
改进STDC-Seg的实时图像语义分割网络算法*
2023-11-20 07:14兰建平董冯雷杨亚会董秀娟胡逸贤
传感器与微系统 2023年11期
兰建平,董冯雷,杨亚会,董秀娟,胡逸贤
(湖北汽车工业学院汽车工程师学院,湖北 十堰 442002)
0 引 言
图像语义分割是指对数字图像中的每个像素进行分类,以便对图像进行深入理解和处理[1]。作为计算机视觉领域的三大基本任务之一,图像语义分割在自动驾驶[2]、医学影像分析[3]、机器人导航[4]等领域均有着极为广泛的应用。近年来,随着深度学习的发展,很多基于卷积神经网络的语义分割方法被提出。Ronneberger O 等人[5]提出编码器-解码器架构,通过跳连接融合编码器中的空间信息和解码器的语义信息。Chen L C 等人提出DeepLab 系列网络[6,7]利用空洞卷积层代替传统的卷积层以在图像大小不变的情况下增大感受野。Zhao H等人在PSPNet中[8]通过聚合不同阶段的信息从而获取全局上下文信息,有效增强特征表征能力。然而上述大规模卷积神经网络对平台的计算能力和内存容量要求很高,无法满足如自动驾驶、机器人导航等对实时性要求较高的领域的应用需求。
为了满足算法的实际部署应用,轻量级的实时语义分割网络越来越受到关注。ESPNet[9]利用逐点卷积和空洞卷积金字塔提取不同感受野尺度下的局部与全局语义信息。BiSeNet[10,11]采用多路径框架分别提取空间细节信息和语义上下文信息,该算法在准确性和实时性方面表现出色。然而,添加额外的网络路径来获取空间细节信息会增加计算消耗,并且辅助路径缺乏底层信息的引导。STDCSeg[12]为了提高计算效率,提出一种短期密集级联(shortterm dense cascade,STDC)模块,然后将该模块集成到U-Net架构中形成STDC-Seg网络,但是该网络解码器结构较为复杂,如何在网络规模、运行速度和分割精度之间找到平衡,满足低功耗移动设备的需求仍是一个具有挑战性的问题。
针对上述问题,本文在STDC-Seg语义分割网络算法的基础上,对其解码器部分进行重新设计优化,使实时性和准确性得到更好地提升。
1 相关方法
1.1 图像语义分割算法
目前主流的设计方法有2 种:1)采用轻型骨干网络:RegSeg[13]引入一种扩张卷积结构设计骨干网络,增加感受野,降低网络规模。2)多分支架构:PIDNet[14]提出3 个分支来分别解析细节、上下文信息和边界信息,并采用注意力机制模块来指导细节和上下文信息的融合。如图1所示。

图1 图像语义分割
1.2 注意力机制
语义分割常将多层次特征进行融合以增强模型特征表示能力。常用的方法有元素求和、元素拼接以及采用注意力机制。注意力机制通过对输入序列或图像中每个位置计算权重来引导模型更加关注重要的特征[15],这些权重与输入进行加权平均,从而得到更加关键和重要的特征,提高模型的表现力和预测精度。如今已广泛应用于自然语言处理[16]、目标检测[17]、图像识别[18]、语义分割[19]等诸多领域。
2 本文算法
本文算法结构如图2 所示。主要包括3 个模块:编码器、解码器和细节聚合模块,其中包含空间注意力融合模块(spatial attention fusion module,SAFM);通道注意力融合模块(channel attention fusion module,CAFM);分割头(Seg Head)和细节头(Detail Head)。细节聚合模块只在训练阶段使用,在推理阶段时去掉,增加模型推理速度。

图2 改进后的算法结构
首先,利用STDCNet作为编码器骨干网络来提取图像层次化的特征。STDCNet的结构如表1所示,共包含5个阶段,每个阶段都进行一次下采样将尺寸变为上一阶段的1/2,所以最终的特征大小为输入图像的1/32。根据第3 到第5阶段STDC模块堆叠次数的不同可以分为STDC1 和STDC2两个网络模型[12]。
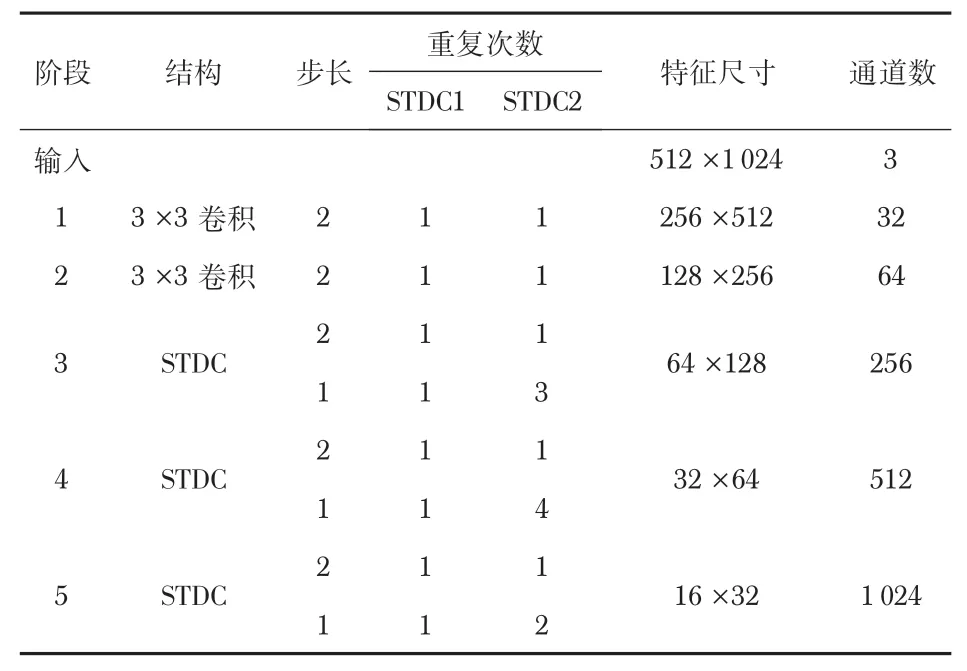
表1 STDCNet骨干网络结构
然后,利用所提出的解码器将编码器所提取到的高级特征进行融合以及上采样,逐步还原丢失的细节信息。采用SAFM来逐步融合编码器的多层次特征映射并进行上采样,并采用CAFM与阶段3经过细节聚合模块[12]引导的特征进行融合。最后通过分割头将通道数减为所需类别数,进行上采样将特征大小扩展到原图像尺寸,并进行argmax操作预测每个像素的标签。采用在线难例挖掘损失函数对模型进行优化。
Seg Head 和Detail Head 的结构相同,如图2 所示,由一个3 ×3卷积、批归一化、ReLU非线性激活函数和1 ×1卷积组成,Seg Head 的输出通道数设置为待分割的语义类别数,Detail Head的输出通道数设置为1,即边缘置信度。
2.1 轻量级解码器
解码器的工作是恢复从骨干网络中丢失的本地细节信息[13]。所提出的解码器架构如图3 所示。与目前常用方法不同[20],本文构建一个简单的池化层,将其分别应用于编码器的3个阶段,可以分别汇聚不同特征层次的上下文信息,同时调整通道数。摒弃STDC-Seg 逐元素相加的操作,采用SAFM进行多层次特征融合,用以产生更加精细的特征。利用CAFM融合低层次的空间细节特征和深层次的上下文语义信息,充分利用注意力机制,有效丰富深层次语义特征的细节信息。此方法与STDC-Seg 网络相比减少了21.3%的参数量,平均交并比(mIoU)高出2.02 个百分点。
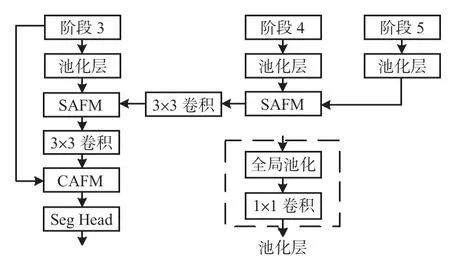
图3 解码器结构示意
2.2 SAFM
本文所采用的注意力融合模块如图4 所示,借鉴PPliteseg[20]的思路,SAFM 利用空间注意力机制产生权重α,并通过元素乘法和相加运算将输入特征与权重融合。其中,Fhigh和Flow分别是高低层次特征的输出,首先将Fhigh上采样到与Flow相同的大小,记为Fup。Fup和Flow作为空间注意力模块的输入,即Fup∈RC×H×W和Flow∈RC×H×W,分别计算出输入特征同一位置在所有通道特征信息上的最值、均值和标准差,共成6 个特征,每个特征的维度均为R1×H×W,然后将这6个特征连接成一个特征Fcat∈R6×H×W;利用卷积操作综合特征权重信息,采用Sigmoid函数将权重归一化后与输入特征相乘,最后对注意力加权特征进行元素加法,输出融合特征。SAFM计算过程如下所示
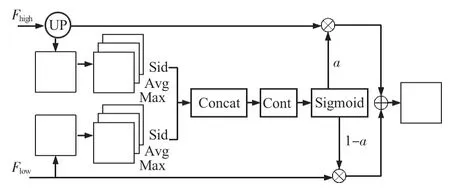
图4 SAFM示意
式中x为输入特征;Xup和Xlow分别为2个输入特征的所提取的最值、均值和标准差;Concat 为拼接函数;Conv 为卷积操作。
2.3 CAFM
如图5所示,首先,将两种不同特征进行拼接;然后,使用1 ×1卷积和批归一化来平衡特征尺度,同时降低通道数以提升推理速度;接着,使用全局平均池化和全局最大池化操作来挤压输入特征的空间维度,分别进行1 ×1 卷积后进行相加,使用Sigmoid函数生成特征权重与拼接后的特征相乘;最后,将融合权重的特征与初始特征相加生成新的特征图。
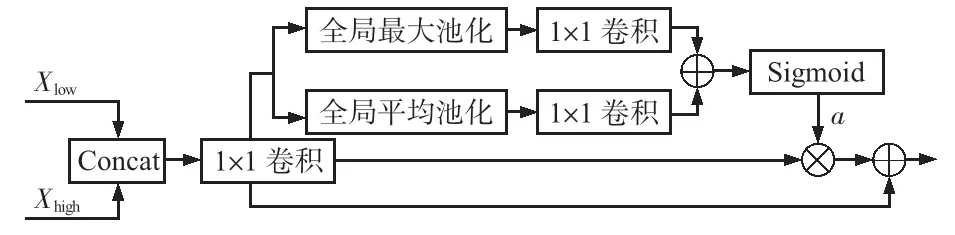
图5 CAFM模块示意
CAFM的计算过程如下
式中Xlow,Xhigh为输入特征;Conv 为卷积、批归一化、ReLU操作;MaxPool和AvgPool分别为全局最大池化和全局平均池化。
3 实验与结果分析
将本文所提语义分割算法在Cityscapes 数据集上进行相关测试以验证算法有效性。该数据集拥有5 000 张精细标注的城市环境中驾驶场景的图像,其中2 975 张用作训练集,500张用作验证集和1 525 张用作测试集。图像分辨率为2 048 ×1 024,一共有30个类别,这里只使用19个类别。
3.1 训练策略
设置批次大小(batchsize)为12,最大迭代次数为160 000;采用随机梯度下降(stochastic gradient descent,SGD)法作为优化器进行模型训练,设置momentum 为0.9,权重衰减为3e-5;采用“poly”学习策略,设置初始学习率为0.01,power设为0.9。使用随机缩放、随机裁剪、随机水平翻转以及随机颜色抖动等方式进行数据增强,随机裁剪的分辨率为1 024 ×512。所有的训练都基于ubuntu 20.04,NVIDIA GeForce 3090硬件平台上使用PaddleSeg 深度学习框架完成。
将Cityscapes的图像大小调整为1 024 ×512,使用推理模型对图像进行推理,计算推理时间。使用平台为NVIDIA 2060 GPU、CUDA 11.4、CUDNN 8.2.4、TensorRT 8.4。使用帧率(frame per second,FPS)作为评价指标衡量算法实时性。使用平均交并比(mean intersection over union,mIoU)作为评价指标进行分割精度比较,其定义如下
式中i为真实值,j为预测值,k+1为语义类别总数。
3.2 消融实验
由表2可见:与STDC1-Seg网络相比,所提出的解码器语义分割性能几乎保持不变,参数量减少24.3%;通过增加SAFM和CAFM后牺牲少许参数量,分割精度得到很大提升,mIoU 分别可以提升0.78%和0.92%;当同时使用SAFM和CAFM后,配合轻量化解码器其准确度可以达到74.22%,参数量减小为6.22 M。图6 为Cityscapes数据集上的分割结果,可以观察到分割结果逐渐与Ground-Truth图像一致。上述消融实验充分验证了轻量化解码器、SAFM和CAFM模块的有效性。
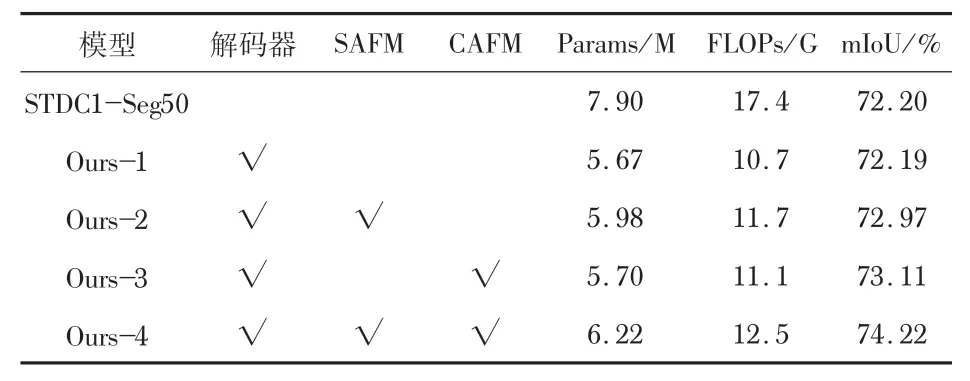
表2 各模块消融实验
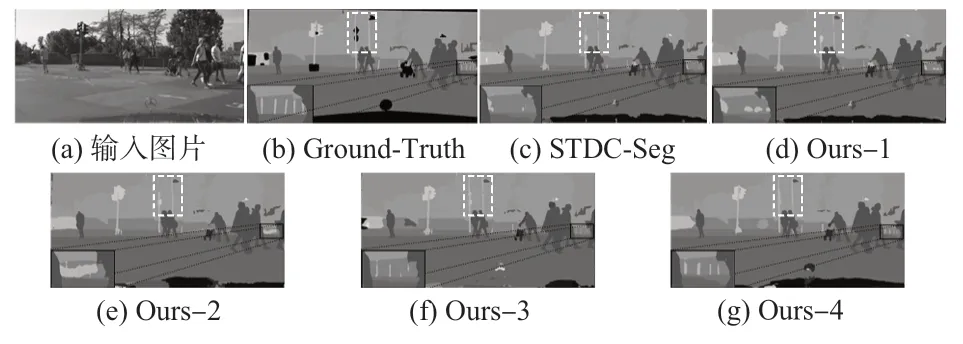
图6 Cityscapes数据集分割结果
3.3 定量分析
通过上述的训练和推理,将本文算法和其他实时语义分割算法进行对比,如表3 所示。将训练出来的模型转为ONNX模型,采用TensorRT进行模型部署。实验结果表明,本文算法的语义分割性能达到了领先的水平,与STDC-Seg等其他流行的轻量级语义分割方法相比,在拥有更高准确性的同时,其实时性表现也得到了一定提升。具体地,本文算法在Cityscapes数据集中以154.7 fps的实时性表现达到74.22%mIoU的准确性。采用STDC2作为骨干网络时精度最高,mIoU 为75.68%。此外,在与STDC-Seg 相同的编码器和输入分辨率下,本文算法表现出更好的性能。
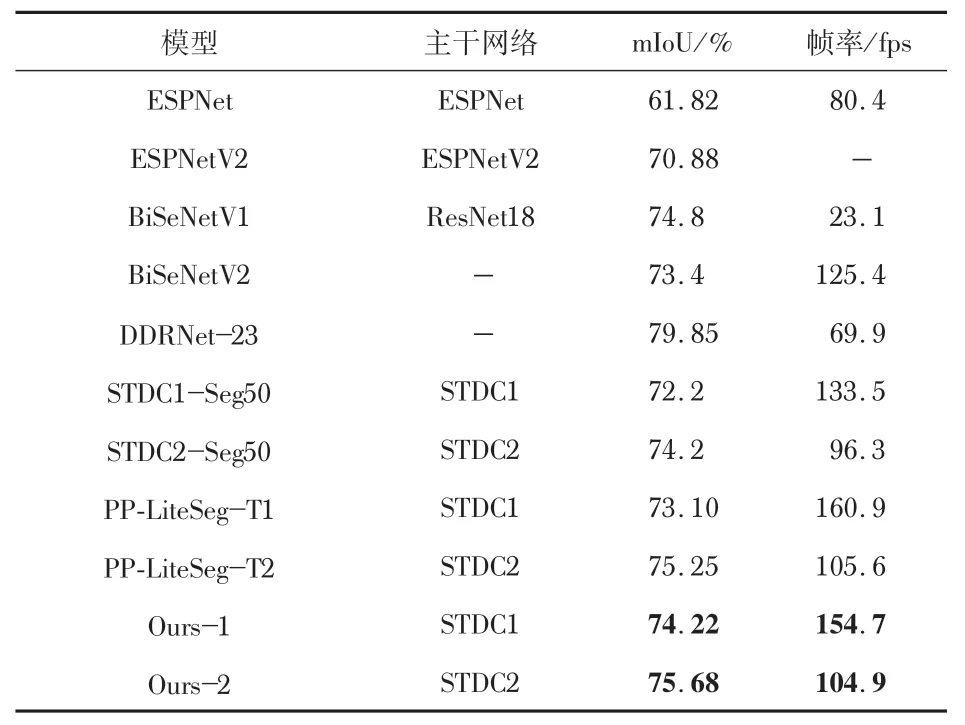
表3 在Cityscapes数据集上各模型对比
4 结 论
本文首先采用STDCNet 作为编码器骨干网络,提取图像特征;随后提出一种灵活的轻量级解码器,以低计算成本聚合全局上下文信息,恢复特征细节,提高现有解码器的效率;同时提出两种注意力机制融合模块,分别为采用空间注意力机制的SAFM 和采用通道注意力机制的特征融合模块,可以有效增强特征表达能力。经过大量实验论证,结果表明:本文算法在分割精度和推理速度之间实现了更先进的平衡,其语义分割性能得到了显著提升。该算法可满足自动驾驶等领域图像语义分割的实际应用部署需求。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
开放教育研究(2020年2期)2020-03-31
家庭影院技术(2019年8期)2019-12-04
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
