
基于GWO-KELM与GBDT的抗乳腺癌药物性质预测
2023-11-18 09:55张国浩陈义安
重庆工商大学学报(自然科学版) 2023年6期
王 斯, 张国浩, 陈义安
1.重庆工商大学 数学与统计学院,重庆 400067 2.经济社会应用统计重庆市重点实验室,重庆 400067
1 引 言
乳腺癌作为女性最常见的癌症,已经跃居世界女性癌症死亡的第二大病因,并且其发病率和死亡率每年仍在不断攀升[1]。为有效治疗该病症,医药与基因学领域进行了大量实验研究,发现人体内雌激素受体α亚型(ERα)与该病的发病率密切相关[2],并在乳腺肿瘤细胞中过度表达。因此,良性乳腺上皮细胞中的ERα活性升高也就表明患乳腺癌的风险增加,使得科研工作者们不断寻找和研发抑制ERα作用的药物[3]。
乳腺癌候选药物研发与临床应用需要的时间和成本巨大。一方面,药物需要有良好的生物活性,相关医药领域通常会为了节约时间与成本,运用计算机与体外研究技术,对可能具有良好表现的化合物进行筛选工作,即收集一系列作用于该靶标的化合物和生物活性数据,应用数学模型,构建定量构效关系[4](Quantitative Structure-Activity Relationship, QSAR),筛选新化合物以及预测药物活性。
另一方面,良好的生物活性虽然有效保证了化合物对抗肿瘤细胞的有效性,但是药物的研发还需要其药代动力学性质和安全性也符合相关政策法规的要求。药代动力学性质即药物吸收、分布、代谢、排泄和毒性的总称,这些性质分别代表着生物体对化合物的各项敏感程度[5]。
随着智能计算的迅速发展,机器学习和深度学习在医疗领域发挥着越来越重要的作用,特别是辅助药物研发方面。顾等[6]构建一种图注意力网络,用于虚拟药物筛选,并将算法横向对比机器学习算法和传统图神经网络算法,均取得良好的结果;谢等[7]基于平均法与堆叠法融合的浅层神经网络模型,通过对药物分子的化学结构进行信息化编码,提高了对药物分子预测的能力,与传统深度学习相比,他们的研究能够保证更好的准确性;Shi等[8]采用卷积神经网络模型,并将其运用在ADMET特性的预测模型上,表明该方法的预测能力与基于手动结构描述和特征选择的可用机器学习模型的预测能力相当;此外,Peng等[9]提出利用一种改进的图神经网络方法以改进对ADMET特性的预测,该方法能够通过将分子键特征与节点特征连接在一起,并应用门单元来调整原子邻域权重以映射中心原子与其相邻原子之间相互作用强度的差异,从而得到更有意义的分子结构模式,探索更好的分子建模。
从上述文献可知:传统药物活性预测方法成本高,时间长,应用范围小,而利用人工智能算法预测候选药物的生物活性和ADMET性质已成为当今研究的主流热点,出色的模型可以有效预测候选化合物分子活性并对化合物ADMET性质进行分类识别,从而显著地降低研发成本,极大地提高研发成功率,且有效避免因药物产生的副作用和毒性导致的人体疾病。因此,利用更先进的人工智能算法预测抗乳腺癌候选药物的生物活性并进行化合物ADMET性质的分别识别极具实践意义。
本文从UA的DrugBanK[10]数据库中获取了1 974种化合物对乳腺癌治疗靶标ERα的生物活性和ADMET性质数据,采用稀疏贝叶斯学习与随机森林算法进行两阶段筛选,随后基于两阶段筛选后的分子描述符建立了定量预测模型,利用GWO-KELM算法构建针对IC50与PIC50(其值用YIC50,YPIC50表示),的定量预测模型,同时利用GBDT构建分类预测模型,预测了化合物的ADMET性质。本文的研究旨在寻找生物活性较高且尽可能达到更好ADMET性质的化合物,以加快抗乳腺癌候选药物的研发进程。
2 变量筛选
2.1 数据描述
通过爬虫技术以及XML解析,获取2种数据集。第一种是用于定量预测的ERα生物活性数据,包含SMILES一维线性表达式,以及YIC50和YPIC50,前者越小越好,后者是前者的负对数变换;另一种是关于ADMET性质的类别数据,用于构建分类预测模型。
两种数据中的输入特征是729种分子描述符,不失一般性,实际数据通常被认为是稀疏的,所以必须在建模分析前进行特征筛选工作。根据各个特征在不同模型不同阶段的贡献度(特征重要性)进行排序,筛选出前20个最显著的分子描述符。常规的变量选择方法包括主成分分析法、LASSO、稀疏贝叶斯学习、随机森林等,但是主成分分析法和LASSO这类经典算法对729个变量指标进行特征提取时,可能不具备代表性。因此本文选择稀疏贝叶斯与随机森林算法对重要变量进行两阶段评估,以此筛选出对活性值影响大的分子描述符。同时,在筛选前,进行了数据预处理,结果表明原始数据中不存在任何的数据缺失,也无异常点存在。
2.2 稀疏贝叶斯模型一阶段筛选
稀疏贝叶斯模型以贝叶斯理论为基础,其优秀的分类和回归能力可以筛选并寻找包含多个零值的权重向量,同时精确逼近目标向量,从而使得容错与逼近性能更优,泛化误差最小[60-61]。稀疏信号恢复可用式(1)表达。
C=ωφ+ε
(1)
稀疏贝叶斯模型的目标是寻找到一个包含很多零值的ω权重向量,同时结果准确地逼近目标向量C。在SBL模型中,为了寻找系数信号恢复的最小范数解,常常使用高斯似然函数模型获取ω的最大似然估计量,具体见式(2)。
(2)
为了找到稀疏解,SBL从数据中估计参数化的先验权重,过程可以用式(3):
(3)
其中,γ=[γ1,γ1,…,γM]T代表M个超参数的向量,它控制每个权重的先验方差。
另一方面,在对变量维数众多的特征进行筛选时,除了通过影响程度去寻找重要变量,还应减小变量与变量之间的相关性对影响程度产生的干扰。本文将采用斯皮尔曼相关系数去表示两个变量之间的关联程度,从而将相关性过强的变量做标记并加入二次筛选的随机森林模型中进行相关性分离。
稀疏贝叶斯模型的筛选结果与斯皮尔曼的相关系数结果如表1及图1所示,一阶段的筛选结果得到了前40个对生物活性最具显著性影响的变量,但有个别特征(nF10Ring、nT10Ring、nF、nsF、mindS、SdS、maxdS)的相关性显示为强相关(深色)。

表1 SBL变量选择结果Table 1 Results of SBL variable selection
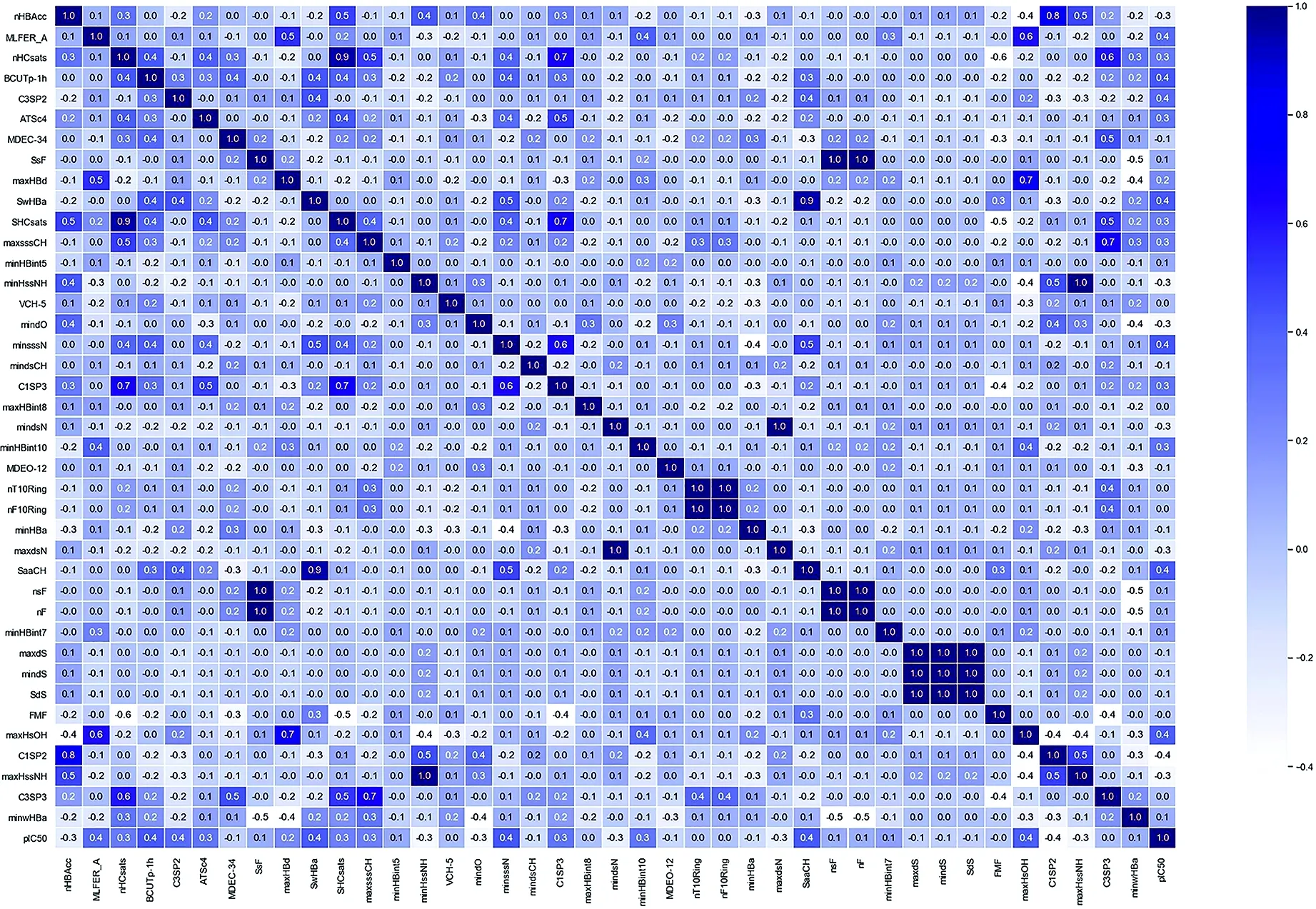
图1 一阶段筛选变量斯皮尔曼系数Fig.1 One-stage screening variable Spearman’s coefficient
2.3 随机森林模型二阶段筛选
为处理各变量之间的相关性,以避免后续缩减模型过拟合情形的发生,在二阶段筛选中,本文将一阶段筛选结果选入随机森林模型中,进行新一轮特征分解提取,从而得到对生物活性最具有显著影响的前20个变量。最终,得到的生物活性最具有显著影响的前20个变量与变量相关系数结果如表2及图2所示。比较图2可以明显看出:通过随机森林模型对变量进行二次筛选后,初次筛选时的强相关性变量相关系数明显减小。
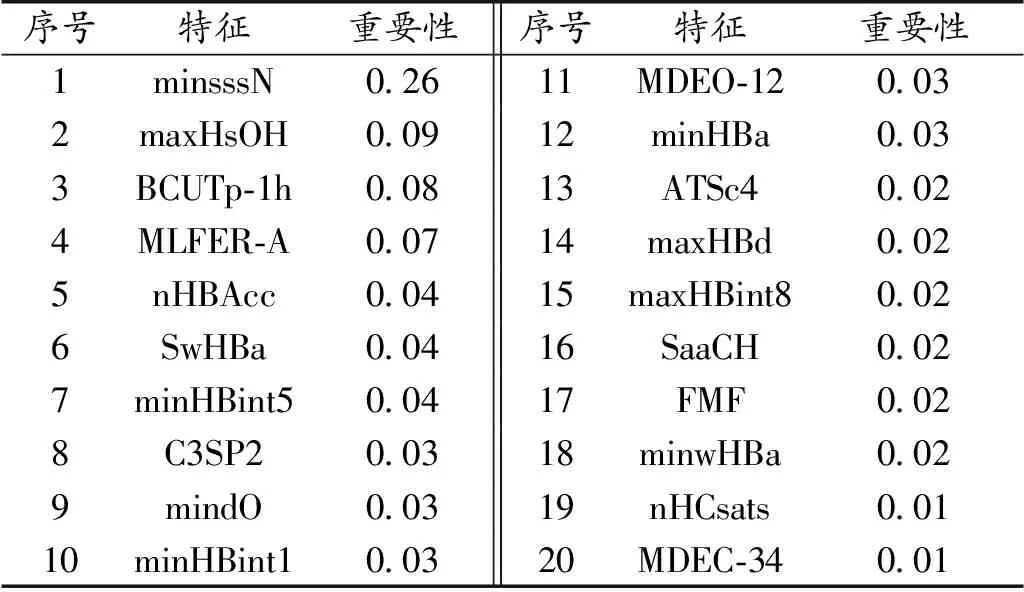
表2 随机森林筛选结果Table 2 Results of random forest screening
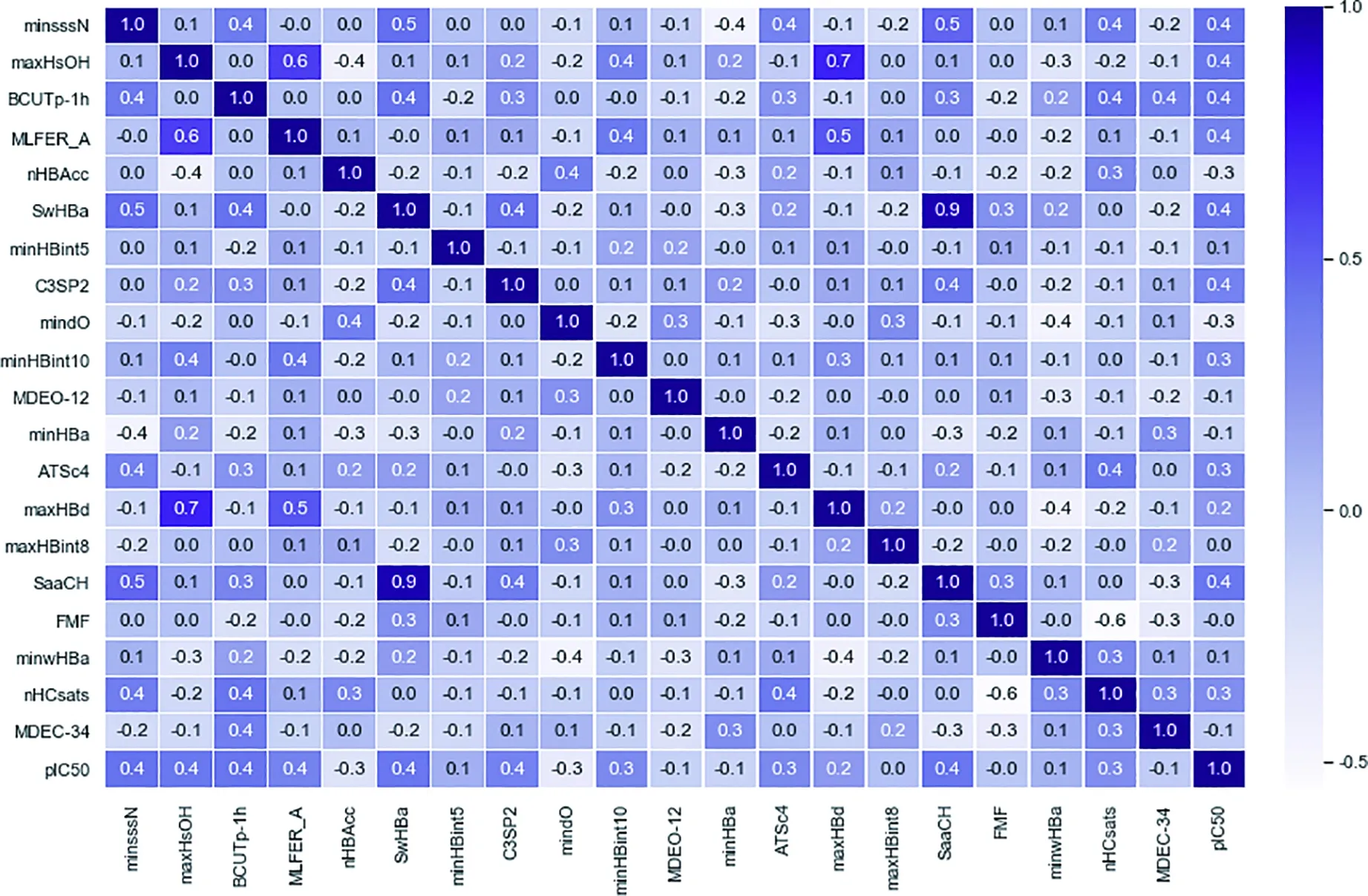
图2 二阶段筛选变量斯皮尔曼系数Fig.2 Two-stage screening variable Spearman’s coefficient
3 基于GWO-KELM算法的QSAR模型预测分析
两阶段筛选后的分子描述符特征已大大减小,考虑到KELM(Kernel based Extreme Learning Machine)算法具有良好的稳定性、泛化能力、容错能力[12],并且目前广泛应用于辅助医药研发,但该模型避免不了KELM神经网络的参数调优问题,特别是正则化系数C与核参数g。因此,本文利用能够进行参数寻优的GWO(Grey Wolf Optimizer)算法对KELM进行改进,从而确定其最优参数,进一步提高模型预测性能。
3.1 KELM原理
数据集D={(xi,yi),i=1,2,…,n},输入数据xi∈Rn,输出值为yi∈R,向量h(xi)=[h1(xi),h2(xi),…,hm(xi)]的作用是将xi从n维输入空间映射到m维隐藏层空间,向量β=[β1,β2,…,βm]T是用来连结输出节点与隐藏层的权值向量,H=[h(x1),h(x2),…,h(xn)]n代表隐含层输出矩阵,正则系数C用来减小模型产生的误差。传统ELM的输出表达式为式(4):
(4)
其中,Y是输出向量。由于传统ELM的输出表达式中有矩阵内积存在,因此使用满足条件的核函数来代替矩阵内积,即式(5)—式(6)。
HTH(i,j)=K(xi,xj)
(5)
h(x)HT=[K(x,x1),K(x,x2),…,K(x,xn)]T
(6)
得到KELM模型的输出为式(7):
(7)
综上可知:KELM模型中的核映射更稳定,因为其回归预测的泛化性能比常见的预测模型更优。同时,KELM模型只涉及自身的内积运算,而且不需预先设置隐含层的节点数,这使得模型更加稳定,收敛速度较快。但值得注意的是,KELM模型有时会因为参数选择不当而导致预测误差偏高。
3.2 灰狼算法改进的KELM模型
为了选择合适的算法针对KELM模型进行优化,本文进行预实验,选择正余弦优化算法(Sine Cosine Algorithm, SCA)、粒子群优化算法(Particle Swarm Optimization, PSO)、灰狼算法进行实验比较。图3可以看出:SCA算法收敛速度很慢,耗时很长,而PSO算法虽然迭代速度收敛较快,但过早陷入局部最优,而GWO算法综合表现更好。因此,利用GWO对KELM算法超参数优化,算法流程图如图4所示。
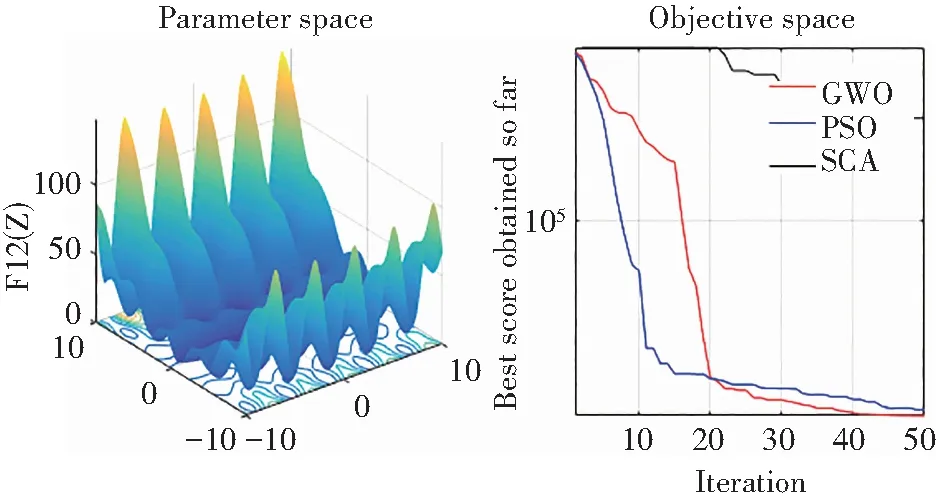
图3 优化算法参数空间和迭代次数对比Fig.3 Comparison of parameter space and number of iterations of optimization algorithm
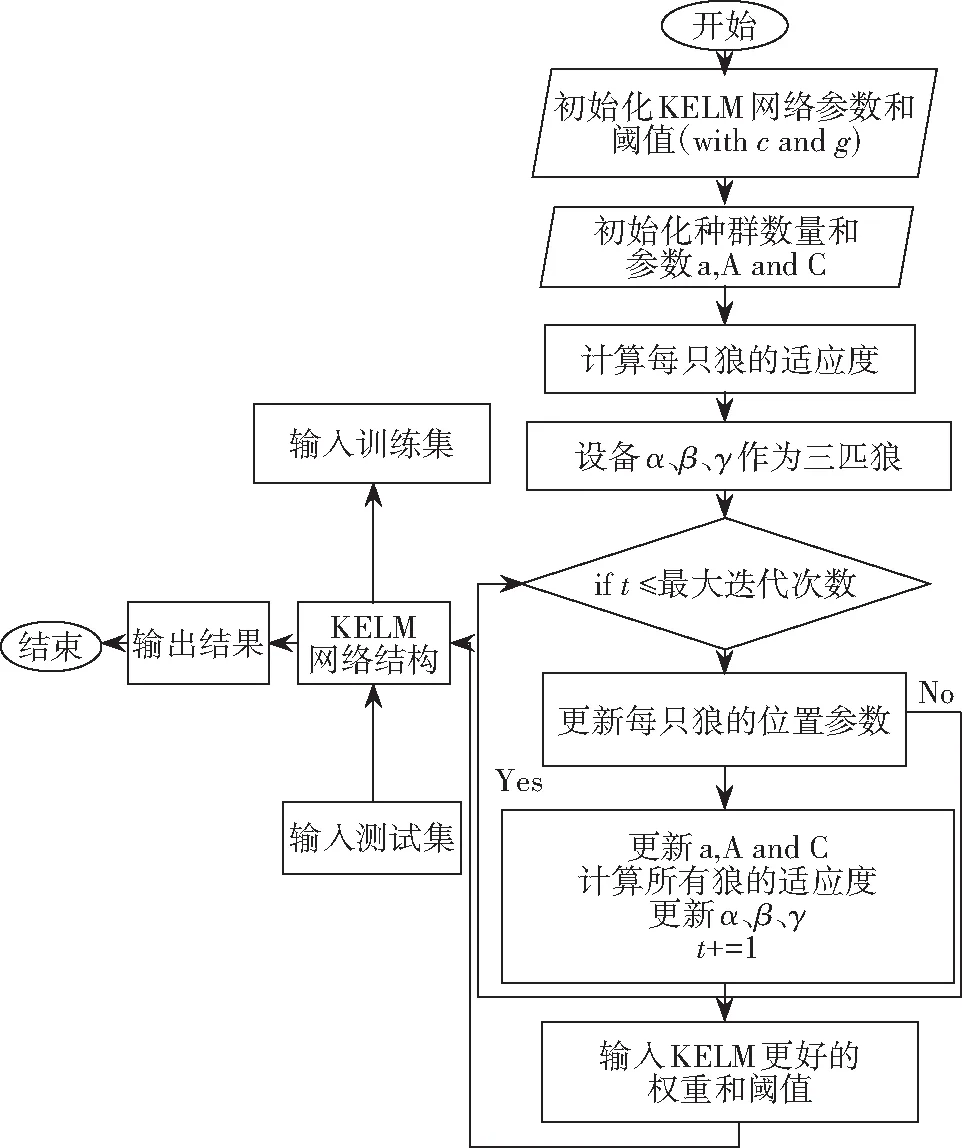
图4 GWO-KELM算法流程图Fig.4 Flow chart of GWO-KELM algorithm
3.3 实验结果与比较分析
为了科学有效地体现出GWO-KELM算法的优越性,本文将基于灰狼优化的KELM算法与11个常见预测算法进行生物活性预测效果对比,通过图像和数据直观体现该模型的优点。具体对比算法是决策树、线性回归、支持向量机回归、k-近邻、增强学习、梯度提升、装袋算法、极限树、贝叶斯岭回归、自动相关性确定算法和泰尔森估算。
通过对比上面的组图可知,11个模型均在一定程度上出现预测误差偏大。观察图5及图6可知,本文算法预测结果与真实值比较吻合,不仅具有最小的误差,而且拟合程度超过70.85%,拟合程度较好。

图5 GWO-KELM算法预测YPIC50结果Fig.5 Prediction of YPIC50 results by GWO-KELM algorithm
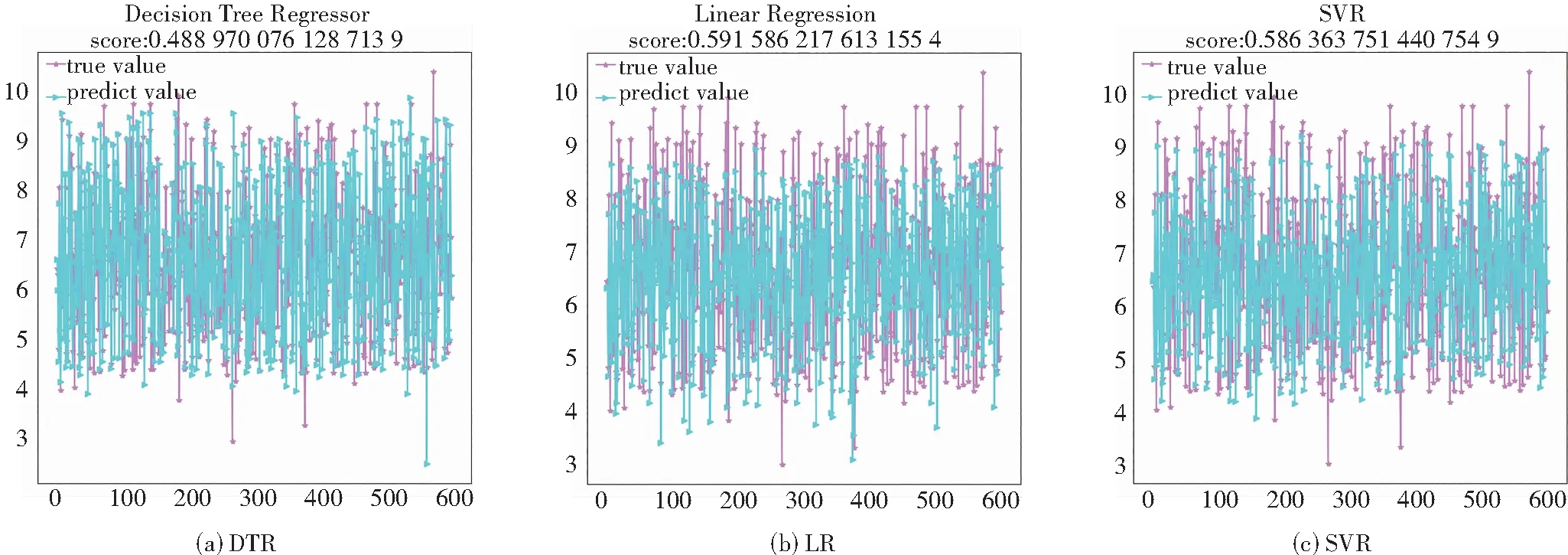
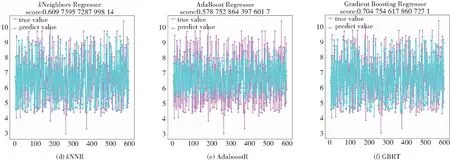
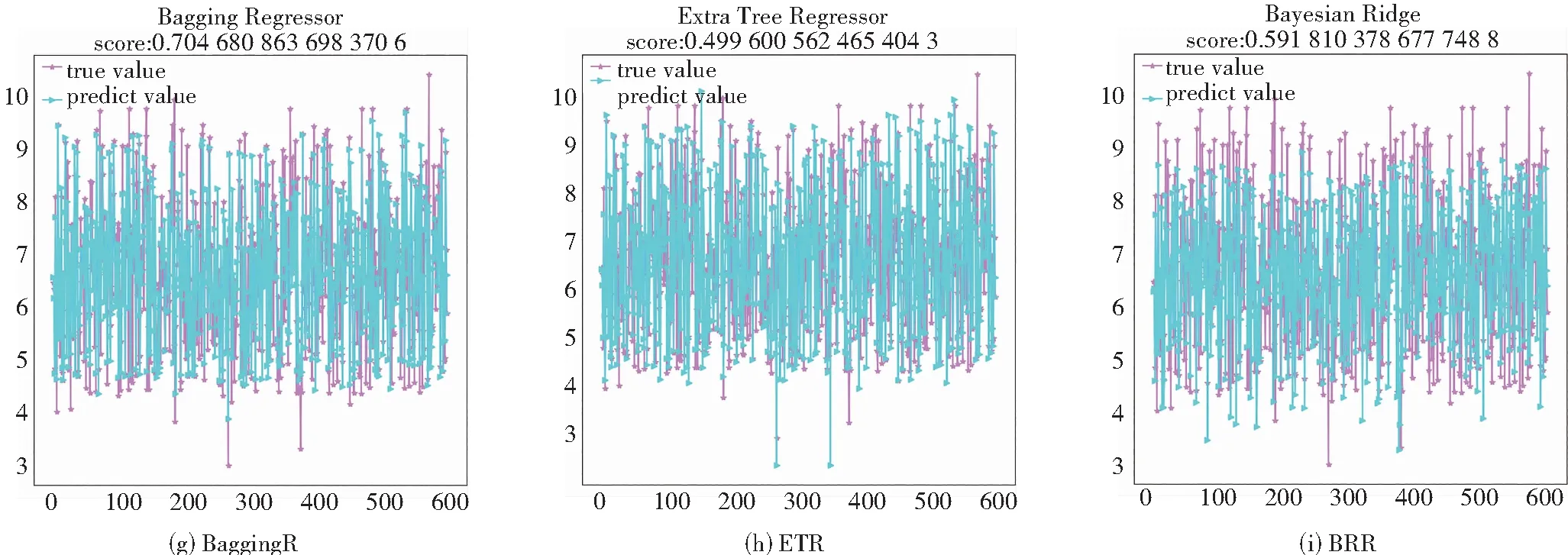
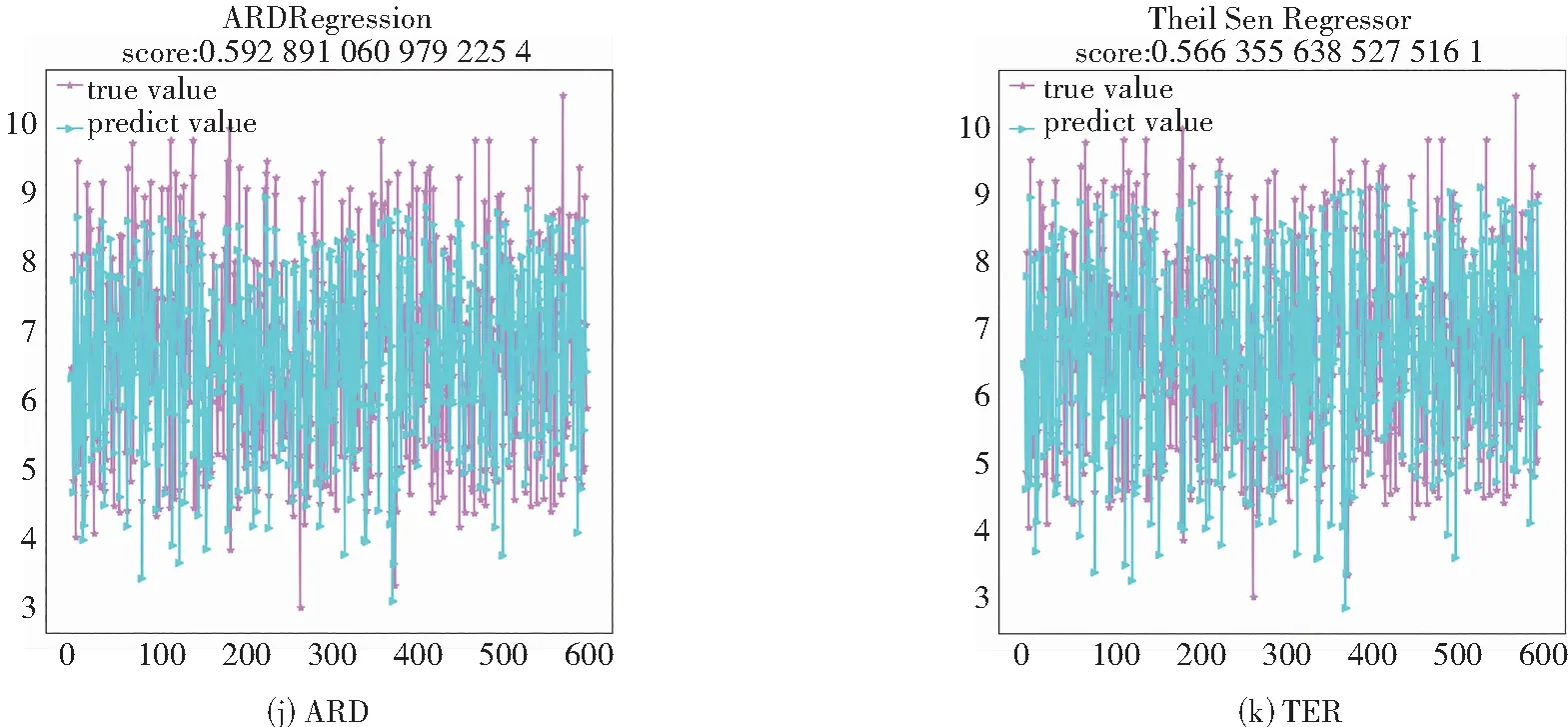
图6 各类算法预测YPIC50结果图Fig.6 Predicted YPIC50 results for each type of algorithm
为了更直观地对比GWO-KELM预测算法与其余算法的预测性能,本文共选取了3个指标来评价生物活性定量预测有效性,模型主要指标分别为拟合优度R2、均方误差、平均绝对误差,计算公式如下:
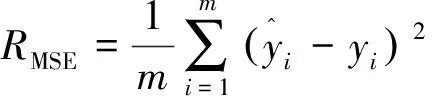
根据上述预测指标结果,将GWO-KELM模型与常见的12个预测模型进行比较,模型的主要指标对比如表3所示:
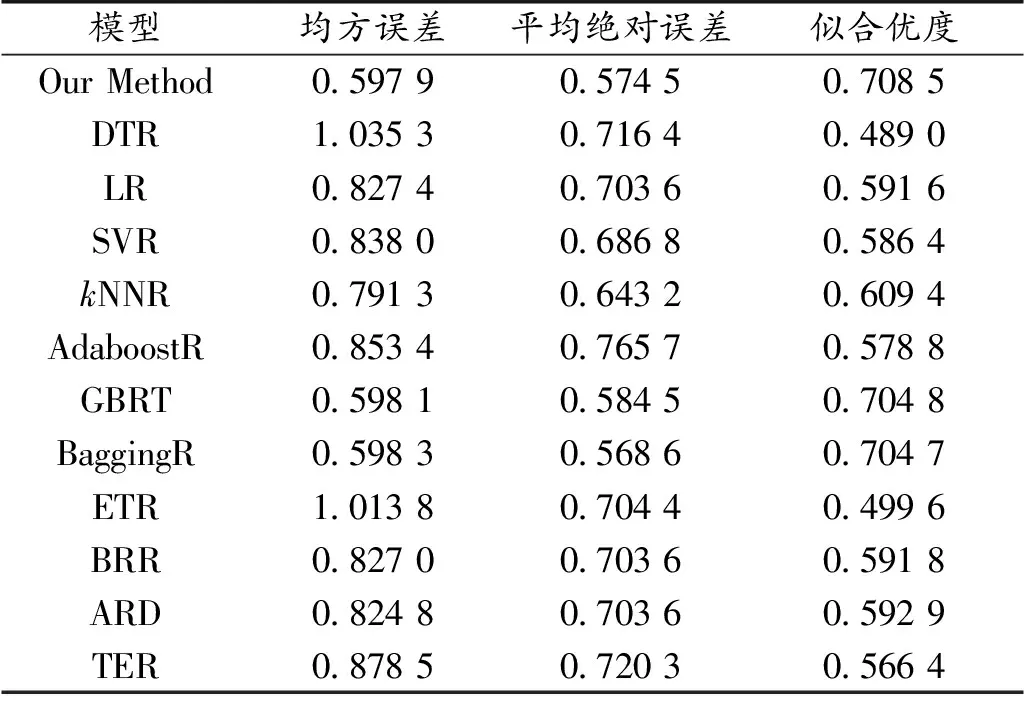
表3 各类算法指标汇总Table 3 Summary of metrics for each type of algorithm
上述结果表明,GWO-KELM生物活性定量预测模型具有良好的优越性及有效性,能够对生物活性定量预测进行良好的建模;另外,通过与真实值以及11个预测模型结果比较,验证了该算法的有效性。其本身模型的特性是在计算时不需要进行迭代,计算速度快,具有出色的泛化能力,能提供更为准确的预测结果;利用GWO算法优化KELM模型的参数,在参数取值范围内寻求全局最优的参数解,使得KELM模型的预测结果更加精确。
3.4 基于GWO-KELM模型定量预测结果
以上实验结论证明了GWO-KELM定量预测的优秀效果。对新的化合物进行预测,YPIC50由负对数变换而来,故无单位,具体可见式(3),预测结果见表4。
YIC50=10-YPIC50+9
(3)
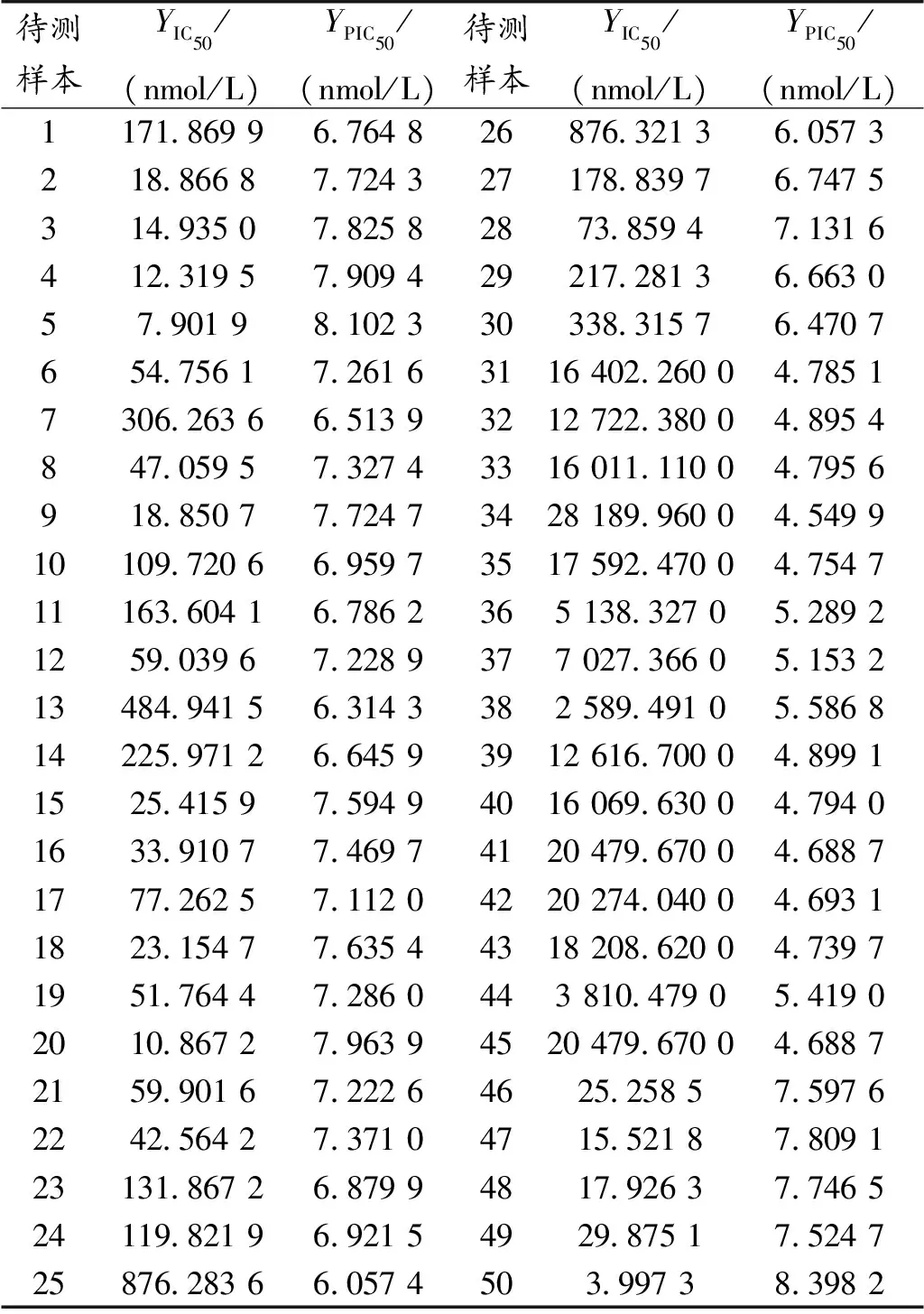
表4 YIC50值和YPIC50值预测结果Table 4 Predicted results of YIC50 and YPIC50 values
从预测结果来看:样本编号31—45的YIC50值,均超过2 500 nmol/L,其YPIC50低于6,可以认为这些新化合物对抑制ERα活性效果较差,无法成为治疗乳腺癌的候选药物,后续研究可考虑优化分子描述符结构或剔除。
4 基于GBDT算法的ADMET性质识别
化合物成为治疗乳腺癌的良好药物,必须具备良好的生物活性和ADEMT性质。其中,ADME主要指化合物的药代动力学性质,描述了化合物在生物体内的浓度随时间变化的规律,T主要指化合物可能在人体内产生的毒副作用。一个符合标准的化合物需具备优良的活性,其次还需要具有容易吸收、代谢适中和无毒等性质。
在选用学习算法进行分类预测建模时,需要考虑算法适用性,分析比较几类常用机器学习算法会发现:kNN(k-Nearest Neighbor)算法有着低复杂度的优势,但其可解释性不强,且计算时间很长,效率不高;LDA(Linear Discriminant Analysis)算法容易出现过拟合情形,严重影响模型的预测精度,导致泛化能力较低;LR(Logistic Regression)算法简单易行,可解释性强,但是其预测准确率不高;NBC(Native Bayes Classification)算法则需要先验假设相互独立,而文章数据集不符合此假设,因此也不适用;而GBDT算法非常适用于文章ADMET性质的分类预测分析。首先,文章涉及代表值分类为二元分类问题;其次,算法不需要对数据进行放缩就可以进行分类,同时,该算法损失函数较为稳定,在数据处理时鲁棒性较强。不仅如此,GBDT分类算法还充分考虑了每个分类器的权重,从而解决了本文的分类任务。因此,本文选择利用GBDT算法建立模型进行分类预测,同时选取查准率、F1值、AUC值3个评价指标作如下说明:

AUC值:ROC曲线右下方的集合面积,一般AUC值的范围大于0.5,在0.85以上为较强。
TP表示被模型预测为正类的正样本,其值用NTP表示;FP表示被模型预测为正类的负样本,其值用NFP表示。
4.1 GBDT原理
GBDT(Gradient Boosting Decision Tree)[13]是基于Boosting的梯度提升算法,采用此算法是因为它在算法可解释性上较强,且容易理解,预测湿度较快、精度较高。具体理论构建如下:
设训练集的特征和标签为
T=(x1,y1),(x2,y2),…,(xN,yN),xi∈χ,yi∈{0,1}
设二分类中的损失函数为L(y,f(x)),则有
L(y,f(x))=-logP(y|x)=log(1+e-yf(x))
则由Newton-Raphson迭代公式可得:
4.2 实验结果与比较分析
4.2.1 化合物渗透性识别
针对Caco-2的识别,图7是常见机器学习算法及本文算法基于训练数据的混淆矩阵,表5是各个算法的查准率、AUC值、F1得分统计。结果显示:GBDT查准率为93.83%,AUC值为94.47%,F1得分为92.40%,横向对比其余5个算法,其具有更好的评估效果与识别能力。
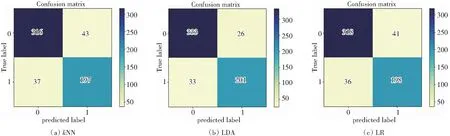
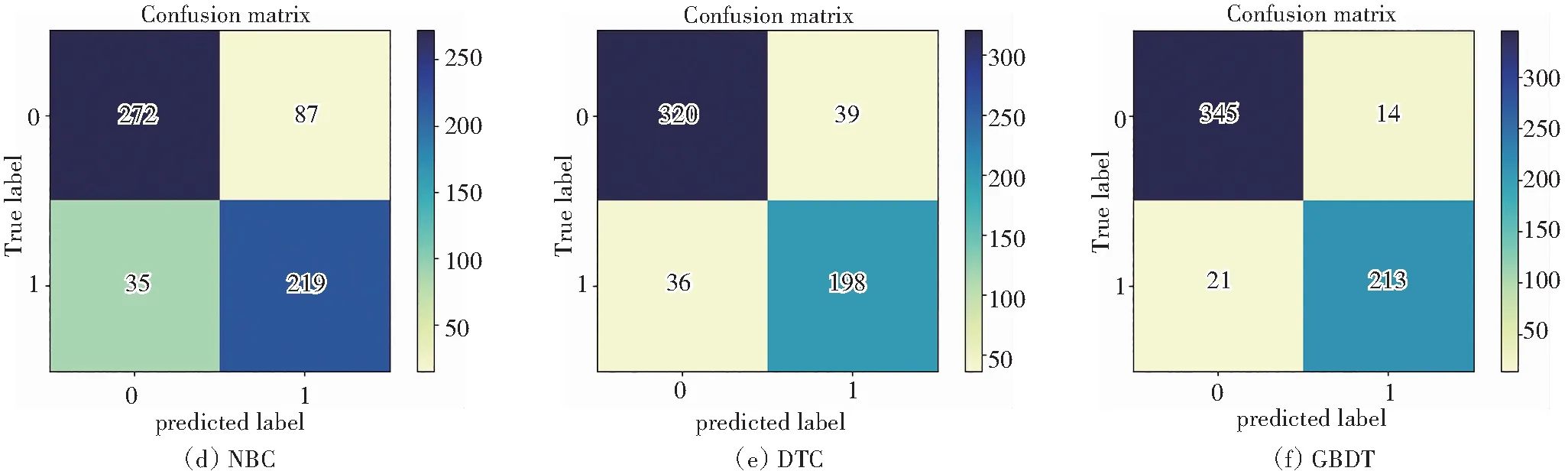
图7 各类算法预测Caco-2混淆矩阵Fig.7 Confusion matrix of Caco-2 predicted by various algorithms
4.2.2 化合物代谢能力识别
针对CYP3A4识别能力,图8和表6是常见机器学习算法及本文算法基于CYPEA4数据的混淆矩阵,结果显示:GBDT的测试集表现最优,其查准率可以达到97.03%,AUC值为93.68%,F1得分为96.81%,140种化合物样本被准确分类到0类,390种化合物被分类到1类中,识别能力很强。
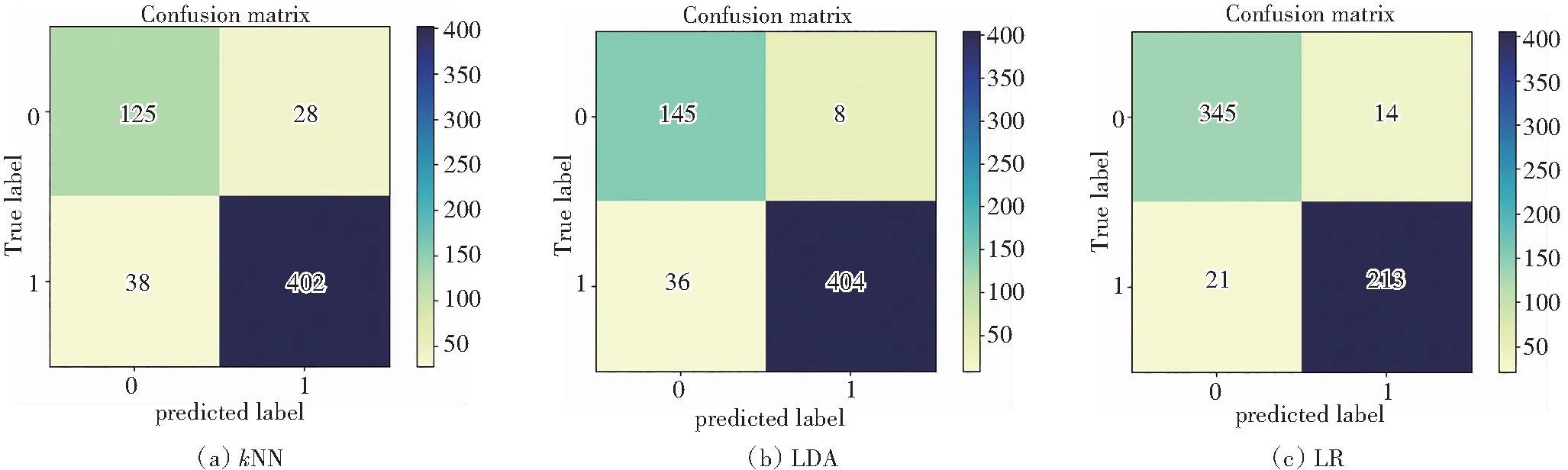
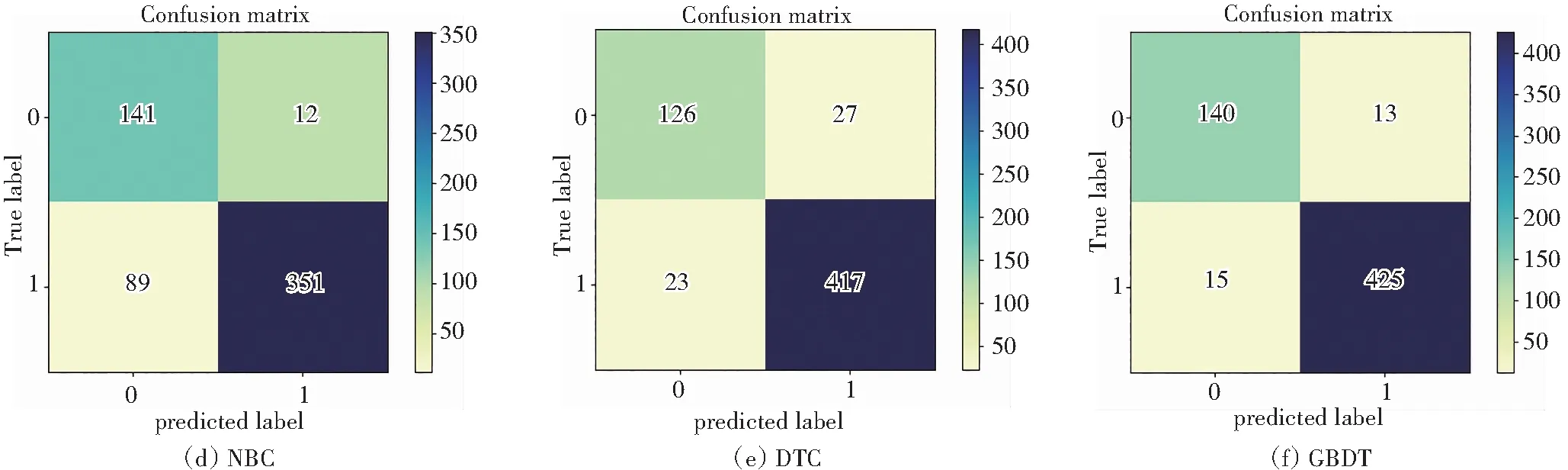
图8 各类算法预测CYP3A4混淆矩阵Fig.8 Confusion matrix of CYP3A4 predicted by various algorithms

表6 CYP3A4度量表Table 6 CYP3A4 metric scale
4.2.3 化合物心脏毒性识别
图9和表7是常见机器学习算法及本文算法基于hERG数据的混淆矩阵。结果显示:GBDT算法的查准率为90.61%、AUC值为89.22%、F1为90.47%。在心脏毒性识别中,测试集数据中有231种化合物被识别为0类,299中化合物被识别为1类,识别能力最优。
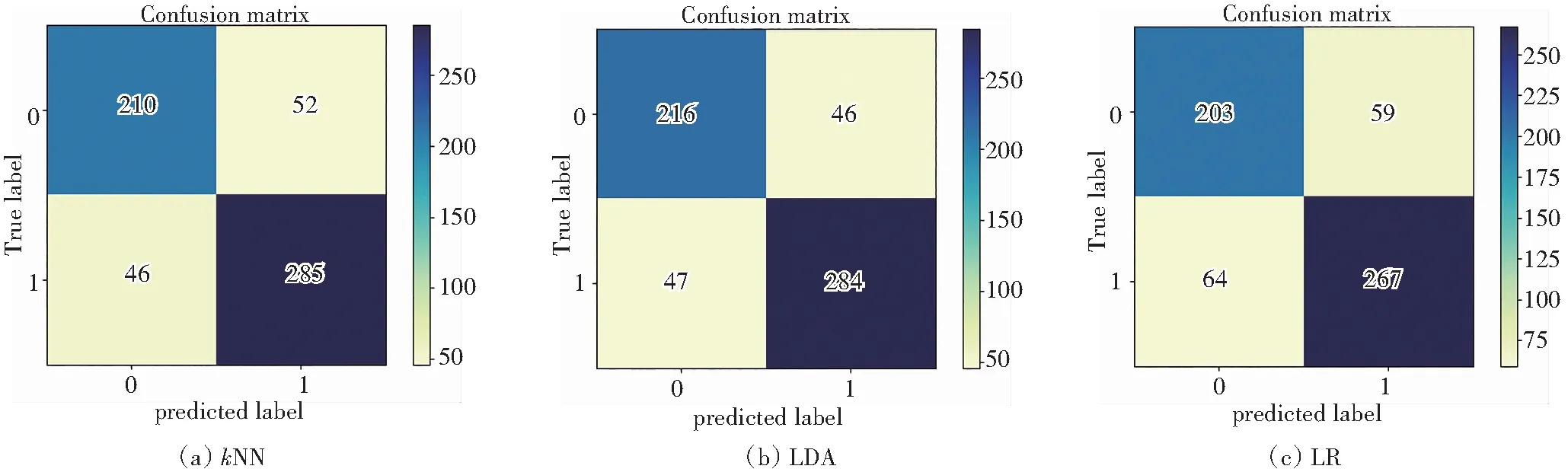
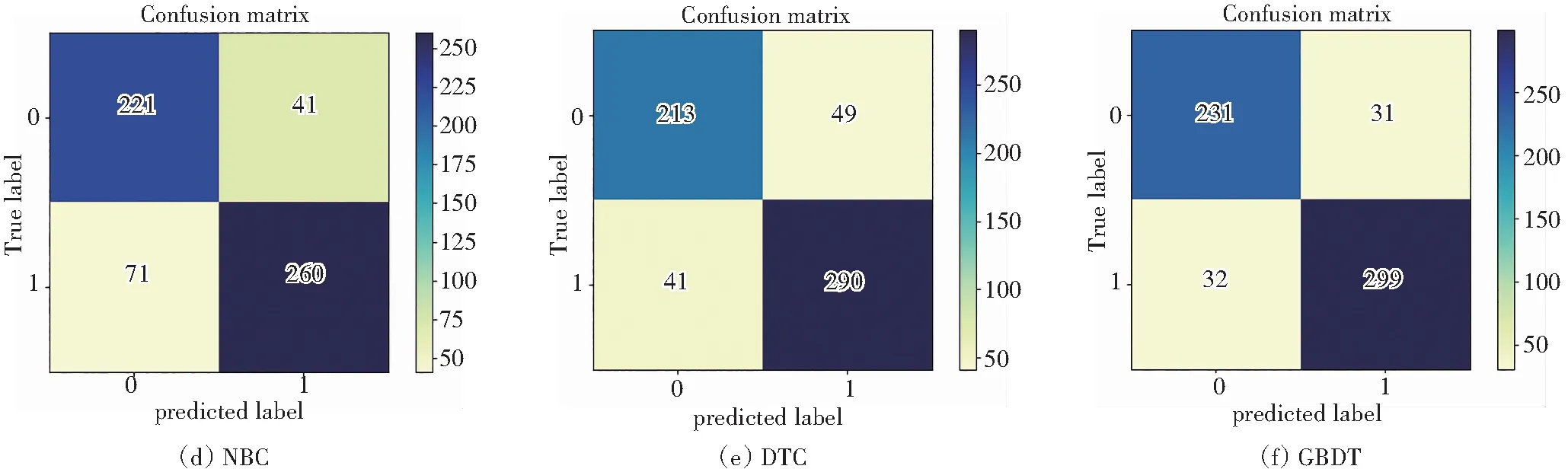
图9 各类算法预测hERG混淆矩阵Fig.9 Confusion matrix of hERG predicted by various algorithms
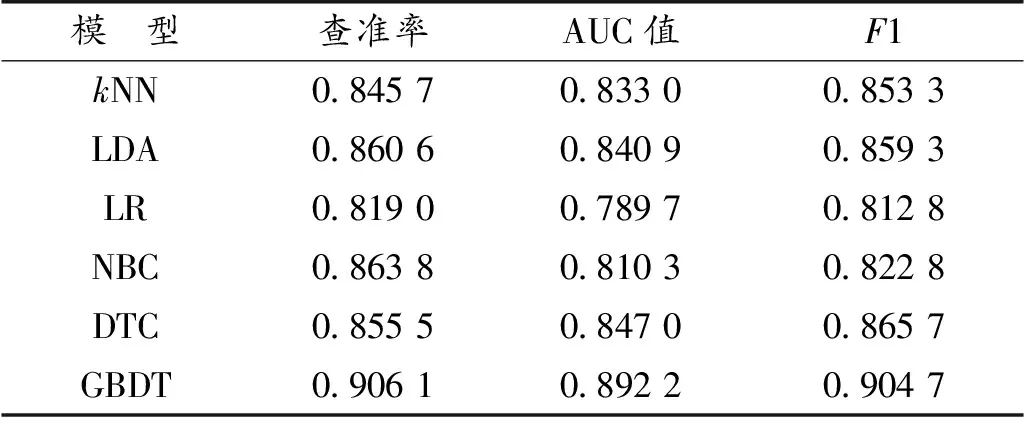
表7 hERG度量表Table 7 hERG metric scale
4.2.4 化合物利用度识别
针对化合物利用度识别,图10是常见机器学习算法及本文算法基于HOB数据的混淆矩阵,结果显示:GBDT算法的查准率为75.00%、AUC值为82.86%、F1为73.17%(表8)。测试集数据中有411种化合物被识别为0类,105中化合物被识别为1类,识别效果相对最优。
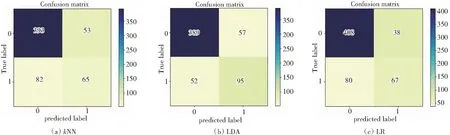

图10 各类算法预测HOB混淆矩阵Fig.10 Confusion matrix of HOB predicted by various algorithms
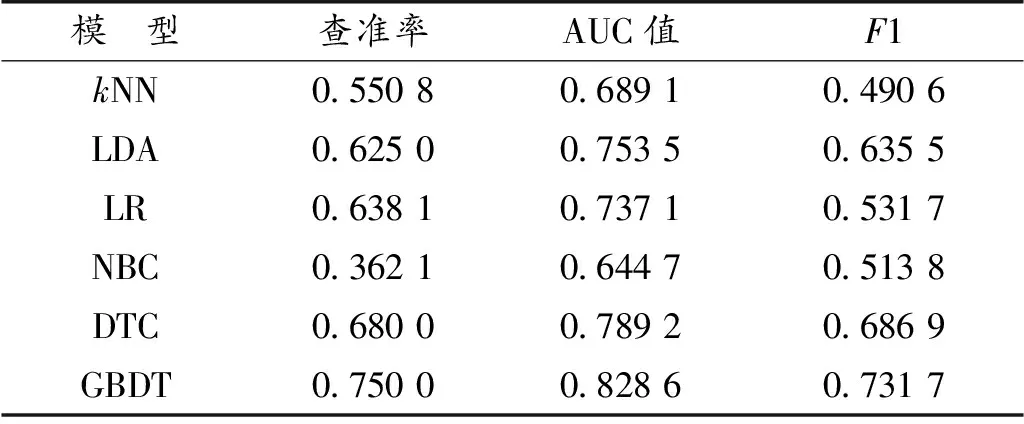
表8 HOB度量表Table 8 HOB metric scale
4.2.5 化合物遗传毒性识别
针对化合物遗传毒性识别,图11是常见机器学习算法及本文算法基于MN数据的混淆矩阵。结果显示:化合物遗传毒性识别中,GBDT算法的查准率为96.72%、AUC值为95.77%、F1为97.58%(表9)。测试集数据中有128种化合物被识别为0类,443中化合物被识别为1类,识别能力很强。

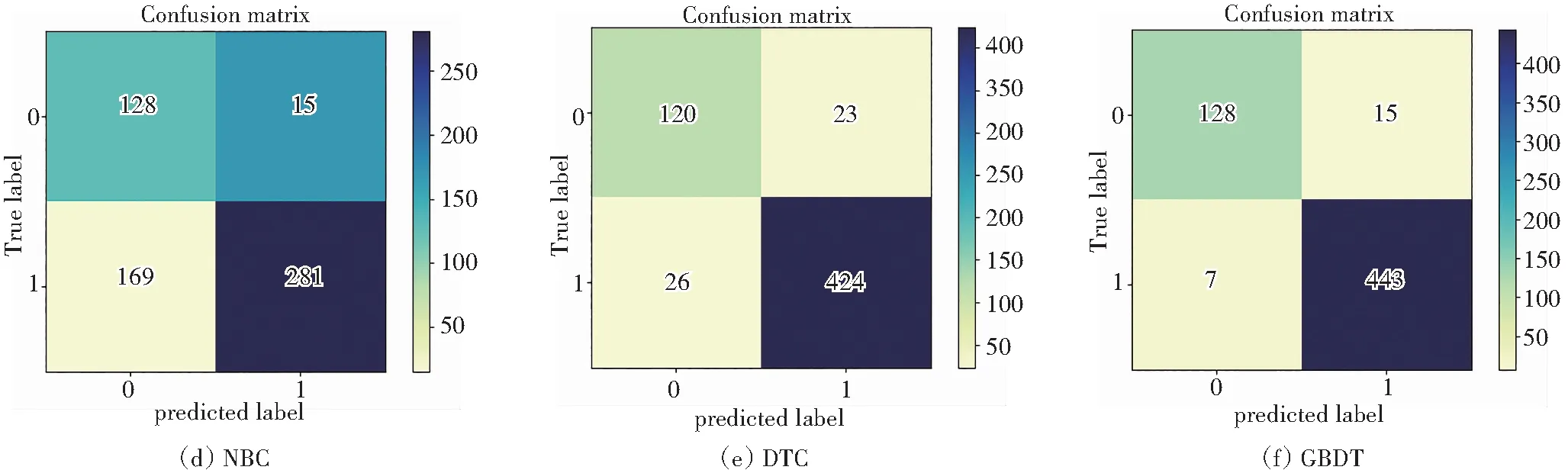
图11 各类算法预测MN混淆矩阵Fig.11 Confusion matrix of MN predicted by various algorithms
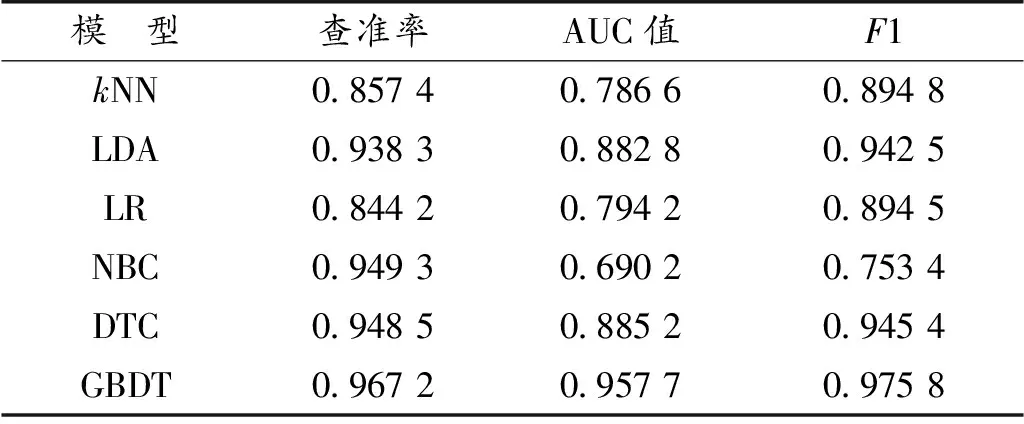
表9 MN度量表Table 9 MN metric scale
综上,基于GBDT算法构建的分类预测模型在测试集中对ADMET性质的识别表现优越,且都保持了较高的预测准确性,因此本文将该模型应用在新化合物的ADMET性质识别中,从而判断新化合物的代谢能力、心脏毒性等,具体预测结果见表10。
5 结束语
本文利用机器学习方法辅助实现抗乳腺癌候选药物研发,极大地节约了时间和成本,降低了人工误差。首先基于拮抗ERα的生物活性数据,利用稀疏贝叶斯学习以及随机森林算法,实现两阶段的变量筛选,并对1 974种化合物进行特征评估,得到20个重要特征;其次构建GWO-KELM算法进行YIC50与YPIC50的定量预测,并与传统的机器学习算法进行横向对比,证明本文改进算法的优越性,其均方误差最低,为0.598,拟合优度为0.709;最后利用GBDT算法分别构建ADMET性质的5个分类模型,进而对50种化合物做二分类预测,同时也做了机器学习算法的横向对比,其具有最优的预测结果,数据集上测试的分类F1分别为92.40%、96.81%、90.47%、73.17%、97.58%。本文算法相比一些传统机器学习算法,具有更好的预测效果,可以为抗乳腺癌候选药物研发提供预测服务,具有一定的实践价值。

表10 GBDT算法预测ADMET性质结果Table 10 Results of GBDT algorithm for predicting ADMET properties
在进一步的研究中,拟从如下几个方面进行延伸:
在抗乳腺癌候选药物的筛选过程中,应该同时考虑将化合物ERα的生物活性以及ADMET性质进行综合评判,在化合物具有较好生物活性的前提下,保证其ADMET性质较好,诸如代谢能力、遗传毒性、渗透性等。
在充分挖掘结构性数据信息中,进一步可以采用图神经网络等深度学习方法,对化合物的一维线性表达式SMILES进行更深层的数据挖掘。
基于筛选重要化合物的分子描述符,进一步可以通过反向优化算法,确定分子描述符的最优阈值,进而调整化合物结构,使得ERα和ADMET性质具有更好的表现。
猜你喜欢
中学生数理化·中考版(2021年12期)2021-12-31
中学生数理化·中考版(2021年11期)2021-12-06
中学生数理化(高中版.高二数学)(2021年5期)2021-07-21
数学小灵通(1-2年级)(2021年4期)2021-06-09
中等数学(2020年6期)2020-09-21
中等数学(2019年6期)2019-08-30
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年4期)2018-06-28
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
中学化学(2017年6期)2017-10-16
