
基于改进CENet的新冠肺炎CT图像感染区域分割*
2023-11-20 07:14邱纯乾陈建森郑茜颖
传感器与微系统 2023年11期
邱纯乾,陈建森,郑茜颖
(1.福州大学物理与信息工程学院,福建 福州 350108;2.福建医科大学附属协和医院,福建 福州 350001)
0 引 言
近年来,随着科技的不断发展,计算机断层扫描(computed tomography,CT)等放射成像技术对于一些疾病的诊断和评估中起到重大的作用[1,2],特别是对胸部肺感染类疾病。因此,CT可以作为检测新冠肺部感染的常规手段。COVID-19肺部CT图片具有一些典型的特征,如磨玻璃阴影、斑片状的阴影,这些阴影可以相互融合形成肺实变。通过CT图像可以临床诊断新冠感染,也可以反映治疗过程中肺部感染大小、位置变化,是用来评价治疗效果的重要指标。然而,在治疗的过程中,反复查看CT图像会极大地浪费医生的时间,并且诊断效率低下,不适用于大规模的治疗。所以利用计算机自动检测CT的图像中的新冠病毒感染将在后续治疗过程中发挥重要作用。
目前,对新冠肺部感染的CT图像研究很多,许多优秀的深度学习框架被设计来检查感染患者。Goze O 等人[3]提出一种利用二维切片分析和三维体积分析实现COVID-19检测的系统;Zheng C 等人[4]提出一种弱监督的基于深度学习的方法,利用3DCT 容积检测COVID-19;Cao Y 等人[5]开发了一种基于卷积神经网络(convolutional neural network,CNN)的CT图像预测模型,用于监测COVID-19 疾病的发展,并对肺受累性进行量化评估;Zhao S X等人[6]提出了一个基于二维CT 图像的感染区域分割网络,该网络在U-NET+ +[7]的基础上重新设计链接结构,并引入了注意力学习机制,获得了更加准确的分割结果;Fan D P 等人[8]提出一种肺部CT 感染区域分割网络,该网络利用并行部分解码器聚合高级特征并生成全局图,利用反向注意力和边缘注意力对边界进行优化和增强。
尽管有些深度学习算法在新冠肺炎检测方面取得不错的成果,但分割感染区域的相关工作仍然较少,这是因为从二维CT图像中分割感染区域存在以下几个难点:1)不同二维CT图像中感染的位置、大小、形状存在巨大的差异,这通常会导致假阴性检测;2)感染区域与正常区域对比度低;3)感染区域边界通常模糊不清,难以获得十分准确的标签。
本文提出了一种基于改进CENet[9]的CT 图像新冠病毒感染区域分割的深度学习网络。该网络以CENet为主体架构,引入注意力机制挤压和激励(squeeze-and-excitation,SE)模块[10],通过学习的方式获取到每一个特征通道的重要程度,再通过这个程度来增强有用的特征,抑制无用的特征;加入了特征聚合模块(feature aggregation module,FAM),将高低层次的特征融合,以保留更多的有效特征,从而提高感染区域的分割精度。
1 本文方法
本文所提出的网络继承了CENet的基本结构---解码和编码的结构。CENet 是一种优秀的图像分割网络,在医学图像分割任务中取得了优异的性能。CENet在特征编码器中采用了预训练的ResNet[11]块,用来更好地提取特征。在编解码连接处提出了密集空洞卷积(dense atrous convolution,DAC)和残差多核池(residual multi-kernel pooling,RMP)用来捕获更多的高级特征并保留更多的空间信息。本文提出的网络在CE-Net的基础上改进,在编码的过程中引入注意力机制模块,使得模型更加关注感染区域,从而提高分割精度,特别对小面积感染区域的检测起到重要作用;加入了FAM,在只增加少量参数的情况下,充分融合低层次特征的位置,细节信息和高层次特征的语义信息,从而达到提升分割精度的效果。
1.1 网络基本结构
本文所提出的网络由3个阶段构成,编码阶段,上下文提取模块,解码阶段。首先,将新冠肺炎数据集进行预处理后输入网络编码部分,经过一个大小为3 ×3 的卷积核;然后,通过4 个ResNet模块,每个ResNet模块后都要经过注意力机制SE 模块进行挤压(squeeze)和激励(excitation);之后,经过上下文提取模块DAC 和RMP,用来捕获更多的高级特征并保留更多的空间信息。解码部分由上采样层、特征聚合模块组成。上采样层是由一个大小为3 ×3,步长为2的反卷积层组成,输出的特征图大小与对应编码过程中特征图大小一致。但是上采样会导致部分感染区域特征信息损失,因此,接入带有特征聚合模块的跳跃连接;最后,通过Sigmoid激活函数对感染区域与背景图像进行分类,输出感染区域分割结果。网络的整体框架如图1所示。

图1 整体模型的结构
1.2 注意力机制SE模块
医学图像分割的最大难点就在于分割小目标任务,小目标物体的纹理信息薄弱,边缘比较模糊。为了解决上面的问题,本文在ResNet模块编码后引入注意力机制SE 模块。SE模块被添加到常见的网络结构中时,可以增强特征提取阶段的感受野,提高与目标相关特征通道的权重,降低与目标无关的特征通道的权重,增强小目标分割的效果。SE模块的基本结构如图2 所示,SE 模块主要分为2个操作:挤压和激励。输入为X,其维度为RH×W×C,H、W、C分别表示特征图的高、宽和通道数。首先将输入的特征图进行全局平均池化来进行挤压操作,得到长度为C的向量,这样做的目的是为了使每个通道都拥有全局的信息,用数学公式表达如下
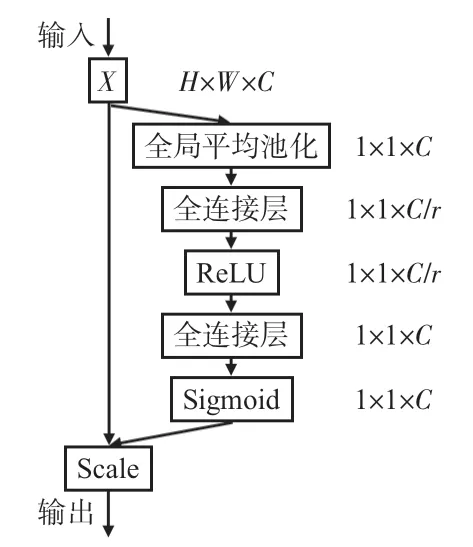
图2 SE模块
激励操作阶段能够获取特征图各通道之间的相互依赖关系。该操作首先是将挤压得到的向量输入全连接层,得到1 ×1 ×(C/r)的向量,(本文模型r设为16),使用ReLU函数激活,然后在经过一个全连接层,将通道数由C/r扩大为C,紧接着通过一个Sigmoid函数计算通道的权重系数s,从而实现激励操作,计算公式如下
其中,σ(·)为Sigmoid 激活函数,δ(·)为ReLU 函数,w1,w22个全连接层的卷积核。最后将权重系数乘以相对应的通道数,得到结果特征图。
1.3 FAM
特征聚合的主要目的是把从图像中提取的特征通过特定的方法,融合成一个比原始输入特征含有更多信息的特征。一般来说,图像的低层次特征包含更多的位置和细节信息,但语义信息较低;而高层次特征具有更高的语义信息,但经过多次的卷积池化操作,位置和细节信息丢失严重,因此,本文提出一种FAM取代原始CENet的跳跃连接,将经过注意力机制增强后的不同层次的特征进行融合,得到一个更具有判别能力的特征,从而达到提高分割精度的效果。
FAM如图3所示,3种类型的线表示不同操作,直线表示同尺寸之间的连接,曲线表示向上线性插值,虚曲线表示向下插值。深色和浅色卷积块表示模块的3 个输入和输出。本文FAM的主要原理是利用双线性插值的方法将不同尺寸的卷积块融合在一起,从而达到特征重用的目的。主要过程如下:首先,将编码过程得到的大小为562×128和282×256 的卷积块分别向上插值2 倍和4 倍得到大小为1122×128和1122×256的卷积块,再通过concat的方法将插值后的2 个卷积块与输入的大小为1122×64 的卷积块融合在一起,得到大小为1122×448 的卷积块;然后,通过同样的方法得到大小为562×448 和282×448 的卷积块;最后,将得到的3个卷积块分配到解码器的相应位置。
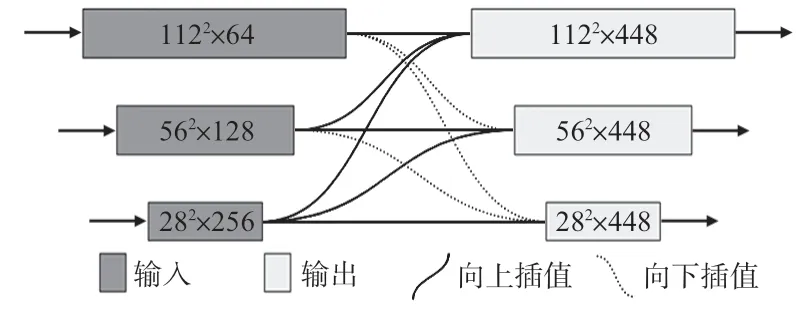
图3 特征聚合模块
1.4 损失函数
本文需要训练所提出的方法来区分每一个像素是在正常区域内的还是在感染区域内,这是一个二分类问题,最常见的损失函数是二元交叉熵损失(binary_cross entropy loss,BCE Loss,BCE)函数[12]。然而医学图像经常存在正负样本不均衡的情况,只使用交叉熵损失函数不能很好地解决这个问题。骰子系数损失(Dice loss)被提出主要是为了解决前后背景不均衡的情况,如一个512 ×512 的图片只有一个10 ×10的分割样例,此时BCE Loss无法解决这种极度不均衡情况,Dice Loss 却不受前景大小的影响。因此,本文损失函数由2种损失函数组合而成,具体表达如下
其中,Y={Y1,Y2,…,Yb}为真实值,Y为预测概率,N为批量大小,σ(·)对应Sigmoid激活函数,α取值为0.5。
2 实验结果分析
2.1 数据集
本文实验采用COVID-19-CT-Scans数据集。数据集由1600张二维CT图像组成,所有的CT图像均由中国放射协会收集。放射科医生使用不同的标签对CT图像进行分割以识别感染区域。其中,1 456张作为训练集,144张作为测试集。本文先对数据集的数据预处理,即将所有CT 图像进行图像增强,采用限制对比度自适应直方图均衡算法增强图像的对比度,使感染区域更容易与正常区域分辨出来,并寻找出肺实质的轮廓,将轮廓以外的部分裁剪,最大程度地减少不相关部分的影响。
2.2 实验参数及环境设置
本文采用的图像经过预处理之后调整大小为224 ×224进行训练。本文所用的所有网络都是基于Pytorch 框架实现。损失函数的α设置为0.5;学习率设置为0.0001;Epoch设置为100,并且每个5 个Epoch保存一次模型。受GPU大小的限制,批次大小(batchsize)设置为8。优化器选择RMSprop算法进行优化。实验所用的计算机配置为Intel®CoreTMi5-6500cpu @3.20 GHz 3.19 GHz,16 GB内存,显卡为NVIDIA TeslaP100,16 G显存。
2.3 评价标准
本文分别测量了分割结果与真实标签之间的Dice 相似系数(Dice similarity coefficient,DSC)、灵敏度(sensitivity,Sen)、特异性(specificity,Spec)、平均交并比(mean intersection over union,MIoU)。计算公式分别如下
式中 TP为被正确检测为感染区域的像素数量,FP 为将正常区域检测为感染区域的像素数量,TN为被正确检测为正常区域的像素数量,FN为将感染区域检测为正常区域的像素数量。
2.4 实验结果与分析
本文采用了6种不同的损失函数进行对比:平均绝对误差(mean absolute error,MAE),IoU,BCE,Dice,Focal,BCE-Dice。不同的损失函数在相同的环境和超参数中训练,实验结果如表1 所示。可知,本文采用的参数α=0.5的BCE和Dice 的混合损失函数在DSC 和Sen 上表现最好,领先第2名的Dice 0.32%,0.04%,而在Spec,MIoU落后Dice和BCE 0.13%,0.48%,综合4 个指标来看,BCE和Dice的混合损失函数在2个指标上取得最优值,而Dice和BCE分别都只在1 个指标上取得最优值,因此,在本文后续实验中均采用BCE和Dice的混合损失函数进行实验。
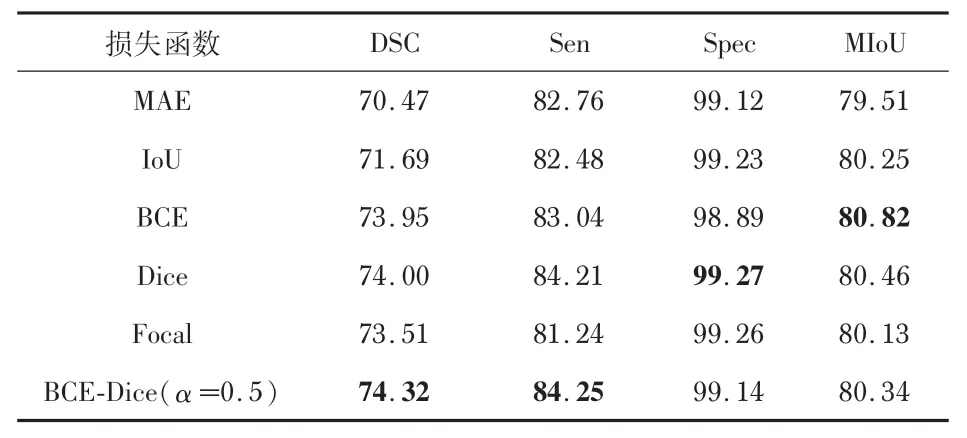
表1 不同损失函数在本文提出的方法上的表现%
在比较感染区域的实验中,本文将所提出的方法与医学图像领域中的4 个经典分割模型对比,包括FCN[13]、DeepLabV3 +[14]、UNet+ +和CENet,实验结果如表2所示。本文所提出的方法在COVID-19-CT-Scans数据集上的DSC,Sen,Spec,MIoU 等性能分别达到了74. 32 %,84. 25 %,99.14%,80.34%,与CENet 相比在Dice 相似系数、特异性、MIoU上分别提高1.91%,0.16%,1.26%,虽然本文提出的网络在灵敏度上不如CENet,但是另外3 个性能指标明显优于它,整体较优。

表2 不同网络的性能对比%
2.5 分割结果可视化对比
本文在测试集中选取5 幅图像,用上述5 种模型对其进行分割,结果如图4所示。其中,图4(a)为原始感染CT图像,图4(b)为标签图像,图4(c)~图4(g)依次为FCN、DeepLabV3 +、UNet+ +、CENet和本文方法分割结果。通过对比图4第1、2行结果可以看出,在对单一目标分割时,本文提出的方法得到的结果与真实标签是最接近的,而其他4种方法的结果在大小、轮廓等方面比真实标签有较大差距。同时由于特征提取的不完整,其他4 种方法均出现错误分割的现象,在未感染区域分割出目标,而本文方法未出现此现象。通过对比第3、4、5 行可以看出,在对多个目标分割时,本文方法的结果也是优于其他方法。尤其是对小目标分割时,相比于其他4种方法,本文方法能正确分割出每一处小目标,而且分割出的结果在形状,大小的方面是最接近真实标签的。

图4 不同模型分割结果
2.6 消融实验
本文采用了4 种不同的CENet 模型在COVID-19-CTScans数据集上进行实验,实验结果如表3所示。通过4 种指标对比可知,本文提出的2 个模块均能一定程度提升CENet在COVID-19-CT-Scans数据集上的分割的性能。
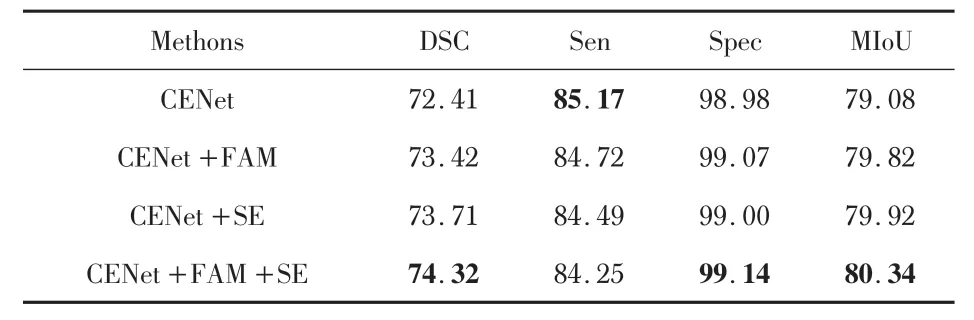
表3 网络结构消融对比%
3 结 论
实验结果表明,本文网络在COVID-19-CT-Scans 数据集上能够更好地捕捉到新冠肺炎感染区域特征,并有良好的分割效果,对比原始CENet和其他分割算法在整体上均有显著的提高。考虑到本文实验样本数较少,导致模型对分割细节上处理不够,进而影响了模型分割效果,后续工作将研究如何扩充实验样本,以进一步提升本模型的分割精度。
猜你喜欢
今日农业(2021年2期)2021-11-27
新世纪智能(数学备考)(2021年9期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·中考版(2021年3期)2021-07-22
今日农业(2021年1期)2021-03-19
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
疯狂英语·初中天地(2020年5期)2020-06-22
恋爱婚姻家庭·养生版(2020年3期)2020-04-13
电子制作(2019年11期)2019-07-04
