
基于跨时空自适应图卷积网络的肢体情绪识别*
2023-11-20 07:14彭亚斯张非凡
传感器与微系统 2023年11期
彭亚斯,张非凡,孙 晓
(1.安徽医科大学生物医学工程学院,安徽 合肥 230012;2.合肥综合性国家科学中心人工智能研究院,安徽 合肥 230088)
0 引 言
当前的情绪识别方法主要基于人的面部表情、语音和文本等方面[1~4],但对于肢体动作的关注相对较少。在人们的日常生活场景中,面部表情、语音等情绪表达载体容易受到遮挡、光照、环境噪声等因素影响。相比之下,人体的肢体动作具有立体性、尺度较大且不易隐藏的特点[5]。为了更好地识别肢体情绪,需要对复杂的肢体动作进行建模,并考虑如何挖掘这些动作所表达的情绪。以前的肢体情绪识别研究中,多数采用手工特征的方法进行分类[6~8],或者使用长短期记忆(long short-term memory,LSTM)网络来建模数据中的时间依赖性[9],又或者将肢体动作特征作为多模态数据的一种模态[10~13]。然而,这些研究在空间维度、时间维度没有充分利用人体的上下文结构信息,从而无法充分挖掘不同肢体动作背后所表达的情绪。图卷积网络(graph convolutional network,GCN)在处理图数据方面有着快速的发展和广泛的应用。由于人体的骨架天生具有图结构的特点,因此利用GCN来处理人体的肢体动作信息具有明显的优势。
为了能够充分挖掘不同肢体动作所表达的情绪,本文使用自适应学习方法和跨时空信息聚合的时空图卷积网络(spatial temporal graph convolutional network,ST-GCN)学习不同肢体行为所表达的情感。
1 图卷积
1.1 骨骼图的构建
本文首先使用开源工具OpenPose 提取出视频中每一帧的骨架数据,一帧中的原始骨架数据以向量序列的形式提供,每个向量表示相应人体关节的二维坐标以及置信度。一个完整的情感动作包含多个不同长度的帧。使用一个时空图来建模这些关节之间的结构化信息与时间信息,沿着空间和时间维度,图的构建遵循ST-GCN[14]的工作。图1为构建的时空骨架图的示例,其中关节点表示为顶点,它们在人体中的自然连接表示为空间边(图1实线)。在时间维度上,相邻两帧之间的对应节点用时间边连接(图1虚线),将每个关节的坐标向量设置为对应顶点的属性。
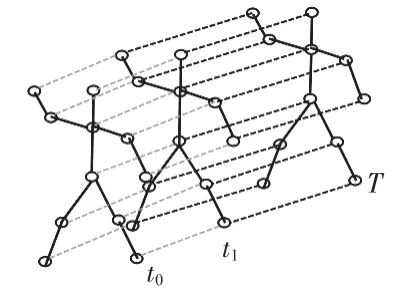
图1 时空图
1.2 图卷积的定义
对于上述定义的图,与传统的卷积网络一样,在图上应用多层时空图卷积运算来提取高层特征。然后使用全局平均池化层和SoftMax分类器根据提取的特征预测情绪类别。
在空间维度上,节点vi的图卷积公式定义如下[14]
式中f为特征映射,v为图的节点,Bi为节点vi卷积的采样面积。Bi被定义为目标节点vi的1 跳邻居节点集合。W类似于卷积操作中的加权函数,它基于给定的输入提供了一个权重向量。其中,Zi为节点vi的邻居节点数量,用于平衡节点vi每一个邻居节点vj对输出的贡献。
1.3 时空图卷积的实现
网络的实际输入X为T×N×C的向量,其中,T为时间序列长度,N为节点个数,C为通道数量。为了实现空间维度的图卷积,式(1)被转化为
式中为t时刻第l层的输入的特征向量,A为N×N的邻接矩阵,D为邻接矩阵的度矩阵,σ为激活函数。W为Cin×Cout×1的权重向量。
邻接矩阵的作用主要用于提取样本的空间特征。邻接矩阵A的构建规则如下
式中d(vi,vj)为节点vi与vj的最短路径。
对于时间维度的卷积,由于每个顶点的邻居数固定为2(2个连续帧中的对应关节),因此使用类似经典卷积操作的时间图卷积是很简单的。具体来说,对上面计算的输出特征图在时间维度上进行Kt×1 卷积,其中Kt为时间维度的卷积核大小。
2 跨时空自适应图卷积模型
2.1 跨时空自适应图卷积层
为了使得模型能够对肢体行为的特征进行建模的同时也能够兼顾上下文信息,本文设计了跨时空自适应图卷积(cross spatio temporal adaptive graph convolutional network,CST-AGCN)模块。图2 为CST-AGCN 层的结构,主要由AGCN层与CST信息交互层组成。下面分别介绍AGCN层与CST信息交互层。

图2 CST-AGCN层
2.1.1 AGCN层
在空间维度上,式(2)所述骨架数据的空间图卷积是基于固定地图结构进行特征提取,用固定的拓扑结构描述多样性的情感样本并不是一个最佳的选择。为了解决这个问题,本文使用AGCN 的方法。它以端到端的学习方式使得图的拓扑结构与网络的其他参数一起优化。该图对于不同的层和样本是唯一的,这增加了模型的灵活性。AGCN 的公式如下
A矩阵和式(2)中一样,它表示了天然的人体结构,Bl矩阵也是一个N×N的邻接矩阵。与A相反,Bl矩阵的元素与训练过程中的其他参数一起被参数化和优化。对Bl的值没有约束,这意味着该邻接矩阵所代表的图结构是完全根据训练数据学习的。通过这种数据驱动方式,模型可以学习完全针对情感识别任务的图结构,并针对不同层中包含的不同信息更加个性化。Cl矩阵是一个数据相关图,它学习每个样本的唯一图结构。本文认为不同的情感样本的应该具有不同特性。模型应该能够学习到不同情感样本的个性图结构。
2.1.2 CST信息交互层
情感的表达是一个连续的过程,为了能够获取更多的上下文信息,本文在输入图序列上设置大小为τ的滑动时间窗口,滑动窗口的每次滑动都获得一个时空子图G(τ)=(Vτ,Eτ)。子图G(τ)包含了τ帧关节点信息,可以构建相应的邻接矩阵Aτ。Aτ的构建规则如式(5)所示
通过构建这样的邻接矩阵,节点的空间连通性将被推广到时域。子图Gτ内的每个节点在相邻的所有τ帧上都与其自身以及1跳空间邻居紧密相连。可以很容易地获得Xτ∈RT×τN×C,同时得到第t个时间窗口的图卷积
图3 所示为τ设置为3 时,可以看出这种CST 策略带来的好处是节点信息的流动就从小范围的当前帧推广到整个时间邻域。

图3 CST信息交互可视化
2.2 CST-AGCN模块
图4 展示了CST-AGCN 模块的结构,由CST-AGCN 层Convs,时间卷积层Convt,BN(batch normalization)层与ReLU层组成。其中时间卷积层Convt与ST-GCN[14]的相同,即对C×T×N的特征向量在时间维度上进行Kt×1 的卷积。残差连接Res用于稳定模型的训练。
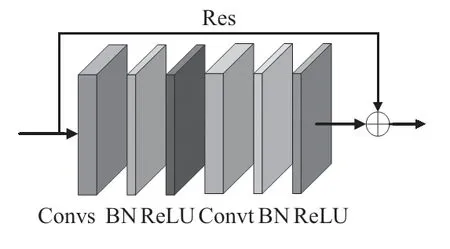
图4 CST-AGCN模块
2.3 CST-AGCN结构
图5 为CST-AGCN 的结构。CST-AGCN 的输入为长度为T的图序列,网络结构由多个CST-AGCN 基础模块堆砌而成,每个块的输出通道数为64,64,128,256。在开始时添加BN层以规范化输入数据,经过多个CST-AGCN模块之后提取样本的深度特征。最后进行全局平均池化层(GMP),将不同样本的特征图平均池化到相同大小。最终输出被送到SoftMax分类器以获得预测结果。

图5 CST-AGCN结构
3 实 验
3.1 数据集
本文使用的是公开数据集Heroes[12]。该数据集由16位非专业演员表达了4 种情绪(快乐、兴趣、厌恶和无聊)的视频组成。对于每个演员,数据集选择了4 个视频来代表每种情绪,总共包含256 个视频片段。这些视频通过使用GoPro相机在2种不同场景下记录全身肢体动作来获取。
3.2 评价指标与损失函数
在实验中,本文使用准确率(accuracy,Acc)与F1 作为评价指标。准确的定义为
式中 TP为测试中的真正例数,FP为假正例数,TN为真反例数,FN为假反例数。
记常用的交叉熵损失函数为
使用的损失函数为文献[15]提出的标签平滑损失函数
经过标签平滑后的损失使用一对损失:H(q,p),H(u,p)代替原始损失H(q,p),使用相对权重ξ/(1 -ξ)惩罚预测的标签p分布与先验分布u的偏差,u为均匀分布。
3.3 消融实验
本文对模型中各个模块进行消融实验。其中,de/X 代表删除X 模块。A,B,C为CST-AGCN 中所使用的矩阵,unfold代表CST信息交互层。τ为CST 信息交互层中时间窗口的长度。
实验结果为表1 前4 行,实验结果表明,本文所设计的CST自适应学习模块有助于情绪识别,不管是删除自适应卷积层还是CST信息交互层都会损坏其性能,而将2 个层拼接在一起,模型获得了最佳的识别性能(表1黑体),其中能够代表身体结构的图矩阵A对模型的性能影响最大,删除A矩阵模型的准确率直接下降了约18%。本文认为这或许是因为人体自身的物理结构信息属于先验知识,先验知识的缺失会导致模型在模型训练的初始阶段陷入局部最优,从而导致模型的最终结果变差。
为了探究上下文信息对肢体情绪识别准确率的影响,本文设置了不同长度的时间窗口,以探究不同时间窗口长度对模型准确率的影响。实验结果为表1 后3 行,本文认为更大的时间窗口应该会有更好的识别效果,为此将时间窗口大小分别设为3、5、7,但是实验结果表明,更大的时间窗口并没有带来更好的效果。模型的准确率下降了约6%,这可能是因为更大的时间窗口会导致局部时空邻域过大,聚合的特征变得过于通用,从而抵消了较大时间覆盖的好处。
3.4 是否引入高级情感特征
受之前研究工作的启发[7~9,16,17],认为高级情感特征有利于提升模型的识别准确率。因此,本文尝试在模型中引入速度、加速度、重心等高级情感特征,希望以此提升模型的准确率,为此做了相关实验。实验结果如表2 所示,其中,Js-AGST代表只使用CST-AGCN 模型提取的深度特征。Fs-AGST代表只使用高级情感特征,2s-AGST 代表将CSTAGCN提取到的深度特征与高级情感特征融合。
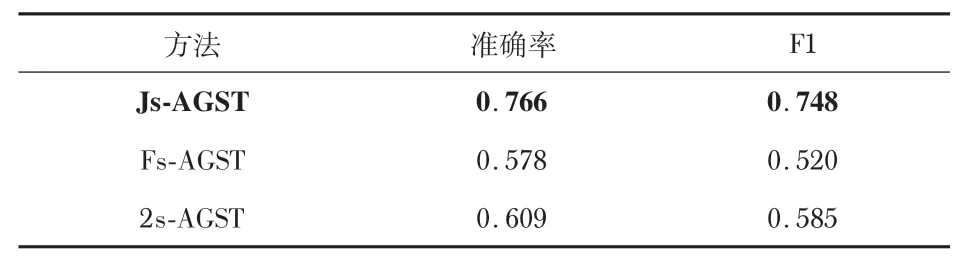
表2 情感特征消融实验结果
实验结果表明,在引入高级情感特征之后,模型并没有带来更高的准确率,反而对模型的准确率起到了恶化的效果。本文认为这是因为直接引入这些高级情感特征之后会导致模型过度依赖这些情感特征,从而导致模型对提取的深度动作特征的关注度减少。后续的工作可以研究如何减少对高级情感特征的依赖,从而使得模型能够充分利用所提取的高级情感特征。
3.5 实验结果比较
将最终的模型在Heroes上的结果与近年来主流的模型ST-GCN[14]、2s-AGCN[18]、MS-G3D[19]作比较。结果如表3 所示。可以看出,本文的使用模型的Acc高于主流算法的最佳约12%,F1约高于13%,充分证明本文所提出的模型的优势。

表3 不同方法的实验结果
3.6 个性化矩阵C的可视化
本文认为AGCN层中的C矩阵是一个个性化矩阵。具体来说,本文认为不同的情感样本应该使用不同的图结构进行信息的聚合。为此,本文对模型中第一层的4种情绪表达的C矩阵进行了可视化。如图6 所示。其中颜色越深(黑色)代表值越小。
可以看出,不同的情绪的个性化矩阵C的差别很大,模型能够根据不用的情感样本选择合适的个性化矩阵进行信息的聚合。
4 结束语
本文提出了CST-AGCN 用于肢体情绪识别,旨在充分利用肢体情绪预测过程中身体结构信息与上下文信息。模型在公开数据集Heroes上取得了优异的性能,实验结果表明:CST-AGCN能提高模型的时空感知范围,根据识别任务自适应的调整图结构。然而,研究发现直接引入高级情感特征会导致模型过度依赖这些情感特征,从而导致模型对提取的深度动作特征的关注度减少。后续的工作可以研究如何减少对高级情感特征的依赖,从而使得模型能够充分利用所提取的高级情感特征。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中华诗词(2019年7期)2019-11-25
电子制作(2019年11期)2019-07-04
第一财经(2019年6期)2019-06-25
北京航空航天大学学报(2018年1期)2018-04-20
天津诗人(2017年2期)2017-11-29
灯与照明(2016年4期)2016-06-05
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01
西南医科大学学报(2016年4期)2016-01-03
电视技术(2014年19期)2014-03-11
