检测实验
3.2.1 数据集分析
KITTI 数据集可用于评测视觉测距、物体检测等技术的性能。KITTI 数据采自于市区、公路等场景,包含彩色图像、灰度图像和激光雷达点云等。KITTI 数据集中目标检测子集包含7 481 个样本。本文依据Chen 等人(2017)方法将样本分为训练集(3 712 个样本)和验证集(3 769 个样本),使用双目相机彩色视图、激光雷达点云、激光雷达与相机的标定数据和数据标签对车辆类别进行训练。
KITTI 数据分为3 个难易度等级:简单、中等和困难。如表1 所示。评估流程如下:根据检测框高度、遮挡率和截断程度建立数据忽略机制。截断程度从0(非截断)到1(截断)浮动。遮挡率分为0(完全可见)、1(小部分遮挡)、2(大部分遮挡)、3(完全遮挡)。对于简单等级,若当前标签的截断程度大于0.15,或遮挡率大于0,或检测框高度小于40,就将该数据忽略,不纳入评估。

表1 KITTI数据集评估等级划分标准Table 1 KITTI dataset evaluation grading standard
3.2.2 实验设置
实验在Intel Xeon Gold 6128 CPU@3.40 GHz 处理器,256 GB 运行内存,8 块NVIDIA 2080Ti 显卡,Ubuntu18.04 操作系统的计算机上运行,基于PyTorch 深度学习框架搭建目标检测网络。深度估计网络采用了基于SceneFlow(Mayer 等,2016)数据集的PSMNet预训练模型,语义分割网络采用了基于Cityscapes(Cordts 等,2016)数据集的HRNet 预训练模型,并且分别使用KITTI数据集对模型进行微调。
使用三维目标检测模型SECOND(Yan 等,2018)、MVX-Net(Sindagi 等,2019)、Voxel-RCNN(Deng等,2021)、Part-A2(Shi等,2021)和PointRCNN(Shi 等,2019)算法作为基准模型,以上5 种模型均使用了点云数据增强,主要方法有:点云绕激光雷达坐标系x轴翻转;使用0.95~1.05 的比例对点云进行随机缩放;将点云绕激光雷达坐标系y轴方向旋转-0.785~0.785弧度;使用真值采样方法(Yan等,2018),将其他帧真值矩形框内的点云抽取出来放在当前帧的空余位置。本文方法作为一种点云图像融合的数据质量增强方法,为更好地测试本文方法,以下实验将原文的数据增强方法替换为本文方法,进行训练和验证,参数配置如表2 所示。所有模型统一使用AdamW(带权重衰减的Adam)优化器进行训练。
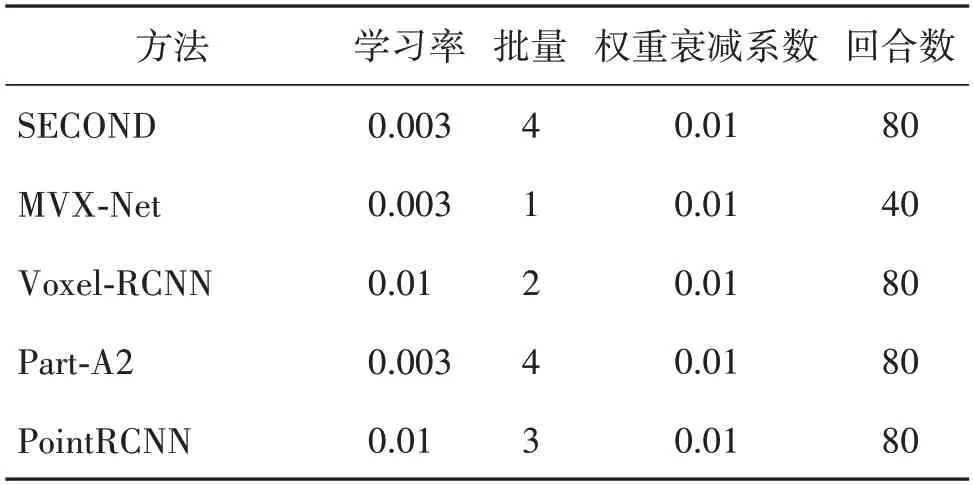
表2 目标检测网络参数表Table 2 Table of parameters in object detection network
3.2.3 评估指标
本文采用特定交并比IoU 下的平均精度AP 作为指标对实验结果进行评估与对比。IoU 值用来衡量预测框与真实框之间的重叠程度,IoU 值越大代表预测越准确。AP通过11个召回位置进行计算。
3.2.4 实验结果
本文对比车辆目标在鸟瞰图(bird’s eye view,BEV)视角下和3D 视角下算法的最终验证集评估结果。表3 为多个网络模型基于本文方法在验证集下IoU 为0.7 的3D 目标检测与鸟瞰图检测结果,即AP3D和APBEV。所有算法数据均来自原论文中KITTI验证集结果。

表3 本文方法应用于各网络在KITTI验证集上的检测平均精度对比Table 3 The comparison of the average detection accuracy of various networks with our method on the KITTI val set∕%
如表3 所示,在三维目标检测方面,在简单和中等难度等级下,多数网络都获得了优于原方法的检测效果;在困难等级下,对测试网络带来最大8.65%的提升,表明本文方法极大提升了小目标的3D检测精度,为三维目标检测带来显著的性能提升。鸟瞰图检测方面,在简单、中等和困难等级下,多数网络都获得了优于原方法的检测效果,本文方法对鸟瞰图检测带来的提升是全方位的。
对于目标检测网络,本文对SECOND 算法和MVX-Net 算法的各指标提升最大。在简单、中等和困难等级下,对SECOND 算法的3D 检测精度提升分别为1.15%、2.38%、8.65%,对SECOND 算法的鸟瞰图检测精度提升分别为0.33%、1.15%、7.05%。对MVX-Net算法的3D检测精度提升分别为1.26%、3.13%、7.32%,对MVX-Net 算法的鸟瞰图检测精度提升分别为0.27%、2.10%、0.43%。对其他目标检测网络的部分指标带来最大6.29%的提升,主要集中于困难等级。
本文对PointRCNN 算法各指标提升最小,PointRCNN 直接对原始点云进行处理,算法一阶段使用前景分割网络将点云分割成前景点和背景点,对每个前景点生成一个候选框,随后在二阶段对候选框进行筛选及优化。本文方法将图像前景转化到三维空间中生成伪点云,经过深度估计与校正,伪点云仍存在部分深度误差。因此PointRCNN 预测为前景点的点云里包含大量存在深度误差的伪点云,对于部分目标,前景伪点云数量大于原始前景点云数量,生成的候选框也会存在误差,在算法二阶段的候选框筛选及优化部分,可能会淹没部分原始点云形成的候选框,占据主导地位,从而无法提升预测效果甚至带来一定的下降。SECOND、MVX-Net、Voxel-RCNN和Part-A2 这4 种算法都是将点云划分为体素的方法,体素粒度大,一个体素包含多个点云及伪点云,大部分伪点云的深度误差小于体素粒度,在以体素为基本单位进行特征提取时,误差对检测结果影响较小或忽略不计,此外,伪点云的加入大大增加了远处小目标非空体素的数量,有利于特征提取,提升小目标检测精度。
图12 显示了应用本文方法后SECOND 算法在KITTI 数据集上目标检测的可视化结果。在图像示意图中,橙色代表检测框真值,蓝色代表应用本文方法预测的检测框。在点云示意图中,蓝色代表检测框真值,绿色为应用本文方法预测的检测框。结果表明,本文方法对于车辆类目标有较好的检测效果,检测框的尺寸、位置和朝向预测较为精准。此外,部分距离较远、被遮挡和未标注的目标也由本文方法检测出来,表明本文方法的有效性与优越性。

图12 KITTI数据集检测结果可视化Fig.12 Visualization of KITTI dataset detection results
图13 为SECOND 算法在使用本文方法前后的可视化结果对比图。图像及点云的真值、预测框颜色表示与图12相同。

图13 使用本文方法前后的检测效果Fig.13 Detection effect before and after using our method((a)original model;(b)ours)
图13 上部分(1-2 行)、下部分(3-4 行)分别展示了本文方法对远处小目标漏检及误检情况的改善。原模型产生的漏检以及误检车辆使用黑色圆圈圈标出。本文方法降低了小目标点云稀疏性导致的漏检,也降低了误检情况的发生。
3.2.5 消融实验
为验证本文方法深度校正模块、前景分割模块、采样模块的有效性,本文设计了采用SECOND 算法为骨干网络的消融实验,如表4 所示。实验结果表明,本文所设计的深度校正模块、前景分割模块和采样模块均对结果的改进起到了作用。
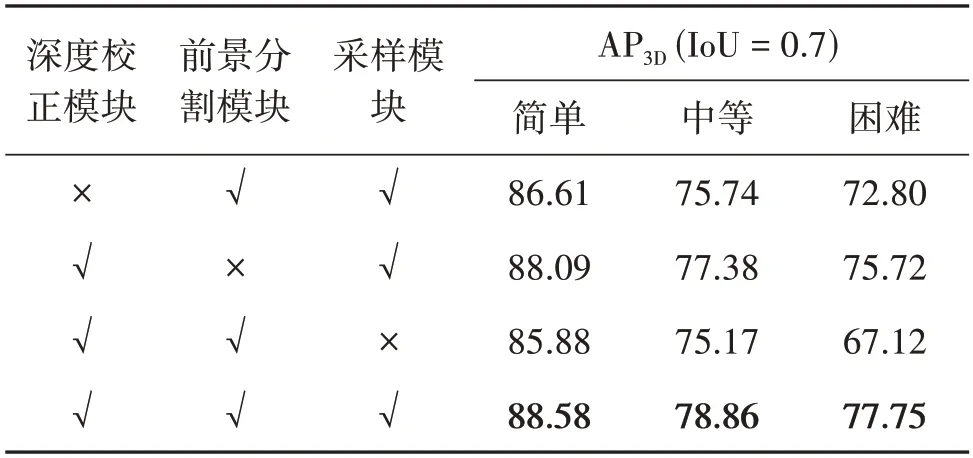
表4 消融实验Table 4 Ablation experiment∕%
1)深度校正模块的有效性。引入深度校正模块使3D目标检测精度在简单、中等和困难等级下分别提升约1.97%、3.12%和4.95%。深度校正模块有助于减少伪点云的深度误差,缩小伪点云与激光点云的差距,这对于目标检测结果的提升至关重要。
2)前景分割模块的有效性。前景分割模块对结果提升最小,该模块使3D 目标检测精度在简单、中等和困难等级下分别提升0.49%、1.48%和2.03%。前景分割模块的设计动机是仅保留前景伪点云,避免过多背景点云使目标检测的回归任务出现偏差。但采样模块使伪点云数量大幅减少,即使保留了伪点云的背景点,其数量有限,对目标检测网络的影响程度有限,因此前景分割模块对检测结果提升较小。
3)采样模块的有效性。采样模块对结果提升最大,该模块使3D 目标检测精度在简单、中等和困难等级下分别提升2.70%、3.69%和10.63%,由于SECOND网络是基于体素的方法,每个体素中的点数量有限,当不对伪点云进行采样时,伪点云数量庞大,在对体素中的点进行随机采样时,采样到伪点云的概率变高。前文已分析过,由于伪点云存在深度误差,伪点云应起到辅助作用而不是主导作用。因此,针对不同距离下的原始点云使用不同线数的伪点云对其进行稀疏补偿,有助于目标检测结果的提升。
3.2.6 时间及存储开销
本文方法的训练及推理分为8 个部分,分别进行了算法时间和存储(显存)的开销统计,如表5 所示。经统计,耗时最严重的是深度估计网络与语义分割网络。在实际自动驾驶场景中,本文方法的深度校正模块可接受一定程度的深度估计误差,可将PSMNet替换为推理速度更快的单目深度估计网络。语义分割依赖高分辨率输入,存在大量参数,实时性是其弱点,本文消融实验表明,前景分割模块对检测结果提升最小,因此前景划分不必过于精细,可使用速度更快的二维目标检测来提取前景区域,最后将会引入包围框内极少量背景伪点云。

表5 模型运行时间及存储开销统计Table 5 Statistics of model running time and storage cost
4 结论
针对激光雷达点云稀疏性导致小目标检测精度下降的问题,本文提出一种伪激光点云增强技术,利用深度估计网络获取双目图像的深度图,将深度图前景部分映射到三维空间形成伪点云,对不同距离下的点云目标给予不同数量的伪点云补充。最终伪点云与点云融合作为网络输入。本文方法实现了对稀疏小目标几何信息的补充,可应用于所有基于点云的目标检测网络。在KITTI 数据集上的实验结果表明,在三维目标检测方面,在困难等级下,测试网络SECOND、MVX-Net 和Voxel-RCNN 分别获 得8.65%、7.32%和6.29%的大幅提升。在简单与中等难度等级下,多数测试网络都获得了优于原方法的检测效果。鸟瞰图检测方面,所有测试网络都获得了优于原方法的检测效果。本文显著提升了道路场景下的三维目标检测性能,改善了远处小目标点云的稀疏性,大幅提升了困难等级下的小目标检测性能。本文方法具备有效性和通用性,对多模态融合的三维目标检测提出了新的思路。
本研究接下来将继续对伪点云下采样策略进行优化,设计自适应的采样策略,对远处的小目标赋予更合理数量的伪点云,改善其稀疏性。此外,将进一步在网络结构设计上深入挖掘。
猜你喜欢
北京测绘(2022年5期)2022-11-22
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
汽车观察(2021年8期)2021-09-01
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
中国交通信息化(2019年1期)2019-03-26
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
电子制作(2018年16期)2018-09-26
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
