
基于机器学习的长沙市滑坡灾害快速风险评价①
2023-11-16 10:50:34方亚其刘磊磊
矿冶工程 2023年5期
王 璨, 肖 浩, 肖 婷, 方亚其, 刘磊磊
(1.湖南省地质灾害调查监测所,湖南 长沙 410004; 2.湖南省地质灾害监测预警与应急救援工程技术研究中心,湖南 长沙 410004; 3.有色金属成矿预测与地质环境监测教育部重点实验室,湖南 长沙 410083; 4.湖南省有色资源与地质灾害探查湖南省重点实验室,湖南 长沙 410083; 5.中南大学地球科学与信息物理学院,湖南 长沙 410083)
我国地质环境脆弱、孕灾条件复杂,是世界上滑坡灾害最严重的国家之一[1]。 滑坡灾害风险评价是滑坡灾害风险管理的核心,是认识滑坡灾害灾情、制定防灾政策、实施防治措施的重要依据。 国内外学者对区域滑坡灾害风险评价的各环节进行了大量探索性研究。 在危险性评价中,常用的评价方法为定性分析法、确定性分析法和概率统计法。 其中,支持向量机、人工神经网络、随机森林等统计机器学习算法[2]因其优良的评价效果得到广泛应用。 目前,评价机器学习模型性能的常用指标有模型精度和接受者操作特性曲线(ROC)[3],这些指标可以有效评价模型在样本集数据建模预测中的优劣,但不能反映模型在非样本区域的评价性能。 对承灾体易损性评价的研究,目前处于从定性分析到定量计算的发展阶段。 在区域性易损性评价工作中,承灾体系统相当复杂,不同研究区承灾体与灾害的作用机理不尽相同,导致定量评价模型并不具备很好的普适性。 风险包括灾害体本身及其造成的后果,常通过精细化承灾体分析计算定量风险,或采用启发式矩阵的经验方法对风险进行分级[4]。
本文采用机器学习模型进行长沙市滑坡灾害危险性评价,基于频率比法检验模型在非样本集上的性能,并对评价结果较差的模型进行矫正;不考虑承灾体的脆弱性差异,选取代表性指标因子构成易损性评价体系,实现易损性的快速评价;引入风险分区矩阵完成长沙市滑坡灾害风险区划,以期为长沙市的防灾减灾规划提供科学依据和理论基础。
1 研究区概况
长沙市位于湖南省东部偏北,湘江下游和长浏盆地西缘,其地理位置介于东经111°53′~114°15′、北纬27°51′~28°40′。 该地属亚热带季风湿润气候区,其特点是春冬多雨、夏秋多晴、严冬期短、暑热期长。 域内各个地质历史时期的地层均有出露,花岗岩体广布,以第四系地层分布最多。 据湖南省国土资源厅提供的资料显示,长沙市滑坡灾害点共808 处(见图1),按照地质灾害灾情分级标准,以小型滑坡为主(802 处),中型滑坡层占极少数(6 处)。
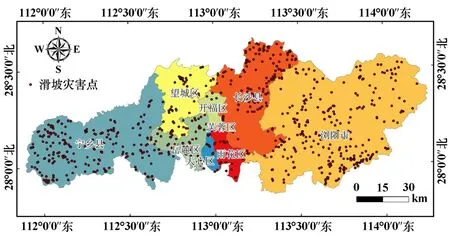
图1 研究区滑坡灾害点分布图
2 研究方法
2.1 危险性评价方法
2.1.1 随机森林模型
随机森林模型(Random Forests, RF)是利用多棵决策树作为分类器对样本进行训练与预测的分类模型[5],算法模型如图2 所示。 该模型方法结合了基于训练样本操作的装袋算法和基于特征集操作的随机子空间方法,将多个决策树结合在一起,有放回地随机选取样本并将部分特征作为输出[6],其预测结果由每棵树的结果投票产生,取投票数最多的类或取其平均值作为结果,具有较好的准确率和稳定性。
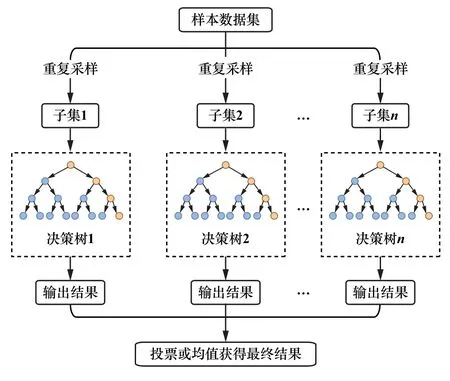
图2 随机森林模型算法示意
2.1.2 极限梯度提升
极限梯度提升(XGBoost)使用梯度增强框架,是一种基于决策树的集成方法[7]。 该方法的核心原理是逐棵建立分类或回归树,然后利用之前树的残差来训练后续的模型。 它将之前已训练树的结果进行集成从而得到更好的结果。 XGBoost 预测值可按下式计算:
式中^y(t)为最终树群的预测值;^y(t-1)为之前树群的预测值;xi为样本i对应的特征值;ft(xi)为新生成树的预测值;t为基础树模型的总数。
2.2 基于FR 的危险性评价模型校正
常用的ROC 曲线和AUC(Area Under Curve,曲线下面积值)值能够很好地反映评价模型在样本集数据上的评价性能,但不能反映模型在非样本集数据上的性能表现。 本文采用滑坡发生频率比(Frequency ratio,FR)与滑坡空间概率之间的线性理论对模型预测结果进行校正[8],以补偿ROC 曲线和AUC 指标在评价非样本集数据上的不足。
FR 表征了各子分类对于滑坡发生的重要程度,可由下式计算得到:
子分类内的滑坡数与子分类面积之比表示子分类内滑坡发生的空间概率,而研究区内滑坡数与研究区面积之比为一常数,那么滑坡发生空间概率与FR的意义就相一致了[8]。 因此可以使用FR值对危险性评价模型进行校正:当FR与危险性值成线性关系时,该危险性区划图能更合理地表达滑坡发生的空间概率。FR>1 时,说明子分类有利于滑坡的发生;FR<1 时,说明该子分类不利于滑坡发生[9]。
2.3 易损性评价方法
采用层次分析法综合分析各指标因素,建立易损性评价模型。 层次分析法能够将复杂的定性问题简明化,合理计算出各指标的综合权重系数,应用步骤如下[10]:
1) 将要素分解为目的层、准则层和方案层,构造递阶层次结构模型;
2) 根据影响因素的结构隶属关系,引用数字1 ~9及其倒数作为标度构造判断矩阵;
3) 进行一致性检验并确定各因素的总权重值,带入下式计算得到易损性指数[11]:
式中Vi为评价单元的地质灾害综合易损性指数;i为评价单元;ωj为第i个评价单元第j个评价指标的权重值;yj为第i个评价单元第j个评价指标标准化后的取值。
3 基于机器学习的滑坡危险性评价
3.1 评价因子选取
从地形地貌、地质条件、自然环境和人类工程活动要素中提取15 个评价因子研究滑坡的形成机制。 数据分别来源于数字高程模型、长沙市1 ∶50000 地质图、长沙市1 ∶50000 地形图及土地利用数据。 评价区域属于大区域,评价单元选用25 m×25 m 的栅格。
在模型计算前,通过皮尔逊相关系数对指标因子进行相关性分析,得到15 个评价因子间的皮尔逊系数见图3,其中平面曲率、剖面曲率、地形起伏度和水流强度指数与部分因子之间相关性系数的绝对值大于0.5,表明这些因子之间相关程度较高[12]。 以剔除平面曲率等因子后剩余的11 个因子组成危险性评价指标体系,并将各因素指标按照相应标准划分出多个二级状态。 其中,离散型数据依据野外调查论证制定划分标准,连续性数据采用自然间断点法划分等级,相应因子分布如图4 所示。
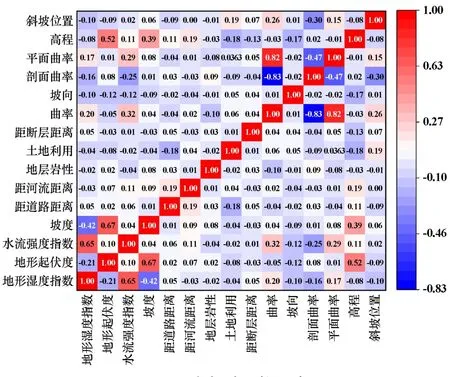
图3 皮尔逊系数矩阵
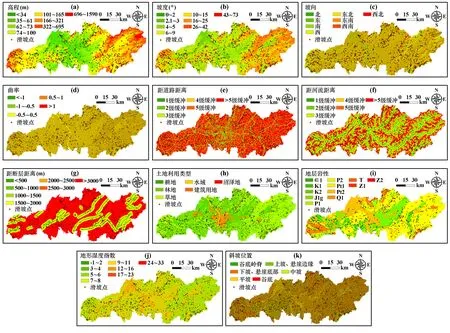
图4 滑坡影响因子分布图
3.2 模型建立
危险性评价样本集由正样本和负样本构成。 正样本数据为滑坡编录数据中的808 个滑坡点,在滑坡点100 m 缓冲区外随机采样生成808 个负样本数据,并将样本集按7 ∶3切割为训练集和测试集。 在Python 中分别构建RF 和XGBoost 模型,导入样本集数据进行训练,将训练好的模型应用至全区实现危险性评价。
ROC 曲线常用来评价易发性模型精度,AUC 与评价精度正相关[13]。 一般来说,ROC 曲线越接近(0,1)点,AUC 值越接近1,模型的预测准确率越高。 采用ROC 曲线对RF 和XGBoost 模型预测结果进行评价检验,2 个机器学习模型的AUC 值分别为0.77 和0.76(见图5),精度相近。
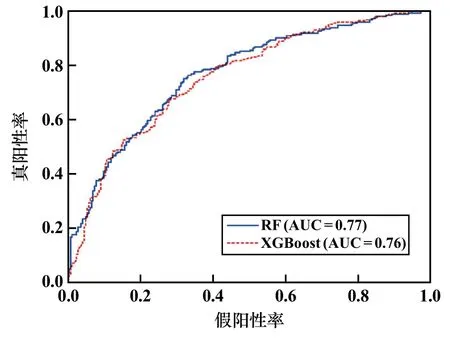
图5 ROC 曲线
3.3 基于FR 模型校正
采用自然断点法将危险性值进行分区,得到RF和XGBoost 模型下的滑坡危险性分区如图6 所示。 为使分布图能更合理表达滑坡发生的空间概率,基于FR值对其进行检验及校正。
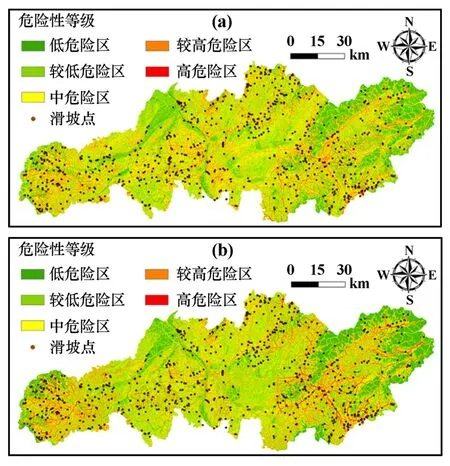
图6 不同模型生成的危险性分布图
将危险性值等间隔划分为50 个区间,统计各个区间的FR 值,图7 为RF 和XGBoost 模型中危险性值与FR 值的关系。 可知,2 个模型中危险性值与FR 值均不成线性关系,且2 个模型都在低危险区低估了滑坡发生的概率,而在高危险区高估了滑坡发生的空间概率,因此需要对危险性分布图进行校正。 其中,RF 模型比XGBoost 模型下的危险性预测值分布更加极端,滑坡几乎只在高危险区中出现。
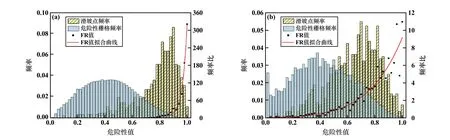
图7 各危险性分布图的频率比分布
2 个模型FR 值与危险性值的拟合关系表达式分别为:
将原始的危险性值代入式(4)~(5)中,并将归一化后的结果作为校正后的危险性值,从而将FR 值与危险性值之间的非线性关系转化为线性关系,结果如图8 和图9 所示。 可知,RF 模型校正后的结果几乎分布于低危险性值区,频率分布过于极端。 XGBoost模型校正后危险性值与FR 值呈现良好的线性关系,且危险性值分布较均匀,表明XGBoost 模型在非样本集上的预测性能更加优良。 以矫正后的XGBoost 模型结果作为最终的危险性区划结果(见图9(b)),研究区内低、较低、中、较高和高危险区面积分别占比36.3%、28.5%、22.4%、11.5%和1.3%,低危险区到高危险区面积占比依次降低。
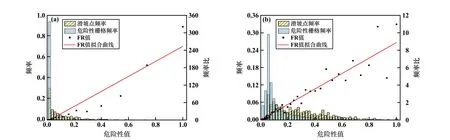
图8 校正后危险性分布图的频率比分布
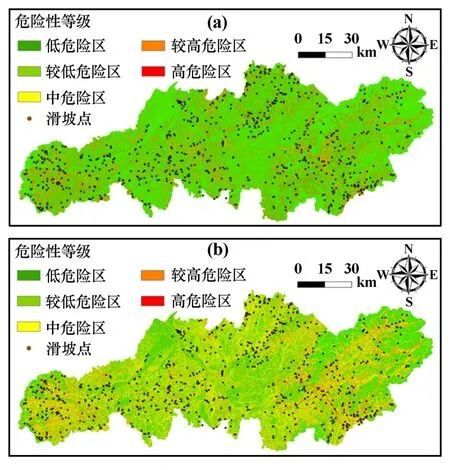
图9 校正后模型生成的危险性分布图
4 基于层次分析法的承灾体易损性评价
4.1 评价因子选取及权重确定
城市地质灾害以人口、建筑物和道路为重要的承灾体,选取这3 个评价因子密度值来表征各因子的易损性程度,并构建递阶层次模型以确定各因子之间的从属关系,相互对比之后的构造判断矩阵如表1所示。 计算结果显示,最大特征值λmax=3,一致性结果CR<0.1,满足一致性检验要求[14],将λmax对应的特征向量进行归一化得到各指标因子权重值如表1所示。
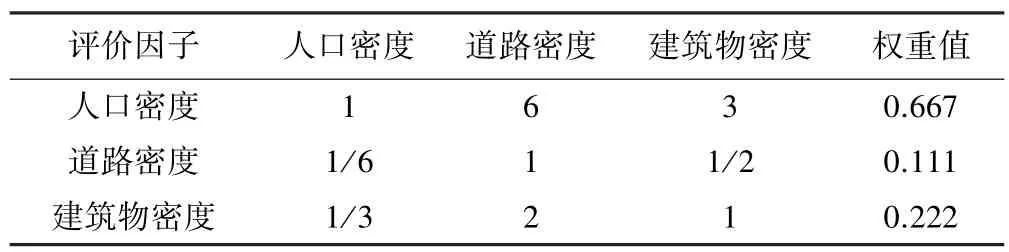
表1 易损性评价因子判断矩阵及权重值
4.2 易损性评价结果
基于ArcGIS 平台,根据式(3)计算每个评价单元的易损性指数,按自然间断法将研究区由低到高划分为5 个等级,易损性分级与区划如图10 所示。 据统计,低、较低、中、较高和高易损区面积分别占长沙市面积的49.9%、26.6%、16.5%、4%和3%;较高-高易损区主要为城镇及人口聚集区、风景区和交通干线。
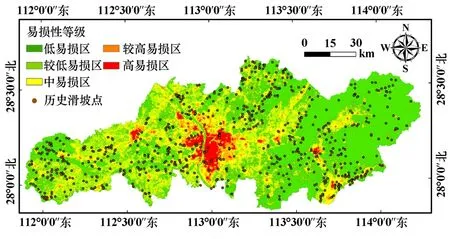
图10 承灾体易损性区划图
5 滑坡灾害风险评价
5.1 风险分区矩阵
在地质灾害的风险评估中,风险是因变量,风险等级由滑坡灾害危险性等级与承灾体易损性等级共同决定。 采用如图11 所示的风险矩阵对长沙市风险进行定性评估。 其中不同的数字代表不同的程度等级,1~5分别表示低、较低、中、较高和高。
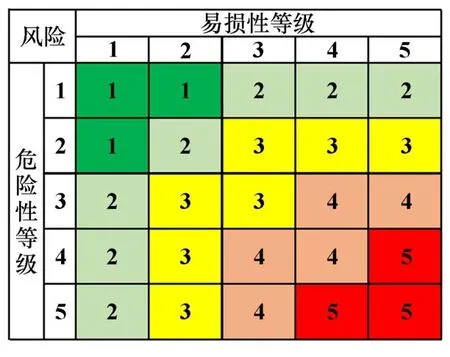
图11 风险分区矩阵
5.2 风险评价结果
风险评价结果如图12 所示。 低、较低、中、较高和高风险区分别占研究区面积的41.4%、32.9%、21.1%、4.2%和0.4%。 可知,随着风险等级增加,相应区划面积递阶减小,具备较高的评价精度。
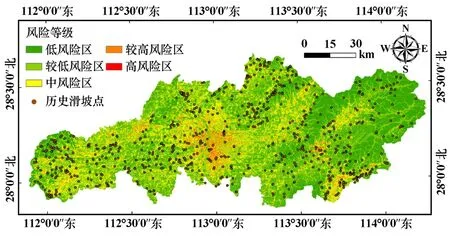
图12 滑坡风险区划图
较高-高风险区主要分布在沟谷、城镇和交通干线等区域。 对比长沙市行政区划图,可知芙蓉区、天心区东部等地处于较高-高风险区,这些区域是全市城市化程度最高、人类工程活动最强烈的地带,联合自然因素的影响产生了大量的潜在不稳定斜坡。 同时,雨花区、开福区等区域的危险性等级不高,但这些区域承灾体有较高的易损性等级,故相应区域也呈现出较高的风险态势。
6 结论
采用RF 和XGBoost 模型对长沙市滑坡危险性进行评价,基于FR 值对结果进行检验和校正,以提高模型在非样本集数据上的合理性和准确性,并采用层次分析法实现承灾体易损性快速评价,集成危险性和易损性评价结果进而生成滑坡风险评价结果。 主要研究结论如下:
1) 经FR 值检验,RF 和XGBoost 模型都在低危险区低估了滑坡空间概率,而在高危险区高估了滑坡空间概率。 以频率比法校正后,XGBoost 模型比RF 模型评价结果分布更合理。 在RF 模型(AUC =0.77)与XGBoost 模型(AUC =0.76)性能相近的情况下,以在非样本集表现更好的XGBoost 模型生成危险性评价结果。
2) 危险性评价结果表明,研究区内低、较低、中、较高和高危险区面积分别占比36.3%、28.5%、22.4%、11.5%和1.3%,面积占比依次降低,精度较高。
3) 选取人口密度、道路密度和建筑物密度构成易损性快速评价指标体系,采用层次分析法得到人口密度对易损性评价的影响最大。
4) 运用数值分级方法将研究区划分为低风险区(41.4%)、较低风险区(32.9%)、中风险区(21.1%)、较高风险区(4.2%)和高风险区(0.4%)。 长沙市较高、高风险多分布在沟谷、城镇和交通干线等地,与实际情况一致,模型预测精度较高。
猜你喜欢
幼儿画刊(2022年8期)2022-10-18 01:44:10
化学工业与工程(2022年1期)2022-03-29 01:14:36
小资CHIC!ELEGANCE(2021年36期)2021-10-15 02:25:24
有色设备(2021年4期)2021-03-16 05:42:32
工程与建设(2019年5期)2020-01-19 06:22:48
中国特种设备安全(2019年10期)2020-01-04 01:56:12
广州大学学报(自然科学版)(2016年2期)2017-01-15 13:42:53
湖南行政学院学报(2016年2期)2016-12-01 06:21:45
苏州科技大学学报(工程技术版)(2015年3期)2015-02-28 16:21:17
水土保持通报(2014年5期)2014-06-09 08:27:30
