
局部相似度异常的强泛化性伪造人脸检测
2023-11-22 01:19戴昀书费建伟夏志华刘家男翁健
中国图象图形学报 2023年11期
戴昀书,费建伟,夏志华,*,刘家男,翁健
1.中山大学网络空间安全学院,深圳 518107;2.南京信息工程大学计算机学院,南京 210044;3.暨南大学网络空间安全学院,广州 510632
0 引言
近年来深度伪造(DeepFake)人脸技术的发展取得了长足进步,这类技术所创造的高逼真伪造人脸图像已经超出了肉眼分辨的范围,给多媒体内容安全带了巨大威胁,不仅对个人隐私安全产生了影响,也给国际政治局势带了隐患。因此,为了遏制层出不穷的深度伪造人脸技术的滥用,亟待开发具有泛化性的检测方法。
早期,深度伪造人脸的逼真度不高、瑕疵明显,传统数字取证算法与深度学习模型即可取得较好的检测效果。而随着深度伪造技术的发展,伪造人脸越发逼真,给检测算法带来了挑战。研究者则试图诉诸更加本质的真伪人脸差异来提升检测效果。有研究发现深度伪造人脸技术的流程一般可以分解为以下几步:1)检测并裁剪目标画面中的人脸;2)利用伪造算法对人脸进行篡改伪造;3)将伪造的人脸粘贴回原画面并利用图像融合技术消除边界瑕疵,提升视觉效果。而步骤3)中的人脸与背景融合的操作往往会造成易检测的局部伪造痕迹。这类局部伪造痕迹是一种区分真伪人脸的重要线索,许多工作试图使模型学习这类痕迹来提升精度,或实现篡改定位的功能(Chen 等,2021;Li 等,2020b;Li 和Lyu,2019)。然而,不同伪造技术所涉及的图像融合方法各不相同,所残留的局部痕迹也有所不同,导致针对不同伪造技术的检测算法并不通用,即检测算法的泛化性较为有限。因此,虽然步骤3)所造成的局部痕迹是普遍的,但直接学习该类特征进行真伪人脸识别对泛化性的贡献较小。
为了实现高泛化性的伪造人脸检测,本文不直接学习局部伪造痕迹来区分真伪人脸,而是将算法的学习目标转化为图像局部特征的相似性。该思路的动机来源于伪造人脸图像中面部区域与背景区域的特征冲突。具体而言,伪造人脸图像的面部区域经过篡改后,与背景区域有着不同的源特征,虽然这两类区域内部具有统一的源特征,但人脸与背景的融合边界则包含了源特征冲突,因此具有较低的局部相似度水平。这类局部相似度异常特征与特定伪造算法与融合算法均无关,是一种更加符合真伪人脸本质差异的特征。本文针对性地研究了这类深度伪造算法中普遍存在的人脸融合操作所引起的伪造痕迹,并提出了一种基于局部相似度异常的深度伪造人脸检测方法,旨在提升深度伪造人脸图像检测模型的泛化性。此外,现有研究发现频域特征中同样包含着区分真伪人脸的重要线索,但目前的工作主要利用预定义的手工高通滤波器或者频域变换来捕捉真伪差异线索,无法自适应地从真伪人脸数据中学习最重要的特征,且所覆盖的频域范围也比较有限,可能遗漏能够辨别真伪人脸的有效信息。为了解决这两个问题,本文借鉴隐写分析领域知识,构建了基于空域富模型(spatial rich model,SRM)的可学习的卷积金字塔模块,弥补了RGB 空间中有限的真伪特征表达能力,提升了库内检测效果。
本文的主要贡献包括3 个方面:1)提出了局部相似度异常预测(local similarity predicator,LSP)模块。将人脸图像的局部深度特征分解为水平组与垂直组,通过计算局部深度特征及其邻域的相似度,将学习目标从识别特定伪造痕迹转换为预测图像内源特征的相似度,以此捕捉更加通用的真伪人脸本质差异。2)提出了空域富模型卷积金字塔(spatial rich model convolutional pyramid,SRMCP)。继 承SRM 核提取高频噪声特性的同时还具有在训练过程中不断更新的能力,并扩展为具有不同感受野的金字塔架构,有效捕捉不同尺度下的高频噪声特征。3)在多个深度伪造人脸的数据集上进行了大量实验。结果表明,仅以小型的18 层残差网络ResNet18(deep residual network-18)为骨干网络,本文方法就能够大幅提升深度伪造人脸检测任务中的表现,在精度、泛化性和抗压缩方面均达到了目前领先水平。
1 相关工作
1.1 深度伪造人脸生成
深度伪造人脸大致包含4 类:1)身份伪造,篡改人脸所表达的身份属性;2)动作伪造,篡改人脸表情以及头部姿态;3)属性伪造,篡改肤色、发型或性别等面部特征;4)全脸伪造,生成完全不存在的人脸。对于伪造人脸的尝试有着很早的历史(Bitouk 等,2008;Blanz 等,2004;De La Hunty 等,2010;Malik,2003;Pighin 等,1998),但在早期,这类技术需要门槛较高的专家知识以及复杂的人工干预,且产物缺乏足够的逼真度,因此并未造成过度危害。然而近几年,随着深度学习浪潮,深度伪造人脸开始出现(Korshunova 等,2017)并经历了爆发式的进展。这类技术主要依赖生成对抗网络(generative adversarial networks,GAN)以及变分自编码器(variational auto-encoder,VAE)(梁瑞刚 等,2020)。时至今日,深度伪造人脸呈现出高分辨率(Naruniec 等,2020)、高真实度(Li 等,2020a)以及多样化的特点,给检测算法带来了极大的挑战(李旭嵘 等,2021)。这类伪造技术的流程中普遍包含利用融合算法将伪造人脸与背景相融合的步骤,导致融合边界残留着局部伪造痕迹,即使肉眼无法观测,也会使像素值统计特性表现异常。
1.2 深度伪造人脸检测
随着深度伪造人脸技术的发展,相对应的检测研究也在不断发展中。早期,一些工作将深度伪造人脸检测问题视做二类分类问题,并尝试利用已有的深度学习模型(Nguyen 等,2019;Sabir 等,2019)或专门设计的模型(Afchar 等,2018;Amerini 等,2019;Wu等,2020)来鉴别伪造人脸。同时,另一些工作从取证的角度出发,借助传统手工特征(Agarwal 等,2017;Zhang 等,2017)进行真伪人脸分类。这些方法虽然在当时取得了一定成效,但缺乏对真伪人脸本质差异的思考,因此面对日益精进的伪造技术,在检测效果上逐渐欠佳。
1.2.1 基于真伪人脸特征差异的检测方法
为了提升检测效果,研究者试图从不同的角度挖掘能够区分真伪人脸差异的特征,并针对性地提出了许多检测方法。例如真实人脸所具有的客观生物信号,如心跳信息(Fernandes 等,2019;Qi 等,2020)、动作行为习惯(Agarwal 等,2019;Li 等,2018)以及嘴唇与声音的同步性(Chugh 等,2020;Zhou 和Lim,2021)均是伪造技术所难以模拟的(王任颖 等,2022),因此被用于检测伪造人脸。时域连续性缺陷也是伪造视频与真实视频的重要差异,研究者由此提出了基于循环神经网络、长短期记忆网络(Masi等,2020;Sabir 等,2019;陈鹏 等,2020)、3 维卷积神经网络(Zhang 等,2021)及帧间特征差异(张怡暄等,2020;祝恺蔓 等,2022)的方法来检测伪造人脸视频。频域能够提供与RGB 空间相互补的真伪线索,为了借助频域信息提升检测效果,一些方法将频域直接作为检测算法的输入(Frank 等,2020;Qian等,2020),另一些则利用频域变换(Chen 等,2021)及滤波等方式提取高频噪声信息作为输入(Han 等,2021)。针对生成图像检测的相关工作(Marra 等,2019;McCloskey 和Albright,2019;Wang 等,2020;Yu等,2019;何沛松 等,2022)表明,深度生成模型生成的图像中包含一种细微且独特的指纹特征(Marra等,2019),这种指纹是识别生成图像的重要依据。有研究发现,相比于空域,在频域中这种指纹更能够反映伪造人脸与真实人脸的差异(Li等,2021)。
然而,如何从频域中提取最有效的真伪差异特征是一个关键问题。将频域特征直接作为输入虽然能够赋予检测模型学习真伪特征的能力,但特征的优劣依赖空域与频域间的变换效果。而借助高通滤波器的方式则限制了频域特征的丰富性,导致关键特征的丢失。与现有工作不同的是,本文所提出的SRMCP,引入了SRM 高通滤波器,并将其表达为可学习的卷积SRMC,使其可以参与模型训练并在训练过程中更新滤波核元素,以此提取最具有判别力的高频噪声特征。另外,为了弥补手工滤波器涵盖频域分布有限的问题,以及以往检测方法中所提出的频域特征尺度单一的问题,本文还将SRMC 扩展为具有多尺度感受野的金字塔架构,自适应地提取人脸图像中的多尺度高频噪声信息,为后续层提供了丰富且具有判别力的特征。
1.2.2 基于伪造算法固有瑕疵的检测方法
伪造技术往往会在人脸与背景的融合边界留下伪造痕迹,这类普遍的痕迹也是最早用于进行伪造检测(Li 和Lyu,2019)与定位(Chen 等,2021;Li 等,2020a;杨少聪 等,2022)的特征之一。Li 和Lyu(2019)首先将人脸从背景图像中剪裁出来进行仿射变换,然后将人脸粘合回原画面,最终利用高斯模糊将变换后的人脸与背景融合。作者通过以上方式动态地生成伪造数据集来训练检测模型,取得了一定成效。Li 等人(2020b)并不直接利用真伪人脸进行二类分类训练,而是通过预测人脸融合边界的方式,使模型关注人脸边界的局部伪造痕迹,忽略其他可能导致过拟合的伪造痕迹。作者也通过动态生成伪造数据的方式来扩展训练数据集,在泛化性上取得了很大提升。
与Li 等人(2020b)工作不同,本文进一步改进了模型的学习目标,将模型从学习伪造人脸边界伪造痕迹转化为学习图像局部特征的相似度,将局部相似度作为判别真伪人脸图像的依据。虽然本文同样考虑的是人脸融合边界的异常,但不直接学习伪造痕迹本身的特征,避免了对特定类型的伪造算法的过拟合。另一方面,本文方法在有效提升泛化性的同时不依赖数据增广,仅在单一数据集上训练的模型就能够实现优秀的跨库检测效果,使得方案的整体复杂度相对较低。
2 本文方法
2.1 方法概览
本文提出了一种基于局部相似度异常的深度伪造人脸检测方法。以包含4 组卷积模块(block)的ResNet18 骨干网络为例,完整的模型结构如图1 所示。该模型首先利用SRMCP 模块从RGB 人脸图像中提取高频噪声信息。可学习的特性使得其在训练过程中能够根据输入数据提取最具有判别力的真伪特征,其多尺度架构能够更加全面地涵盖不同尺度的伪造瑕疵细节,为后续层提供丰富的高频特征。随后,SRMCP 模块的输出被输入到ResNet18 的前3 组卷积模块,模型在此时分为两个分支:1)二分类分支。经过ResNet18的第4组卷积模块并进行最终的二类分类任务;2)局部相似度异常学习分支。4个LSP 模块利用第3 组卷积模块输出的特征图,预测4 幅局部相似度异常特征图。两个分支形成多任务学习架构,有监督地进行训练。为了防止模型学习到特定伪造类型的瑕疵,LSP 不直接利用输入特征区分真伪人脸,而是预测两个局部特征的相似度,使模型不关注特定伪造类型的痕迹,而是提取能够表达局部相似度的源特征,以提升真伪人脸检测的精度与泛化性。为了更加精确地计算局部特征间的相似度特征,本文设计了4 种不同的LSP 来关注局部区域中不同方位、距离的相似度。

图1 基于局部相似度异常的深度伪造人脸检测方法Fig.1 Face forgery detection based on local similarity anomaly
2.2 空域富模型卷积金字塔
空域富模型(SRM)是Fridrich和Kodovsky(2012)所提出的一种隐写分析特征提取方法。该方法利用30 个SRM 高通滤波器(SRM 核)提取图像残差特征并进行量化与截断。残差指某像素的估计值与其真实值之间的差异,具体为
式中,i,j表示图像像素的索引,Nij是中心像素Iij的邻域,Pij表示基于邻域像素Nij对Iij进行预测的估计,Rij表示预测残差。接着,SRM对Rij进行量化,具体为
式中,q为量化因子。最后,SRM 提取残差特征的共生信息作为最终特征,以进行图像的隐写分析。
由于伪造算法对图像高频部分的影响更为显著,因此数字取证领域的许多研究者利用SRM 核作为预处理工具来提取图像高频噪声(Han 等,2021;Zhou 等,2018)。在深度伪造人脸检测任务中,若仅通过RGB 输入学习真伪差异,篡改区域与真实区域在噪声层级的细微差异则难以被全面捕获。为此,本文借鉴SRM 滤波器,从RGB 图像中提取高频噪声特征,作为模型输入。现有研究表明,在30 个SRM核中,仅使用其中特定的3 个就可以有效提取高频噪声,并用于取证任务(Zhou 等,2018)。鉴于此,本文同样选择(Zhou 等,2018)所建议的3 个SRM 核,其具体值如图2(a)所示。

图2 本文采用的3个SRM核以及SRMCP的具体结构Fig.2 The 3 SRM kernels and details of SRMCP((a)the 3 SRM kernels;(b)details of SRMCP)
固定的SRM 核只能学习固定模式的高频噪声,无法自适应地从数据中学习最能够判别人脸真伪的特征。为此,本文设计了一种基于SRM 结构的卷积模块SRMC,将SRM 核融合到网络训练中。具体而言,预先利用量化因子1∕2、1∕4 和1∕12 对所选择的3个SRM核进行量化预处理,并用以初始化包含3个卷积核的卷积层。以上操作允许SRM 核随着网络训练,以梯度下降的方式更新其元素值。为了从RGB 的3 个通道全面提取噪声,本文将每个SRM 核进行通道扩展。具体而言,记图2(a)中的3 个SRM核及其量化因子分别为k1,k2,k3以及q1,q2,q3,则拓展后的核为
式中,i∈{1,2,3}表示核的索引,[·]为通道拼接操作。这样就保证RGB中的每一个通道都能经过3个不同的SRM 卷积核的处理。对于输入图像I,所得到的高频噪声特征为
式中,*表示卷积操作。
原始SRM核的感受野为5 × 5像素,仅能够捕捉固定尺度的噪声特征。而伪造人脸与真实人脸的高频差异往往存在于多个不同尺度。为此,本文将SRMC 进行扩展,设计了一种捕捉多尺度噪声的SRMCP。如图2(b)所示,在原尺度SRMC的基础上,扩充了额外两个SRMC,并将其扩张率分别设置为2和3,即将SRM的元素间隔分别设置为原间隔的2倍和3倍。新增的SRMC分别具有9 × 9像素和13 × 13像素的感受野,与原始SRM核构成了具有3个感受野尺度的卷积金字塔式结构,弥补了原SRM核感受野的尺度局限性。最终,SRMCP将3种不同感受野SRMC的输出进行通道拼接,得到I′′ ∈RH×W×9,作为骨干网络的输入,其中H和W分别表示图像的高和宽。
2.3 局部相似度预测模块
2.3.1 模块构建
人脸伪造的一般流程中往往包含融合人脸与背景的步骤,使人脸边界留下了与周边区域不一致的瑕疵,这种瑕疵具有一定的局部性。一些现有方法试图直接学习这种伪造瑕疵,但是难免会对特定伪造算法产生的痕迹过拟合。为此,本文拟从新的视角出发,提出了一种局部相似度预测模块(LSP),该模块不直接通过学习融合边界瑕疵以区分真伪人脸,而是学习局部区域的相似度。具体而言,若一幅人脸图像满足处处局部相似的条件,则认为它是未经伪造的,若在某些区域违背了该条件,则可以认为该图像经过了伪造。
首先,人脸图像I∈RH×W×3输入到以SRMCP 为第1 层的骨干网络F中,对该网络第3 个block 所输出的深度特征图X=F(I) ∈Rh×w×c进行局部相似度的计算与监督优化,其中h,w,c分别为特征图的高度、宽度和通道数。为了缩减特征维度,降低计算复杂度,并保证局部感受野的适当大小,本文对X进行步长为2 的下采样,以256 × 256 像素的分辨率为例,下采样后特征的空间维度为16 × 16 像素,即h=w=16。可以认为,X中的某个空间位置(i,j)的特征向量xi,j∈Rc是原图中对应位置且大小为(H∕h,W∕w)的局部区域的特征向量。本文设计了一种局部相似度预测模块,从深度特征图中学习图像局部特征的相似度。根据不同方向,本文将局部特征的邻域中的其他局部特征分解为水平组与垂直组。类似地,根据不同距离,将其他局部特征分解为近邻组与次近邻组。考虑到相似度的对称性,水平组与垂直组中的近邻只计算左侧以及上侧的局部特征相似度。针对局部特征xi,j,分别计算其与xi-1,j,xi-2,j,xi,j-1,xi,j-2的相似度。与现有工作中利用余弦相似度来计算特征相似度不同,本文构造了一种基于卷积操作的相似度预测器f,在有监督情况下,从一对局部特征中学习其相似度。针对以上4 种情况,本文设计了4 个权值不共享的预测器fv1,fv2,fh1,fh2,其中,下标v,h分别表示垂直与水平的方向,下标1,2 分别表示近邻与次近邻,则对于xi,j,4个预测器分别计算其相似度S特征图,具体为
根据式(5),可以得到4 幅不同的单通道的局部相似度特征图S*∈[0,1]h×w,* ∈{v1,v2,h1,h2}。
2.3.2 损失函数
由于相似度特征图的学习需要监督信息,因此本文直接根据伪造区域的掩膜(mask)计算其标签。具体而言,对于掩膜M,利用平均池化操作P,以H∕h作为池化窗口的尺寸,将其长宽的尺度缩减到与X相等,使得M′中的一个像素能够对应原图的一块局部区域。具体为
然后,利用M′中的像素点之差作为局部相似度的真实值,为了防止模型学习到特定的伪造痕迹,本文设计了一种硬门限方式来通过M′计算真实值
式中,p,q表示位置索引,即(i,j)的邻近特征的坐标。根据式(7),凡是M′中的像素对不相等,即表明这两个像素所对应的原图区域存在差异。即使原图的两个局部区域均包含伪造区域而面积不同,本文也认为其所具有的特征是不相同的。在训练局部相似度预测模块的过程中,考虑到根据式(7)所得到相似度图的元素值均为0或1,因此利用二值交叉熵损失对该分支进行优化
式中,Si表示预测的相似度图中的第i个元素值,而是真实相似度图中的第i个值。为了简洁,式中不区分4 种相似度图,其计算操作均如式(8)所示。由此,训练本文模型的完整损失为
式中,第1项为LSP的训练损失(L),第2项为模型主分支中的二值交叉熵损失(BCE),y和分别表示输入图像的标签与模型预测值,a和b分别为两个损失的权重。
3 实验与分析
3.1 实验设置
本文所有实验基于Pytorch 1.9 框架实现,操作系统为CentOS 7.0,搭配4 块RTX 3090 24 GB 显卡、2 块Intel Xeon Gold 6126@2.60 GHz 处理器。所 有模型的训练均使用Adam 优化器,学习率为1E-3,不采取其他任何学习率调整策略。用ImageNet权重对ResNet18 骨干网络进行初始化,模型训练轮数为50,批次大小为32,每轮200次迭代。损失函数权重a与b均为0.5。所有人脸根据FaceForensics++(FF++)中DeepFakes 所对应mask 的2.6倍进行裁剪得到,并统一缩放为256 × 256 像素的矩形。另外,为了保证实验结果的可靠性,本文未使用额外数据集与数据增广(包括随机剪裁或翻转等)。
3.2 数据集与评价指标
在数据集方面,本文以FF++(Rössler 等,2019)作为模型训练与测试的主要数据集。该数据集由4 类不同算法制作的伪造人脸组成,分别为DF(DeepFakes)、F2F(face2face)、FS(FaceSwap)和NT(NeuralTextures)。其中,DeepFakes 和FaceSwap 是由深度生成模型制作的换脸视频数据集,Face2Face和NeuralTextures 是由图形学技术制作的表情操控数据集。每个子集均包含1 000段视频,划分为720∕140∕140的训练∕验证∕测试集。根据H.264 编码中的固定码率系数不同,该数据集具有3个质量等级:未压缩(RAW,CRF=0),轻微压缩(HQ(high quality),CRF=23)与重度压缩(LQ(low quality),CRF=40)。同时,为了验证所提出方法的泛化性能,本文还在Celeb-DF 数据集上进行了跨库测试。Celeb-DF 由590 段真实的名人采访视频和5 639 段伪造视频组成。其中,人物的性别、年龄和种族分布各不相同,且相较于FF++,该数据集视觉效果更好,检测难度更大。
在实验指标方面,本文使用二分类精度(binary classification accuracy,Acc)以及曲线下面积(area under curve,AUC)对算法进行评估。
3.3 库内精度对比分析
3.3.1 FF++总体精度
首先对比了FF++中3 个不同压缩条件下的总体结果,并对比了现有典型算法以及最先进算法的结果。如表1 所示,以ResNet18 作为骨干网络的本文方法在无损以及有损版本上都达了极高的检测精度。不仅大幅超越了经典的数字取证算法,也超越了一部分针对深度伪造检测的先进算法。具体而言,本文方法在RAW,C23 以及C40 上分别达到了99.72%、98.34%以及90.73% 的Acc。相比于Xception,本文方法的平均精度高出2.31%。相比于同类较为轻量的MesoNet(Afchar 等,2018),本文方法的平均精度高出13.33%,在C40 数据集上甚至高出20.26%。另外,与发表于CVPR 2021的一种融合了频域与空域瑕疵的度量学习方法(Li 等,2021)相比,Acc 分别高出了0.29%、1.65%以及1.22%。与基于噪声输入和RGB 输入的双流融合算法(Kong等,2022)相比,本文方法虽然在C23 版本上的精度落后0.06%,但在C40 版本上大幅领先了5.89%。总体而言,本文方法在抗轻微压缩方面的精度处于领先水平,而在对抗重度压缩时普遍高出目前最新的工作至少2%。该结果表明,本文提出的局部相似度模块能够有效捕捉伪造人脸的固有特征,因此在检测效果上带来了大幅提升,即使以简单的ResNet18作为骨干网络,也能够达到较高精度,且在不同压缩情况下都保持着有效性。

表1 FF++不同压缩率下的精度(Acc)Table 1 Accuracies of different compression level of FF++/%
3.3.2 FF++子集精度与对比
为了更全面地衡量本文方法的效果,表2—表4给出了本文方法与一些现有方法在DF、F2F、FS 和NT等4个子集上的具体精度。

表2 FF++无压缩版本上的精度(Acc)Table 2 Accuracies of FF++(RAW)/%
表2给出了RAW 下4个子集的具体精度。由于该数据集检测难度较低,因此本文仅对比了骨干网络ResNet18 以及常用基准模型Xception 的效果,以表明本文方法对常规模型在检测效果上的巨大提升。ResNet18 在RAW 数据集上已经能够达到可观的精度,复杂度更高的且更深的Xception 的精度则进一步提升。本文方法使ResNet18 骨干的总体精度超越Xception,且在DF 与FS 上的精度提升到了100%。
表3 展示了本文与现有最优方法的对比。首先,在SRMCP 与LSP 的帮助下,ResNet18 的性能全面高出了更深、更复杂的Xception 网络,在Xception精度几乎饱和的情况下,平均精度仍然高出了0.86%,且保持在稳定的较高水平,而同样的轻量化MesoNet 在NT 子集上的效果则发生大幅下降,缺乏稳定性。其次,相较于Yang 等人(2021)的方法,本文在DF、F2F 与NT 上的精度分别提升了0.92%、1.39%以及0.53%。虽然F2F 上的精度要小幅落后,但总体平均精度仍然高出0.48%。而相比于同样利用了频域特征的Qian 等人(2020)的方法,4 个子集的精度则分别高出了1.13%、0.37%、1.47%和1.91%。

表3 FF++轻微压缩版本上的精度(Acc)Table 3 Accuracies of FF++(HQ)/%
表4 详细展示了本文方法在对抗C40 压缩时的效果。可以发现,在面对高压缩情况时,传统取证方法的效果极差,远远落后于现有的最优方法。在Hu等人(2021)的方法中,借助了视频帧间的残差信息,设计了一种抗视频压缩的检测方法。但本文方法在3 个子集上的效果仍然以2.48%、4.83%和10.10%的精度差距超越了Hu 等人(2021)的方法中的视频级检测结果。同时,相比于Liu 等人(2021)的方法,本文方法的平均精度也要高出3.59%。与Liang 等人(2022)最新发表于ECCV2022 的基于解耦学习的方法相比,本文方法在4 个子数据集上的平均精度高出约2%,而该方法所采用的骨干网络是比本文更深且容量更大的ResNet50。

表4 FF++高压缩版本上的精度(Acc)Table 4 Accuracies of FF++(LQ)/%
虽然本文方法并没有在全部4 个子集上达到最优精度,但总体结果仍表明本文方法在对抗高压缩深度伪造人脸上的有效性,对于各种类型的数据集以及极端压缩情况下都能够保持极佳的检测精度。
图3 展示了不同模型在训练阶段中验证集的精度,图3(a)—(d)分别表示DF、F2F、FS 以及NT 上的结果,以上4 个数据均为C23 压缩版本,水平虚线表示50 轮结果的平均值。根据图中验证集精度(Val Acc)变化曲线可以发现,ResNet18 在面对C23 压缩时,不仅精度不高,而且训练过程不稳定,验证集精度波动大,Xception 则具有相对更高的精度与稳定性。而本文方法大幅提升了ResNet18 的效果,总体训练过程具有更好的稳定性,且训练过程中的验证精度的均值全面高于Xception。

图3 不同模型在训练过程中验证集精度变化Fig.3 Val Acc changes of different models during training((a)Val Acc in training(DF);(b)Val Acc in training(F2F);(c)Val Acc in training(FS);(d)Val Acc in training(NT))
3.3.3 LSP与SRMCP可视化
图4 展示了局部相似度模块的预测结果。其中,横向第1组表示伪造人脸,第2组均为真实人脸,人脸图像右侧的黑白二值图像是反映篡改区域的mask,像素值为0 的黑色区域代表未经篡改,像素值为1 的白色区域则表示经过篡改。人脸图像下方的GT表示根据mask与式(7)所计算得到的4种局部相似度的真实值,同样为二值图。相似度1、2 分别表示邻近与非邻近区域所计算得到的相似度。其中白色区域为1,表示局部存在相似度异常;黑色区域为0,表示局部相似度不存在异常,右侧为本文方法的预测值。可以看出,不同伪造算法的伪造区域与形态不同,GT 也显示出不同的形态,而本文的局部相似度预测模块均能够准确预测出不同类型深度伪造人脸中的局部相似度异常区域,使得本文方法不仅具有很高的检测精度,还一定程度上实现了篡改定位的功能。对于真实人脸,本文方法也能够给出全局相似度正常的结果,预测值均接近0。

图4 局部相似度预测模块的输出结果Fig.4 Output results of LSP
图5 展示了SRMCP 的输出,可以发现,不同SRMC 关注着不同的高频噪声。第1 个SRM 卷积核由于其特性更为简单且感受野较低,所提取的高频分量更为广泛。与此同时,第3 个核的特性更为复杂,所提取的高频分量也更加具有针对性。另外,相同SRMC 的不同尺度的提取结果也不相同。尺度更大的核由于感受野更大,因此也更具有全局性,例如SRM 卷积核1,更大尺度的核更能够关注人脸的边缘部位,忽略皮肤与背景等区域的高频信息。

图5 SRMCP的输出结果Fig.5 Output results of SRMCP
3.4 跨库精度对比分析
真实场景中的深度伪造人脸检测对泛化性提出了很高要求,要求模型在测试不同数据集时也保持较高的精度。由于FF++中4 个子集由不同伪造算法制作,视觉质量以及瑕疵特点各不相同,在单个子集上训练的模型往往无法很好地泛化到其他数据集,跨库检测精度有限。为了验证本文算法的跨库检测效果,本文测试了FF++中4个子集的相互跨库检测精度。具体结果如表5 所示,本文分别在FF++中的1 个子集上训练模型,并报告了全部子集包括其他3 个未参与训练的子集上单独测试的AUC结果。

表5 FF++上的跨库AUCTable 5 AUC of cross domain evaluations on FF++/%
从表5中可以发现,本文方法在4个子集上的平均跨库AUC 分别达到了91.40%、96.03%、99.08%和96.05%,相较于Xception 分别提升了15.41%、16.47%、24.11%和14.70%。Xception 的结果表明未经特殊设计的模型,即使具有较强的特征提取能力,在跨域测试上的效果也比较欠佳,而本文方法通过将二类分类问题转化为图像内局部特征相似度异常的识别,挖掘了深度伪造人脸具有的普遍特征,即使利用较为简单的ResNet18 骨干网络,也具有较高的泛化性。Li等人(2020b)的方法中,通过预测伪造人脸的融合边界来提升泛化性,同样取得了很好的跨库精度。但本文模型的平均精度与Li 等人(2020b)的方法相比,分别提升了0.77%、5.59%、6.11%和4.28%,表明本文方法通过优化学习目标,更能够避免对特点伪造类型的过拟合。值得注意的是,该方法使用的骨干网络是更为复杂的HRNet。
图6 展示了本文方法在跨数据集上的相似度预测结果,即利用DF 训练的模型,分别对其他类型的伪造人脸进行预测。与图4 中的结果类似,由于DF算法的伪造人脸是矩形区域,因此模型在预测相似度异常区域时往往更倾向于预测垂直或水平方向的直线边框。可以发现,即使在模型未见过的伪造类型上,所提出的方法仍然能够有效地预测出显著的相似度异常区域。虽然预测结果不具有很好的定位功能,但能够充分证明人脸的真伪。

图6 跨数据集局部相似度预测模块的输出结果Fig.6 Output results of LSP in cross domain evaluation
本文方法在FF++上训练的库内测试结果以及在Celeb-DF 上的跨库测试结果如表6 所示,评估指标均为AUC。可以看出,早期方法不仅库内精度不高,而且跨库效果极差。与此同时,虽然最新的伪造人脸检测方法在库内以及跨库上都取得了显著提升,但本文方法仅借助ResNet18 网络,在两方面效果上均超越了已有方法。虽然近年方法与早期方法相比,跨库效果取得了明显进度,平均精度超越70%,但本文方法即使与2022 年方法相比,跨库精度也依然高出1.11%、3.73%以及5.17%。表明本文方法不仅库内精度几乎饱和,跨库精度也得到了大幅提升。

表6 Celeb-DF数据集上的泛化性能结果精度对比Table 6 Accuracies of cross domain evaluations on Celeb-DF/%
3.5 消融实验与有效性分析
3.5.1 消融实验
为了证明所提出SRMCP 模块以及LSP 模块的有效性,表7 展示了消融实验的结果。具体而言,以ResNet18 为基准,分别逐步增加SRMCP 以及LSP 模块,并报告了FF++在3 种不同压缩率下的平均结果。可以发现,单独增加SRMCP 与LSP 均能够带来有效的精度提升。而相比于SRMCP,LSP 对于模型精度的积极影响不仅更大,也更加全面,在3 种压缩率下实现了全方位的提升。SRMCP 对于C40 的效果较差,这可能是由于严重的图像压缩操作抑制了高频信息中真伪人脸的差异,RAW 以及C23 压缩条件下0.74%和0.95%的提升也佐证了这一点。与此同时,图像压缩对LSP模块的影响则相对较小,相比于原始ResNet18,分别提升了1.08%、3.13%和1.22%。当两种模块结合时其平均精度进一步提升,比原始网络高出1.82%。
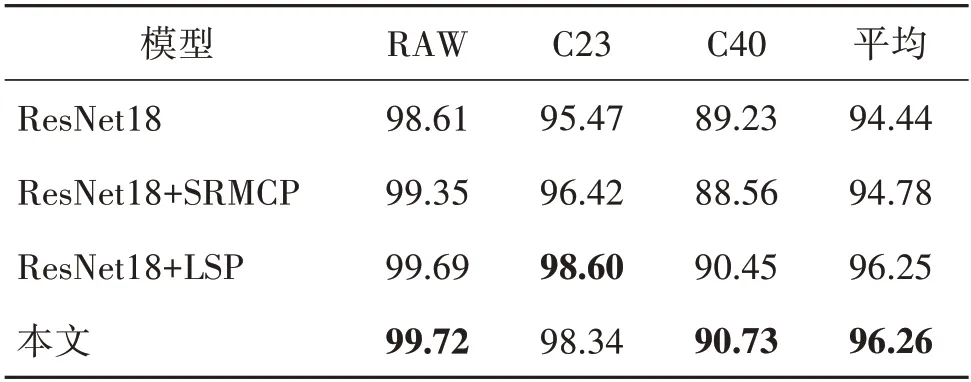
表7 SRMCP与LSP模块的消融实验结果(Acc)Table 7 Accuracies of ablation studies on SRMCP and LSP/%
3.5.2 超参数对比实验
在之前的实验中,本文均将ResNet18 的第3 个block 输出的特征图下采样到16 × 16 像素进行局部相似度的计算,使得特征图中的一个像素点对应原图中16 × 16 像素的局部区域。本文额外测试了不同局部区域尺寸的影响,具体操作为:1)将下采样操作中的窗口边长扩大为4,将特征图缩小为8 × 8 像素;2)取消下采样操作,将特征图保持为32 × 32 像素。以上操作使得特征图种的一个像素点分别对应原图中32 × 32 像素以及8 × 8 像素的局部区域。具体结果如表8 所示,可以发现,在多数情况下,16 ×16像素的局部大小能够获得最优的精度,而8 × 8像素的局部大小则在高压缩情况下更加具有一定的优势。

表8 不同分块尺度下的精度Table 8 Accuracies of different patch size/%
为了进一步测试LSP 模块位置的影响,设计了模型的两个变种,分别将LSP 模块的位置施加在ResNet18 第4 个和第2 个卷积模块后,记做T0 与T2模型,而前文的设置则记做T1。表9 报告了不同LSP 位置对于精度的影响,本文在C40 条件下测试了不同子集的精度。总体而言,第3 个模块后施加LSP 能取得最好效果。这可能是由于若LSP 靠近模型底层,则难以约束模型高层特征具有泛化性,而越靠近高层,模型越难以收敛。

表9 LSP在模型不同位置的精度Table 9 Accuracies of different position of LSP/%
前文的训练一直未采取任何数据增广策略,为了研究数据增广对检测效果的影响,本文额外对比了有无数据增广的差异。通过水平翻转、随机裁剪、随机缩放、基于双线性插值、三次样条插值、最低质量以及最高质量插值的重采样等操作来进行数据增广。图7(a)(b)分别对比了C23 和C40 条件下不同数据集在有无数据增广下的精度。数据增广对于C23 的作用并不明显,甚至在FS 和NT 上是负收益。而对于C40,则有略微的提升效果,平均精度提升了0.45%。结果表明,常规的数据增广对模型检测精度的影响较小。
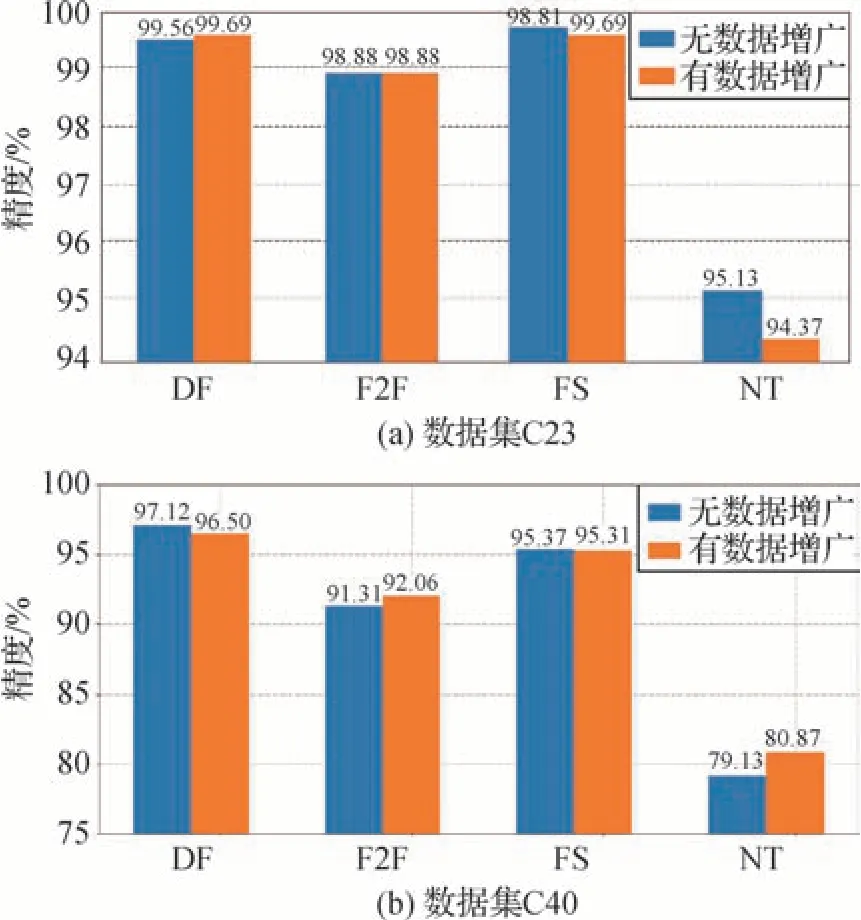
图7 本文方法有∕无数据增广结果对比Fig.7 Effect on data augmentation of proposed method((a)dataset C23;(b)dataset C40)
3.5.3 参数量与计算复杂度
本文方法在参数量以及计算量等方面带来的增长主要由SRMCP 模块以及LSP 模块带来。为了评估模型复杂度,本文采取了4 个指标对参数量和计算量消耗进行全面分析,包括:1)参数量(单位M),用来衡量模型的参数数量;2)浮点运算数(floating point operations,FLOPs,单位G),表示模型在一次前馈过程中需要的浮点运算次数,用来衡量模型的计算复杂度,其中,单位G 表示109次,单位M 表示106次;3)前馈耗时(单位ms),指模型一次前向传播的消耗时间;4)反馈耗时(单位ms),指模型一次反向传播的消耗时间。其中,参数量与浮点运算数可以由静态的模型计算得到精确值,而前馈耗时与反馈耗时由于计算设备与运行状态的差异,存在一定浮动。因此,本文给出了这两个指标在104次实验中的平均值作为参考,每次实验批次大小均为1。具体结果如表10 所示,以ResNet18 为骨干网络,逐步增加SRMCP 与LSP 并计算以上4 个指标,表10 同时还给出了Xception的结果。
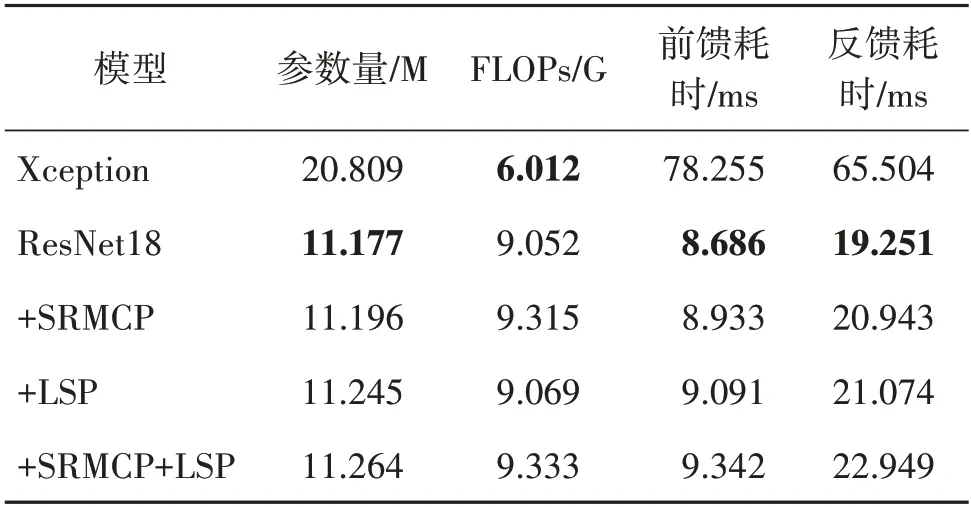
表10 参数量与计算量对比Table 10 Comparisons of parameters amount and computing power consumption
可以发现,在参数量上,SRMCP 与LSP 仅分别增加了约0.019 M 和0.068 M 个参数,相比于基准模型ResNet18,相对参数量仅增加了0.169%和0.608%。总体而言,在加上所提出的2 个模块后,参数量仅增加了0.778%,但却在FF++多个压缩条件下带来了1.92%的平均相对精度提升,以及Celeb-DF 跨库条件下16.47%的相对精度提升。在计算复杂度上,两个模块带来了额外的0.281 G 计算量,相比基准模型仅增加了3.104%。在耗时方面,模型的前馈与反馈耗时分别增加了0.656 ms 和3.698 ms,相对增加7.552%和19.209%,属于可接受范围内。虽然Xception 中的深度可分离卷积有效控制了参数数量并减少了理论计算量,但实际的前馈与反馈耗时远大于本文方法,且Xception 在FF++库内跨域精度比本文方法低17.673%。
3.5.4 特征可视化
图8 展示了本文模型和ResNet18 在DF 数据集上训练后,不同类型伪造人脸的特征的分布。具体而言,利用T-SNE 将最后一层的特征降维至2 维后进行展示。其中蓝色点表示真实人脸的特征,紫色、黄色和绿色点分别表示DF、F2F 和NT 伪造人脸。可以发现,利用DF 训练的ResNet18 的特征空间中,真实人脸和DF人脸可以得到很好的区分,但真实人脸与F2F 及NT 的特征分布却存在大面积重叠。而本文模型在成功区分真实人脸与DF人脸的同时,也能够很好地区分F2F 以及NT 人脸,佐证了本文算法所具有的泛化性优势。

图8 特征经过T-SNE降维之后的分布Fig.8 Visualization of feature distribution using T-SNE((a)ours;(b)ResNet18)
4 结论
本文提出了一种基于局部相似度异常的深度伪造人脸检测方法,针对伪造算法存在的通用瑕疵,设计了一种细粒度的局部相似度异常预测模块,将真伪人脸检测二类分类问题转化为人脸图像全局相似度度量问题,并提出了一种空域富模型卷积金字塔,捕捉图像中的多尺度高频噪声,为最终分类提供更加具有判别力的特征。实验表明,本文方法能够大幅提升小型卷积神经网络对不同深度伪造人脸的检测效果,在对抗视频压缩以及跨域检测上与现有最优方法具有相当的竞争力。未来工作旨在对局部相似度学习模块进行进一步优化,保证其能够预测具有不同类型的伪造人脸的局部异常,以进一步提升对未知伪造人脸的泛化性效果。
猜你喜欢
艺术家(2023年8期)2023-11-02
小哥白尼(军事科学)(2022年2期)2022-05-25
中学生数理化·七年级数学人教版(2022年11期)2022-02-22
少儿美术·书法版(2021年9期)2021-10-20
数学物理学报(2021年2期)2021-06-09
红领巾·萌芽(2019年8期)2019-08-27
动漫星空(2018年9期)2018-10-26
发明与创新(2016年38期)2016-08-22
艺术生活-福州大学厦门工艺美术学院学报(2016年3期)2016-07-31
CHIP新电脑(2016年3期)2016-03-10
