
混合双注意力机制生成对抗网络的图像修复模型
2023-11-22 01:19兰治严彩萍李红郑雅丹
中国图象图形学报 2023年11期
兰治,严彩萍*,李红,郑雅丹
1.杭州师范大学,杭州 311121;2.杭州启源视觉科技有限公司,杭州 311121
0 引言
在计算机视觉领域,图像修复是一项长期且关键的挑战。图像修复算法试图用合理的和语义上可接受的信息来修复图像缺失区域。一种有效的图像修复算法可以应用于许多现实场景,例如对象移除、图像恢复以及照片修复。过去已经提出了多种用于图像修复的方法。然而,当单幅图像的缺失部分较大时或修复的场景比较复杂时,大多数方法很难得到合理并且令人满意的结果。现有方法通常分为传统方法和基于深度学习的方法两类。
为了满足人们对于图像修复的需求,早期提出许多基于扩散(Drori 等,2003)和基于块(Barnes 等,2009)的传统方法。由于基于扩散的方法恢复缺失的区域,是从边界朝着等值线的方向进行处理,当修复区域较大或较复杂时,这些方法往往不能很好地完成图像修复。无独有偶,基于块的方法如 Barnes等人(2009)提出PatchMatch,通过检测图像块之间估计的最近邻匹配,然后复制粘贴到待修复区域进而修复缺失区域。当然,这些方法可以在某些简单的情况下取得不错的效果,但是当缺失的区域较大或较复杂时,它们因为无法找到既符合逻辑又符合视觉习惯的块,同样也无法满足人们的需求。
近年来,基于深度学习和对抗学习的图像修复方法取得了越来越令人满意的结果。深度图像修复模型大多基于生成对抗网络和基于重建损失和对抗损失的联合优化。在小范围或常规修复方面,现有的深度学习模型(Yu 等,2018;Iizuka 等,2017)均表现出比较乐观的效果。然而,这些方法通常在整个网络上使用的都是常规的卷积操作,可能只是通过修改卷积核的大小或增加卷积操作的层数,而不是用一些有效的方法进行特征提取和特征生成,导致网络通常只“看到”局部区域并用局部特征来完成受损图像的修复工作。因此,在高分辨率图像中很难恢复大面积的缺失区域。为了使网络能够学习到更广泛的特征信息,Nazeri 等人(2019)提出的EC(edge connect)和Zeng 等人(2023)提出的AOT-GAN(aggregated contextual transformations generative adversarial network)使用空洞卷积而不是常规卷积。虽然空洞卷积可以捕捉到更远的内容,但叠加空洞卷积经常会产生网格伪影,而且它本质上没有考虑全局结构信息,只扩大了局部感受野。
为了解决上述问题,本文提出了一种用于图像修复的混合注意力生成对抗网络(hybrid dual attention generative adversarial network,HDA-GAN),其包括一个生成器和一个鉴别器。生成器通过在网络的不同层引入两种级联的注意力传播模块,既捕获全局结构信息,又捕获局部细节纹理;鉴别器促进生成器对缺失区域的产生。同时,引入了对抗损失函数、L1损失函数LL1、感知损失函数Lpercept和风格损失函数Lstyle。
与此同时,深度学习网络的浅层卷积操作编码低水平空间视觉特征,如边缘、角、圆等,可能有助于生成更好的边界,用于高分辨率图像修复。对高级语义特征如物体或类别级证据进行深层的编码可能有助于对图像区域进行正确分类。然而,深度卷积层的高级语义特征缺乏强空间信息。幸运的是,研究发现,描述对象部件特征的中间层仍然保留了令人满意的空间信息(Lin等,2017)。如何有效地开发和合并所有级别的特性仍然是一个有待解决的问题,值得更多的关注。
因此,本文提出在网络的不同层中嵌入不同的注意力模块来有效地合并多层次的特征。具体来说,本文设计了一个用于低级特征学习的级联通道注意力传播模块,该模块将几个多尺度通道注意力块串联起来,从低级细节学到高级语义。同时,本文设计了一个用于中高层特征的级联自注意力传播模块,该模块将多个基于分块的自注意力块堆叠在一起,在捕获长期或全局语义依赖的同时保存更多的细节。
本文的贡献可归纳如下:1)提出一种新的生成对抗图像修复网络HDA-GAN,该网络通过融合两个精心设计的注意力传播模块,可以为失真图像生成合理且令人满意的内容。2)提出一种新的级联通道注意力传播模块,该模块通过连接多个多尺度通道注意力块来将低级视觉特征编码为高级语义特征。3)提出一种新的级联自注意力传播模块,通过叠加多个基于分块的自注意力块来更好地维护细节,同时学习长期和全局语义信息交互。特别是与原来的自注意力相比,该设计还有效地降低了计算复杂度。4)对自然景观数据集Paris Street View(Doersch 等,2012)和人脸数据集CelebA-HQ(CelebA-high quality)(Karras 等,2018)进行了大量的实验。结果表明,本文模型优于对比方法。
1 相关工作
图像修复的目的是恢复受损的照片。由于图像的普遍使用和对图像编辑软件越来越高的要求,大量研究学者优化了图像修复算法。本节将图像修复方法分为传统图像修复方法和基于深度学习图像修复方法两类。
1.1 传统图像修复方法
基于扩散的传统方法将有效像素传播到缺失区域。具体地,在像素传播过程中,利用偏微分方程施加一些边界信息。由于使用了边界信息的先验知识,所有基于扩散的算法都不能很好地修复大区域的细节纹理和复杂结构。
基于块的方法通常从有效的图像信息或已知的图像背景中搜索一些相似的块来填补缺失的像素。虽然这类方法在修复详细的纹理和填补大的空洞方面更加出色,但它们通常会产生巨大的计算量。为了降低计算成本,Barnes 等人(2009)提出了一种新的方法,即块匹配,用于高效地寻找图像块之间的近似最近邻匹配。Komodakis 和Tziritas(2007)提出了一种将基于块的修复与全局相关度测量和全局优化算法相结合的方法。当图像中缺失的像素被嵌入重复的图案时,这些方法通常可以很好地修复图像,但是由于它们无法产生新块,缺乏语义结构理解,修复的图像效果可能不符合逻辑。
1.2 基于深度学习的图像修复
近年来高速发展的深度特征学习和对抗训练都极大地提高了图像修复的效果。因此,越来越多的研究工作转向了基于深度学习的方法(强振平 等,2019;张桂梅和李艳兵,2019;刘坤华 等,2021;杨红菊 等,2022)。与传统方法相比,基于深度学习的图像修复方法能够针对人脸和大区域的复杂自然场景合成更合理可靠的内容。
基于深度学习的图像修复是为了学习一种直接映射来预测缺失内容(Wang等,2021)。早期的一些方法在修复细小的缺失区域效果还不错。但在复杂的场景中,这些方法无法填补较大且不规则的空洞。通过网络结构越来越强大的表现能力和更大规模端到端的训练以及多种损失函数,可以更加有效地修饰高级语义结构。
在前者开创性的研究中,如Pathak 等人(2016)首先提出使用一种结合重建损失函数和对抗损失函数的编码—解码网络来提取特征并重建缺失内容。由于该模型中使用了全连接层,它只能处理低分辨率图像和形状规则的缺失区域。为了解决这一问题,Iizuka 等人(2017)提出了一种基于全卷积网络(fully convolutional networks,FCN)的模型,其中包括两个鉴别器,将全局鉴别器和局部鉴别器联合训练,使结构更合理,背景更清晰。为了在FCN 的基础上进一步提取受损图像中的上下文信息,Yu 等人(2018)和Liu 等人(2019)的方法中提出了一个上下文注意力模块,通过逐块匹配的方法从上下文中找到感兴趣的块。与此同时,Zeng 等人(2019)提出了一种新的非局部模型,名为注意力转移网络(attention transfer network,ATN),其作用是填补图像级的内容或特征级的缺失区域。即使非局部模块可以使用远处的上下文信息来恢复图像细节,但这些模块通常会导致缺失区域出现重复模式和不合理的结构。为了解决重复模式的问题,Sagong 等人(2019)提出使用空洞卷积来捕捉更远的上下文信息。通过空洞卷积不同的空洞率可以有效地扩大卷积核的感受野,更重要的是可以将周围的信息传递到目标区域。为了获取用于上下文推理的大面积特征区域,研究人员经常将空洞卷积堆叠起来使用。然而,堆叠使用空洞卷积往往会出现网格状伪影的现象,因此这些方法也无法很好实现图像修复。同上述方法对比,本文提出了一种精心设计的单阶段方法,可以修复出更令人满意的结果。它不同于从粗糙到精细的多阶段方法,也不同于引入辅助特征的方法,它是一种新型端到端的网络架构,称为HDAGAN(hybrid dual attention generative adversarial network)。
2 方法
图像修复试图为失真的图像生成令人满意和可信的内容。如图1 所示,本文提出的生成式对抗图像修复网络建立在生成对抗网络(generative adversarial network,GAN)上,即由生成器网络和鉴别器网络组成。此外,为生成器和鉴别器设计的基本网络都是基于U-Net 框架的。众所周知,U-Net 广泛作用于端到端图像修复的基础网络框架,因为它的跳跃连接可以保持底层信息,并允许网络的其余部分专注于重建损坏区域。因此,本文使用U-Net 作为研究的基础框架,但是对其进行了必要的改变。具体来说,生成器网络引入了两个精心设计的级联注意力传播模块:一个是级联的通道注意力传播模块;另一个是级联的自注意力传播模块。此外,级联的通道注意力传播模块和级联的自注意力传播模块分别由多个多尺度通道注意力块和基于分块的自注意力块组成。同时,鉴别器与EC 的鉴别器网络是一样的,可以促进生成器网络构造更合理的纹理。

图1 混合注意力生成对抗网络(HDA-GAN)整体结构Fig.1 The overview of the Hybrid Attention generative adversarial network
2.1 生成器网络架构
如图2 所示,生成器网络以U-Net 为基础架构,由精心设计的两个级联注意力传播模块(级联的通道注意力传播模块和级联的自注意力传播模块)构成,能够增强上下文推理和纹理生成。更具体地,级联的通道注意力传播模块是由几个多尺度通道注意力块构建的,并在生成器的浅层的跳跃连接中使用,用于理解从低级细节到高级语义的所有特征。级联的自注意力传播模块在生成器的深层跳跃连接中堆叠了多个基于分块的自注意力块,以关注全局结构信息和局部细节纹理。

图2 生成器网络的结构Fig.2 The overview of the generator network
实际中,生成器网络的输入包含4 个通道,可以表示为
式中,Igt表示真实图像,m表示掩码图像(已知区域像素值为0,缺失区域像素值为1),⊙表示像素相乘,⊕表示通道的级联。生成器网络的输出Ipred表示为
式中,G表示生成器网络,⊙表示逐像素相乘。则修复好的结果Icomp可表示为
式(3)表明最终的修复结果Icomp是由Igt中属于已知区域的像素和在Ipred中对应修复好缺失区域的像素构成。对于基本框架,使用4 × 4 的卷积核、步幅大小为2、填充像素个数为1 进行下采样,使用双线性插值和3 × 3 的卷积核、步幅大小为1 和填视像素个数为1 进行上采样。此外,在生成器网络的跳跃连接中使用一个步幅大小为1、填充像素个数为1、卷积内核大小为1 × 1的卷积操作。本文用Icomp和Igt作为鉴别器的输入来训练鉴别器,输出是真或假。
2.2 级联的通道注意力传播模块
在本节中,提出了一种新颖的级联通道注意力传播模块,以加强对生成器特征提取的训练。为了保证原始图像区域和修复区域的结构一致,深度图像修复模型需要学习更多的全局结构信息。另一方面,需要修复的图像通常是具有复杂场景的高分辨率图像。对于纹理生成来说,使网络获取尽可能丰富的局部细节是非常重要的。因此,将级联通道注意力传播模块集成到生成器的浅层中,从低级细节到高级语义学习特征。此外,级联通道注意力传播模块由几个相同的多尺度通道注意力块串联而成,下面将详细介绍多尺度通道注意力块的设计。
多尺度通道注意力模块采用分离—注意力—合并策略和残差—门控操作,如图3 所示,其中的注意力是通道注意力。对于分离—注意力—合并策略,主要由3个步骤实现:

图3 多尺度通道注意力块模块Fig.3 The details of the MSCA block
1)分离。首先通过1 × 1 卷积减少特征映射的通道,这个操作主要为了控制计算成本。然后为了保证学习图像特征的同时能够学习全局结构信息和局部纹理信息,利用不同步长、不同卷积核大小得到多通道、多尺度的特征。例如,在这一步中,输入一个张量c×h×w,输出n个张量,如1c×h×w、2c×h∕2×w∕2,…,nc×h∕2n-1×w/2n-1。
2)注意力。每个输出特征先送到通道注意力(Fu 等,2019),然后通过卷积和双线性插值进行上采样到同样的大小和同样的通道数。具体来说,通道注意力通过整合所有通道映射之间的关联特征,选择性地强调相互依赖的通道映射。该网络通过多尺度通道注意力,提取通道之间不同分辨率的通道特征信息,既能关注局部纹理,又能关注全局结构,进一步增强网络修复图像的能力。
3)合并。将步骤2)之后来自不同通道的上下文映射最后通过拼接和普通的卷积进行特征融合。
经过上述3个步骤,从张量y1得到了张量y2。
由于残差连接的一致性以及ResNet(residual network)和聚合变换(Xie 等,2017)的有效性,输入特征y1和通过学习到的残差特征y2忽略了缺失区域内外输入像素的差异,导致输入图像的色差问题。因此,通常会在构建块中包含一个相同的剩余连接。残差—门控连接(Zeng 等,2023)通过普通的卷积和sigmoid 激活函数操作,从y1计算出空间变化的门控值g,然后通过注意力块与g加权求和,将输入特征y1和学习到的残差特征y2聚合起来,记为
这种类型的空间变换特征聚合支持空区域内的特征更新,而只保留缺失区域外的已知特征。
通过上述分离—注意力—合并策略和残差—门控操作,多尺度通道注意力块能够聚合多个通道相关性,增强高级语义的同时保留低级细节。此外,级联通道注意力传播模块将几个多尺度通道注意力块连接起来,极大地丰富了生成器网络中低级特征的组合,帮助生成器获取尽可能多的有用信息,用于纹理生成和上下文推理。
2.3 级联自注意力传播模块
在本节中,提出了另一个级联注意力传播模块——级联自注意力传播模块,该模块应用于生成器的中间层和深层的跳跃连接中,在捕获长期或全局语义依赖的同时保留更多细节。具体来说,级联自注意力传播模块也由几个相同的连续块组成,唯一的区别是连续的每个块都是基于分块的自注意力块。
基于分块的自注意力块采用了与多尺度通道注意力块相同的分离—注意力—合并策略,但是本文进行了一些改变,并采用相同的残差—门控操作,如图4 所示,其中的注意力是自注意力。具体步骤如下:

图4 基于分块的自注意力块模块Fig.4 The details of the PSSA block
1)分离。级联自注意力传播将输入张量分割为m×m个具有相同分辨率和相同通道数的张量来控制计算成本。也就是说,如果在分裂后输入一个张量c×h×w,将会得到m×m个张量c×h/m×w/m。
2)注意力。由于自注意力机制的操作能够处理学习特征之间全局的交互然后聚焦到局部,进而对特征图中的远程依赖关系建模,将m×m个张量送入到自注意力(Zhang等,2019)中输出m×m个注意力张量。值得一提的是,与原有的自注意力算法相比,该算法能有效降低计算复杂度,更专注于局部纹理。
3)合并。m×m个不同张量最后通过拼接合并,再通过普通的卷积操作进行特征融合。
经过上述3 个步骤,张量x1变成了张量x2。此外,级联自注意力传播模块使用了与多尺度通道注意力块相同的残差—门控操作,该操作在2.2 节中已经介绍。上述操作可以表示为
该设计的目的是利用基于分块的自注意力块能更好地维护细节,同时学习远程语义信息交互。值得注意的是,与原来的自注意力相比,该设计还有效降低了计算复杂度。此外,级联自注意力传播模块通过叠加多个基于分块的自注意力块明显地增强了从局部或长距离相关性到全局结构的传播。
2.4 损失函数
生成器网络在一个联合损失函数上训练,该联合损失函数包括对抗损失函数、L1 损失函数LL1、感知损失函数Lpercept和风格损失函数Lstyle。鉴别器只是在对抗性损失函数上训练。在本文中,真实图像为Igt,对应的二值修复掩码为m(已知像素的值为0,缺失区域的值为1),G作为生成器,D作为鉴别器。因此,鉴别器的对抗性损失函数为
相应地,生成器的对抗性损失函数为
式中,pdata表示真实数据分布,Igt表示分布中的样本,pIcomp表示修复结果Icomp的先验分布。本文利用重建损失函数LL1,计算最终生成的输出Ipred与地面真实图像Igt之间的L1距离。定义LL1损失函数为
式中,NIgt是基础真理元素的数量。Johnson 等人(2016)主张使用感知损失函数训练前导网络来创建高质量的照片,而Gatys等人(2016)引入了使用风格损失函数Ipercept通过在预训练网络模型的激活映射之间生成距离度量来惩罚感知上与标签不同的结果。感知损失函数的定义为
式中,θi(x) 为VGG-19(Visual Geometry Group-19)(Simonyan 和Zisserman,2015)第i层特征图,Ni是θi中的元素个数。这些特征映射也被用来计算风格损失,衡量差异的协方差的特征映射。风格损失函数的计算方法为
Gi(x)=(θi(x))T·(θi(x)) 是用于 对VGG-19 的每个特征图进行自相关的Gram 矩阵点乘,Ni是θi中的元素个数。整体损失函数定义为
实验中的超参数选择如下:λadv=0.01,λL1=1,λp=0.1,λs=100。
3 实验
3.1 实验设置
本文在两个公开数据集上评估所提出的方法,即Paris Street View 数据集和CelebA-HQ数据集。
3.1.1 数据集
对于训练和测试,本文采用Liu 等人(2018)提出的自由形式掩码,同时遵守标准设置(Nazeri 等,2019;Zeng 等,2023;Liu 等,2020)。遵循标准设置(Zeng 等,2023),训练和测试的数据集中所有图像的尺寸都调整为512 × 512像素或256 × 256像素。
1)Paris Street View 数据集 。包括15 000 幅巴黎街景图像、14 900幅训练图像和100幅测试图像。
2)CelebA-HQ 数据集。包含30 000幅高质量的人脸图像,28 000 幅图像用于训练,2 000 幅图像用于测试。
3.1.2 对比方法
为了验证本文方法,与以下方法进行对比。
1)GL(globally locally)(Iizuka 等,2017)。该方法使用经过训练的全局和局部上下文鉴别器来识别真实和完整的图像。
2)Pconv(partial convolutions)(Liu 等,2018)。该方法使用部分卷积操作,这些卷积被屏蔽并重新规范化。
3)DeepFillv2(free-form image inpainting with gated convolution)(Yu 等,2019)。引入了一种新的实用的基于块的GAN鉴别器。
4)EC(edge connect)(Nazeri 等,2019)。一个两阶段对抗模型,包括一个边缘生成器和一个图像修复网络。
5)MEDFE(mutual encoder-decoder with feature equalizations)(Liu 等,2020)。交互式的编解码网络架构,并且引入一种特征均衡方法。
6)EDGE-LBAM(edge-guided learnable bidiretional attention maps)(Wang 等,2021)。一种名为EDGE-LBAM 的多尺度边缘完成网络,以及一种可学习的前向注意力映射。
7)AOT-GAN(aggregated contextual transformations generative adversarial network)(Zeng 等,2023)。一种新的AOT-GAN网络来学习聚合上下文变换,并设计了一种新的掩码预测任务来训练鉴别器。
3.1.3 评价指标
1)L1 误差。该指标广泛应用于大多数实验结果比较,通过计算原始图像和修复图像之间的平均绝对误差来评估逐像素重建精度。
2)峰值信噪比(peak signal-to-noise ratio,PSNR)。一种常用的图像质量度量指标。
3)结构相似性指数(structural similarity index,SSIM)。在亮度方面对绘制图像与原始图像进行比较、反转和重建。
3.1.4 实现细节
本文使用PyTorch框架来实现文中提出的方法。为了与EC、Edge-LBAM 等其他方法进行公平的比较,网络使用Paris Street View数据集,在256 × 256像素的图像上进行训练。由于AOT-GAN 是在CelebAHQ 数据集上使用512 × 512 像素的分辨率图像训练,所以本文将继续使用与它相同的设置。模型使用Adam 优化器,其中β1=0.5,β2=0.999。生成器的学习率为5E-5,而鉴别器的学习率为1E-5。在这些实验中,多尺度的通道注意力块的数量为每层2个,基于分块的自注意力块的数量为每层8个。同时,在多尺度通道注意力块中将输入张量的分成4 个部分,在基于分块的自注意力块中将输入张量分成4个小块。
3.2 实验比较
本文方法使用Paris Street View 和CelebA-HQ 数据集进行评估。实验与以上方法进行定量和定性比较。
3.2.1 定量比较
表1 和表2 分别列出了多种比较方法在Paris Street View 和CelebA-HQ 数据集上的L1 平均损失、PSNR和SSIM值。
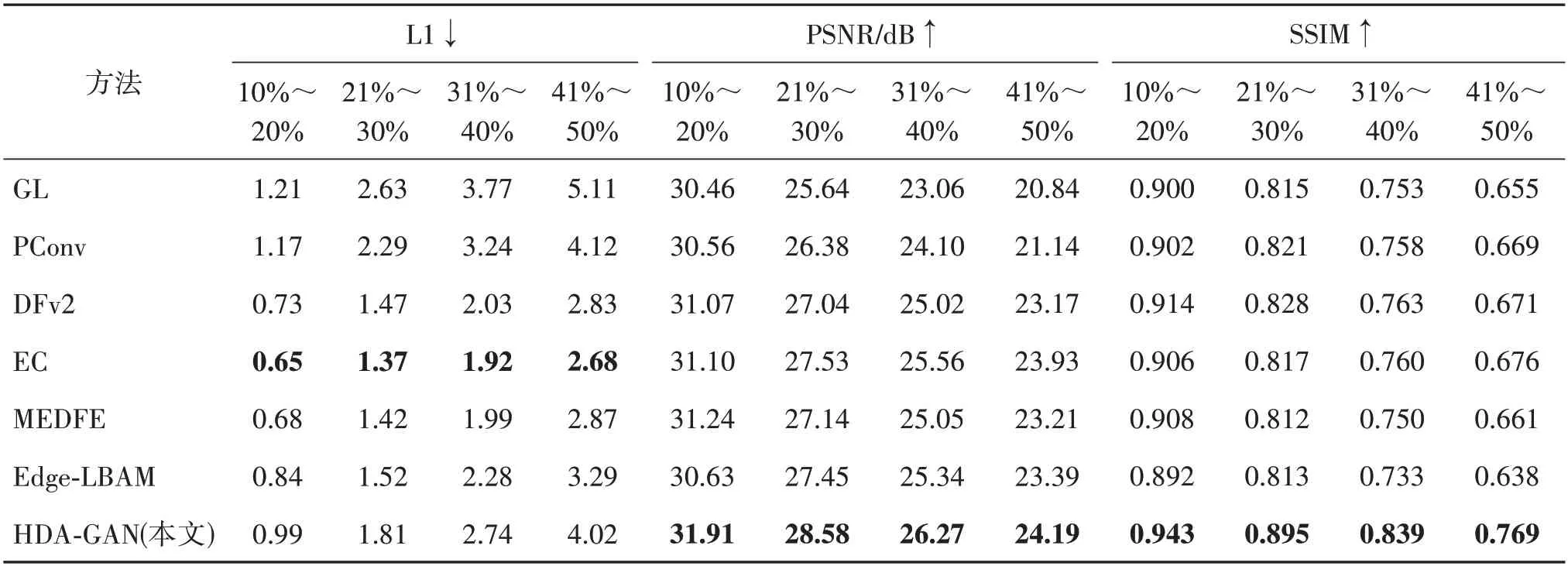
表1 不同方法在Paris Street View 数据集的定量结果Table 1 Quantitative results on the Paris Street View datasets with different mothods

表2 本文方法与AOT-GAN在CelebA-HQ数据集的定量比较结果Table 2 Comparision of quantitative results on CelebA-HQ datatsets between AOT-GAN and ours
本文按照AOT-GAN 和Edge-LBAM 方法比较方式,提供不同掩码区域比例((0.0,0.1],(0.1,0.2],(0.2,0.3],(0.3,0.4],(0.4,0.5])的修复结果。比较方 法GL、PConv、DeepFillv2、EC 和MEDFE 的性能来自Edge-LBAM 的实验部分。但是Edge-LBAM 和AOT-GAN是在Paris Street View 或CelebA-HQ 数据集上使用随机不规则掩码的官方代码下自行训练得出的结果。
表1 展示了不同掩码比例下,本文方法在Paris Street View 数据集的实验结果。从效果图可以观察到,本文方法在评价指标PSNR 和SSIM 下的表现始终优于现有的所有方法,但平均L1 误差不是最优。
此外,实验显示本文方法在CelebA-HQ 数据集上时3个评价指标都实现了最优的修复结果,如表2所示。多尺度通道注意力块和基于分块的自注意力块是本文方法有效性的重要原因。特别地,由于改进后的注意力机制,该网络能够“看到”更多的全局结构信息和局部纹理。在这两类块中采用了残差门控连接,它可以在空白区域内更新特征,同时保持缺失区域外已知特征的完整性。因此,本文方法可以提高受损图像的修复质量。此外,注意力机制使模型能够创建长期关系,这有助于创造更可信的语义和感知信息。
3.2.2 定性比较
图5 和图6 分别描绘了在Paris Street View 和CelebA-HQ 数据集测试集的定性实验结果,掩码比从上(第1 行)到下逐渐增大。由于比较的方法中,EC、MEDFE 和Edge-LBAM 的训练时分辨率为256 ×256 像素,因此为了与它们进行公平比较,本文也保持这个设置。本文使用官方代码和预先训练的模型来生成EC 和MEDFE 的实验结果,但是本文重新训练了Edge-LBAM 的结果,由于官方资源不提供预训练模型。类似地,当与AOT-GAN 进行比较时,使用官方代码在分辨率为512×512 像素的条件下对该方法进行训练。

图5 不同方法在Paris Street View 数据集上的定性比较Fig.5 Comparisons of results of qualitative on Paris Street View datasets among different methods((a)masked images;(b)EC;(c)MEDFE;(d)Edge-LBAM;(e)ours;(f)ground truth)
如图5 所示,在边缘区域附近,EC 表现出不一致和不合理的语义,或由于该方法只是将受损图像和期望的边缘映射连接起来进行修复,可能导致模糊修复,这可能不足以合理利用预测的边缘映射。此外,MEDFE 无法完成一些缺失区域非常大的场景,如图5第5行。相比而言,Wang等人(2021)提出的Edge-LBAM 将Edge-LRAM 引入编码器特征映射并使用Edge-LFAM 集成期望的边缘映射。因此,与EC 和MEDFE 相比,Edge-LBAM 在最小化颜色伪影和模糊的同时,能更有效地产生精细的接近真实纹理的照片和高级语义结构。然而,该方法在整体结构上的修复效果还不够好。
同样地,在CelebA-HQ 数据集上的定性比较如图6所示,掩码比从上(第1行)到下逐渐变大。当掩码比例较大时,图6 中AOT-GAN 会导致口鼻畸形(第6 行),同时也可能忽略了图6 第5 行和第6 行中的眼睛的颜色。显然,无论掩码比是高还是低,本文模型能够产生更好的结果。本文认为这是因为AOT-GAN 堆叠的AOT 块,只是增加了局部的感受野,而不能考虑图像的整体结构信息。因此,建议在对图像进行修复时,该模型应同时考虑局部细节纹理和全局结构信息。本文方法用了两个精心构造的注意力块,它们不仅“看到”局部的细节纹理,还能“看到”全局的结构信息。
3.3 消融研究
本节中进行了3 组消融研究,以验证HDA-GAN 3 个部分的有效性,即多尺度通道注意力块、级联自注意力传播模块以及尺度通道注意力块或级联自注意力传播模块的数量。如表3 所示,每组消融研究都基于前面的组成部分。具体来说,在Paris Street View 数据集上与不同的掩码图像进行了定量和定性的比较。

表3 关于不同层的多尺度通道注意块或位置分离自注意块及其数量的消融实验Table 3 Ablation experiments were performed to investigate the amount of multi-scale channel-attention block or positional-separated self-attention block
如表3 所示,完整模型(HDA-GAN)采用l1跳跃连接层到l5跳跃连接层的所有注意力块,HDA-GAN(l1)意味着只添加HDA-GAN的l1跳跃连接层的所有块。HDA-GAN(l1,l3,l5)方法的意思是只要添加l1,l3和l5跳跃连接层对应的注意力块。方法HDAGAN(l1,l3,l5,b1)的意思是只添加一个HDA-GAN的l1,l3,l5跳跃连接层的注意力块。为了验证多尺度通道注意力块和基于分块的自注意力块的有效性,本文将级联通道注意力传播模块和级联自注意力传播模块中的注意阻塞。本文使用完整的HDAGAN 模型作为基准,与HDA-GAN(l1)方法(只在l1跳跃连接层添加所有多尺度通道注意力块)、HDAGAN(l3)方法(只在l3跳跃连接层添加所有基于分块的自注意力块)、HDA-GAN(l5)方法(只在l5跳跃连接层添加所有级联自注意力传播模块)、HDAGAN(l3,l5)方法(只在l3和l5跳跃连接层添加所有级联自注意力传播模块)进行比较。表3 消融实验研究了添加不同跳跃连接层的多尺度通道注意力块或基于分块的自注意力块以及多尺度通道注意力块或基于分块的自注意力块数量。HDA-GAN(l1,l3,l5)方法只添加所有的多尺度通道注意力块在l1跳跃连接层和所有的级联自注意力传播模块在l3和l5跳跃连接层。
通过表3 的定量比较可以看出,完整方法HDAGAN 在L1 误差、PSNR 和SSIM 方面与其他不完整方法相比基本获得了明显的改善。从这个结果可以证明本文的两个级联注意力传播模块可以促进生成器网络产生更合理的内容。本文推测这是因为使用更多的残差连接层和级联注意力传播模块可以显著改善生成器捕获的全局结构和局部纹理。特别是当填补复杂的缺失区域时,这对于图像修复是至关重要的。此外,将级联自注意力传播模块只添加到中间或较低的层时不会产生比将本文的级联自注意力传播模块同时添加到中低层更好的结果。
本文认为这是因为仅在低层添加级联自注意力传播模块往往关注更多的结构和更少的细节,而在中层添加级联自注意力传播模块通常考虑更多的结构和更少的细节,而在中低层都添加级联自注意力传播模块可以缓解这个问题。此外,可以观察到,增加多尺度通道注意力块和级联自注意力传播模块的数量也可以在L1 误差,PSNR 和SSIM 产生更好的结果。这可能是由于多个注意力块的叠加可以将局部信息传播到全局结构。添加多尺度通道注意力块到高层相比不添加它会有轻微的效果提升。
4 结论
本文提出了一种名为HDA-GAN 的混合双注意力生成对抗网络,该网络通过融合两个精心设计的注意力传播模块,可以为失真图像生成合理且令人满意的内容。一个是级联的通道注意力传播模块,它通过连接几个多尺度通道注意力块将低级视觉特征编码为高级语义;另一个是级联的自注意力传播模块,它通过堆叠多个基于分块的自注意力块,在学习长期和全局语义信息交互的同时,更好地维护细节。研究表明,HDA-GAN生成纹理具有体面的结构和独特的细节,同时优于最先进的Edge-LBAM 和AOT-GAN 方法。在Paris Street View 数据上,HDAGAN 方法相比于Edge-LBAM 等方法在PSNR 和SSIM 等评价指标上都有很好地提升。在CelebAHQ 数据上,HDA-GAN 方法相比于AOT-GAN 方法在MAE、PSNR 和SSIM 等评价指标也有不错地提升。原因是HDA-GAN 使用了多个注意力块的叠加策略,可以将局部信息传播到全局结构,并且添加多尺度通道注意力块到高层相比于不添加有一定的效果提升。但是,本文引入注意力的同时会带来小部分计算负担。未来将继续在图像修复领域探索,将本文提出的注意力传播模块进行优化并且应用到更多图像处理的领域。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
电子制作(2016年15期)2017-01-15
第二课堂(课外活动版)(2016年2期)2016-10-21
系统工程与电子技术(2016年2期)2016-04-16
电测与仪表(2014年1期)2014-04-04
电测与仪表(2014年1期)2014-04-04
