
近邻优化跨域无监督行人重识别算法
2023-11-22 01:19朱锦雷李艳凤陈后金孙嘉潘盼
中国图象图形学报 2023年11期
朱锦雷,李艳凤,陈后金,孙嘉,潘盼
北京交通大学电子信息工程学院,北京 100044
0 引言
行人重识别(person re-identification,Re-ID)属于目标分类的一种,其目的是确定出现在不同摄像场景下的行人是否属于同一人员,可以看做是图像检索的子问题,广泛应用于智能视频监控、刑事侦查和安全生产等领域。罗艳等人(2022)对行人检测技术的进展做了较为系统的综述,深度学习技术在行人检测(Zhu 等,2021)、行人行为分析(Zhu 等,2022b)、目标检测(刘万军 等,2021)和边缘计算(Zhu等,2022a)等领域快速发展。
行人重识别技术发展迅速,但有监督方法依赖于大量的标记数据集,标注成本高。为解决这个问题,越来越多的研究人员关注半监督∕无监督行人重识别技术。在无监督行人重识别相关技术中,无监督域自适应是最常见的Re-ID 方案,其首先在有标记的源域上预训练,然后基于预训练模型在未标记的目标域上进行无监督学习。相比于有监督行人识别,无监督行人识别技术具有更大的应用前景,但存在一些困难和挑战,如行人在穿着、背景等方面存在很大差异,不同场景图像也存在风格差异,在某个场景下训练好的模型直接在另一个场景下使用,其识别性能可能会大幅下降,这通常需要跨域无监督迁移学习来优化。另外,受到环境光照、摄像背景、行人姿态和遮挡等因素影响,聚类容易受到噪声干扰,这些因素都给跨域行人再识别带来不少挑战。。
由于源域数据和目标域数据在成像条件和应用场景等方面存在较大差异,一种UDA(unsupervised domain adaptive)方法应用生成对抗网络(generative adversarial network,GAN)(Liu 等,2019a;Ge 等,2020a)来减少域差异,从而改变两个域之间的图像样式。PDA(pose disentanglement and adaptation)(Li等,2019)实现了在域间减少差异,但其忽略了目标域内的差异。PTGAN(person transfer generative adversarial network)(Wei 等,2018)有助于改善域偏移,但生成图像容易受到源域影响。SPGAN(generative adversarial network with preserved self-similarity and domain-dissimilarity)(Deng等,2018)采用自相似度对这一问题进行了改进,CR-GAN(context rendering generative adversarial network)(Chen 等,2019)通过增强个体渲染效果提升识别能力。但上述基于GAN 的生成方法通常会引入额外的生成噪声,从而影响识别性能。IMPLICT(Implicit network)(Zhang等,2022)模型采用邻域生成机制缓解了这一问题,取得了一定的改善效果。
另一类UDA 方法采用软标签或伪标签机制探索两个域之间的相似性。其中,伪标签对未标注数据进行预测,基于预测结果进行二次训练;软标签将One-Hot标签转为与其他图像相似度的向量值,基于向量值进行二次训练。Yu 等人(2019)通过计算目标域样本和源域样本之间的相似性,为目标域分配软标签,为无监督学习开拓了新的方向,但受制于源域与目标域数据模态的差异,软标签噪声非常严重。
PAST(progressive augmentation self-training)(Zhang 等,2019)使用聚类方法为目标域图像分配伪标签,但其没有对伪标签噪声进行处理,导致模型退化。针对伪标签噪声问题,PUL(person reidentification with unsupervised learning)(Fan 等,2018)尝试根据到聚类中心的远近筛选可靠样本进行模型训练,但对疑似噪声样本的直接丢弃会导致训练样本信息量减少。SPCL(self-paced contrastive learning)(Ge 等,2020b)在目标域使用Hard 伪标签和Soft 软标签相结合的方式训练模型,使得伪标签噪声问题在一定程度上得到改善。TJ-AIDL(transferable joint attribute-identity deep learning)(Wang等,2018)根据识别样本特性对无监督学习过程进行优 化;HHL(hetero-and homogeneously)(Zhong 等,2018)对同源与异源个体进行独立学习;ENC(exemplar memory network by a controller)(Zhong 等,2019)采用的协方差损失是对ATNet(adaptive transfer network)(Liu 等,2019b)、SSG(self-similarity grouping network)(Fu 等,2019)自适应学习的一种改进;上述方法均取得了一定效果。大多数无监督行人重识别通过测量特征相似性产生伪标签,忽略了相机之间的分布差异。针对该问题,ICAM(intra-inter camera network)(Xuan 和Zhang,2021)在进行跨域学习时依据相机参数进行优化,但其需要对相机进行较为详细的定向训练与测试,算法的普适性不高。
基于伪标签的无监督学习方法是目前的主流方案,但需要解决伪标签噪声等系列问题。伪标签噪声会导致现有方法对着装、体态和相貌等相似人群具有较弱的辨别能力,如图1所示。

图1 相似的行人之间容易产生误识Fig.1 Similar pedestrians tend to produce false recognition
为解决这一问题,提出了一种基于近邻优化的跨域无监督行人重识别方法,其主要思想是基于特征具有类内收敛性、类内连续性与类间外散性的特点。首先,基于预训练模型对目标域样本进行聚类,为样本分配伪标签;其次,采用三元组硬损失(batch hard triplet loss,BHTL)(Hermans 等,2017)控制同类样本特征的内敛性与不同类样本特征的外散性;再者,为增强算法对相似行人的辨识能力,设计了对抗损失函数,类中特征距离较近的一组样本对与特征距离较远的一组样本对进行对抗;进一步,为使类内特征的收敛方向一致,设计了特征连续性损失函数,对批处理组内各类样本特征的连续性进行度量和控制;最后,将上述3 个损失函数加权相加作为总体损失函数。
本文的主要贡献如下:1)设计了一种新的跨域无监督行人重识别算法模型,可以更好地解决相似行人的重识别问题;2)为增强对高相似度行人的辨识能力,设计了邻域对抗损失函数,任意样本与其他样本构成样本对,使类别确定性最强的一组样本对与不确定性最强的一组样本对之间进行对抗,实现了伪标签滤波的类似效果;3)为使类内样本特征朝着同一方向收敛,设计了特征连续性损失函数,将特征距离曲线进行中心归一化处理,在维持特征曲线固有差异的同时,拉近样本k邻近样本特征距离。
1 本文算法
当训练集和测试集来自同一源域时,容易获得良好的识别性能,但实际中会出现训练集与测试集存在较大域偏移的问题,将源域模型直接应用至目标域,识别性能将显著下降。为了更好地将源域预训练模型迁移到目标域,通常需要使用目标域数据来进一步优化模型。
本文提出了一种基于近邻优化的跨域无监督行人重识别方法,方法框架如图2 所示。首先在源数据集上进行有监督预训练,然后基于预训练模型在目标域训练集上进行无监督训练。无监督训练过程中,通过对样本特征聚类以获得样本伪标签,基于同类特征连续性、类间特征发散性等特点,对batch 内样本特征距离分布通过排序、求梯度等操作进行变换处理,采用伪标签三元组损失函数(pseudo-based triplet loss,PTL)、邻域连续损失函数(neighbor consistency loss,NCL)和邻域对抗损失函数(neighbor adversarial loss,NAL)训练模型。

图2 基于邻域对抗与连续性损失的跨域无监督行人重识别算法框架Fig.2 Cross-domain unsupervised Re-ID algorithm based on neighbor adversarial and consistency loss
1.1 源域有监督预训练方法
本文采用的基准网络模型(baseline model)如图3 所示,其是一个多尺度多特征融合网络,采用通道注意力与空间注意力机制进行特征融合,输出特征分别采用最大值池化算子(global maximum pooling,GMP)和平均池化算子(global average pooling,GAP)进行处理,拼接(cascade)后形成最终的特征。本文在主干网络中将MEMF(multi-level-attention embedding and multi-layer-feature fusion model)(Sun等,2021b)使用的ResNet-50(residual network)更换为ResNeXt-50,并以此作为基准网络模型。

图3 本文用到的基准网络模型Fig.3 The baseline model used in the paper
源域数据包括行人的ID(identity)标签信息,其损失函数由三元组硬损失BHTL 和交叉熵损失(cross-entropy loss,CEL)构成。三元组损失从batch大小为PK的组中随机选取P个预测结果,每个样本与随机选取的其他K个样本进行比较,综合P个距离最近值与P个距离最远值形成三元组损失,由于局部突出样本参与了计算,故其关注的是批处理组内的局部损失。
针对每一个输入xs,a,寻找合适的正负样本对xs,p与xs,n,BHTL方法定义为
式中,f(·)指提取样本特征,m为超参数,表达式[z]+=max {0,z},PK为批处理组batch 的大小,以参数P与K随机选取样本。交叉熵损失函数CEL 主要关注样本的全局损失,其定义为
式中,ys,i是xs,i对应的真实标签,Yys,i为xs,i的全连接层(full connection,FC)输出值,Ms为所有类别数量(即参与训练的行人数量)。源域预训练的总体损失函数为
1.2 目标域无监督学习方法
目标域训练的具体步骤为:1)加载CheckPoint阶段性存储的模型参数对无标签样本进行预测分类,赋予伪标签;2)采用基于伪标签的BHTL 损失函数计算三元组损失;3)计算批处理组(batch)内特征之间的余弦相似度,并进行降序排列;4)从序列中分别选取距离较小且确定性较强的K个值,其对应正样本,距离较大且不确定性较强的K个值,其对应负样本,根据正负样本计算邻域对抗损失;5)兼顾组内特征分布的固有差异,计算邻域连续性损失函数以拉近邻域特征的距离,实现特征之间密度可达;6)前述3 个损失函数进行加权相加,作为目标域模型微调的损失函数。
1.2.1 伪标签三元组损失函数
伪标签三元组损失函数PTL的计算过程为首先对基准网络输出的样本特征进行聚类,聚类应满足两个特性:1)尽可能接近预训练模型预测的目标特征中心,测度为dN;2)样本特征之间的距离尽可能小,即具有较高内敛性和外散性,测度为dJ。设fs是样本xs,i基于源域预训练模型的预测结果,f是在目标域训练过程中的神经网络前向预测结果,则dN和dJ测度分别定义为
对两个测度进行加权求和,可得到最终测度dij,具体为
式中,λ为超参数。基于dij测度,采用DBSCAN(density-based spatical clustering of applications with noise)(Ester等,1996)方法进行聚类。
假设有TS个样本参与计算,通过sklearn库赋予伪标签过程参考以下代码:
代码中,通过eps 设置邻近样本特征最大距离,min_samples为簇的样本数,K与本文前述定义相同,labels 即为得到的样本伪标签,一般情况下,可每个epoch为训练样本分配一次伪标签。
基于伪标签,与BHTL类似,PTL定义为
式中,f(·)指目标域样本特征,其他符号含义与前述标准的BHTL相同。
1.2.2 邻域对抗损失函数
由于可能会错误地赋予样本伪标签,其给模型带来了局限性和不确定性。针对该问题,本文设计了邻域对抗损失函数NAL,通过batch内确定性样本与不确定性样本对抗,增强相似人群辨识能力。该损失基于目标域batch中样本间距离计算,不需要伪标签支持。其基本思想是,通过拉近确定性强的样本对与不确定性较强的样本对之间的特征距离,增强临界不确定性图像(相似行人样本)的特征表示能力。
样本xs,i与xs,j特征的余弦相似度定义为
式中,f指样本特征。在batch 大小为PK的处理组中,计算任意组合(xs,i,xs,j)的特征余弦相似度,形成Dcosine,并以行为单位进行降序排列,形成新的行列式Drank。具体为
式中,Drank中的dc(xs,i,)代表了 按行排 序后第i行、第j列位置上的值。按Drank行方向,进行差分运算,得到行方向梯度ΔDrank,具体为
如图4 所示,从Drank中选取K个正集K+与K个负集K-,K+是取相似度最高的前K个dc值;K-是一个滑动窗口,取窗口内累积梯度最大的滑动窗,设Kc为其中心。

图4 K+与K-的选取方法Fig.4 K+ and K- sliding window
直观上,Drank中正例集K+代表K个相似度最高的dc值,负例集K-代表相似度变化最为剧烈的K个dc值,即样本相似度不确定性最高的一组数据。邻近集K+与K-的对抗可提升算法对相似行人的辨别能力,因此邻域对抗损失函数NAL 的定义为
式中,γ为正则超参数。
1.2.3 邻域特征连续性损失
尽管NAL 可以强化图像特征的内敛性与外散性,但不能确保K+类内图像特征收敛方向的一致性。针对该问题,设计了邻域特征连续性损失函数NCL,通过约束k邻近特征收敛方向,进一步提升网络性能。
邻域特征连续性损失的本质作用是使每个样本的k邻近距离趋近相等,以便使用DBSCAN 进行聚类时通过设定eps 参数实现密度可达。由于Drank行列式每行存在固有差异,强制使得batch中每个样本的k邻近距离等值分布,将导致特征距离拉近过程过于刚性。一种解决办法是将Drank的每行元素进行中心归一化处理,具体为
式中,kc为Drank每行Kc位置所对应的dc值(Kc的定义参考图4),变换后的Drank记做。邻域特征连续性损失基于进行计算,希望K+内部的k邻近样本的特征相似度更高,故需要概率化计量相邻相似度损失,具体为
式中,ε为概率系数,用于调节概率曲线的陡峭程度。wi,j通过提升邻域低相似度损失占比,减少高相似度损失占比,以进一步拉近k邻域特征之间的距离,促使类内图像特征向同一方向收敛。
1.2.4 目标域总体损失函数
前述伪标签三元组损失函数、邻域对抗损失函数和邻域特征连续性损失函数加权求和,得到目标域损失函数为
式中,α为超参数。
2 实验分析
2.1 数据集与实验参数
在公开数据集Market-1501(1501 identities dataset from market)(Zheng 等,2015)和DukeMTMC-reID(multi-target multi-camera person re-identification dataset from Duke University)(Zheng 等,2017)上对本文方法进行验证,其中部分样例如图5所示。

图5 数据集中的样例Fig.5 Some samples in the datasets
Market-1501 数据集包括6 台摄像机拍摄的1 501 个身份的32 668 幅标签图像,其中751 个身份的12 936幅图像用于训练,其余用于测试,在测试数据中,查询集(probe)为具有750个身份的3 368幅图像。DukeMTMC-reID 数据集包含1 812 个身份的36 411幅图像,这些图像由8 台摄像机拍摄,其中1 404 个身份出现在两台以上的摄像机中,408 个身份出现在一台摄像机中,1 404 个身份被随机分出702 个用于训练,其他用于测试。在测试集中,为每个摄像机的每个身份选择一个查询图像作为查询集,包括干扰在内的所有剩余图像构成搜索库(gallery)。
实验采用首位识别(Rank-1)、前五识别(Rank-5)、前十识别(Rank-10)、平均精度均值(mean average precision,mAP)进行测度。mAP 相对于Rank-n指标更侧重于描述检索图像的总体排序情况,mAP 值越大,代表检索正确的图像越靠前。假设query待检索图像集中包含N幅图像,qi表示第i个query 图像,则数据集记为Q={q1,q2,…,qi,…,qN}。gallery 表示图像库,假设包含M幅图像,gi表示第i幅图像,则数据集记为G={g1,g2,…,gi,…,gN}。假设qi对应行人ID在G中出现的次数为,对每个query查询过程qi提取特征向量后依次和G中每幅图像的特征向量进行比对并计算距离,按照距离大小对gallery进行排列,排序后的gallery 数据集记为Gqi,qi检索出的图像组成的数据集记为是的子集。假设在中的排位记为rj,在中的排位记为,对所有query 图像重复这个过程,则mAP计算为
显然,mAP 与Rank-1 正相关。实验训练参数K=4,P=32,PK=128,采用Adam 作为优化器,初始学习率为0.03,epoch 训练次数为150,保存训练期间的最佳评估模型。参考2.5 节超参数性能评价,相关超参数设置为λ=0.1,m=0.5,γ=0.5,ε=0.05,k=8,α=0.3。
2.2 消融实验
消融实验分两组进行,其中一组实验中,DukeMTMC-reID→Market-1501 指DukeMTMC-reID作为源域,Market-1501 作为目标域;另一组实验Market-1501 →DukeMTMC-reID 与其相反。设Baseline 为基准网络模型,分别以Baseline、Baseline+PTL、Baseline+PTL+NAL、Baseline+PTL+NCL、Baseline+All 组合来验证损失函数各部分的有效性,Baseline+All 指同时使用PTL+NAL+NCL 损失函数。图6(a)表示DukeMTMC-reID→Market-1501 实验中各损失函数组合下Rank-n对应的识别率,图6(b)表示Market-1501→DukeMTMC-reID 实验中各损失函数组合下Rank-n对应的识别率,表1 为图6 所对应的具体数据,mAP 计算方法参考式(18),参考图6和表1,对比不同损失函数组合时Rank-n和mAP 的变化,通过观察各损失函数的有效性,分析结果如下:

表1 消融实验中各损失函数的有效性实验数据Table 1 Ablation experimental results of effectiveness of each part of loss∕%
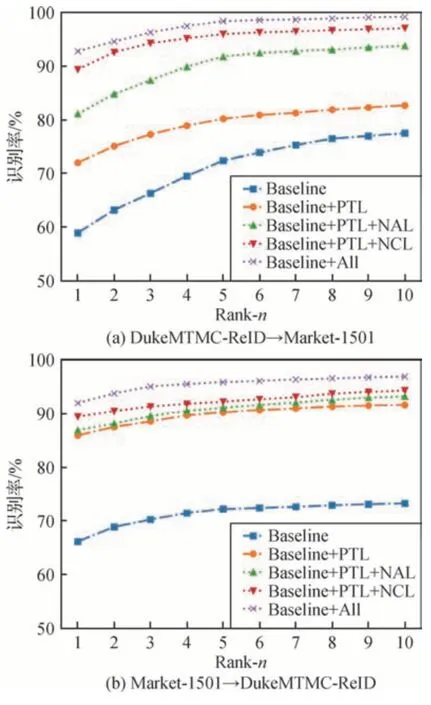
图6 消融实验中损失函数有效性对比Fig.6 Effectiveness of each part of loss((a)DukeMTMCreID→Market-1501;(b)Market-1501→DukeMTMC-reID)
1)PTL 损失的有效性。与仅在目标域使用预训练模型相比,Baseline+PTL组合在DukeMTMC-reID→Market-1501 实验中,mAP 提升了14.2%;在Market-1501→DukeMTMC-reID实验中,mAP提升了30.8%。上述实验结果表明有必要使用PTL在目标数据集上进行无监督优化训练。
2)NAL 损失的有效性。相对Baseline+PTL 组合,Baseline+PTL+NAL 的mAP 在两组实验中分别提升了18.6%和12.2%,说明采用邻域对抗的方式可有效抑制PTL引入的伪标签噪声。
3)NCL 损失的有效性。相对Baseline+PTL 组合,Baseline+PTL+NCL 的mAP 在两组实验中分别提升了33.3%和15.4%,说明在考虑特征的类内收敛性和类间发散性同时,还应考虑类内特征收敛方向的一致性,即类内特征的连续性。
4)总体损失的有效性。Baseline+PTL+NAL+NCL 在所有实验中取得了最佳mAP 值,其他指标也最优,表明PTL、NAL、NCL 这3个损失函数具有一定互补性,可以综合提升行人重识别算法的性能。
实验中无法进行“Baseline+NAL”与“Baseline+NCL”的原因如下:NAL 处理PTL 引入的伪噪声,依赖于PTL,直接使用Baseline+NAL 训练时模型将不收敛;NCL 是对PTL 的进一步优化,依赖于PTL,直接使用Baseline+NCL训练时模型将不收敛。
2.3 对比实验
将本文方法与PUL(Fan 等,2018)、PTGAN(Wei等,2018)、SPGAN(Deng 等,2018)、TJ-AIDL(Wang等,2018)、HHL(Zhong 等,2019)、BUC(bottom-up clustering)(Lin 等,2019)、MAR(multi-label adaptive re-identification)(Yu 等,2019)、ENC(Zhong 等,2019)、ATNet(Liu 等,2019b)、PAST(Zhang 等,2019)、CR-GAN(Chen 等,2019)、SSG(Fu 等,2019)、Method(Lin 等,2020)、PDA(Li 等,2019)、MMT(mutual mean-teaching)(Ge 等,2020a)、Selfpaced(self-paced contrastive learning)(Ge 等,2020b)、PPLR(part-based pseudo label refinement)(Cho 等,2022)、MLOL(multi-loss optimization learning)(Sun等,2021a)、GAWARE(group-aware label transfer learning)(Zheng 等,2021)、ICAM(Xuan 和Zhang,2021)等现有最前沿的方法(state-of-the-art,SOTA)进行比较,实验结果如表2所示。表中,Market-1501表示将数据集DukeMTMC-reID 作为源域进行预训练,数据集Market-1501 作为目标域进行无监督学习,基于Market-1501 的测试集进行评估的结果;DukeMTMC-reID 表示将数据集Market-1501 作为源域进行预训练,数据集DukeMTMC-reID 作为目标域进行无监督学习,基于DukeMTMC-reID 的测试集进行评估的结果。
在DukeMTMC-reID→Market-1501 迁移学习实验中,本文方法在Rank-1、Rank-5、Rank-10、mAP 明显优于已有SOTA 方法,取得了92.8%的Rank-1 精度 与84.1% 的mAP精度。在Market-1501→DukeMTMC-reID 迁移学习实验中,本文方法取得了83.9%的Rank-1 精度与71.1%的mAP 精度,相对SOTA 方法有着较为明显的性能提升。具体的原因如下:由于相似人群容易产生伪标签噪声,本文方法在损失函数中增加了邻域相似特征对抗学习有效控制伪标签噪声,通过邻域特征连续性损失函数控制了特征收敛方向一致性,取得了较好的效果。
2.4 损失函数效率分析
本文基准网络的Backbone 为ResNeXt-50,其损失函数计算过程比较复杂。考虑到目前主流SOTA方 法将ResNet-50 或ResNeXt-50 作为Backbone,因此重点分析损失函数与Backbone 的相对计算复杂度。
借助Pytorch 统计工具,批处理大小PK=128,输入尺度为3 × 256 × 128 时,批处理ResNeXt-50的计算复杂度合计约为356.5 GFLOPs。
仍按batchsize计算,特征输出尺度为1 × 1 024,式(6)的计算复杂度为PK×P×K× 2 ×(1 024 ×1 024),式(9)的计算复杂度为(PK×(PK+1)∕2) ×(1 024 × 1 024),其他公式为相似度分值的简单处理,计算量可忽略不计。本文损失函数计算复杂度如表3所示,以batch为计算基准,PTL损失函数计算复杂度为34.4 GFLOPs,NAL 损失函数的计算复杂度为8.7 GFLOPs,NCL 增加的复杂度忽略不计,则损失函数相对Backbone 增加了大约12% 的计算量。

表3 损失函数计算复杂度Table 3 The batch complexity of loss function
2.5 超参数分析
超参取值与目标数据集的规模及分布相关,通常采用先估计后实验的方法获得其取值,下述以epoch=30进行超参数实验。
1)k超参数分析。首先对数据集中行人出现频次进行统计,Market-1501 数据集中行人大多出现2~11 次,再通过在[2,11]区间内枚举所有k值,计算其对mAP 和Rank1 的影响,即可获得最优k值,如图7所示,故本实验设置k=8。

图7 k邻近值参数对算法性能的影响Fig.7 Influence of parameters-k on algorithm performance
2)K,P超参数分析。P抽取本质上是batch的随机子集,P取值与PK相关,取值范围为[PK∕2,PK∕4,PK∕8,PK∕16,…],相应K取值为[2,4,8,16,…]。当PK=128时,在P数据集上随机抽取K个正例与K个负例后计算三元组损失,通过实验获得最佳mAP和Rank1所对应的K值,如图8所示,当K=4,P=32时,算法的识别性能最佳。
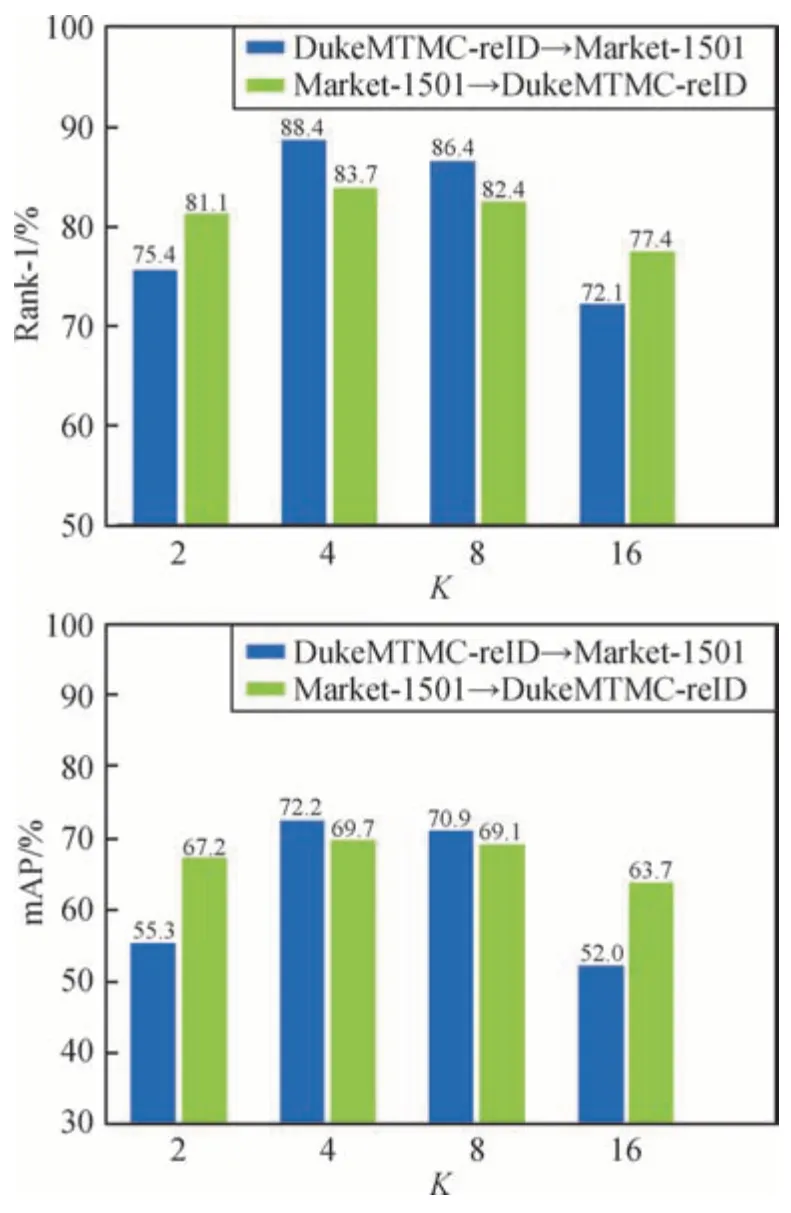
图8 K参数对算法性能的影响Fig.8 Influence of K on algorithm performance
3)α超参数分析。NCL损失是对基本损失函数PTL 的增强,因此α取值应为(0,1],以0.1 为步长依次枚举所有可能取值[0.1,0.2,0.3,…,1.0],通过对mAP 和Rank1 的影响可确定α最优取值。图9 显示了不同α的实验结果,本文设置α=0.3。

图9 α加权参数对算法性能的影响Fig.9 Influence of parameters-α on algorithm performance
4)ε,λ超参数分析。ε为NCL 损失函数中涉及的超参数,主要用于调节概率密度,其影响DBSCAN 聚类参数eps 的设置,指定eps=0.01,λ=0.5,ε取值范围为(0,1],可以通过实验得到ε=0.05时mAP和Rank1性能最佳。λ代表源域对目标域聚类的影响系数,对eps 也有影响,取值范围为(0,1],通过实验可得λ=0.1 时mAP 和Rank1 性能最佳。ε,λ可能同时影响eps,重复上述过程进行3~4 次实验,发现二者之间相互影响甚微,基本可认为相互独立。最终,设置ε=0.05,λ=0.1。
5)超参数极限优化。超参之间可能相互影响,如需极限优化超参取值,一般方法为,先固定其他超参数取值,重复进行以上实验。
3 结论
针对聚类伪标签噪声导致现有方法对着装、体态等相似行人辨别能力差的问题,基于特征具有类内收敛性、类内连续性与类间外散性的特点,提出了一种基于近邻优化的跨域无监督行人重识别方法,首先采用有监督方法得到源域预训练模型,然后在目标域进行无监督训练,以提升模型在目标域的识别能力。
本文主要贡献为面向跨域无监督行人重识别,提出了一种实现近邻特征优化的新型框架和系列损失函数。设计了邻域对抗损失函数,任意样本与其他样本构成样本对,使类别确定性最强的一组样本对与不确定性最强的一组样本对之间进行对抗,从而增强了模型对高相似度行人的辨识能力。设计了特征连续性损失函数,将特征距离曲线进行中心归一化处理,在维持特征曲线固有差异的同时,拉近样本k邻近特征距离,使类内样本特征朝着同一方向收敛。实验在Market-1501 和DukeMTMC-reID 公开数据集上进行,消融实验表明了各损失函数的有效性,与已有SOTA 方法相比,提出方法具有一定优势。
由于在目标域进行网络训练时,会静态地受到源间隙的影响,可能影响算法对目标域样本聚类的收敛能力。在模型中充分考虑域间分布特性,对目标域训练过程动态干预,可进一步提升网络无监督学习能力,这将作为我们的后续研究方向。
猜你喜欢
意林(2021年5期)2021-04-18
吉林大学学报(理学版)(2020年3期)2020-05-29
扬子江(2019年1期)2019-03-08
车迷(2018年11期)2018-08-30
自动化学报(2018年7期)2018-08-20
海峡姐妹(2018年3期)2018-05-09
小天使·一年级语数英综合(2017年6期)2017-06-07
周口师范学院学报(2016年5期)2016-10-17
公民与法治(2016年10期)2016-05-17
计算机工程(2015年8期)2015-07-03
