
基于情感分析的电商平台评论应用研究
2023-11-19 00:46:32鲁程逸代子正王艳红
科技创业月刊 2023年10期
鲁程逸,代子正,王艳红
(武汉科技大学 恒大管理学院,湖北 武汉 430065)
0 引言
随着互联网的普及,网络购物逐渐兴起。并盛行《中国互联网络发展状况统计报告》[1]显示,截至2022年12月,我国网络支付用户规模达9.11亿,成为推动消费扩容的重要力量。但面对琳琅满目的商品,消费者如何快速购买到满意的商品,成为了网络购物市场快速扩张的新问题。
基于此,各大电商平台都在用户搜索商品时使用了推荐算法,如表1所示。现阶段电商平台所使用的推荐算法在大体上可以划分为以下几个类别[2]。

表1 电商平台所使用的推荐算法
近年来随着国内外学者不断地提出并改进算法,推荐系统的实用性大大提高,但也存在一些问题。目前大多数算法都是从商品的价格、销量以及商家的描述入手,而忽视了消费者购买商品后的感想。而消费者在挑选商品时,比起参考商家提供的描述,往往会更倾向于参考其他买家的意见。有学者从用户视角的商品推荐角度进行研究,提出了针对商品评论的情感分析算法。周立柱等[3]综合阐述了当前国内外情感分析技术的研究成果,并从用户评论数据挖掘入手探讨了情感分析技术的多个应用领域。张紫琼等[4]针对在线评论情感分析提出了一种动态归纳算法,根据用户近期习惯来动态列举用户情感偏向。杜姝等[5]提出了一个基于WordNet 和互信息 PMI 算法淘宝评论评分算法,探讨从评论出发的商品推荐系统的搭建。
总体来说,通过用户评论情感分析的推荐算法仍处于探索阶段,采用互联网语言将基于情感分析的推荐算法应用于电商平台的应用中更是刚刚起步。
本文结合爬虫等相关技术,提出了基于情感分析的电商平台商品评论有用性的分析方法,并基于此实现了一个基于淘宝的商品评论的推荐系统,其可以根据用户输入的关键字,向用户推荐商品。在网络购物高速发展,用户的评论反馈越发受重视的当下,对契合互联网用语的情感分析算法,无疑十分具有研究意义。
1 商品评论应用研究的方法框架
本文从电商平台的评论信息获取、情感词典的制作、情感分析模型搭建、分析结果展示等方面进行评论有用性研究。采用Selenium爬虫技术挖掘获取电商平台用户评论信息,采用word2vec技术制作一个适用于网络商品评论语言环境的精确情感词典,并基于淘宝评论的评分算法模型,对该算法模型进行了相应实践。
2 商品评论分析的方法和模型
2.1 商品评论的获取
商品评论的获取方式是通过Selenium爬虫获取,首先需要向Selenium输入需要爬取商品的商品链接,Selenium通过商品链接打开浏览器并通过商品链接进入商品页面,在浏览器完成服务器所发送的网页信息处理后,Selenium会通过模拟点击,寻找标签等方式在网页源代码中获取商品评论信息。在寻找到评论信息位置后,按照一定格式计入文档中,之后,在本页评论爬取完毕后会进入下一页,继续进行爬取,直至爬取到所设定的页数。
Selenium能打开浏览器模拟真实用户操作,通过这些操作,可以减少被所爬取网站的反爬虫程序识别风险,增强爬虫程序的稳定性。因为许多网页中的内容是被隐藏的,普通的爬虫方法难以获取动态或加密的内容,而Selenium能够模仿用户点击、认证等一系列操作获取加密内容,并通过网页中的一系列标签内容来爬取所需内容[6]。
2.2 制作精确情感词典
2.2.1 情感词典分析处理工具
(1)情感词典。情感词典是判断词语和文本情感倾向的重要工具,多数主观文本均包含情感词,情感词是情感分析的重要依据,所以找出情感词,正确判断其情感极性,从而构造高准确率和覆盖率的情感词典,具有至关重要的意义[7]。在中文文本的情感分析中,知网Hownet、台湾大学NTUSD、清华大学李军中文褒贬义词典,波森自然语言处理公司推出的BosonNLP情感词典被广泛使用。
(2)Word2vec。Word2vec是谷歌公司于2013年运用Deep Learning技术开发出来用于解析语义的一款开源学习工具,其模型是基于神经网络模型实现的.它可以将文本内容的处理简化为向量空间中的向量运算,计算出向量空间上的相似度,用空间向量的相似来表示文本语义的相似度。Word2vec输出的词向量可以用来做很多NLP(Neuro—Linguistic Programming)相关的研究,比如词聚类、找同近义词、词性分析等。
2.2.2 情感词典制作
本文采用基于词典的情感倾向挖掘方法,如图1所示,首先将基于BosonNLP情感词典制作情感词词典,基于知网Hownet词典与台湾大学NTUSD词典制作程度词词典。将两个词典合并后完成基础情感词典。同时,使用Python爬虫程序获得一定量的评论信息,通过Word2vec训练得出词向量模型。通过词向量模型完善基础情感词典,得到精确的情感词典[8]。
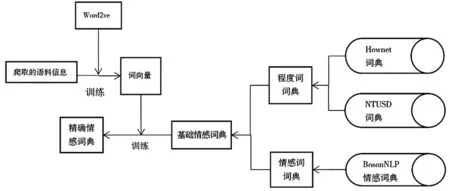
图1 情感词典制作过程
(1)基础情感词典。在商品评论分析模型中,往往会将词语分为表达情感强度的程度词与表达情感倾向的情感词两部分,程度词(例如“非常”“特别”)往往会被用来修饰情感词(“好”“不好”)。①情感词词典。正确地识别情感词是对评论进行情感分析的基础,而一个词典的收录范围将决定情感分析地精确程度。BosonNLP情感词典是从微博、新闻、论坛等数据来源的上百万篇情感标注数据当中自动构建的情感极性词典,并将情感词分为正向与负向两个部分。这一词典的词汇收集量大,且收录了部分网络用语,并且每一个情感词都有其对应的情感分值,可以作为情感分析中的计算权重使用,如表2所示。本文以BosonNLP情感词典为基础,构建带有权重的基础情感词词典。

表2 情感词词典
②程度词词典。在一段评论中,有用于表达情感倾向的情感词,也有不带情感倾向,用于修饰情感词,表达不同情感强度的程度词。程度词的修饰程度同样有强弱之分,因此对其所修饰情感词的影响强度也不同。本文在参考知网Hownet、台湾大学NTUSD词典的基础上,将程度词分为稍微、轻度、更加、特别、最、否定六类,并进行权值标记如表3所示。权值大于l表示对情感有加强作用,小于l则表示对情感有削弱作用,-1则代表否定作用。

表3 程度词词典
(2)精确基础情感词典。 精确情感词典通过词向量模型完善基础情感词典而得到。由于网络用语相对于传统语言表达存在差异,网络时代的海量信息客观上要求网络交流实现最大程度的迅速和快捷,传统的语言表达无法满足信息的最简捷输入输出,由此应运而生了一种由符号、数字、汉字和英字母等杂糅使用的网络语言,这种表述方式因其简单方便、幽默诙谐、使用起来方便时尚而网络上以惊人的速度迅速普及和传播。电商平台消费者的评论也是如此,随着消费者的评论用词不断变化,上文中基于现有情感词典搭建的基础情感词典,并不契合对于电商平台商品评论的分析需求。面对这一问题,本文使用Word2vec对现有的商品评论用语进行分析,并根据训练得出的词向量模型搭建更加契合现今互联网用户用词方式的精确情感词典。在向Word2vec输入训练用的评论信息后,它可以将评论信息的文本内容的处理简化为向量空间中的向量运算,并得出词向量模型,其中,两个词汇的余弦值越接近一,说明两个词汇越相似。在评论中筛选出基础情感词典中未出现的词语,并将其输入词向量模型,得出与输入词汇余弦值接近1的一组词汇,筛选出余弦值最接近1基础情感词典中已有的词汇后,并根据得出词汇在基础情感词典中的分类,将新词汇赋予在情感词典中相同的位置与权重,其具体步骤如下:
①使用Python编写Selenium爬虫程序,采集淘宝网各类商品的评论信息,获取用户评论约20 000条;
②对获取的评论信息进行处理,进行分词、去除标点符号,去除停用词等操作;
③使用处理后的评论信息进行训练,得到记录每个词词向量的数据模型;
④将词典中未出现词汇输入词向量模型,得出与输入词汇余弦值接近1的一组词汇,筛选出余弦值最接近1基础情感词典中已有的词汇后,并根据得出词汇在基础情感词典中的分类,将新词汇赋予在情感词典中相同的位置与权重;
⑤重复第四步,将所有新词汇加入基础情感词典后,最终得出精确的情感词典。如表4所示。
2.3 商品评论的评分计算分析
互信息是信息论中的一个概念,是计算两个随机变量之间相互共有的信息量的大小,在NLP领域广泛应用于语义消歧、搭配、以及聚类[9]。
Fano提出的点互信息概念,是用来计算两个特定样本之间的互信息,及确定两个元素之间的关联程度,他提出两个样本词x和y,他们出现的概率分别是p(z),p(y)。
Turney提出,对于词ω1和ω2,它们的点互信息可以表示为:
(1)
(2)
(3)
基于互信息SO—PMI算法,得出商品评论分析的具体思路[10]:在上文所述结合知网Hownet、台湾大学NTUSD、BosonNLP情感词典并通过Word2vec处理后的精确情感词典中,存在正向(Pos)与负向(Neg)两类情感词与六类程度词,且每个词语都有其对应的权重。以此为基础,得出商品评分计算模型CS-model(Commodity Scoring Model),该算法的基本思想是:一个商品中拥有多个评论,每个评论中有多个语句(Words)。在每个语句中,将情感词与程度词(EMO)一一对应,根据其在词典中的对应权重求得其乘积。将所得乘积求和,汇总出单个评论的得分(PuSC)。计算公式如下:

(4)
在得出商品每个评论的得分后,需要对得分进行汇总,得出总分(PuASC)。由于在电商平台中,好评总是多种多样,而对于商品的差评往往是千篇一律,着重于指出商品的缺点,所以好评得分的绝对值往往远高于差评。针对这一情况,算法需要重视差评的影响,从而更高效的计算出单个商品的得分。在统计单个商品评分大于0的好评数(NFC)与评分小于0的差评数(NNC)后,使用计算公式如下:
(5)
得出的总分P即为商品评价的得分,通过该模型对多个商品进行评分排序后,使用者可在大量商品中快速找出优秀的商品,而不必花费大量时间去挑选。
3 商品评论的具体实践
程序通过Python运行,其具体计算流程如下。
3.1 读取评论并分句
在爬虫程序获取到一定数量的评论数据后,将其打包发送给商品评论分析程序。程序依次读取每条评论,在读取一条评论后,程序通过SentenceSplitter包中的功能将该评论分句,并创建列表Sentence_list,将每句作为一个数据项放入列表Sentence_list中。
例如,当爬虫程序对一款玻璃罐商品的评论数据进行获取时,得到的评论数据如下:①马上就把咸金桔放进去啦!腌制的东西还是要玻璃罐才好。下次试试白萝卜,放冰箱大小也合适,真的是买的很居家。四个,两个小两个大,装什么都可以啦。②买这家的罐子要小心,我拍了八个罐子就发了六个再不发了,问客服也不答复,客服电话是关机状态,这家是个骗子都小心一点!!!!③几个月的时间里断断续续买了大大小小几十个瓶子了,非常的实用,腌菜做酱装调料啥的都很好!只要不被小孩打坏应该可以用很久!
......
在分句功能中,一段评论将以标点符号为间隔分为多段,以第一段评论为例,评论将被分为:①马上就把咸金桔放进去啦!②腌制的东西还是要玻璃罐才好。③下次试试白萝卜,放冰箱大小也合适,真的是买的很居家。④四个,两个小两个大,装什么都可以啦
3.2 分词并去除停用词
程序依次读取列表Sentence_list中的句子,通过Jieba包中的功能对句子进行分词,同时载入停用词表,去除掉分词结果中的停用词。
分词并去除停用词的结果如下:①马上 就 把 咸 金桔 放进去 啦 ! ②腌制 的 东西 还是 要 玻璃罐 才 好 。③下次 试试 白萝卜 放 冰箱 大小 也 合适 真的 是 买 的 很 居家。
3.3 找出情感词
载入情感词词典中的正向词Posdict词典和负向词Negdict词典,通过与词典中的正向词与负向词比对,识别出句子中的情感词,并根据词典中的权重对其赋予权重,如果结尾为感叹号或者问号,表示句子结束,并且倒序查找感叹号前的情感词,将该词所赋予的权重乘二。例如,在上述评论中,“合适”“居家”两词即为情感词。
3.4 找出对应程度词
载入程度词词典,在每个在情感词附近寻找对应程度词,将程度词与其对应的情感词一一对应并记录。在“合适”“居家”两词中,“合适”无配对的程度词,与“居家”配对的程度词为“很”,其在词典中对应的权重为1.5。
3.5 权重相乘,得到某条评论的得分
将每一情感词权重与其对应的程度词权重相乘,并将所有结果相加,得出单句的分数,将所有的句子分数相加,得出一条评论的得分。例如,在“下次试试白萝卜,放冰箱大小也合适,真的是买的很居家。”这一句中,“居家”与“很”的权重分别为2.088和1.5,因此该对词语的计算结果为3.132。
3.6 相加并汇总,得到某个商品的评论分数
在得出单条评论分数后,循环进行上述流程,得出该商品所有评论的分数。将所有评论分数带入上述公式(5)中,进行计算,得出单个商品的得分。在得出多个商品的得分后,即可进行排序并推荐。效果如图2所示。

图2 结果示例
4 总结与展望
网络购物已成为当今社会许多人的首选购物方式。面对网络上繁多的商品,用户需要一个完善的推荐系统来辅助其挑选商品。本文基于电商平台中商品的评论信息,设计了一种推荐算法,旨在从海量的商品中为用户甄选出心仪商品,以节省用户的时间和精力。
本方法无疑在网络购物中具有实际应用价值。通过基于商品评论信息的推荐算法,可以为用户提供个性化的推荐结果,帮助用户从众多商品中筛选出符合其需求和兴趣的商品,提高用户的购物体验和满意度。而对于电商平台来说,有效的推荐算法可以帮助电商平台提高销售额和用户留存率,通过精准的推荐,促使用户更多地购买商品并保持长期的使用习惯。此外,对于平台商户来说,使用基于评论的推荐算法也可以帮助其深入了解用户的购物偏好和消费行为,为商家提供有价值的市场营销信息和数据支持,从而提升商家的竞争力和盈利能力。
当然,本方法仍然存在一些需要进一步开发和完善的地方。例如,可以通过考虑研发更准确的情感分析模型,以提高对商品评论情感的识别和分析能力,从而减少误判和漏判,以此提高推荐算法的准确性和效果。可以考虑结合商品的属性和特征进行推荐,例如参考商品的价格、品牌、类别、销量等属性以及用户的历史购买记录和浏览行为,从而实现更加精准和个性化的推荐。此外,可以考虑将推荐算法应用于更多不同类型的电商平台,例如社交媒体电商、二手交易平台等,以适应不同平台不同的需求和特点。也可以考虑将其他信息源纳入推荐算法,如用户的社交网络、地理位置、时间等信息,以进一步提升推荐的效果和用户体验。此外,还可以考虑引入深度学习、自然语言处理、图像识别等先进技术,不断改进和优化推荐算法的性能和效果。
网络购物的发展离不开推荐算法的不断改进和完善,希望未来能够有更多的研究者加入进来,共同推动这一领域的发展。
猜你喜欢
房地产导刊(2022年10期)2022-10-18 08:03:52
新高考·高一数学(2022年3期)2022-04-28 07:02:46
现代信息科技(2021年21期)2021-05-07 02:54:12
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
文苑(2019年24期)2020-01-06 12:06:50
电子测试(2018年1期)2018-04-18 11:53:04
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:36
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:10
电子制作(2017年9期)2017-04-17 03:00:46
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
